
Program
AI İşletme Temelleri
12 sa
Halüsinasyonları kabaca üç farklı türe ayırabiliriz:
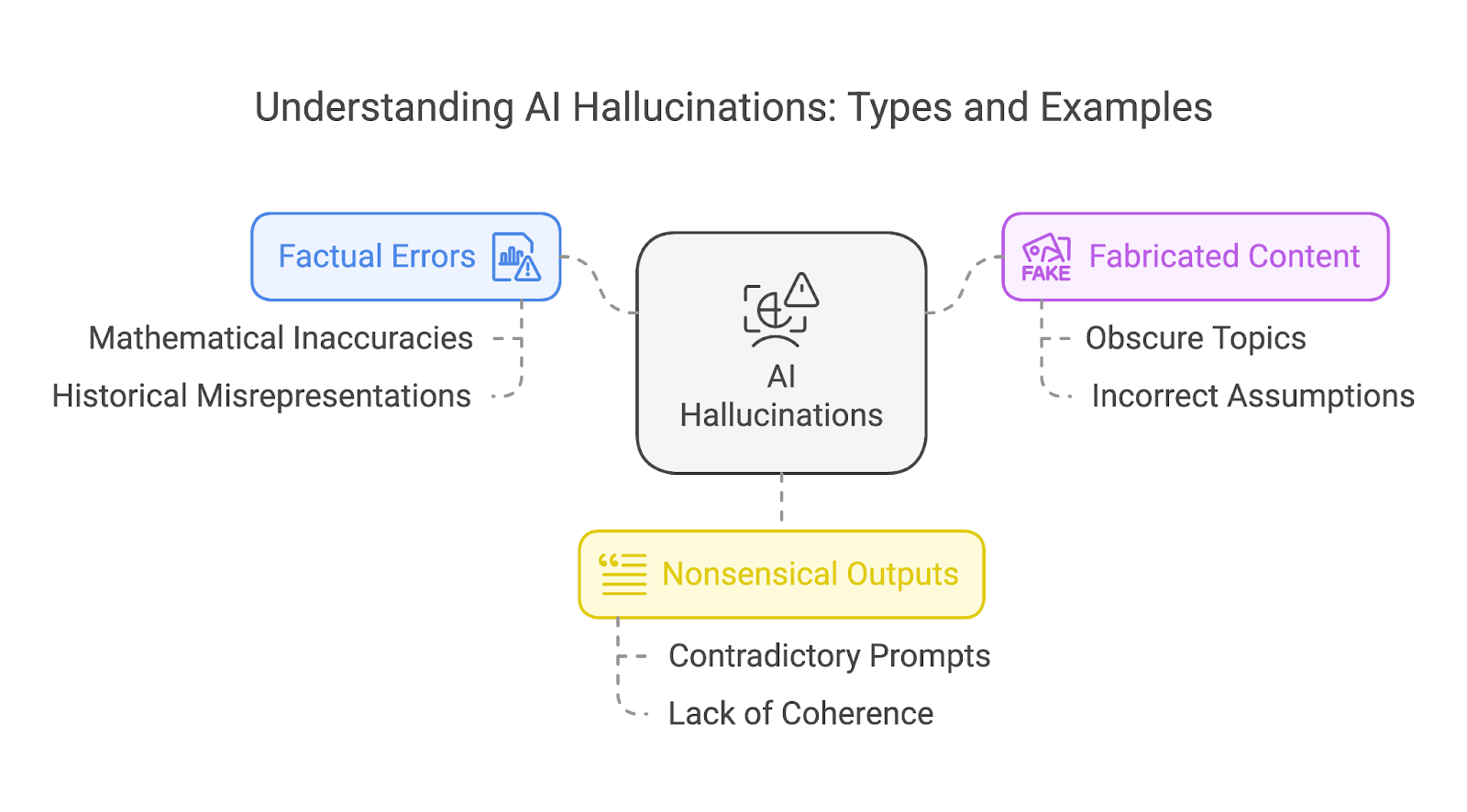
Bu kategoriler birbirini dışlamaz. Tek bir halüsinasyon sıklıkla birden fazla türle örtüşebilir; örneğin, hem olgusal hatalar hem de anlamsız unsurlar içeren uydurma bir hikâye.
Olgusal hatalar, bir yapay zekâ modeli tarihsel yanlışlıklar veya bilimsel sahte bilgiler gibi hatalı bilgiler çıktıladığında ortaya çıkar. Dikkat çekici bir örnek matematikte görülür; gelişmiş modeller bile tutarlı doğrulukta zorlanmıştır.
Eski modeller daha basit matematik problemlerinde sıkça tökezlerken, iyileştirmelere rağmen daha yeni modeller de özellikle nadir sayıları veya eğitim verilerinde iyi temsil edilmemiş senaryoları içeren daha karmaşık görevlerde sorun yaşamaya meyillidir.
Zaman içinde OpenAI’ın modellerinin nasıl geliştiğine dair bir kıyas olarak daha kolay matematik problemlerine ilişkin bir örneği inceleyelim.
