Curso
Tratamiento de datos faltantes en R
4 h
17.2K
La falta de datos es un problema común e inherente a la recopilación de datos, especialmente cuando se trabaja con grandes conjuntos de datos. Hay varias razones para que falten datos, como la información incompleta facilitada por los participantes, la falta de respuesta de quienes se niegan a compartir información, encuestas mal diseñadas o eliminación de datos por razones de confidencialidad.
Si no se gestionan adecuadamente, los datos que faltan pueden sesgar las conclusiones de todos los análisis estadísticos de los datos, llevando a la empresa a tomar decisiones equivocadas.
Este artículo se centrará en algunas técnicas para manejar eficazmente los valores perdidos y sus implementaciones en Python. Ilustraremos las ventajas e inconvenientes de cada técnica para ayudarle a elegir la más adecuada en cada situación.
Los datos que faltan se presentan en distintos formatos. En esta sección se explican los distintos tipos de datos que faltan y cómo identificarlos.
Existen tres tipos principales de datos omitidos: (1) Falta Completamente al Azar (MCAR), (2) Falta al Azar (MAR) y (3) Falta No al Azar (MNAR).
Es importante conocer mejor cada uno de ellos para elegir los métodos adecuados para gestionarlos.
Esto ocurre si todas las variables y observaciones tienen la misma probabilidad de faltar. Imagina que le das a un niño Lego de distintos colores para que construya una casa. Cada Lego representa una información, como la forma y el color. El niño puede perder algunos Legos durante el juego. Estos legos perdidos representan información perdida, igual que cuando no pueden recordar la forma o el color del Lego que tenían. Esa información se perdió al azar, pero no cambian la información que el niño tiene sobre los otros Legos.
Para MAR, la probabilidad de que falte un valor está relacionada con el valor de la variable o de otras variables del conjunto de datos. Esto significa que no todas las observaciones y variables tienen la misma probabilidad de faltar. Un ejemplo de SAM es una encuesta en la comunidad de datos en la que los científicos de datos que no actualizan con frecuencia sus conocimientos tienen más probabilidades de no estar al tanto de los nuevos algoritmos o tecnologías de vanguardia, de ahí que se salten ciertas preguntas. Los datos que faltan, en este caso, están relacionados con la frecuencia con la que el científico de datos se actualiza.
Se considera que MNAR es el escenario más difícil entre los tres tipos de datos que faltan. Se aplica cuando no se aplican ni MAR ni MCAR. En esta situación, la probabilidad de que falte es completamente diferente para distintos valores de la misma variable, y estas razones pueden ser desconocidas para nosotros. Un ejemplo de MNAR es una encuesta sobre parejas casadas. Es posible que las parejas con una mala relación no quieran responder a ciertas preguntas porque les da vergüenza hacerlo.
Hay múltiples métodos que se pueden utilizar para identificar los datos que faltan en pandas. A continuación figuran los más recurrentes.
|
Funciones |
Descripciones |
|
.isnull() |
Esta función devuelve un marco de datos pandas, donde cada valor es un valor booleano True si falta el valor, False en caso contrario. |
|
.notnull() |
De forma similar a la función anterior, los valores para ésta son False si se detecta un valor NaN o None. |
|
.info() |
Esta función genera tres columnas principales, incluido el "Recuento de valores no nulos", que muestra el número de valores no ausentes de cada columna. |
|
.isna() |
Es similar a isnull y notnull. Sin embargo, sólo muestra True cuando el valor que falta es de tipo NaN. |
Tabla de métodos para identificar los datos que faltan
Existen múltiples métodos para tratar los datos que faltan. En esta sección se describen algunas de ellas, junto con sus ventajas e inconvenientes.
Para ilustrar mejor el caso de uso, utilizaremos los Datos de Préstamos disponibles en DataLab junto con el código fuente cubierto en el tutorial.
