Curso
Fundamentos do PySpark
4 h
157.5K
O Apache Spark é um sistema de processamento distribuído usado para executar tarefas de big data e aprendizado de máquina em grandes conjuntos de dados.
Como entusiasta da ciência de dados, você provavelmente está familiarizado com o armazenamento de arquivos em seu dispositivo local e o processamento usando linguagens como R e Python. No entanto, as estações de trabalho locais têm suas limitações e não conseguem lidar com conjuntos de dados extremamente grandes.
É aí que entra um sistema de processamento distribuído como o Apache Spark. O processamento distribuído é uma configuração na qual vários processadores são usados para executar um aplicativo. Em vez de tentar processar grandes conjuntos de dados em um único computador, a tarefa pode ser dividida entre vários dispositivos que se comunicam entre si.
Com o Apache Spark, os usuários podem executar consultas e fluxos de trabalho de aprendizado de máquina em petabytes de dados, o que é impossível de ser feito no seu dispositivo local.
Essa estrutura é ainda mais rápida do que os mecanismos de processamento de dados anteriores, como o Hadoop, e sua popularidade aumentou nos últimos oito anos. Empresas como IBM, Amazon e Yahoo estão usando o Apache Spark como sua estrutura de computação.
A capacidade de analisar dados e treinar modelos de aprendizado de máquina em conjuntos de dados de grande escala é uma habilidade valiosa se você quiser se tornar um cientista de dados. Ter o conhecimento necessário para trabalhar com estruturas de Big Data, como o Apache Spark, fará com que você se diferencie de outros profissionais da área.
Pratique o uso do Pyspark com exercícios práticos em nosso curso Introdução ao PySpark.
O PySpark é uma interface para o Apache Spark em Python. Com o PySpark, você pode escrever comandos do tipo Python e SQL para manipular e analisar dados em um ambiente de processamento distribuído. Para aprender os conceitos básicos da linguagem, você pode fazer o curso Introduction to PySpark da Datacamp. Este é um programa para iniciantes que levará você a manipular dados, criar pipelines de aprendizado de máquina e ajustar modelos com o PySpark.
A maioria dos cientistas e analistas de dados está familiarizada com o Python e o utiliza para implementar fluxos de trabalho de aprendizado de máquina. O PySpark permite que eles trabalhem com uma linguagem familiar em conjuntos de dados distribuídos em grande escala.
O Apache Spark também pode ser usado com outras linguagens de programação de ciência de dados, como o R. Se você tiver interesse em aprender isso, o curso Introduction to Spark with sparklyr in R é um ótimo ponto de partida.
As empresas que coletam terabytes de dados terão uma estrutura de Big Data, como o Apache Spark, instalada. Para trabalhar com esses conjuntos de dados em grande escala, apenas o conhecimento das estruturas Python e R não será suficiente.
Você precisa aprender uma estrutura que lhe permita manipular conjuntos de dados sobre um sistema de processamento distribuído, pois a maioria das organizações orientadas por dados exigirá que você faça isso. O PySpark é um ótimo lugar para começar, pois sua sintaxe é simples e pode ser aprendida facilmente se você já estiver familiarizado com Python.
O motivo pelo qual as empresas optam por usar uma estrutura como o PySpark é a rapidez com que ela pode processar big data. Ele é mais rápido do que bibliotecas como Pandas e Dask, e pode lidar com quantidades maiores de dados do que essas estruturas. Se você tivesse mais de petabytes de dados para processar, por exemplo, o Pandas e o Dask falhariam, mas o PySpark seria capaz de lidar com isso facilmente.
Embora também seja possível escrever código Python em um sistema distribuído como o Hadoop, muitas organizações optam por usar o Spark e a API do PySpark, pois ele é mais rápido e pode lidar com dados em tempo real. Com o PySpark, você pode escrever código para coletar dados de uma fonte que é continuamente atualizada, enquanto os dados só podem ser processados em modo de lote com o Hadoop.
O Apache Flink é um sistema de processamento distribuído que tem uma API Python chamada PyFlink e é, na verdade, mais rápido do que o Spark em termos de desempenho. No entanto, o Apache Spark existe há mais tempo e tem melhor suporte da comunidade, o que significa que é mais confiável.
Além disso, o PySpark oferece tolerância a falhas, o que significa que ele tem a capacidade de recuperar perdas após a ocorrência de uma falha. A estrutura também tem computação na memória e é armazenada na memória de acesso aleatório (RAM). Ele pode ser executado em uma máquina que não tenha um disco rígido ou SSD instalado.
