Curso
Importação Intermediária de Dados em Python
2 h
210.9K

O Pandas é um pacote Python popular para ciência de dados, e por um bom motivo: ele oferece estruturas de dados poderosas, expressivas e flexíveis que facilitam a manipulação e a análise de dados, entre muitas outras coisas. O DataFrame é uma dessas estruturas.
Este tutorial aborda os DataFrames do pandas, desde as manipulações básicas até as operações avançadas, abordando 11 das perguntas mais populares para que você entenda - e evite - as dúvidas dos pitonistas que o precederam.
Para praticar mais, experimente o primeiro capítulo do curso Pandas DataFrames gratuitamente!
Antes de começar, vamos fazer uma breve recapitulação do que são DataFrames.
Aqueles que estão familiarizados com o R conhecem o quadro de dados como uma forma de armazenar dados em grades retangulares que podem ser facilmente visualizadas. Cada linha dessas grades corresponde a medições ou valores de uma instância, enquanto cada coluna é um vetor que contém dados para uma variável específica. Isso significa que as linhas de um quadro de dados não precisam conter, mas podem conter, o mesmo tipo de valores: eles podem ser numéricos, caracteres, lógicos etc.
Agora, os DataFrames em Python são muito semelhantes: eles vêm com a biblioteca pandas e são definidos como estruturas de dados rotuladas bidimensionais com colunas de tipos potencialmente diferentes.
Em geral, pode-se dizer que o DataFrame do pandas consiste em três componentes principais: os dados, o índice e as colunas.
DataFrameSeries: uma matriz rotulada unidimensional capaz de conter qualquer tipo de dados com rótulos de eixo ou índice. Um exemplo de um objeto Series é uma coluna de um DataFrame.ndarray, que pode ser um registro ou uma estruturandarrayndarray's, listas, dicionários ou séries.Observe a diferença entre np.ndarray e np.array(). O primeiro é um tipo de dados real, enquanto o segundo é uma função para criar matrizes a partir de outras estruturas de dados.
As matrizes estruturadas permitem que os usuários manipulem os dados por campos nomeados: no exemplo abaixo, é criada uma matriz estruturada de três tuplas. O primeiro elemento de cada tupla será chamado foo e será do tipo int, enquanto o segundo elemento será chamado bar e será um float.
As matrizes de registro, por outro lado, expandem as propriedades das matrizes estruturadas. Eles permitem que os usuários acessem campos de matrizes estruturadas por atributo em vez de por índice. Veja abaixo que os valores de foo são acessados na matriz de registros r2.
Um exemplo:
import pandas as pd
import numpy as np
# A structured array
my_array = np.ones(3, dtype=([('foo', int), ('bar', float)]))
# Print the structured array
print(my_array['foo'])
# A record array
my_array2 = my_array.view(np.recarray)
# Print the record array
print(my_array2.foo)[1 1 1]
[1 1 1]Se você ainda tiver dúvidas sobre os DataFrames do Pandas e como eles diferem de outras estruturas de dados, como uma matriz NumPy ou uma série, assista à pequena apresentação abaixo:
Observe que, nesta postagem, na maioria das vezes, as bibliotecas de que você precisa já foram carregadas. A biblioteca Pandas geralmente é importada com o alias pd, enquanto a biblioteca NumPy é carregada como np. Lembre-se de que, ao codificar em seu próprio ambiente de ciência de dados, você não deve se esquecer dessa etapa de importação, que deve ser escrita da seguinte forma:
import numpy as np
import pandas as pdAgora que você não tem mais dúvidas sobre o que são DataFrames, o que eles podem fazer e como eles diferem de outras estruturas, é hora de abordar as perguntas mais comuns que os usuários têm sobre como trabalhar com eles!
Execute e edite o código deste tutorial online
Executar códigoObviamente, criar seus DataFrames é o primeiro passo em quase tudo o que você deseja fazer quando se trata de processamento de dados em Python. Às vezes, você desejará começar do zero, mas também pode converter outras estruturas de dados, como listas ou matrizes NumPy, em Pandas DataFrames. Nesta seção, você abordará apenas o último. No entanto, se quiser saber mais sobre como criar DataFrames vazios que podem ser preenchidos com dados posteriormente, vá para a seção 7.
