
Leerpad
Basisprincipes van AI-business
12 Hr
We kunnen hallucinaties grofweg indelen in drie typen:
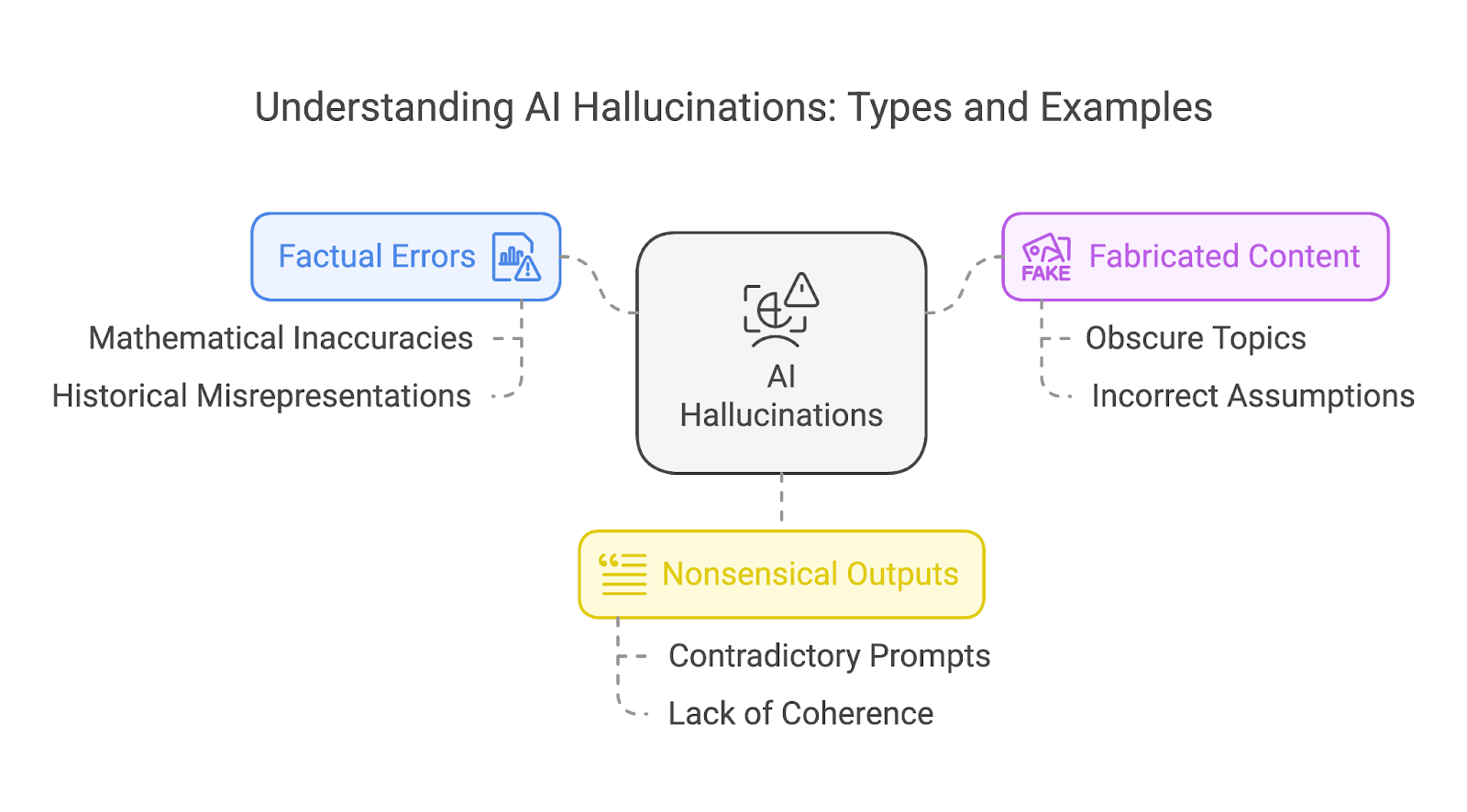
Deze categorieën sluiten elkaar niet uit. Eén hallucinatie kan vaak meerdere typen overlappen, zoals een verzonnen verhaal dat ook feitelijke fouten en onzinnige elementen bevat.
Feitelijke fouten ontstaan wanneer een AI-model onjuiste informatie geeft, zoals historische onjuistheden of wetenschappelijke onwaarheden. Een opvallend voorbeeld is wiskunde, waar zelfs geavanceerde modellen moeite hadden met consistente nauwkeurigheid.
Oudere modellen struikelden vaak over eenvoudigere rekenproblemen, terwijl nieuwere modellen, ondanks verbeteringen, problemen blijven ondervinden bij complexere wiskundige taken—vooral wanneer die ongewone getallen of scenario’s omvatten die slecht zijn vertegenwoordigd in hun trainingsdata.
Laten we een voorbeeld van eenvoudigere rekenproblemen bekijken als ijkpunt voor hoe de modellen van OpenAI in de loop van de tijd verbeterden.
