Curso
Mineração de Texto com Bag-of-Words em R
4 h
44.3K
Os dados de texto são um dos tipos mais comuns de dados que as empresas usam atualmente, mas, como não têm uma estrutura clara, pode ser difícil e demorado extrair insights dos dados de texto. Lidar com dados de texto faz parte do Processamento de Linguagem Natural, um dos subcampos da inteligência artificial.
O Processamento de Linguagem Natural (PLN) é um campo da ciência da computação e da inteligência artificial que analisa como os computadores interagem com as linguagens humanas e como programar computadores para processar e analisar grandes quantidades de dados de linguagem natural.
A PNL é usada de muitas maneiras diferentes, como para responder a perguntas automaticamente, gerar resumos de textos, traduzir textos de um idioma para outro etc. A pesquisa em PNL também é realizada em áreas como ciência cognitiva, linguística e psicologia. A classificação de textos é um desses casos de uso da NLP.
Este blog explorará os casos de uso de classificação de texto. Ele também contém um exemplo completo de como criar um pipeline de pré-processamento de texto seguido de um modelo de classificação de texto em Python.
Se você quiser saber mais sobre o processamento de linguagem natural, nossos cursos Processamento de linguagem natural em Python e Processamento de linguagem natural em R são úteis. Você adquirirá as principais habilidades de PNL necessárias para converter esses dados de texto em insights valiosos. Você também conhecerá as bibliotecas populares de PNL em Python, incluindo NLTK, scikit-learn, spaCy e SpeechRecognition
A classificação de texto é uma tarefa comum de PNL usada para resolver problemas de negócios em vários campos. O objetivo da classificação de texto é categorizar ou prever uma classe de documentos de texto não vistos, geralmente com a ajuda do aprendizado de máquina supervisionado.
Semelhante a um algoritmo de classificação que foi treinado em um conjunto de dados tabulares para prever uma classe, a classificação de texto também usa aprendizado de máquina supervisionado. O fato de o texto estar envolvido na classificação do texto é a principal distinção entre os dois.
Você também pode realizar a classificação de texto sem usar o aprendizado de máquina supervisionado. Em vez de algoritmos, um sistema manual baseado em regras pode ser projetado para executar a tarefa de classificação de texto. Na próxima seção, compararemos e analisaremos os prós e os contras dos sistemas de classificação de texto baseados em regras e em aprendizado de máquina.
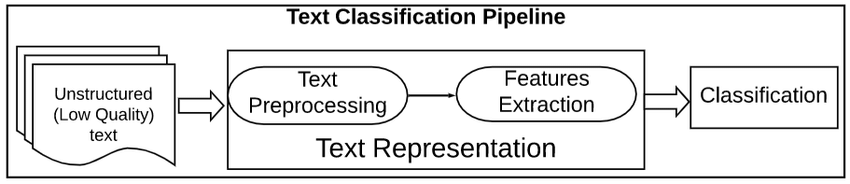
Se quiser saber mais sobre aprendizado de máquina supervisionado, consulte nosso artigo separado.
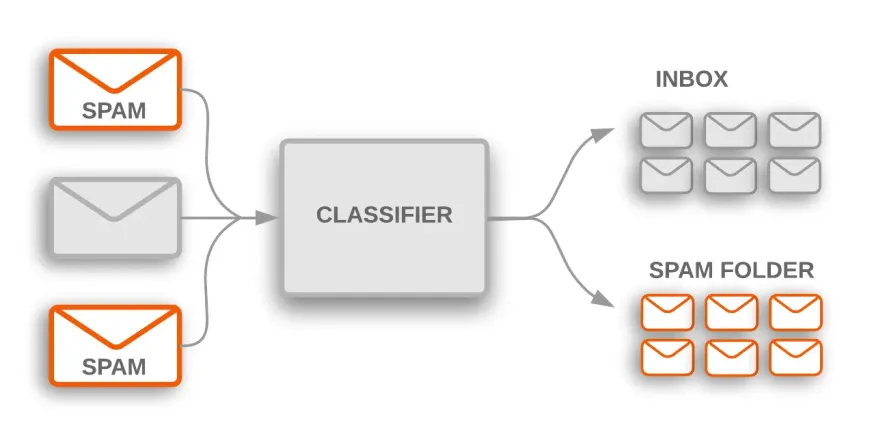
Há muitos casos de uso prático para classificação de texto em vários setores. Por exemplo, um filtro de spam é um aplicativo comum que usa classificação de texto para classificar e-mails em categorias de spam e não spam.
