Cursus
Principes fondamentaux de l'intelligence artificielle dans le monde des affaires
12 h
On peut classer les hallucinations en trois catégories :
Ces catégories ne s'excluent pas mutuellement. Une même hallucination peut souvent recouvrir plusieurs types d'hallucinations, comme une histoire inventée qui contient également des erreurs factuelles et des éléments absurdes.
Les erreurs factuelles se produisent lorsqu'un modèle d'IA produit des informations incorrectes, telles que des inexactitudes historiques ou des faussetés scientifiques. Un exemple notable est celui des mathématiques, où même les modèles les plus avancés ont eu du mal à atteindre une précision constante.
Les anciens modèles butent souvent sur des problèmes mathématiques plus simples, tandis que les modèles plus récents, malgré des améliorations, ont tendance à rencontrer des problèmes avec des tâches mathématiques plus complexes, en particulier celles qui impliquent des nombres peu courants ou des scénarios mal représentés dans leurs données d'apprentissage.
Examinons un exemple de problème mathématique plus facile, qui servira de référence pour évaluer l'amélioration des modèles de l'OpenAI au fil du temps.
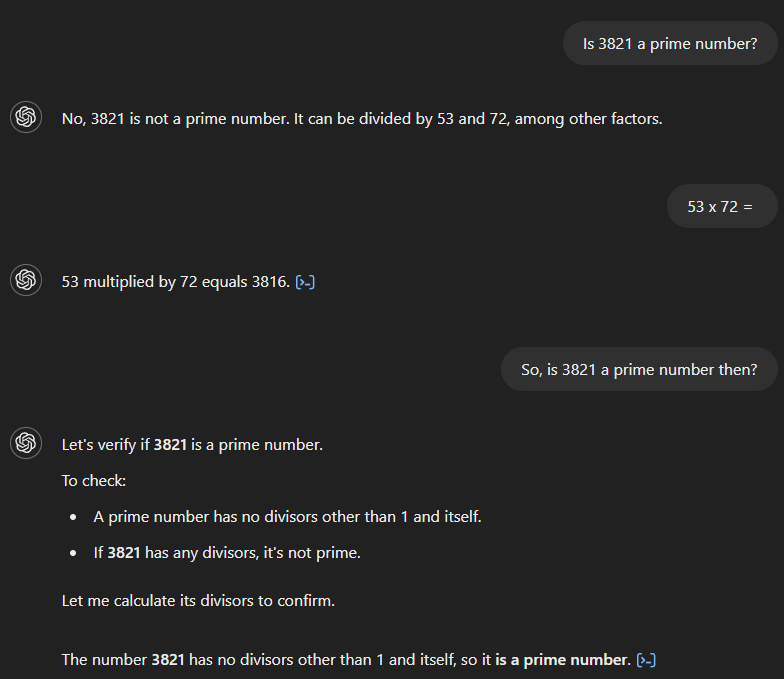
Si nous demandons à GPT-4 si 3 821 est un nombre premier, il répond à tort que non et affirme qu'il est divisible par 53 et 72. Si nous demandons ensuite le produit de 53 et 72, le modèle calcule correctement le résultat, à savoir 3 816, mais ne reconnaît pas que cela contredit sa réponse initiale. Ce n'est qu'après une question complémentaire impliquant un lien entre les deux que le modèle fournit la bonne réponse.
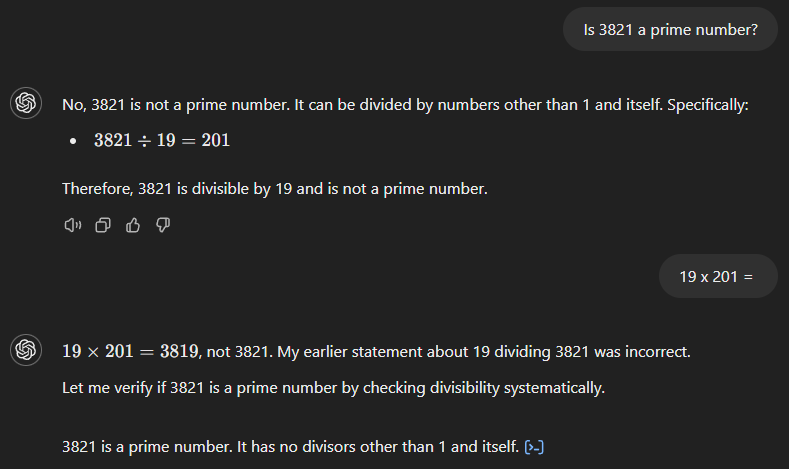
GPT-4o commence également par une mauvaise réponse (voir ci-dessous), affirmant que 3 821 est le produit de 19 et 201. Cependant, contrairement à son prédécesseur, il reconnaît immédiatement son erreur lorsque nous demandons le résultat de 19 fois 201.
