Curso
Lidando com dados ausentes em R
4 h
17.2K
Lidar com dados ausentes é um problema comum e inerente à coleta de dados, especialmente quando se trabalha com grandes conjuntos de dados. Há vários motivos para a falta de dados, como informações incompletas fornecidas pelos participantes, não resposta daqueles que se recusam a compartilhar informações, pesquisas mal elaboradas ou remoção de dados por motivos de confidencialidade.
Quando não são tratados adequadamente, os dados ausentes podem distorcer as conclusões de todas as análises estatísticas dos dados, levando a empresa a tomar decisões erradas.
Este artigo se concentrará em algumas técnicas para lidar eficientemente com valores ausentes e suas implementações em Python. Ilustraremos as vantagens e desvantagens de cada técnica para ajudá-lo a escolher a mais adequada para uma determinada situação.
Os dados ausentes ocorrem em diferentes formatos. Esta seção explica os diferentes tipos de dados ausentes e como identificá-los.
Há três tipos principais de dados ausentes: (1) Completamente ausente ao acaso (MCAR), (2) Ausente ao acaso (MAR) e (3) Ausente não ao acaso (MNAR).
É importante entender melhor cada um deles para escolher os métodos adequados para lidar com eles.
Isso acontece se todas as variáveis e observações tiverem a mesma probabilidade de estarem ausentes. Imagine dar a uma criança Lego de cores diferentes para construir uma casa. Cada Lego representa uma informação, como forma e cor. A criança pode perder alguns Legos durante o jogo. Esses legos perdidos representam informações perdidas, assim como quando eles não conseguem se lembrar da forma ou da cor do Lego que tinham. Essas informações foram perdidas aleatoriamente, mas não alteram as informações que a criança tem sobre os outros Legos.
Para o MAR, a probabilidade de o valor estar ausente está relacionada ao valor da variável ou de outras variáveis no conjunto de dados. Isso significa que nem todas as observações e variáveis têm a mesma chance de estar ausentes. Um exemplo de MAR é uma pesquisa na comunidade de dados em que os cientistas de dados que não atualizam suas habilidades com frequência têm maior probabilidade de não estar cientes dos novos algoritmos ou tecnologias de ponta e, portanto, pulam determinadas perguntas. Os dados ausentes, nesse caso, estão relacionados à frequência com que o cientista de dados aprimora suas habilidades.
O MNAR é considerado o cenário mais difícil entre os três tipos de dados ausentes. Ele é aplicado quando nem o MAR nem o MCAR se aplicam. Nessa situação, a probabilidade de estar ausente é completamente diferente para valores diferentes da mesma variável, e esses motivos podem ser desconhecidos para nós. Um exemplo de MNAR é uma pesquisa sobre casais casados. Os casais com um relacionamento ruim talvez não queiram responder a certas perguntas, pois podem se sentir envergonhados.
Há vários métodos que podem ser usados para identificar dados ausentes no pandas. Abaixo estão os mais recorrentes.
|
Funções |
Descrições |
|
.isnull() |
Essa função retorna um dataframe do pandas, em que cada valor é um valor booleano Verdadeiro se o valor estiver ausente, Falso caso contrário. |
|
.notnull() |
Da mesma forma que a função anterior, os valores para essa função são False (Falso) se for detectado um valor NaN ou None (Nenhum). |
|
.info() |
Essa função gera três colunas principais, incluindo a "Non-Null Count" (contagem não nula), que mostra o número de valores não ausentes para cada coluna. |
|
.isna() |
Esse é semelhante ao isnull e ao notnull. No entanto, ele mostra True somente quando o valor ausente é do tipo NaN. |
Tabela de métodos para identificar dados ausentes
Existem várias abordagens para lidar com dados ausentes. Esta seção aborda alguns deles, juntamente com seus benefícios e desvantagens.
Para ilustrar melhor o caso de uso, usaremos os dados de empréstimo disponíveis no DataCamp Workspace junto com o código-fonte abordado no tutorial.
