Curso
Manipulando dados de séries temporais em Python
4 h
71.6K
No mundo da análise de dados, Python é uma linguagem popular devido à sua versatilidade e ao amplo ecossistema de bibliotecas. A manipulação e a análise de dados desempenham um papel fundamental na extração de insights e na tomada de decisões informadas. No entanto, como os conjuntos de dados continuam a crescer em tamanho e complexidade, a necessidade de soluções de alto desempenho torna-se fundamental.
O manuseio eficiente de grandes conjuntos de dados requer ferramentas que possam fornecer cálculos rápidos e operações otimizadas. É nesse ponto que a Polars entra em cena. O Polars é uma biblioteca de código aberto avançada, projetada especificamente para manipulação e análise de dados de alto desempenho em Python.
Polars é uma biblioteca DataFrame totalmente escrita em Rust e foi criada para capacitar os desenvolvedores Python com uma estrutura escalonável e eficiente para lidar com dados e é considerada uma alternativa à popular biblioteca pandas. Ele oferece uma ampla gama de funcionalidades que facilitam várias tarefas de manipulação e análise de dados. Alguns dos principais recursos e vantagens do uso do Polars incluem:
O Polars foi projetado com o desempenho em mente. Ele aproveita o processamento paralelo e as técnicas de otimização de memória, o que lhe permite processar grandes conjuntos de dados de forma significativamente mais rápida do que os métodos tradicionais.
O Polars oferece um kit de ferramentas abrangente para a manipulação de dados, incluindo operações essenciais como filtragem, classificação, agrupamento, união e agregação de dados. Embora o Polars possa não ter a mesma funcionalidade extensiva do pandas devido à sua relativa novidade, ele abrange aproximadamente 80% das operações comuns encontradas no Pandas.
O Polars emprega uma sintaxe concisa e intuitiva, o que o torna fácil de aprender e usar. Sua sintaxe lembra as bibliotecas populares do Python, como a pandas, permitindo que os usuários se adaptem rapidamente ao Polars e aproveitem o conhecimento que já possuem.
No núcleo do Polars estão as estruturas DataFrame e Series, que fornecem uma abstração familiar e poderosa para trabalhar com dados tabulares. As operações de DataFrame no Polars podem ser encadeadas, permitindo transformações de dados eficientes e concisas.
O Polars incorpora a avaliação preguiçosa, que envolve o exame e a otimização de consultas para melhorar seu desempenho e minimizar o consumo de memória. Ao trabalhar com Polars, a biblioteca analisa suas consultas e busca oportunidades para agilizar sua execução ou reduzir o uso da memória. Por outro lado, o Pandas suporta apenas a avaliação ansiosa, em que as expressões são avaliadas imediatamente ao encontrá-las.
A pandas, uma biblioteca amplamente adotada, é conhecida por sua flexibilidade e facilidade de uso. No entanto, ao lidar com grandes conjuntos de dados, o Pandas pode sofrer gargalos de desempenho devido à sua dependência da execução de um único thread. À medida que o tamanho do conjunto de dados aumenta, o tempo de processamento pode se tornar proibitivamente longo, limitando a produtividade.
O Polars foi projetado especificamente para lidar com grandes conjuntos de dados de forma eficiente. Com sua estratégia de avaliação preguiçosa e recursos de execução paralela, o Polars se destaca no processamento rápido de quantidades substanciais de dados. Ao distribuir os cálculos em vários núcleos de CPU, o Polars aproveita o paralelismo para proporcionar ganhos de desempenho impressionantes. Veja o teste de comparação de velocidade entre Pandas e Polars feito por Yuki.
