
Tracks
Cơ bản về Kinh doanh Trí tuệ Nhân tạo
12 giờ
Chúng ta có thể phân loại rộng rãi ảo giác thành ba nhóm:
Các nhóm này không loại trừ lẫn nhau. Một ảo giác đơn lẻ thường có thể chồng lấp nhiều loại, chẳng hạn một câu chuyện bịa đặt cũng chứa lỗi thực tế và yếu tố vô nghĩa.
Lỗi thực tế xảy ra khi mô hình AI đưa ra thông tin không chính xác, như sai lệch lịch sử hoặc sai lầm khoa học. Một ví dụ đáng chú ý là trong toán học, nơi ngay cả các mô hình tiên tiến cũng gặp khó về độ chính xác ổn định.
Các mô hình cũ thường vấp ở bài toán đơn giản, trong khi các mô hình mới hơn, dù đã cải thiện, lại dễ gặp vấn đề với nhiệm vụ toán học phức tạp hơn—đặc biệt liên quan đến các số ít gặp hoặc tình huống không được đại diện tốt trong dữ liệu huấn luyện.
Hãy xem một ví dụ về các bài toán dễ hơn như một thước đo để thấy các mô hình của OpenAI đã cải thiện theo thời gian ra sao.
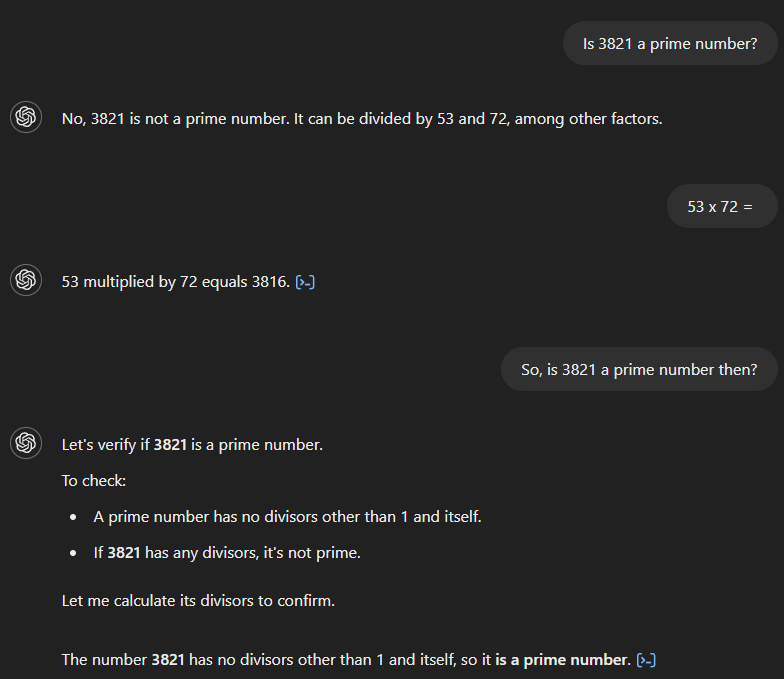
Nếu hỏi GPT-4 liệu 3.821 có phải là số nguyên tố không, nó trả lời sai rằng không và cho rằng số này chia hết cho 53 và 72. Khi yêu cầu tích của 53 và 72, mô hình tính đúng là 3.816 nhưng không nhận ra điều này mâu thuẫn với câu trả lời ban đầu. Chỉ sau một câu hỏi tiếp theo hàm ý mối liên hệ giữa hai kết quả, mô hình mới đưa ra đáp án đúng.
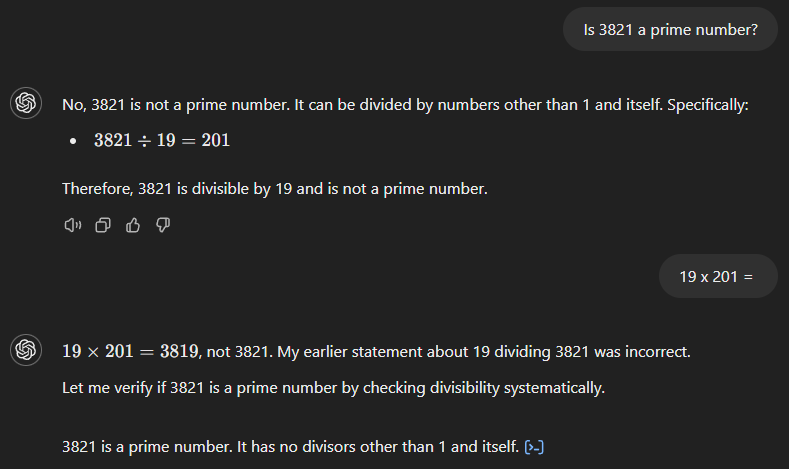
GPT-4o cũng bắt đầu với đáp án sai (xem bên dưới), cho rằng 3.821 là tích của 19 và 201. Tuy nhiên, không giống người tiền nhiệm, nó ngay lập tức nhận ra sai sót khi được hỏi kết quả của 19 nhân 201.