Entre as muitas coisas que podem servir de entrada para criar um 'DataFrame', um NumPy ndarray é uma delas. Para criar um quadro de dados a partir de uma matriz NumPy, basta passá-la para a função DataFrame() no argumento data.
data = np.array([['','Col1','Col2'],
['Row1',1,2],
['Row2',3,4]])
print(pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:]))
Col1 Col2
Row1 1 2
Row2 3 4
Preste atenção em como os trechos de código acima selecionam elementos da matriz NumPy para construir o DataFrame: primeiro, você seleciona os valores contidos nas listas que começam com Row1 e Row2, depois seleciona os números de índice ou de linha Row1 e Row2 e, em seguida, os nomes das colunas Col1 e Col2.
Em seguida, você também vê que, no exemplo acima, imprimimos uma pequena seleção dos dados. Isso funciona da mesma forma que o subconjunto de matrizes 2D NumPy: primeiro você indica a linha em que deseja procurar os dados e, em seguida, a coluna. Não se esqueça de que os índices começam em 0! Para data, no exemplo acima, você procura nas linhas do índice 1 até o final e seleciona todos os elementos que vêm depois do índice 1. Como resultado, você acaba selecionando 1, 2, 3 e 4.
Essa abordagem para criar DataFrames será a mesma para todas as estruturas que o DataFrame() pode receber como entrada.
Veja o exemplo abaixo:
Lembre-se de que a biblioteca do Pandas já foi importada como pd.
# Take a 2D array as input to your DataFrame
my_2darray = np.array([[1, 2, 3], [4, 5, 6]])
print(pd.DataFrame(my_2darray))
# Take a dictionary as input to your DataFrame
my_dict = {1: ['1', '3'], 2: ['1', '2'], 3: ['2', '4']}
print(pd.DataFrame(my_dict))
# Take a DataFrame as input to your DataFrame
my_df = pd.DataFrame(data=[4,5,6,7], index=range(0,4), columns=['A'])
print(pd.DataFrame(my_df))
# Take a Series as input to your DataFrame
my_series = pd.Series({"Belgium":"Brussels", "India":"New Delhi", "United Kingdom":"London", "United States":"Washington"})
print(pd.DataFrame(my_series))0 1 2
0 1 2 3
1 4 5 6
1 2 3
0 1 1 2
1 3 2 4
A
0 4
1 5Observe que o índice de sua série (e DataFrame) contém as chaves do dicionário original, mas que elas estão classificadas: A Bélgica será o índice em 0, enquanto os Estados Unidos serão o índice em 3.
Depois de criar o DataFrame, talvez você queira saber um pouco mais sobre ele. Você pode usar a propriedade shape ou a função len() em combinação com a propriedade .index:
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
# Use the `shape` property
print(df.shape)
# Or use the `len()` function with the `index` property
print(len(df))(2, 3)
2Essas duas opções fornecem informações ligeiramente diferentes sobre o DataFrame: a propriedade shape fornecerá as dimensões do DataFrame. Isso significa que você saberá a largura e a altura do seu DataFrame. Por outro lado, a função len(), em combinação com a propriedade index, só fornecerá informações sobre a altura do DataFrame.
No entanto, tudo isso não é nada extraordinário, como você explicitamente informa na propriedade index.
Você também poderia usar df[0].count() para saber mais sobre a altura do DataFrame, mas isso excluirá os valores de NaN (se houver algum). É por isso que chamar .count() em seu DataFrame nem sempre é a melhor opção.
Se quiser obter mais informações sobre as colunas do DataFrame, você sempre poderá executar list(my_dataframe.columns.values).
Agora que você colocou seus dados em uma estrutura Pandas DataFrame mais conveniente, é hora de começar a trabalhar de verdade!
Esta primeira seção o guiará pelas primeiras etapas do trabalho com DataFrames em Python. Ele abordará as operações básicas que você pode realizar no DataFrame recém-criado: adicionar, selecionar, excluir, renomear e muito mais.
Antes de começar a adicionar, excluir e renomear os componentes do DataFrame, primeiro você precisa saber como selecionar esses elementos. Então, como você faz isso?
Mesmo que você ainda se lembre de como fazer isso na seção anterior: selecionar um índice, uma coluna ou um valor do DataFrame não é tão difícil, muito pelo contrário. É semelhante ao que você vê em outras linguagens (ou pacotes!) que são usadas para análise de dados. Se você não estiver convencido, considere o seguinte:
No R, você usa a notação [,] para acessar os valores do quadro de dados.
Agora, digamos que você tenha um DataFrame como este:
A B C
0 1 2 3
1 4 5 6
2 7 8 9E você deseja acessar o valor que está no índice 0, na coluna 'A'.
