
Curso
Trabalhar com a API da OpenAI
3 h
141.6K
O GPT-5 chegou e tá mudando a forma como usamos as ferramentas de IA. É ótimo pra codificar, chamar ferramentas, seguir instruções e automatizar. Na verdade, é tão bom que alguns estão ficando preocupados: O GPT-5 pode facilmente substituir um desenvolvedor júnior e de nível médio.
Se você quiser saber mais sobre o que o GPT-5 pode fazer, dá uma olhada em GPT-5: Novos recursos, testes, benchmarks e muito mais | DataCamp. Você também pode conferir 7 exemplos do GPT-5 que você pode experimentar no chat.
Neste tutorial, não vamos nos concentrar nas habilidades gerais do modelo. Em vez disso, vamos explorar e testar osnovos recursos da API GPT-5 introduzidos com o novo modelo. Vamos ver cada recurso e rodar um código de exemplo pra você ver como eles funcionam.
Tem algumas coisas especiais aqui que nenhum outro provedor de API oferece no momento. Com o SDK OpenAI, agora você pode criar um aplicativo baseado em agente totalmente funcional sem precisar integrar nenhuma estrutura externa. Funciona logo de cara.

Imagem do autor
O GPT-5 traz um novo parâmetro de esforço de raciocínio que te deixa controlar o quanto o modelo pensa antes de responder. Você pode escolher entre os níveis de esforço mínimo, baixo, médio ou alto d, dependendo das suas necessidades.
O esforço mínimo é ideal para tarefas que exigem rapidez, como codificação rápida ou seguir instruções simples, enquanto o médio e o alto permitem um raciocínio mais detalhado, passo a passo. Essa flexibilidade permite equilibrar latência, custo e precisão.
Primeiro, instale o SDK Python da OpenAI e defina sua chave API como uma variável de ambiente:
pip install openaiDefina sua chave API (substitua pela sua chave real):
export OPENAI_API_KEY="your_api_key_here"setx OPENAI_API_KEY "your_api_key_here"Vamos usar a API de resposta para criar um texto com o mínimo de esforço de raciocínio. Isso quer dizer que o modelo vai responder direto, sem precisar usar tokens pra raciocínio interno.
import os
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
)
print(resp.output_text)Saída:
Guido van Rossum is known as the father (creator) of Python. He first released Python in 1991.Você também pode conferir o resumo de uso do token pra entender como o modelo processou sua solicitação:
print(f"Input tokens: {resp.usage.input_tokens}")
print(f" - Cached tokens: {resp.usage.input_tokens_details.cached_tokens}")
print(f"Output tokens: {resp.usage.output_tokens}")
print(f" - Reasoning tokens: {resp.usage.output_tokens_details.reasoning_tokens}")
print(f"Total tokens: {resp.usage.total_tokens}")Como mostrado, nenhum token foi usado para raciocínio quando o esforço foi definido como mínimo.
Input tokens: 13
- Cached tokens: 0
Output tokens: 31
- Reasoning tokens: 0
Total tokens: 44Agora, vamos aumentar o esforço de raciocínio para “alto” pra ver como o raciocínio interno do modelo muda:
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "high"},
)
print(resp.output_text)Saída:
Guido van Rossum. He created Python and first released it in 1991.Dá uma olhada no uso do token de novo:
print(f"Input tokens: {resp.usage.input_tokens}")
print(f" - Cached tokens: {resp.usage.input_tokens_details.cached_tokens}")
print(f"Output tokens: {resp.usage.output_tokens}")
print(f" - Reasoning tokens: {resp.usage.output_tokens_details.reasoning_tokens}")
print(f"Total tokens: {resp.usage.total_tokens}")Mesmo pra uma pergunta simples, o modelo usou 192 tokens pra raciocinar com um esforço alto. Isso mostra como agora você pode controlar a profundidade do raciocínio para otimizar o custo, a velocidade ou a precisão, conforme necessário.
Input tokens: 13
- Cached tokens: 0
Output tokens: 216
- Reasoning tokens: 192
Total tokens: 229Com o GPT-5, agora você pode controlar diretamente o quanto o modelo fala usando o parâmetro de verbosidade. Defina como“ ” (baixo) para respostas curtas, “medium” (médio ) para detalhes equilibrados ou “high” (alto ) para explicações detalhadas. Isso é super útil pra gerar código — pouca verbosidade deixa o código curto e limpo, enquanto muita verbosidade inclui comentários embutidos e explicações detalhadas.