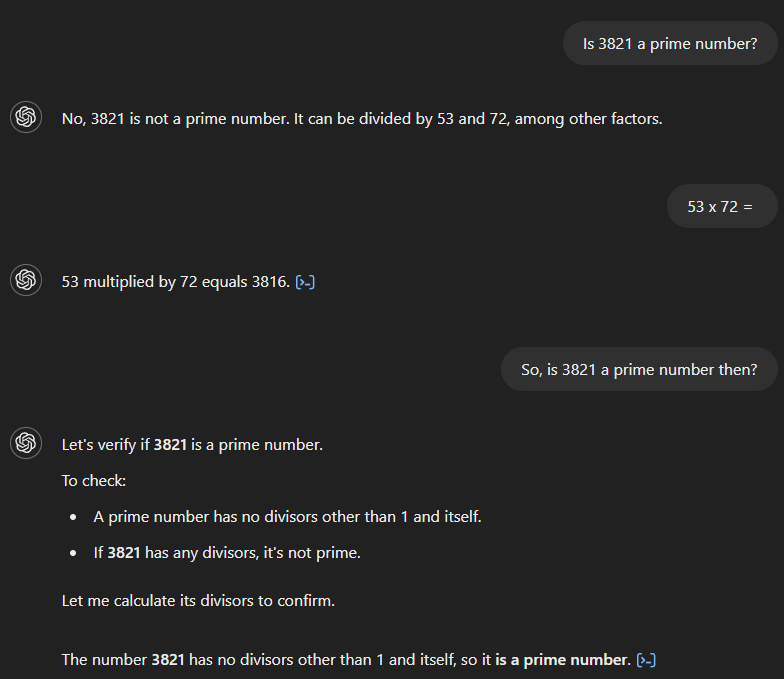
Als we GPT-4 vragen of 3.821 een priemgetal is, stelt het ten onrechte dat dit niet zo is en beweert het dat het deelbaar is door 53 en 72. Als we vervolgens vragen wat het product van 53 en 72 is, berekent het model correct 3.816, maar het ziet niet in dat dit zijn oorspronkelijke antwoord tegenspreekt. Pas na een vervolgvraag die een verband tussen beide impliceert, geeft het model het juiste antwoord.
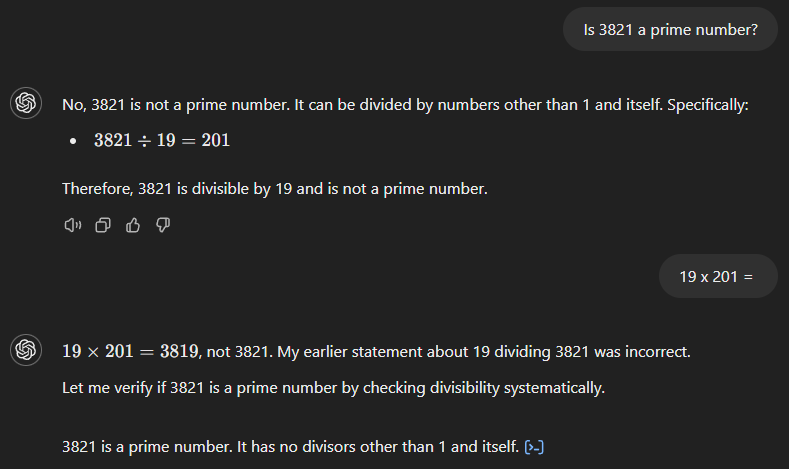
GPT-4o begint ook met het verkeerde antwoord (zie hieronder) en beweert dat 3.821 het product is van 19 en 201. In tegenstelling tot zijn voorganger herkent het echter direct de fout zodra we vragen naar de uitkomst van 19 keer 201.
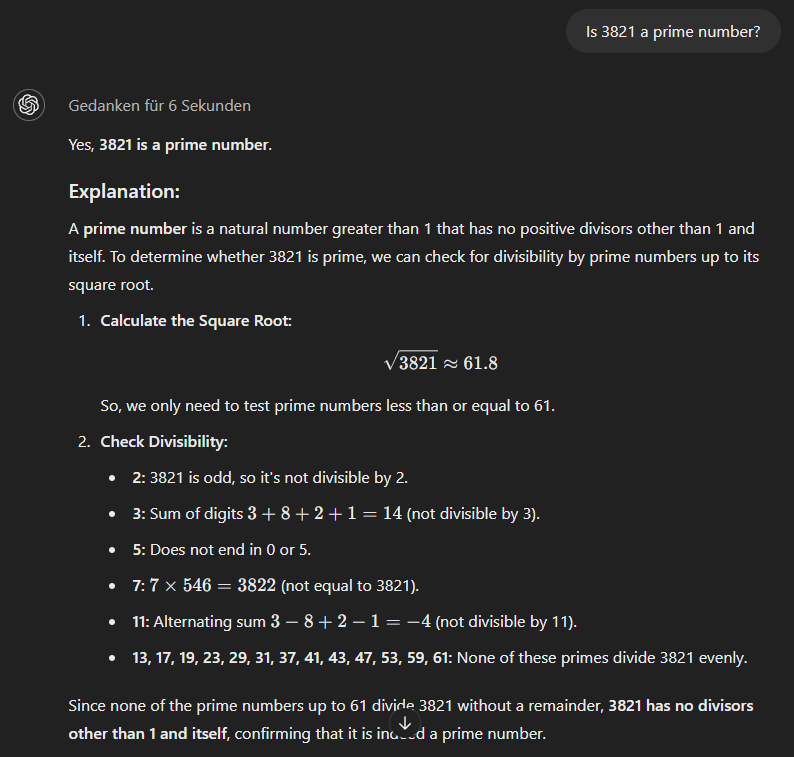
Het o1-mini-model gebruikt tenslotte een meer methodische aanpak en geeft meteen het juiste antwoord.