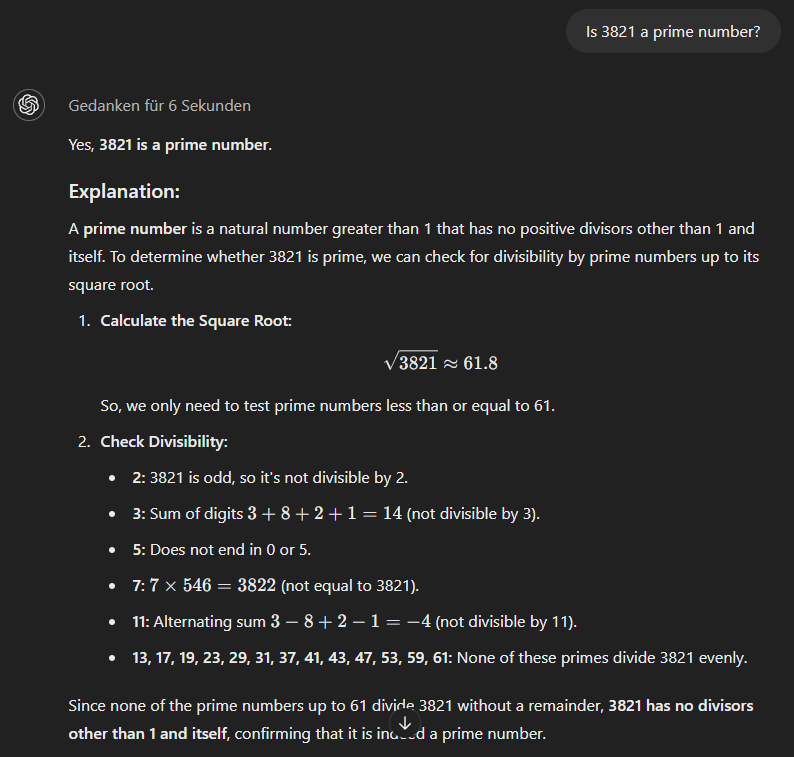
Cuối cùng, mô hình o1-mini sử dụng cách tiếp cận có phương pháp hơn và đưa ra đáp án đúng ngay lập tức.
Khi mô hình AI không thể trả lời đúng, đôi khi nó bịa ra một câu chuyện hoàn toàn hư cấu để củng cố phản hồi sai. Chủ đề càng mơ hồ hoặc kém quen thuộc, xác suất mô hình bịa nội dung càng cao.
Một thách thức khác, đặc biệt với các mô hình cũ, xuất hiện khi kết hợp hai sự kiện—ngay cả khi mô hình “biết” cả hai, như minh họa ở ví dụ tiếp theo.
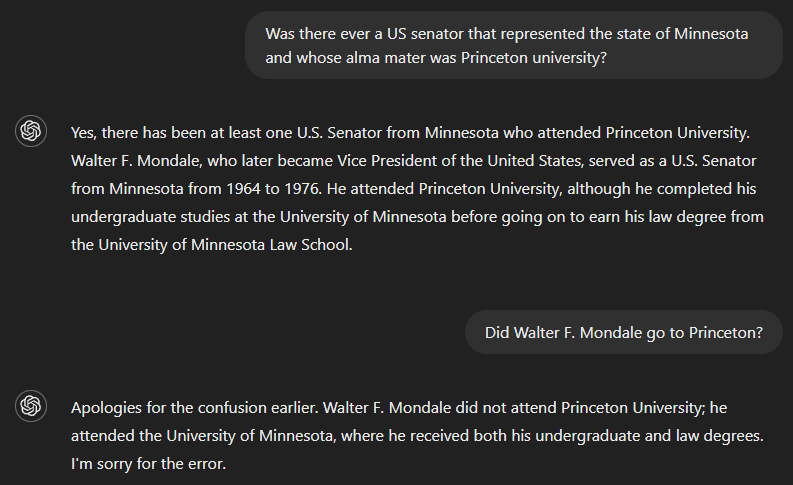
Nếu hỏi liệu đã từng có thượng nghị sĩ Hoa Kỳ phục vụ bang Minnesota và có alma mater là Đại học Princeton hay chưa, câu trả lời đúng là không. Nhưng vì GPT-4 dường như thiếu thông tin đủ để trả lời trọn vẹn, đầu ra của nó bao gồm một phần câu trả lời—xác định Walter F. Mondale là một thượng nghị sĩ đại diện Minnesota—và suy diễn sai rằng điều này cũng đúng cho phần còn lại. Tuy vậy, mô hình đã nhận ra lỗi khi được hỏi liệu Walter F. Mondale có học Princeton không.