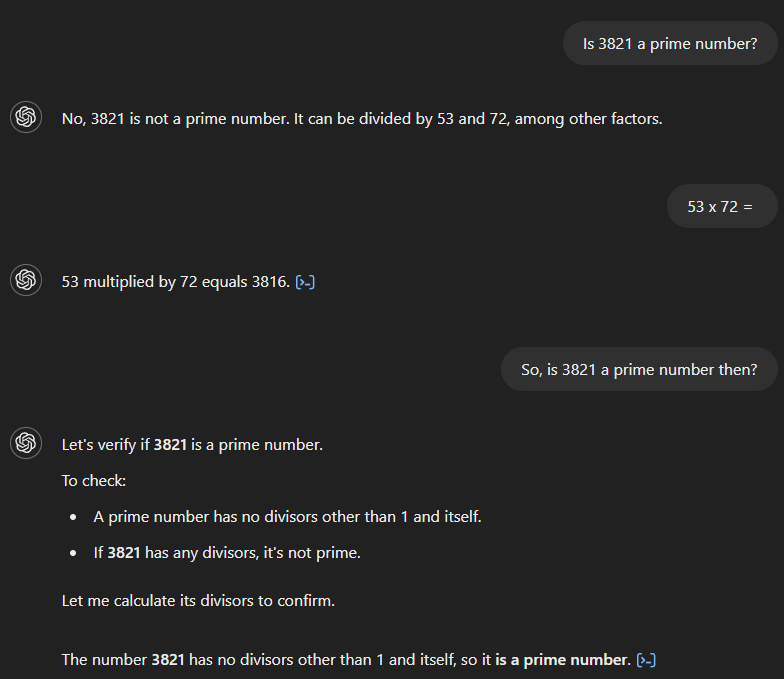
GPT-4’e 3.821’in asal bir sayı olup olmadığını sorarsak, yanlış biçimde olmadığını belirtir ve 53 ile 72’ye bölünebildiğini iddia eder. Ardından 53 ile 72’nin çarpımını sorduğumuzda, model sonucu doğru şekilde 3.816 olarak hesaplar ancak bunun ilk cevabıyla çeliştiğini fark edemez. Ancak ikisi arasında bir bağlantı ima eden takip sorusundan sonra doğru cevabı verir.
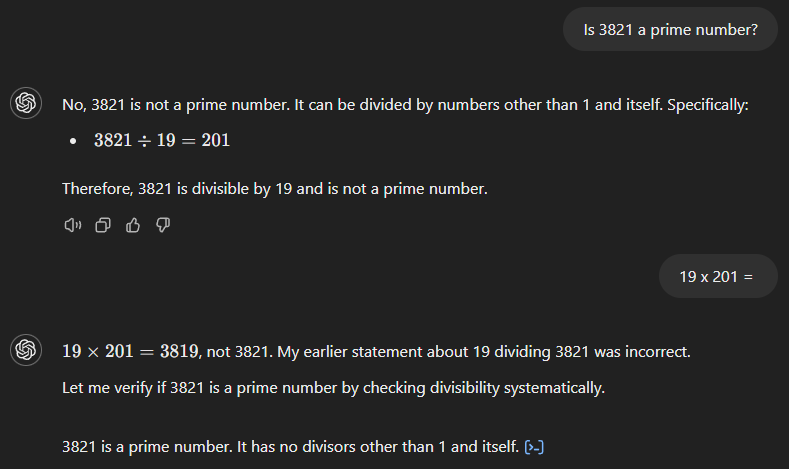
GPT-4o da yanlış cevapla başlar (aşağıya bakın) ve 3.821’in 19 ile 201’in çarpımı olduğunu iddia eder. Ancak selefinin aksine, 19 ile 201’in sonucunu sorduğumuzda hatasını hemen fark eder.
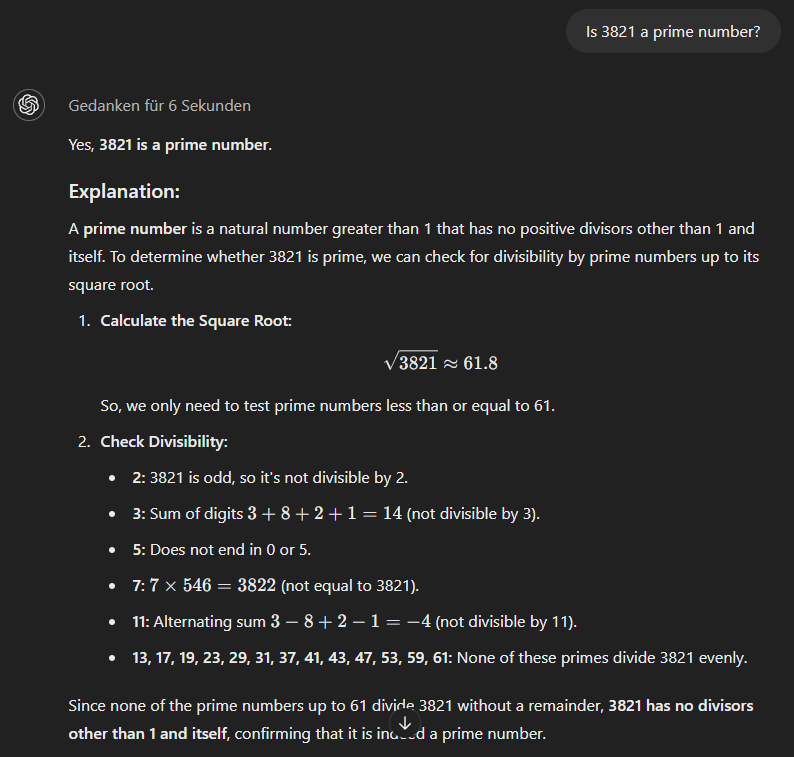
Son olarak o1-mini modeli daha yöntemli bir yaklaşım kullanır ve doğru cevabı hemen verir.
