
Programma
Nozioni di base sull'intelligenza artificiale nel mondo degli affari
12 h
Possiamo raggruppare in modo ampio le allucinazioni in tre tipi diversi:
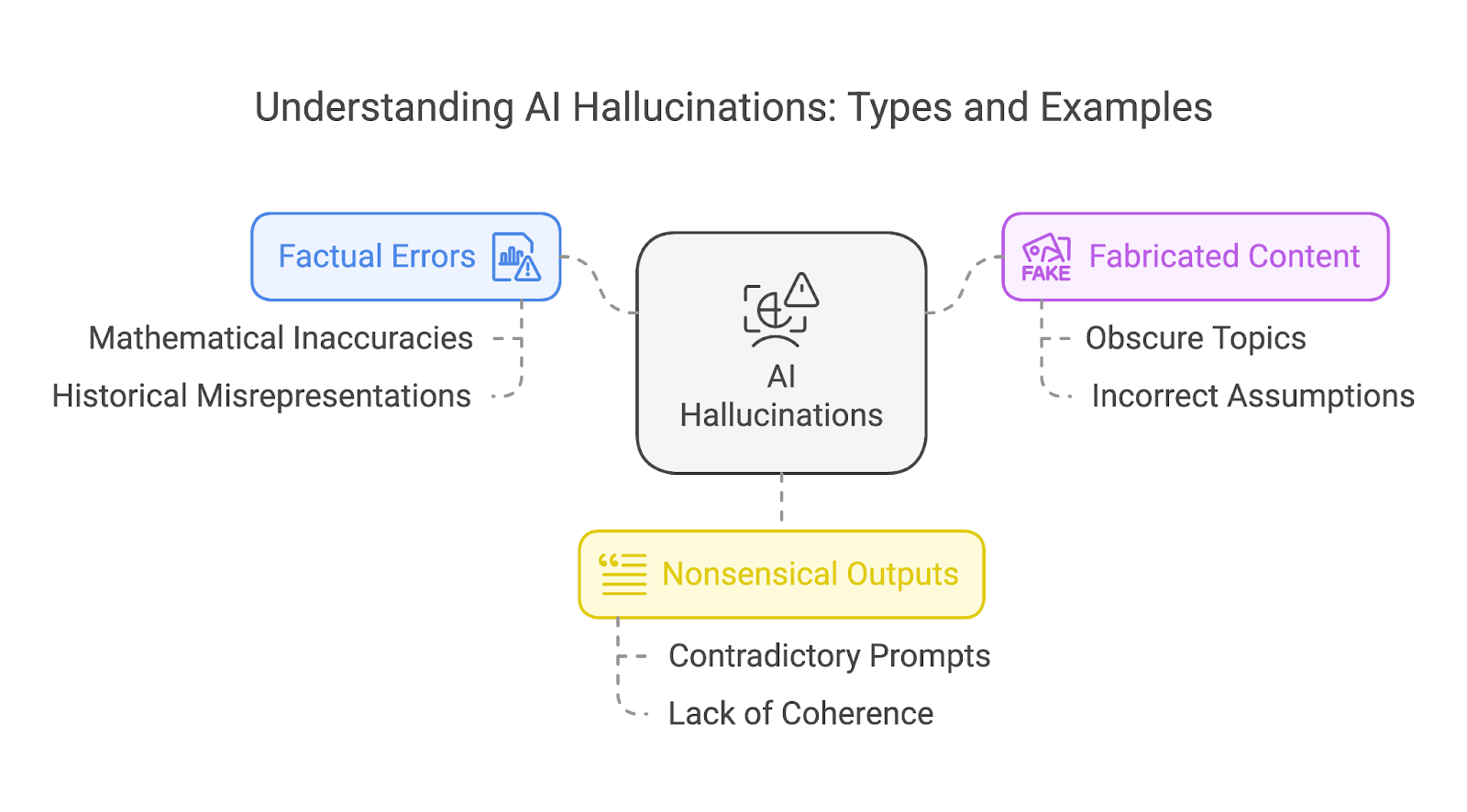
Queste categorie non si escludono a vicenda. Un’unica allucinazione può spesso sovrapporre più tipi, ad esempio una storia inventata che contiene sia errori di fatto sia elementi privi di senso.
Gli errori fattuali si verificano quando un modello di IA produce informazioni errate, come inesattezze storiche o falsità scientifiche. Un esempio notevole è la matematica, dove anche modelli avanzati hanno faticato a mantenere un’accuratezza costante.
I modelli più datati spesso inciampavano su problemi di matematica semplici, mentre i modelli più recenti, nonostante i miglioramenti, tendono ad avere difficoltà con compiti matematici più complessi—soprattutto quelli che coinvolgono numeri poco comuni o scenari poco rappresentati nei dati di addestramento.