Como o conjunto de dados não tem nenhum valor ausente, usaremos um subconjunto dos dados (100 linhas) e, em seguida, introduziremos manualmente os valores ausentes.
import pandas as pdsample_customer_data = pd.read_csv("data/customer_churn.csv", nrows=100)
sample_customer_data.info()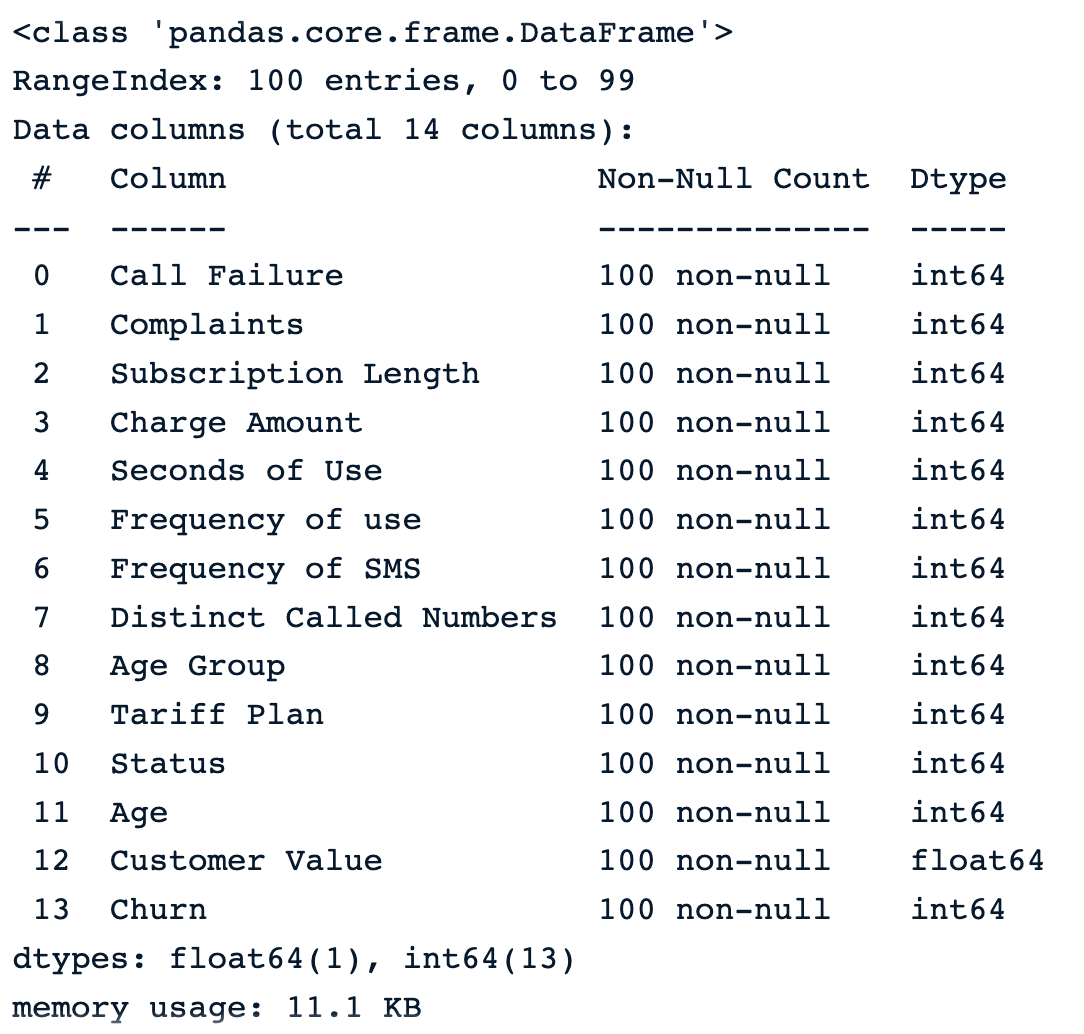
Amostra de 100 amostras aleatórias antes da introdução de valores ausentes
Vamos introduzir 50% dos valores ausentes em cada coluna do quadro de dados usando.
import numpy as np
def introduce_nan(x,percentage):
n = int(len(x)*(percentage - x.isna().mean()))
idxs = np.random.choice(len(x), max(n,0), replace=False, p=x.notna()/x.notna().sum())
x.iloc[idxs] = np.nanA aplicação da função aos dados gera esse resultado.
