
Torne-se um cientista de ML
Embora o kNN possa ser usado para classificação e regressão, este artigo se concentrará na criação de um modelo de classificação. A classificação na aprendizagem automática é uma tarefa de aprendizagem supervisionada que envolve a previsão de um rótulo categórico para um determinado ponto de dados de entrada. O algoritmo é treinado em um conjunto de dados rotulado e usa os recursos de entrada para aprender o mapeamento entre as entradas e os rótulos de classe correspondentes. Podemos usar o modelo treinado para prever dados novos e não vistos. Você também pode executar o código deste tutorial abrindo esta pasta de trabalho do DataLab.
Uma visão geral do K-Nearest Neighbors
O algoritmo kNN pode ser considerado um sistema de votação, em que o rótulo da classe majoritária determina o rótulo da classe de um novo ponto de dados entre seus vizinhos 'k' (em que k é um número inteiro) mais próximos no espaço de recursos. Imagine um pequeno vilarejo com algumas centenas de habitantes e você precisa decidir em qual partido político deve votar. Para fazer isso, você pode ir até seus vizinhos mais próximos e perguntar qual partido político eles apoiam. Se a maioria dos seus "k" vizinhos mais próximos apoiar o partido A, então você provavelmente também votará no partido A. Isso é semelhante ao funcionamento do algoritmo kNN, em que o rótulo da classe majoritária determina o rótulo da classe de um novo ponto de dados entre seus k vizinhos mais próximos.
Vamos dar uma olhada mais profunda com outro exemplo. Imagine que você tenha dados sobre frutas, especificamente uvas e peras. Você tem uma pontuação para o quão redonda a fruta é e o diâmetro. Você decide plotar esses dados em um gráfico. Se alguém lhe der uma nova fruta, você também poderá desenhá-la no gráfico e, em seguida, medir a distância até k (um número) pontos mais próximos para decidir qual é a fruta. No exemplo abaixo, se optarmos por medir três pontos, podemos dizer que os três pontos mais próximos são peras, portanto, tenho 100% de certeza de que se trata de uma pera. Se optarmos por medir os quatro pontos mais próximos, três são peras e um é uma uva, portanto, diríamos que temos 75% de certeza de que se trata de uma pera. Abordaremos como encontrar o melhor valor para k e as diferentes maneiras de medir a distância mais adiante neste artigo.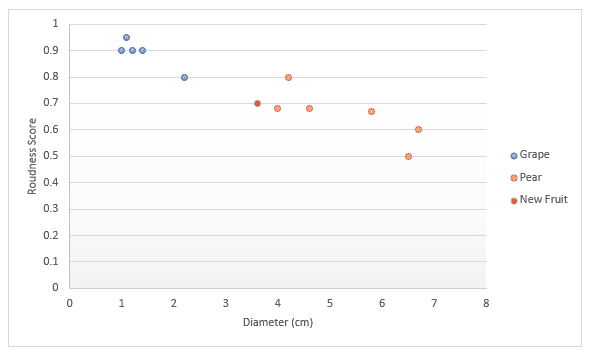
O conjunto de dados
Para ilustrar melhor o algoritmo kNN, vamos trabalhar em um estudo de caso que você pode encontrar ao trabalhar como cientista de dados. Vamos supor que você seja um cientista de dados em um varejista on-line e tenha sido encarregado de detectar transações fraudulentas. Os únicos recursos que você tem nesse estágio são:
dist_from_home: A distância entre o local de residência do usuário e o local onde a transação foi feita.purchase_price_ratioPreço médio de compra: a relação entre o preço do item comprado nessa transação e o preço médio de compra desse usuário.
Os dados têm 39 observações que são transações individuais. Neste tutorial, recebemos o conjunto de dados e a variável df, que tem a seguinte aparência:
|
0
|
2.1
|
6.4
|
1
|
|
1
|
3.8
|
2.2
|
1
|
|
2
|
15.7
|
4.4
|
1
|
|
3
|
26.7
|
4.6
|
1
|
|
4
|
10.7
|
4.9
|
1
|
Fluxo de trabalho do k-Nearest Neighbors
Para ajustar e treinar esse modelo, seguiremos o infográfico Fluxo de trabalho de aprendizado de máquina.
