
Cours
Travailler avec l'API OpenAI
3 h
141.9K
Le GPT-5 est arrivé et transforme la manière dont nous utilisons les outils d'IA. Il excelle dans le codage, l'appel d'outils, le suivi d'instructions et l'automatisation. En réalité, il est si performant que certains tirent la sonnette d'alarme : GPT-5 peut facilement remplacer un développeur junior ou intermédiaire.
Si vous souhaitez approfondir vos connaissances sur les capacités de GPT-5, veuillez consulter GPT-5 : Nouvelles fonctionnalités, tests, benchmarks et plus encore | DataCamp. Vous pouvez également consulter 7 exemples de GPT-5 que vous pouvez essayer dans le chat.
Dans ce tutoriel, nous ne nous concentrerons pas sur les capacités générales du modèle. Au lieu de cela, nous allons explorer et testerles nouvelles fonctionnalités de l'API GPT-5 d' , disponibles à l'adresse, qui ont été introduites avec le nouveau modèle. Nous allons passer en revue chaque fonctionnalité et exécuter des exemples de code afin que vous puissiez les voir en action.
Il existe ici certaines fonctionnalités spéciales qu'aucun autre fournisseur d'API n'offre actuellement. Grâce au SDK OpenAI, vous pouvez désormais créer une application basée sur des agents entièrement fonctionnelle sans intégrer de frameworks externes. Il fonctionne immédiatement après son achat.

Image par l'auteur
GPT-5 introduit un nouveau paramètre de raisonnement qui vous permet de contrôler la profondeur de réflexion du modèle avant qu'il ne réponde. Vous pouvez choisir parmi quatre niveaux d'effort : minimal, faible, moyen ou élevé, en fonction de vos besoins.
Un effort minimal est idéal pour les tâches où la rapidité est essentielle, telles que le codage rapide ou le suivi d'instructions simples, tandis que les niveaux moyen et élevé permettent un raisonnement plus approfondi, étape par étape. Cette flexibilité vous permet d'équilibrer la latence, le coût et la précision.
Commencez par installer le SDK Python OpenAI et définissez votre clé API en tant que variable d'environnement :
pip install openaiVeuillez définir votre clé API (remplacer par votre clé réelle) :
export OPENAI_API_KEY="your_api_key_here"setx OPENAI_API_KEY "your_api_key_here"Utilisons l'API Response pour générer du texte avec un effort de raisonnement « minimal ». Cela signifie que le modèle répondra directement, sans allouer de jetons pour le raisonnement interne.
import os
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
)
print(resp.output_text)Résultat :
Guido van Rossum is known as the father (creator) of Python. He first released Python in 1991.Vous pouvez également consulter le résumé d'utilisation des jetons pour comprendre comment le modèle a traité votre requête :
print(f"Input tokens: {resp.usage.input_tokens}")
print(f" - Cached tokens: {resp.usage.input_tokens_details.cached_tokens}")
print(f"Output tokens: {resp.usage.output_tokens}")
print(f" - Reasoning tokens: {resp.usage.output_tokens_details.reasoning_tokens}")
print(f"Total tokens: {resp.usage.total_tokens}")Comme indiqué, aucun jeton n'a été utilisé pour le raisonnement lorsque l'effort est défini sur minimal.
Input tokens: 13
- Cached tokens: 0
Output tokens: 31
- Reasoning tokens: 0
Total tokens: 44Maintenant, augmentons le niveau de raisonnement à « élevé » pour observer comment le raisonnement interne du modèle évolue :
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "high"},
)
print(resp.output_text)Résultat :
Guido van Rossum. He created Python and first released it in 1991.Veuillez vérifier à nouveau l'utilisation du jeton :
print(f"Input tokens: {resp.usage.input_tokens}")
print(f" - Cached tokens: {resp.usage.input_tokens_details.cached_tokens}")
print(f"Output tokens: {resp.usage.output_tokens}")
print(f" - Reasoning tokens: {resp.usage.output_tokens_details.reasoning_tokens}")
print(f"Total tokens: {resp.usage.total_tokens}")Même pour une question simple, le modèle a utilisé 192 jetons pour raisonner à un niveau élevé. Cela démontre comment vous pouvez désormais contrôler la profondeur du raisonnement afin d'optimiser les coûts, la vitesse ou la précision selon vos besoins.
