
Track
AI Business Fundamentals
12 hr
We can broadly categorize hallucinations into three different types:
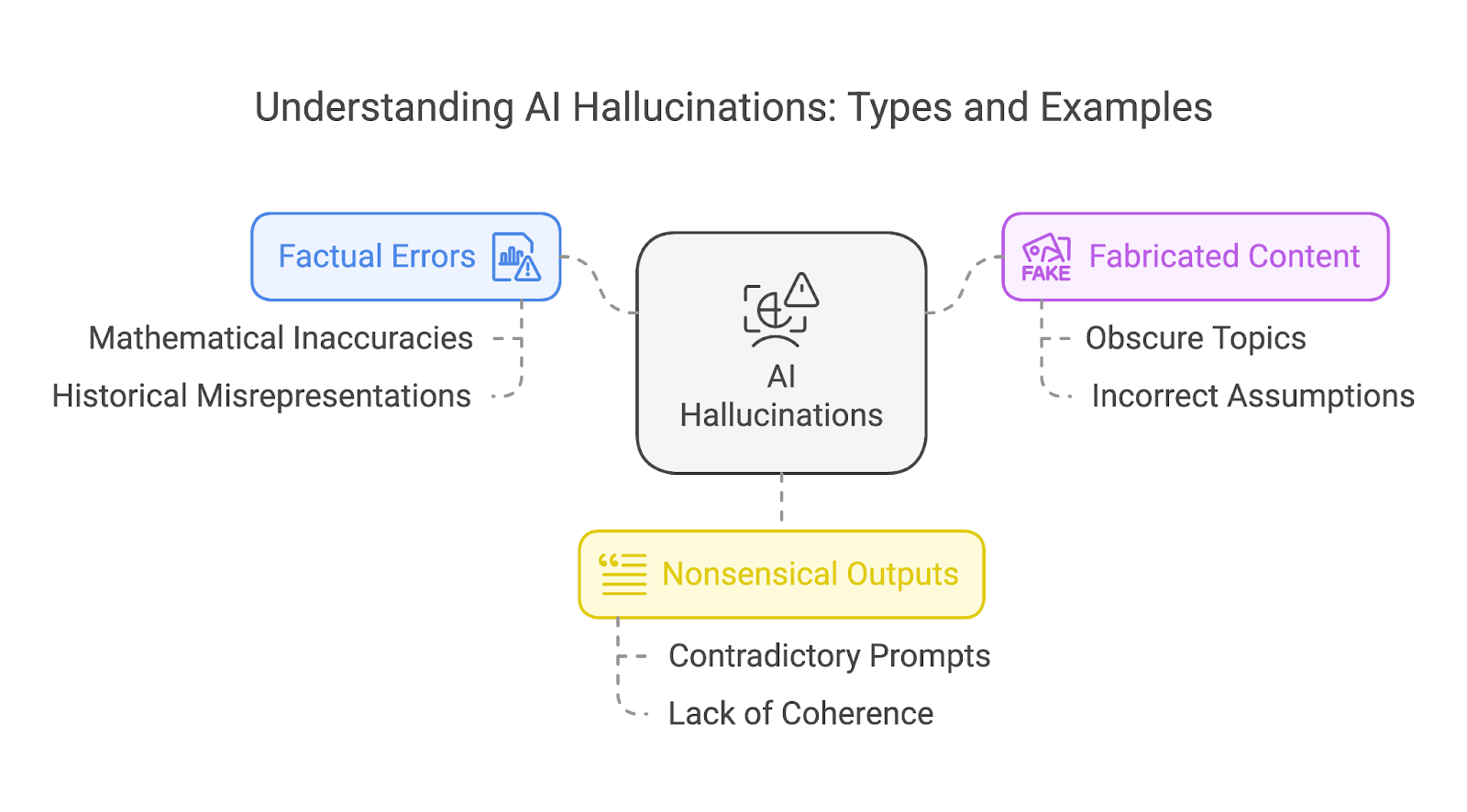
These categories are not mutually exclusive. A single hallucination can often overlap multiple types, such as a fabricated story that also contains factual errors and nonsensical elements.