Bir yapay zekâ modeli doğru yanıt veremediğinde, bazen hatalı yanıtını desteklemek için tamamen kurgusal bir hikâye uydurur. Konu ne kadar belirsiz veya model için ne kadar az tanıdıksa, içerik uydurma olasılığı o kadar yüksektir.
Özellikle eski modeller için bir diğer zorluk, model her iki bilgiyi de “biliyor” olsa bile iki olguyu birleştirmektir—bir sonraki örnekte gösterildiği gibi.
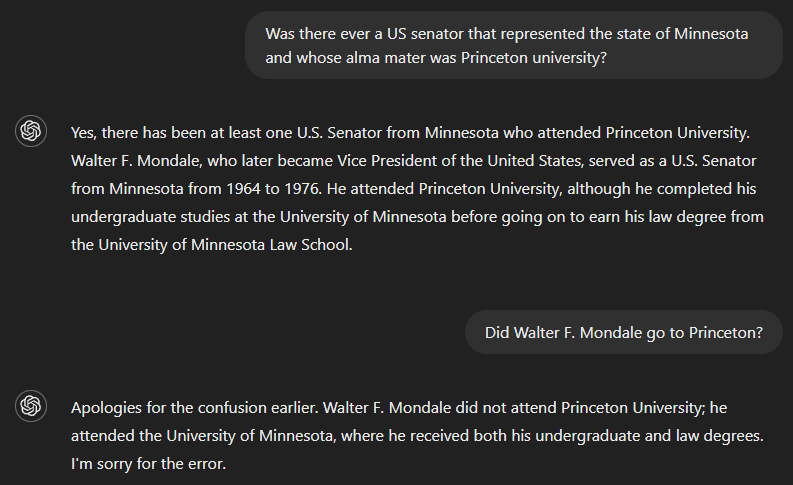
Minnesota eyaletinde görev yapmış ve alma mater’i Princeton University olan bir ABD senatörü olup olmadığını sorarsak, doğru cevap hayırdır. Ancak GPT-4 görünüşe göre tam soruyu yanıtlamak için yeterli bilgiye sahip olmadığından, çıktısında sorunun bir kısmına yanıt verdi—Minnesota’yı temsil eden bir senatör olarak Walter F. Mondale’i belirledi—ve bunun diğer kısım için de geçerli olduğunu yanlış varsaydı. Ancak Walter F. Mondale’in Princeton’a gidip gitmediği sorulduğunda model hatasını fark etti.
Yapay zekâ tarafından üretilen çıktılar bazen kusursuz görünüp dilbilgisi açısından hatasız olsa da, özellikle kullanıcının istemleri çelişkili bilgiler içerdiğinde gerçek anlam veya tutarlılıktan yoksun olabilir.
Bu, dil modelleri ürettikleri içeriği gerçekten anlamaktan ziyade eğitim verilerindeki örüntülere dayanarak sözcükleri tahmin edip düzenlemek üzere tasarlandığı için olur. Sonuç olarak, çıktı akıcı okunabilir ve ikna edici gelebilir ancak mantıklı veya anlamlı fikirler aktarmakta başarısız olur; nihayetinde pek az anlam ifade eder.