Existem várias opções para recuperar seu valor 1:
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
print(df) A B C
0 1 2 3
1 4 5 6
2 7 8 9# Using `iloc[]`
print(df.iloc[0][0])
# Using `loc[]`
print(df.loc[0]['A'])
# Using `at[]`
print(df.at[0,'A'])
# Using `iat[]`
print(df.iat[0,0])1
1
1
1Os mais importantes a serem lembrados são, sem dúvida, .loc[] e .iloc[]. As diferenças sutis entre esses dois serão discutidas nas próximas seções.
Por enquanto, chega de selecionar valores de seu DataFrame. E quanto à seleção de linhas e colunas? Nesse caso, você usaria:
# Use `iloc[]` to select row `0`
print(df.iloc[0])
# Use `loc[]` to select column `'A'`
print(df.loc[:,'A'])A 1
B 2
C 3
Name: 0, dtype: int64
0 1
1 4
2 7
Name: A, dtype: int64Por enquanto, basta saber que você pode acessar os valores chamando-os pelo rótulo ou pela posição no índice ou na coluna. Se você não perceber isso, observe novamente as pequenas diferenças nos comandos: uma vez, você vê [0][0], outra vez, você vê [0,'A'] para recuperar seu valor 1.
Agora que você aprendeu a selecionar um valor em um DataFrame, é hora de começar a trabalhar de verdade e adicionar um índice, uma linha ou uma coluna a ele!
Ao criar um DataFrame, você tem a opção de adicionar entradas ao argumento "index" para garantir que você tenha o índice desejado. Se você não especificar isso, seu DataFrame terá, por padrão, um índice com valor numérico que começa com 0 e continua até a última linha do DataFrame.
No entanto, mesmo quando o índice é especificado automaticamente, você ainda pode reutilizar uma de suas colunas e torná-la seu índice. Você pode fazer isso facilmente chamando set_index() em seu DataFrame. Experimente isso abaixo!
# Print out your DataFrame `df` to check it out
print(df)
# Set 'C' as the index of your DataFrame
df.set_index('C') A B C
0 1 2 3
1 4 5 6
2 7 8 9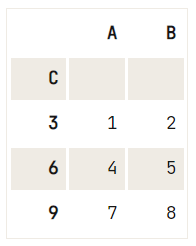
Antes de chegar à solução, é bom entender o conceito de loc e como ele difere de outros atributos de indexação, como .iloc[] e .ix[]:
Tudo isso pode parecer muito complicado. Vamos ilustrar tudo isso com um pequeno exemplo:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2, 'A', 4], columns=[48, 49, 50])
# Pass `2` to `loc`
print(df.loc[2])
# Pass `2` to `iloc`
print(df.iloc[2])48 1
49 2
50 3
Name: 2, dtype: int64
48 7
49 8
50 9
Name: 4, dtype: int64Observe que, nesse caso, você usou um exemplo de DataFrame que não é baseado apenas em números inteiros para facilitar a compreensão das diferenças. Você pode ver claramente que passar 2 para .loc[] ou .iloc[]/.ix[] não dá o mesmo resultado!
48 1
49 2
50 3.iloc[] examinará as posições no índice. Quando você passar pelo site 2, você receberá o retorno:48 7
49 8
50 9.ix[] terá o mesmo comportamento que o site iloc e examinará as posições no índice. Você obterá o mesmo resultado de .iloc[].Agora que a diferença entre .iloc[], .loc[] e .ix[] está clara, você está pronto para tentar adicionar linhas ao seu DataFrame!
Dica: como consequência do que acabou de ler, agora você também entende que a recomendação geral é usar o site .loc para inserir linhas no DataFrame. Isso ocorre porque, se você usasse df.ix[], poderia tentar fazer referência a um índice de valor numérico com o valor do índice e acidentalmente sobrescrever uma linha existente do DataFrame. Você deve evitar isso!
Confira a diferença mais uma vez no DataFrame abaixo:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2.5, 12.6, 4.8], columns=[48, 49, 50])
# This will make an index labeled `2` and add the new values
df.loc[2] = [11, 12, 13]
print(df) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
2.0 11 12 13Você pode ver por que tudo isso pode ser confuso, certo?
Em alguns casos, você deseja que o índice faça parte do DataFrame. Você pode fazer isso facilmente pegando uma coluna do seu DataFrame ou fazendo referência a uma coluna que ainda não foi criada e atribuindo-a à propriedade .index, da seguinte forma:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Use `.index`
df['D'] = df.index
# Print `df`
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2Em outras palavras, você diz ao seu DataFrame que ele deve usar a coluna A como seu índice.