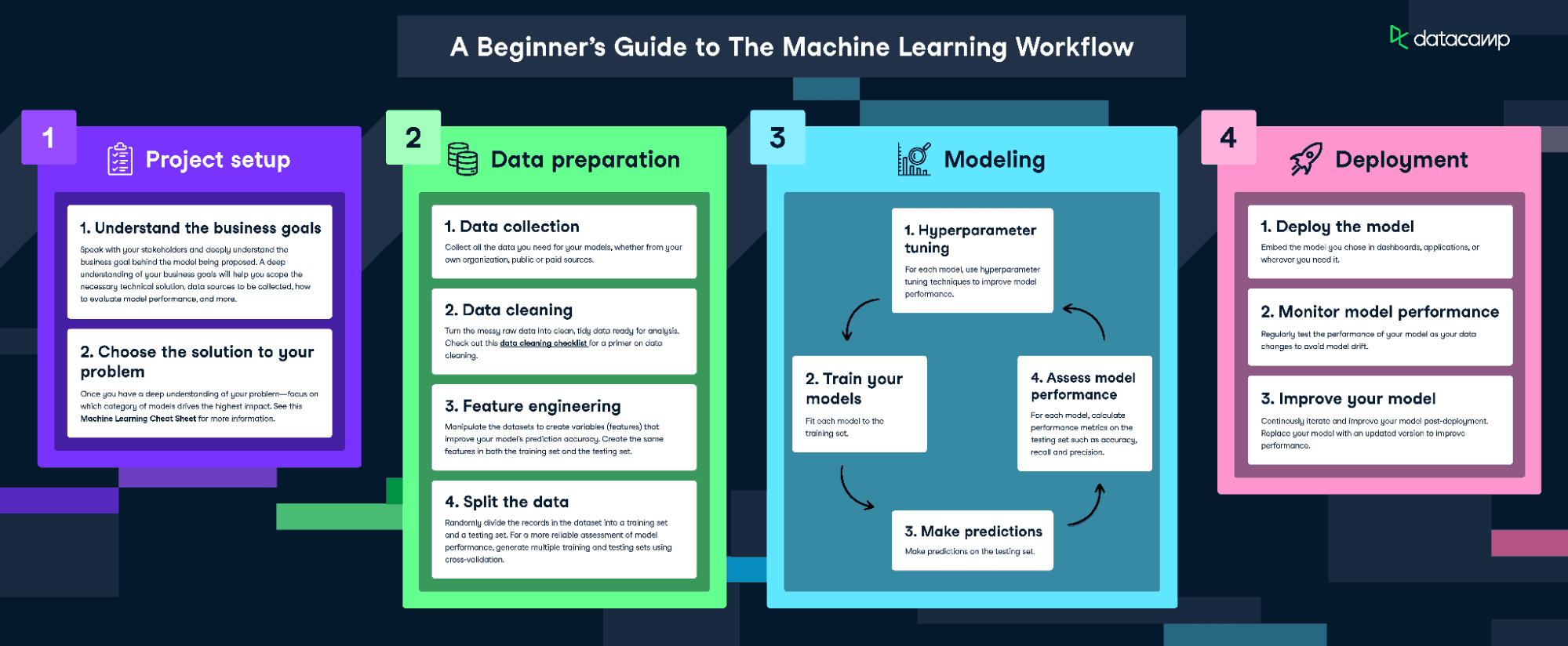
Baixe o infográfico do fluxo de trabalho de aprendizado de máquina
Entretanto, como nossos dados são bastante limpos, não executaremos todas as etapas. Faremos o seguinte:
- Engenharia de recursos
- Dividindo os dados
- Treinar o modelo
- Ajuste de hiperparâmetros
- Avaliar o desempenho do modelo
Visualize os dados
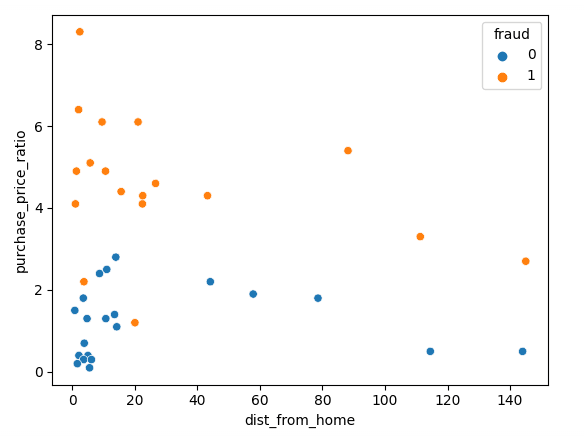
Vamos começar visualizando nossos dados usando o Matplotlib; podemos plotar nossos dois recursos em um gráfico de dispersão.