sample_customer_data.apply(introduce_nan, percentage=.5)
sample_customer_data.info()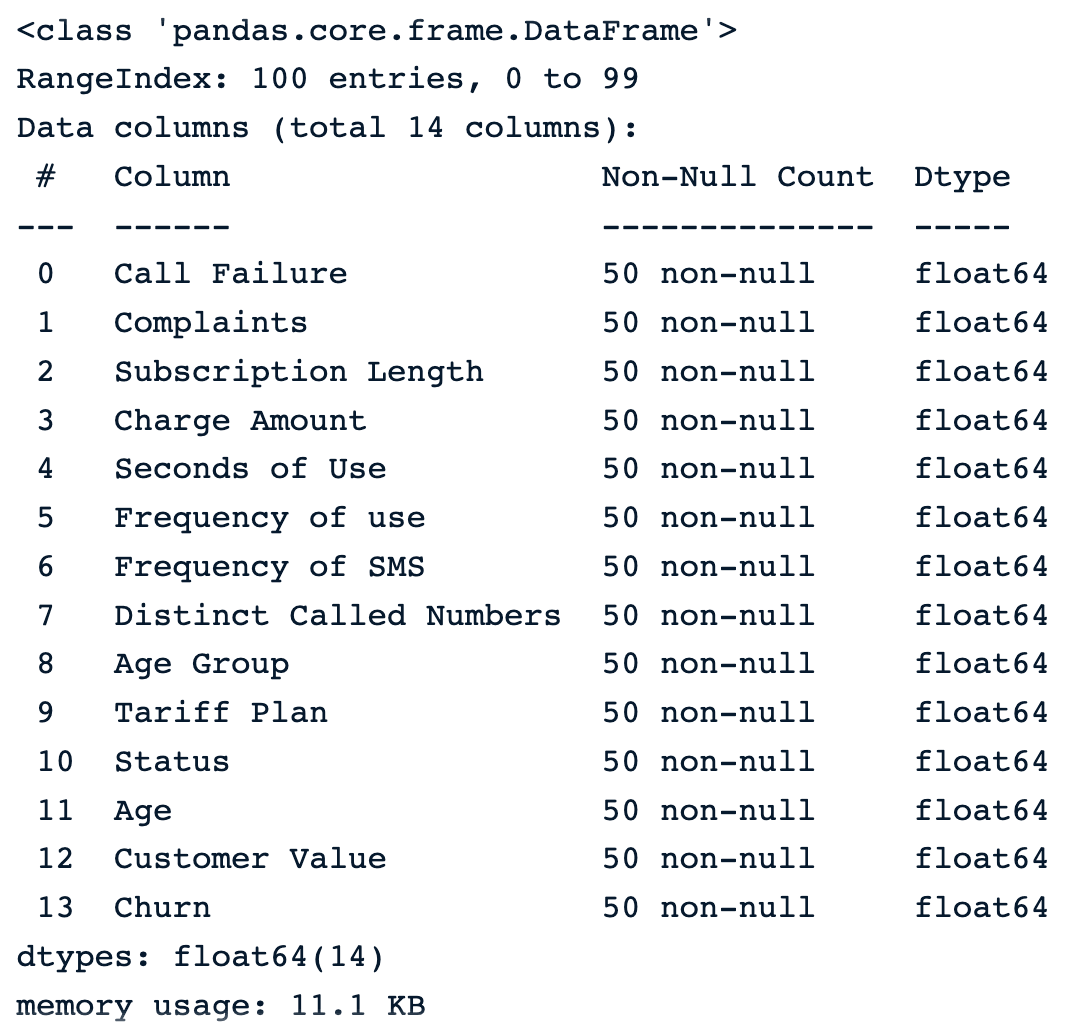
Amostra de 100 amostras aleatórias após a introdução de valores ausentes
Abaixo estão as primeiras cinco linhas do conjunto de dados.