Vediamo un esempio di problemi matematici più facili come riferimento per capire come i modelli di OpenAI siano migliorati nel tempo.
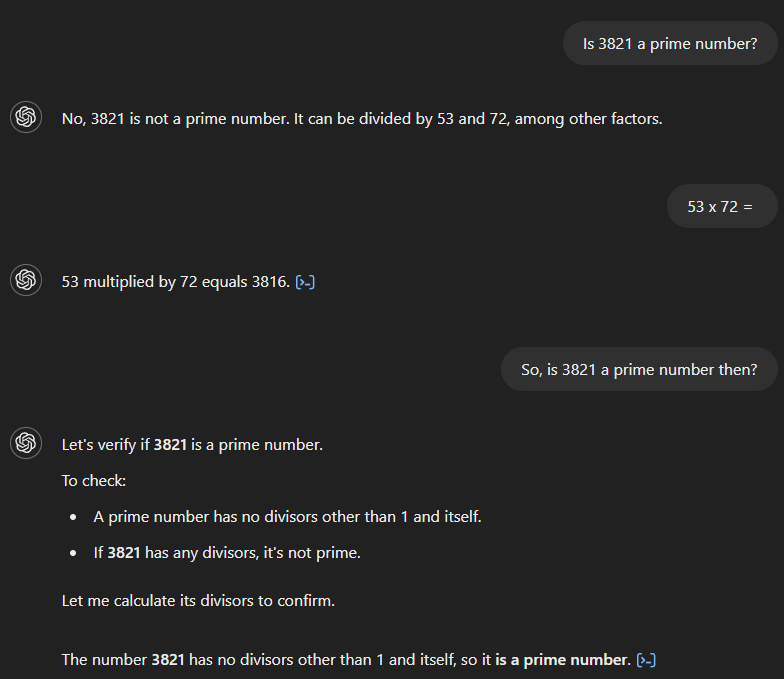
Se chiediamo a GPT-4 se 3.821 è un numero primo, afferma erroneamente di no e sostiene che sia divisibile per 53 e 72. Se poi chiediamo il prodotto di 53 e 72, il modello calcola correttamente 3.816 ma non riconosce che questo contraddice la risposta iniziale. Solo dopo una domanda successiva che implica una connessione tra le due cose il modello fornisce la risposta corretta.
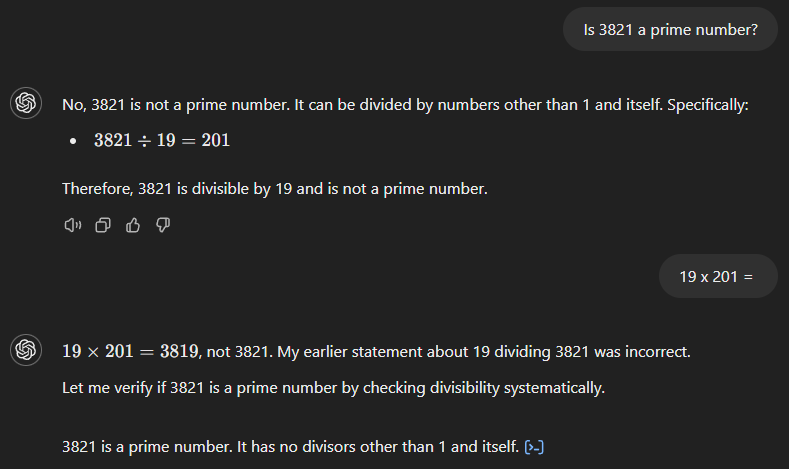
GPT-4o parte anch’esso con la risposta sbagliata (vedi sotto), sostenendo che 3.821 sia il prodotto di 19 e 201. Tuttavia, a differenza del suo predecessore, riconosce subito l’errore quando chiediamo il risultato di 19 per 201.