Você pode juntar o parâmetro de verbosidade com os controlesde raciocínio para personalizar as respostas exatamente como você precisa. Quer você queira uma frase curta, uma resposta mais longa ou um relatório completo, você tem total flexibilidade.
A verbosidade “baixa” dá uma resposta curta e direta.
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "low"},
)
print(resp.output_text)Saída:
Guido van Rossum.A verbosidade “alta” gera uma resposta bem mais detalhada e explicativa.
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "high"},
)
print(resp.output_text)Saída:
Guido van Rossum is known as the "father of Python." He created Python in the late 1980s and released the first version (Python 0.9.0) in 1991. He also served for many years as Python's "Benevolent Dictator For Life" (BDFL), guiding the language's development.Uma das maiores melhorias do GPT-5 é a capacidade de passar o raciocínio da cadeia de pensamentos (CoT) entre as respostas na API Responses. Isso quer dizer que o modelo lembra o raciocínio interno das etapas anteriores, evitando repensar coisas que já foram feitas e melhorando a velocidade e a precisão.
Em conversas com várias voltas, principalmente quando você usa ferramentas, basta passar o previous_response_id para manter o contexto do raciocínio vivo.
A primeira solicitação pergunta: “Quem é o pai de Python?”, e a segunda solicitação, ligada à primeira por meio de previous_response_id, pede ao modelo para “Escrever um blog sobre isso” sem repetir o assunto. Ao passar o ID da resposta anterior, o modelo mantém o contexto do raciocínio.
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
first = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "low"},
)
followup = client.responses.create(
model="gpt-5",
previous_response_id=first.id,
input="Write a blog on it.",
reasoning={"effort": "medium"},
text={"verbosity": "high"},
)
print(followup.output_text)No fim das contas, criamos um blog sobre o pai do Python.

As ferramentas personalizadas no GPT-5 agora aceitam entradas em formato livre, permitindo que o modelo envie texto bruto, como código, consultas SQL ou comandos de shell diretamente para suas ferramentas. Isso é um grande salto em relação à antiga abordagem estruturada apenas em JSON, dando a você mais flexibilidade na forma como o modelo interage com seus sistemas. Se você está criando um executor de código, um mecanismo de consulta ou um interpretador DSL, a entrada em formato livre torna o GPT-5 muito mais adaptável para tarefas não estruturadas do mundo real.
No código abaixo, a gente definiu um executor SQL falso, registrou ele como uma ferramenta personalizada e fez uma solicitação inicial onde o modelo responde com uma consulta SQL de formato livre. Essa consulta é extraída, executada localmente e o resultado é enviado de volta para o modelo usando o mesmo call_id para manter o contexto da chamada da ferramenta. Por fim, o GPT-5 transforma a resposta bruta da ferramenta numa resposta em linguagem natural.
from openai import OpenAI
import random
client = OpenAI()
def run_sql_query(sql: str) -> str:
print("\n[FAKE DB] Executing SQL:\n", sql)
categories = ["Electronics", "Clothing", "Furniture", "Toys", "Books"]
result = "category | total_sales\n" + "-" * 28 + "\n"
for cat in categories:
result += f"{cat:<11} | {random.randint(5000, 200000)}\n"
return result
tools = [
{
"type": "custom",
"name": "sql_query_runner",
"description": "Runs raw SQL queries on the company sales database.",
}
]
messages = [
{
"role": "user",
"content": "Show me the total sales for each product category last month.",
}
]
# 1) First call - model emits a freeform tool call
resp = client.responses.create(model="gpt-5", tools=tools, input=messages)
# IMPORTANT: carry the tool call into the next turn
messages += resp.output # <-- this preserves the tool_call with its call_id
# Find the tool call from the response output
tool_call = next(
(
x
for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "function_call", "tool_call")
),
None,
)
assert tool_call is not None, "No tool call found."