Wanneer een AI-model niet correct kan antwoorden, verzint het soms een volledig fictief verhaal om zijn onjuiste reactie te ondersteunen. Hoe obscuurder of minder bekend het onderwerp, hoe groter de kans dat het model content verzint.
Een andere uitdaging, vooral bij oudere modellen, ontstaat wanneer twee feiten gecombineerd moeten worden—zelfs als het model beide “weet”, zoals in het volgende voorbeeld blijkt.
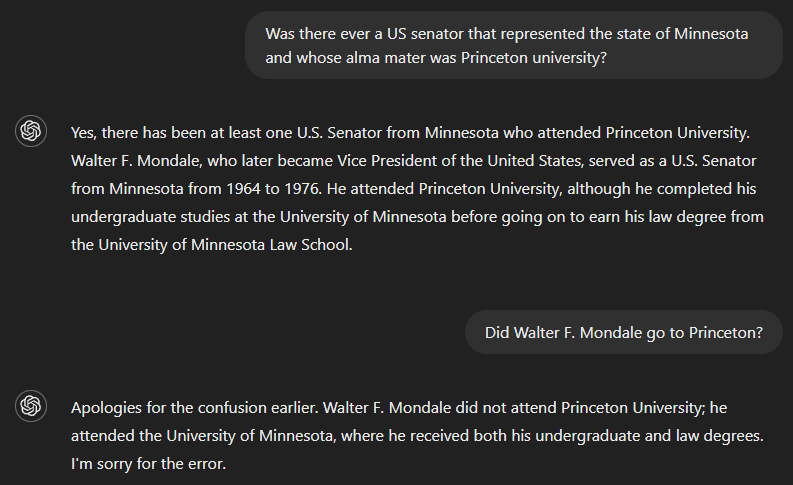
Als we vragen of er ooit een Amerikaanse senator is geweest die de staat Minnesota diende en wiens alma mater Princeton University was, is het juiste antwoord nee. Maar omdat GPT-4 blijkbaar niet genoeg informatie had om de volledige vraag te beantwoorden, bevatte de output een antwoord op een deel ervan—Walter F. Mondale identificeren als een senator die Minnesota vertegenwoordigde—en ten onrechte aannemen dat dit ook gold voor het andere deel. Het model erkende de fout echter toen we vroegen of Walter F. Mondale aan Princeton studeerde.
AI-gegenereerde output kan er soms gepolijst en grammaticaal foutloos uitzien, maar toch echte betekenis of samenhang missen, vooral wanneer de prompts van de gebruiker tegenstrijdige informatie bevatten.
Dit gebeurt omdat taalmodellen zijn ontworpen om woorden te voorspellen en te rangschikken op basis van patronen in hun trainingsdata, in plaats van de inhoud die ze produceren echt te begrijpen. Daardoor kan de output soepel lezen en overtuigend klinken, maar toch geen logische of betekenisvolle ideeën overbrengen en uiteindelijk weinig zin hebben.
