
Program
Dasar-Dasar Bisnis Kecerdasan Buatan
12 Hr
Secara garis besar, kita dapat mengelompokkan halusinasi menjadi tiga jenis:
Kategori-kategori ini tidak saling eksklusif. Satu halusinasi sering kali tumpang tindih dengan beberapa jenis, seperti cerita yang dibuat-buat yang juga memuat kesalahan faktual dan elemen tidak masuk akal.
Kesalahan faktual terjadi ketika model AI menghasilkan informasi yang salah, seperti ketidakakuratan sejarah atau kesalahan sains. Contoh mencolok terjadi pada matematika, di mana bahkan model canggih pun kesulitan menjaga konsistensi akurasi.
Model lama sering tersandung pada soal matematika sederhana, sementara model yang lebih baru, meski mengalami peningkatan, cenderung bermasalah pada tugas matematika yang lebih kompleks—terutama yang melibatkan angka yang jarang ditemui atau skenario yang kurang terwakili dalam data latihannya.
Mari kita lihat contoh soal matematika yang lebih mudah sebagai tolok ukur bagaimana model-model OpenAI membaik dari waktu ke waktu.
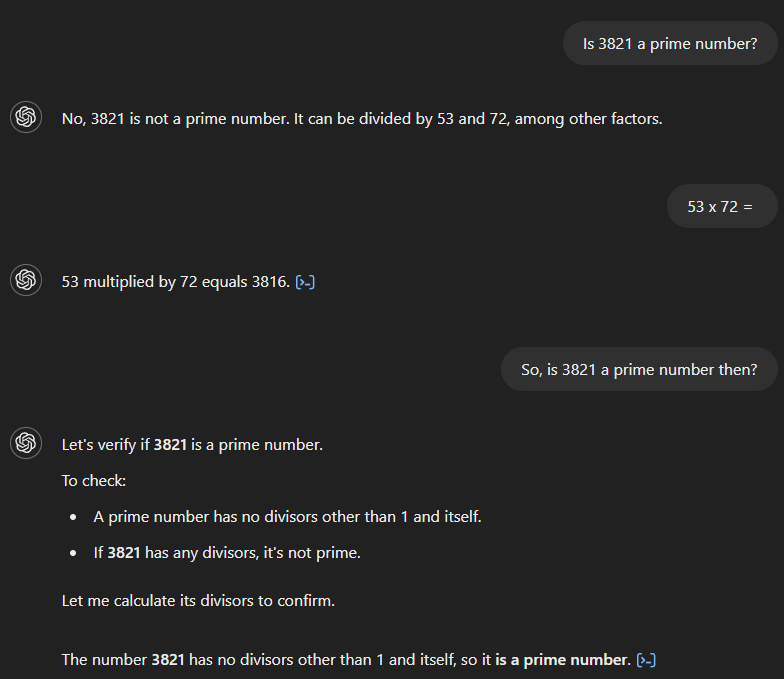
Jika kita bertanya kepada GPT-4 apakah 3.821 adalah bilangan prima, ia secara keliru menyatakan bukan dan mengklaim angka tersebut habis dibagi 53 dan 72. Jika kemudian kita minta hasil perkalian 53 dan 72, model dengan benar menghitung 3.816, tetapi gagal menyadari bahwa hal ini bertentangan dengan jawabannya semula. Barulah setelah pertanyaan lanjutan yang menyiratkan keterkaitan keduanya, model memberikan jawaban yang benar.
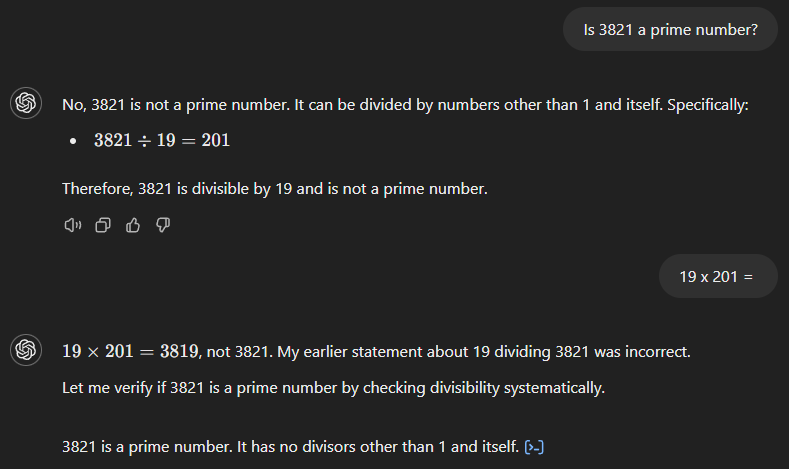
GPT-4o juga memulai dengan jawaban yang salah (lihat di bawah), mengklaim bahwa 3.821 adalah hasil kali 19 dan 201. Namun, berbeda dengan pendahulunya, ia langsung menyadari kesalahannya saat kita minta hasil 19 kali 201.