Factual errors occur when an AI model outputs incorrect information, such as historical inaccuracies or scientific falsehoods. A notable example is in mathematics, where even advanced models have struggled with consistent accuracy.
Older models often stumbled on simpler math problems, while newer models, despite improvements, tend to experience problems with more complex mathematical tasks—particularly those involving uncommon numbers or scenarios not well-represented in their training data.
Let’s examine an example of easier mathematical problems as a benchmark for how OpenAI’s models improved over time.
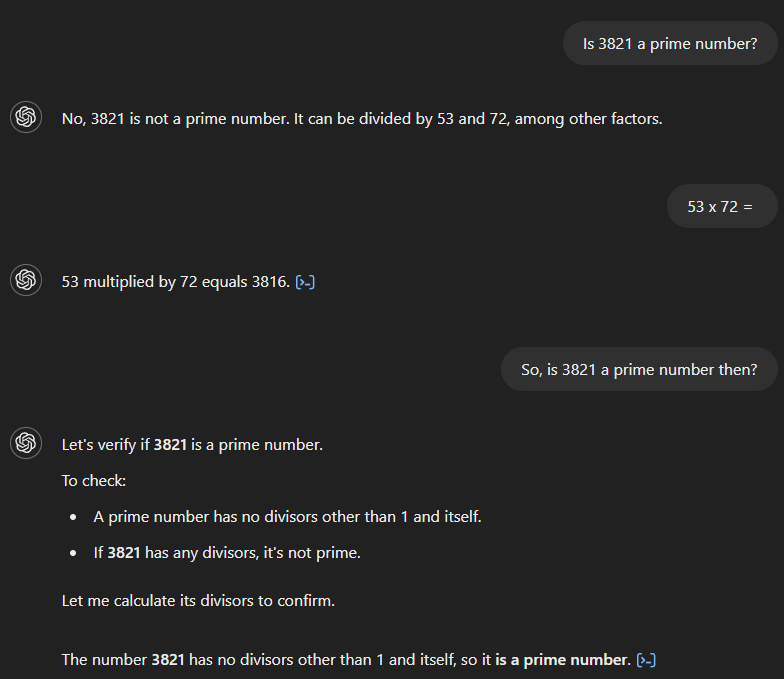
If we ask GPT-4 whether 3,821 is a prime number, it incorrectly states that it is not and claims it is divisible by 53 and 72. If we then ask for the product of 53 and 72, the model correctly calculates the result as 3,816 but fails to recognize that this contradicts its initial answer. Only after a follow-up question implying a connection between the two does the model provide the correct answer.
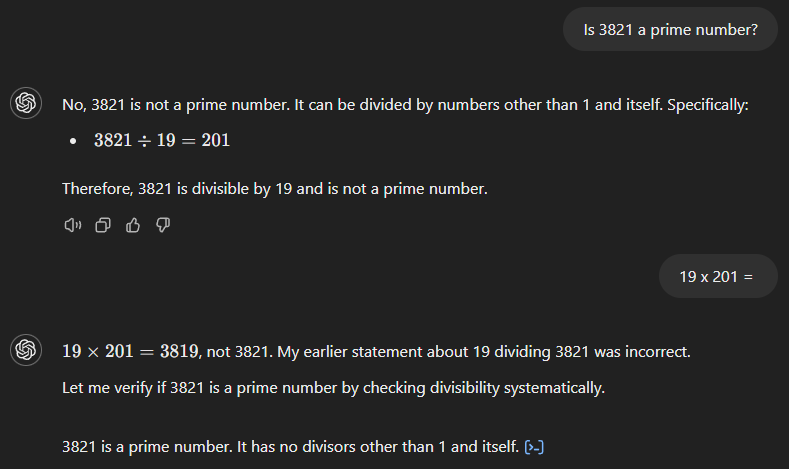
GPT-4o also starts with the wrong answer (see below), claiming that 3,821 is the product of 19 and 201. However, unlike its predecessor, it immediately recognizes its mistake when we ask for the result of 19 times 201.