# Freeform text is in `input` (fallback to `arguments` for safety)
raw_text = getattr(tool_call, "input", None) or getattr(tool_call, "arguments", "")
sql_text = raw_text.strip()
# 2) Execute the tool locally
fake_result = run_sql_query(sql_text)
# 3) Send tool result back, referencing the SAME call_id
messages.append(
{
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": fake_result,
}
)
# 4) Final call - model turns tool output into a natural answer
final = client.responses.create(model="gpt-5", tools=tools, input=messages)
print("\nFinal output text:\n", final.output_text)Saída:
[FAKE DB] Executing SQL:
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema','pg_catalog')
ORDER BY 1,2;
Final output text:
Here are the total sales by category for last month (July 2025):
- Electronics: 31,766
- Clothing: 90,266
- Furniture: 55,471
- Toys: 124,625
- Books: 74,263
Want this as a CSV or chart?Para cenários em que a precisão é fundamental, o GPT-5 suporta gramáticas livres de contexto (CFGs) para controlar rigorosamente os formatos de saída. Ao adicionar uma gramática como a sintaxe SQL ou uma linguagem específica do domínio, você pode garantir que as respostas do modelo sempre correspondam à estrutura que você precisa. Isso é super importante prafluxos de trabalho automatizados ou de alto risco, tipo , onde até pequenos erros no formato podem causar problemas.
No código de exemplo, criamos um sql_query_runner e definimos sua sintaxe SQL usando uma gramática Lark, garantindo que qualquer SQL gerado pelo modelo seja sempre válido e siga exatamente nossa estrutura.
Na primeira chamada do modelo, o GPT-5 usa essa ferramenta pra gerar uma consulta SQL que segue as regras gramaticais pra ver as vendas do mês passado por categoria. Depois, a gente executa essa consulta localmente, manda os resultados de volta pro modelo usando o mesmo call_id e faz uma segunda chamada onde o GPT‑5 transforma os dados brutos numa resposta clara e em linguagem natural.
from openai import OpenAI
import random
client = OpenAI()
def run_sql_query(sql: str) -> str:
cats = ["Electronics", "Clothing", "Furniture", "Toys", "Books"]
rows = [f"{c:<11} | {random.randint(5_000, 200_000)}" for c in cats]
return "category | total_sales\n" + "-" * 28 + "\n" + "\n".join(rows)
tools = [
{
"type": "custom",
"name": "sql_query_runner",
"description": "Runs raw SQL on the sales DB.",
"format": {
"type": "grammar",
"syntax": "lark",
"definition": r"""
start: SELECT CATEGORY COMMA SUM LPAREN SALES RPAREN AS TOTAL_SALES FROM ORDERS WHERE ORDER_MONTH EQ ESCAPED_STRING GROUP BY CATEGORY ORDER BY TOTAL_SALES (DESC|ASC)?
SELECT: "SELECT"
CATEGORY: "category"
COMMA: ","
SUM: "SUM"
LPAREN: "("
SALES: "sales"
RPAREN: ")"
AS: "AS"
TOTAL_SALES: "total_sales"
FROM: "FROM"
ORDERS: "orders"
WHERE: "WHERE"
ORDER_MONTH: "order_month"
EQ: "="
GROUP: "GROUP"
BY: "BY"
ORDER: "ORDER"
DESC: "DESC"
ASC: "ASC"
%import common.ESCAPED_STRING
%ignore /[ \t\r\n]+/
""",
},
}
]
msgs = [
{
"role": "user",
"content": "Show me the total sales for each product category last month.",
}
]
print("\n=== 1) First Model Call ===")
resp = client.responses.create(
model="gpt-5", input=msgs, tools=tools, text={"format": {"type": "text"}}
)
print("Raw model output objects:\n", resp.output)
msgs += resp.output
tool_call = next(
x
for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "function_call", "tool_call")
)
sql = (getattr(tool_call, "input", None) or getattr(tool_call, "arguments", "")).strip()
print("\nExtracted SQL from tool call:\n", sql)
print("\n=== 2) Local Tool Execution ===")
tool_result = run_sql_query(sql)
print(tool_result)
msgs.append(
{
"type": "function_call_output",
"call_id": getattr(tool_call, "call_id", None) or tool_call["call_id"],
"output": tool_result,
}
)
print("\n=== 3) Second Model Call ===")
final = client.responses.create(
model="gpt-5", input=msgs, tools=tools, text={"format": {"type": "text"}}
)
print("\nFinal natural-language answer:\n", final.output_text)Como dá pra ver, o modelo primeiro criou uma consulta SQL que segue as regras gramaticais e, depois, executou a função pra pegar os dados de vendas. Por fim, o GPT-5 transformou esses dados em um resumo claro e classificado em linguagem natural das vendas do mês passado por categoria.