No entanto, se quiser acrescentar colunas ao DataFrame, você também pode seguir a mesma abordagem de quando adiciona um índice ao DataFrame: use .loc[] ou .iloc[]. Nesse caso, você adiciona uma série a um DataFrame existente com a ajuda do site .loc[]:
# Study the DataFrame `df`
print(df)
# Append a column to `df`
df.loc[:, 4] = pd.Series(['5', '6', '7'], index=df.index)
# Print out `df` again to see the changes
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Lembre-se de que um objeto Series é muito parecido com uma coluna de um DataFrame. Isso explica por que você pode adicionar facilmente uma série a um DataFrame existente. Observe também que a observação feita anteriormente sobre .loc[] continua válida, mesmo quando você está adicionando colunas ao seu DataFrame!
Quando o índice não tiver a aparência que você deseja, você pode optar por redefini-lo. Você pode fazer isso facilmente com o site .reset_index(). No entanto, você ainda deve ficar atento, pois pode passar vários argumentos que podem aumentar ou diminuir o sucesso de sua redefinição:
# Check out the weird index of your dataframe
print(df)
# Use `reset_index()` to reset the values.
df_reset = df.reset_index(level=0, drop=True)
# Print `df_reset`
print(df_reset) A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Você pode tentar substituir o argumento drop por inplace no exemplo acima e ver o que acontece!
Observe como você usa o argumento drop para indicar que deseja se livrar do índice que estava lá. Se você tivesse usado inplace, o índice original com floats seria adicionado como uma coluna extra ao seu DataFrame.
Agora que você já viu como selecionar e adicionar índices, linhas e colunas ao seu DataFrame, é hora de considerar outro caso de uso: remover esses três elementos da sua estrutura de dados.
Se você quiser remover o índice do seu DataFrame, deve reconsiderar, pois os DataFrames e as Series sempre têm um índice.
No entanto, o que você *pode* fazer é, por exemplo:
del df.index.name,df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
df.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')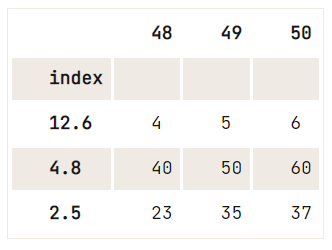
Agora que você já sabe como remover um índice do DataFrame, pode prosseguir com a remoção de colunas e linhas!
Para se livrar de (uma seleção de) colunas do seu DataFrame, você pode usar o método drop():
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out the DataFrame `df`
print(df)
# Drop the column with label 'A'
df.drop('A', axis=1, inplace=True)
# Drop the column at position 1
df.drop(df.columns[[1]], axis=1) A B C
0 1 2 3
1 4 5 6
2 7 8 9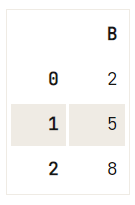
Você pode pensar agora: bem, isso não é tão simples; há alguns argumentos extras que são passados para o método drop()!
axis é 0 quando indica linhas e 1 quando é usado para eliminar colunas.inplace como True para excluir a coluna sem precisar reatribuir o DataFrame.Você pode remover linhas duplicadas de seu DataFrame executando df.drop_duplicates(). Também é possível remover linhas do DataFrame, levando em conta apenas os valores duplicados que existem em uma coluna.
Dê uma olhada neste exemplo:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
# Check out your DataFrame `df`
print(df)
# Drop the duplicates in `df`
df.drop_duplicates([48], keep='last') 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37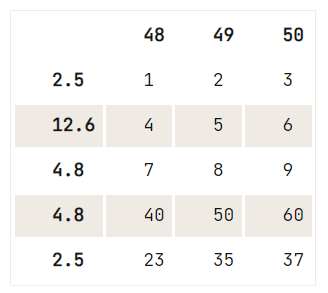
Se não houver um critério de exclusividade para a exclusão que deseja realizar, você pode usar o método drop(), no qual usa a propriedade index para especificar o índice das linhas que deseja remover do DataFrame:
# Check out the DataFrame `df`
print(df)
# Drop the index at position 1
df.drop(df.index[1]) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37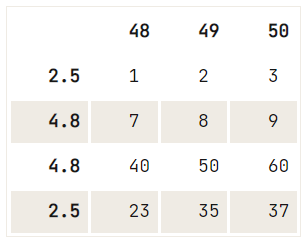
Após esse comando, talvez você queira redefinir o índice novamente.