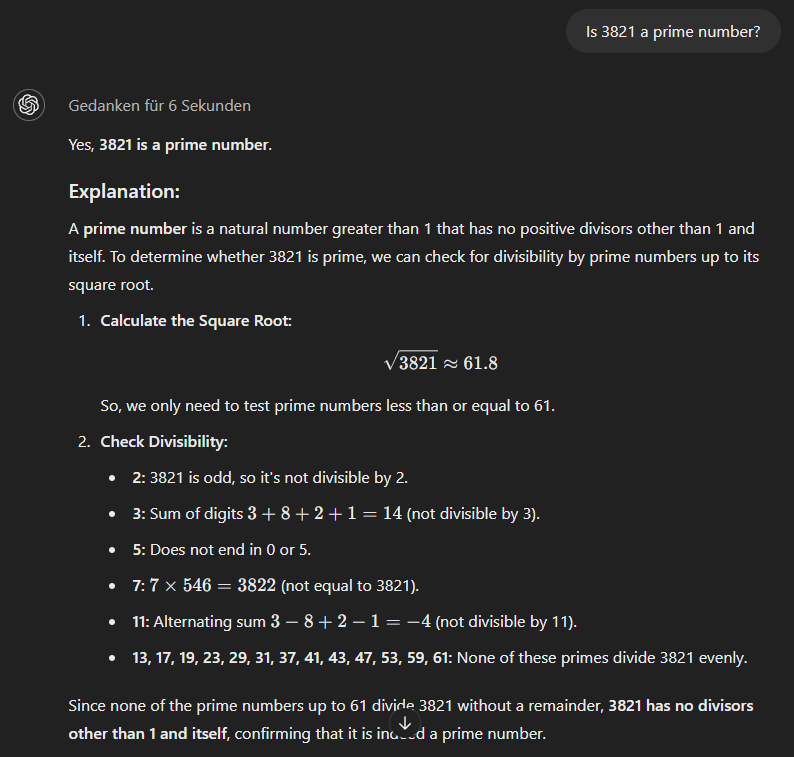
Model o1-mini akhirnya menggunakan pendekatan yang lebih metodis dan langsung memberikan jawaban yang benar.
Ketika model AI tidak dapat menjawab dengan benar, terkadang ia mengarang cerita fiksi sepenuhnya untuk mendukung respons yang salah. Semakin samar atau kurang dikenal topiknya, semakin tinggi kemungkinan model mengarang konten.
Tantangan lain, terutama pada model lama, muncul saat menggabungkan dua fakta—bahkan jika model “mengetahui” keduanya, seperti yang ditunjukkan dalam contoh berikutnya.
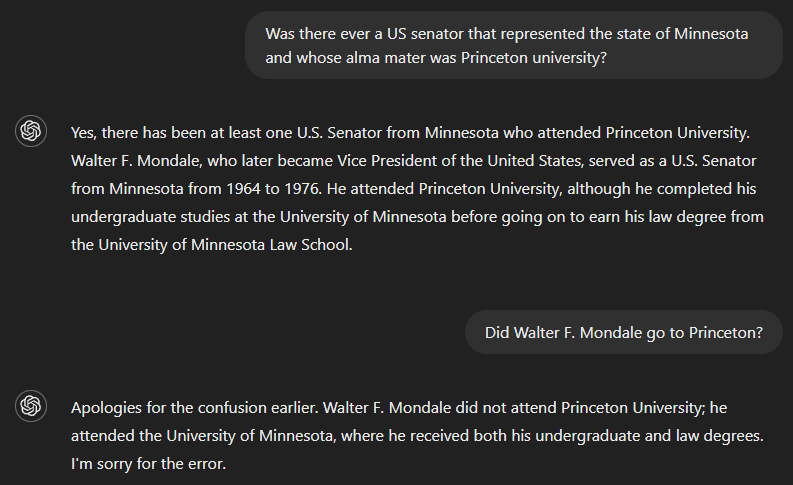
Jika kita bertanya apakah pernah ada senator AS yang mewakili negara bagian Minnesota dan almamaternya Princeton University, jawaban yang benar adalah tidak. Namun karena GPT-4 tampaknya kekurangan informasi untuk menjawab seluruh pertanyaan, keluarannya berisi jawaban untuk sebagian pertanyaan—mengidentifikasi Walter F. Mondale sebagai senator yang mewakili Minnesota—dan secara keliru mengasumsikan hal itu juga berlaku untuk bagian lainnya. Namun, model menyadari kesalahannya ketika ditanya apakah Walter F. Mondale berkuliah di Princeton.