Đầu ra do AI tạo đôi khi có vẻ trau chuốt và chuẩn ngữ pháp nhưng lại thiếu ý nghĩa hoặc tính mạch lạc thực sự, đặc biệt khi lời nhắc của người dùng chứa thông tin mâu thuẫn.
Điều này xảy ra vì các mô hình ngôn ngữ được thiết kế để dự đoán và sắp xếp từ ngữ dựa trên các mẫu trong dữ liệu huấn luyện hơn là thực sự hiểu nội dung chúng tạo ra. Kết quả là, đầu ra có thể đọc trôi chảy và nghe thuyết phục nhưng không truyền tải ý tưởng logic hoặc có ý nghĩa, rốt cuộc trở nên khó hiểu.
Bốn yếu tố chính thường góp phần gây ảo giác:
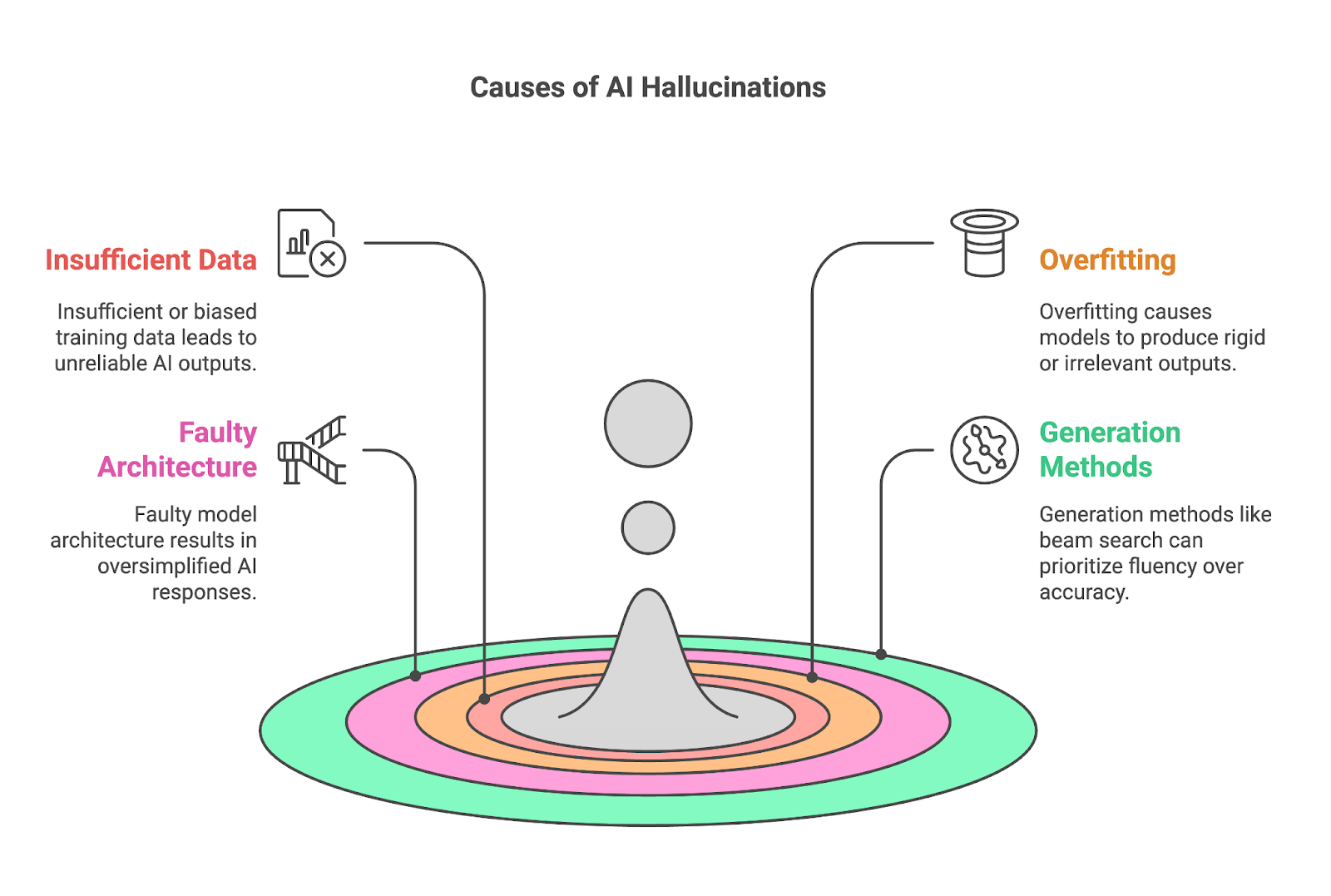
Dữ liệu huấn luyện không đủ hoặc thiên lệch là nguyên nhân cơ bản của ảo giác AI, vì các mô hình như LLM dựa vào tập dữ liệu khổng lồ để học mẫu và tạo đầu ra. Khi dữ liệu huấn luyện thiếu thông tin toàn diện hoặc chính xác về một chủ đề cụ thể, mô hình sẽ khó tạo kết quả đáng tin cậy, thường lấp đầy khoảng trống bằng nội dung sai hoặc bịa đặt.