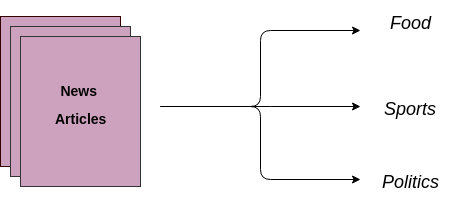
Outro caso de uso é atribuir automaticamente documentos de texto a categorias predeterminadas. Um modelo de aprendizado de máquina supervisionado é treinado em dados rotulados, que incluem tanto o texto bruto quanto o alvo. Depois que um modelo é treinado, ele é usado na produção para obter uma categoria (rótulo) nos dados novos e não vistos (artigos/blogs escritos no futuro).
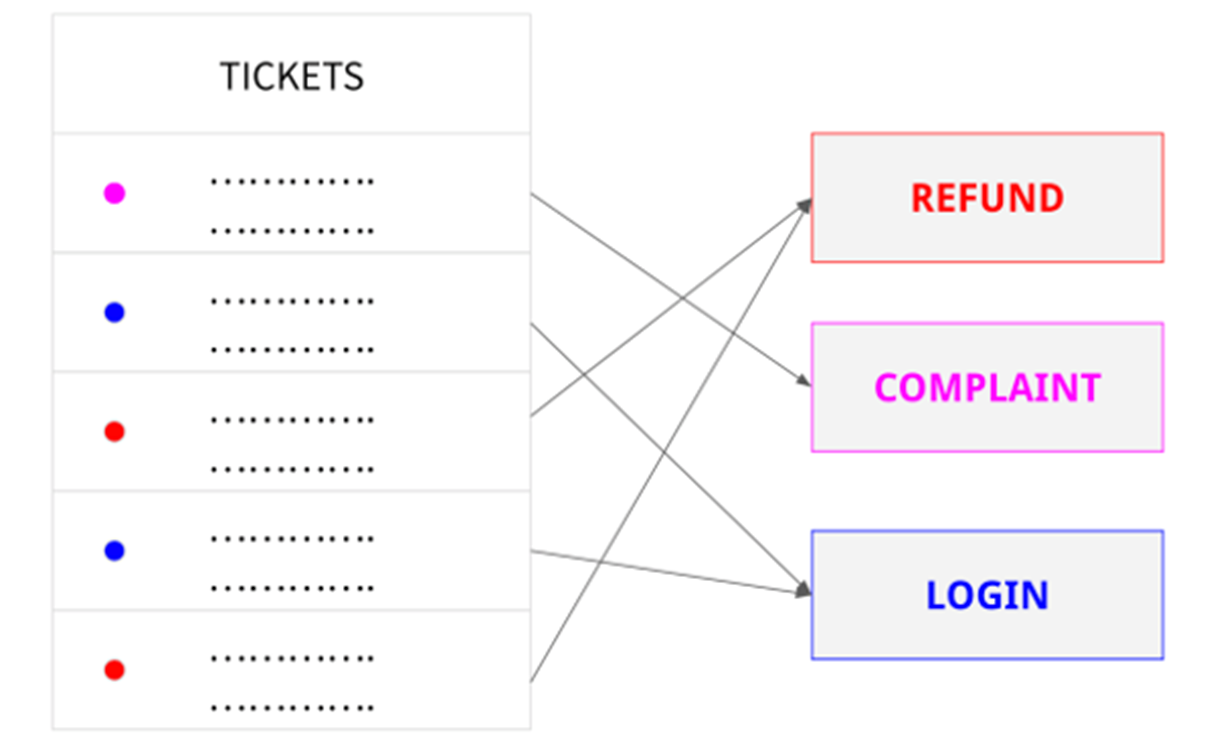
Uma empresa pode usar a classificação de texto para categorizar automaticamente as solicitações de suporte ao cliente por tópico ou para priorizar e encaminhar as solicitações para o departamento apropriado.