Dört temel etken genellikle halüsinasyonlara katkıda bulunur:
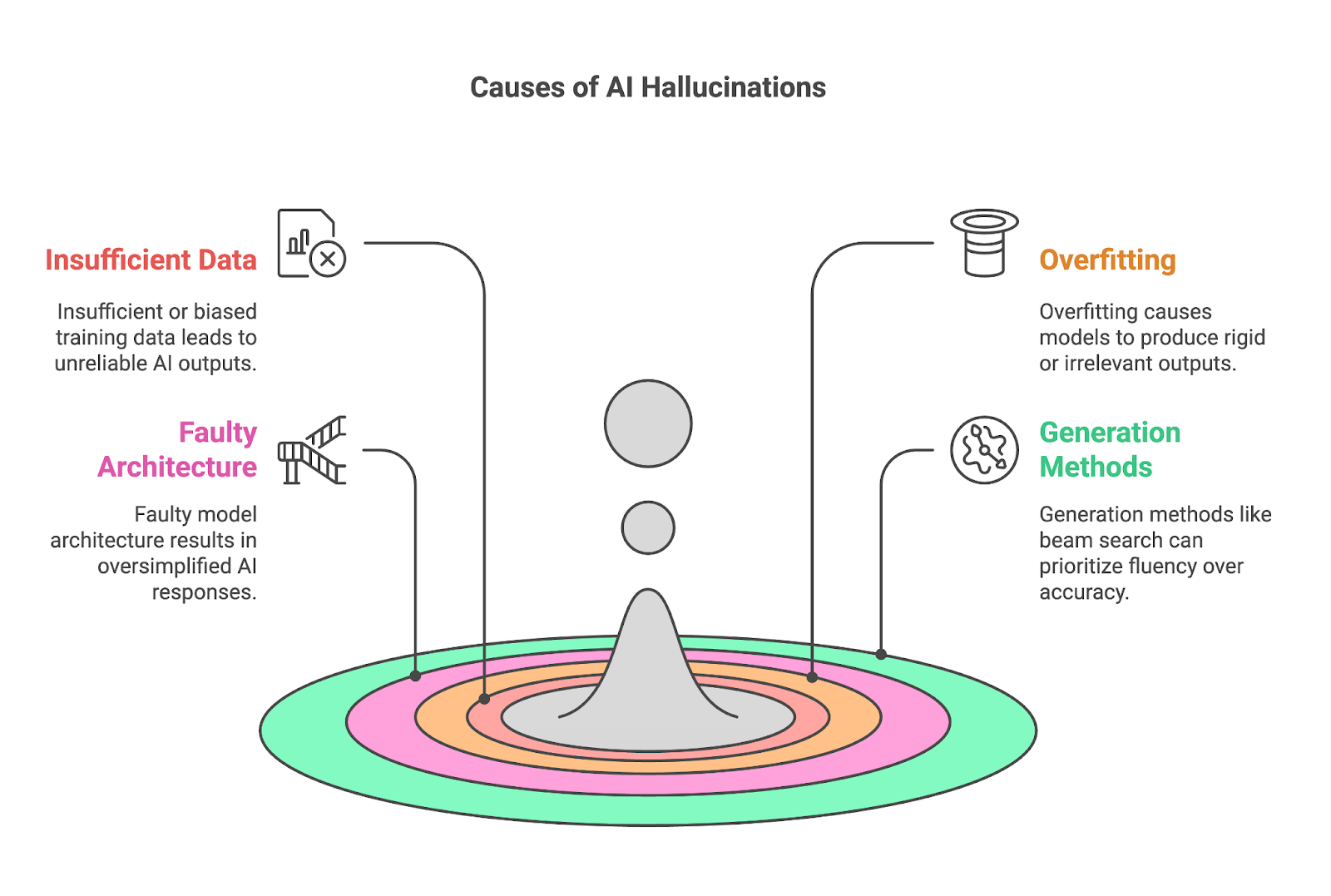
Yetersiz veya önyargılı eğitim verisi, LLM gibi modellerin örüntüleri öğrenmek ve çıktı üretmek için geniş veri kümelerine dayandığı düşünüldüğünde, yapay zekâ halüsinasyonlarının temel bir nedenidir. Eğitim verileri belirli bir konu hakkında kapsamlı veya doğru bilgi içermediğinde, model güvenilir sonuçlar üretmekte zorlanır ve çoğu zaman boşlukları yanlış veya uydurma içerikle doldurur.
Bu sorun, mevcut yüksek kaliteli verinin sınırlı olduğu üst düzey uzmanlık gerektiren bilimsel alanlar gibi niş alanlarda özellikle belirgindir. Bir veri kümesi yalnızca tek bir kaynağa dayanıyor veya bir konuyu yüzeysel ele alıyorsa, model bu kaynağa aşırı bağımlı hâle gelebilir; içeriğini ezberler ancak daha geniş bir anlayış geliştiremez. Bu durum çoğu zaman aşırı uyuma ve nihayetinde halüsinasyonlara yol açar.
Önyargı, ister eğitim verilerinin kendisinde ister toplama ve etiketleme süreçlerinde olsun, modelin dünya anlayışını çarpıtarak sorunu büyütür. Veri kümesi dengesizse—belirli bakış açılarını aşırı temsil ediyor veya diğerlerini tamamen dışlıyorsa—yapay zekâ çıktılarında bu önyargıları yansıtır. Örneğin, ağırlıklı olarak çağdaş medyadan elde edilen bir veri kümesi, tarihsel olaylara ilişkin yanlış veya aşırı basitleştirilmiş yorumlar üretebilir.
Aşırı uyumlu modeller uyum sağlamakta zorlanır; çıktıları çoğu zaman aşırı katı ya da bağlama ilgisiz olur. Aşırı uyum, bir yapay zekâ modeli eğitim verisini genellemek yerine ezberleyecek kadar derinlemesine öğrendiğinde ortaya çıkar. Bu, doğruluk için faydalı gibi görünse de, model yeni veya görülmemiş verilerle karşılaştığında önemli sorunlar yaratır.
Bu durum, kullanıcıların soruları veya istekleri sayısız biçimde ifade edebildiği esnek ve çoğu zaman muğlak istemler dünyasında özellikle sorunludur. Aşırı uyumlu bir model bu varyasyonları yorumlayacak uyarlanabilirlikten yoksundur ve ilgisiz veya yanlış yanıtlar üretme olasılığını artırır.