Pré-requisitos:
Antes de instalar o Apache Spark e o PySpark, você precisa ter os seguintes softwares configurados no seu dispositivo:
Se você ainda não tiver o Python instalado, siga nosso guia de configuração do desenvolvedor Python para configurá-lo antes de prosseguir para a próxima etapa.
Em seguida, siga este tutorial para instalar o Java no seu computador se você estiver usando o Windows. Aqui você encontra um guia de instalação para MacOs e aqui está um para Linux.
Um Jupyter Notebook é um aplicativo da Web que você pode usar para escrever código e exibir equações, visualizações e texto. É um dos editores de programação mais usados pelos cientistas de dados. Usaremos um Jupyter Notebook para escrever todo o código do PySpark neste tutorial, portanto, certifique-se de que você o tenha instalado.
Você pode seguir nosso tutorial para colocar o Jupyter em funcionamento no seu dispositivo local.
Usaremos o conjunto de dados de comércio eletrônico do Datacamp para todas as análises deste tutorial, portanto, certifique-se de que você tenha feito o download dele. Renomeamos o arquivo para "datacamp_ecommerce.csv" e o salvamos no diretório principal, e você pode fazer o mesmo para facilitar a codificação.
Agora que você tem todos os pré-requisitos configurados, pode prosseguir com a instalação do Apache Spark e do PySpark.
Para configurar o Apache Spark, navegue até apágina de download e faça o download do arquivo .tgz exibido na página:
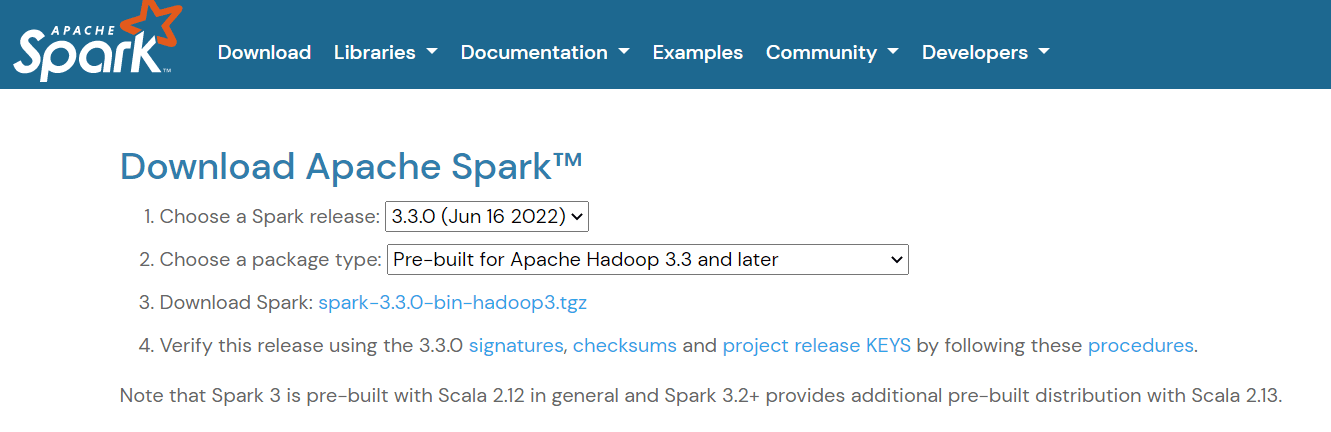
Em seguida, se você estiver usando o Windows, crie uma pasta no diretório C chamada "spark". Se você usa Linux ou Mac, pode colar isso em uma nova pasta no seu diretório pessoal.