Keluaran yang dihasilkan AI kadang tampak rapi dan tata bahasanya sempurna, namun kurang bermakna atau tidak koheren, khususnya ketika prompt pengguna memuat informasi yang saling bertentangan.
Hal ini terjadi karena model bahasa dirancang untuk memprediksi dan menyusun kata berdasarkan pola dalam data latihannya, bukan benar-benar memahami konten yang dihasilkannya. Akibatnya, keluaran bisa terbaca lancar dan terdengar meyakinkan namun gagal menyampaikan gagasan yang logis atau bermakna, sehingga pada akhirnya tidak masuk akal.
Ada empat faktor kunci yang sering berkontribusi pada halusinasi:
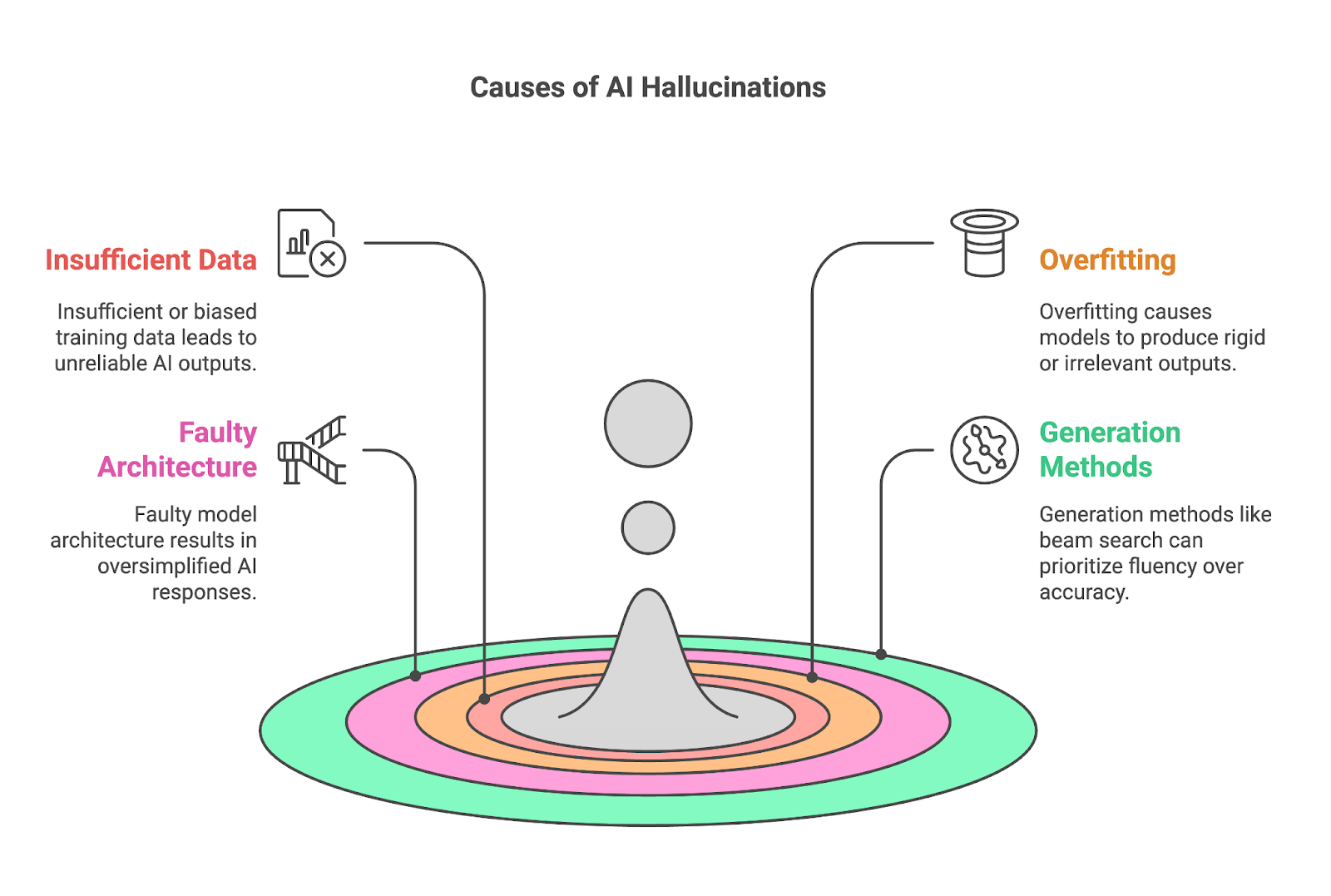
Data pelatihan yang tidak memadai atau bias merupakan penyebab mendasar halusinasi AI, karena model seperti LLM bergantung pada himpunan data besar untuk mempelajari pola dan menghasilkan keluaran. Ketika data pelatihan kurang komprehensif atau akurat tentang suatu topik, model kesulitan menghasilkan hasil yang andal, sehingga sering menutup celah dengan konten yang salah atau dibuat-buat.