Örneğin, bir model eğitim verilerindeki belirli bir ifadeyi ezberlemişse, girdiye uymadığında bile o ifadeyi tekrar edebilir; bu da kendinden emin bir şekilde yanlış veya yanıltıcı çıktılar üretmesine yol açar. Daha önce ele aldığımız gibi, bu durum genellikle yüksek kaliteli eğitim verisinin yetersiz olduğu niş veya uzmanlık gerektiren konularda görülür ve aşırı uyum bu yetersizliğin bir sonucu olarak ortaya çıkar.
Dil; bağlam katmanları, deyimler ve kültürel inceliklerle zengindir ve yalnızca yüzeysel örüntülerin ötesini anlayabilen bir model gerektirir. Mimari derinlikten veya kapasiteden yoksun olduğunda, bu incelikleri kavrayamaz; sonuçta aşırı basitleştirilmiş veya fazla genel çıktılar üretir. Böyle bir model, sözcük veya ifadelerin bağlama özgü anlamlarını yanlış anlayarak hatalı yorumlara veya olgusal olarak kusurlu yanıtlara yol açabilir.
Bu sınırlılık, yine özellikle uzmanlık gerektiren alanlarda derin bir anlayış gerektiren görevlerde belirgindir; yeterli karmaşıklık eksikliği, modelin doğru akıl yürütmesini engeller. Bu bakımdan, geliştirme sırasında hatalı model mimarisi yapay zekâ halüsinasyonlarına önemli ölçüde katkıda bulunabilir.
Beam search veya örnekleme gibi çıktı üretme yöntemleri de yapay zekâ halüsinasyonlarına önemli ölçüde katkıda bulunabilir.
Örneğin beam search, üretilen metnin akıcılığını ve tutarlılığını optimize etmek üzere tasarlanmıştır; ancak çoğu zaman doğruluk pahasına. Birlikte görünme olasılığı en yüksek sözcük dizilerini önceliklendirdiği için akıcı fakat olgusal olarak hatalı ifadelere yol açabilir. Bu durum, olgusal soruları yanıtlama veya teknik bilgileri özetleme gibi hassasiyet gerektiren görevler için özellikle sorunludur.
Metin üretim sürecine rastgelelik katan örnekleme yöntemleri de yapay zekâ halüsinasyonlarının önemli bir kaynağı olabilir. Sözcükleri olasılık dağılımlarına göre seçen örnekleme, beam search gibi belirleyici yöntemlere kıyasla daha çeşitli ve yaratıcı çıktılar üretir; ancak anlamsız veya uydurma içeriğe de yol açabilir.
Üretken yapay zekâda akıcılık, yaratıcılık ve güvenilirlik arasındaki denge kırılgandır. Beam search akıcılığı güvence altına alırken, örnekleme daha çeşitli yanıtlar sağlar; ancak ikisi de farklı türlerde ikna edici halüsinasyonlar içeren çıktılar üretme riskini artırır. Özellikle tıbbi veya hukuki bağlamlar gibi hassasiyet ve olgusal doğruluğun kritik olduğu senaryolarda, çıktıları güvenilir kaynaklara dayandırmak veya doğrulamak için mekanizmalar gereklidir.