Dado que el conjunto de datos no contiene valores perdidos, utilizaremos un subconjunto de los datos (100 filas) e introduciremos manualmente los valores perdidos.
import pandas as pdsample_customer_data = pd.read_csv("data/customer_churn.csv", nrows=100)
sample_customer_data.info()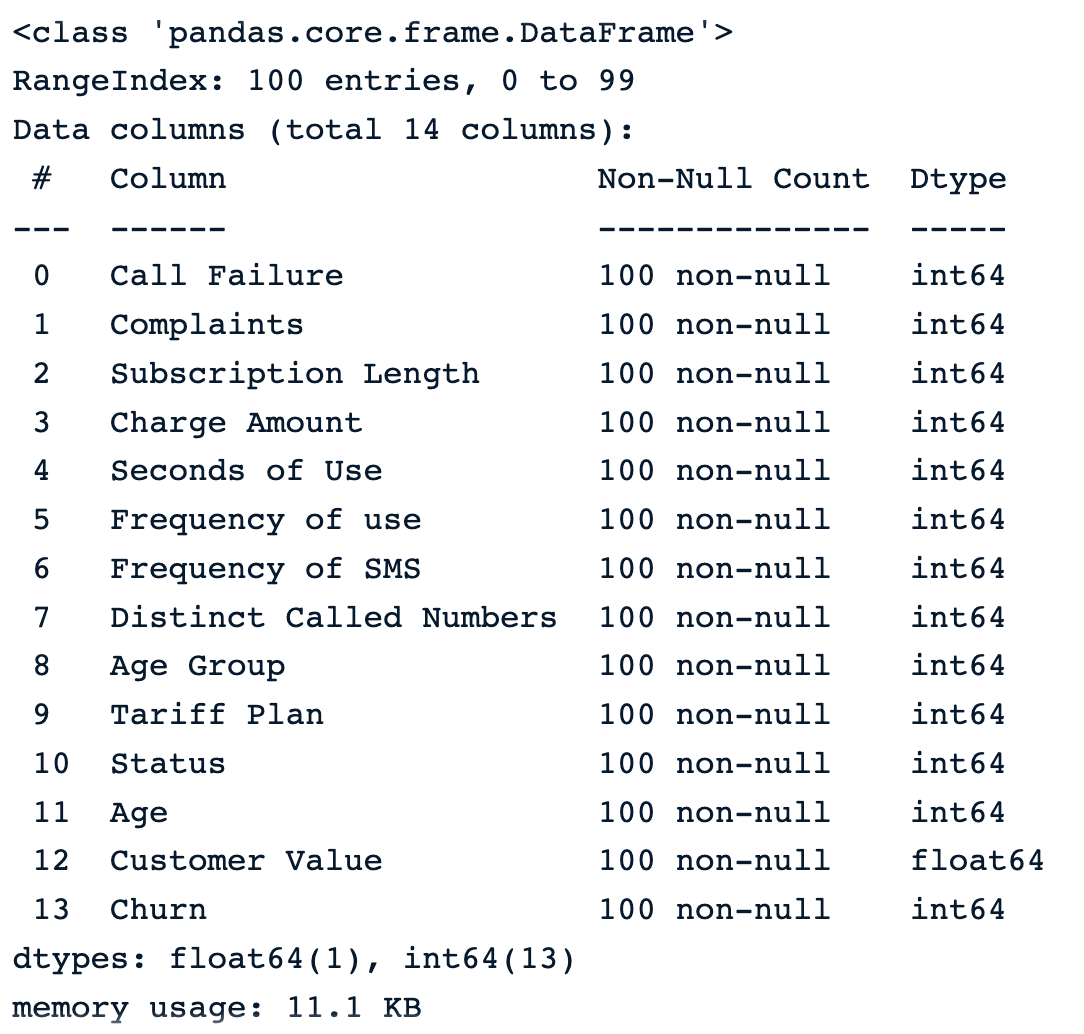
Muestra de 100 muestras aleatorias antes de introducir los valores perdidos
Introduzcamos el 50% de valores perdidos en cada columna del marco de datos utilizando.
import numpy as np
def introduce_nan(x,percentage):
n = int(len(x)*(percentage - x.isna().mean()))
idxs = np.random.choice(len(x), max(n,0), replace=False, p=x.notna()/x.notna().sum())
x.iloc[idxs] = np.nanAplicando la función a los datos se obtiene este resultado.