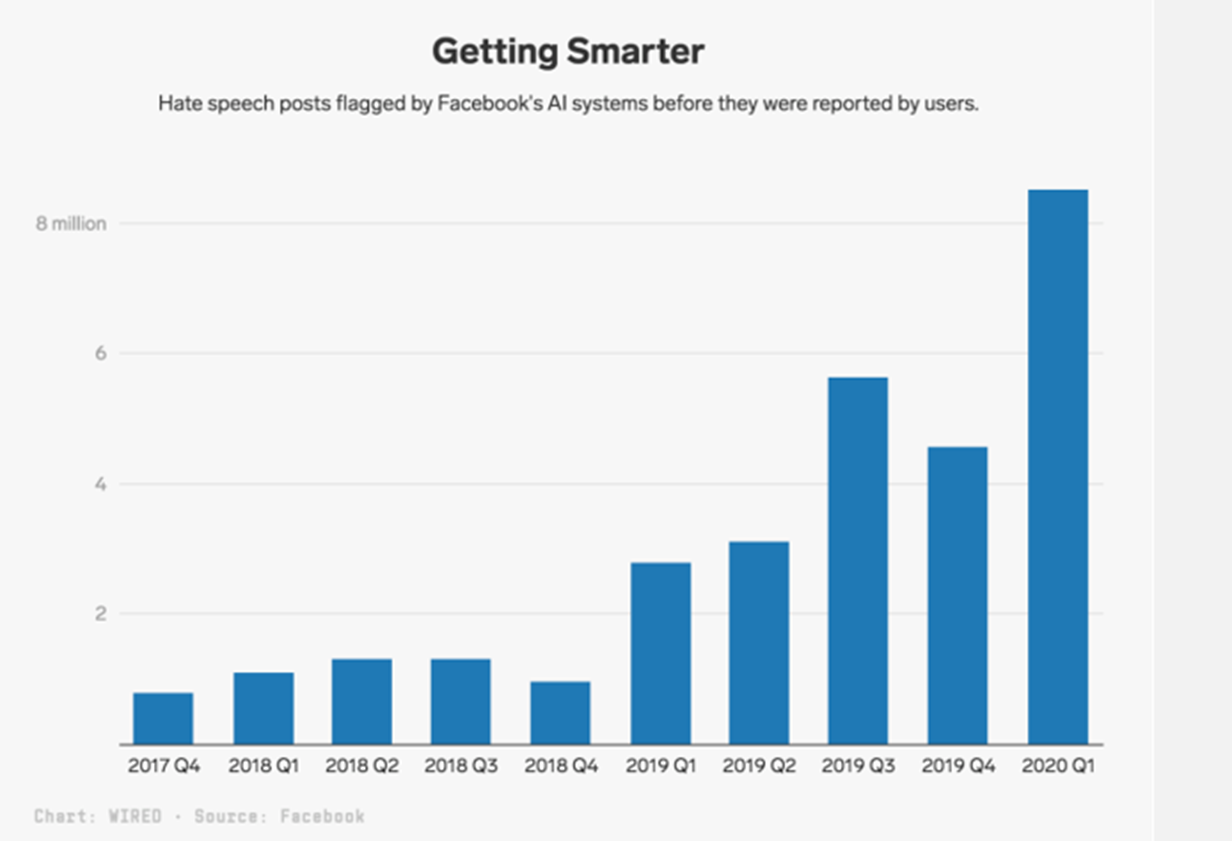
Com mais de 1,7 bilhão de usuários ativos diariamente, o Facebook inevitavelmente tem conteúdo criado no site que é contra as regras. O discurso de ódio está incluído nesse conteúdo indesejável.