Dica: tente redefinir o índice do DataFrame resultante por conta própria! Não se esqueça de usar o argumento drop se achar necessário.
Para dar às colunas ou aos valores de índice do seu dataframe um valor diferente, é melhor usar o método .rename().
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out your DataFrame `df`
print(df)
# Define the new names of your columns
newcols = {
'A': 'new_column_1',
'B': 'new_column_2',
'C': 'new_column_3'
}
# Use `rename()` to rename your columns
df.rename(columns=newcols, inplace=True)
# Rename your index
df.rename(index={1: 'a'}) A B C
0 1 2 3
1 4 5 6
2 7 8 9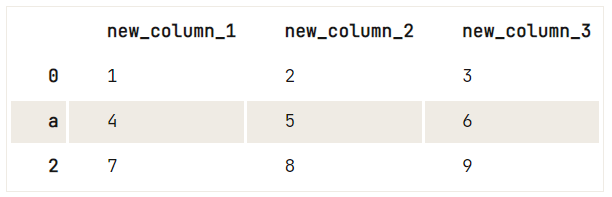
Dica: tente alterar o argumento inplace na primeira tarefa (renomeando suas colunas) para False e veja o que o script agora renderiza como resultado. Você vê que agora o DataFrame não foi reatribuído ao renomear as colunas. Como resultado, a segunda tarefa usa o DataFrame original como entrada e não aquele que você acabou de receber da primeira operação rename().
Agora que você já passou por um primeiro conjunto de perguntas sobre os DataFrames do Pandas, é hora de ir além do básico e colocar a mão na massa de verdade, pois há muito mais nos DataFrames do que você viu na primeira seção.
Na maioria das vezes, você também desejará poder realizar algumas operações nos valores reais contidos no DataFrame. Nas seções a seguir, você abordará várias maneiras de formatar os valores do DataFrame do pandas
Para substituir determinadas cadeias de caracteres em seu DataFrame, você pode usar facilmente o site replace(): passe os valores que deseja alterar, seguidos dos valores pelos quais deseja substituí-los.
Assim mesmo:
df = pd.DataFrame({"Student1":['OK','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
# Study the DataFrame `df` first
print(df)
# Replace the strings by numerical values (0-4)
df.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'], [0, 1, 2, 3, 4]) Student1 Student2 Student3
0 OK Perfect Acceptable
1 Awful Awful Perfect
2 Acceptable OK Poor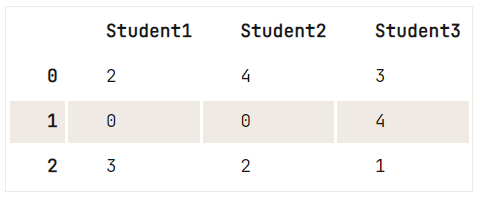
Observe que há também um argumento regex que pode ajudá-lo muito quando você se depara com combinações estranhas de strings:
df = pd.DataFrame([["1\n", 2, "3\n"], [4, 5, "6\n"] ,[7, "8\n", 9]])
# Check out your DataFrame `df`
print(df)
# Replace strings by others with `regex`
df.replace({'\n': ''}, regex=True) 0 1 2
0 1\n 2 3\n
1 4 5 6\n
2 7 8\n 9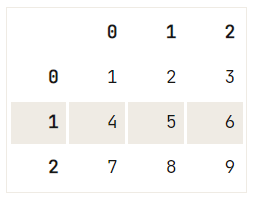
Resumindo, replace() é o que você precisa fazer quando quiser substituir valores ou cadeias de caracteres em seu DataFrame por outros!
A remoção de partes indesejadas das cordas é um trabalho complicado. Felizmente, há uma solução fácil para esse problema!
df = pd.DataFrame([["+-1aAbBcC", "2", "+-3aAbBcC"], ["4", "5", "+-6aAbBcC"] ,["7", "+-8aAbBcC", "9"]])
# Check out your DataFrame
print(df)
# Delete unwanted parts from the strings in the first column
df[0] = df[0].map(lambda x: x.lstrip('+-').rstrip('aAbBcC'))
# Check out the result again
df 0 1 2
0 +-1aAbBcC 2 +-3aAbBcC
1 4 5 +-6aAbBcC
2 7 +-8aAbBcC 9
Você usa map() na coluna result para aplicar a função lambda em cada elemento ou em todos os elementos da coluna. A função em si pega o valor da cadeia de caracteres e remove o + ou - que está localizado à esquerda e também remove qualquer um dos seis aAbBcC à direita.