Em seguida, extraia o arquivo que você acabou de baixar e cole seu conteúdo nessa pasta "spark". É assim que o caminho da pasta deve se parecer:

Agora, você precisa definir suas variáveis de ambiente. Há duas maneiras de você fazer isso:
Método 1: Alteração de variáveis de ambiente usando o Powershell
Se você estiver usando uma máquina Windows, a primeira maneira de alterar as variáveis de ambiente é usar o Powershell:
Etapa 1: Clique em Iniciar -> Windows Powershell -> Executar como administrador
Etapa 2: Digite a seguinte linha no Windows Powershell para definir o SPARK_HOME:
setx SPARK_HOME "C:\spark\spark-3.3.0-bin-hadoop3" # change this to your pathEtapa 3: Em seguida, defina o diretório bin do Spark como uma variável de caminho:
setx PATH "C:\spark\spark-3.3.0-bin-hadoop3\bin"Método 2: Alterando manualmente as variáveis de ambiente
Etapa 1: Navegue até Iniciar -> Sistema -> Configurações -> Configurações avançadas
Etapa 2: Clique em Environment Variables (Variáveis de ambiente)
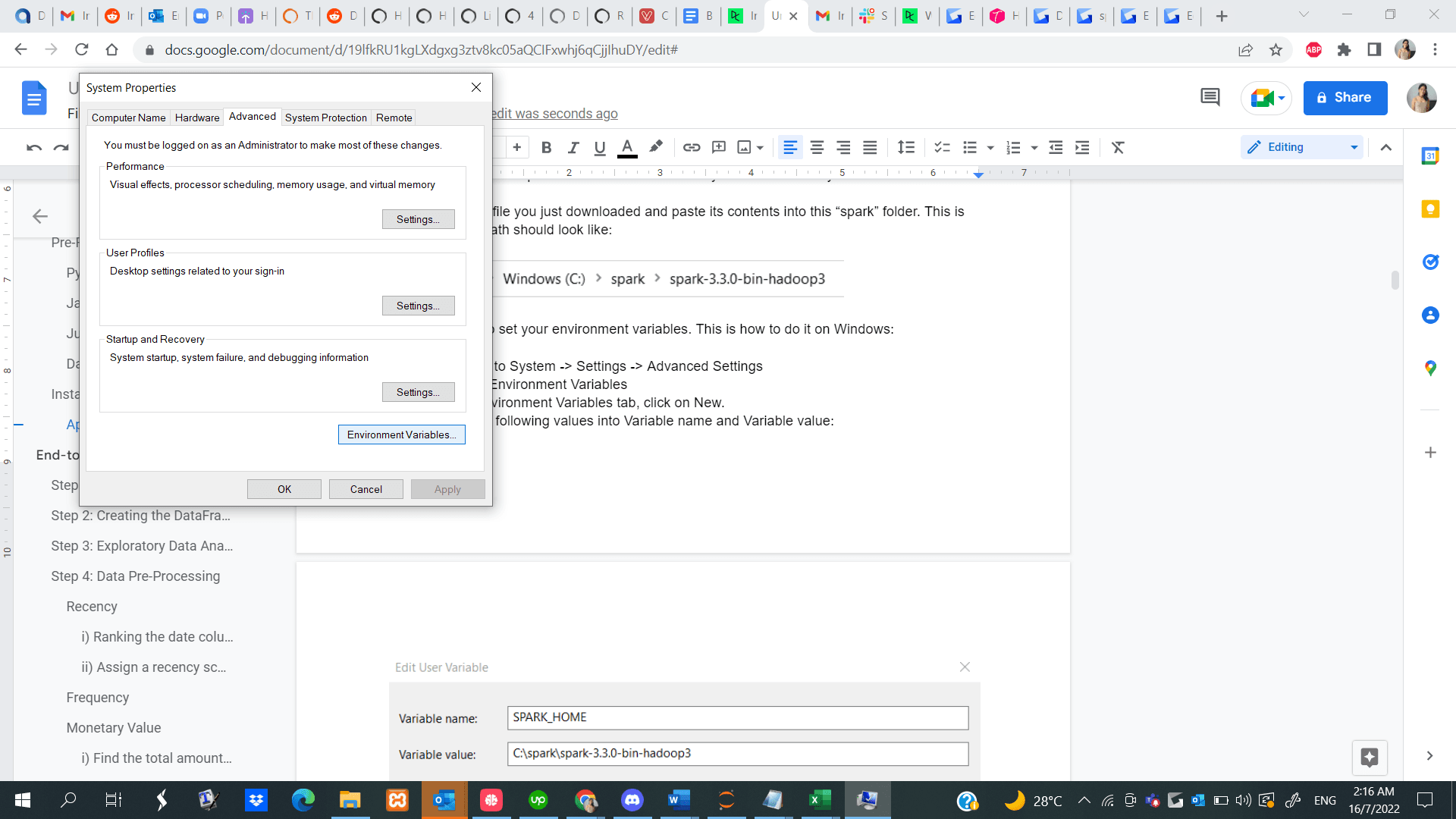
Etapa 3: Na guia Environment Variables (Variáveis de ambiente), clique em New (Novo).