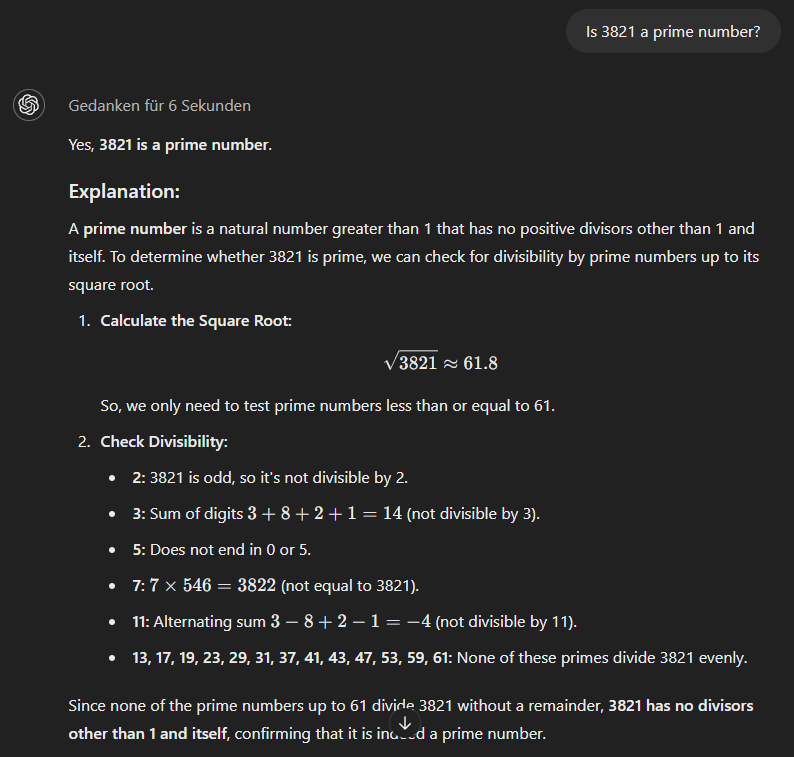
The o1-mini model, finally, uses a more methodical approach and gives the correct answer right away.
When an AI model cannot answer correctly, it sometimes fabricates an entirely fictional story to support its incorrect response. The more obscure or less familiar the topic, the higher the likelihood of the model fabricating content.
Another challenge, especially for older models, arises when combining two facts—even if the model “knows” both, as demonstrated in the next example.
If we ask whether there has ever been a U.S. senator who served the state of Minnesota and whose alma mater was Princeton University, the correct answer is no. But since GPT-4 seemingly lacked sufficient information to answer the full question, its output included an answer to part of it—identifying Walter F. Mondale as a senator who represented Minnesota—and incorrectly assumed this was also valid for the other part. However, the model recognized its mistake when asked whether Walter F. Mondale attended Princeton.
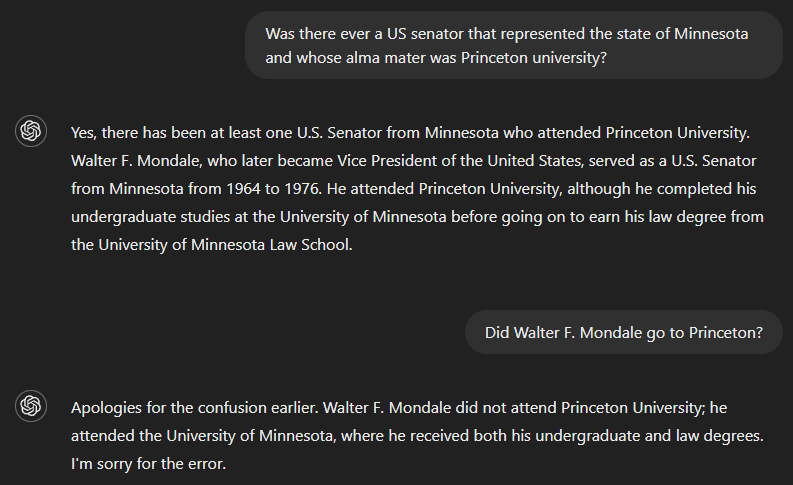
AI-generated output can sometimes appear polished and grammatically flawless while lacking true meaning or coherence, particularly when the user’s prompts contain contradictory information.
This happens because language models are designed to predict and arrange words based on patterns in their training data rather than genuinely understanding the content they produce. As a result, the output may read smoothly and sound convincing but fail to convey logical or meaningful ideas, ultimately making little sense.