Essa é uma tarefa de formatação um pouco mais difícil. No entanto, o próximo trecho de código o guiará pelas etapas:
df = pd.DataFrame({"Age": [34, 22, 19],
"PlusOne":[0,0,1],
"Ticket":["23:44:55", "66:77:88", "43:68:05 56:34:12"]})
# Inspect your DataFrame `df`
print(df)
# Split out the two values in the third row
# Make it a Series
# Stack the values
ticket_series = df['Ticket'].str.split(' ').apply(pd.Series, 1).stack()
# Get rid of the stack:
# Drop the level to line up with the DataFrame
ticket_series.index = ticket_series.index.droplevel(-1)
print(ticket_series) Age PlusOne Ticket
0 34 0 23:44:55
1 22 0 66:77:88
2 19 1 43:68:05 56:34:12
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: object
0
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12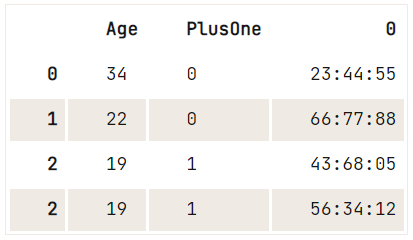
Em resumo, o que você faz é:
Ticket do DataFrame df e a encadeia em um espaço. Isso garantirá que os dois tíquetes fiquem em duas filas separadas no final. Em seguida, você pega esses quatro valores (os quatro números de tíquetes) e os coloca em um objeto Series: 0 1
0 23:44:55 NaN
1 66:77:88 NaN
2 43:68:05 56:34:12NaN values in there! Você precisa empilhar a série para garantir que não haja nenhum valor NaN na série resultante.0 0 23:44:55
1 0 66:77:88
2 0 43:68:05
1 56:34:120 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: objectTicket original.Talvez você queira ajustar os dados em seu DataFrame aplicando uma função a ele. Vamos começar a responder a essa pergunta criando sua própria função lambda:
doubler = lambda x: x*2Dica: se você quiser saber mais sobre funções em Python, considere fazer este tutorial sobre funções em Python.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Study the `df` DataFrame
print(df)
# Apply the `doubler` function to the `A` DataFrame column
df['A'].apply(doubler)
A B C
0 1 2 3
1 4 5 6
2 7 8 9
0 2
1 8
2 14
Name: A, dtype: int64Observe que você também pode selecionar a linha do DataFrame e aplicar a função lambda doubler a ela. Lembre-se de que você pode selecionar facilmente uma linha de seu DataFrame usando .loc[] ou .iloc[].
Em seguida, você executaria algo parecido com isso, dependendo se deseja selecionar o índice com base na posição ou no rótulo:
df.loc[0].apply(doubler)Observe que a função apply() só aplica a função doubler ao longo do eixo do DataFrame. Isso significa que você tem como alvo o índice ou as colunas. Ou, em outras palavras, uma linha ou uma coluna.
No entanto, se quiser aplicá-la a cada elemento ou a cada elemento, você pode usar a função map(). Você pode simplesmente substituir a função apply() no trecho de código acima por map(). Não se esqueça de passar a função doubler para ele para garantir que você multiplique os valores por 2.
Digamos que você queira aplicar essa função de duplicação não apenas à coluna A do DataFrame, mas a todo o DataFrame. Nesse caso, você pode usar applymap() para aplicar a função doubler a cada elemento do DataFrame inteiro:
doubled_df = df.applymap(doubler)
print(doubled_df) A B C
0 2 4 6
1 8 10 12
2 14 16 18Observe que, nesses casos, trabalhamos com funções lambda ou funções anônimas que são criadas em tempo de execução. No entanto, você também pode escrever sua própria função. Por exemplo:
def doubler(x):
if x % 2 == 0:
return x
else:
return x * 2
# Use `applymap()` to apply `doubler()` to your DataFrame
doubled_df = df.applymap(doubler)
# Check the DataFrame
print(doubled_df) A B C
0 2 2 6
1 4 10 6
2 14 8 18Se você quiser obter mais informações sobre o fluxo de controle em Pythonpode sempre dar uma olhada em nossos outros recursos.
A função que você usará é a função Pandas Dataframe(): ela exige que você passe os dados que deseja inserir, os índices e as colunas.
Lembre-se de que os dados contidos no quadro de dados não precisam ser homogêneos. Ele pode ser de diferentes tipos de dados!