O Facebook aborda esse problema solicitando uma revisão manual das publicações que um classificador de texto de IA identificou como discurso de ódio. As postagens que foram sinalizadas pela IA são examinadas da mesma forma que as postagens que os usuários denunciaram. De fato, apenas nos três primeiros meses de 2020, a plataforma removeu 9,6 milhões de itens de conteúdo que haviam sido classificados como discurso de ódio.
Há principalmente dois tipos de sistemas de classificação de texto: classificação de texto baseada em regras e baseada em aprendizado de máquina.
As técnicas baseadas em regras usam um conjunto de regras de linguagem construídas manualmente para categorizar o texto em categorias ou grupos. Essas regras dizem ao sistema para classificar o texto em uma categoria específica com base no conteúdo de um texto usando elementos textuais semanticamente relevantes. Cada regra é composta por um antecedente ou padrão e uma categoria projetada.
Por exemplo, imagine que você tenha muitos artigos novos e seu objetivo seja atribuí-los a categorias relevantes, como Esportes, Política, Economia etc.
Com um sistema de classificação baseado em regras, você fará uma análise humana de alguns documentos para chegar a regras linguísticas como esta:
Os sistemas baseados em regras podem ser refinados com o tempo e são compreensíveis para os seres humanos. No entanto, essa estratégia tem algumas desvantagens.
Esses sistemas, para começar, exigem um conhecimento profundo no campo. Elas levam muito tempo, pois a criação de regras para um sistema complicado pode ser difícil e, com frequência, exige estudos e testes extensivos.
Como a inclusão de novas regras pode alterar os resultados das regras preexistentes, os sistemas baseados em regras também são difíceis de manter e não são dimensionados de forma eficaz.
A classificação de texto baseada em aprendizado de máquina é um problema de aprendizado de máquina supervisionado. Ele aprende o mapeamento dos dados de entrada (texto bruto) com os rótulos (também conhecidos como variáveis de destino). Isso é semelhante aos problemas de classificação sem texto, em que treinamos um algoritmo de classificação supervisionado em um conjunto de dados tabulares para prever uma classe, com a exceção de que, na classificação de texto, os dados de entrada são textos brutos em vez de recursos numéricos.
Como qualquer outro aprendizado de máquina supervisionado, o aprendizado de máquina de classificação de texto tem duas fases: treinamento e previsão.
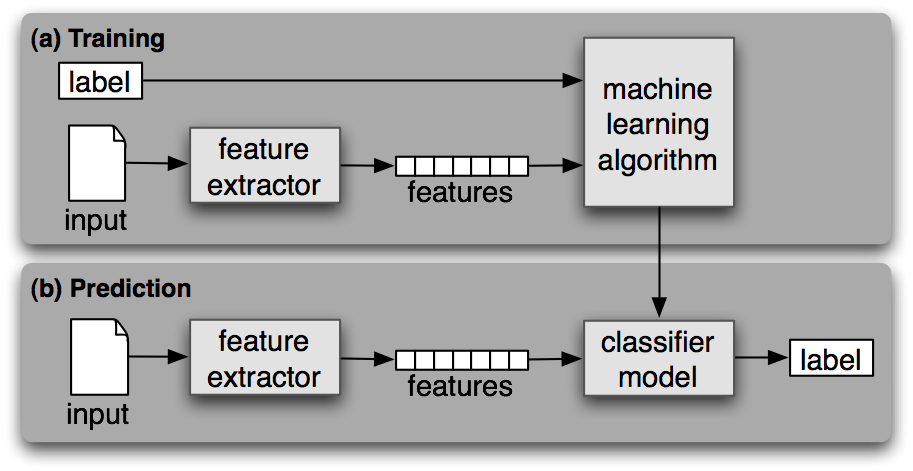
Um algoritmo de aprendizado de máquina supervisionado é treinado no conjunto de dados rotulados de entrada durante a fase de treinamento. Ao final desse processo, obtemos um modelo treinado que pode ser usado para obter previsões (rótulos) em dados novos e não vistos.
Depois que um modelo de aprendizado de máquina é treinado, ele pode ser usado para prever rótulos em dados novos e não vistos. Isso geralmente é feito implantando o melhor modelo de uma fase anterior como uma API no servidor.