Vấn đề này đặc biệt rõ trong các lĩnh vực ngách, như những ngành khoa học chuyên sâu, nơi lượng dữ liệu chất lượng cao sẵn có còn hạn chế. Nếu tập dữ liệu chỉ chứa một nguồn duy nhất hoặc bao quát mơ hồ một chủ đề, mô hình có thể phụ thuộc quá mức vào nguồn đó, ghi nhớ nội dung mà không có hiểu biết rộng hơn. Điều này thường dẫn đến quá khớp và cuối cùng là ảo giác.
Thiên lệch, dù nằm trong chính dữ liệu huấn luyện hay trong quá trình thu thập và gán nhãn, càng khuếch đại vấn đề bằng cách bóp méo hiểu biết của mô hình về thế giới. Nếu tập dữ liệu mất cân bằng—quá đại diện cho một số góc nhìn hoặc hoàn toàn bỏ sót những góc nhìn khác—AI sẽ phản ánh các thiên lệch đó trong đầu ra. Ví dụ, một tập dữ liệu chủ yếu lấy từ truyền thông đương đại có thể tạo ra diễn giải không chính xác hoặc đơn giản hóa quá mức các sự kiện lịch sử.
Các mô hình quá khớp khó thích ứng, thường tạo ra đầu ra hoặc quá cứng nhắc hoặc không liên quan đến ngữ cảnh. Quá khớp xảy ra khi mô hình AI học dữ liệu huấn luyện quá kỹ, đến mức ghi nhớ hơn là khái quát hóa. Dù có vẻ có lợi cho độ chính xác, điều này gây vấn đề nghiêm trọng khi mô hình gặp dữ liệu mới hoặc chưa thấy.
Điều này đặc biệt rắc rối xét tới tính linh hoạt và thường mơ hồ của lời nhắc, nơi người dùng có thể diễn đạt câu hỏi hoặc yêu cầu theo vô số cách. Một mô hình quá khớp thiếu khả năng thích nghi để diễn giải các biến thể này, làm tăng khả năng tạo phản hồi không liên quan hoặc sai lệch.
Chẳng hạn, nếu mô hình đã ghi nhớ cách diễn đạt cụ thể từ dữ liệu huấn luyện, nó có thể lặp lại cách diễn đạt đó ngay cả khi không phù hợp với đầu vào, dẫn tới tự tin tạo ra đầu ra sai hoặc gây hiểu lầm. Như đã đề cập, điều này thường xảy ra ở chủ đề ngách hoặc chuyên sâu, nơi quá khớp là hệ quả của dữ liệu huấn luyện chất lượng cao không đủ.
Ngôn ngữ, với nhiều lớp ngữ cảnh, thành ngữ và sắc thái văn hóa, đòi hỏi mô hình có khả năng hiểu hơn là các mẫu bề mặt. Khi kiến trúc thiếu chiều sâu hoặc năng lực, nó thường không nắm bắt được những tinh tế này, dẫn đến đầu ra đơn giản hóa quá mức hoặc quá chung chung. Mô hình như vậy có thể hiểu sai nghĩa theo ngữ cảnh của từ hoặc cụm, dẫn tới diễn giải sai hoặc phản hồi sai sự thật.
Một lần nữa, hạn chế này đặc biệt rõ ở các nhiệm vụ đòi hỏi hiểu biết sâu về lĩnh vực chuyên môn, nơi thiếu độ phức tạp cản trở khả năng suy luận chính xác. Theo đó, kiến trúc mô hình khiếm khuyết trong quá trình phát triển có thể góp phần đáng kể vào ảo giác AI.
Các phương pháp dùng để tạo đầu ra, như beam search hoặc sampling, cũng có thể góp phần đáng kể vào ảo giác AI.
Lấy beam search làm ví dụ, phương pháp này tối ưu độ trôi chảy và mạch lạc của văn bản sinh ra, nhưng thường đánh đổi độ chính xác. Vì ưu tiên các chuỗi từ có khả năng xuất hiện cùng nhau cao nhất, nó có thể dẫn đến câu trôi chảy nhưng sai sự thật. Điều này đặc biệt gây vấn đề cho các nhiệm vụ cần độ chính xác, như trả lời câu hỏi thực tế hoặc tóm tắt thông tin kỹ thuật.