Input tokens: 13
- Cached tokens: 0
Output tokens: 216
- Reasoning tokens: 192
Total tokens: 229Avec GPT-5, vous pouvez désormais contrôler directement la quantité d'informations fournies par le modèle à l'aide du paramètre « verbosity » (verbosité). Réglez-le sur «faible » ( ) pour des réponses concises, « moyen » (medium ) pour des détails équilibrés ou «élevé » (high) ( ) pour des explications approfondies. Ceci est particulièrement utile pour la génération de code : une verbosité faible produit un code court et clair, tandis qu'une verbosité élevée inclut des commentaires en ligne et des explications détaillées.
Vous pouvez associer le paramètre de verbosité aux contrôles d' sde raisonnement afin d'adapter les réponses à vos besoins. Que vous souhaitiez une phrase courte, une réponse plus longue ou un rapport complet, vous bénéficiez d'une flexibilité totale.
Le niveau de verbosité « faible » produit une réponse brève et directe.
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "low"},
)
print(resp.output_text)Résultat :
Guido van Rossum.Le niveau de verbosité « élevé » génère une réponse beaucoup plus détaillée et explicative.
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "high"},
)
print(resp.output_text)Résultat :
Guido van Rossum is known as the "father of Python." He created Python in the late 1980s and released the first version (Python 0.9.0) in 1991. He also served for many years as Python's "Benevolent Dictator For Life" (BDFL), guiding the language's development.L'une des principales améliorations de GPT-5 réside dans sa capacité à transmettre l' sissues du raisonnement en chaîne de pensées (CoT) entre les tours dans l'API Responses. Cela signifie que le modèle mémorise son raisonnement interne des étapes précédentes, ce qui évite les réflexions redondantes et améliore à la fois la vitesse et la précision.
Dans les conversations à plusieurs tours, en particulier lorsque vous utilisez des outils, transmettez simplement l' previous_response_id pour conserver le contexte du raisonnement.
La première requête demande « Qui est le père de Python ? », et la deuxième requête, liée à la première via previous_response_id, demande au modèle « Écrivez un blog à ce sujet » sans reformuler le sujet. En transmettant l'ID de la réponse précédente, le modèle conserve le contexte du raisonnement.
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
first = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "low"},
)
followup = client.responses.create(
model="gpt-5",
previous_response_id=first.id,
input="Write a blog on it.",
reasoning={"effort": "medium"},
text={"verbosity": "high"},
)
print(followup.output_text)Nous avons ainsi obtenu un blog sur le père de Python.

Les outils personnalisés dans GPT-5 prennent désormais en charge les entrées libres, ce qui permet au modèle d'envoyer du texte brut, tel que du code, des requêtes SQL ou des commandes shell, directement à vos outils. Il s'agit d'une avancée significative par rapport à l'ancienne approche structurée exclusivement JSON, qui vous offre davantage de flexibilité dans la manière dont le modèle interagit avec vos systèmes. Que vous développiez un exécuteur de code, un moteur de requête ou un interpréteur DSL, la saisie libre rend GPT-5 beaucoup plus adaptable aux tâches réelles et non structurées.
Dans le code ci-dessous, nous avons défini un faux exécuteur SQL, l'avons enregistré en tant qu'outil personnalisé et avons effectué une requête initiale à laquelle le modèle répond par une requête SQL libre. Cette requête est extraite, exécutée localement, et le résultat est renvoyé au modèle à l'aide du mêmeidentifiant d'appel d' , call_id, afin de conserver le contexte d'appel de l'outil. Enfin, GPT-5 transforme les résultats bruts de l'outil en une réponse en langage naturel.
from openai import OpenAI
import random
client = OpenAI()
def run_sql_query(sql: str) -> str:
print("\n[FAKE DB] Executing SQL:\n", sql)
categories = ["Electronics", "Clothing", "Furniture", "Toys", "Books"]
result = "category | total_sales\n" + "-" * 28 + "\n"
for cat in categories:
result += f"{cat:<11} | {random.randint(5000, 200000)}\n"
return result
tools = [
{
"type": "custom",
"name": "sql_query_runner",
"description": "Runs raw SQL queries on the company sales database.",
}
]
messages = [
{
"role": "user",
"content": "Show me the total sales for each product category last month.",
}
]
# 1) First call - model emits a freeform tool call
resp = client.responses.create(model="gpt-5", tools=tools, input=messages)
# IMPORTANT: carry the tool call into the next turn
messages += resp.output # <-- this preserves the tool_call with its call_id
# Find the tool call from the response output
tool_call = next(
(
x
for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "function_call", "tool_call")
),
None,
)
assert tool_call is not None, "No tool call found."