sample_customer_data.apply(introduce_nan, percentage=.5)
sample_customer_data.info()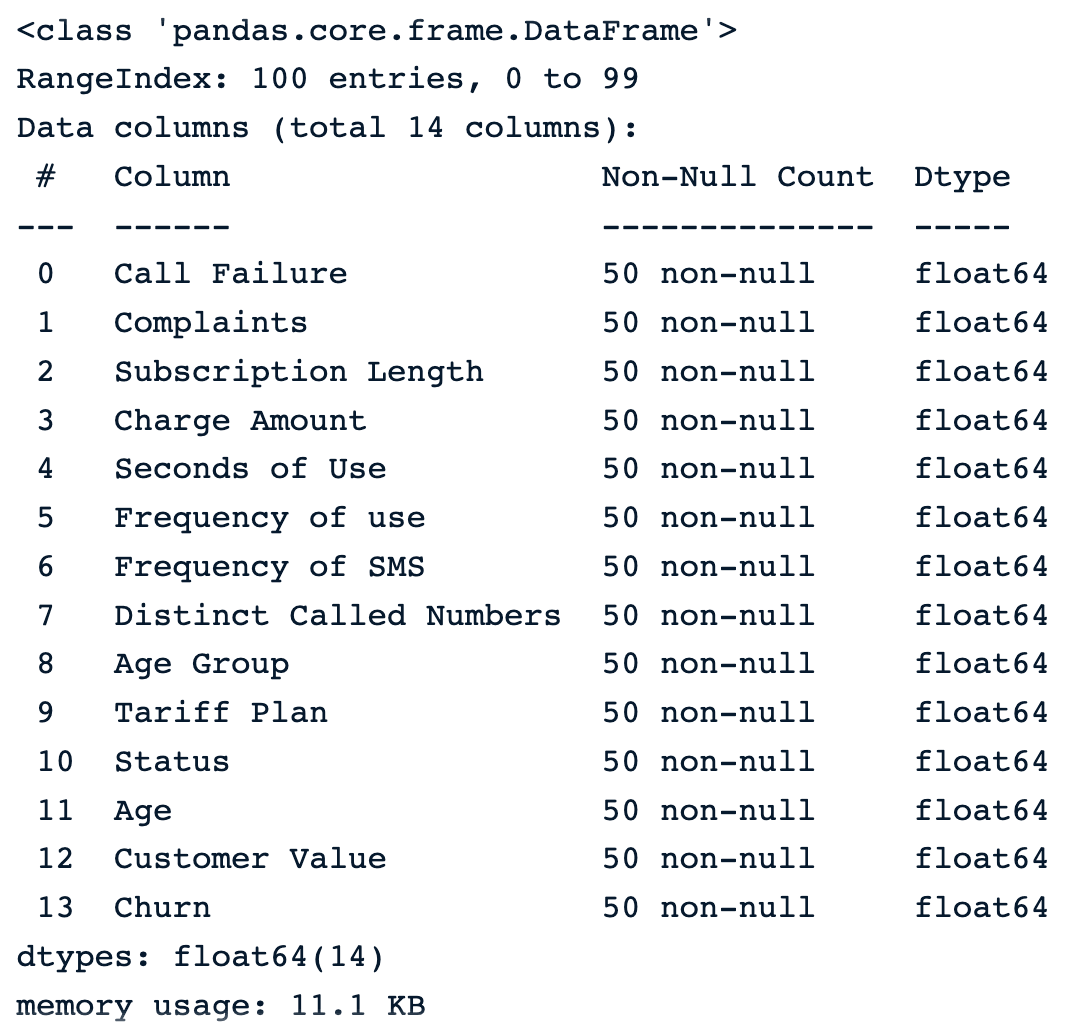
Muestra de 100 muestras aleatorias tras introducir los valores perdidos
A continuación se muestran las cinco primeras filas del conjunto de datos.
sample_customer_data.head()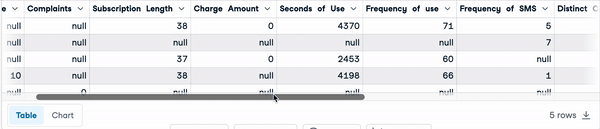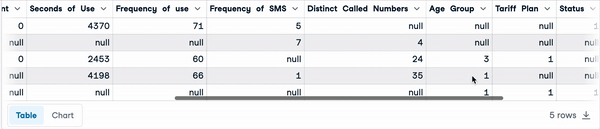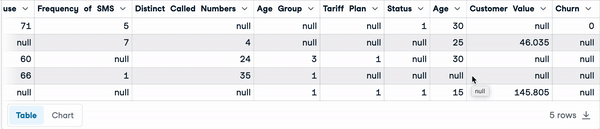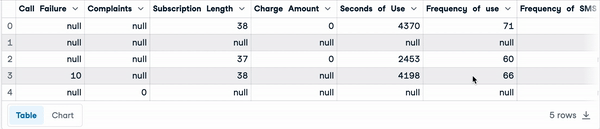
Cinco primeras filas con valores nulos
Utilizar la función dropna() es la forma más sencilla de eliminar observaciones o características con valores perdidos del marco de datos. A continuación se exponen algunas técnicas.