=== 1) First Model Call ===
Raw model output objects:
[ResponseReasoningItem(id='rs_6897acee8afc819f9e7ae0f675bfa4ee0d5175a46255063b', summary=[], type='reasoning', content=None, encrypted_content=None, status=None), ResponseCustomToolCall(call_id='call_vzcHPT7EGvb7QbhF2djVIJZA', input='SELECT category, SUM(sales) AS total_sales FROM orders WHERE order_month = "2025-07" GROUP BY category ORDER BY total_sales DESC', name='sql_query_runner', type='custom_tool_call', id='ctc_6897acf67a34819f84a085191e4ca1fb0d5175a46255063b', status='completed')]
Extracted SQL from tool call:
SELECT category, SUM(sales) AS total_sales FROM orders WHERE order_month = "2025-07" GROUP BY category ORDER BY total_sales DESC
=== 2) Local Tool Execution ===
category | total_sales
----------------------------
Electronics | 52423
Clothing | 59976
Furniture | 172713
Toys | 69667
Books | 14633
=== 3) Second Model Call ===
Final natural-language answer:
Here are the total sales by category for last month (2025-07):
- Furniture: 172,713
- Toys: 69,667
- Clothing: 59,976
- Electronics: 52,423
- Books: 14,633
Want this as a chart or need a different month?O novo parâmetro allowed_tools permite definir um subconjunto de ferramentas que o modelo pode usar a partir do seu kit de ferramentas completo. Você pode definir o modo como automático (o modelo pode escolher) ou obrigatório (o modelo deve usar um). Isso melhoraa segurança, a previsibilidade e o armazenamento em cache rápido d , impedindo que o modelo chame ferramentas indesejadas, ao mesmo tempo que dá flexibilidade para escolher a melhor opção do conjunto permitido.
Um kit completo de ferramentas tem os dois: get_weather e send_email, mas a gente só deixou usar o get_weather e definimos o modo como “obrigatório”, forçando o modelo a usá-lo.
Quando perguntado “Como está o tempo em Oslo?”, o GPT-5 respondeu com uma chamada de função para get_weather e o argumento correto {“city”: "Oslo"}.
from openai import OpenAI
client = OpenAI()
# Full toolset (N)
tools = [
{
"type": "function",
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
{
"type": "function",
"name": "send_email",
"parameters": {
"type": "object",
"properties": {"to": {"type": "string"}, "body": {"type": "string"}},
"required": ["to", "body"],
},
},
]
# Allowed subset (M < N), mode=required → must call get_weather
resp = client.responses.create(
model="gpt-5",
input="What's the weather in Oslo?",
tools=tools,
tool_choice={
"type": "allowed_tools",
"mode": "required", # use "auto" to let it decide
"tools": [{"type": "function", "name": "get_weather"}],
},
)
for item in resp.output:
if getattr(item, "type", None) in ("function_call", "tool_call", "custom_tool_call"):
print("Tool name:", getattr(item, "name", None))
print("Arguments:", getattr(item, "arguments", None))Saída:
Tool name: get_weather
Arguments: {"city":"Oslo"}Preambulos são explicações curtas e visíveis para o usuário que o GPT-5 pode gerar antes de chamar uma ferramenta, explicando por que ele está fazendo essa chamada. Isso aumenta a transparência, a confiança do usuário e facilita a depuração, especialmente em fluxos de trabalho complexos. Simplesmente instruindo o modelo a “explicar antes de chamar uma ferramenta”, você pode tornar as interações maise es, humanas e intencionais, sem adicionar latência significativa.
No código abaixo, a gente definiu um função e adicionamos uma instrução do sistema dizendo ao modelo para gerar uma frase curta e visível ao usuário, precedida por “Preâmbulo:” antes de chamar a ferramenta.