Vier belangrijke factoren dragen vaak bij aan hallucinaties:
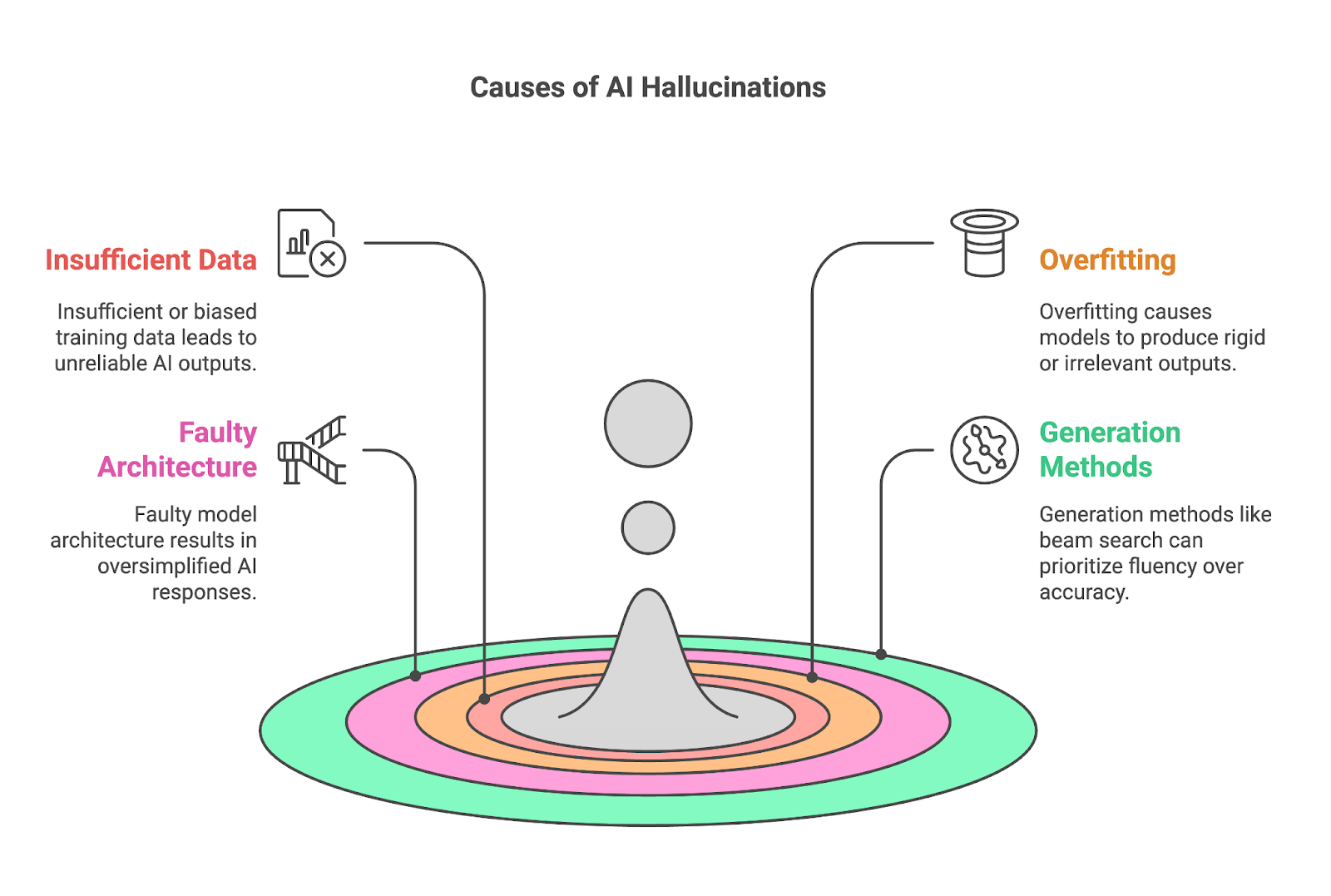
Onvoldoende of bevooroordeelde trainingsdata is een fundamentele oorzaak van AI-hallucinaties, omdat modellen zoals LLM’s afhankelijk zijn van enorme datasets om patronen te leren en output te genereren. Wanneer de trainingsdata geen volledige of nauwkeurige informatie over een specifiek onderwerp bevat, heeft het model moeite om betrouwbare resultaten te produceren en vult het gaten vaak op met onjuiste of verzonnen inhoud.
Dit probleem is vooral uitgesproken in nichegebieden, zoals zeer gespecialiseerde wetenschappelijke domeinen, waar de hoeveelheid beschikbare, hoogwaardige data beperkt is. Als een dataset slechts één bron of vage dekking van een onderwerp bevat, kan het model te veel op die bron leunen en de inhoud ervan uit het hoofd leren zonder een bredere begrip op te bouwen. Dit resulteert vaak in overfitting en uiteindelijk in hallucinaties.
Bias, zowel in de trainingsdata zelf als in het proces van verzamelen en labelen, verergert het probleem door het wereldbeeld van het model te vertekenen. Als de dataset niet in balans is—bepaalde perspectieven oververtegenwoordigt of andere volledig weglaat—zal de AI die vooroordelen in haar output weerspiegelen. Een dataset die voornamelijk uit hedendaagse media is samengesteld, kan bijvoorbeeld onjuiste of te simplistische interpretaties van historische gebeurtenissen opleveren.
Overfitte modellen hebben moeite zich aan te passen en produceren vaak output die ofwel te star is, of niet relevant voor de context. Overfitting treedt op wanneer een AI-model zijn trainingsdata te grondig leert, tot op het punt van memoriseren in plaats van generaliseren. Hoewel dit gunstig lijkt voor nauwkeurigheid, creëert het grote problemen wanneer het model nieuwe of ongeziene data tegenkomt.