1) Eliminar las observaciones con valores omitidos
Estas tres situaciones pueden darse al intentar eliminar observaciones de un conjunto de datos:
dropna(): elimina todas las filas con valores perdidos.drop_na_strategy = sample_customer_data.dropna()
drop_na_strategy.info()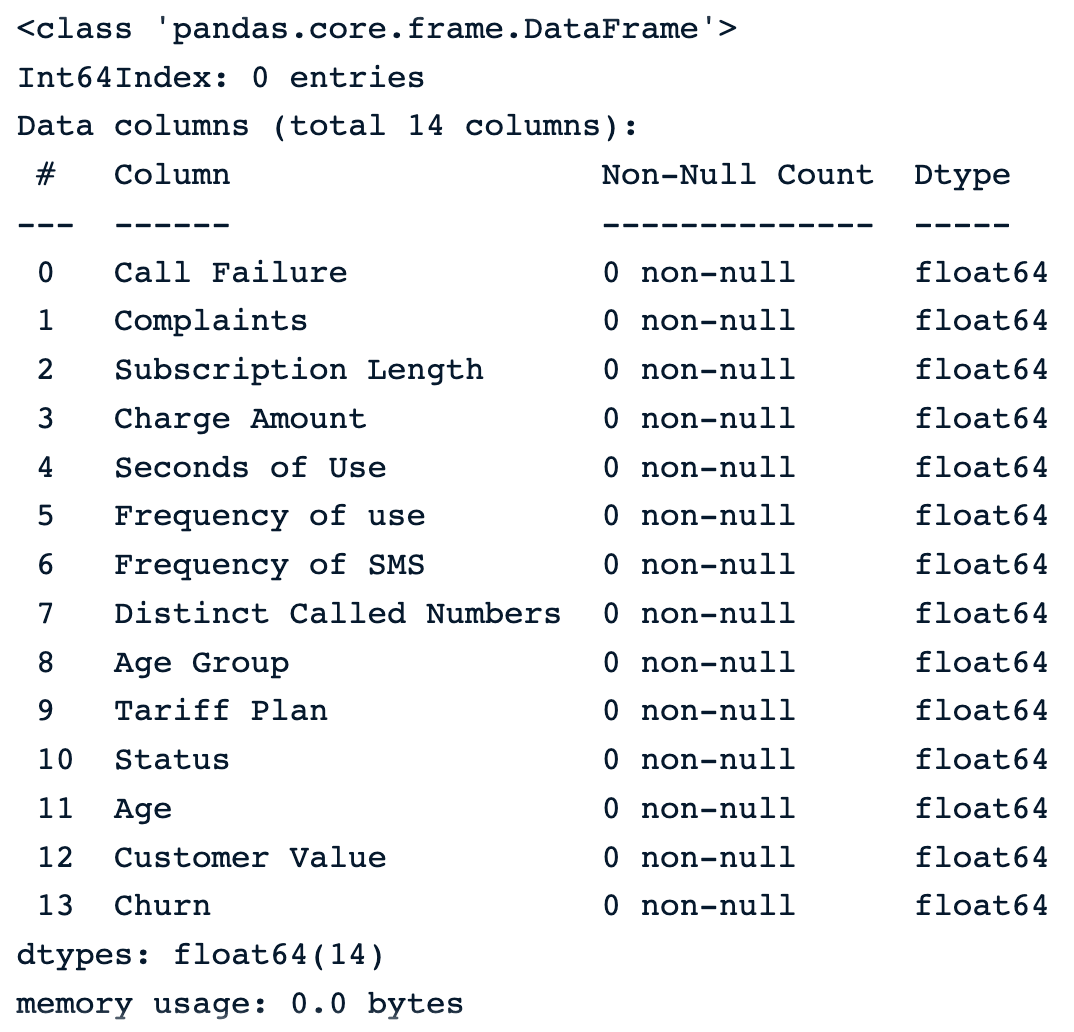
Deje caer las observaciones utilizando la función por defecto dropna()
Podemos ver que todas las observaciones se eliminan del conjunto de datos, lo que puede ser especialmente peligroso para el resto del análisis.