Há várias maneiras de usar essa função para criar um DataFrame vazio. Em primeiro lugar, você pode usar numpy.nan para inicializar seu quadro de dados com NaNs. Observe que numpy.nan tem o tipo float.
df = pd.DataFrame(np.nan, index=[0,1,2,3], columns=['A'])
print(df) A
0 NaN
1 NaN
2 NaN
3 NaNNo momento, o tipo de dados do quadro de dados é inferido por padrão: como numpy.nan tem o tipo float, o quadro de dados também conterá valores do tipo float. No entanto, você também pode forçar o DataFrame a ser de um tipo específico, adicionando o atributo dtype e preenchendo o tipo desejado. Como neste exemplo:
df = pd.DataFrame(index=range(0,4),columns=['A'], dtype='float')
print(df)
A
0 NaN
1 NaN
2 NaN
3 NaNObserve que, se você não especificar os rótulos ou o índice do eixo, eles serão construídos a partir dos dados de entrada com base em regras de bom senso.
O Pandas pode reconhecê-lo, mas você precisa ajudá-lo um pouco: adicione o argumento parse_dates quando estiverlendo dados de, digamos, um arquivo de valor separado por vírgula (CSV):
import pandas as pd
pd.read_csv('yourFile', parse_dates=True)
# or this option:
pd.read_csv('yourFile', parse_dates=['columnName'])No entanto, sempre há formatos estranhos de data e hora.
Não se preocupe! Nesses casos, você pode criar seu próprio analisador para lidar com isso. Você poderia, por exemplo, criar uma função lambda que pegasse o DateTime e o controlasse com uma string de formato.
import pandas as pd
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
# Which makes your read command:
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
# Or combine two columns into a single DateTime column
pd.read_csv(infile, parse_dates={'datetime': ['date', 'time']}, date_parser=dateparse)Remodelar seu DataFrame é transformá-lo de modo que a estrutura resultante o torne mais adequado para sua análise de dados. Em outras palavras, a remodelagem não se preocupa tanto com a formatação dos valores contidos no DataFrame, mas sim com a transformação de sua forma.
Isso responde a quando e por quê. Mas como você reformularia seu DataFrame?
Há três maneiras de remodelar que frequentemente geram dúvidas entre os usuários: pivotar, empilhar e desempilhar e derreter.
Você pode usar a função pivot() para criar uma nova tabela derivada a partir da tabela original. Ao usar a função, você pode passar três argumentos:
values: esse argumento permite especificar quais valores do DataFrame original você deseja ver na tabela dinâmica.columns: tudo o que você passar para esse argumento se tornará uma coluna na tabela resultante.indexO que quer que você passe para esse argumento se tornará um índice na tabela resultante.# Import pandas
import pandas as pd
# Create your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot the DataFrame
pivot_products = products.pivot(index='category', columns='store', values='price')
# Check out the result
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 55.75 NaN 111.55Quando você não preenche especificamente quais valores espera que estejam presentes na tabela resultante, você dinamizará por várias colunas:
# Import the Pandas library
import pandas as pd
# Construct the DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot your DataFrame
pivot_products = products.pivot(index='category', columns='store')
# Check out the results
print(pivot_products)
price testscore
store Dia Fnac Walmart Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42 3.0 NaN 4.0
Entertainment NaN 15.95 19.99 NaN 7.0 5.0
Tech 55.75 NaN 111.55 5.0 NaN 8.0Observe que seus dados não podem ter linhas com valores duplicados para as colunas que você especificar. Se esse não for o caso, você receberá uma mensagem de erro. Se não for possível garantir a exclusividade dos dados, use o método pivot_table:
# Import the Pandas library
import pandas as pd
# Your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 19.99, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Pivot your `products` DataFrame with `pivot_table()`
pivot_products = products.pivot_table(index='category', columns='store', values='price', aggfunc='mean')
# Check out the results
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 19.99 NaN 111.55Observe o argumento adicional aggfunc que é passado para o método pivot_table. Esse argumento indica que você usa uma função de agregação usada para combinar vários valores. Neste exemplo, você pode ver claramente que a função mean é usada.
stack() e unstack() para remodelar seu DataFrame do PandasVocê já viu um exemplo de empilhamento na seção 5. Basicamente, talvez você ainda se lembre de que, ao empilhar um DataFrame, ele fica mais alto. Você move o índice da coluna mais interna para se tornar o índice da linha mais interna. Você retorna um DataFrame com um índice com um novo nível mais interno de rótulos de linha.
Volte para o passo a passo completo na seção 5 se não tiver certeza do funcionamento dostack().