# Freeform text is in `input` (fallback to `arguments` for safety)
raw_text = getattr(tool_call, "input", None) or getattr(tool_call, "arguments", "")
sql_text = raw_text.strip()
# 2) Execute the tool locally
fake_result = run_sql_query(sql_text)
# 3) Send tool result back, referencing the SAME call_id
messages.append(
{
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": fake_result,
}
)
# 4) Final call - model turns tool output into a natural answer
final = client.responses.create(model="gpt-5", tools=tools, input=messages)
print("\nFinal output text:\n", final.output_text)Résultat :
[FAKE DB] Executing SQL:
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema','pg_catalog')
ORDER BY 1,2;
Final output text:
Here are the total sales by category for last month (July 2025):
- Electronics: 31,766
- Clothing: 90,266
- Furniture: 55,471
- Toys: 124,625
- Books: 74,263
Want this as a CSV or chart?Pour les scénarios où la précision est essentielle, GPT-5 prend en charge les grammaires sans contexte (CFG) afin de contrôler strictement les formats de sortie. En associant une syntaxe telle que celle du langage SQL ou un langage spécifique à un domaine, vous pouvez garantir que les réponses du modèle correspondent toujours à la structure requise. Ceci est particulièrement utile pourl' s à haut risque ou les flux de travail automatisés, où même de légères divergences de format peuvent entraîner des erreurs.
Dans l'exemple de code, nous avons créé une outil sql_query_runner et défini sa syntaxe SQL à l'aide d'une grammaire Lark, garantissant ainsi que tout SQL généré par le modèle est toujours valide et respecte notre structure exacte.
Lors du premier appel de modèle, GPT-5 utilise cet outil pour générer une requête SQL conforme à la grammaire pour les ventes du mois dernier par catégorie. Nous exécutons ensuite cette requête localement, renvoyons les résultats au modèle à l'aide du mêmeidentifiant d'appel , puis effectuons un deuxième appel au cours duquel GPT-5 transforme les données brutes en une réponse claire et naturelle.
from openai import OpenAI
import random
client = OpenAI()
def run_sql_query(sql: str) -> str:
cats = ["Electronics", "Clothing", "Furniture", "Toys", "Books"]
rows = [f"{c:<11} | {random.randint(5_000, 200_000)}" for c in cats]
return "category | total_sales\n" + "-" * 28 + "\n" + "\n".join(rows)
tools = [
{
"type": "custom",
"name": "sql_query_runner",
"description": "Runs raw SQL on the sales DB.",
"format": {
"type": "grammar",
"syntax": "lark",
"definition": r"""
start: SELECT CATEGORY COMMA SUM LPAREN SALES RPAREN AS TOTAL_SALES FROM ORDERS WHERE ORDER_MONTH EQ ESCAPED_STRING GROUP BY CATEGORY ORDER BY TOTAL_SALES (DESC|ASC)?
SELECT: "SELECT"
CATEGORY: "category"
COMMA: ","
SUM: "SUM"
LPAREN: "("
SALES: "sales"
RPAREN: ")"
AS: "AS"
TOTAL_SALES: "total_sales"
FROM: "FROM"
ORDERS: "orders"
WHERE: "WHERE"
ORDER_MONTH: "order_month"
EQ: "="
GROUP: "GROUP"
BY: "BY"
ORDER: "ORDER"
DESC: "DESC"
ASC: "ASC"
%import common.ESCAPED_STRING
%ignore /[ \t\r\n]+/
""",
},
}
]
msgs = [
{
"role": "user",
"content": "Show me the total sales for each product category last month.",
}
]
print("\n=== 1) First Model Call ===")
resp = client.responses.create(
model="gpt-5", input=msgs, tools=tools, text={"format": {"type": "text"}}
)
print("Raw model output objects:\n", resp.output)
msgs += resp.output
tool_call = next(
x
for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "function_call", "tool_call")
)
sql = (getattr(tool_call, "input", None) or getattr(tool_call, "arguments", "")).strip()
print("\nExtracted SQL from tool call:\n", sql)
print("\n=== 2) Local Tool Execution ===")
tool_result = run_sql_query(sql)
print(tool_result)
msgs.append(
{
"type": "function_call_output",
"call_id": getattr(tool_call, "call_id", None) or tool_call["call_id"],
"output": tool_result,
}
)
print("\n=== 3) Second Model Call ===")
final = client.responses.create(
model="gpt-5", input=msgs, tools=tools, text={"format": {"type": "text"}}
)
print("\nFinal natural-language answer:\n", final.output_text)Comme nous pouvons le constater, le modèle a d'abord généré une requête SQL conforme à la grammaire, puis a exécuté la fonction pour récupérer les données de vente. Enfin, GPT-5 a converti ces données en un résumé clair et classé en langage naturel des ventes du mois dernier par catégorie.