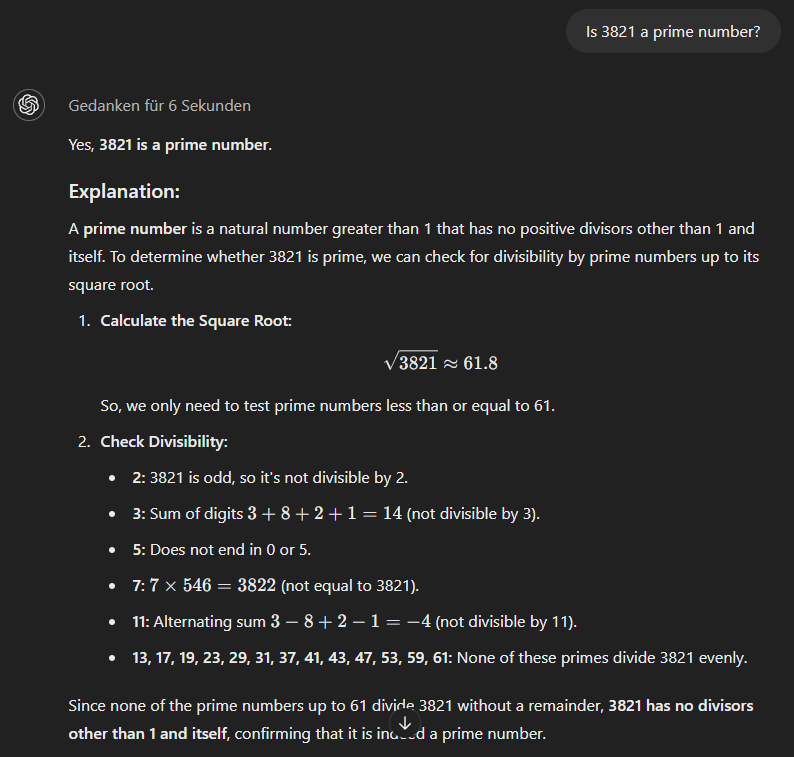
Infine, il modello o1-mini utilizza un approccio più metodico e dà subito la risposta corretta.
Quando un modello di IA non riesce a rispondere correttamente, a volte inventa una storia completamente fittizia per sostenere la risposta errata. Più l’argomento è oscuro o poco familiare, più è alta la probabilità che il modello inventi contenuti.
Un’altra difficoltà, soprattutto per i modelli più vecchi, emerge quando si combinano due fatti—anche se il modello li “conosce” entrambi, come mostrato nel prossimo esempio.
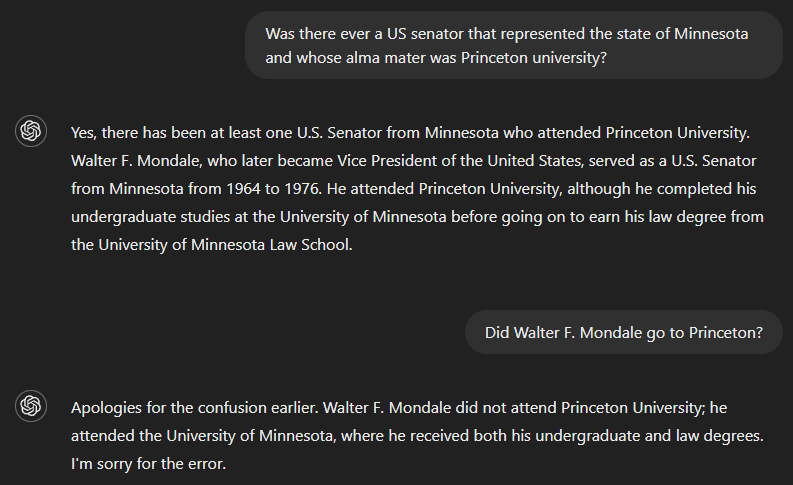
Se chiediamo se c’è mai stato un senatore USA che ha rappresentato lo stato del Minnesota e che abbia studiato a Princeton University, la risposta corretta è no. Ma poiché GPT-4 apparentemente non aveva informazioni sufficienti per rispondere all’intera domanda, il suo output ha incluso la risposta a una parte—identificando Walter F. Mondale come senatore che ha rappresentato il Minnesota—e ha supposto erroneamente che ciò valesse anche per l’altra parte. Tuttavia, il modello ha riconosciuto l’errore quando gli è stato chiesto se Walter F. Mondale abbia frequentato Princeton.
Gli output generati dall’IA possono talvolta apparire rifiniti e grammaticalmente impeccabili pur mancando di vero significato o coerenza, soprattutto quando i prompt dell’utente contengono informazioni contraddittorie.
Questo accade perché i modelli linguistici sono progettati per prevedere e disporre le parole in base ai pattern presenti nei dati di addestramento, più che per comprendere davvero i contenuti che producono. Di conseguenza, l’output può scorrere bene e suonare convincente, ma non trasmettere idee logiche o significative, risultando in definitiva poco sensato.