Quando perguntaram “Como está o tempo em Oslo?”, o GPT-5 primeiro explicou que estava verificando um serviço de previsão do tempo ao vivo e, em seguida, chamou a ferramenta get_weather com o argumento correto {“city”: “Oslo”. Depois de usar a ferramenta localmente e ver o resultado, o modelo deu a resposta final em linguagem natural.
from openai import OpenAI
client = OpenAI()
def get_weather(city: str):
return {"city": city, "temperature_c": 12}
# Tool
tools = [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for a city.",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
"additionalProperties": False
},
"strict": True,
}]
# Messages (enable preamble via system instruction)
msgs = [
{"role": "system", "content": "Before you call a tool, explain why you are calling it in ONE short sentence prefixed with 'Preamble:'."},
{"role": "user", "content": "What's the weather in Oslo?"}
]
# 1) Model call → expect a visible preamble + a tool call
resp = client.responses.create(model="gpt-5", input=msgs, tools=tools)
print("=== First response objects ===")
for item in resp.output:
t = getattr(item, "type", None)
if t == "message": # preamble is a normal assistant message
print("PREAMBLE:", getattr(item, "content", None))
if t in ("function_call","tool_call","custom_tool_call"):
print("TOOL:", getattr(item, "name", None))
print("ARGS:", getattr(item, "arguments", None))
tool_call = next(x for x in resp.output if getattr(x, "type", None) in ("function_call","tool_call","custom_tool_call"))
msgs += resp.output # keep context
# 2) Execute tool locally (fake)
import json
args = json.loads(getattr(tool_call, "arguments", "{}"))
city = args.get("city", "Unknown")
tool_result = get_weather(city)
# 3) Return tool result
msgs.append({"type": "function_call_output", "call_id": tool_call.call_id, "output": json.dumps(tool_result)})
# 4) Final model call → natural answer
final = client.responses.create(model="gpt-5", input=msgs, tools=tools)
print("\n=== Final answer ===")
print(final.output_text)Como dá pra ver, o modelo primeiro deu uma breve introdução explicando o que ia fazer e, depois, chamou a ferramenta get_weathercorretamente com {“city”: “Oslo”} e, por fim, mostrou a temperatura em linguagem natural.
=== First response objects ===
PREAMBLE: [ResponseOutputText(annotations=[], text='Preamble: I'm checking a live weather service to get the current conditions for Oslo.', type='output_text', logprobs=[])]