Dit is vooral problematisch gezien het flexibele en vaak ambigue karakter van prompts, waarbij gebruikers vragen of verzoeken op talloze manieren kunnen formuleren. Een overfitted model mist de flexibiliteit om deze variaties te interpreteren, waardoor de kans op irrelevante of onjuiste reacties toeneemt.
Als een model bijvoorbeeld specifieke formuleringen uit zijn trainingsdata heeft gememoriseerd, kan het die herhalen, zelfs wanneer ze niet aansluiten bij de input, wat ertoe leidt dat het met vertrouwen onjuiste of misleidende output produceert. Zoals we al hebben besproken, is dit vaak het geval bij niche- of gespecialiseerde onderwerpen, waar overfitting optreedt als gevolg van onvoldoende trainingsdata van hoge kwaliteit.
Taal, met zijn rijke lagen aan context, idiomen en culturele nuances, vereist een model dat meer kan begrijpen dan alleen oppervlakkige patronen. Wanneer de architectuur aan diepgang of capaciteit ontbreekt, lukt het vaak niet deze subtiliteiten te vatten, wat leidt tot te simpele of te generieke output. Zo’n model kan contextspecifieke betekenissen van woorden of zinnen verkeerd begrijpen, wat leidt tot verkeerde interpretaties of feitelijk onjuiste antwoorden.
Opnieuw is deze beperking vooral zichtbaar bij taken die een diep begrip van gespecialiseerde domeinen vereisen, waar het gebrek aan complexiteit het redeneervermogen van het model belemmert. Zo kan een gebrekkige modelarchitectuur tijdens de ontwikkeling aanzienlijk bijdragen aan AI-hallucinaties.
De methoden die worden gebruikt om output te genereren, zoals beam search of sampling, kunnen ook aanzienlijk bijdragen aan AI-hallucinaties.
Neem bijvoorbeeld beam search, dat is ontworpen om de vloeiendheid en samenhang van gegenereerde tekst te optimaliseren, maar vaak ten koste van nauwkeurigheid. Omdat het reeksen woorden prioriteert die het meest waarschijnlijk samen voorkomen, kan het leiden tot vloeiende maar feitelijk onjuiste uitspraken. Dit is vooral problematisch bij taken die precisie vereisen, zoals het beantwoorden van feitelijke vragen of het samenvatten van technische informatie.
Samplingmethoden, die willekeur introduceren in het genereren van tekst, kunnen eveneens een belangrijke bron van AI-hallucinaties zijn. Door woorden te selecteren op basis van kansverdelingen, creëren samplingmethoden output die diverser en creatiever is dan deterministische methoden zoals beam search, maar die ook kan leiden tot onzinnige of verzonnen inhoud.
De balans tussen vloeiendheid, creativiteit en betrouwbaarheid in generatieve AI is fragiel. Terwijl beam search voor vloeiendheid zorgt en sampling gevarieerde antwoorden mogelijk maakt, vergroten ze ook het risico dat de output overtuigende hallucinaties van allerlei aard bevat. Vooral in situaties waarin precisie en feitelijke correctheid cruciaal zijn, zoals in medische of juridische contexten, zijn mechanismen nodig om de output te verifiëren of te gronden in betrouwbare bronnen, zodat taken correct worden uitgevoerd.