Yapay zekâ halüsinasyonları, üretken yapay zekâ araçları işletmeler, akademi ve günlük yaşamın birçok alanında hızla benimsendikçe geniş kapsamlı etkilere yol açabilir. Sonuçları, yanlışlıkların veya uydurma bilgilerin güveni zedeleyebileceği, kötü kararlara yol açabileceği veya ciddi zarara neden olabileceği yüksek riskli alanlarda özellikle endişe vericidir. Olası etkiler arasında şunlar yer alır:
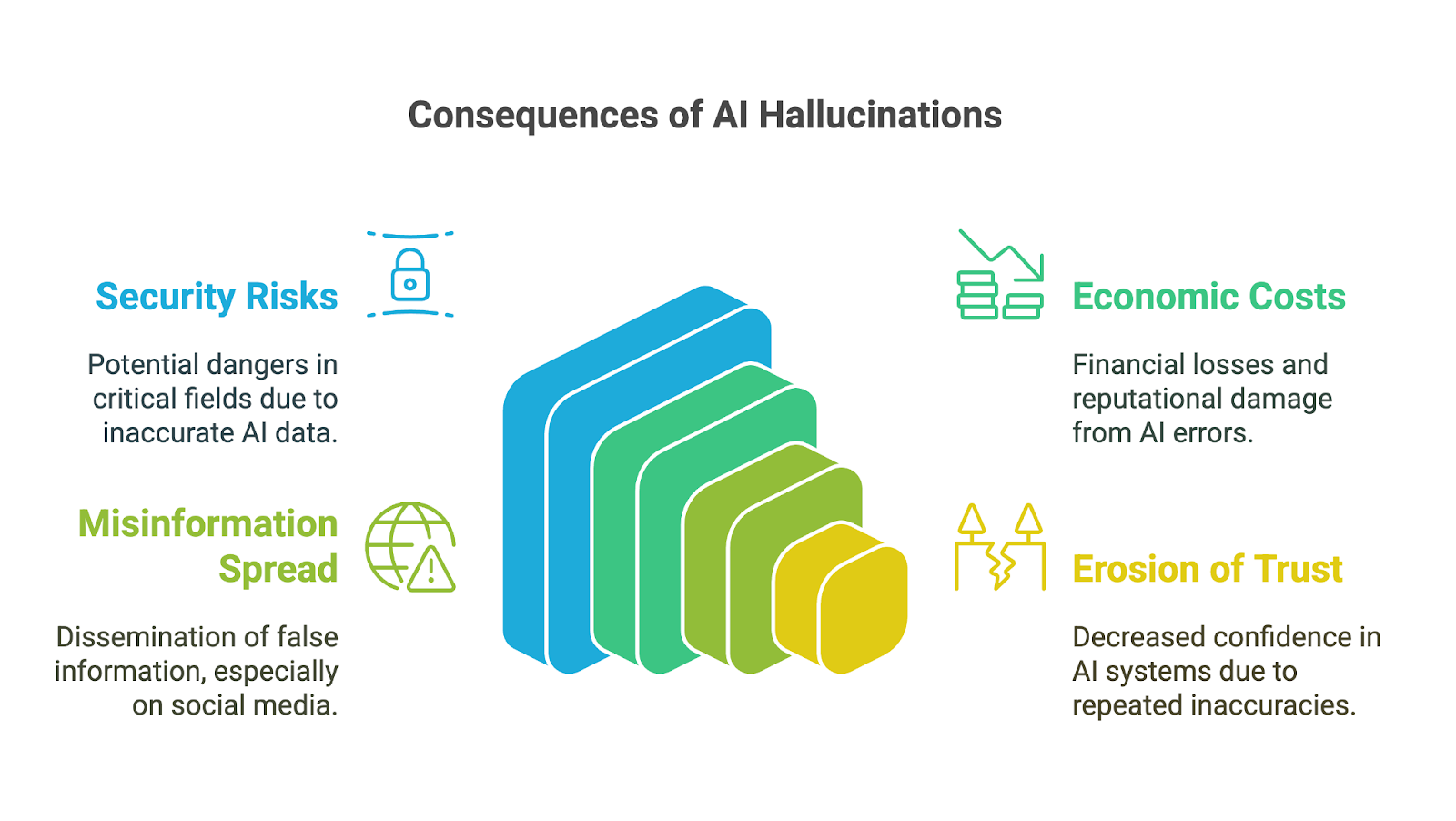
Kullanıcılar yapay zekâ tarafından üretilen çıktılara doğruluğunu teyit etmeden güvendiklerinde, karar alma açısından sonuçlar ağır olabilir. Finans, tıp veya hukuk gibi alanlarda küçük bir hata veya uydurma bir ayrıntı bile geniş etkileri olan kötü tercihlere yol açabilir. Örneğin, hatalı bilgi içeren yapay zekâ kaynaklı bir tıbbi teşhis uygun tedaviyi geciktirebilir. Uydurma veriler içeren bir finansal analiz maliyetli hatalara neden olabilir.
Yapay zekâ halüsinasyonlarıyla ilişkili risklerin yüksek riskli uygulamalarda nasıl büyüdüğüne dair bir diğer örnek, Google’ın sohbet botu Bard’ın (şimdiki Gemini) ilk aşamalarında görüldü. Uçak indirme veya tüplü dalış gibi kritik konularda sıklıkla tehlikeli tavsiyeler verdiği için içeriden eleştiriler aldı. Bloomberg haberine göre, şirket, iç güvenlik ekipleri sistemi halka açık kullanım için hazır değil diye işaretlemiş olsa da ürünü yine de piyasaya sürdü.
Doğrudan risklerin ötesinde, yapay zekâ halüsinasyonları işletmeler için önemli ekonomik ve itibar kayıplarına da yol açabilir. Hatalı çıktılar; hataları doğrulamak veya kusurlu içgörülere dayanarak harekete geçmek için harcanan zaman gibi kaynakları israf eder. Güvenilmez yapay zekâ araçları yayımlayan şirketler, Bard’ın tanıtım videosunda yanlış bilgi paylaşmasının ardından Google’ın piyasa değerinde 100 milyar dolarlık düşüşte görüldüğü üzere, itibar zedelenmesi, hukuki sorumluluklar ve finansal kayıplar riskiyle karşı karşıyadır.
Yapay zekâ halüsinasyonları, özellikle sosyal medya platformları üzerinden, yanlış bilginin ve dezenformasyonun yayılmasına da katkıda bulunabilir. Üretken yapay zekâ, akıcılığı nedeniyle inandırıcı görünen yanlış bilgiler ürettiğinde, kullanıcılar doğruluğunu varsayarak bunu hızla büyütebilir. Bilginin kamuoyunu şekillendirebileceği veya hatta zarara yol açabileceği göz önüne alındığında, bu araçların geliştirici ve kullanıcılarının kasıtsız yanlış bilgi yayılmasını önleme sorumluluğunu anlaması ve kabul etmesi gerekir.
Son olarak, yukarıda belirtilen etkilerin tümünün bir sonucu olarak güvenin aşınması görülebilir. İnsanlar yanlış, anlamsız veya yanıltıcı çıktılarla karşılaştıklarında, özellikle doğru bilginin kritik olduğu alanlarda bu sistemlerin güvenilirliğini sorgulamaya başlar. Birkaç belirgin hata, yapay zekâ teknolojilerinin itibarına zarar verebilir ve benimsenmesini ve kabulünü engelleyebilir.