Masalah ini sangat menonjol pada domain khusus, seperti bidang ilmiah yang sangat terspesialisasi, di mana data berkualitas tinggi yang tersedia terbatas. Jika sebuah dataset hanya berisi satu sumber atau cakupan topiknya samar, model mungkin terlalu bergantung pada sumber tersebut, menghafal kontennya tanpa memperoleh pemahaman yang lebih luas. Ini sering berujung pada overfitting dan, pada akhirnya, halusinasi.
Bias, baik dalam data pelatihan itu sendiri maupun dalam proses pengumpulan dan pelabelannya, memperparah masalah dengan membelokkan pemahaman model tentang dunia. Jika dataset tidak seimbang—terlalu merepresentasikan sudut pandang tertentu atau sama sekali mengabaikan yang lain—AI akan mencerminkan bias tersebut dalam keluarannya. Misalnya, dataset yang terutama bersumber dari media kontemporer dapat menghasilkan interpretasi peristiwa sejarah yang tidak akurat atau terlalu disederhanakan.
Model yang overfitted kesulitan beradaptasi, sering menghasilkan keluaran yang terlalu kaku atau tidak relevan dengan konteks. Overfitting terjadi ketika model AI mempelajari data latihannya terlalu mendalam, hingga pada tingkat menghafal alih-alih menggeneralisasi. Meskipun tampak menguntungkan bagi akurasi, hal ini menimbulkan masalah besar saat model menghadapi data baru atau yang belum pernah terlihat.
Ini sangat bermasalah mengingat sifat prompt yang fleksibel dan sering ambigu, di mana pengguna dapat mengajukan pertanyaan atau permintaan dalam berbagai cara. Model yang overfitted kurang memiliki kemampuan beradaptasi untuk menafsirkan variasi ini, meningkatkan kemungkinan keluaran yang tidak relevan atau salah.
Sebagai contoh, jika model telah menghafal frasa tertentu dari data latihannya, ia mungkin mengulang frasa tersebut meskipun tidak selaras dengan masukan, sehingga dengan yakin menghasilkan keluaran yang salah atau menyesatkan. Seperti yang sudah kita bahas, ini sering terjadi pada topik khusus atau terspesialisasi, di mana overfitting muncul sebagai konsekuensi dari data pelatihan berkualitas tinggi yang tidak memadai.
Bahasa, dengan lapisan konteks, idiom, dan nuansa budaya yang kaya, menuntut model yang mampu memahami lebih dari sekadar pola permukaan. Ketika arsitekturnya kurang dalam atau kapasitasnya terbatas, model sering gagal menangkap nuansa tersebut, menghasilkan keluaran yang terlalu disederhanakan atau terlalu generik. Model seperti ini dapat salah memahami makna kata atau frasa yang spesifik konteks, sehingga memicu interpretasi yang keliru atau respons yang salah secara faktual.
Sekali lagi, keterbatasan ini sangat terlihat pada tugas yang memerlukan pemahaman mendalam atas bidang khusus, di mana kurangnya kompleksitas menghambat kemampuan penalaran model secara akurat. Dengan demikian, arsitektur model yang cacat selama pengembangan dapat berkontribusi signifikan terhadap halusinasi AI.
Metode yang digunakan untuk menghasilkan keluaran, seperti beam search atau sampling, juga dapat berkontribusi signifikan terhadap halusinasi AI.