dropna(how = ‘all’): las filas en las que faltan todos los valores de columna.drop_na_all_strategy = sample_customer_data.dropna(how="all")
drop_na_all_strategy.info()En el resultado que se muestra a continuación, observamos que no hay ninguna observación en la que falten todas las columnas.
Eliminar observaciones utilizando la estrategia "todos
dropna(thresh = minimum_value): elimina filas en función de un umbral. Esta estrategia establece un número mínimo de valores perdidos necesarios para conservar las filas. drop_na_thres_strategy = sample_customer_data.dropna(thresh=0.6)
drop_na_thres_strategy.info()Ajustando el umbral al 60%, el resultado es el mismo que el anterior.

Eliminación de observaciones mediante umbral
2) Eliminar las columnas con valores omitidos
El parámetro axis = 1 puede utilizarse para especificar explícitamente que nos interesan las columnas en lugar de las filas.
dropna(axis = 1): elimina todas las columnas con valores perdidos.drop_na_cols_strategy = sample_customer_data.dropna(axis=1)
drop_na_cols_strategy.info()No hay más columnas en los datos. Esto se debe a que en todas las columnas falta al menos un valor.

Cuadro de datos vacío después de dropna() en columnas
Como muchos otros enfoques, dropna() también tiene algunos pros y contras.
Estas estrategias de sustitución se explican por sí solas. Las imputaciones de la media y la mediana se utilizan, respectivamente, para sustituir los valores que faltan en una columna determinada por la media y la mediana de los valores que no faltan en esa columna.
La distribución normal es el escenario ideal. Por desgracia, no siempre es así. Aquí es donde la imputación de la mediana puede ser útil porque no es sensible a los valores atípicos.
En Python, se puede utilizar la función fillna() de pandas para realizar estas sustituciones.
mean_value = sample_customer_data.mean()
mean_imputation = sample_customer_data.fillna(mean_value)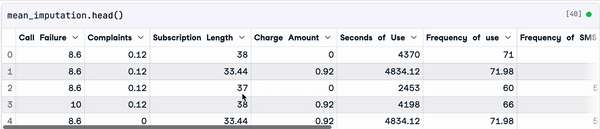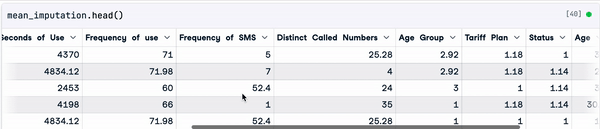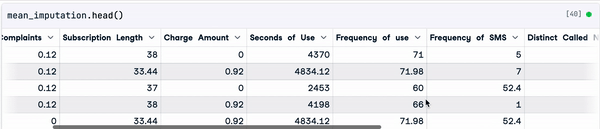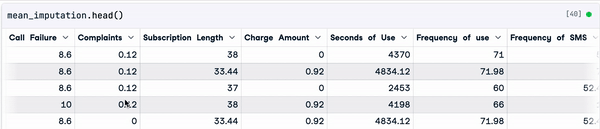
Resultado de la imputación media
median_value = sample_customer_data.median()
median_imputation = sample_customer_data.fillna(median_value)
median_imputation.head()
Resultado de la imputación mediana
La idea que subyace a la imputación de muestras aleatorias es diferente de las anteriores e implica pasos adicionales.