sample_customer_data.head()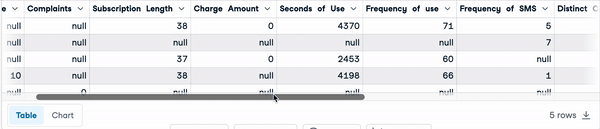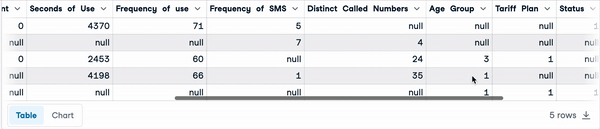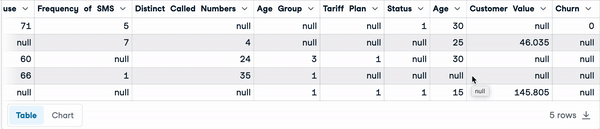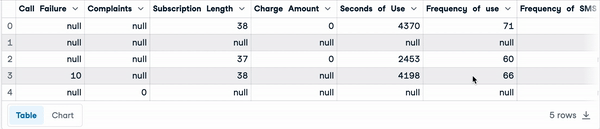
Primeiras cinco linhas com valores nulos
Usar a função dropna() é a maneira mais fácil de remover observações ou recursos com valores ausentes do dataframe. Abaixo estão algumas técnicas.
1) Eliminar observações com valores ausentes
Esses três cenários podem ocorrer ao tentar remover observações de um conjunto de dados:
dropna()Elimina todas as linhas com valores ausentes.drop_na_strategy = sample_customer_data.dropna()
drop_na_strategy.info()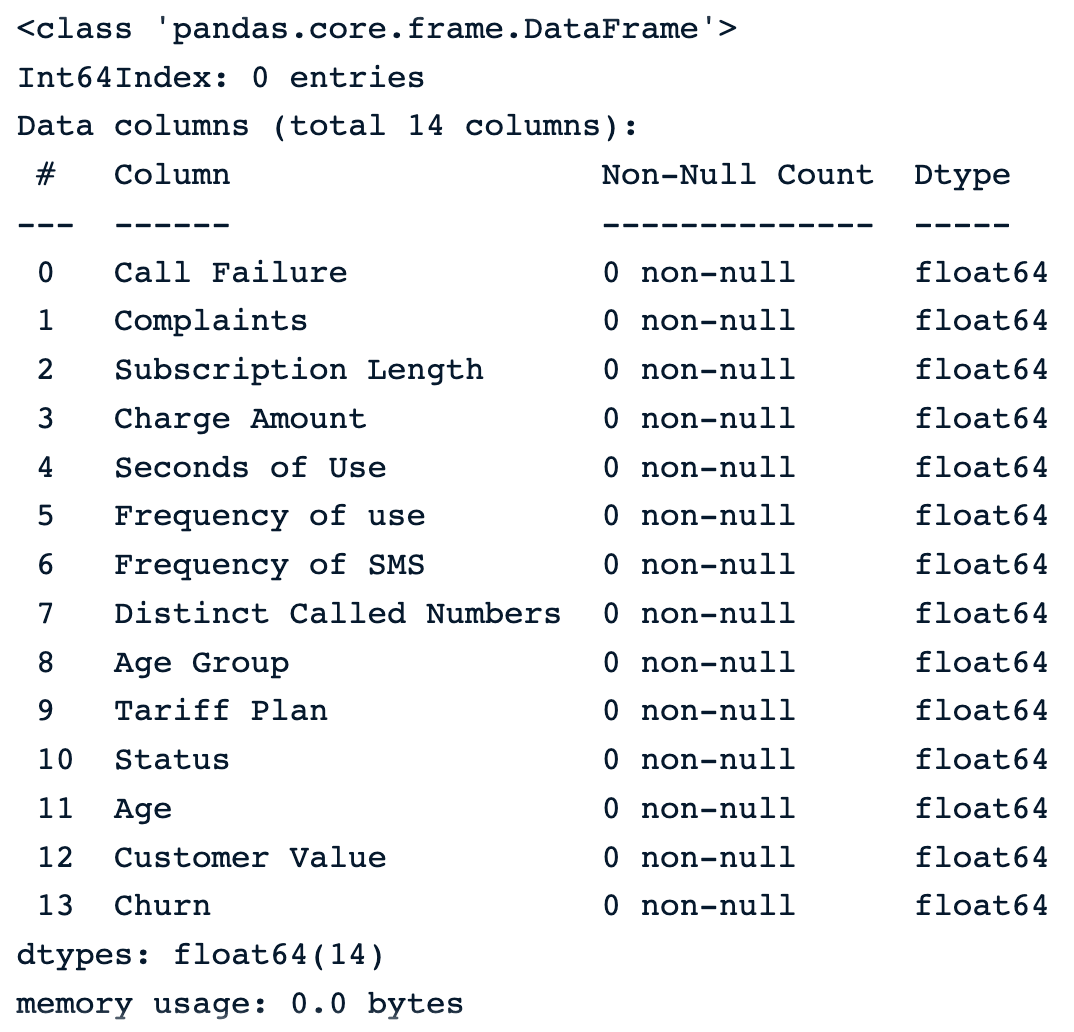
Eliminar observações usando a função padrão dropna()
Podemos ver que todas as observações são excluídas do conjunto de dados, o que pode ser especialmente perigoso para o restante da análise.