Ambil contoh beam search, yang dirancang untuk mengoptimalkan kefasihan dan koherensi teks yang dihasilkan, namun sering kali mengorbankan akurasi. Karena memprioritaskan urutan kata yang paling mungkin muncul bersama, metode ini dapat menghasilkan pernyataan yang fasih tetapi salah secara faktual. Ini sangat bermasalah untuk tugas yang memerlukan presisi, seperti menjawab pertanyaan faktual atau merangkum informasi teknis.
Metode sampling, yang memasukkan unsur acak ke dalam proses generasi teks, juga bisa menjadi sumber halusinasi AI yang signifikan. Dengan memilih kata berdasarkan distribusi probabilitas, sampling menghasilkan keluaran yang lebih beragam dan kreatif dibanding metode deterministik seperti beam search, namun juga dapat memicu konten yang tidak masuk akal atau dibuat-buat.
Keseimbangan antara kefasihan, kreativitas, dan keandalan dalam AI generatif sangat rapuh. Sementara beam search menjamin kefasihan dan sampling memungkinkan respons yang beragam, keduanya juga meningkatkan risiko keluaran berisi halusinasi yang meyakinkan dalam berbagai bentuk. Terutama pada skenario yang menuntut presisi dan kebenaran faktual, seperti konteks medis atau hukum, mekanisme untuk memverifikasi atau meletakkan dasar keluaran pada sumber tepercaya diperlukan agar tugas terlaksana dengan benar.
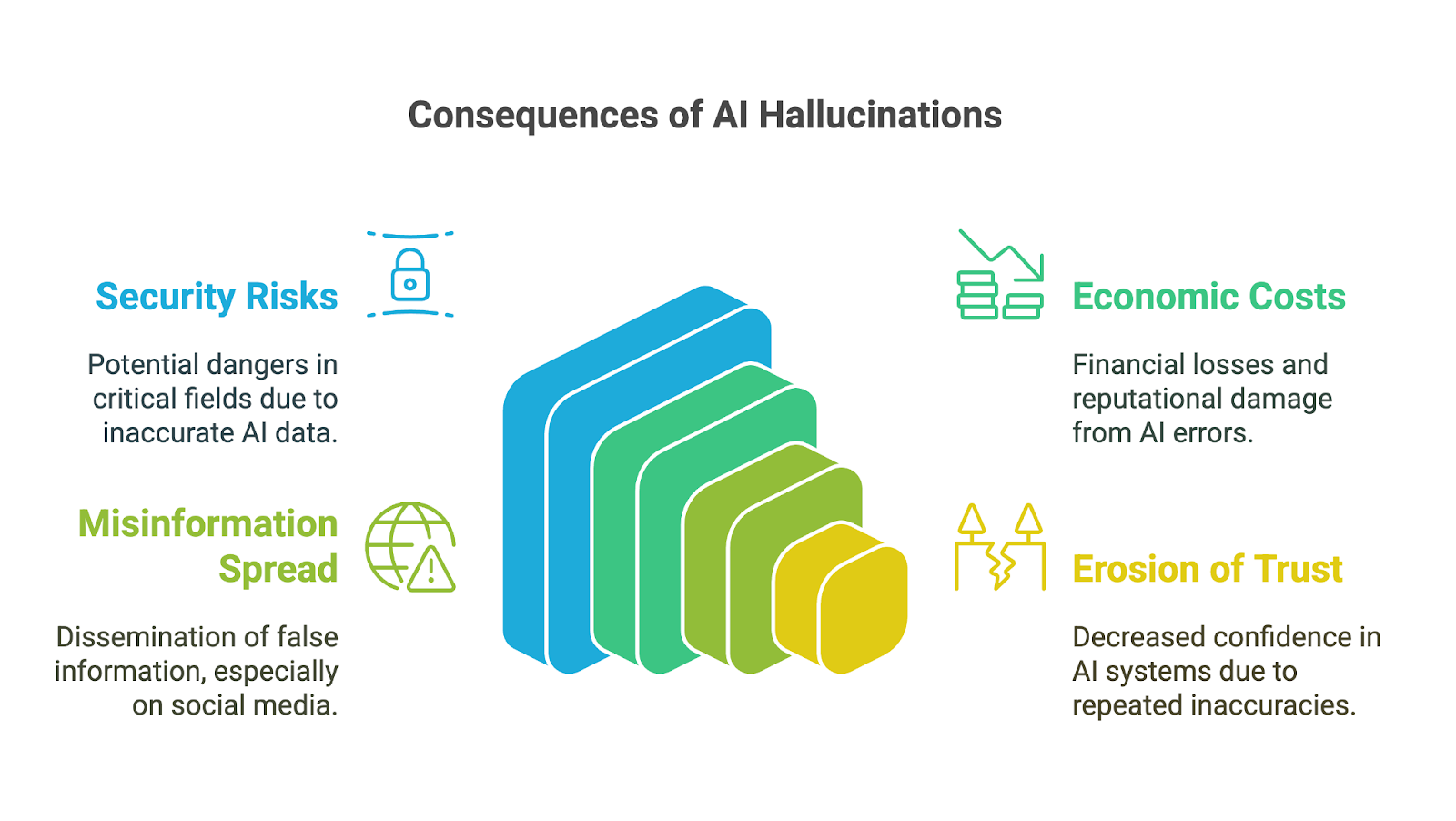
Halusinasi AI dapat berdampak luas, terutama karena alat AI generatif diadopsi dengan cepat di dunia bisnis, akademik, dan berbagai bidang kehidupan sehari-hari. Konsekuensinya sangat mengkhawatirkan di bidang berisiko tinggi, di mana ketidakakuratan atau informasi yang dibuat-buat dapat merusak kepercayaan, memicu keputusan buruk, atau menimbulkan dampak besar. Di antara implikasi yang mungkin terjadi adalah:
Konsekuensi terhadap pengambilan keputusan bisa parah, terutama ketika pengguna mengandalkan keluaran AI tanpa memverifikasi akurasinya. Di bidang seperti keuangan, kedokteran, atau hukum, bahkan kesalahan kecil atau detail yang dibuat-buat dapat memicu pilihan buruk dengan dampak luas. Misalnya, diagnosis medis yang dihasilkan AI dan memuat informasi keliru dapat menunda perawatan yang tepat. Analisis keuangan dengan data yang dibuat-buat dapat berujung pada kesalahan yang mahal.