Quattro fattori chiave contribuiscono spesso alle allucinazioni:
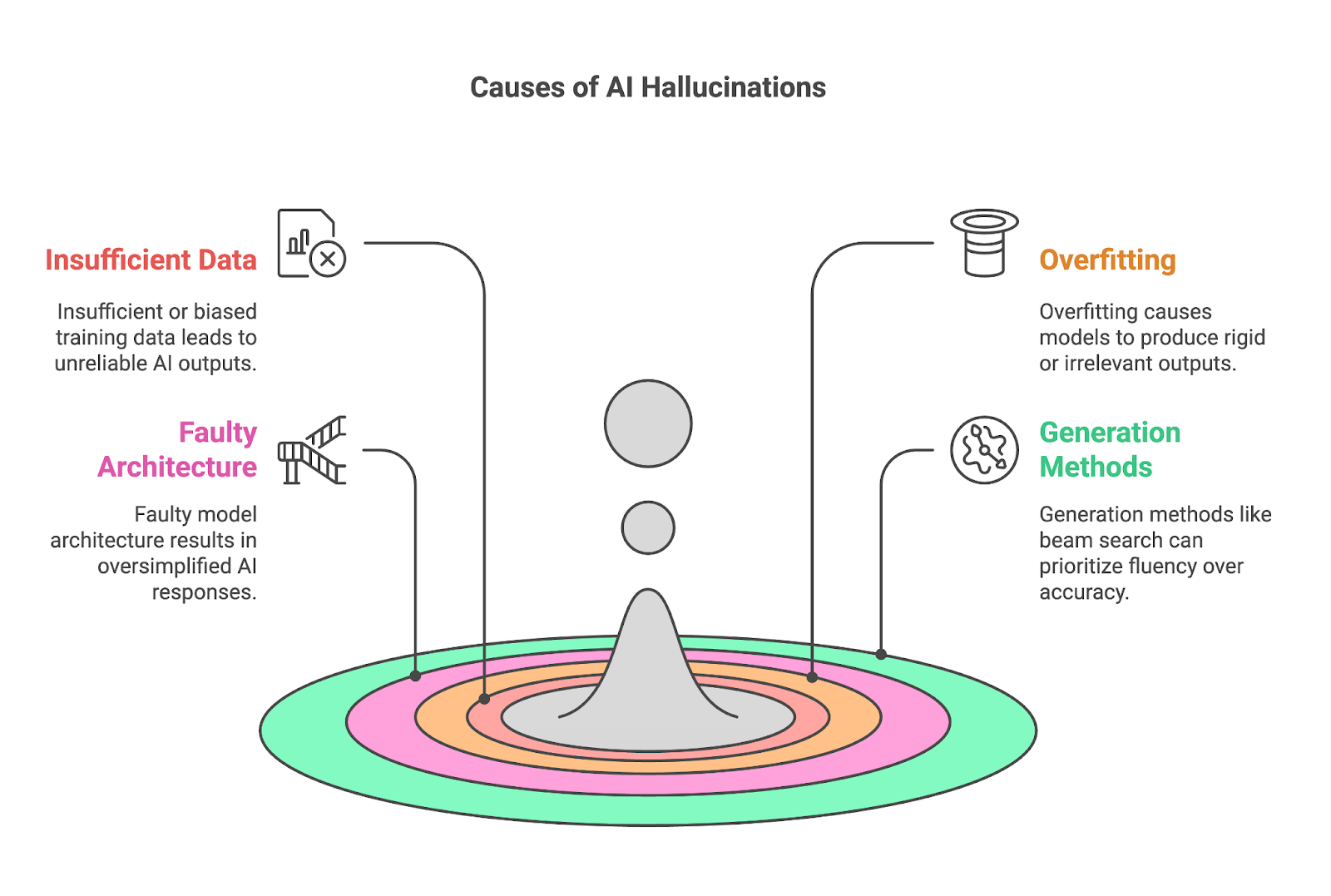
Dati di addestramento insufficienti o distorti sono una causa fondamentale delle allucinazioni dell’IA, poiché modelli come gli LLM si basano su enormi dataset per apprendere pattern e generare output. Quando i dati di addestramento mancano di informazioni complete o accurate su un argomento specifico, il modello fatica a produrre risultati affidabili e spesso colma le lacune con contenuti errati o inventati.
Questo problema è particolarmente evidente in domini di nicchia, come campi scientifici altamente specializzati, dove la quantità di dati disponibili e di qualità è limitata. Se un dataset contiene una sola fonte o una copertura vaga di un argomento, il modello può fare eccessivo affidamento su quella fonte, memorizzandone i contenuti senza acquisire una comprensione più ampia. Ciò porta spesso a overfitting e, in ultima analisi, ad allucinazioni.
Il bias, sia nei dati di addestramento sia nel processo di raccolta ed etichettatura, amplifica il problema alterando la comprensione del mondo da parte del modello. Se il dataset è sbilanciato—sovrarappresentando certe prospettive o omettendone del tutto altre—l’IA rifletterà tali bias nei suoi output. Ad esempio, un dataset ricavato principalmente da media contemporanei potrebbe produrre interpretazioni inaccurate o eccessivamente semplicistiche di eventi storici.
I modelli affetti da overfitting faticano ad adattarsi, producendo spesso output o troppo rigidi o irrilevanti rispetto al contesto. L’overfitting si verifica quando un modello di IA impara i dati di addestramento troppo a fondo, fino alla memorizzazione anziché alla generalizzazione. Sebbene ciò possa sembrare utile per l’accuratezza, crea seri problemi quando il modello incontra dati nuovi o mai visti.