Etapa 4: Digite os seguintes valores em Nome da variável e Valor da variável. Observe que a versão que você instala pode ser diferente da mostrada abaixo, portanto, copie e cole o caminho para o diretório do Spark.
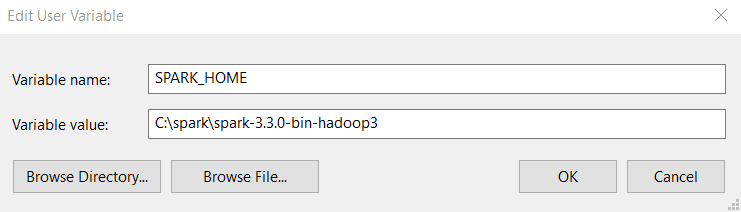
Etapa 5: Em seguida, na guia Environment Variables (Variáveis de ambiente), clique em Path (Caminho) e selecione Edit (Editar).
Etapa 6: Clique em New (Novo) e cole o caminho para o diretório bin do Spark. Aqui está um exemplo de como é o diretório bin:
C:\spark\spark-3.3.0-bin-hadoop3\binAqui está um guia sobre como configurar as variáveis de ambiente se você usar um dispositivo Linux e aqui está um guia para o MacOS.
Agora que você instalou com sucesso o Apache Spark e todos os outros pré-requisitos necessários, abra um arquivo Python no seu Jupyter Notebook e execute as seguintes linhas de código na primeira célula:
!pip install pysparkComo alternativa, você pode seguir este guia de instalação completo do PySpark para instalar o software no seu dispositivo.
Agora que você já tem o PySpark instalado e funcionando, mostraremos como executar um projeto de segmentação de clientes de ponta a ponta usando a biblioteca.
A segmentação de clientes é uma técnica de marketing que as empresas usam para identificar e agrupar usuários que apresentam características semelhantes. Por exemplo, se você visita a Starbucks somente durante o verão para comprar bebidas geladas, pode ser segmentado como um "comprador sazonal" e atraído com promoções especiais criadas para a temporada de verão.
Os cientistas de dados geralmente criam algoritmos de aprendizado de máquina não supervisionados, como o agrupamento K-Means ou o agrupamento hierárquico, para realizar a segmentação de clientes. Esses modelos são ótimos para identificar padrões semelhantes entre grupos de usuários que muitas vezes passam despercebidos pelo olho humano.
Neste tutorial, usaremos o agrupamento K-Means para realizar a segmentação de clientes no conjunto de dados de comércio eletrônico que baixamos anteriormente.
Ao final deste tutorial, você estará familiarizado com os seguintes conceitos:
Uma SparkSession é um ponto de entrada para todas as funcionalidades do Spark e é necessária se você quiser criar um dataframe no PySpark. Execute as seguintes linhas de código para inicializar uma SparkSession:
spark = SparkSession.builder.appName("Datacamp Pyspark Tutorial").config("spark.memory.offHeap.enabled","true").config("spark.memory.offHeap.size","10g").getOrCreate()Usando os códigos acima, criamos uma sessão do Spark e definimos um nome para o aplicativo. Em seguida, os dados foram armazenados em cache na memória fora do heap para evitar armazená-los diretamente no disco, e a quantidade de memória foi especificada manualmente.
Agora podemos ler o conjunto de dados que acabamos de baixar:
df = spark.read.csv('datacamp_ecommerce.csv',header=True,escape="\"")Observe que definimos um caractere de escape para evitar vírgulas no arquivo .csv durante a análise.
Vamos dar uma olhada no cabeçalho do dataframe usando a função show():
df.show(5,0)
O dataframe consiste em 8 variáveis:
Agora que você já viu as variáveis presentes nesse conjunto de dados, vamos realizar algumas análises exploratórias de dados para entender melhor esses pontos de dados:
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95Para encontrar o país no qual a maioria das compras é feita, precisamos usar a cláusula groupBy() no PySpark:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()A tabela a seguir será renderizada depois que você executar os códigos acima:

Quase todas as compras na plataforma foram feitas no Reino Unido, e apenas algumas foram feitas em países como Alemanha, Austrália e França.