=== 1) First Model Call ===
Raw model output objects:
[ResponseReasoningItem(id='rs_6897acee8afc819f9e7ae0f675bfa4ee0d5175a46255063b', summary=[], type='reasoning', content=None, encrypted_content=None, status=None), ResponseCustomToolCall(call_id='call_vzcHPT7EGvb7QbhF2djVIJZA', input='SELECT category, SUM(sales) AS total_sales FROM orders WHERE order_month = "2025-07" GROUP BY category ORDER BY total_sales DESC', name='sql_query_runner', type='custom_tool_call', id='ctc_6897acf67a34819f84a085191e4ca1fb0d5175a46255063b', status='completed')]
Extracted SQL from tool call:
SELECT category, SUM(sales) AS total_sales FROM orders WHERE order_month = "2025-07" GROUP BY category ORDER BY total_sales DESC
=== 2) Local Tool Execution ===
category | total_sales
----------------------------
Electronics | 52423
Clothing | 59976
Furniture | 172713
Toys | 69667
Books | 14633
=== 3) Second Model Call ===
Final natural-language answer:
Here are the total sales by category for last month (2025-07):
- Furniture: 172,713
- Toys: 69,667
- Clothing: 59,976
- Electronics: 52,423
- Books: 14,633
Want this as a chart or need a different month?Le nouveau paramètre allowed_tools vous permet de définir un sous-ensemble d'outils que le modèle peut utiliser à partir de votre boîte à outils complète. Vous pouvez régler le mode sur automatique (le modèle peut choisir) ou obligatoire (le modèle doit en utiliser un). Cela améliorela sécurité, la prévisibilité et la rapidité de la mise en cache de l' en empêchant le modèle d'appeler des outils non souhaités, tout en lui laissant la flexibilité nécessaire pour choisir la meilleure option parmi celles autorisées.
Une boîte à outils complète contient à la fois get_weather et send_email, mais nous n'avons autorisé que get_weather et défini le mode sur « required », forçant ainsi le modèle à l'utiliser.
À la question « Quel temps fait-il à Oslo ? », GPT-5 a répondu par un appel de fonction à get_weather et l'argument correct {« city » : "Oslo"}.
from openai import OpenAI
client = OpenAI()
# Full toolset (N)
tools = [
{
"type": "function",
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
{
"type": "function",
"name": "send_email",
"parameters": {
"type": "object",
"properties": {"to": {"type": "string"}, "body": {"type": "string"}},
"required": ["to", "body"],
},
},
]
# Allowed subset (M < N), mode=required → must call get_weather
resp = client.responses.create(
model="gpt-5",
input="What's the weather in Oslo?",
tools=tools,
tool_choice={
"type": "allowed_tools",
"mode": "required", # use "auto" to let it decide
"tools": [{"type": "function", "name": "get_weather"}],
},
)
for item in resp.output:
if getattr(item, "type", None) in ("function_call", "tool_call", "custom_tool_call"):
print("Tool name:", getattr(item, "name", None))
print("Arguments:", getattr(item, "arguments", None))Résultat :
Tool name: get_weather
Arguments: {"city":"Oslo"}Les préambules sont de courtes explications visibles par l'utilisateur que GPT-5 peut générer avant d'appeler un outil, expliquant pourquoi il effectue cet appel. Cela améliore la transparence, la confiance des utilisateurs et facilite le débogage, en particulier dans les flux de travail complexes. En demandant simplement au modèle « d'expliquer avant d'utiliser un outil », vous pouvez rendre les interactions plus humaines et intentionnelles sans ajouter de latence significative.
Dans le code ci-dessous, nous avons défini une fonction appelée fonction et ajouté une instruction système indiquant au modèle d'afficher une courte phrase visible par l'utilisateur, précédée de « Préambule : », avant d'appeler l'outil.