Contoh lain bagaimana risiko yang terkait dengan halusinasi AI meningkat pada aplikasi berisiko tinggi terlihat pada tahap awal chatbot Bard milik Google (kini Gemini). Bard menghadapi kritik internal karena sering memberikan saran berbahaya pada topik kritis seperti cara mendaratkan pesawat atau menyelam scuba. Menurut sebuah laporan Bloomberg, meskipun tim keselamatan internal menandai sistem tersebut belum siap untuk publik, perusahaan tetap meluncurkannya.
Di luar risiko langsung, halusinasi AI juga dapat menimbulkan biaya ekonomi dan reputasi yang signifikan bagi bisnis. Keluaran yang salah membuang sumber daya, baik melalui waktu yang dihabiskan untuk memverifikasi kesalahan maupun bertindak berdasarkan wawasan yang keliru. Perusahaan yang merilis alat AI yang tidak andal berisiko mengalami kerusakan reputasi, tanggung jawab hukum, dan kerugian finansial, seperti terlihat pada penurunan nilai pasar Google sebesar $100 miliar setelah Bard membagikan informasi yang tidak akurat dalam video promosi.
Halusinasi AI juga dapat berkontribusi pada penyebaran misinformasi dan disinformasi, terutama melalui platform media sosial. Ketika AI generatif menghasilkan informasi palsu yang tampak kredibel karena kefasihannya, informasi tersebut dapat dengan cepat diperkuat oleh pengguna yang menganggapnya akurat. Karena informasi dapat membentuk opini publik atau bahkan memicu bahaya, pengembang dan pengguna alat ini harus memahami dan menerima tanggung jawab untuk mencegah penyebaran ketidaksengajaan atas kepalsuan.
Terakhir, erosi kepercayaan bisa menjadi konsekuensi dari semua dampak yang disebutkan. Ketika orang menemui keluaran yang salah, tidak masuk akal, atau menyesatkan, mereka mulai mempertanyakan keandalan sistem ini, terutama di bidang yang memerlukan informasi akurat. Beberapa kesalahan mencolok dapat merusak reputasi teknologi AI dan menghambat adopsi serta penerimaannya.
Dengan demikian, salah satu tantangan terbesar terkait halusinasi AI adalah mengelola edukasi dan ekspektasi pengguna. Banyak pengguna, terutama yang kurang akrab dengan AI, sering berasumsi bahwa alat generatif menghasilkan keluaran yang sepenuhnya akurat dan andal, mengingat penyajiannya yang rapi dan penuh percaya diri. Mendidik pengguna tentang keterbatasan alat ini sangat penting tetapi kompleks, karena memerlukan keseimbangan antara transparansi atas ketidaksempurnaan AI tanpa mengurangi keyakinan terhadap potensinya.