Observe que os dados da tabela acima não são apresentados na ordem das compras. Para classificar essa tabela, podemos incluir a cláusula orderBy():
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()A saída exibida agora está classificada em ordem decrescente:

Para descobrir quando a última compra foi feita na plataforma, precisamos converter a coluna "InvoiceDate" em um formato de carimbo de data/hora e usar a função max() no Pyspark:
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
df = df.withColumn('date',to_timestamp("InvoiceDate", 'yy/MM/dd HH:mm'))
df.select(max("date")).show()Você deverá ver a tabela a seguir após executar o código acima:
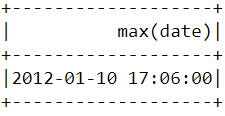
De forma semelhante ao que fizemos acima, a função min() pode ser usada para encontrar a data e a hora da primeira compra:
df.select(min("date")).show()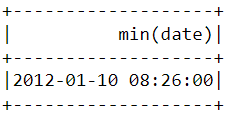
Observe que a compra mais recente e a mais antiga foram feitas no mesmo dia, com apenas algumas horas de diferença. Isso significa que o conjunto de dados que baixamos contém informações apenas das compras feitas em um único dia.
Agora que analisamos o conjunto de dados e temos uma melhor compreensão de cada ponto de dados, precisamos preparar os dados para alimentar o algoritmo de aprendizado de máquina.
Vamos dar uma olhada no cabeçalho do dataframe mais uma vez para entender como o pré-processamento será feito:
df.show(5,0)
A partir do conjunto de dados acima, precisamos criar vários segmentos de clientes com base no comportamento de compra de cada usuário.
As variáveis desse conjunto de dados estão em um formato que não pode ser facilmente inserido no modelo de segmentação de clientes. Esses recursos, individualmente, não nos dizem muito sobre o comportamento de compra do cliente.
Por isso, usaremos as variáveis existentes para derivar três novos recursos informativos: recência, frequência e valor monetário (RFM).
O RFM é comumente usado no marketing para avaliar o valor de um cliente com base em seu desempenho:
Agora, vamos pré-processar o dataframe para criar as variáveis acima.
Primeiro, vamos calcular o valor de recência - a última data e hora em que uma compra foi feita na plataforma. Isso pode ser feito em duas etapas:
Subtrairemos todas as datas do dataframe da data mais antiga. Isso nos informará quão recentemente um cliente foi visto no dataframe. Um valor de 0 indica a menor recência, pois será atribuído à pessoa que foi vista fazendo uma compra na data mais antiga.
df = df.withColumn("from_date", lit("12/1/10 08:26"))
df = df.withColumn('from_date',to_timestamp("from_date", 'yy/MM/dd HH:mm'))
df2=df.withColumn('from_date',to_timestamp(col('from_date'))).withColumn('recency',col("date").cast("long") - col('from_date').cast("long"))Um cliente pode fazer várias compras em momentos diferentes. Precisamos selecionar apenas a última vez que eles foram vistos comprando um produto, pois isso indica quando a compra mais recente foi feita:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Vamos dar uma olhada no cabeçalho do novo dataframe. Agora você tem uma variável chamada "recency" anexada a ela:
df2.show(5,0)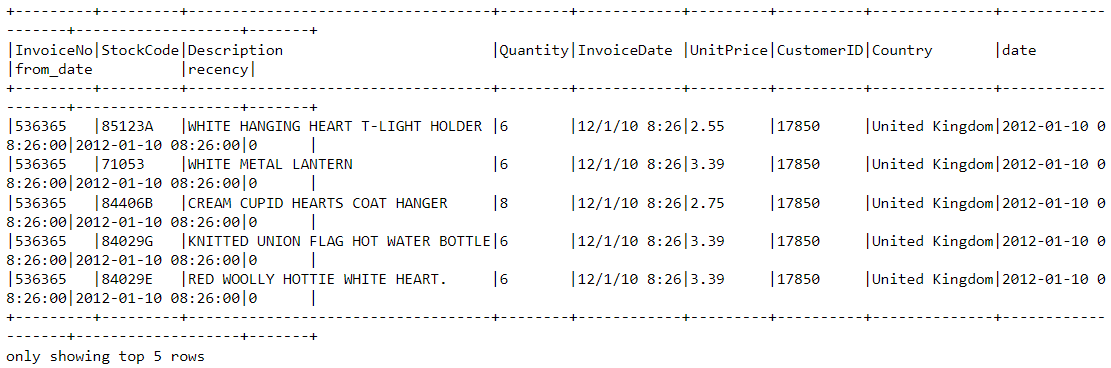
Uma maneira mais fácil de visualizar todas as variáveis presentes em um dataframe do PySpark é usar a função printSchema(). Esse é o equivalente à função info() no Pandas:
df2.printSchema()A saída renderizada deve ter a seguinte aparência:

Vamos agora calcular o valor da frequência - a frequência com que um cliente comprou algo na plataforma. Para fazer isso, basta agrupar por cada ID de cliente e contar o número de itens que eles compraram:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Observe o cabeçalho desse novo dataframe que acabamos de criar:
df_freq.show(5,0)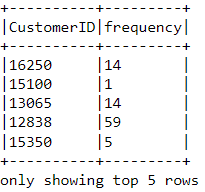
Há um valor de frequência anexado a cada cliente no quadro de dados. Esse novo dataframe tem apenas duas colunas, e precisamos uni-lo ao anterior:
df3 = df2.join(df_freq,on='CustomerID',how='inner')Vamos imprimir o esquema desse dataframe:
df3.printSchema()
Por fim, vamos calcular o valor monetário - o valor total gasto por cada cliente no dataframe. Há duas etapas para você conseguir isso:
Cada ID de cliente vem com variáveis chamadas "Quantity" (Quantidade) e "UnitPrice" (Preço unitário) para uma única compra:

Para obter o valor total gasto por cada cliente em uma compra, precisamos multiplicar "Quantity" (Quantidade) por "UnitPrice" (Preço unitário):
m_val = df3.withColumn('TotalAmount',col("Quantity") * col("UnitPrice"))Para encontrar o valor total gasto por cada cliente em geral, basta agrupar pela coluna CustomerID e somar o valor total gasto:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Mesclar esse dataframe com todas as outras variáveis:
finaldf = m_val.join(df3,on='CustomerID',how='inner')Agora que criamos todas as variáveis necessárias para construir o modelo, execute as seguintes linhas de código para selecionar somente as colunas necessárias e eliminar as linhas duplicadas do dataframe:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Observe o cabeçalho do dataframe final para garantir que o pré-processamento tenha sido feito com precisão:

Antes de criar o modelo de segmentação de clientes, vamos padronizar o quadro de dados para garantir que todas as variáveis estejam na mesma escala:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StandardScaler
assemble=VectorAssembler(inputCols=[
'recency','frequency','monetary_value'
], outputCol='features')
assembled_data=assemble.transform(finaldf)
scale=StandardScaler(inputCol='features',outputCol='standardized')
data_scale=scale.fit(assembled_data)
data_scale_output=data_scale.transform(assembled_data)Execute as seguintes linhas de código para ver como é o vetor de recursos padronizado:
data_scale_output.select('standardized').show(2,truncate=False)
Esses são os recursos em escala que serão inseridos no algoritmo de agrupamento.
Se você quiser saber mais sobre a preparação de dados com o PySpark, faça este curso de engenharia de recursos no Datacamp.
Agora que concluímos toda a análise e preparação dos dados, vamos criar o modelo de agrupamento K-Means.
O algoritmo será criado usando a API de aprendizado de máquina do PySpark.
Ao criar um modelo de clustering K-Means, primeiro precisamos determinar o número de clusters ou grupos que queremos que o algoritmo retorne. Se decidirmos por três clusters, por exemplo, teremos três segmentos de clientes.
A técnica mais popular usada para decidir quantos clusters usar no K-Means é chamada de "método do cotovelo".
Para isso, basta executar o algoritmo K-Means para uma ampla gama de clusters e visualizar os resultados do modelo para cada cluster. O gráfico terá um ponto de inflexão que se assemelha a um cotovelo, e nós apenas escolhemos o número de clusters nesse ponto.
Leia este tutorial de clustering K-Means da Datacamp para saber mais sobre como o algoritmo funciona.