Lorsqu'on lui a demandé « Quel temps fait-il à Oslo ? », GPT-5 a d'abord produit un préambule expliquant qu'il vérifiait un service météo en direct, puis a appelé l'outil get_weather avec l'argument correct {"city": "Oslo"}. Après avoir exécuté l'outil localement et renvoyé le résultat, le modèle a fourni la réponse finale en langage naturel.
from openai import OpenAI
client = OpenAI()
def get_weather(city: str):
return {"city": city, "temperature_c": 12}
# Tool
tools = [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for a city.",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
"additionalProperties": False
},
"strict": True,
}]
# Messages (enable preamble via system instruction)
msgs = [
{"role": "system", "content": "Before you call a tool, explain why you are calling it in ONE short sentence prefixed with 'Preamble:'."},
{"role": "user", "content": "What's the weather in Oslo?"}
]
# 1) Model call → expect a visible preamble + a tool call
resp = client.responses.create(model="gpt-5", input=msgs, tools=tools)
print("=== First response objects ===")
for item in resp.output:
t = getattr(item, "type", None)
if t == "message": # preamble is a normal assistant message
print("PREAMBLE:", getattr(item, "content", None))
if t in ("function_call","tool_call","custom_tool_call"):
print("TOOL:", getattr(item, "name", None))
print("ARGS:", getattr(item, "arguments", None))
tool_call = next(x for x in resp.output if getattr(x, "type", None) in ("function_call","tool_call","custom_tool_call"))
msgs += resp.output # keep context
# 2) Execute tool locally (fake)
import json
args = json.loads(getattr(tool_call, "arguments", "{}"))
city = args.get("city", "Unknown")
tool_result = get_weather(city)
# 3) Return tool result
msgs.append({"type": "function_call_output", "call_id": tool_call.call_id, "output": json.dumps(tool_result)})
# 4) Final model call → natural answer
final = client.responses.create(model="gpt-5", input=msgs, tools=tools)
print("\n=== Final answer ===")
print(final.output_text)Comme nous pouvons le constater, le modèle a d'abord fourni une brève introduction expliquant son intention, puis a correctement appelé l'outil get_weather avec l' e {« city » : « Oslo » ;, puis a finalement renvoyé la température en langage naturel.
=== First response objects ===
PREAMBLE: [ResponseOutputText(annotations=[], text='Preamble: I'm checking a live weather service to get the current conditions for Oslo.', type='output_text', logprobs=[])]
TOOL: get_weather
ARGS: {"city":"Oslo"}
=== Final answer ===
