
Kurs
Arbeiten mit der OpenAI-API
3 Std.
141.9K
GPT-5 ist da und verändert die Art und Weise, wie wir KI-Tools nutzen. Es ist super beim Codieren, Aufrufen von Tools, Befolgen von Anweisungen und Automatisieren. Tatsächlich ist es so leistungsfähig, dass einige Alarm schlagen: GPT-5 kann ganz einfach einen Junior- oder Mid-Level-Entwickler ersetzen.
Wenn du mehr über die Möglichkeiten von GPT-5 erfahren möchtest, schau dir „ GPT-5” an . Neue Funktionen, Tests, Benchmarks und mehr | DataCamp. Du kannst dir auch 7 GPT-5-Beispiele ansehen, die du im Chat ausprobieren kannst.
In diesem Tutorial geht's nicht um die allgemeinen Fähigkeiten des Modells. Stattdessen werden wir dieneuen GPT-5-API-Funktionen , die mit dem neuen Modell eingeführt wurden, erkunden und testen. Wir zeigen dir alle Funktionen und probieren Beispielcode aus, damit du sie in Aktion sehen kannst.
Hier gibt's ein paar coole Features, die sonst kein anderer API-Anbieter hat. Mit dem OpenAI SDK kannst du jetzt eine voll funktionsfähige agentenbasierte Anwendung erstellen,ohne externe Frameworks integrieren zu müssen. Es funktioniert sofort nach dem Auspacken.

Bild vom Autor
GPT-5 hat einen neuen Parameter für das logische Denken, mit dem du einstellen kannst, wie tief das Modell nachdenkt, bevor es antwortet. Du kannst je nach Bedarf zwischen den Schwierigkeitsstufen „ “, „minimal“, „low“, „medium“ oder „high“ wählen.
Minimaler Aufwand ist super für Aufgaben, bei denen es auf Schnelligkeit ankommt, wie schnelles Programmieren oder einfache Anweisungen befolgen, während mittlerer und hoher Aufwand mehr Zeit für gründliches, schrittweises Denken lassen. Dank dieser Flexibilität kannst du Latenz, Kosten und Genauigkeit gut aufeinander abstimmen.
Installiere zuerst das OpenAI Python SDK und leg deinen API-Schlüssel als Umgebungsvariable fest:
pip install openaiGib deinen API-Schlüssel ein (ersetze ihn durch deinen echten Schlüssel):
export OPENAI_API_KEY="your_api_key_here"setx OPENAI_API_KEY "your_api_key_here"Lass uns die Response-API nutzen , um Text mit „minimalem“ Denkaufwand zu erstellen. Das heißt, das Modell reagiert direkt, ohne Tokens für interne Überlegungen zu vergeben.
import os
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
)
print(resp.output_text)Ausgabe:
Guido van Rossum is known as the father (creator) of Python. He first released Python in 1991.Du kannst auch die Zusammenfassung der Token-Verwendung checken, um zu sehen, wie das Modell deine Anfrage bearbeitet hat:
print(f"Input tokens: {resp.usage.input_tokens}")
print(f" - Cached tokens: {resp.usage.input_tokens_details.cached_tokens}")
print(f"Output tokens: {resp.usage.output_tokens}")
print(f" - Reasoning tokens: {resp.usage.output_tokens_details.reasoning_tokens}")
print(f"Total tokens: {resp.usage.total_tokens}")Wie gezeigt, wurden bei minimalem Aufwand keine Tokens für die Argumentation verwendet.
Input tokens: 13
- Cached tokens: 0
Output tokens: 31
- Reasoning tokens: 0
Total tokens: 44Jetzt erhöhen wir den Denkaufwand auf „hoch“, um zu sehen, wie sich die interne Argumentation des Modells ändert:
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "high"},
)
print(resp.output_text)Ausgabe:
Guido van Rossum. He created Python and first released it in 1991.Überprüfe nochmal die Verwendung des Tokens:
print(f"Input tokens: {resp.usage.input_tokens}")
print(f" - Cached tokens: {resp.usage.input_tokens_details.cached_tokens}")
print(f"Output tokens: {resp.usage.output_tokens}")
print(f" - Reasoning tokens: {resp.usage.output_tokens_details.reasoning_tokens}")
print(f"Total tokens: {resp.usage.total_tokens}")Selbst für eine einfache Frage hat das Modell 192 Token gebraucht, um das zu verstehen. Das zeigt, wie du jetzt die Tiefe der Schlussfolgerungen steuern kannst, um je nach Bedarf Kosten, Geschwindigkeit oder Genauigkeit zu optimieren.
Input tokens: 13
- Cached tokens: 0
Output tokens: 216
- Reasoning tokens: 192
Total tokens: 229Mit GPT-5 kannst du jetzt direkt über den Parameter „Verbosity“ (Ausführlichkeit) steuern, wie viel das Modell sagt. Stell es auf„ “ (niedrig) für kurze Antworten, „medium“ für ausgewogene Details oder „high“ ( ) für ausführliche Erklärungen. Das ist besonders praktisch für die Codegenerierung – wenig ausführliche Kommentare sorgen für kurzen, übersichtlichen Code, während ausführliche Kommentare Inline-Kommentare und detaillierte Erläuterungen enthalten.
Du kannst den Parameter „Verbosity“ mit den Steuerelementenfür die Argumentations en kombinieren , um die Antworten genau an deine Bedürfnisse anzupassen. Ob du einen kurzen Satz, eine längere Antwort oder einen umfassenden Bericht willst, du hast die volle Flexibilität.
Die „geringe“ Ausführlichkeit sorgt für eine kurze, direkte Antwort.
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "low"},
)
print(resp.output_text)Ausgabe:
Guido van Rossum.Die „hohe“ Ausführlichkeit sorgt für eine viel detailliertere und erklärendere Antwort.
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "high"},
)
print(resp.output_text)Ausgabe:
Guido van Rossum is known as the "father of Python." He created Python in the late 1980s and released the first version (Python 0.9.0) in 1991. He also served for many years as Python's "Benevolent Dictator For Life" (BDFL), guiding the language's development.Eine der größten Verbesserungen von GPT-5 ist, dass es jetzt in der Responses API zwischen den Antwortendie „Chain-of-Thought”-Argumentations enweitergebenkann . Das heißt, das Modell merkt sich, wie es in den vorherigen Schritten gedacht hat, sodass es nicht alles nochmal überdenken muss und so schneller und genauer wird.
In längeren Unterhaltungen, vor allem wenn Tools benutzt werden, gib einfach die previous_response_id weiter, damit der Kontext der Argumentation erhalten bleibt.
Die erste Anfrage lautet: „Wer ist der Vater von Python?“, und die zweite Anfrage, die über previous_response_idmit der ersten verknüpft ist , fordert das Modell auf, „einen Blogbeitrag dazu zu schreiben“, ohne das Thema erneut zu nennen. Durch die Weitergabe der ID der vorherigen Antwort behält das Modell den Kontext der Argumentation bei.
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
first = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "low"},
)
followup = client.responses.create(
model="gpt-5",
previous_response_id=first.id,
input="Write a blog on it.",
reasoning={"effort": "medium"},
text={"verbosity": "high"},
)
print(followup.output_text)So haben wir einen Blog über den Vater von Python bekommen.

Benutzerdefinierte Tools in GPT-5 unterstützen jetzt Freitexteingaben, sodass das Modell Rohtext wie Code, SQL-Abfragen oder Shell-Befehle direkt an deine Tools senden kann. Das ist ein großer Schritt weg von dem alten, nur auf JSON basierenden Ansatz und gibt dir mehr Flexibilität bei der Interaktion des Modells mit deinen Systemen. Egal, ob du einen Code-Executor, eine Abfrage-Engine oder einen DSL-Interpreter entwickelst – dank der freien Eingabe ist GPT-5 viel flexibler für echte, unstrukturierte Aufgaben.
Im folgenden Code haben wir einen falschen SQL-Runner definiert, ihn als benutzerdefiniertes Tool registriert und eine erste Anfrage gestellt, auf die das Modell mit einer freien SQL-Abfrage antwortet. Diese Abfrage wird extrahiert, lokal ausgeführt und das Ergebnis wird unter Verwendung derselbenAbfrage-ID „ “ und derselbenAufruf-ID „ “ an das Modell zurückgesendet, um den Aufrufkontext des Tools beizubehalten. Zum Schluss macht GPT-5 aus dem rohen Tool-Output eine Antwort in natürlicher Sprache.
from openai import OpenAI
import random
client = OpenAI()
def run_sql_query(sql: str) -> str:
print("\n[FAKE DB] Executing SQL:\n", sql)
categories = ["Electronics", "Clothing", "Furniture", "Toys", "Books"]
result = "category | total_sales\n" + "-" * 28 + "\n"
for cat in categories:
result += f"{cat:<11} | {random.randint(5000, 200000)}\n"
return result
tools = [
{
"type": "custom",
"name": "sql_query_runner",
"description": "Runs raw SQL queries on the company sales database.",
}
]
messages = [
{
"role": "user",
"content": "Show me the total sales for each product category last month.",
}
]
# 1) First call - model emits a freeform tool call
resp = client.responses.create(model="gpt-5", tools=tools, input=messages)
# IMPORTANT: carry the tool call into the next turn
messages += resp.output # <-- this preserves the tool_call with its call_id
# Find the tool call from the response output
tool_call = next(
(
x
for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "function_call", "tool_call")
),
None,
)
assert tool_call is not None, "No tool call found."
# Freeform text is in `input` (fallback to `arguments` for safety)
raw_text = getattr(tool_call, "input", None) or getattr(tool_call, "arguments", "")
sql_text = raw_text.strip()
# 2) Execute the tool locally
fake_result = run_sql_query(sql_text)
# 3) Send tool result back, referencing the SAME call_id
messages.append(
{
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": fake_result,
}
)
# 4) Final call - model turns tool output into a natural answer
final = client.responses.create(model="gpt-5", tools=tools, input=messages)
print("\nFinal output text:\n", final.output_text)Ausgabe:
[FAKE DB] Executing SQL:
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema','pg_catalog')
ORDER BY 1,2;
Final output text:
Here are the total sales by category for last month (July 2025):
- Electronics: 31,766
- Clothing: 90,266
- Furniture: 55,471
- Toys: 124,625
- Books: 74,263
Want this as a CSV or chart?Für Fälle, in denen es auf Genauigkeit ankommt, unterstützt GPT-5 kontextfreie Grammatiken (CFGs), um die Ausgabeformate genau zu steuern. Durch das Hinzufügen einer Grammatik wie der SQL-Syntax oder einer domänenspezifischen Sprache kannst du sicherstellen, dass die Antworten des Modells immer der von dir gewünschten Struktur entsprechen. Das ist besonders wichtig für„ “,also automatisierte Arbeitsabläufe mit hohem Risiko, wo schon kleine Abweichungen im Format Fehler verursachen können.
Im Beispielcode haben wir eine sql_query_runner Tool erstellt und seine SQL-Syntax mit einer Lark-Grammatik definiert, um sicherzustellen, dass alle vom Modell generierten SQL-Anweisungen immer gültig sind und genau unserer Struktur entsprechen.
Beim ersten Aufruf des Modells nutzt GPT-5 dieses Tool, um eine grammatikalisch korrekte SQL-Abfrage für die Verkäufe des letzten Monats nach Kategorien zu erstellen. Dann führen wir diese Abfrage lokal aus, schicken die Ergebnisse mit dem gleichenAufruf „ “ zurück an das Modell und machen einen zweiten Aufruf, bei dem GPT-5 die Rohdaten in eine klare Antwort in natürlicher Sprache umwandelt.
from openai import OpenAI
import random
client = OpenAI()
def run_sql_query(sql: str) -> str:
cats = ["Electronics", "Clothing", "Furniture", "Toys", "Books"]
rows = [f"{c:<11} | {random.randint(5_000, 200_000)}" for c in cats]
return "category | total_sales\n" + "-" * 28 + "\n" + "\n".join(rows)
tools = [
{
"type": "custom",
"name": "sql_query_runner",
"description": "Runs raw SQL on the sales DB.",
"format": {
"type": "grammar",
"syntax": "lark",
"definition": r"""
start: SELECT CATEGORY COMMA SUM LPAREN SALES RPAREN AS TOTAL_SALES FROM ORDERS WHERE ORDER_MONTH EQ ESCAPED_STRING GROUP BY CATEGORY ORDER BY TOTAL_SALES (DESC|ASC)?
SELECT: "SELECT"
CATEGORY: "category"
COMMA: ","
SUM: "SUM"
LPAREN: "("
SALES: "sales"
RPAREN: ")"
AS: "AS"
TOTAL_SALES: "total_sales"
FROM: "FROM"
ORDERS: "orders"
WHERE: "WHERE"
ORDER_MONTH: "order_month"
EQ: "="
GROUP: "GROUP"
BY: "BY"
ORDER: "ORDER"
DESC: "DESC"
ASC: "ASC"
%import common.ESCAPED_STRING
%ignore /[ \t\r\n]+/
""",
},
}
]
msgs = [
{
"role": "user",
"content": "Show me the total sales for each product category last month.",
}
]
print("\n=== 1) First Model Call ===")
resp = client.responses.create(
model="gpt-5", input=msgs, tools=tools, text={"format": {"type": "text"}}
)
print("Raw model output objects:\n", resp.output)
msgs += resp.output
tool_call = next(
x
for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "function_call", "tool_call")
)
sql = (getattr(tool_call, "input", None) or getattr(tool_call, "arguments", "")).strip()
print("\nExtracted SQL from tool call:\n", sql)
print("\n=== 2) Local Tool Execution ===")
tool_result = run_sql_query(sql)
print(tool_result)
msgs.append(
{
"type": "function_call_output",
"call_id": getattr(tool_call, "call_id", None) or tool_call["call_id"],
"output": tool_result,
}
)
print("\n=== 3) Second Model Call ===")
final = client.responses.create(
model="gpt-5", input=msgs, tools=tools, text={"format": {"type": "text"}}
)
print("\nFinal natural-language answer:\n", final.output_text)Wie wir sehen können, hat das Modell erst eine SQL-Abfrage erstellt, die mit der Grammatik klappt, und dann die Funktion ausgeführt, um die Verkaufsdaten zu holen. Schließlich hat GPT-5 diese Daten in eine übersichtliche, nach Kategorien geordnete Zusammenfassung der Verkäufe des letzten Monats in natürlicher Sprache umgewandelt.
=== 1) First Model Call ===
Raw model output objects:
[ResponseReasoningItem(id='rs_6897acee8afc819f9e7ae0f675bfa4ee0d5175a46255063b', summary=[], type='reasoning', content=None, encrypted_content=None, status=None), ResponseCustomToolCall(call_id='call_vzcHPT7EGvb7QbhF2djVIJZA', input='SELECT category, SUM(sales) AS total_sales FROM orders WHERE order_month = "2025-07" GROUP BY category ORDER BY total_sales DESC', name='sql_query_runner', type='custom_tool_call', id='ctc_6897acf67a34819f84a085191e4ca1fb0d5175a46255063b', status='completed')]
Extracted SQL from tool call:
SELECT category, SUM(sales) AS total_sales FROM orders WHERE order_month = "2025-07" GROUP BY category ORDER BY total_sales DESC
=== 2) Local Tool Execution ===
category | total_sales
----------------------------
Electronics | 52423
Clothing | 59976
Furniture | 172713
Toys | 69667
Books | 14633
=== 3) Second Model Call ===
Final natural-language answer:
Here are the total sales by category for last month (2025-07):
- Furniture: 172,713
- Toys: 69,667
- Clothing: 59,976
- Electronics: 52,423
- Books: 14,633
Want this as a chart or need a different month?M it dem neuen Parameter „allowed_tools“ kannst du eine Untergruppe von Tools definieren , die das Modell aus deinem kompletten Toolkit verwenden darf. Du kannst den Modus auf „Auto“ (Modell kann wählen) oder „Erforderlich“ (Modell muss einen verwenden) stellen. Das machtdie Sicherheit, Vorhersagbarkeit und schnelle Zwischenspeicherung von „ “ besser, indem es verhindert, dass das Modell versehentlich falsche Tools aufruft, und trotzdem die Flexibilität gibt, die beste Option aus den erlaubten auszuwählen.
Ein komplettes Toolkit hat beides: get_weather als auch send_email, aber wir haben nur get_weather zugelassen und den Modus auf „required” gesetzt, damit das Modell es verwenden muss.
Auf die Frage „Wie ist das Wetter in Oslo?“ antwortete GPT-5 mit einem Funktionsaufruf an get_weather und dem richtigen Argument {„city“: "Oslo"}.
from openai import OpenAI
client = OpenAI()
# Full toolset (N)
tools = [
{
"type": "function",
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
{
"type": "function",
"name": "send_email",
"parameters": {
"type": "object",
"properties": {"to": {"type": "string"}, "body": {"type": "string"}},
"required": ["to", "body"],
},
},
]
# Allowed subset (M < N), mode=required → must call get_weather
resp = client.responses.create(
model="gpt-5",
input="What's the weather in Oslo?",
tools=tools,
tool_choice={
"type": "allowed_tools",
"mode": "required", # use "auto" to let it decide
"tools": [{"type": "function", "name": "get_weather"}],
},
)
for item in resp.output:
if getattr(item, "type", None) in ("function_call", "tool_call", "custom_tool_call"):
print("Tool name:", getattr(item, "name", None))
print("Arguments:", getattr(item, "arguments", None))Ausgabe:
Tool name: get_weather
Arguments: {"city":"Oslo"}Präambeln sind kurze, für den Benutzer sichtbare Erklärungen, die GPT-5 vor dem Aufruf eines Tools generieren kann, um zu erklären, warum dieser Aufruf erfolgt. Das macht alles transparenter, die Leute vertrauen dir mehr und Fehler sind einfacher zu finden, vor allem bei komplizierten Abläufen. Indem du dem Modell einfach sagst, dass es „vor dem Aufruf eines Tools eine Erklärung geben soll“, kannst du die Interaktionenmenschlicher und zielgerichteter wirkenlassen, ohne dass es zu nennenswerten Verzögerungen kommt.
Im folgenden Code haben wir eine Funktion namens „get_weather“ definiert. Diese Funktion ruft die Wetterdaten vom Wetterdienst ab und spe get_weather und eine Systemanweisung hinzugefügt, die dem Modell sagt, dass es vor dem Aufruf des Tools einen kurzen, für den Benutzer sichtbaren Satz mit dem Präfix „Preamble:“ ausgeben soll.
Auf die Frage „Wie ist das Wetter in Oslo?“ hat GPT-5 erst mal eine Einleitung gegeben, dass es einen Live-Wetterdienst checkt, und dann das Tool get_weather mit dem richtigen Argument aufgerufen :{"city": "Oslo"}. Nachdem das Tool lokal ausgeführt wurde und das Ergebnis zurückkam, gab das Modell die endgültige Antwort in natürlicher Sprache.
from openai import OpenAI
client = OpenAI()
def get_weather(city: str):
return {"city": city, "temperature_c": 12}
# Tool
tools = [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for a city.",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
"additionalProperties": False
},
"strict": True,
}]
# Messages (enable preamble via system instruction)
msgs = [
{"role": "system", "content": "Before you call a tool, explain why you are calling it in ONE short sentence prefixed with 'Preamble:'."},
{"role": "user", "content": "What's the weather in Oslo?"}
]
# 1) Model call → expect a visible preamble + a tool call
resp = client.responses.create(model="gpt-5", input=msgs, tools=tools)
print("=== First response objects ===")
for item in resp.output:
t = getattr(item, "type", None)
if t == "message": # preamble is a normal assistant message
print("PREAMBLE:", getattr(item, "content", None))
if t in ("function_call","tool_call","custom_tool_call"):
print("TOOL:", getattr(item, "name", None))
print("ARGS:", getattr(item, "arguments", None))
tool_call = next(x for x in resp.output if getattr(x, "type", None) in ("function_call","tool_call","custom_tool_call"))
msgs += resp.output # keep context
# 2) Execute tool locally (fake)
import json
args = json.loads(getattr(tool_call, "arguments", "{}"))
city = args.get("city", "Unknown")
tool_result = get_weather(city)
# 3) Return tool result
msgs.append({"type": "function_call_output", "call_id": tool_call.call_id, "output": json.dumps(tool_result)})
# 4) Final model call → natural answer
final = client.responses.create(model="gpt-5", input=msgs, tools=tools)
print("\n=== Final answer ===")
print(final.output_text)Wie wir sehen können, hat das Modell zuerst eine kurze Einleitung gegeben, um zu erklären, was es machen will, und dann das Tool get_weather mit {"city": „Oslo“; und hat dann die Temperatur in normaler Sprache zurückgegeben.
=== First response objects ===
PREAMBLE: [ResponseOutputText(annotations=[], text='Preamble: I'm checking a live weather service to get the current conditions for Oslo.', type='output_text', logprobs=[])]
TOOL: get_weather
ARGS: {"city":"Oslo"}
=== Final answer ===