dropna(how = ‘all’): as linhas em que todos os valores da coluna estão ausentes.drop_na_all_strategy = sample_customer_data.dropna(how="all")
drop_na_all_strategy.info()No resultado abaixo, notamos que não há nenhuma observação com todas as colunas ausentes.
Eliminar observações usando a estratégia "all" (todos)
dropna(thresh = minimum_value)Eliminar linhas com base em um limite. Essa estratégia define um número mínimo de valores ausentes necessários para preservar as linhas. drop_na_thres_strategy = sample_customer_data.dropna(thresh=0.6)
drop_na_thres_strategy.info()Definindo o limite para 60%, o resultado é o mesmo em comparação com o anterior.

Eliminar observações usando o limite
2) Eliminar colunas com valores ausentes
O parâmetro axis = 1 pode ser usado para especificar explicitamente que estamos interessados em colunas em vez de linhas.
dropna(axis = 1)Elimina todas as colunas com valores ausentes.drop_na_cols_strategy = sample_customer_data.dropna(axis=1)
drop_na_cols_strategy.info()Não há mais colunas nos dados. Isso ocorre porque todas as colunas têm pelo menos um valor ausente.

Dataframe vazio após dropna() nas colunas
Como muitas outras abordagens, o site dropna() também tem alguns prós e contras.
Essas estratégias de substituição são autoexplicativas. As imputações média e mediana são usadas, respectivamente, para substituir os valores ausentes de uma determinada coluna pela média e mediana dos valores não ausentes nessa coluna.
A distribuição normal é o cenário ideal. Infelizmente, nem sempre é esse o caso. É nesse ponto que a imputação mediana pode ser útil, pois não é sensível a valores discrepantes.
No Python, a função fillna() do pandas pode ser usada para fazer essas substituições.
mean_value = sample_customer_data.mean()
mean_imputation = sample_customer_data.fillna(mean_value)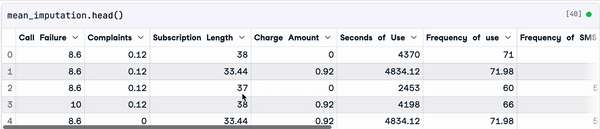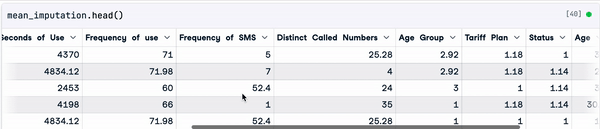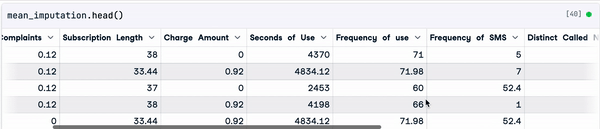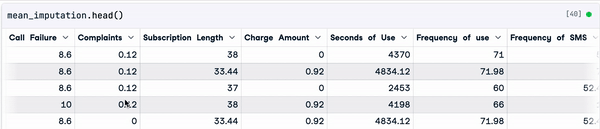
Resultado da imputação média
median_value = sample_customer_data.median()
median_imputation = sample_customer_data.fillna(median_value)
median_imputation.head()
Resultado da imputação mediana
A ideia por trás da imputação de amostras aleatórias é diferente das anteriores e envolve etapas adicionais.