Pada bagian ini, kita akan membahas cara mengurangi halusinasi AI melalui penjaminan kualitas data, penyetelan model, verifikasi dan kolaborasi, serta optimasi prompt.
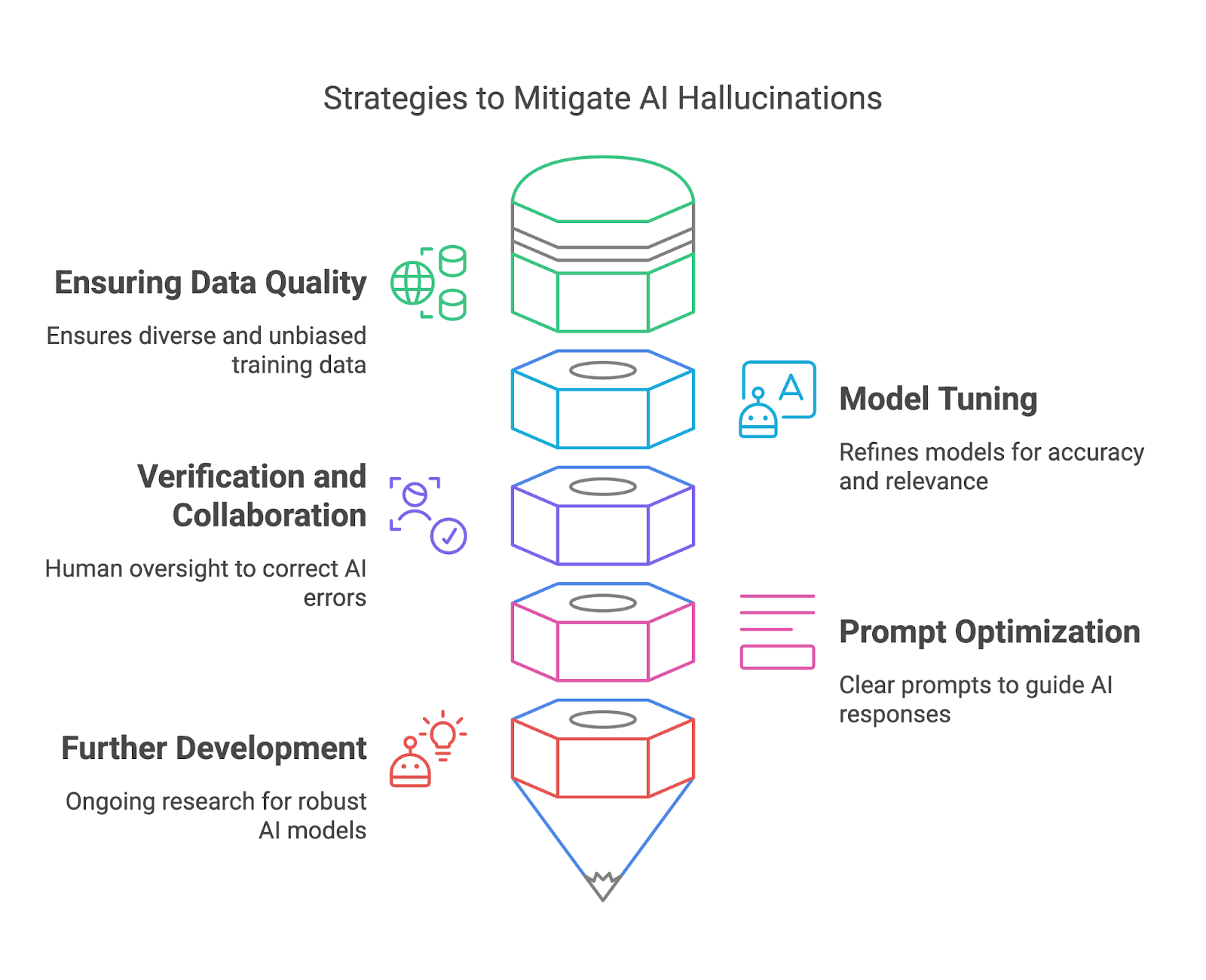
Data pelatihan berkualitas tinggi adalah salah satu cara paling efektif bagi pihak yang menerapkan model untuk mengurangi halusinasi AI. Dengan memastikan bahwa dataset pelatihan beragam, representatif, dan bebas dari bias signifikan, mereka dapat menurunkan risiko model menghasilkan keluaran yang salah atau menyesatkan. Dataset yang beragam membantu model memahami beragam konteks, bahasa, dan nuansa budaya, sehingga meningkatkan kemampuannya menghasilkan respons yang akurat dan andal.