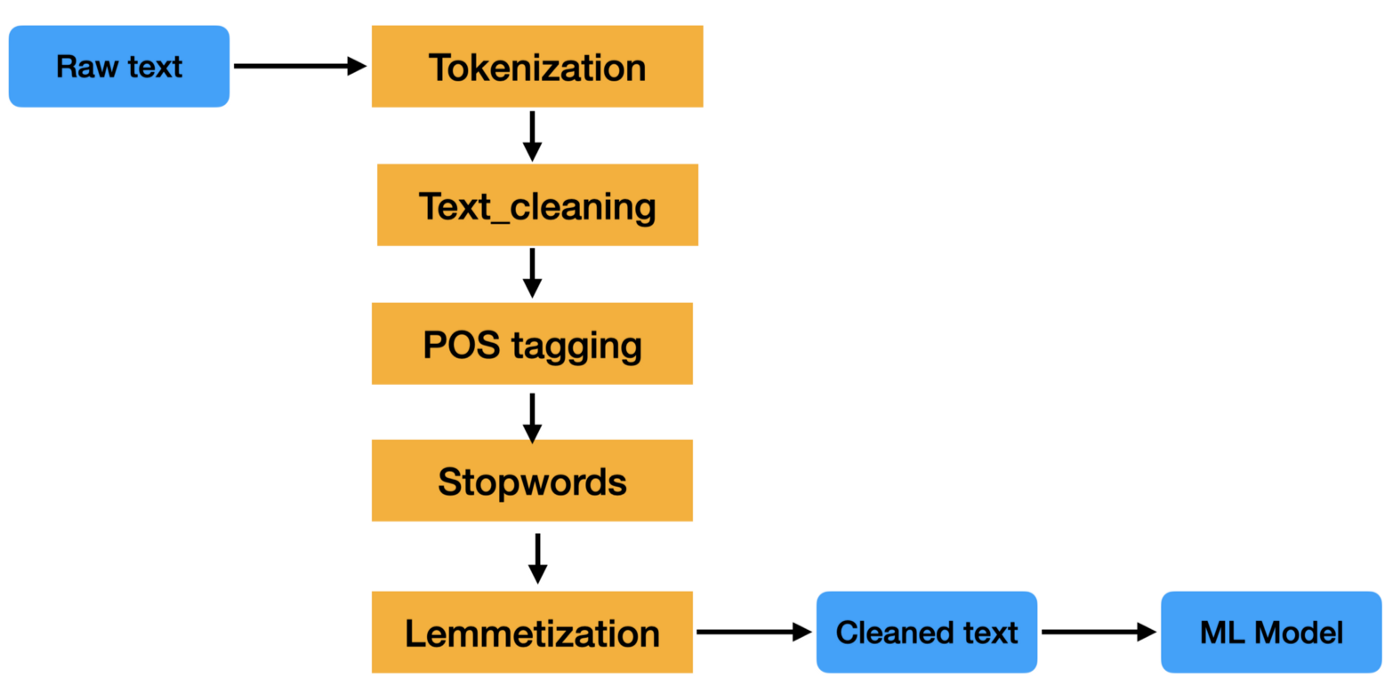
O pré-processamento de dados de texto é uma etapa importante em qualquer tarefa de processamento de linguagem natural. Ele ajuda a limpar e preparar os dados de texto para processamento ou análise posterior.
Um pipeline de pré-processamento de texto é uma série de etapas de processamento aplicadas a dados de texto bruto para prepará-los para uso em tarefas de processamento de linguagem natural.
As etapas em um pipeline de pré-processamento de texto podem variar, mas normalmente incluem tarefas como tokenização, remoção de palavras de parada, stemming e lematização. Essas etapas ajudam a reduzir o tamanho dos dados de texto e também melhoram a precisão das tarefas de PNL, como classificação de texto e extração de informações.
Os dados de texto são difíceis de processar porque não são estruturados e geralmente contêm muito ruído. Esse ruído pode estar na forma de erros de ortografia, erros gramaticais e formatação fora do padrão. Um pipeline de pré-processamento de texto tem o objetivo de limpar esse ruído para que os dados de texto possam ser analisados com mais facilidade.