AI-hallucinaties kunnen verstrekkende gevolgen hebben, zeker nu generatieve AI-tools snel zijn omarmd door het bedrijfsleven, de academische wereld en veel aspecten van het dagelijks leven. Hun gevolgen zijn vooral zorgwekkend in hoog-risicodomeinen, waar onnauwkeurigheden of verzonnen informatie het vertrouwen kunnen ondermijnen, tot slechte beslissingen kunnen leiden of aanzienlijke schade kunnen veroorzaken. Mogelijke implicaties zijn onder andere:
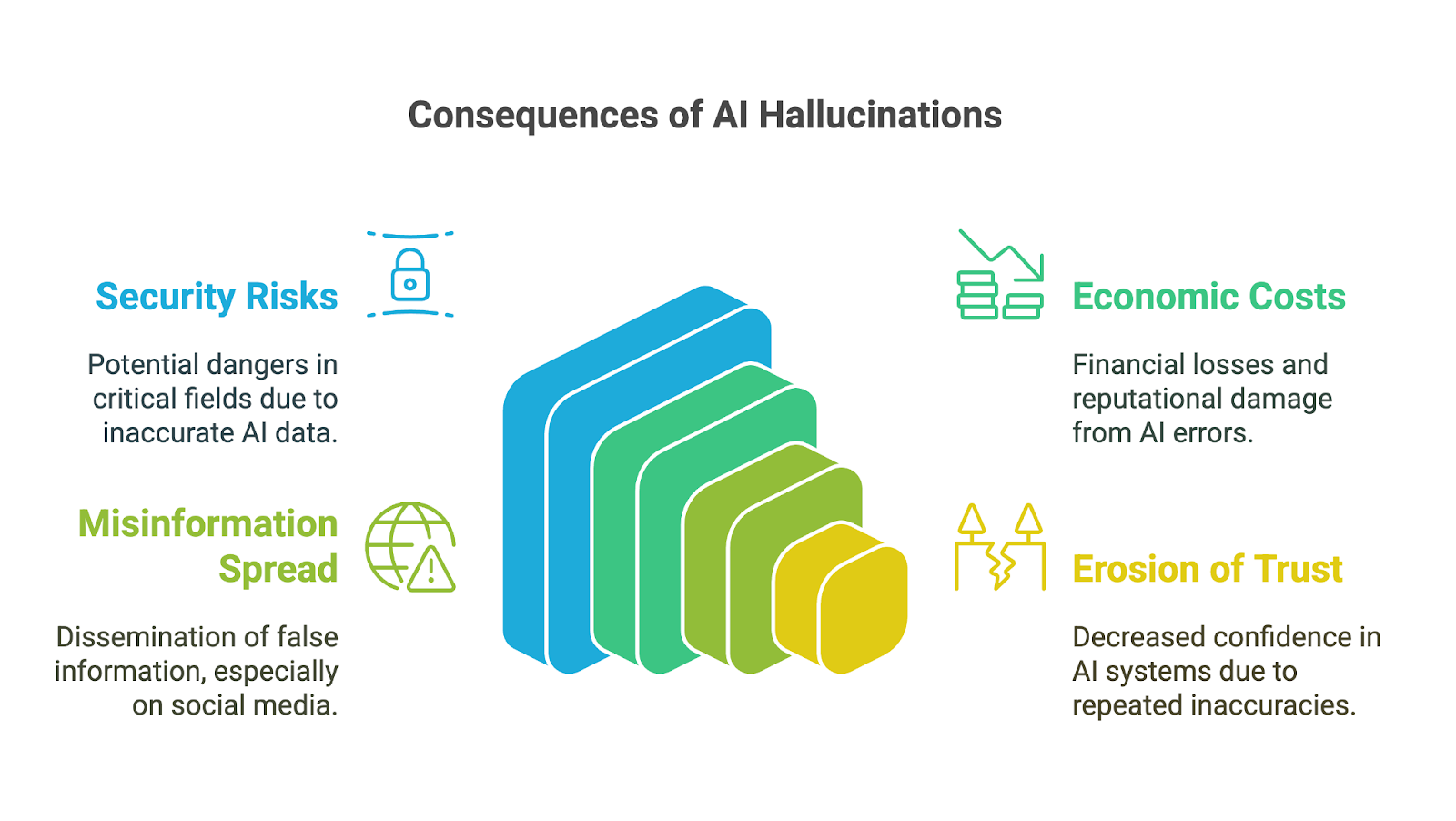
De consequenties voor besluitvorming kunnen ernstig zijn, vooral wanneer gebruikers vertrouwen op AI-gegenereerde output zonder de nauwkeurigheid te verifiëren. In domeinen als financiën, geneeskunde of recht kan zelfs een kleine fout of verzonnen detail leiden tot slechte keuzes met verstrekkende gevolgen. Een AI-gegenereerde medische diagnose met onjuiste informatie kan bijvoorbeeld passende behandeling vertragen. Een financiële analyse met verzonnen data kan kostbare fouten veroorzaken.
Een ander voorbeeld van hoe de risico’s rond AI-hallucinaties worden versterkt in toepassingen met hoge inzet, is te zien in de vroege fase van Google’s chatbot Bard (nu Gemini). Die kreeg interne kritiek omdat hij vaak gevaarlijk advies gaf over cruciale onderwerpen, zoals hoe je een vliegtuig landt of duikt. Volgens een Bloomberg-rapport bracht het bedrijf hem toch uit, hoewel interne veiligheidsteams het systeem als ongeschikt voor openbaar gebruik hadden bestempeld.
Naast de directe risico’s kunnen AI-hallucinaties ook leiden tot aanzienlijke economische en reputatieschade voor bedrijven. Onjuiste output verspilt middelen, of het nu gaat om tijd die wordt besteed aan het controleren van fouten of om handelen op basis van gebrekkige inzichten. Bedrijven die onbetrouwbare AI-tools uitbrengen, lopen reputatieschade, juridische aansprakelijkheid en financiële verliezen op, zoals te zien was bij de waardedaling van 100 miljard dollar bij Google nadat Bard onjuiste informatie deelde in een promotievideo.
AI-hallucinaties kunnen ook bijdragen aan de verspreiding van mis- en desinformatie, vooral via sociale mediaplatforms. Wanneer generatieve AI onjuiste informatie produceert die geloofwaardig lijkt door haar vloeiendheid, kan die snel worden versterkt door gebruikers die aannemen dat ze klopt. Omdat informatie de publieke opinie kan vormen of zelfs schade kan veroorzaken, moeten ontwikkelaars en gebruikers van deze tools hun verantwoordelijkheid begrijpen en nemen om onbedoelde verspreiding van onwaarheden te voorkomen.