def random_sample_imputation(df):
cols_with_missing_values = df.columns[df.isna().any()].tolist()
for var in cols_with_missing_values:
# extract a random sample
random_sample_df = df[var].dropna().sample(df[var].isnull().sum(),
random_state=0)
# re-index the randomly extracted sample
random_sample_df.index = df[
df[var].isnull()].index
# replace the NA
df.loc[df[var].isnull(), var] = random_sample_df
return dfdf = sample_customer_data.copy()
random_sample_imp_df = random_sample_imputation(sample_customer_data)
random_sample_imp_df.head()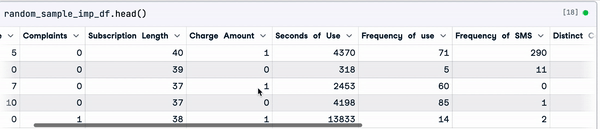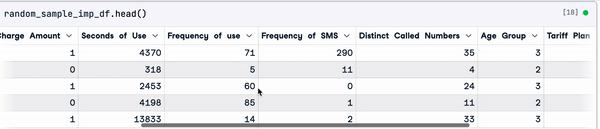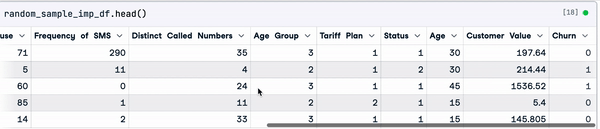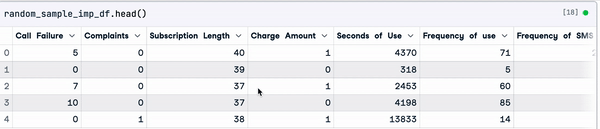
Imputación aleatoria de muestras
Se trata de una técnica de imputación multivariante, lo que significa que la información que falta se rellena teniendo en cuenta la información de las demás columnas.
Por ejemplo, si falta el valor de los ingresos de una persona, no se sabe si tiene o no una hipoteca. Por lo tanto, para determinar el valor correcto, es necesario evaluar otras características como la puntuación crediticia, la ocupación y si la persona posee o no una vivienda.
La imputación múltiple por ecuaciones encadenadas (MICE, por sus siglas en inglés) es uno de los métodos de imputación multivariante más populares. Para comprender mejor el enfoque MICE, consideremos el conjunto de variables X1, X2, ... Xn, donde algunas o todas tienen valores perdidos.
El algoritmo funciona de la siguiente manera:
La implementación se realiza utilizando la biblioteca miceforest.
En primer lugar, tenemos que instalar la biblioteca utilizando la página pip.
pip install miceforestA continuación, importamos el módulo ImputationKernel y creamos el núcleo para la imputación.
from miceforest import ImputationKernel
mice_kernel = ImputationKernel(
data = sample_customer_data,
save_all_iterations = True,
random_state = 2023
)Además, ejecutamos el núcleo en los datos durante dos iteraciones y, por último, creamos los datos imputados.
mice_kernel.mice(2)
mice_imputation = mice_kernel.complete_data()
mice_imputation.head()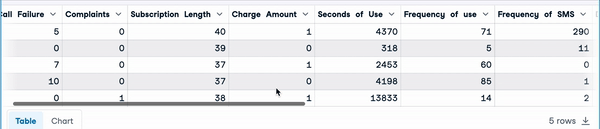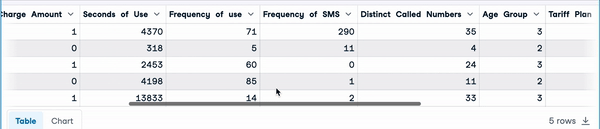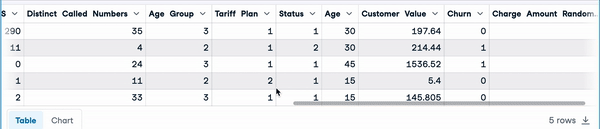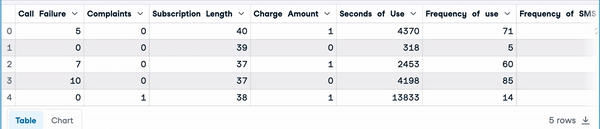
Imputación múltiple
De todas las imputaciones, es posible identificar cuál se aproxima más a la distribución de los datos originales.