Four key factors often contribute to hallucinations:
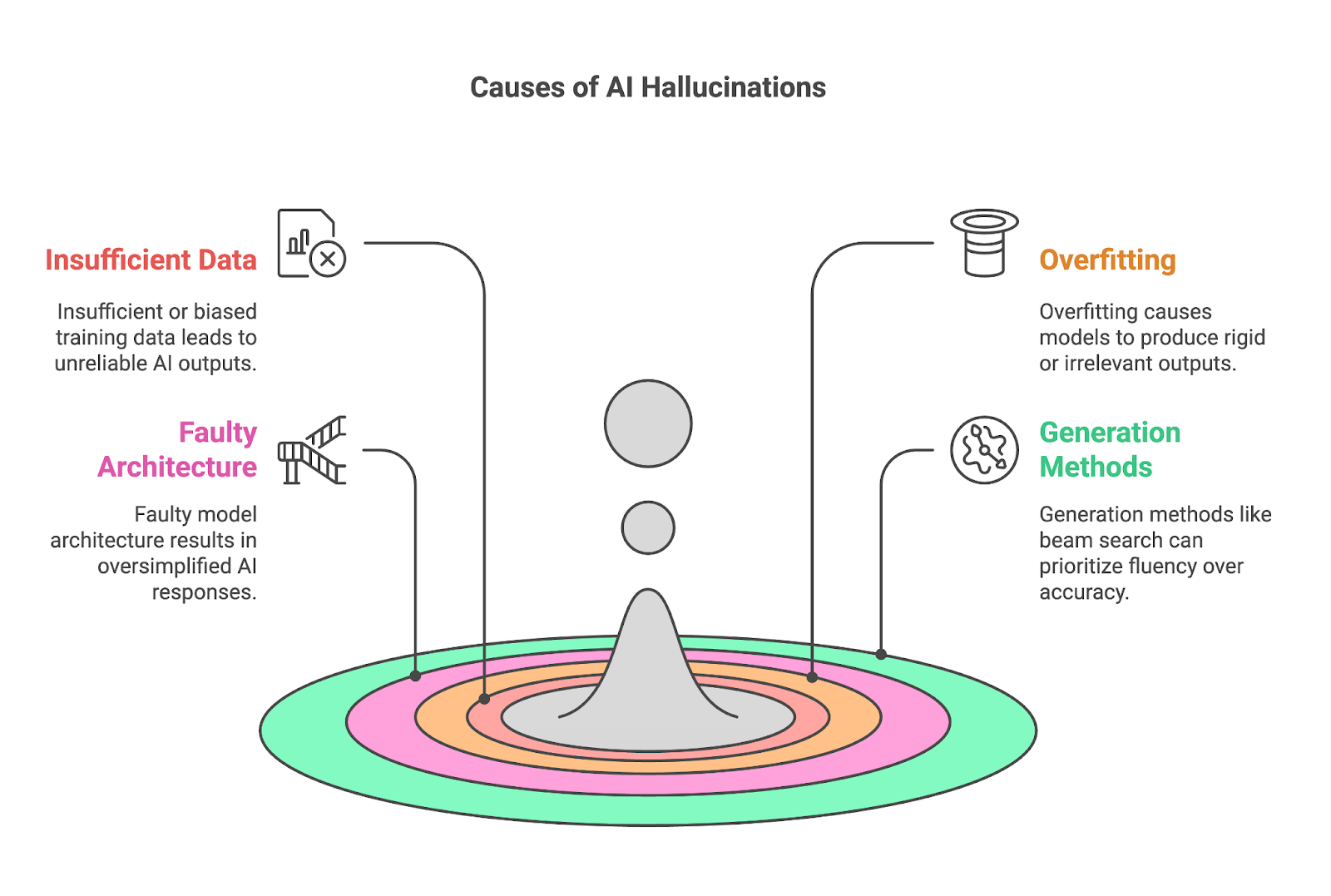
Insufficient or biased training data is a fundamental cause of AI hallucinations, as models like LLMs rely on vast datasets to learn patterns and generate outputs. When the training data lacks comprehensive or accurate information about a specific topic, the model struggles to produce reliable results, often filling the gaps with incorrect or fabricated content.