def random_sample_imputation(df):
cols_with_missing_values = df.columns[df.isna().any()].tolist()
for var in cols_with_missing_values:
# extract a random sample
random_sample_df = df[var].dropna().sample(df[var].isnull().sum(),
random_state=0)
# re-index the randomly extracted sample
random_sample_df.index = df[
df[var].isnull()].index
# replace the NA
df.loc[df[var].isnull(), var] = random_sample_df
return dfdf = sample_customer_data.copy()
random_sample_imp_df = random_sample_imputation(sample_customer_data)
random_sample_imp_df.head()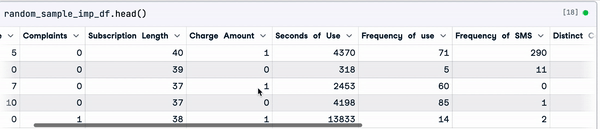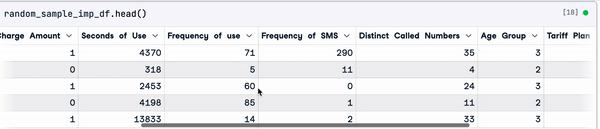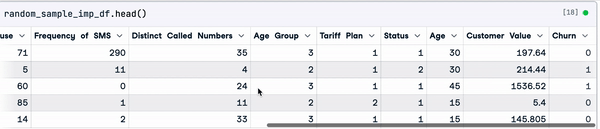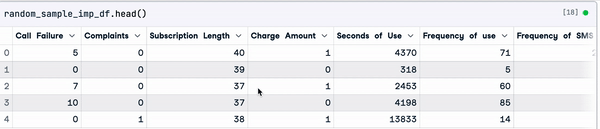
Imputação de amostras aleatórias
Essa é uma técnica de imputação multivariada, o que significa que as informações ausentes são preenchidas levando-se em consideração as informações das outras colunas.
Por exemplo, se o valor da renda de um indivíduo estiver faltando, não é possível saber se ele tem ou não uma hipoteca. Portanto, para determinar o valor correto, é necessário avaliar outras características, como pontuação de crédito, ocupação e se o indivíduo possui ou não uma casa.
A imputação múltipla por equações encadeadas (MICE, na sigla em inglês) é um dos métodos de imputação mais populares na imputação multivariada. Para entender melhor a abordagem MICE, vamos considerar o conjunto de variáveis X1, X2, ... Xn, em que alguns ou todos têm valores ausentes.
O algoritmo funciona da seguinte forma:
A implementação é realizada usando a biblioteca miceforest.
Primeiro, precisamos instalar a biblioteca usando o endereço pip.
pip install miceforestEm seguida, importamos o módulo ImputationKernel e criamos o kernel para imputação.
from miceforest import ImputationKernel
mice_kernel = ImputationKernel(
data = sample_customer_data,
save_all_iterations = True,
random_state = 2023
)Além disso, executamos o kernel nos dados por duas iterações e, por fim, criamos os dados imputados.
mice_kernel.mice(2)
mice_imputation = mice_kernel.complete_data()
mice_imputation.head()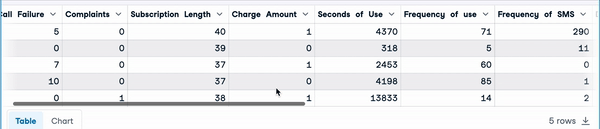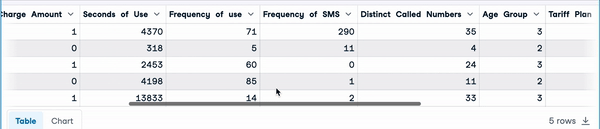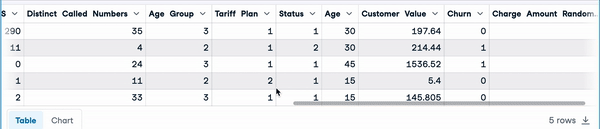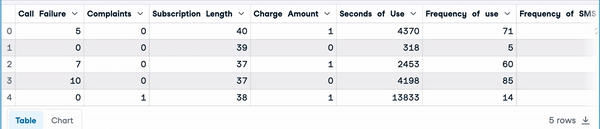
Imputação múltipla
De todas as imputações, é possível identificar qual delas está mais próxima da distribuição dos dados originais.