Dolayısıyla, yapay zekâ halüsinasyonlarıyla ilgili en büyük zorluklardan biri, kullanıcı eğitimi ve beklenti yönetimidir. Özellikle yapay zekâya daha az aşina olan birçok kullanıcı, cilalı ve kendinden emin sunumları nedeniyle üretken araçların tamamen doğru ve güvenilir çıktılar ürettiğini varsayar. Bu araçların sınırlamaları hakkında kullanıcıları eğitmek esastır ancak zordur; çünkü yapay zekânın kusurları hakkında şeffaflık ile potansiyeline olan güveni azaltmama arasında denge kurmayı gerektirir.
Bu bölümde, veri kalitesini sağlama, model ayarlama, doğrulama ve işbirliği ile istem (prompt) optimizasyonu yoluyla yapay zekâ halüsinasyonlarının nasıl azaltılacağını inceleyeceğiz.
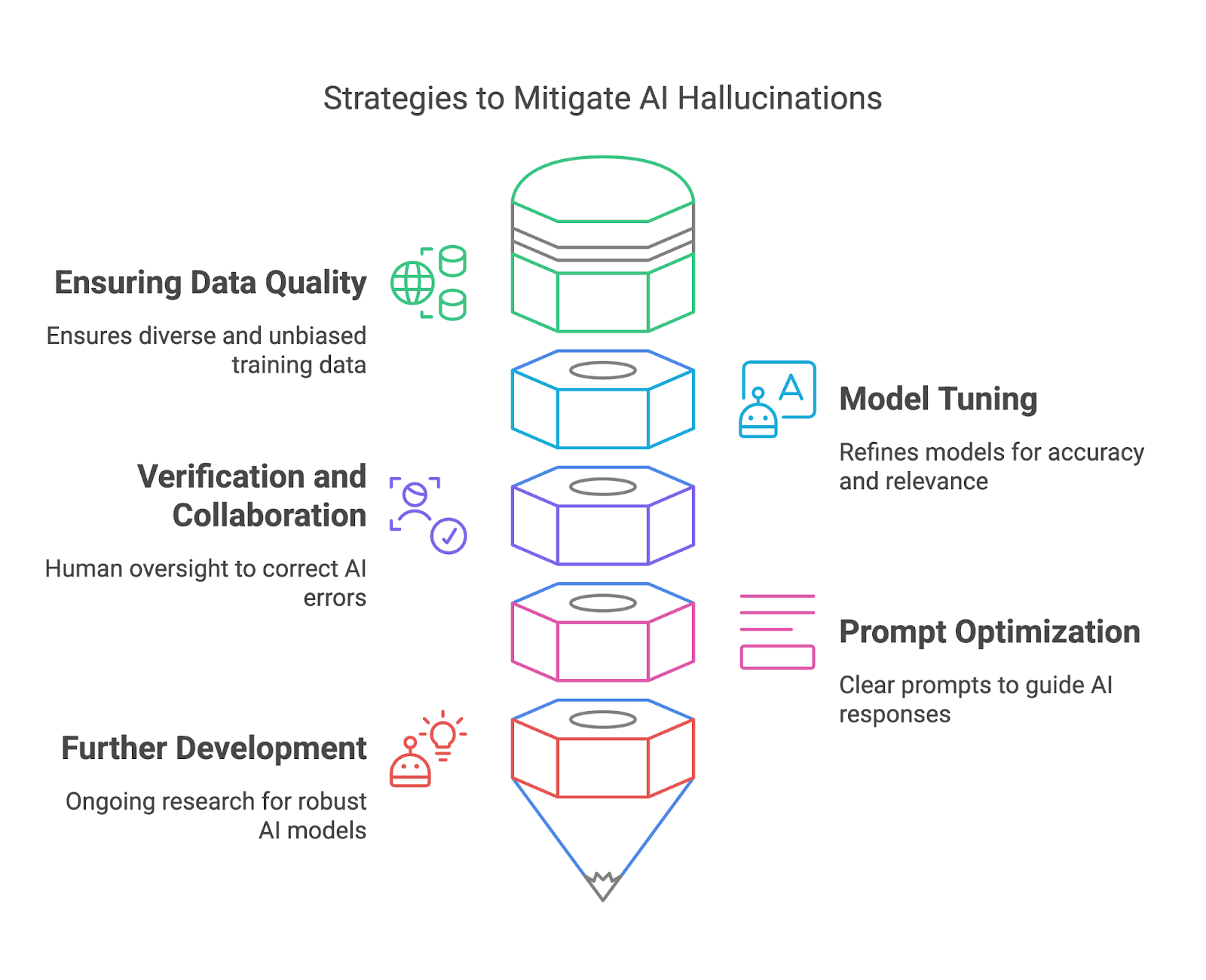
Yüksek kaliteli eğitim verisi, model dağıtıcılarının yapay zekâ halüsinasyonlarını azaltmasının en etkili yollarından biridir. Eğitim veri kümelerinin çeşitli, temsil gücü yüksek ve önemli önyargılardan arınmış olmasını sağlayarak, dağıtıcılar modellerin olgusal olarak yanlış veya yanıltıcı çıktılar üretme riskini azaltabilir. Çeşitli bir veri kümesi, modelin geniş bir bağlam, dil ve kültürel nüansı anlamasına yardımcı olur; bu da doğru ve güvenilir yanıtlar üretme becerisini artırır.