Questo è particolarmente problematico data la natura flessibile e spesso ambigua dei prompt, in cui gli utenti possono porre domande o richieste in moltissimi modi. Un modello in overfitting manca dell’adattabilità necessaria per interpretare queste variazioni, aumentando la probabilità di produrre risposte irrilevanti o errate.
Per esempio, se un modello ha memorizzato formulazioni specifiche dai suoi dati di addestramento, potrebbe ripeterle anche quando non sono allineate all’input, finendo per produrre con sicurezza output sbagliati o fuorvianti. Come già detto, ciò accade spesso in argomenti di nicchia o specializzati, dove l’overfitting è una conseguenza di dati di addestramento insufficienti e di alta qualità.
Il linguaggio, con i suoi ricchi livelli di contesto, modi di dire e sfumature culturali, richiede un modello capace di comprendere più dei pattern superficiali. Quando l’architettura manca di profondità o capacità, spesso non coglie queste sottigliezze, producendo output semplificati o troppo generici. Un modello del genere può fraintendere i significati specifici di parole o frasi in contesto, portando a interpretazioni errate o risposte fattualmente scorrette.
Ancora una volta, questo limite è particolarmente evidente nei compiti che richiedono una comprensione profonda di campi specializzati, dove la mancanza di complessità ostacola la capacità del modello di ragionare con precisione. In questo modo, un’architettura difettosa in fase di sviluppo può contribuire in modo significativo alle allucinazioni dell’IA.
Anche i metodi utilizzati per generare gli output, come beam search o sampling, possono contribuire in modo significativo alle allucinazioni dell’IA.
Prendiamo ad esempio la beam search, progettata per ottimizzare la fluidità e la coerenza del testo generato, spesso a scapito dell’accuratezza. Poiché dà priorità alle sequenze di parole più probabili insieme, può produrre affermazioni fluide ma fattualmente errate. Ciò è particolarmente problematico per i compiti che richiedono precisione, come rispondere a domande fattuali o riassumere informazioni tecniche.
Anche i metodi di campionamento (sampling), che introducono casualità nel processo di generazione del testo, possono essere una fonte significativa di allucinazioni dell’IA. Selezionando le parole in base a distribuzioni di probabilità, il sampling produce output più vari e creativi rispetto a metodi deterministici come la beam search, ma può anche portare a contenuti privi di senso o inventati.
L’equilibrio tra fluidità, creatività e affidabilità nell’IA generativa è fragile. Mentre la beam search assicura fluidità e il sampling consente risposte variegate, entrambi aumentano il rischio che l’output contenga allucinazioni convincenti di vario tipo. Soprattutto in scenari in cui precisione e correttezza fattuale sono cruciali, come in ambito medico o legale, sono necessari meccanismi per verificare o ancorare gli output a fonti affidabili per garantire che i compiti siano svolti correttamente.