TOOL: get_weather
ARGS: {"city":"Oslo"}
=== Final answer ===
It's currently about 12°C in Oslo.O GPT-5 foi feito pra mandar bem com prompts bem elaborados, e a OpenAI tem um Otimizador de Prompts para te ajudar a ajustá-las. Essa ferramenta adapta automaticamente suas solicitações ao estilo de raciocínio do GPT-5, melhorando a precisão e a eficiência.
Vá para o prompt Editar - API OpenAI e escreva um prompt simples, como “Crie um aplicativo web clone do Netflix”. Ele vai dividir sua solicitação em uma estrutura detalhada, otimizada para o modelo GPT-5.
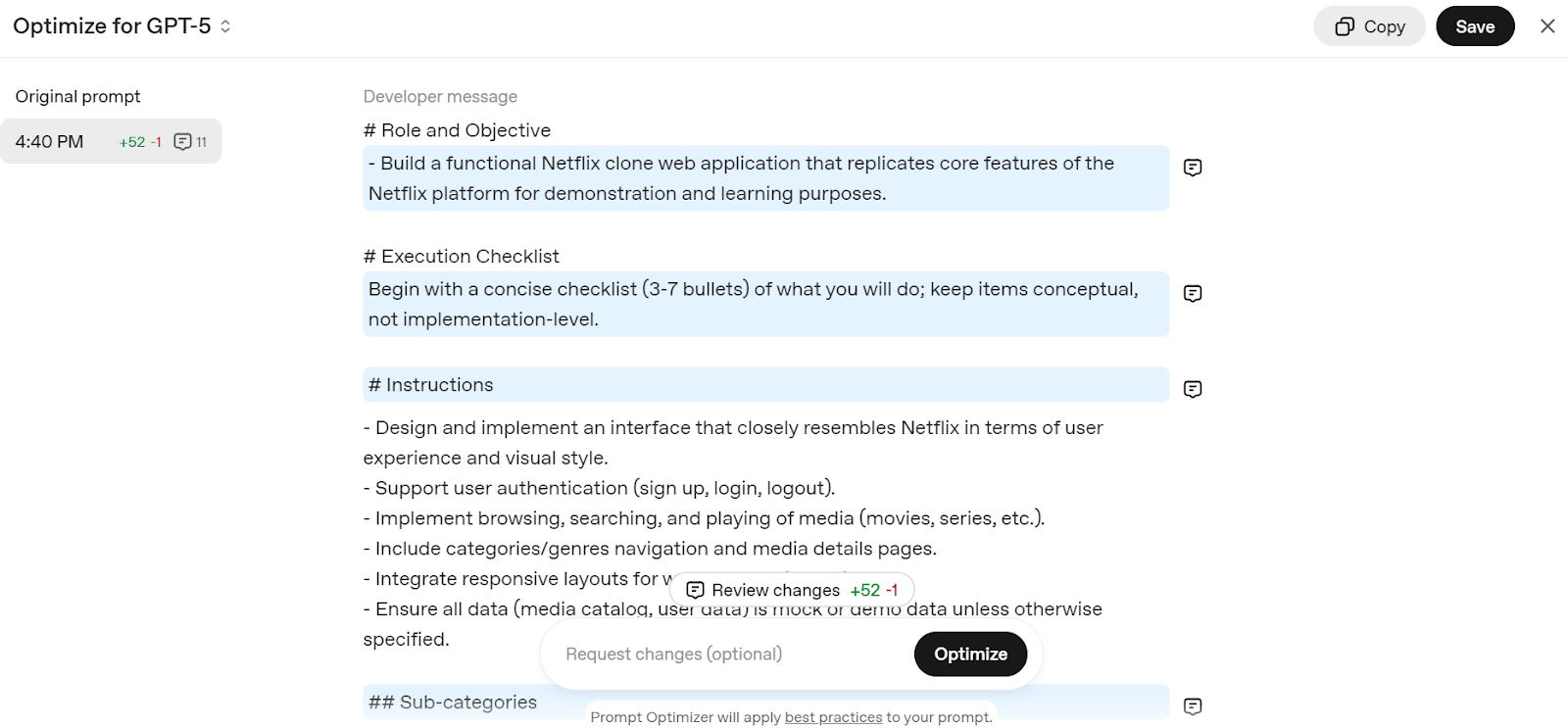
Fonte: Otimizador de prompts
É só copiar o prompt e adicionar ao chat do ChatGPT pra começar a criar seu próprio serviço web Netflix.
A OpenAI recomenda muito que os desenvolvedores mudem dos modelos antigos para a nova família GPT-5 pra reduzir custos, melhorar a precisão e a qualidade das respostas.
A migração é simples; basta seguir a tabela abaixo para escolher o modelo GPT-5 e o nível de raciocínio certos para o seu caso de uso.
|
Modelo atual |
Modelo GPT-5 recomendado |
Nível inicial de raciocínio |
Notas sobre migração |
|
o3 |
GPT-5 |
Médio |
Comece com raciocínio médio + ajuste rápido; aumente para alto se necessário. |
|
gpt-4.1 |
GPT-5 |
Mínimo |
Comece com o mínimo de raciocínio + ajuste rápido; aumente para baixo para obter um melhor desempenho. |
|
o4-mini |
GPT-5-mini |
Médio |
Use o GPT-5-mini com ajuste rápido. |
|
gpt-4.1-mini |
GPT-5-mini |
Mínimo |
Use o GPT-5-mini com ajuste rápido. |
|
gpt-4.1-nano |
GPT-5-nano |
Mínimo |
Use o GPT-5-nano com ajuste rápido. |
O GPT-5 é mais do que só um modelo mais inteligente; é um kit de ferramentas para desenvolvedores criarem sistemas de IA inteligentes, confiáveis e eficientes. Com controle detalhado sobre raciocínio, verbosidade, uso de ferramentas e formatos de saída, ele se adapta a tudo, desde tarefas rápidas de codificação até fluxos de trabalho complexos com várias etapas.
Aproveitando os novos recursos e as melhores práticas, você pode desenvolver aplicativos de IA prontos para produção usando o SDK OpenAI com o mínimo de esforço.
Se você é novo no mundo da OpenAI, não deixe de conferir os recursos abaixo:
Principais cursos da OpenAI
Curso
Curso
Curso
blog
Richie Cotton
7 min
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan