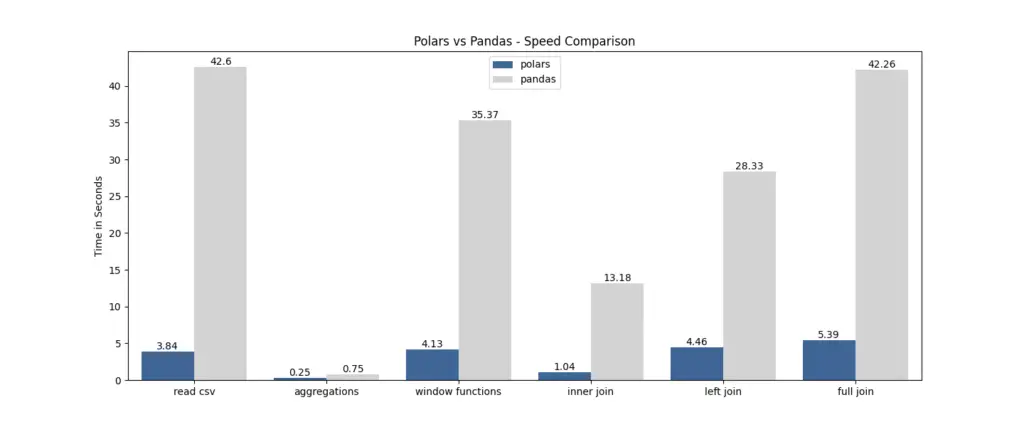
Para uma comparação completa entre polares e pandas, confira nosso artigo separado.
O Polars pode ser instalado por meio do pip, o gerenciador de pacotes Python. Abra sua interface de linha de comando e execute o seguinte comando:
install polars
O Polars fornece métodos convenientes para carregar dados de várias fontes, incluindo arquivos CSV, arquivos Parquet e Pandas DataFrames. Os métodos para ler arquivos CSV ou parquet são os mesmos da biblioteca pandas.
# read csv file
import polars as pl
data = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# check the head
data.head()
Saída:
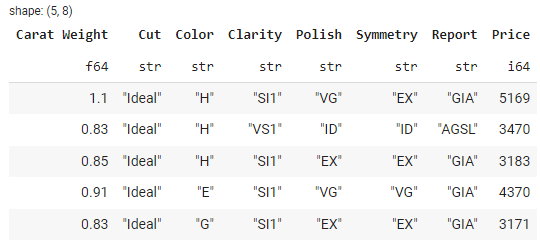
O tipo de data é polars.DataFrame.
type(data)
>>> polars.dataframe.frame.DataFrame
Saída:
O Polars oferece um conjunto abrangente de funcionalidades para manipulação de dados, permitindo que você selecione, filtre, classifique, transforme e limpe seus dados com facilidade. Vamos explorar algumas tarefas comuns de manipulação de dados e como realizá-las usando o Polars:
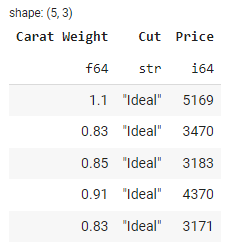
Para selecionar colunas específicas de um DataFrame, você pode usar o método select(). Veja um exemplo:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# Select specific columns: carat, cut, and price
selected_df = df.select(['Carat Weight', 'Cut', 'Price'])
# show selected_df head
selected_df.head()
Saída:
A filtragem de linhas com base em determinadas condições pode ser feita usando o método filter(). Por exemplo, para filtrar as linhas em que o quilate é maior que 1,0, você pode fazer o seguinte:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# filter the df with condition
filtered_df = df.filter(pl.col('Carat Weight') > 2.0)
# show filtered_df head
filtered_df.head()
Saída:
O Polars fornece o método sort() para classificar um DataFrame com base em uma ou mais colunas. Veja um exemplo:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# sort the df by price
sorted_df = df.sort(by='Price')
# show sorted_df head
sorted_df.head()
Saída:
O Polars oferece métodos convenientes para lidar com valores ausentes. O método drop_nulls() permite que você elimine as linhas que contêm valores ausentes:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# drop missing values
cleaned_df = df.drop_nulls()
# show cleaned_df head
cleaned_df.head()
Saída:
Como alternativa, você pode usar o método fill_nulls() para substituir os valores ausentes por um valor padrão especificado ou um método de preenchimento.
Para agrupar dados com base em colunas específicas, você pode usar o método groupby(). Aqui está um exemplo que agrupa os dados pela coluna Cut e calcula a média de Price para cada grupo:
import polars as pl
# Load diamond data from a CSV file
df = pl.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# group by cut and calc mean of price
grouped_df = df.groupby(by='Cut').agg(pl.col('Price').mean())
# show grouped_df head
grouped_df.head()
Saída:
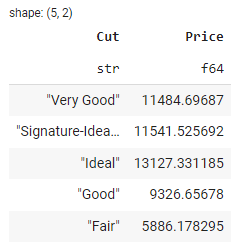
No resultado acima, você pode ver o preço médio dos diamantes por Cut dimensão.