Các phương pháp sampling, đưa tính ngẫu nhiên vào quá trình sinh văn bản, cũng có thể là nguồn gây ảo giác AI đáng kể. Bằng cách chọn từ dựa trên phân phối xác suất, sampling tạo đầu ra đa dạng và sáng tạo hơn so với phương pháp quyết định như beam search, nhưng cũng có thể dẫn đến nội dung vô nghĩa hoặc bịa đặt.
Cân bằng giữa độ trôi chảy, tính sáng tạo và độ tin cậy trong AI sinh là mong manh. Trong khi beam search đảm bảo trôi chảy và sampling cho phép phản hồi đa dạng, chúng cũng làm tăng rủi ro đầu ra chứa các dạng ảo giác thuyết phục. Đặc biệt trong bối cảnh cần độ chính xác và đúng sự thật, như y tế hoặc pháp lý, cần có cơ chế kiểm chứng hoặc neo đầu ra vào nguồn đáng tin cậy để đảm bảo thực hiện nhiệm vụ đúng đắn.
Ảo giác AI có thể tạo ra tác động sâu rộng, đặc biệt khi các công cụ AI sinh đang được áp dụng nhanh trong kinh doanh, học thuật và nhiều lĩnh vực đời sống. Hệ quả của chúng đặc biệt đáng lo trong các lĩnh vực rủi ro cao, nơi sai sót hoặc thông tin bịa đặt có thể làm xói mòn niềm tin, dẫn đến quyết định kém hoặc gây hại đáng kể. Một số hệ lụy có thể gồm:
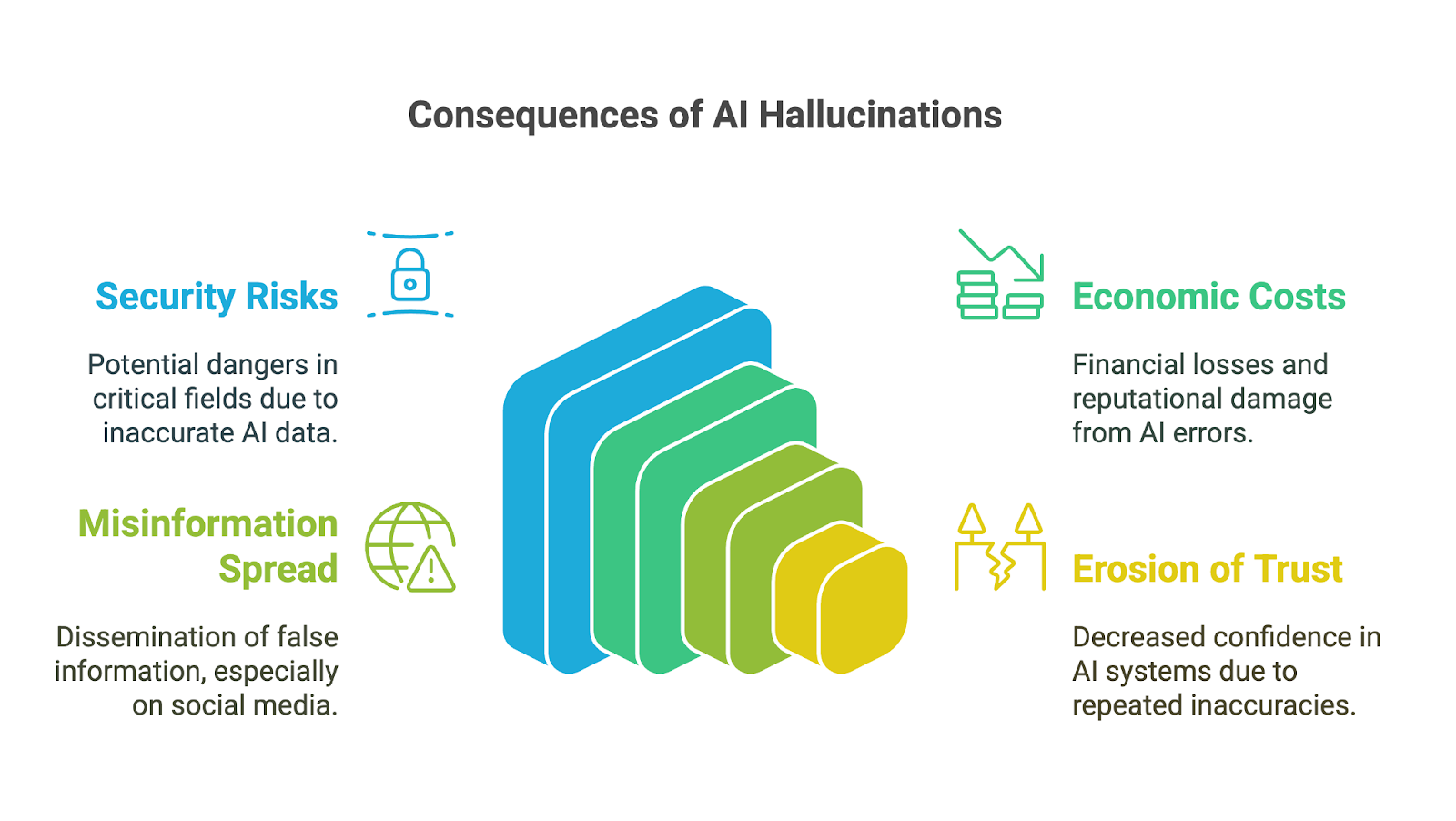
Hệ quả với việc ra quyết định có thể nghiêm trọng, đặc biệt khi người dùng dựa vào đầu ra do AI tạo mà không kiểm chứng độ chính xác. Trong các lĩnh vực như tài chính, y tế hoặc pháp luật, chỉ một sai sót nhỏ hoặc chi tiết bịa đặt cũng có thể dẫn đến lựa chọn tồi gây ảnh hưởng sâu rộng. Ví dụ, một chẩn đoán y khoa do AI tạo có chứa thông tin sai có thể làm chậm điều trị phù hợp. Một phân tích tài chính với dữ liệu bịa đặt có thể dẫn đến sai lầm tốn kém.
Một ví dụ khác cho thấy rủi ro liên quan ảo giác AI bị khuếch đại trong ứng dụng rủi ro cao có thể thấy ở giai đoạn đầu của chatbot Bard (nay là Gemini) của Google. Nó bị chỉ trích nội bộ vì thường đưa ra lời khuyên nguy hiểm về các chủ đề trọng yếu như cách hạ cánh máy bay hoặc lặn biển. Theo một báo cáo của Bloomberg, dù các nhóm an toàn nội bộ đã cảnh báo hệ thống chưa sẵn sàng cho công chúng, công ty vẫn ra mắt.