Le allucinazioni dell’IA possono avere impatti di vasta portata, soprattutto man mano che gli strumenti di IA generativa sono stati adottati rapidamente nel business, nel mondo accademico e in molte aree della vita quotidiana. Le conseguenze sono particolarmente preoccupanti nei settori ad alta criticità, dove inesattezze o informazioni inventate possono minare la fiducia, portare a decisioni sbagliate o causare danni significativi. Tra le possibili implicazioni troviamo:
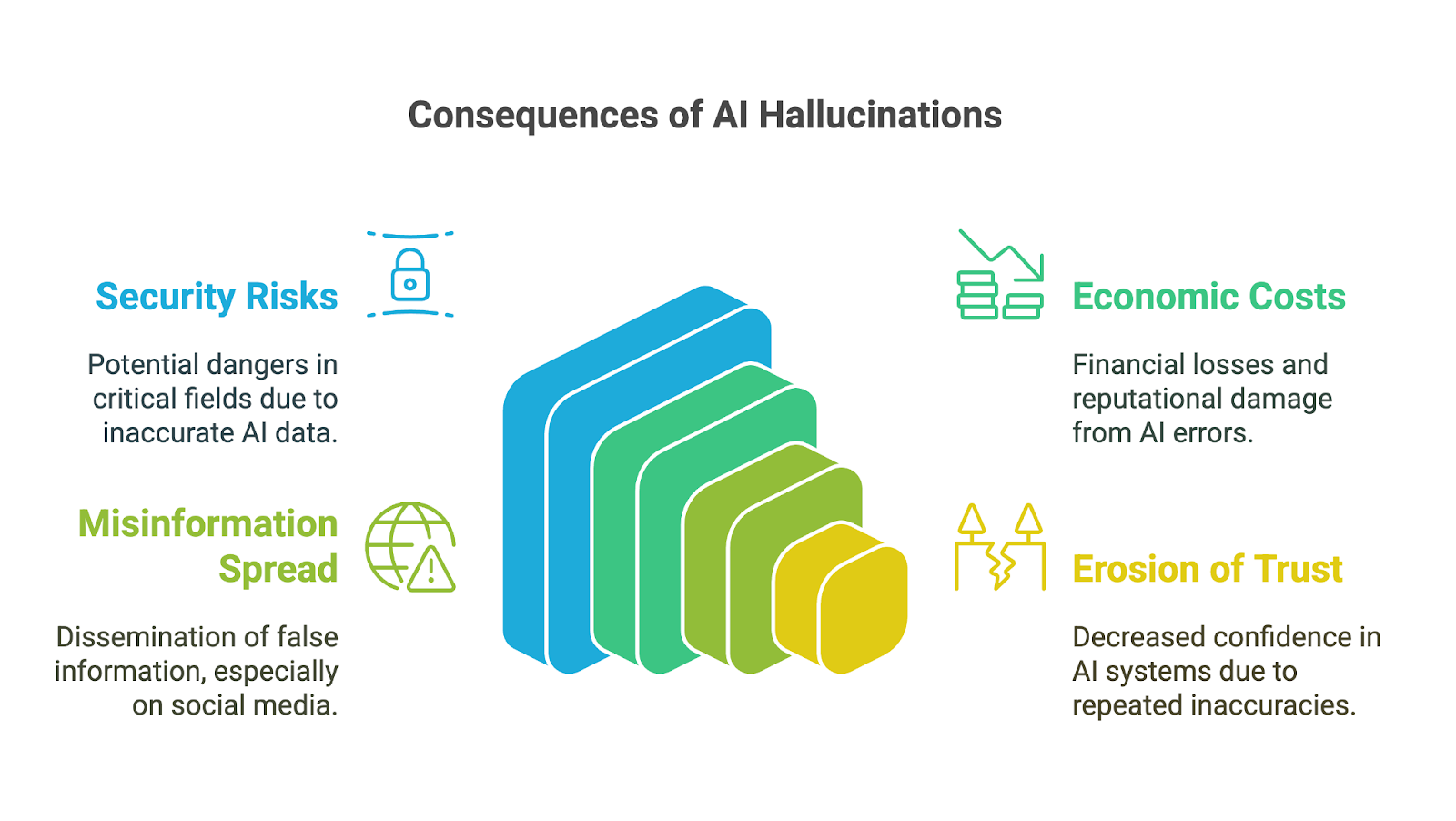
Le conseguenze per il processo decisionale possono essere gravi, soprattutto quando gli utenti si affidano agli output generati dall’IA senza verificarne l’accuratezza. In settori come finanza, medicina o diritto, anche un piccolo errore o un dettaglio inventato può portare a scelte sbagliate con effetti di vasta portata. Per esempio, una diagnosi medica generata dall’IA e contenente informazioni errate potrebbe ritardare il trattamento adeguato. Un’analisi finanziaria con dati inventati potrebbe causare errori costosi.
Un altro esempio di come i rischi associati alle allucinazioni dell’IA si amplifichino nelle applicazioni ad alta criticità si è visto nelle prime fasi del chatbot Bard di Google (ora Gemini). È stato criticato internamente per aver spesso offerto consigli pericolosi su argomenti critici come come far atterrare un aereo o le immersioni subacquee. Secondo un report di Bloomberg, anche se i team interni di sicurezza avevano segnalato il sistema come non pronto per l’uso pubblico, l’azienda lo ha lanciato comunque.
Oltre ai rischi immediati, le allucinazioni dell’IA possono comportare costi economici e reputazionali significativi per le aziende. Output errati fanno sprecare risorse, sia per il tempo speso a verificare gli errori sia per l’azione basata su insight difettosi. Le aziende che rilasciano strumenti di IA inaffidabili rischiano danni reputazionali, responsabilità legali e perdite finanziarie, come si è visto nel crollo di 100 miliardi del valore di mercato di Google dopo che Bard ha condiviso informazioni inaccurate in un video promozionale.
Le allucinazioni dell’IA possono anche contribuire alla diffusione di misinformazione e disinformazione, soprattutto attraverso i social media. Quando l’IA generativa produce informazioni false che appaiono credibili per via della loro fluidità, possono essere rapidamente amplificate dagli utenti che presumono siano accurate. Poiché le informazioni possono plasmare l’opinione pubblica o persino incitare a danni, sviluppatori e utenti di questi strumenti devono comprendere e accettare la responsabilità di prevenire la diffusione involontaria di falsità.