This issue is particularly pronounced in niche domains, such as highly specialized scientific fields, where the amount of available, high-quality data is limited. If a dataset contains only a single source or vague coverage of a topic, the model may over-rely on that source, memorizing its content without gaining a broader understanding. This often results in overfitting and, ultimately, hallucinations.
Bias, whether in the training data itself or in the process of collecting and labeling it, amplifies the problem by skewing the model’s understanding of the world. If the dataset is unbalanced—overrepresenting certain perspectives or completely omitting others—the AI will reflect those biases in its outputs. For example, a dataset primarily sourced from contemporary media could produce inaccurate or oversimplified interpretations of historical events.
Overfitted models struggle to adapt, often producing outputs that are either overly rigid or irrelevant to the context. Overfitting occurs when an AI model learns its training data too thoroughly, to the point of memorization rather than generalization. While this might seem beneficial for accuracy, it creates significant problems when the model encounters new or unseen data.
This is especially problematic given the flexible and often ambiguous nature of prompts, where users may phrase questions or requests in countless ways. An overfitted model lacks the adaptability to interpret these variations, increasing the likelihood of producing irrelevant or incorrect responses.
For instance, if a model has memorized specific phrasing from its training data, it may repeat that phrasing even when it doesn't align with the input, leading to confidently producing outputs that are incorrect or misleading. As we have already covered, this is often the case in niche or specialized topics, where overfitting occurs as a consequence of insufficient high-quality training data.
Language, with its rich layers of context, idioms, and cultural nuances, requires a model capable of understanding more than just surface-level patterns. When the architecture lacks depth or capacity, it often fails to grasp these subtleties, resulting in oversimplified or overly generic outputs. Such a model may misunderstand context-specific meanings of words or phrases, leading to incorrect interpretations or factually flawed responses.
Once again, this limitation is especially evident in tasks requiring a deep understanding of specialized fields, where the lack of complexity hinders the model's ability to reason accurately. This way, faulty model architecture during development can significantly contribute to AI hallucinations.
The methods used to generate outputs, such as beam search or sampling, can also significantly contribute to AI hallucinations.
Take beam search, for example, which is designed to optimize the fluency and coherence of generated text, but often at the expense of accuracy. Because it prioritizes sequences of words most likely to appear together, it can result in fluent but factually incorrect statements. This is particularly problematic for tasks requiring precision, such as answering factual questions or summarizing technical information.
Sampling methods, which introduce randomness to the text generation process, can be a significant source of AI hallucinations, too. By selecting words based on probability distributions, sampling creates outputs that are more diverse and creative compared to deterministic methods like beam search, but it can also lead to nonsensical or fabricated content.
The balance between fluency, creativity, and reliability in generative AI is fragile. While beam search assures fluency and sampling allows for varied responses, they also increase the risk of the output containing convincing hallucinations of various sorts. Especially in scenarios where precision and factual correctness are crucial, such as medical or legal contexts, mechanisms to verify or ground the outputs against reliable sources are necessary to ensure tasks are fulfilled correctly.