O inverso do empilhamento é chamado de desempilhamento. Assim como em stack(), você usa unstack() para mover o índice de linha mais interno para se tornar o índice de coluna mais interno.
Para obter uma explicação sobre o pivotamento, empilhamento e desempilhamento de pandas, confira nosso artigo Reformulando dados com pandas curso.
melt()A fusão é considerada útil nos casos em que você tem dados com uma ou mais colunas que são variáveis identificadoras, enquanto todas as outras colunas são consideradas variáveis medidas.
Essas variáveis medidas são todas "não pivotadas" para o eixo da linha. Ou seja, enquanto as variáveis medidas que estavam espalhadas pela largura do DataFrame, a fusão garantirá que elas sejam colocadas na altura dele. Ou, em outras palavras, seu DataFrame se tornará mais longo em vez de mais largo.
Como resultado, você tem duas colunas sem identificador, a saber, 'variable' e 'value'.
Vamos ilustrar isso com um exemplo:
# The `people` DataFrame
people = pd.DataFrame({'FirstName' : ['John', 'Jane'],
'LastName' : ['Doe', 'Austen'],
'BloodType' : ['A-', 'B+'],
'Weight' : [90, 64]})
# Use `melt()` on the `people` DataFrame
print(pd.melt(people, id_vars=['FirstName', 'LastName'], var_name='measurements')) FirstName LastName measurements value
0 John Doe BloodType A-
1 Jane Austen BloodType B+
2 John Doe Weight 90
3 Jane Austen Weight 64Se estiver procurando mais maneiras de remodelar seus dados, consulte a documentação.
Você pode iterar sobre as linhas do seu DataFrame com a ajuda de um loop for em combinação com uma chamada iterrows() no seu DataFrame:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
for index, row in df.iterrows() :
print(row['A'], row['B'])1 2
4 5
7 8iterrows() permite que você faça um loop eficiente sobre as linhas do DataFrame como pares (index, Series). Em outras palavras, ele fornece tuplas (índice, linha) como resultado.
Depois de fazer a manipulação e o processamento de dados com o Pandas, talvez você queira exportar o DataFrame para outro formato. Esta seção abordará duas maneiras de enviar o DataFrame do pandas para um arquivo CSV ou Excel.
Para gravar um DataFrame como um arquivo CSV, você pode usar to_csv():
import pandas as pd
df.to_csv('myDataFrame.csv')Esse trecho de código parece bastante simples, mas é justamente aí que começam as dificuldades para a maioria das pessoas, pois você terá requisitos específicos para a saída dos seus dados. Talvez você não queira uma vírgula como delimitador ou queira especificar uma codificação específica.
Não se preocupe! Você pode passar alguns argumentos adicionais para to_csv() para garantir que seus dados sejam gerados da maneira que você deseja!
sep:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t')encoding:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t', encoding='utf-8')NaN ou ausentes sejam representados, se deseja ou não gerar o cabeçalho, se deseja ou não gravar os nomes das linhas, se deseja compactação, etc. Você pode ler sobre as opções.Da mesma forma que você fez para enviar seu DataFrame para CSV, você pode usar o site to_excel() para gravar sua tabela no Excel. No entanto, é um pouco mais complicado:
import pandas as pd
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()Observe, no entanto, que, assim como em to_csv(), você tem vários argumentos extras, como startcol, startrow, e assim por diante, para garantir que os dados sejam gerados corretamente. Você pode saber mais sobre como importar e exportar dados para arquivos CSV usando o pandas em nosso tutorial.
Se, no entanto, você quiser obter mais informações sobre as ferramentas de IO no Pandas, consulte a documentação do pandas DataFrames to excel.
É isso aí! Você concluiu com êxito o tutorial do Pandas DataFrame!
As respostas às 11 perguntas frequentes sobre o Pandas representam as funções essenciais de que você precisará para importar, limpar e manipular os dados para seu trabalho de ciência de dados. Você não tem certeza de que se aprofundou o suficiente nesse assunto? Nosso curso Importando dados em Python o ajudará! Se você já entendeu isso, talvez queira ver os Pandas trabalhando em um projeto da vida real. A série de tutoriais The Importance of Preprocessing in Data Science and the Machine Learning Pipeline é de leitura obrigatória, e o curso aberto Introduction to Python & Machine Learning é de conclusão obrigatória.
Saiba mais sobre Python e pandas
Curso
Curso
Curso
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Vidhi Chugh
Tutorial
Kurtis Pykes
Tutorial
Aditya Sharma
Tutorial
DataCamp Team