It's currently about 12°C in Oslo.GPT-5 est conçu pour exceller avec des invites bien rédigées, et OpenAI fournit un optimiseur de invites pour vous aider à les affiner. Cet outil adapte automatiquement vos invites au style de raisonnement de GPT-5, améliorant ainsi la précision et l'efficacité.
Accédez à l' Invite d'édition - API OpenAI et écrivez une invite simple, telle que « Créer une application web clone de Netflix ». Il décomposera votre invite en une structure détaillée, optimisée pour le modèle GPT-5.
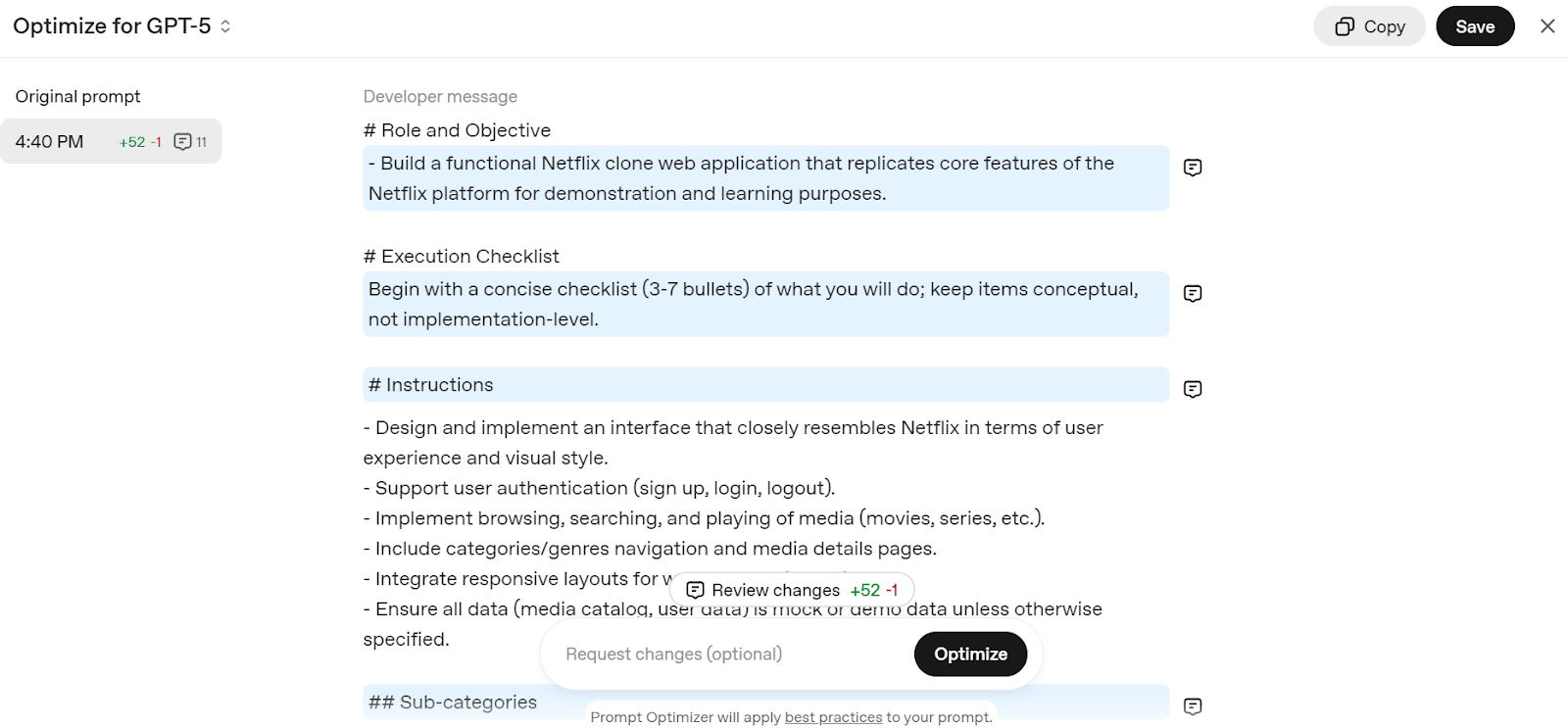
Source : Optimiseur de prompt
Il vous suffit de copier l'invite et de l'ajouter au chat ChatGPT pour commencer à créer votre propre service web Netflix.
OpenAI recommande vivement aux développeurs de migrer des anciens modèles vers la nouvelle famille GPT-5 afin de réduire les coûts, d'améliorer la précision et d'optimiser la qualité des réponses.
La migration est simple : il vous suffit de suivre le tableau ci-dessous pour choisir le modèle GPT-5 et le niveau de raisonnement adaptés à votre cas d'utilisation.
|
Modèle actuel |
Modèle GPT-5 recommandé |
Niveau de raisonnement de départ |
Remarques relatives à la migration |
|
o3 |
GPT-5 |
Moyen |
Commencez par un raisonnement moyen + un réglage rapide ; augmentez à élevé si nécessaire. |
|
gpt-4.1 |
GPT-5 |
Minimal |
Commencez par un raisonnement minimal et un réglage rapide, puis augmentez jusqu'à un niveau faible pour obtenir de meilleures performances. |
|
o4-mini |
GPT-5-mini |
Moyen |
Veuillez utiliser GPT-5-mini avec un réglage rapide. |
|
gpt-4.1-mini |
GPT-5-mini |
Minimal |
Veuillez utiliser GPT-5-mini avec un réglage rapide. |
|
gpt-4.1-nano |
GPT-5-nano |
Minimal |
Veuillez utiliser GPT-5-nano avec un réglage rapide. |
GPT-5 est bien plus qu'un modèle plus intelligent ; il s'agit d'une boîte à outils pour développeurs permettant de créer des systèmes d'IA intelligents, fiables et efficaces. Grâce à un contrôle précis du raisonnement, du niveau de détail, de l'utilisation des outils et des formats de sortie, il s'adapte à toutes les situations, des tâches de codage rapides aux workflows complexes en plusieurs étapes.
En tirant parti de ses nouvelles fonctionnalités et des meilleures pratiques, vous pouvez développer des applications d'IA prêtes pour la production à l'aide du SDK OpenAI avec un minimum d'effort.
Si vous débutez avec OpenAI, veuillez consulter les ressources suivantes :
Meilleurs cours OpenAI
Cours
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
Tutoriel
Matt Crabtree
Tutoriel
Sejal Jaiswal