AI hallucinations can have far-reaching impacts, especially as generative AI tools have been rapidly adopted across business, academia, and many areas of daily life. Their consequences are particularly concerning in high-stakes fields, where inaccuracies or fabricated information can undermine trust, lead to poor decisions, or result in significant harm. Among the possible implications are:
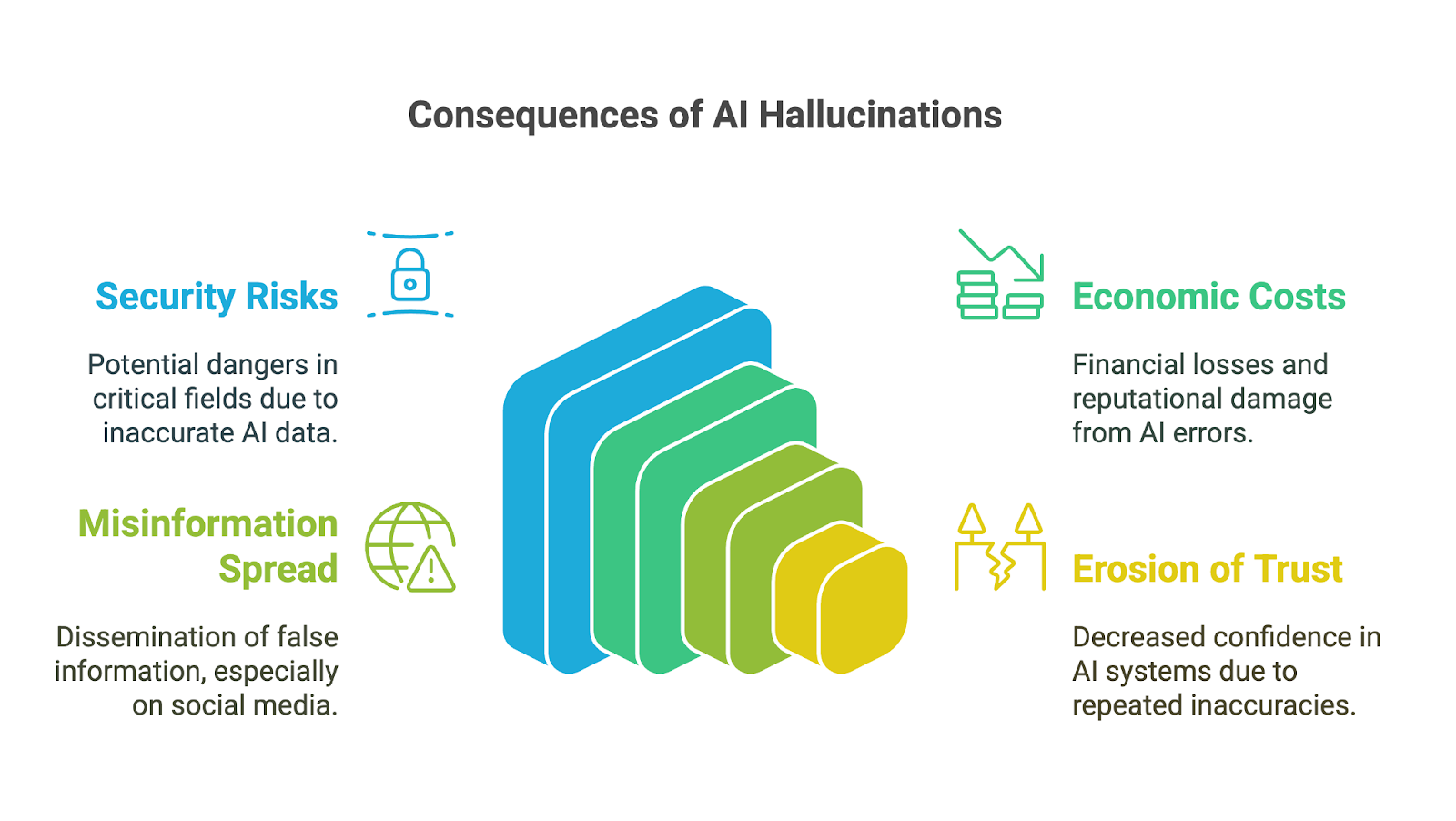
Consequences for decision-making can be severe, especially when users rely on AI-generated outputs without verifying their accuracy. In fields like finance, medicine, or law, even a small mistake or fabricated detail can lead to poor choices with far-reaching impacts. For instance, an AI-generated medical diagnosis containing incorrect information could delay proper treatment. A financial analysis with fabricated data could result in costly errors.
Another example of how the risks associated with AI hallucinations are amplified in high-stakes applications can be seen in the early stages of Google’s chatbot Bard (now Gemini). It faced internal criticism for frequently offering dangerous advice on critical topics such as how to land a plane or scuba diving. According to a Bloomberg report, even though internal safety teams had flagged the system as not ready for public use, the company launched it regardless.
Beyond the immediate risks, AI hallucinations can also result in significant economic and reputational costs for businesses. Incorrect outputs waste resources, whether through time spent verifying errors or acting on flawed insights. Companies that release unreliable AI tools risk reputational damage, legal liabilities, and financial losses, as seen in Google’s $100 billion market value drop after Bard shared inaccurate information in a promotional video.