Quer saber mais sobre isso? Confira nossa trilha Text Mining with R.
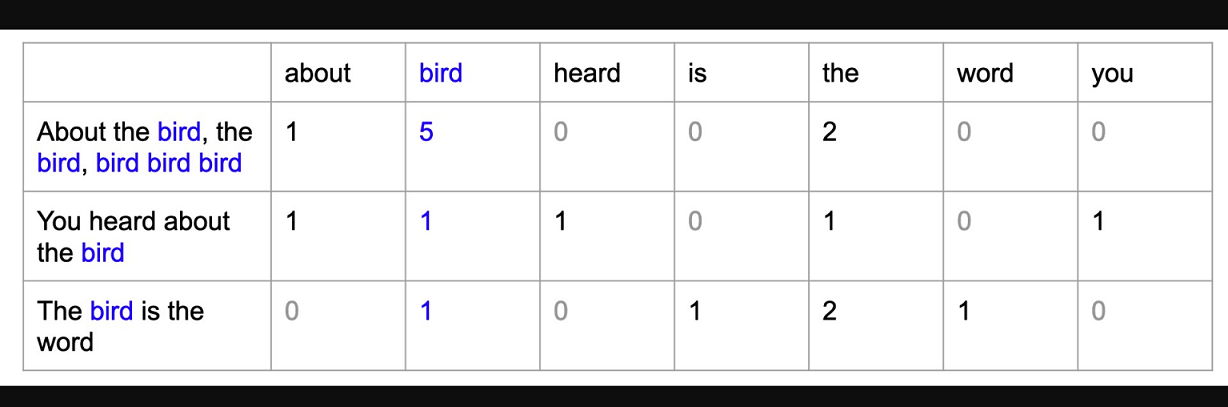
Os dois métodos mais comuns para extrair recursos do texto ou, em outras palavras, converter dados de texto (strings) em recursos numéricos para que o modelo de aprendizado de máquina possa ser treinado são: Bag of Words (também conhecido como CountVectorizer) e Tf-IDF.
Um modelo de saco de palavras (BoW) é uma maneira simples de representar dados de texto como recursos numéricos. Isso envolve a criação de um vocabulário de palavras conhecidas no corpus e, em seguida, a criação de um vetor para cada documento que contém contagens da frequência com que cada palavra aparece.
TF-IDF significa term frequency-inverse document frequency (frequência de termo - frequência inversa de documento) e é outra forma de representar o texto como recursos numéricos. Há algumas deficiências no modelo Bag of Words (BoW) que o Tf-IDF supera. Não entraremos em detalhes sobre isso neste artigo, mas se você quiser explorar mais esse conceito, confira nosso curso Introduction to Natural Language Processing in Python.
O modelo TF-IDF é diferente do modelo de saco de palavras, pois leva em conta a frequência das palavras no documento, bem como a frequência inversa do documento. Isso significa que o modelo TF-IDF tem mais probabilidade de identificar as palavras importantes em um documento do que o modelo de saco de palavras.
Primeiro, comece importando o conjunto de dados diretamente deste link do GitHub. A SMS Spam Collection é um conjunto de dados que contém 5.574 mensagens SMS em inglês, juntamente com o rótulo Spam ou Ham (não é spam). Nosso objetivo é treinar um modelo de aprendizado de máquina que aprenderá com o texto do SMS e o rótulo e será capaz de prever a classe das mensagens SMS.
# reading data
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv', encoding='latin-1')
data.head()
Depois de ler o conjunto de dados, observe que há algumas colunas extras de que não precisamos. Precisamos apenas das duas primeiras colunas. Vamos prosseguir e eliminar as colunas restantes e também renomear as duas primeiras colunas.
# drop unnecessary columns and rename cols
data.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)
data.columns = ['label', 'text']
data.head()
Vamos fazer uma EDA básica para verificar se há valores faltantes no conjunto de dados e qual é o equilíbrio desejado.
# check missing values
data.isna().sum()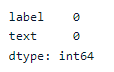
# check data shape
data.shape>>> (5572, 2)# check target balance
data['label'].value_counts(normalize = True).plot.bar()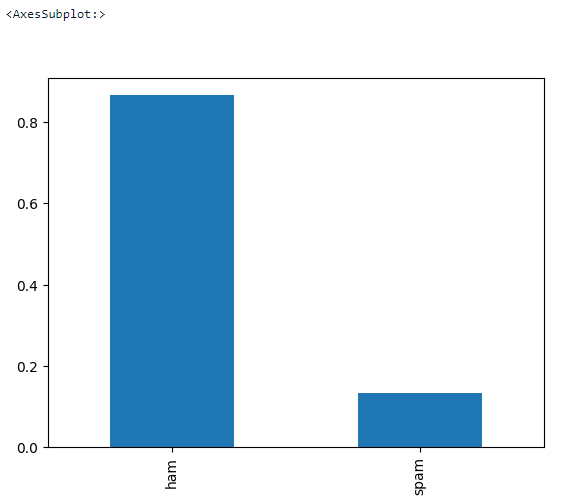
É aqui que ocorre toda a limpeza do texto. É um loop que itera por todos os 5.572 documentos e faz o seguinte:
# text preprocessing
# download nltk
import nltk
nltk.download('all')
# create a list text
text = list(data['text'])
# preprocessing loop
import re
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
corpus = []
for i in range(len(text)):
r = re.sub('[^a-zA-Z]', ' ', text[i])
r = r.lower()
r = r.split()
r = [word for word in r if word not in stopwords.words('english')]
r = [lemmatizer.lemmatize(word) for word in r]
r = ' '.join(r)
corpus.append(r)
#assign corpus to data['text']
data['text'] = corpus
data.head()
Vamos dividir o conjunto de dados em treinamento e teste antes da extração de recursos.
# Create Feature and Label sets
X = data['text']
y = data['label']
# train test split (66% train - 33% test)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=123)
print('Training Data :', X_train.shape)
print('Testing Data : ', X_test.shape)>>> Training Data : (3733,)
>>> Testing Data : (1839,)Aqui, usamos o modelo Bag of Words (CountVectorizer) para converter o texto limpo em recursos numéricos. Isso é necessário para treinar o modelo de aprendizado de máquina.
# Train Bag of Words model
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X_train_cv = cv.fit_transform(X_train)
X_train_cv.shape>>> (3733, 7020)Nesta parte, estamos treinando um modelo de regressão logística e avaliando a matriz de confusão do modelo treinado.
# Training Logistic Regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train_cv, y_train)
# transform X_test using CV
X_test_cv = cv.transform(X_test)
# generate predictions
predictions = lr.predict(X_test_cv)
predictions>>> array(['ham', 'spam', 'ham', ..., 'ham', 'ham', 'spam'], dtype=object)# confusion matrix
import pandas as pd
from sklearn import metrics
df = pd.DataFrame(metrics.confusion_matrix(y_test,predictions), index=['ham','spam'], columns=['ham','spam'])
df
Confira o Workspace completo para obter mais detalhes.
A PNL ainda é uma área ativa de pesquisa e desenvolvimento, com muitas universidades e empresas trabalhando no desenvolvimento de novos algoritmos e aplicativos. A PNL é um campo interdisciplinar, com pesquisadores de diversas origens, incluindo ciência da computação, linguística, psicologia e ciência cognitiva.
A classificação de texto é uma tarefa avançada e amplamente utilizada em PLN que pode ser usada para categorizar ou prever automaticamente uma classe de documentos de texto não vistos, geralmente com a ajuda do aprendizado de máquina supervisionado.
Ele nem sempre é preciso, mas, quando usado corretamente, pode agregar muito valor à sua análise. Há muitas maneiras e algoritmos diferentes de configurar um classificador de texto, e nenhuma abordagem única é a melhor. É importante fazer experiências e descobrir o que funciona melhor para seus dados e seus objetivos.
Principais cursos
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Avinash Navlani
Tutorial
Sejal Jaiswal