Vượt ra ngoài rủi ro tức thời, ảo giác AI còn có thể dẫn tới chi phí kinh tế và uy tín đáng kể cho doanh nghiệp. Đầu ra sai làm lãng phí nguồn lực, dù là thời gian kiểm tra lỗi hay hành động dựa trên nhận định sai. Các công ty tung ra công cụ AI không đáng tin cậy có nguy cơ tổn hại danh tiếng, trách nhiệm pháp lý và thua lỗ tài chính, như đã thấy ở việc Google mất 100 tỷ USD vốn hóa sau khi Bard chia sẻ thông tin không chính xác trong một video quảng bá.
Ảo giác AI cũng có thể góp phần lan truyền thông tin sai lệch và tin giả, đặc biệt qua các nền tảng mạng xã hội. Khi AI sinh tạo ra thông tin sai nhưng có vẻ đáng tin nhờ độ trôi chảy, nó có thể nhanh chóng được khuếch đại bởi người dùng cho rằng đó là chính xác. Vì thông tin có thể định hình dư luận hoặc thậm chí kích động gây hại, nhà phát triển và người dùng các công cụ này phải hiểu và chấp nhận trách nhiệm ngăn chặn việc phát tán sai sự thật ngoài ý muốn.
Cuối cùng, xói mòn niềm tin có thể là hệ quả của tất cả các tác động nêu trên. Khi con người gặp đầu ra sai, vô nghĩa hoặc gây hiểu lầm, họ bắt đầu nghi ngờ độ tin cậy của các hệ thống này, đặc biệt trong lĩnh vực nơi thông tin chính xác là tối quan trọng. Vài sai lầm nổi cộm có thể làm tổn hại danh tiếng của công nghệ AI và cản trở việc chấp nhận, áp dụng.
Theo đó, một trong những thách thức lớn nhất với ảo giác AI nằm ở quản lý giáo dục và kỳ vọng của người dùng. Nhiều người dùng, đặc biệt những người ít quen thuộc với AI, thường cho rằng các công cụ sinh tạo ra đầu ra hoàn toàn chính xác và đáng tin vì cách trình bày trau chuốt, tự tin. Việc giáo dục người dùng về hạn chế của các công cụ này là cần thiết nhưng phức tạp, vì đòi hỏi cân bằng giữa minh bạch về điểm chưa hoàn hảo của AI mà không làm giảm niềm tin vào tiềm năng của nó.
Trong phần này, chúng ta sẽ khám phá cách giảm thiểu ảo giác AI thông qua đảm bảo chất lượng dữ liệu, tinh chỉnh mô hình, kiểm chứng và cộng tác, cùng tối ưu lời nhắc.