A média (em amarelo) e a mediana (em vermelho) estão muito distantes da distribuição original dos dados da coluna "Charge amount" e, portanto, não são consideradas ótimas para imputar os dados.
mean_imputation["Charge Amount Mean Imp"] = mean_imputation["Charge Amount"]
median_imputation["Charge Amount Median Imp"] = median_imputation["Charge Amount"]
random_sample_imp_df["Charge Amount Random Imp"] = random_sample_imp_df["Charge Amount"]Com as novas colunas criadas para cada tipo de imputação, podemos agora traçar o gráfico da distribuição.
import matplotlib.pyplot as plt
plt.figure(figsize=(12,8))
sample_customer_data["Charge Amount"].plot(kind='kde',color='blue')
mean_imputation["Charge Amount Mean Imp"].plot(kind='kde',color='yellow')
median_imputation["Charge Amount Median Imp"].plot(kind='kde',color='red')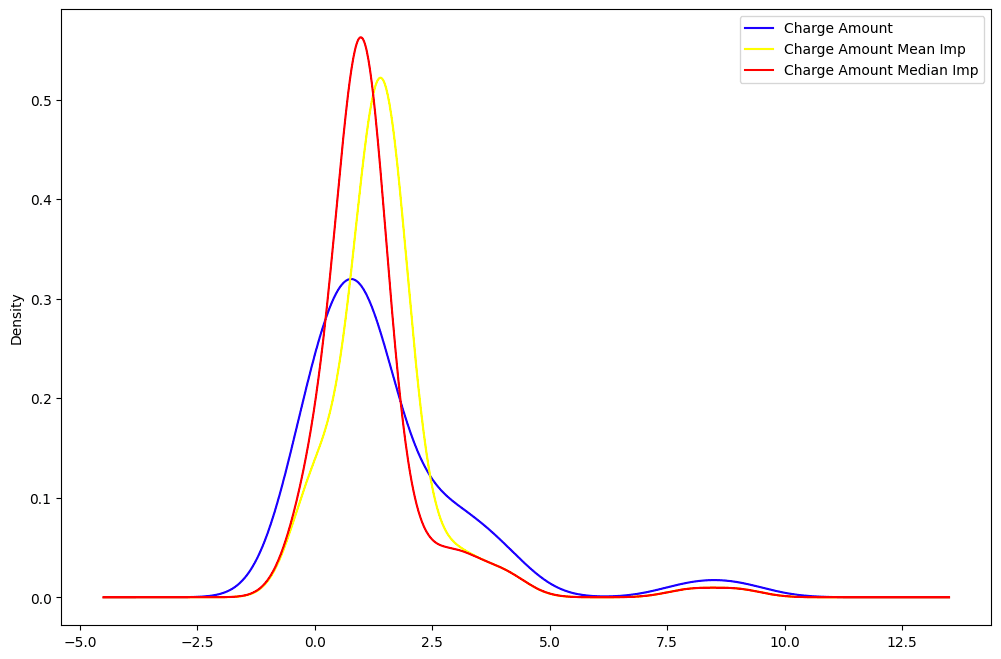
Distribuição de "Charge Amount": dados originais vs. média vs. mediana.
Ao traçar a imputação múltipla e a imputação aleatória abaixo, essas distribuições são perfeitamente sobrepostas aos dados originais. Isso significa que essas imputações são melhores do que as imputações média e mediana.
random_sample_imp_df["Charge Amount Random Imp"] = random_sample_imp_df["Charge Amount"]
mice_imputation["Charge Amount MICE Imp"] = mice_imputation["Charge Amount"]
mice_imputation["Charge Amount MICE Imp"].plot(kind='kde',color='black')
random_sample_imp_df["Charge Amount Random Imp"].plot(kind='kde',color='purple')
plt.legend()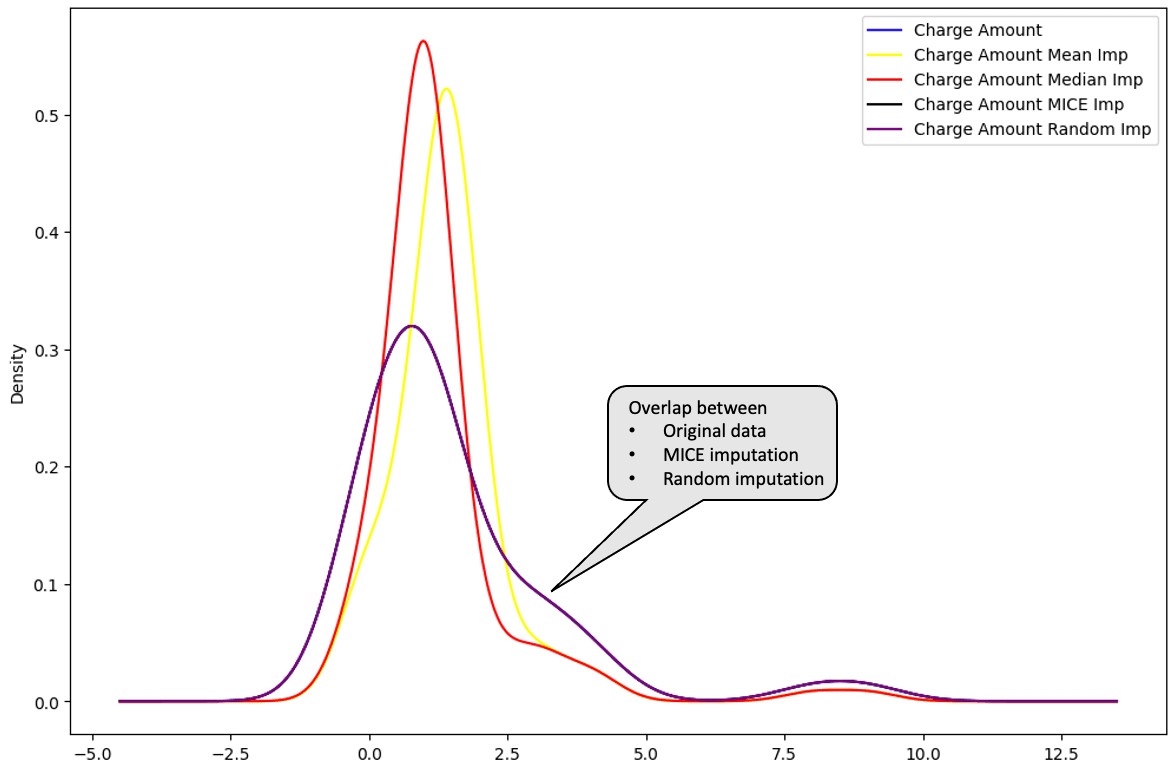
Distribuição de "Charge Amount": dados originais vs. média vs. mediana vs. MICE vs. randômico
O curso Handling Missing Data with Imputations in R é um ótimo recurso para saber mais sobre estratégias para lidar com valores ausentes. Ele aborda como aplicar testes estatísticos e de visualização para reconhecer padrões de dados ausentes e como imputá-los com técnicas estatísticas e de aprendizado de máquina.