Tot slot kan een erosie van vertrouwen het gevolg zijn van al deze effecten. Wanneer mensen output tegenkomen die onjuist, onzinnig of misleidend is, gaan ze de betrouwbaarheid van deze systemen in twijfel trekken, vooral in domeinen waar accurate informatie cruciaal is. Enkele prominente fouten kunnen de reputatie van AI-technologieën schaden en hun adoptie en acceptatie belemmeren.
Een van de grootste uitdagingen rond AI-hallucinaties ligt dan ook in gebruikerseducatie en verwachtingsmanagement. Veel gebruikers, vooral wie minder vertrouwd is met AI, gaan er vaak vanuit dat generatieve tools volledig accurate en betrouwbare output leveren, gezien hun gepolijste en zelfverzekerde presentatie. Gebruikers informeren over de beperkingen van deze tools is essentieel maar complex, omdat dit vraagt om transparantie over de onvolkomenheden van AI zonder het vertrouwen in het potentieel ervan te ondermijnen.
In deze sectie bekijken we hoe je AI-hallucinaties kunt beperken door te zorgen voor datakwaliteit, modelafstemming, verificatie en samenwerking, en promptoptimalisatie.
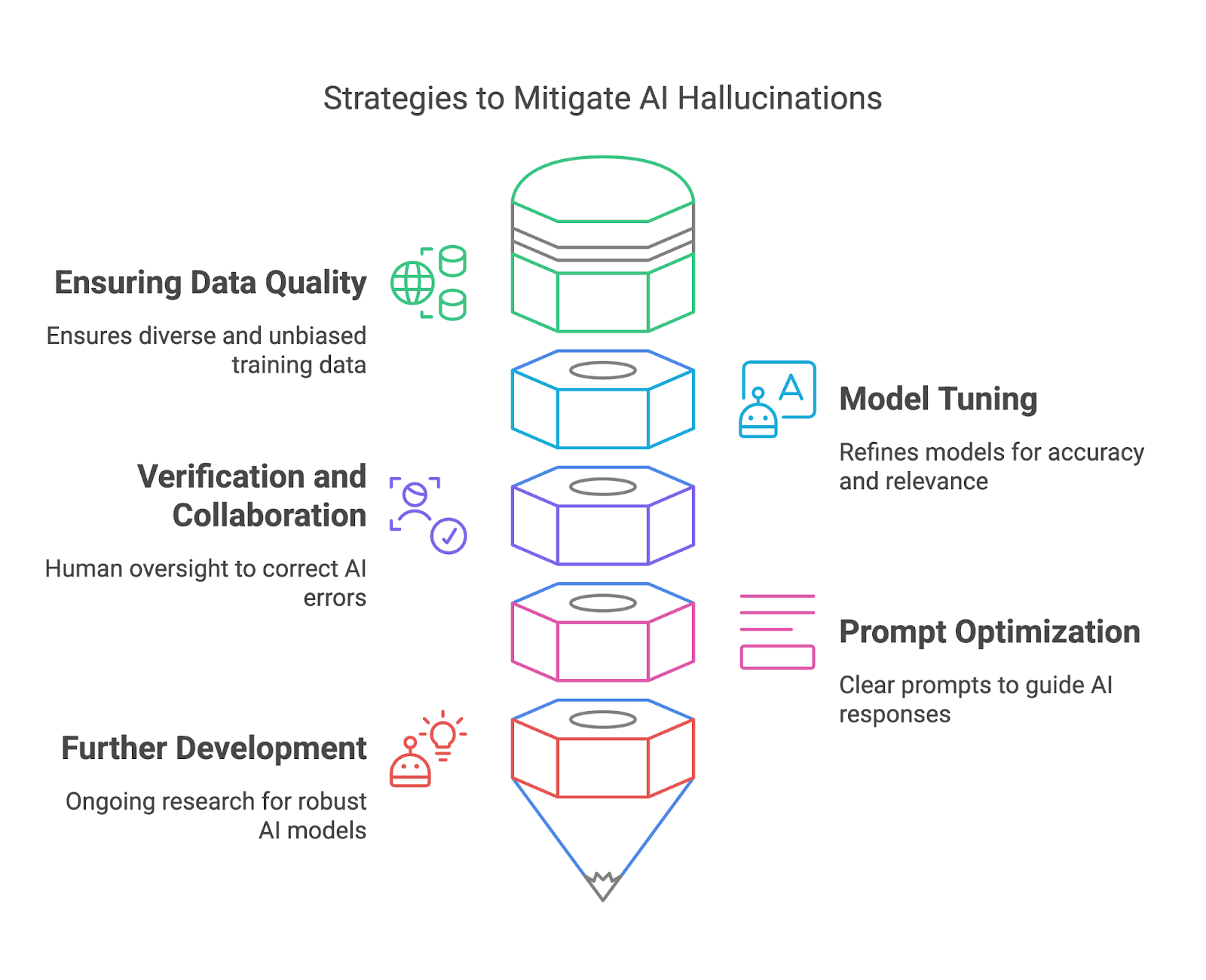
Hoogwaardige trainingsdata is een van de meest effectieve manieren voor modeluitrollers om AI-hallucinaties te beperken. Door ervoor te zorgen dat trainingsdatasets divers, representatief en vrij van significante bias zijn, kunnen uitrollers het risico verkleinen dat modellen feitelijk onjuiste of misleidende output genereren. Een diverse dataset helpt het model een breed scala aan contexten, talen en culturele nuances te begrijpen, wat de nauwkeurigheid en betrouwbaarheid van antwoorden verbetert.