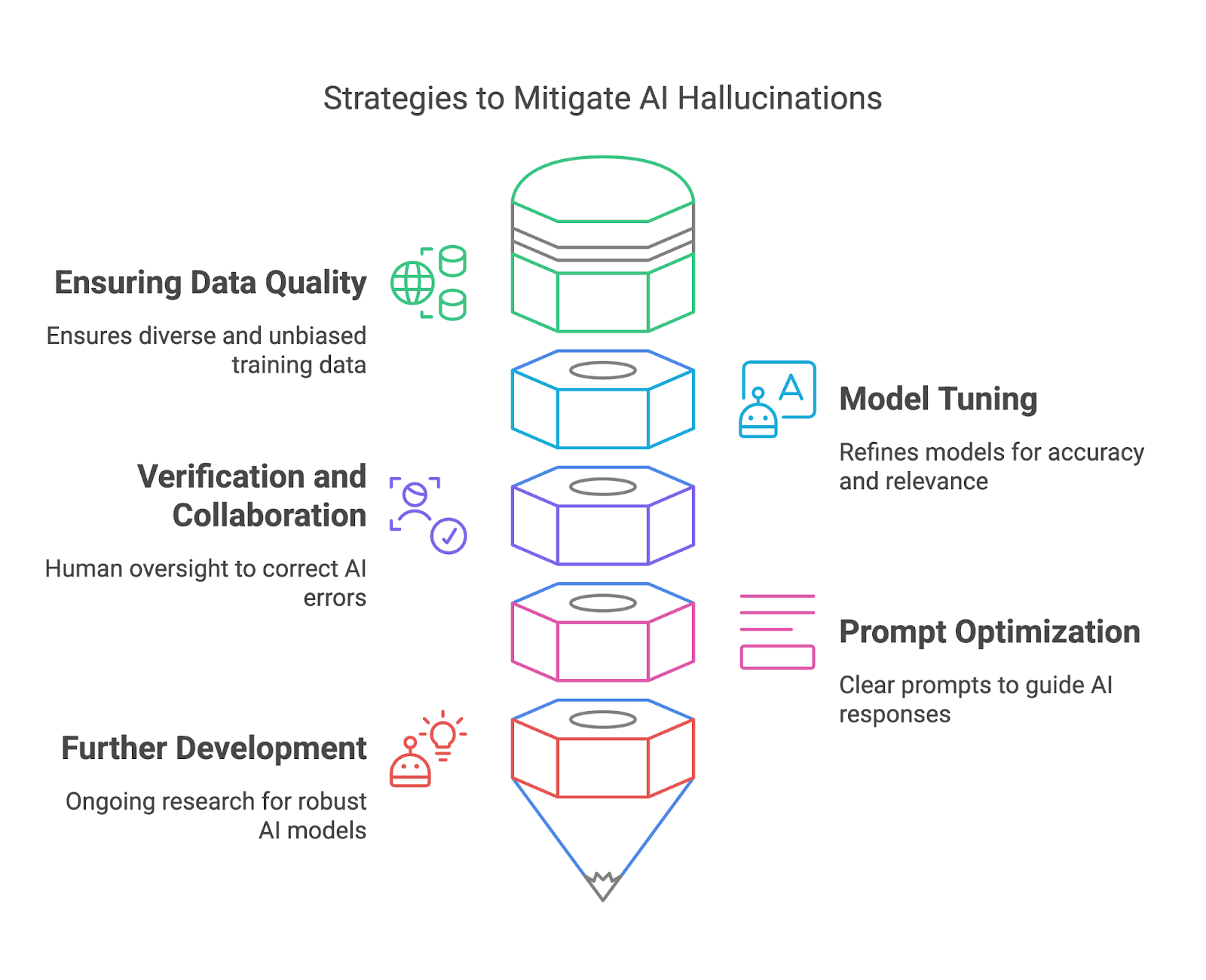
Dữ liệu huấn luyện chất lượng cao là một trong những cách hiệu quả nhất để bên triển khai mô hình giảm thiểu ảo giác AI. Bằng cách đảm bảo tập dữ liệu huấn luyện đa dạng, đại diện và không có thiên lệch đáng kể, bên triển khai có thể giảm rủi ro mô hình tạo ra đầu ra sai sự thật hoặc gây hiểu lầm. Tập dữ liệu đa dạng giúp mô hình hiểu nhiều bối cảnh, ngôn ngữ và sắc thái văn hóa, cải thiện khả năng tạo phản hồi chính xác và đáng tin cậy.