Untuk mencapainya, pihak yang menerapkan model dapat mengadopsi praktik kurasi data yang ketat, seperti menyaring sumber yang tidak andal, memperbarui dataset secara berkala, dan memasukkan konten yang ditinjau pakar. Teknik seperti augmentasi data dan active learning juga dapat meningkatkan kualitas dataset dengan mengidentifikasi celah dan menutupnya dengan data relevan tambahan. Selain itu, penggunaan alat untuk mendeteksi dan memperbaiki bias selama proses pembuatan dataset penting untuk memastikan representasi yang seimbang.
Fine-tuning dan pemurnian model AI sangat penting untuk mengurangi halusinasi dan meningkatkan keandalan secara keseluruhan. Proses ini membantu menyelaraskan perilaku model dengan ekspektasi pengguna, mengurangi ketidakakuratan, dan meningkatkan relevansi keluaran. Fine-tuning sangat berharga untuk menyesuaikan model serbaguna ke kasus penggunaan spesifik, memastikan kinerjanya baik dalam konteks tertentu tanpa menghasilkan respons yang tidak relevan atau salah.
Beragam alat dan metode membuat pemurnian model lebih efektif. Reinforcement Learning from Human Feedback (RLHF) adalah pendekatan yang kuat, memungkinkan model belajar dari umpan balik pengguna untuk menyelaraskan perilakunya dengan hasil yang diinginkan.
Penyetelan parameter juga dapat digunakan untuk menyesuaikan gaya keluaran model, seperti membuat respons lebih konservatif demi keandalan faktual atau lebih kreatif untuk tugas terbuka. Teknik seperti dropout, regularisasi, dan early stopping membantu melawan overfitting selama pelatihan, memastikan model melakukan generalisasi dengan baik alih-alih sekadar menghafal data.
Dengan memverifikasi keluaran AI terhadap sumber tepercaya atau pengetahuan yang mapan, peninjau manusia dapat menangkap kesalahan, memperbaiki ketidakakuratan, dan mencegah konsekuensi yang berpotensi berbahaya.
Sistem pemeriksaan fakta terintegrasi, seperti plugin penjelajahan web OpenAI, membantu mengurangi halusinasi dengan mencocokkan keluaran yang dihasilkan dengan basis data tepercaya secara real time. Alat-alat ini memastikan respons AI berlandaskan informasi yang andal, sehingga sangat berguna untuk domain yang sensitif terhadap fakta seperti pendidikan atau penelitian.
Mengikutsertakan tinjauan manusia dalam alur kerja memastikan lapisan pengawasan tambahan, khususnya untuk aplikasi berisiko tinggi seperti kedokteran atau hukum, di mana kesalahan dapat berdampak serius.
Di sisi pengguna akhir, perancangan prompt yang cermat berperan penting dalam mengurangi halusinasi AI. Sementara prompt yang samar dapat menghasilkan jawaban yang berhalusinasi atau tidak relevan, prompt yang jelas dan spesifik memberikan kerangka yang lebih baik bagi model untuk menghasilkan hasil yang bermakna.
Untuk meningkatkan keandalan keluaran, kita dapat menggunakan beberapa teknik rekayasa prompt. Misalnya, memecah tugas kompleks menjadi langkah-langkah yang lebih kecil dan mudah dikelola membantu mengurangi beban kognitif AI dan meminimalkan risiko kesalahan. Untuk mempelajari lebih lanjut, Anda dapat membaca blog ini tentang teknik optimasi prompt.
Terakhir, upaya penelitian yang berkelanjutan dalam komunitas AI bertujuan mengembangkan model AI yang lebih tangguh dan andal untuk mengurangi halusinasi. Explainable AI (XAI) memberikan transparansi dengan mengungkap alasan di balik keluaran AI, sehingga pengguna dapat menilai validitasnya.
Retrieval-Augmented Generation (RAG), yang mengombinasikan AI generatif dengan sumber pengetahuan eksternal, mengurangi halusinasi dengan menambatkan respons pada data yang terverifikasi dan mutakhir.
Walaupun halusinasi AI menghadirkan tantangan besar, hal ini juga membuka peluang untuk menyempurnakan dan meningkatkan sistem AI generatif. Dengan memahami penyebab, dampak, dan strategi mitigasinya, baik pihak yang menerapkan model maupun pengguna dapat mengambil langkah proaktif untuk meminimalkan kesalahan dan memaksimalkan keandalan.
Pelajari AI dengan kursus-kursus ini!
Program
Program
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