La media (en amarillo) y la mediana (en rojo) están muy alejadas de la distribución original de los datos de la columna "Importe del cargo", por lo que no se consideran adecuadas para imputar los datos.
mean_imputation["Charge Amount Mean Imp"] = mean_imputation["Charge Amount"]
median_imputation["Charge Amount Median Imp"] = median_imputation["Charge Amount"]
random_sample_imp_df["Charge Amount Random Imp"] = random_sample_imp_df["Charge Amount"]Con las nuevas columnas creadas para cada tipo de imputación, ahora podemos trazar la distribución.
import matplotlib.pyplot as plt
plt.figure(figsize=(12,8))
sample_customer_data["Charge Amount"].plot(kind='kde',color='blue')
mean_imputation["Charge Amount Mean Imp"].plot(kind='kde',color='yellow')
median_imputation["Charge Amount Median Imp"].plot(kind='kde',color='red')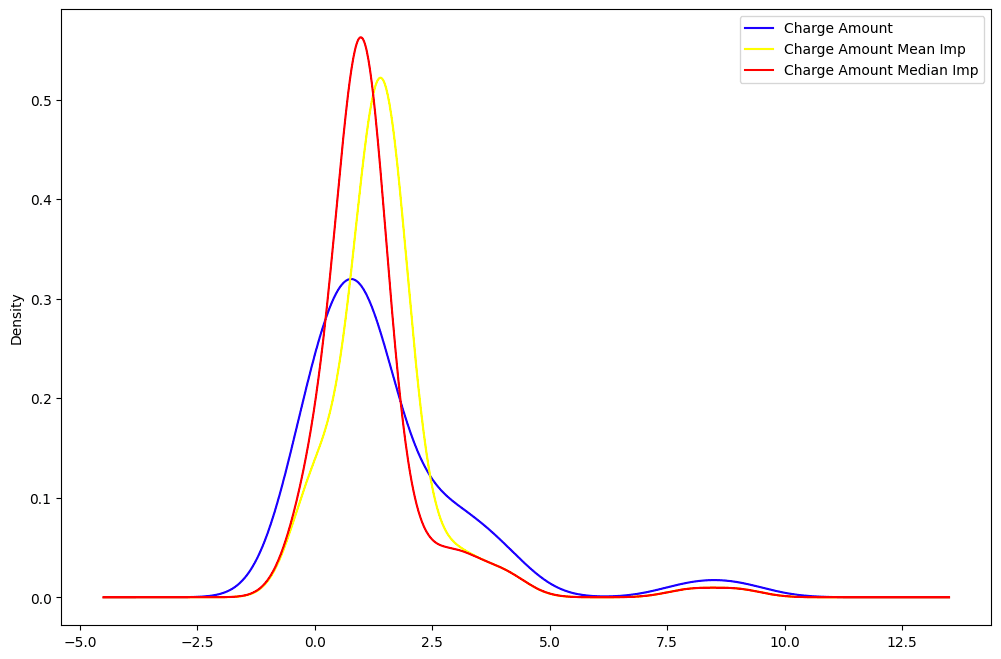
Distribución "Importe del cargo": datos originales frente a media frente a mediana.
Al trazar la imputación múltiple y la imputación aleatoria a continuación, estas distribuciones se superponen perfectamente con los datos originales. Esto significa que esas imputaciones son mejores que las imputaciones de la media y la mediana.
random_sample_imp_df["Charge Amount Random Imp"] = random_sample_imp_df["Charge Amount"]
mice_imputation["Charge Amount MICE Imp"] = mice_imputation["Charge Amount"]
mice_imputation["Charge Amount MICE Imp"].plot(kind='kde',color='black')
random_sample_imp_df["Charge Amount Random Imp"].plot(kind='kde',color='purple')
plt.legend()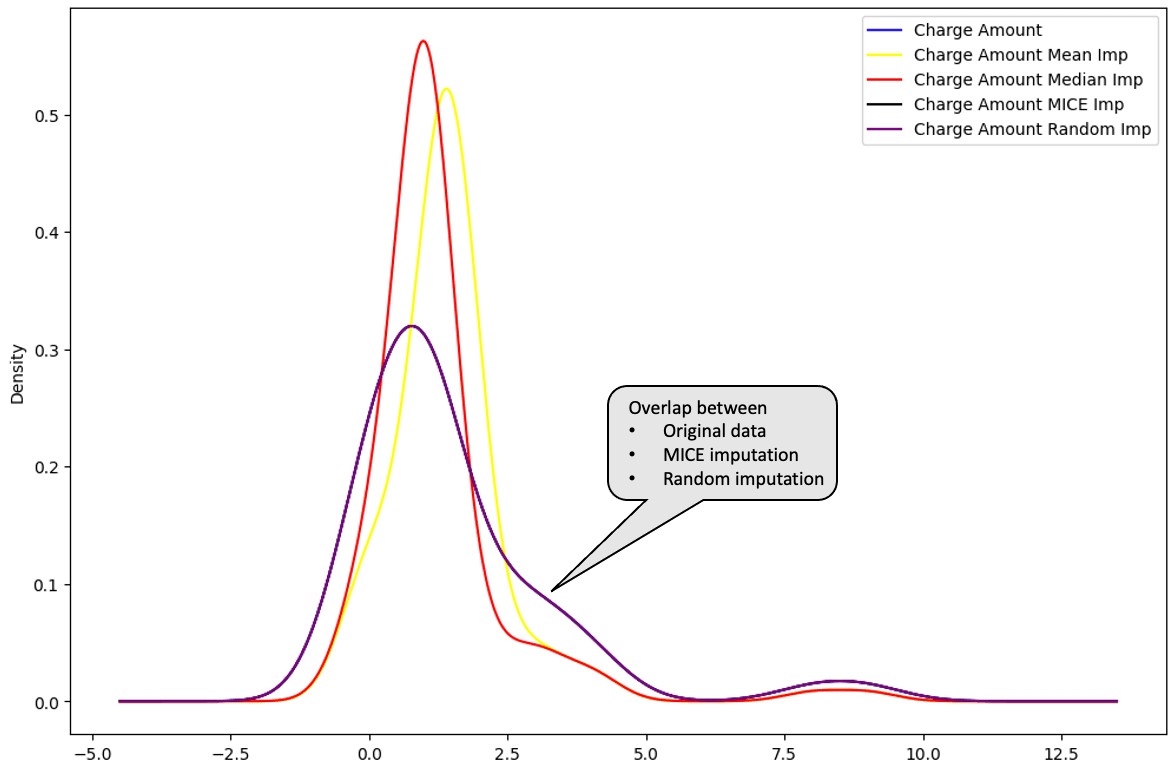
Distribución "Importe del cargo": datos originales vs. media vs. mediana vs. MICE vs.aleatorio
El curso Manejo de datos perdidos con imputaciones en R es un gran recurso para aprender más sobre estrategias para manejar valores perdidos. Cubre cómo aplicar la visualización y las pruebas estadísticas para reconocer patrones de datos perdidos y cómo imputarlos con técnicas estadísticas y de aprendizaje automático.