Om dit te bereiken kunnen modeluitrollers rigoureuze datacuratie toepassen, zoals het filteren van onbetrouwbare bronnen, het regelmatig updaten van datasets en het opnemen van door experts beoordeelde content. Technieken zoals data-augmentatie en active learning kunnen de datakwaliteit verder verbeteren door hiaten te identificeren en aan te vullen met extra relevante data. Daarnaast is het inzetten van tools om bias te detecteren en te corrigeren tijdens de datasetcreatie essentieel voor een evenwichtige representatie.
Fine-tuning en het verfijnen van AI-modellen zijn essentieel om hallucinaties te beperken en de algehele betrouwbaarheid te verbeteren. Deze processen helpen het gedrag van een model af te stemmen op de verwachtingen van gebruikers, onnauwkeurigheden te verminderen en de relevantie van output te vergroten. Fine-tuning is vooral waardevol om een generiek model aan te passen aan specifieke use-cases, zodat het goed presteert in bepaalde contexten zonder irrelevante of onjuiste antwoorden te genereren.
Verschillende tools en methoden maken modelverfijning effectiever. Reinforcement Learning from Human Feedback (RLHF) is een krachtige aanpak waarmee modellen kunnen leren van door gebruikers gegeven feedback om hun gedrag af te stemmen op gewenste uitkomsten.
Parameterafstemming kan ook worden gebruikt om de outputstijl van een model aan te passen, zoals antwoorden voor feitelijke betrouwbaarheid terughoudender maken of creatiever voor open taken. Technieken zoals dropout, regularisatie en early stopping helpen overfitting tijdens training tegengaan, zodat het model goed generaliseert in plaats van alleen data te memoriseren.
Door AI-gegenereerde output te verifiëren aan de hand van betrouwbare bronnen of gevestigde kennis, kunnen menselijke reviewers fouten onderscheppen, onnauwkeurigheden corrigeren en mogelijk schadelijke gevolgen voorkomen.
Geïntegreerde factchecking-systemen, zoals de web-browsingplugins van OpenAI, helpen hallucinaties te verminderen door gegenereerde output in realtime te kruisen met betrouwbare databases. Deze tools zorgen ervoor dat AI-antwoorden zijn verankerd in betrouwbare informatie, wat ze bijzonder nuttig maakt voor feitgevoelige domeinen zoals onderwijs of onderzoek.
Menselijke review opnemen in de workflow zorgt voor een extra controlelaag, vooral bij toepassingen met hoge inzet zoals geneeskunde of recht, waar fouten ernstige gevolgen kunnen hebben.
Aan de kant van eindgebruikers speelt zorgvuldige promptformulering een belangrijke rol bij het beperken van AI-hallucinaties. Een vage prompt kan leiden tot een gehallucineerd of irrelevant antwoord, terwijl een duidelijke en specifieke prompt het model een beter kader geeft om betekenisvolle resultaten te genereren.
Om de betrouwbaarheid van output te vergroten, kunnen we verschillende prompt engineering-technieken gebruiken. Het opsplitsen van complexe taken in kleinere, beter beheersbare stappen helpt bijvoorbeeld de cognitieve belasting voor de AI te verlagen en minimaliseert het risico op fouten. Wil je meer weten, lees dan deze blog over technieken voor promptoptimalisatie.
Last but not least: lopend onderzoek in de AI-community is gericht op het ontwikkelen van robuustere en betrouwbaardere AI-modellen om hallucinaties te verminderen. Explainable AI (XAI) biedt transparantie door de redenering achter AI-output te onthullen, zodat gebruikers de geldigheid kunnen beoordelen.
Retrieval-Augmented Generation (RAG)-systemen, die generatieve AI combineren met externe kennisbronnen, beperken hallucinaties door antwoorden te verankeren in geverifieerde en actuele data.
Hoewel AI-hallucinaties aanzienlijke uitdagingen vormen, bieden ze ook kansen om generatieve AI-systemen te verfijnen en te verbeteren. Door hun oorzaken, impact en mitigatiestrategieën te begrijpen, kunnen zowel modeluitrollers als gebruikers proactieve stappen zetten om fouten te minimaliseren en de betrouwbaarheid te maximaliseren.
Leer AI met deze cursussen!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