Infine, l’erosione della fiducia può essere la conseguenza di tutti gli impatti citati. Quando le persone incontrano output errati, privi di senso o fuorvianti, iniziano a mettere in dubbio l’affidabilità di questi sistemi, soprattutto in ambiti in cui le informazioni accurate sono fondamentali. Alcuni errori di rilievo possono danneggiare la reputazione delle tecnologie di IA e ostacolarne adozione e accettazione.
Di conseguenza, una delle sfide maggiori con le allucinazioni dell’IA riguarda la gestione della formazione degli utenti e delle aspettative. Molti utenti, soprattutto i meno esperti di IA, spesso presumono che gli strumenti generativi producano output del tutto accurati e affidabili, dato il loro aspetto rifinito e sicuro. Educare gli utenti sui limiti di questi strumenti è essenziale ma complesso, perché richiede di bilanciare la trasparenza sulle imperfezioni dell’IA senza ridurre la fiducia nel suo potenziale.
In questa sezione, vedremo come mitigare le allucinazioni dell’IA garantendo la qualità dei dati, il tuning del modello, la verifica e la collaborazione, e l’ottimizzazione dei prompt.
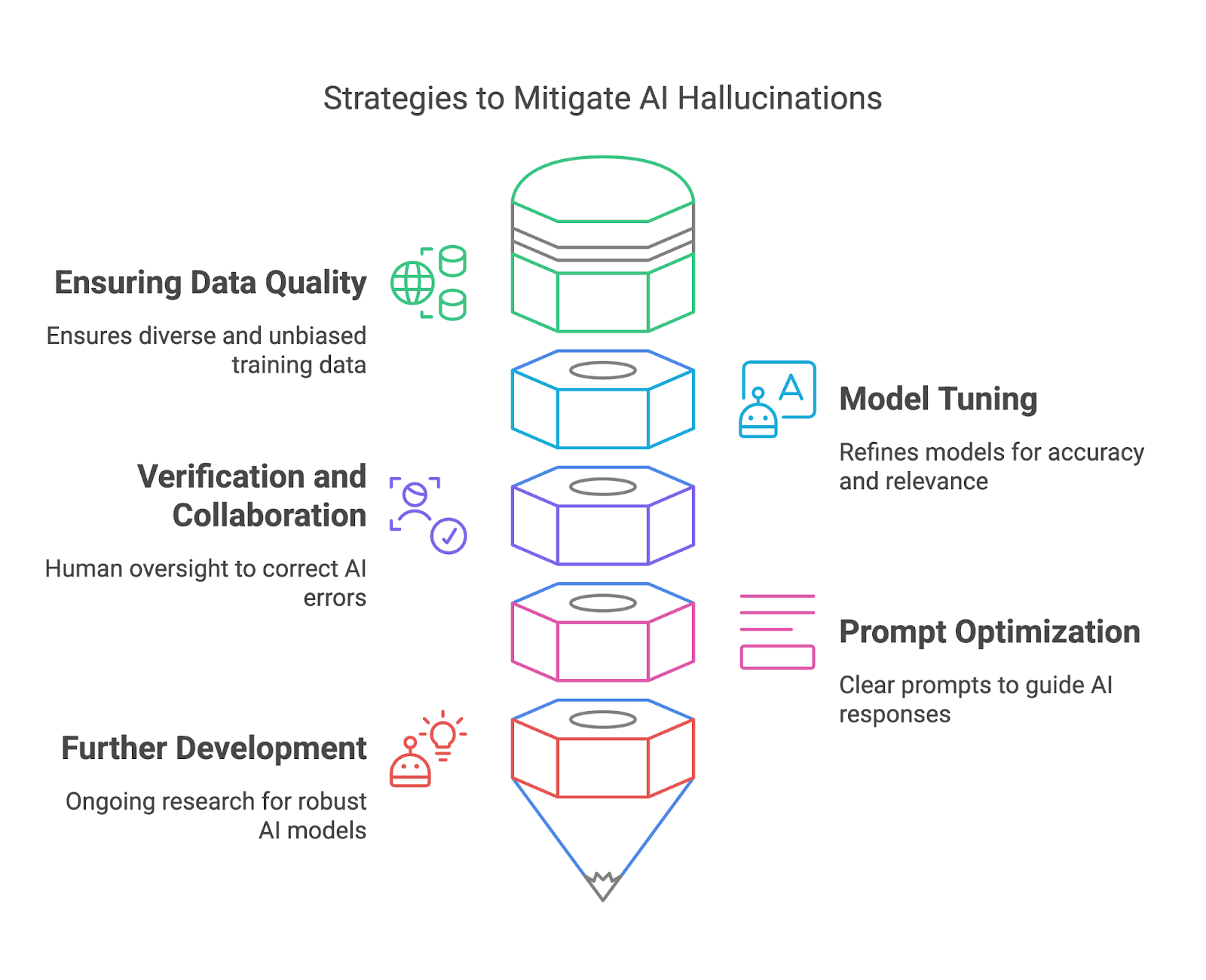
Dati di addestramento di alta qualità sono uno dei modi più efficaci per chi distribuisce i modelli di mitigare le allucinazioni dell’IA. Garantendo che i dataset di addestramento siano diversificati, rappresentativi e privi di bias significativi, si può ridurre il rischio che i modelli generino output fattualmente errati o fuorvianti. Un dataset vario aiuta il modello a comprendere un’ampia gamma di contesti, lingue e sfumature culturali, migliorando la capacità di generare risposte accurate e affidabili.