sns.scatterplot(x=df['dist_from_home'],y=df['purchase_price_ratio'], hue=df['fraud'])Como você pode ver, há uma clara diferença entre essas transações, com as transações fraudulentas sendo de valor muito mais alto, em comparação com o pedido médio dos clientes. As tendências em relação à distância do domicílio são um pouco difíceis de interpretar, com transações não fraudulentas normalmente mais próximas do domicílio, mas com vários valores discrepantes.
Normalizando e dividindo os dados
Ao treinar qualquer modelo de aprendizado de máquina, é importante dividir os dados em dados de treinamento e de teste. Os dados de treinamento são usados para ajustar o modelo. O algoritmo usa os dados de treinamento para aprender a relação entre os recursos e o alvo. Ele tenta encontrar um padrão nos dados de treinamento que possa ser usado para fazer previsões em dados novos e não vistos. Os dados de teste são usados para avaliar o desempenho do modelo. O modelo é testado nos dados de teste, usando-o para fazer previsões e comparando essas previsões com os valores-alvo reais.
Ao treinar um classificador kNN, é essencial normalizar os recursos. Isso ocorre porque o kNN mede a distância entre os pontos. O padrão é usar a Distância Euclidiana, que é a raiz quadrada da soma das diferenças quadradas entre dois pontos. No nosso caso, o purchase_price_ratio está entre 0 e 8, enquanto o dist_from_home é muito maior. Se não normalizássemos isso, nosso cálculo seria fortemente ponderado por dist_from_home porque os números são maiores.
Devemos normalizar os dados depois de dividi-los em conjuntos de treinamento e teste. Isso evita o "vazamento de dados", pois a normalização forneceria ao modelo informações adicionais sobre o conjunto de teste se normalizássemos todos os dados de uma só vez.
O código a seguir divide os dados em divisões de treinamento/teste e, em seguida, normaliza usando o scaler padrão do scikit-learn. Primeiro, chamamos .fit_transform() nos dados de treinamento, o que ajusta nosso escalonador à média e ao desvio padrão dos dados de treinamento. Em seguida, podemos aplicar isso aos dados de teste chamando .transform(), que usa os valores aprendidos anteriormente.
# Split the data into features (X) and target (y)
X = df.drop('fraud', axis=1)
y = df['fraud']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Scale the features using StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Ajuste e avaliação do modelo
Agora estamos prontos para treinar o modelo. Para isso, usaremos um valor fixo de 3 para k, mas precisaremos otimizar isso mais tarde. Primeiro, criamos uma instância do modelo kNN e, em seguida, ajustamos esse modelo aos nossos dados de treinamento. Passamos os recursos e a variável de destino para que o modelo possa aprender.
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)O modelo agora está treinado! Podemos fazer previsões no conjunto de dados de teste, que podem ser usadas posteriormente para pontuar o modelo.
y_pred = knn.predict(X_test)A maneira mais simples de avaliar esse modelo é usando a precisão. Verificamos as previsões em relação aos valores reais no conjunto de testes e contamos quantos o modelo acertou.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Accuracy: 0.875Essa é uma pontuação muito boa! No entanto, talvez possamos nos sair melhor otimizando o valor de k.