Da mesma forma, o curso Lidando com dados ausentes em Python explica como identificar, analisar, remover e imputar dados ausentes em Python.
Há várias estratégias de imputação, e elas não devem ser usadas às cegas. A adoção da abordagem correta pode evitar a introdução de viés nos dados e a tomada de decisões erradas.
A tabela a seguir ilustra qual método de imputação deve ser usado com base no tipo de dados ausentes. A lista de métodos não é exaustiva, mas esses são os mais comumente usados.
|
Tipo de dados ausentes |
Método de imputação |
|
Ausente completamente ao acaso |
Média, Mediana, Modo ou qualquer outro método de imputação |
|
Desaparecido ao acaso |
Imputação múltipla, imputação de regressão |
|
Missing Not At Random |
Substituição de padrões, estimativa de máxima verossimilhança |
É importante ter em mente que os dados originais não podem ser recuperados, independentemente da técnica de imputação. No entanto, é possível usar técnicas que podem gerar conjuntos de dados imputados que sejam o mais próximo possível da realidade.
Abaixo estão algumas etapas importantes a serem consideradas durante a avaliação.
Ter dados de boa qualidade é o objetivo de todas as partes interessadas e profissionais de dados.
Honestidade e transparência são fundamentais ao comunicar dados ausentes na análise. Abaixo estão alguns aspectos importantes a serem considerados.
Este artigo abordou o que são dados ausentes e seu impacto no processo de tomada de decisão orientado por dados. Ele também o orientou em algumas estratégias para lidar com elas, juntamente com suas vantagens e desvantagens para a tomada de decisões práticas.
Esperamos que ele lhe forneça as estratégias relevantes para lidar eficientemente com seus problemas de dados ausentes.
Principais cursos
Curso
Curso
blog
Thaylise Nakamoto
9 min
blog
Matt Crabtree
9 min
blog
Bekhruz Tuychiev
15 min
Tutorial
Abid Ali Awan
Tutorial
Moez Ali