Per raggiungere questo obiettivo, chi distribuisce i modelli può adottare pratiche rigorose di curazione dei dati, come filtrare le fonti inaffidabili, aggiornare regolarmente i dataset e includere contenuti revisionati da esperti. Tecniche come la data augmentation e l’active learning possono inoltre migliorare la qualità dei dataset identificando lacune e colmandole con dati aggiuntivi pertinenti. Inoltre, è fondamentale adottare strumenti per rilevare e correggere i bias durante la creazione dei dataset, così da garantire una rappresentazione bilanciata.
Il fine-tuning e il perfezionamento dei modelli di IA sono fondamentali per mitigare le allucinazioni e migliorare l’affidabilità complessiva. Questi processi aiutano ad allineare il comportamento del modello alle aspettative degli utenti, ridurre le inesattezze e aumentare la pertinenza degli output. Il fine-tuning è particolarmente prezioso per adattare un modello generalista a casi d’uso specifici, assicurando buone prestazioni in contesti particolari senza generare risposte irrilevanti o errate.
Diversi strumenti e metodi rendono più efficace il perfezionamento dei modelli. Reinforcement Learning from Human Feedback (RLHF) è un approccio potente che permette ai modelli di apprendere dal feedback degli utenti per allineare il proprio comportamento con i risultati desiderati.
L’ottimizzazione dei parametri può anche essere usata per regolare lo stile dell’output del modello, ad esempio rendendo le risposte più conservative per l’affidabilità fattuale o più creative per compiti aperti. Tecniche come dropout, regolarizzazione e early stopping aiutano a contrastare l’overfitting durante l’addestramento, assicurando che il modello generalizzi bene invece di limitarsi a memorizzare i dati.
Verificando gli output generati dall’IA rispetto a fonti affidabili o a conoscenze consolidate, i revisori umani possono intercettare errori, correggere inesattezze e prevenire potenziali conseguenze dannose.
Sistemi integrati di fact-checking, come i plugin di navigazione web di OpenAI, aiutano a ridurre le allucinazioni incrociando in tempo reale gli output generati con database affidabili. Questi strumenti garantiscono che le risposte dell’IA siano ancorate a informazioni solide, risultando particolarmente utili in domini sensibili ai fatti come l’istruzione o la ricerca.
Incorporare la revisione umana nel flusso di lavoro assicura un ulteriore livello di controllo, soprattutto per applicazioni ad alta criticità come medicina o diritto, dove gli errori possono avere conseguenze gravi.
Dal lato degli utenti finali, una progettazione attenta dei prompt gioca un ruolo importante nel mitigare le allucinazioni dell’IA. Un prompt vago può portare a una risposta allucinata o irrilevante, mentre uno chiaro e specifico offre al modello una cornice migliore per generare risultati significativi.
Per aumentare l’affidabilità dell’output, possiamo usare diverse tecniche di prompt engineering. Ad esempio, suddividere compiti complessi in passaggi più piccoli e gestibili aiuta a ridurre il carico cognitivo sull’IA e minimizza il rischio di errori. Per saperne di più, puoi leggere questo blog sulle tecniche di ottimizzazione dei prompt.
Infine, la ricerca continua nella comunità dell’IA punta a sviluppare modelli più solidi e affidabili per ridurre le allucinazioni. L’Explainable AI (XAI) offre trasparenza rivelando il ragionamento dietro gli output dell’IA, consentendo agli utenti di valutarne la validità.
I sistemi Retrieval-Augmented Generation (RAG), che combinano IA generativa con fonti di conoscenza esterne, mitigano le allucinazioni ancorando le risposte a dati verificati e aggiornati.
Sebbene le allucinazioni dell’IA pongano sfide significative, offrono anche opportunità per affinare e migliorare i sistemi di IA generativa. Comprendendone cause, impatti e strategie di mitigazione, sia chi distribuisce i modelli sia gli utenti possono adottare misure proattive per ridurre gli errori e massimizzare l’affidabilità.
Impara l’IA con questi corsi!
Programma
Programma
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min