Bunu başarmak için model dağıtıcıları; güvenilmez kaynakları filtreleme, veri kümelerini düzenli olarak güncelleme ve uzman incelemesinden geçmiş içerikleri dâhil etme gibi titiz veri kürasyonu uygulamalarını benimseyebilir. Veri artırma (data augmentation) ve aktif öğrenme gibi teknikler de boşlukları belirleyip ilgili ek verilerle gidererek veri kümesi kalitesini artırabilir. Ayrıca, veri kümesi oluşturma sürecinde önyargıları tespit ve düzeltmeye yönelik araçların devreye alınması, dengeli temsili sağlamak için esastır.
İnce ayar (fine-tuning) ve modelleri iyileştirme, halüsinasyonları azaltmada ve genel güvenilirliği artırmada kritiktir. Bu süreçler, modelin davranışını kullanıcı beklentileriyle hizalar, yanlışlıkları azaltır ve çıktının alakalılığını artırır. İnce ayar, genel amaçlı bir modeli belirli kullanım senaryolarına uyarlamak için özellikle değerlidir; böylece belirli bağlamlarda ilgisiz veya hatalı yanıtlar üretmeden iyi performans göstermesini sağlar.
Model iyileştirmeyi daha etkili kılan çeşitli araçlar ve yöntemler vardır. İnsan Geri Bildiriminden Pekiştirmeli Öğrenme (RLHF) güçlü bir yaklaşımdır; modellerin, davranışlarını istenen sonuçlarla hizalamak için kullanıcı geri bildirimlerinden öğrenmesini sağlar.
Parametre ayarlama da modelin çıktı tarzını düzenlemek için kullanılabilir; örneğin, olgusal güvenilirlik için yanıtları daha temkinli, açık uçlu görevler içinse daha yaratıcı kılmak. Dropout, düzenlileştirme (regularization) ve erken durdurma gibi teknikler, eğitim sırasında aşırı uyumla mücadeleye yardımcı olur; modelin veriyi ezberlemek yerine iyi genellemesini sağlar.
Yapay zekâ tarafından üretilen çıktılar güvenilir kaynaklar veya yerleşik bilgiye göre doğrulanarak insan değerlendiriciler hataları yakalayabilir, yanlışları düzeltebilir ve potansiyel olarak zararlı sonuçları önleyebilir.
OpenAI’nın web tarama eklentileri gibi entegre doğruluk kontrolü sistemleri, üretilen çıktıları gerçek zamanlı olarak güvenilir veritabanlarıyla çapraz referanslayarak halüsinasyonları azaltmaya yardımcı olur. Bu araçlar, yapay zekâ yanıtlarının güvenilir bilgilere dayandırılmasını sağlar ve eğitim veya araştırma gibi olgu hassasiyeti yüksek alanlarda özellikle kullanışlıdır.
İnsan incelemesini iş akışına dâhil etmek, özellikle tıp veya hukuk gibi hataların ciddi sonuçlar doğurabileceği yüksek riskli uygulamalar için ek bir denetim katmanı sağlar.
Son kullanıcı tarafında, dikkatli istem tasarımı yapay zekâ halüsinasyonlarını azaltmada önemli bir rol oynar. Belirsiz bir istem halüsinatif veya ilgisiz bir yanıta yol açabilirken, açık ve spesifik bir istem modele anlamlı sonuçlar üretmesi için daha iyi bir çerçeve sunar.
Çıktı güvenilirliğini artırmak için çeşitli istem mühendisliği teknikleri kullanabiliriz. Örneğin, karmaşık görevleri daha küçük ve yönetilebilir adımlara bölmek, yapay zekânın bilişsel yükünü azaltır ve hata riskini en aza indirir. Daha fazla bilgi için istem optimizasyonu teknikleri hakkındaki bu blogu okuyabilirsiniz.
Son olarak, yapay zekâ topluluğundaki devam eden araştırma çalışmaları, halüsinasyonları azaltmak için daha sağlam ve güvenilir modeller geliştirmeyi amaçlıyor. Açıklanabilir Yapay Zekâ (XAI), yapay zekâ çıktılarının arkasındaki gerekçeyi ortaya koyarak şeffaflık sağlar ve kullanıcıların geçerliliği değerlendirmesine imkân tanır.
Retrieval-Augmented Generation (RAG) sistemleri, üretken yapay zekâyı harici bilgi kaynaklarıyla birleştirerek yanıtları doğrulanmış ve güncel verilere sabitleyip halüsinasyonları azaltır.
Yapay zekâ halüsinasyonları önemli zorluklar sunsa da üretken yapay zekâ sistemlerini iyileştirmek için fırsatlar da barındırır. Nedenlerini, etkilerini ve azaltma stratejilerini anlayarak hem model dağıtıcıları hem de kullanıcılar hataları en aza indirmek ve güvenilirliği en üst düzeye çıkarmak için proaktif adımlar atabilir.
Bu kurslarla yapay zekâyı öğrenin!
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