AI hallucinations can also contribute to the spread of misinformation and disinformation, especially via social media platforms. When generative AI produces false information that appears credible because of its fluency, it can quickly be amplified by users who assume it is accurate. Since information can shape public opinion or even incite harm, developers and users of these tools must understand and accept their responsibility to prevent the unintentional spread of falsehoods.
Finally, an erosion of trust can be the consequence of all the impacts mentioned. When people encounter outputs that are incorrect, nonsensical, or misleading, they begin to question the reliability of these systems, especially in fields where accurate information is critical. A few prominent mistakes can damage the reputation of AI technologies and hinder their adoption and acceptance.
Accordingly, one of the biggest challenges with AI hallucinations lies in managing user education and expectations. Many users, especially those less familiar with AI, often assume that generative tools produce entirely accurate and reliable outputs, given their polished and confident presentation. Educating users about the limitations of these tools is essential but complex, as it requires balancing transparency about AI’s imperfections without reducing confidence in its potential.
In this section, we’ll explore how to mitigate AI hallucinations through ensuring data quality, model tuning, verification and collaboration, and prompt optimization.
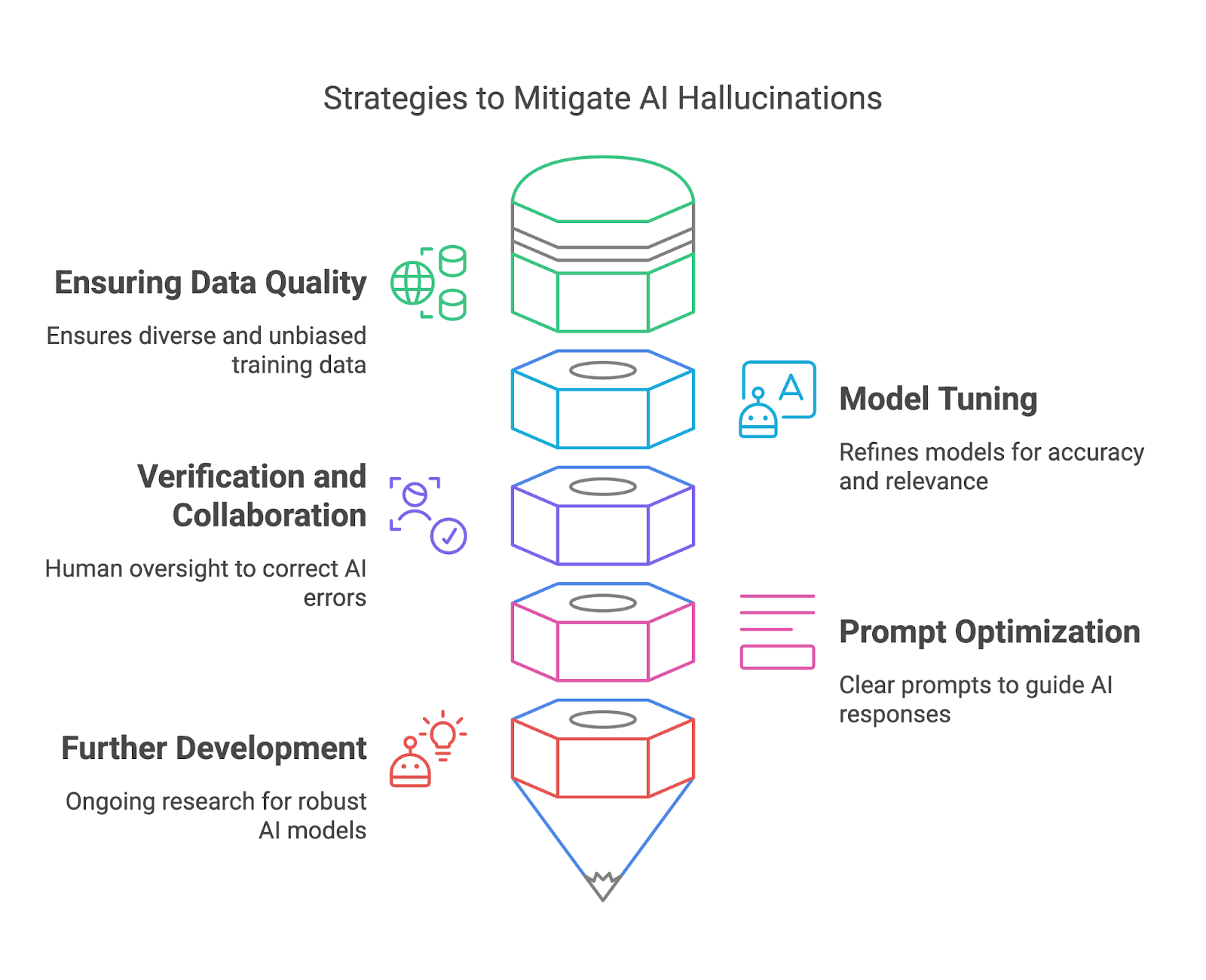
High-quality training data is one of the most effective ways for model deployers to mitigate AI hallucinations. By ensuring that training datasets are diverse, representative, and free from significant biases, deployers can reduce the risk of models generating outputs that are factually incorrect or misleading. A diverse dataset helps the model understand a wide range of contexts, languages, and cultural nuances, improving its ability to generate accurate and reliable responses.