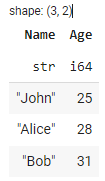
O Polars oferece opções flexíveis para unir e combinar DataFrames, permitindo que você mescle e concatene dados de diferentes fontes. Para executar uma operação de união, você pode usar o método join(). Aqui está um exemplo que demonstra uma união interna entre dois DataFrames com base em uma coluna de chave comum:
import polars as pl
# Create the first DataFrame
df1 = pl.DataFrame({
'id': [1, 2, 3, 4],
'name': ['Alice', 'Bob', 'Charlie', 'David']
})
# Create the second DataFrame
df2 = pl.DataFrame({
'id': [2, 3, 5],
'age': [25, 30, 35]
})
# Perform an inner join on the 'id' column
joined_df = df1.join(df2, on='id')
# Display the joined DataFrame
joined_df
Saída:

Neste exemplo, criamos dois DataFrames (df1 e df2) usando o construtor pl.DataFrame. O primeiro DataFrame df1 contém as colunas id e name, e o segundo DataFrame df2 contém as colunas id e age. Em seguida, realizamos uma união interna na coluna id usando o método join(), especificando a coluna id como a chave de união.
O Polars oferece integração perfeita com outras bibliotecas Python populares, permitindo que os analistas de dados aproveitem uma ampla gama de ferramentas e funcionalidades. Vamos explorar dois aspectos fundamentais da integração: trabalhar com outras bibliotecas e a interoperabilidade com o Pandas.
O Polars se integra de forma conveniente a bibliotecas como NumPy e PyArrow, permitindo que os usuários combinem os pontos fortes de várias ferramentas em seus fluxos de trabalho de análise de dados. Com a integração do NumPy, o Polars converte sem esforço entre os DataFrames do Polars e as matrizes do NumPy, aproveitando os poderosos recursos de computação científica do NumPy. Essa integração garante transições de dados suaves e permite que os analistas apliquem diretamente as funções do NumPy aos dados do Polars.
Da mesma forma, ao aproveitar o PyArrow, o Polars otimiza a transferência de dados entre o Polars e os sistemas baseados no Arrow. Essa integração permite o trabalho contínuo com dados armazenados no formato Arrow e aproveita os recursos de manipulação de dados de alto desempenho do Polars.
O Polars oferece uma conversão perfeita de Polars DataFrames para Pandas DataFrames. Aqui está um exemplo que ilustra a conversão de polares para pandas.
import polars as pl
import pandas as pd
# Create a Polars DataFrame
df_polars = pl.DataFrame({
'column_A': [1, 2, 3],
'column_B': ['apple', 'banana', 'orange']
})
# Convert Polars DataFrame to Pandas DataFrame
df_pandas = df_polars.to_pandas()
# Display the Pandas DataFrame
df_pandas
Saída:
O Polars é uma biblioteca avançada para manipulação e análise de dados de alto desempenho em Python. Suas otimizações de velocidade e desempenho fazem dele a opção ideal para lidar com grandes conjuntos de dados de forma eficiente.
Com sua sintaxe expressiva e estruturas DataFrame, o Polars oferece uma interface familiar e intuitiva para tarefas de manipulação de dados. Além disso, o Polars se integra perfeitamente a outras bibliotecas Python, como NumPy e PyArrow, expandindo seus recursos e permitindo que os usuários aproveitem um ecossistema diversificado de ferramentas.
A capacidade de converter Polars DataFrames em pandas DataFrames garante a interoperabilidade e facilita a integração do Polars aos fluxos de trabalho existentes. Quer esteja trabalhando com tipos de dados complexos, lidando com grandes conjuntos de dados ou buscando aprimoramentos de desempenho, o Polars oferece um kit de ferramentas abrangente para liberar todo o potencial de seus esforços de análise de dados.
Principais cursos de manipulação de dados em Python
Curso
Curso
Tutorial
Karlijn Willems
Tutorial
Abid Ali Awan
Tutorial
Satyam Tripathi
Tutorial
Kevin Babitz