Vamos executar as seguintes linhas de código para criar um algoritmo de agrupamento K-Means de 2 a 10 clusters:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized',metricName='silhouette', distanceMeasure='squaredEuclidean')
for i in range(2,10):
KMeans_algo=KMeans(featuresCol='standardized', k=i)
KMeans_fit=KMeans_algo.fit(data_scale_output)
output=KMeans_fit.transform(data_scale_output)
cost[i] = KMeans_fit.summary.trainingCostCom os códigos acima, criamos e avaliamos com sucesso um modelo de agrupamento K-Means com 2 a 10 agrupamentos. Os resultados foram colocados em uma matriz e agora podem ser visualizados em um gráfico de linhas:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns = ["cost"]
new_col = range(2,10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()Os códigos acima renderizarão o gráfico a seguir:
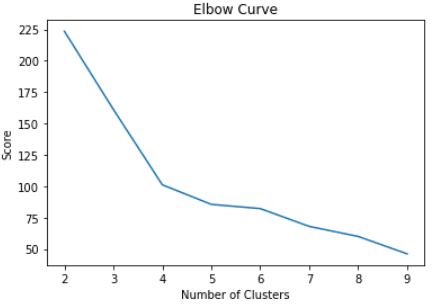
No gráfico acima, podemos ver que há um ponto de inflexão que se parece com um cotovelo em quatro. Por esse motivo, continuaremos a criar o algoritmo K-Means com quatro clusters:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Vamos usar o modelo que criamos para atribuir clusters a cada cliente no conjunto de dados:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Observe que há uma coluna "prediction" (previsão) nesse dataframe que nos informa a qual cluster cada CustomerID pertence:

A etapa final deste tutorial é analisar os segmentos de clientes que acabamos de criar.
Execute as seguintes linhas de código para visualizar a recência, a frequência e o valor monetário de cada customerID no dataframe:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 = ['recency','frequency','monetary_value']
for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()Os códigos acima renderizarão os seguintes gráficos:
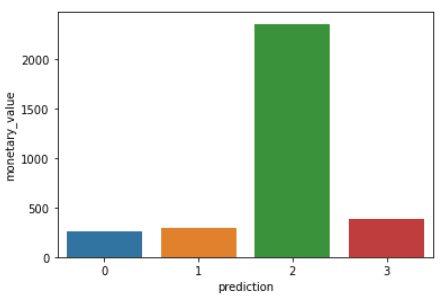
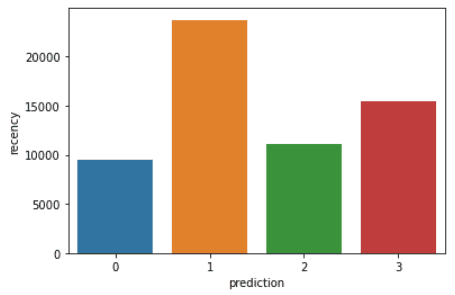
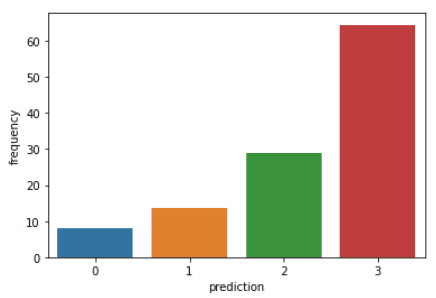
Aqui está uma visão geral das características exibidas pelos clientes em cada cluster:
Para ir além dos conceitos de modelagem preditiva abordados neste curso, você pode fazer o curso Machine Learning with PySpark na Datacamp.
Se você conseguiu acompanhar todo este tutorial do PySpark, parabéns! Agora você instalou com sucesso o PySpark no seu dispositivo local, analisou um conjunto de dados de comércio eletrônico e criou um algoritmo de aprendizado de máquina usando a estrutura.
Uma ressalva da análise acima é que ela foi realizada com 2.500 linhas de dados de comércio eletrônico coletados em um único dia. O resultado dessa análise pode ser solidificado se você tiver uma quantidade maior de dados para trabalhar, pois técnicas como a modelagem de RFM geralmente são aplicadas a meses de dados históricos.
No entanto, você pode usar os princípios aprendidos neste artigo e aplicá-los a uma ampla variedade de conjuntos de dados maiores no espaço de aprendizado de máquina não supervisionado.
Confira esta folha de dicas da Datacamp para saber mais sobre a sintaxe do PySpark e seus módulos.
Por fim, se quiser ir além dos conceitos abordados neste tutorial e aprender os fundamentos da programação com o PySpark, você pode fazer a trilha de aprendizado Big Data com PySpark no Datacamp. Essa faixa contém uma série de cursos que ensinarão você a fazer o seguinte com o PySpark:
Cursos para visualização de dados
Curso
Curso
Curso
Tutorial
Vidhi Chugh
Tutorial
Joleen Bothma
Tutorial
Kurtis Pykes
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