En la misma línea, el curso de tratamiento de datos omitidos en Python explica cómo identificar, analizar, eliminar e imputar datos omitidos en Python.
Existen múltiples estrategias de imputación, y no deben utilizarse a ciegas. Adoptar el enfoque adecuado puede evitar introducir sesgos en los datos y tomar decisiones equivocadas.
La siguiente tabla ilustra qué método de imputación utilizar en función del tipo de datos que faltan. La lista de métodos no es exhaustiva, pero éstos son los más utilizados.
|
Tipo de datos que faltan |
Método de imputación |
|
Desaparecido completamente al azar |
Media, mediana, moda o cualquier otro método de imputación |
|
Desaparecido al azar |
Imputación múltiple, Imputación por regresión |
|
Desaparecido No al azar |
Sustitución de patrones, estimación de máxima verosimilitud |
Es importante tener en cuenta que los datos originales no pueden recuperarse sea cual sea la técnica de imputación. Sin embargo, es posible utilizar técnicas capaces de generar conjuntos de datos imputados lo más parecidos posible a la realidad.
A continuación se indican algunos pasos clave a tener en cuenta durante la evaluación.
Disponer de datos de buena calidad es el objetivo de cualquier interesado y profesional de los datos.
La honestidad y la transparencia son fundamentales a la hora de comunicar los datos que faltan en el análisis. A continuación se indican algunos aspectos importantes a tener en cuenta.
En este artículo se ha tratado qué son los datos que faltan y su repercusión en el proceso de toma de decisiones basado en datos. También le ha guiado a través de algunas estrategias para manejarlos, junto con sus ventajas e inconvenientes para la toma de decisiones procesables.
Esperamos que le proporcione las estrategias pertinentes para resolver eficazmente sus problemas de falta de datos.
Cursos superiores
Curso
Curso
blog
Javier Canales Luna
14 min
blog
Matt Crabtree
9 min
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani
Tutorial
DataCamp Team