Usando a validação cruzada para obter o melhor valor de k
Infelizmente, não existe uma maneira mágica de encontrar o melhor valor para k. Temos que passar por muitos valores diferentes e, em seguida, usar nosso melhor julgamento.
No código abaixo, selecionamos um intervalo de valores para k e criamos uma lista vazia para armazenar nossos resultados. Usamos a validação cruzada para encontrar as pontuações de precisão, o que significa que não precisamos criar uma divisão de treinamento e teste, mas precisamos dimensionar nossos dados. Em seguida, percorremos os valores e adicionamos as pontuações à nossa lista.
Para implementar a validação cruzada, usamos o cross_val_score do scikit-learn. Passamos uma instância do modelo kNN, juntamente com nossos dados e um número de divisões a serem feitas. No código abaixo, usamos cinco divisões, o que significa que o modelo dividirá os dados em cinco grupos de tamanho igual e usará 4 para treinar e 1 para testar o resultado. Ele percorrerá cada grupo e fornecerá uma pontuação de precisão, que será usada como média para encontrar o melhor modelo.
k_values = [i for i in range (1,31)]
scores = []
scaler = StandardScaler()
X = scaler.fit_transform(X)
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=5)
scores.append(np.mean(score))Você pode plotar os resultados com o seguinte código
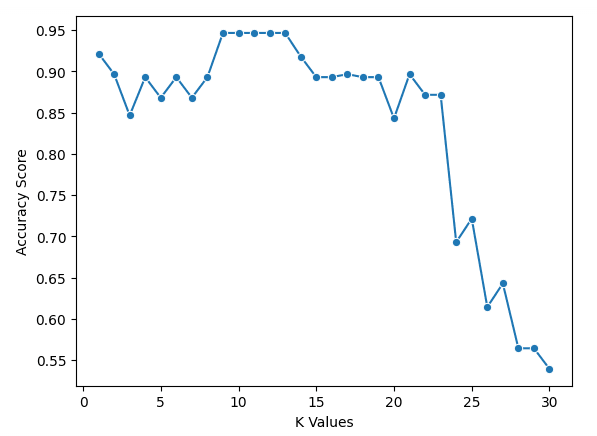
sns.lineplot(x = k_values, y = scores, marker = 'o')
plt.xlabel("K Values")
plt.ylabel("Accuracy Score")Podemos ver em nosso gráfico que k = 9, 10, 11, 12 e 13 têm uma pontuação de precisão de pouco menos de 95%. Como eles estão empatados na melhor pontuação, é aconselhável usar um valor menor para k. Isso ocorre porque, ao usar valores mais altos de k, o modelo usará mais pontos de dados que estão mais distantes do original. Outra opção seria explorar outras métricas de avaliação.
Mais métricas de avaliação
Agora podemos treinar nosso modelo usando o melhor valor de k usando o código abaixo.
best_index = np.argmax(scores)
best_k = k_values[best_index]
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)Em seguida, avalie com exatidão, precisão e recuperação (observe que seus resultados podem ser diferentes devido à randomização)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Accuracy: 0.875
Precision: 0.75
Recall: 1.0Leve-o para o próximo nível
- O curso Aprendizado supervisionado com o scikit-learn é o ponto de entrada para o currículo de aprendizado de máquina em Python do DataCamp e abrange os vizinhos mais próximos.
- Os cursos Anomaly Detection in Python, Dealing with Missing Data in Python e Machine Learning for Finance in Python mostram exemplos de uso do k-nearest neighbors.
- O tutorial Decision Tree Classification in Python aborda outro modelo de aprendizado de máquina para classificar dados.
- A folha de dicas do scikit-learn fornece uma referência útil para a funcionalidade popular de aprendizado de máquina.