Để đạt được điều này, bên triển khai có thể áp dụng các thực hành chọn lọc dữ liệu nghiêm ngặt, như lọc bỏ nguồn không đáng tin, cập nhật tập dữ liệu thường xuyên và đưa vào nội dung do chuyên gia thẩm định. Các kỹ thuật như tăng cường dữ liệu và học chủ động cũng có thể nâng cao chất lượng tập dữ liệu bằng cách xác định khoảng trống và bổ sung dữ liệu liên quan. Hơn nữa, triển khai các công cụ phát hiện và sửa thiên lệch trong quá trình tạo tập dữ liệu là điều thiết yếu để đảm bảo tính đại diện cân bằng.
Fine-tuning và tinh luyện mô hình AI là điều thiết yếu để giảm ảo giác và cải thiện độ tin cậy tổng thể. Các quy trình này giúp điều chỉnh hành vi mô hình theo kỳ vọng người dùng, giảm sai lệch và tăng mức độ liên quan của đầu ra. Fine-tuning đặc biệt hữu ích để thích ứng mô hình mục đích chung cho ca sử dụng cụ thể, đảm bảo mô hình hoạt động tốt trong bối cảnh riêng mà không tạo phản hồi không liên quan hoặc sai.
Nhiều công cụ và phương pháp giúp tinh luyện mô hình hiệu quả hơn. Học tăng cường từ phản hồi con người (RLHF) là một cách tiếp cận mạnh mẽ, cho phép mô hình học từ phản hồi của người dùng để điều chỉnh hành vi theo kết quả mong muốn.
Điều chỉnh tham số cũng có thể được dùng để điều chỉnh phong cách đầu ra của mô hình, chẳng hạn làm phản hồi thận trọng hơn nhằm đảm bảo độ tin cậy thực tế hoặc sáng tạo hơn cho nhiệm vụ mở. Các kỹ thuật như dropout, regularization và early stopping giúp chống quá khớp trong quá trình huấn luyện, đảm bảo mô hình khái quát tốt thay vì chỉ ghi nhớ dữ liệu.
Bằng cách kiểm chứng đầu ra do AI tạo với các nguồn tin cậy hoặc tri thức đã được thiết lập, người đánh giá có thể phát hiện lỗi, sửa không chính xác và ngăn hệ quả tiềm ẩn gây hại.
Hệ thống kiểm chứng tích hợp, như plugin duyệt web của OpenAI, giúp giảm ảo giác bằng cách đối chiếu đầu ra sinh với cơ sở dữ liệu đáng tin theo thời gian thực. Các công cụ này đảm bảo phản hồi AI được neo vào thông tin đáng tin cậy, đặc biệt hữu ích cho lĩnh vực nhạy cảm với sự thật như giáo dục hoặc nghiên cứu.
Đưa đánh giá của con người vào quy trình đảm bảo thêm một lớp rà soát, đặc biệt cho các ứng dụng rủi ro cao như y tế hoặc pháp luật, nơi sai sót có thể gây hậu quả nghiêm trọng.
Về phía người dùng cuối, thiết kế lời nhắc cẩn trọng đóng vai trò quan trọng trong việc giảm ảo giác AI. Trong khi một lời nhắc mơ hồ có thể dẫn tới câu trả lời ảo giác hoặc không liên quan, lời nhắc rõ ràng và cụ thể cung cấp cho mô hình khuôn khổ tốt hơn để tạo kết quả có ý nghĩa.
Để tăng độ tin cậy của đầu ra, chúng ta có thể dùng một số kỹ thuật kỹ sư lời nhắc. Ví dụ, phân rã nhiệm vụ phức tạp thành các bước nhỏ, dễ quản lý hơn giúp giảm tải nhận thức cho AI và giảm rủi ro sai sót. Để tìm hiểu thêm, bạn có thể đọc bài viết về các kỹ thuật tối ưu lời nhắc.
Cuối cùng nhưng không kém phần quan trọng, các nỗ lực nghiên cứu liên tục trong cộng đồng AI nhằm phát triển mô hình mạnh mẽ và đáng tin cậy hơn để giảm ảo giác. AI khả giải (XAI) mang lại tính minh bạch bằng cách tiết lộ lập luận đằng sau đầu ra AI, cho phép người dùng đánh giá tính hợp lệ.
Hệ thống Retrieval-Augmented Generation (RAG), kết hợp AI sinh với nguồn tri thức bên ngoài, giảm ảo giác bằng cách neo phản hồi vào dữ liệu đã kiểm chứng và cập nhật.
Mặc dù ảo giác AI đặt ra những thách thức đáng kể, chúng cũng mở ra cơ hội để tinh chỉnh và cải thiện các hệ thống AI sinh. Bằng cách hiểu nguyên nhân, tác động và chiến lược giảm thiểu, cả bên triển khai mô hình lẫn người dùng đều có thể chủ động giảm thiểu sai sót và tối đa hóa độ tin cậy.
Học AI với các khóa học này!
Tracks
Tracks
Courses