To achieve this, model deployers can adopt rigorous data curation practices, such as filtering out unreliable sources, regularly updating datasets, and incorporating expert-reviewed content. Techniques like data augmentation and active learning can also enhance dataset quality by identifying gaps and addressing them with additional relevant data. Furthermore, deploying tools to detect and correct biases during the dataset creation process is essential to ensure balanced representation.
Fine-tuning and refining AI models are essential in mitigating hallucinations and improving overall reliability. These processes help align a model’s behavior with user expectations, reduce inaccuracies, and enhance the relevance of outputs. Fine-tuning is especially valuable for adapting a general-purpose model to specific use cases, ensuring it performs well in particular contexts without generating irrelevant or incorrect responses.
Several tools and methods make model refinement more effective. Reinforcement Learning from Human Feedback (RLHF) is a powerful approach, allowing models to learn from user-provided feedback to align their behavior with desired outcomes.
Parameter tuning can also be used to adjust a model’s output style, such as making responses more conservative for factual reliability or more creative for open-ended tasks. Techniques like dropout, regularization, and early stopping help combat overfitting during training, ensuring the model generalizes well rather than simply memorizing data.
By verifying AI-generated outputs against trusted sources or established knowledge, human reviewers can catch errors, correct inaccuracies, and prevent potentially harmful consequences.
Integrated fact-checking systems, such as OpenAI's web-browsing plugins, help reduce hallucinations by cross-referencing generated outputs with trusted databases in real time. These tools ensure that AI responses are grounded in reliable information, making them particularly useful for fact-sensitive domains like education or research.
Incorporating human review into the workflow ensures an additional layer of scrutiny, particularly for high-stakes applications like medicine or law, where errors can have serious consequences.
On the side of end users, careful prompt design plays an important role in mitigating AI hallucinations. While a vague prompt may lead to a hallucinated or irrelevant answer, a clear and specific one gives the model a better framework for generating meaningful results.
To enhance output reliability, we can use several prompt engineering techniques. For example, breaking down complex tasks into smaller, more manageable steps helps reduce the cognitive load on the AI and minimizes the risk of errors. To learn more, you can read this blog on prompt optimization techniques.
Last but not least, ongoing research efforts in the AI community aim to develop more robust and reliable AI models to reduce hallucinations. Explainable AI (XAI) provides transparency by revealing the reasoning behind AI outputs, allowing users to assess their validity.
Retrieval-Augmented Generation (RAG) systems, which combine generative AI with external knowledge sources, mitigate hallucinations by anchoring responses in verified and up-to-date data.
While AI hallucinations present significant challenges, they also offer opportunities to refine and improve generative AI systems. By understanding their causes, impacts, and mitigation strategies, both model deployers and users can take proactive steps to minimize errors and maximize reliability.
Learn AI with these courses!
Track
Track
Course
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Amberle McKee
8 min
blog
Rajesh Kumar
15 min
blog
Arun Nanda
14 min
Tutorial
François Aubry
Tutorial
Patrick Brus