It's currently about 12°C in Oslo.GPT-5 ist so konzipiert, dass es mit gut formulierten Eingabeaufforderungenhervorragende Ergebnisse liefert , und OpenAI stellt einen Prompt-Optimierer, mit dem du sie optimieren kannst. Dieses Tool passt deine Eingabeaufforderungen automatisch an den Denkstil von GPT-5 an und macht so alles genauer und effizienter.
Geh zum „Edit prompt – OpenAI API“ und gib eine einfache Eingabe ein, z. B. „Erstelle eine Netflix-Klon-Webanwendung”. Es zerlegt deine Eingabeaufforderung in eine detaillierte Struktur, die für das GPT-5-Modell optimiert ist.
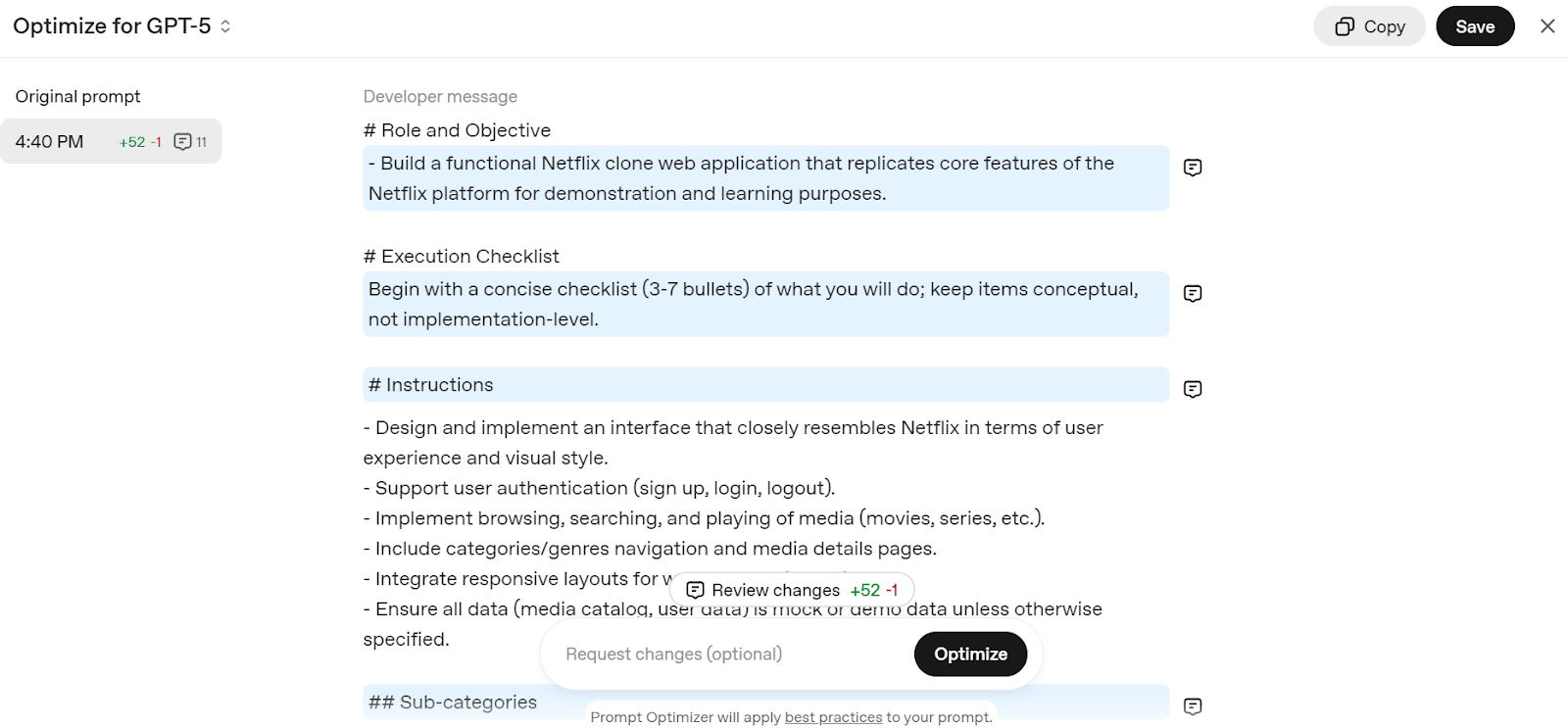
Quelle: Optimierer für Eingabeaufforderungen
Kopiere einfach die Eingabeaufforderung und füge sie zum ChatGPT-Chat hinzu, um mit der Erstellung deines eigenen Netflix-Webdienstes zu beginnen.
OpenAI rät Entwicklern dringend, von älteren Modellen auf die neue GPT-5-Familie umzusteigen, um Kosten zu sparen, die Genauigkeit zu verbessern und die Antwortqualität zu steigern.
Die Migration ist ganz einfach: Wähle einfach anhand der Tabelle unten das richtige GPT-5-Modell und die richtige Schlussfolgerungsstufe für deinen Anwendungsfall aus.
|
Aktuelles Modell |
Empfohlenes GPT-5-Modell |
Startstufe für logisches Denken |
Migrationshinweise |
|
o3 |
GPT-5 |
Mittel |
Fang mit mittlerer Argumentation + schneller Anpassung an und steigere bei Bedarf auf hoch. |
|
gpt-4.1 |
GPT-5 |
Minimal |
Fang mit minimaler Argumentation + schneller Anpassung an und steigere auf „niedrig“, um die Leistung zu verbessern. |
|
o4-mini |
GPT-5-Mini |
Mittel |
GPT-5-mini mit Prompt-Tuning verwenden. |
|
gpt-4.1-mini |
GPT-5-Mini |
Minimal |
GPT-5-mini mit Prompt-Tuning verwenden. |
|
gpt-4.1-nano |
GPT-5-nano |
Minimal |
GPT-5-nano mit Prompt-Tuning verwenden. |
GPT-5 ist mehr als nur ein smarteres Modell; es ist ein Toolkit für Entwickler zum Aufbau intelligenter, zuverlässiger und effizienter KI-Systeme. Dank der genauen Kontrolle über die Argumentation, die Ausführlichkeit, die Verwendung von Tools und die Ausgabeformate passt es sich an alles an, von schnellen Programmieraufgaben bis hin zu komplexen mehrstufigen Arbeitsabläufen.
Mit den neuen Funktionen und Best Practices kannst du mit dem OpenAI SDK ganz einfach produktionsreife KI-Anwendungen entwickeln.
Wenn du noch keine Erfahrung mit OpenAI hast, schau dir unbedingt die folgenden Ressourcen an:
Die besten OpenAI-Kurse
Kurs
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
Adel Nehme
Tutorial
Sejal Jaiswal