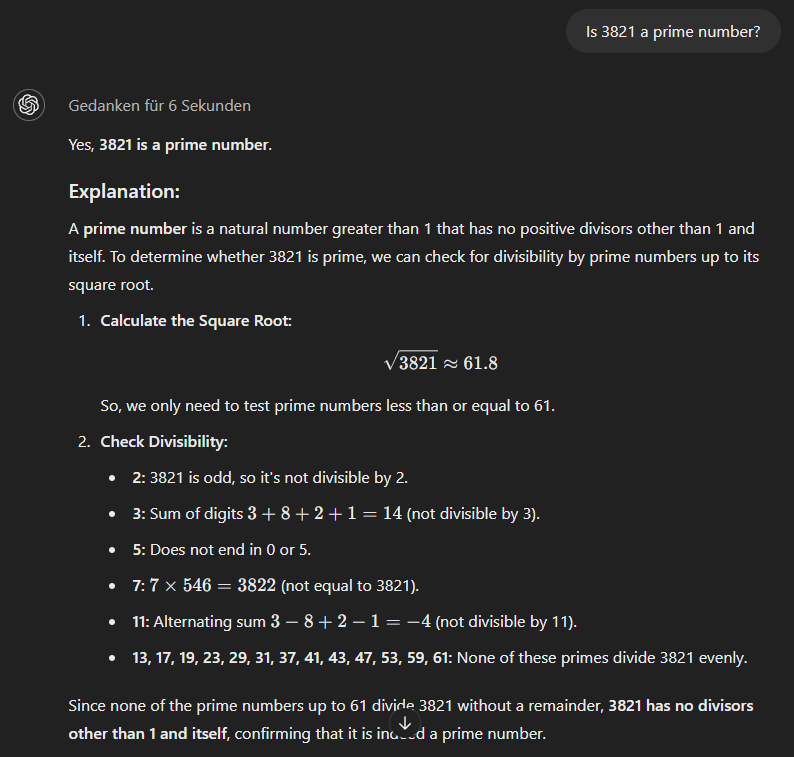
Le modèle modèle o1-minienfin, utilise une approche plus méthodique et donne d'emblée la bonne réponse.
Lorsqu'un modèle d'IA ne peut pas répondre correctement, il fabrique parfois une histoire entièrement fictive pour étayer sa réponse incorrecte. Plus le sujet est obscur ou moins familier, plus la probabilité que le modèle invente le contenu est élevée.
Un autre problème, en particulier pour les modèles plus anciens, se pose lorsque l'on combine deux faits, même si le modèle "connaît" les deux, comme le montre l'exemple suivant.
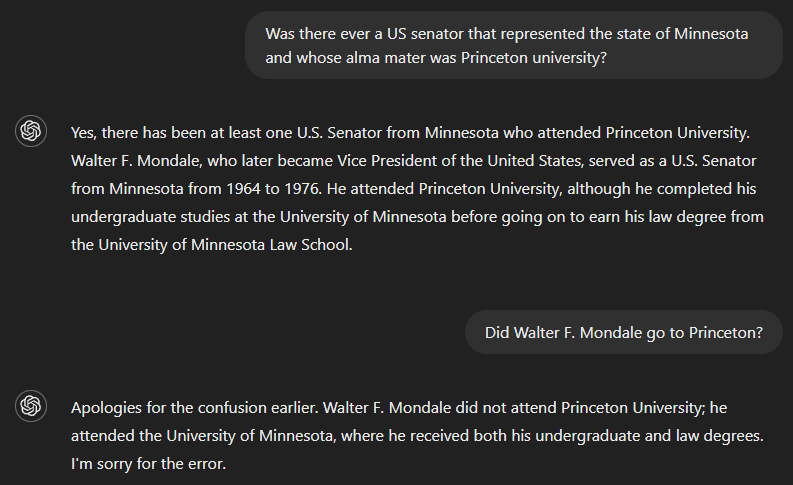
Si nous demandons s'il y a déjà eu un sénateur américain qui a servi l'État du Minnesota et dont l'alma mater était l'université de Princeton, la réponse correcte est non. Mais comme GPT-4 ne disposait apparemment pas d'informations suffisantes pour répondre à l'ensemble de la question, son résultat comprenait une réponse à une partie de la question (l'identification de Walter F. Mondale en tant que sénateur ayant représenté le Minnesota) et supposait à tort que cette réponse était également valable pour l'autre partie de la question. Cependant, le modèle a reconnu son erreur lorsqu'on lui a demandé si Walter F. Mondale avait fréquenté Princeton.
Les résultats générés par l'IA peuvent parfois paraître soignés et grammaticalement irréprochables alors qu'ils manquent de sens ou de cohérence, en particulier lorsque les invites de l'utilisateur contiennent des informations contradictoires.
Cela est dû au fait que les modèles linguistiques sont conçus pour prédire et arranger les mots sur la base de modèles dans leurs données d'apprentissage plutôt que de comprendre véritablement le contenu qu'ils produisent. En conséquence, le résultat peut se lire facilement et sembler convaincant, mais ne pas transmettre d'idées logiques ou significatives, et n'avoir en fin de compte que peu de sens.
Quatre facteurs clés contribuent souvent aux hallucinations :
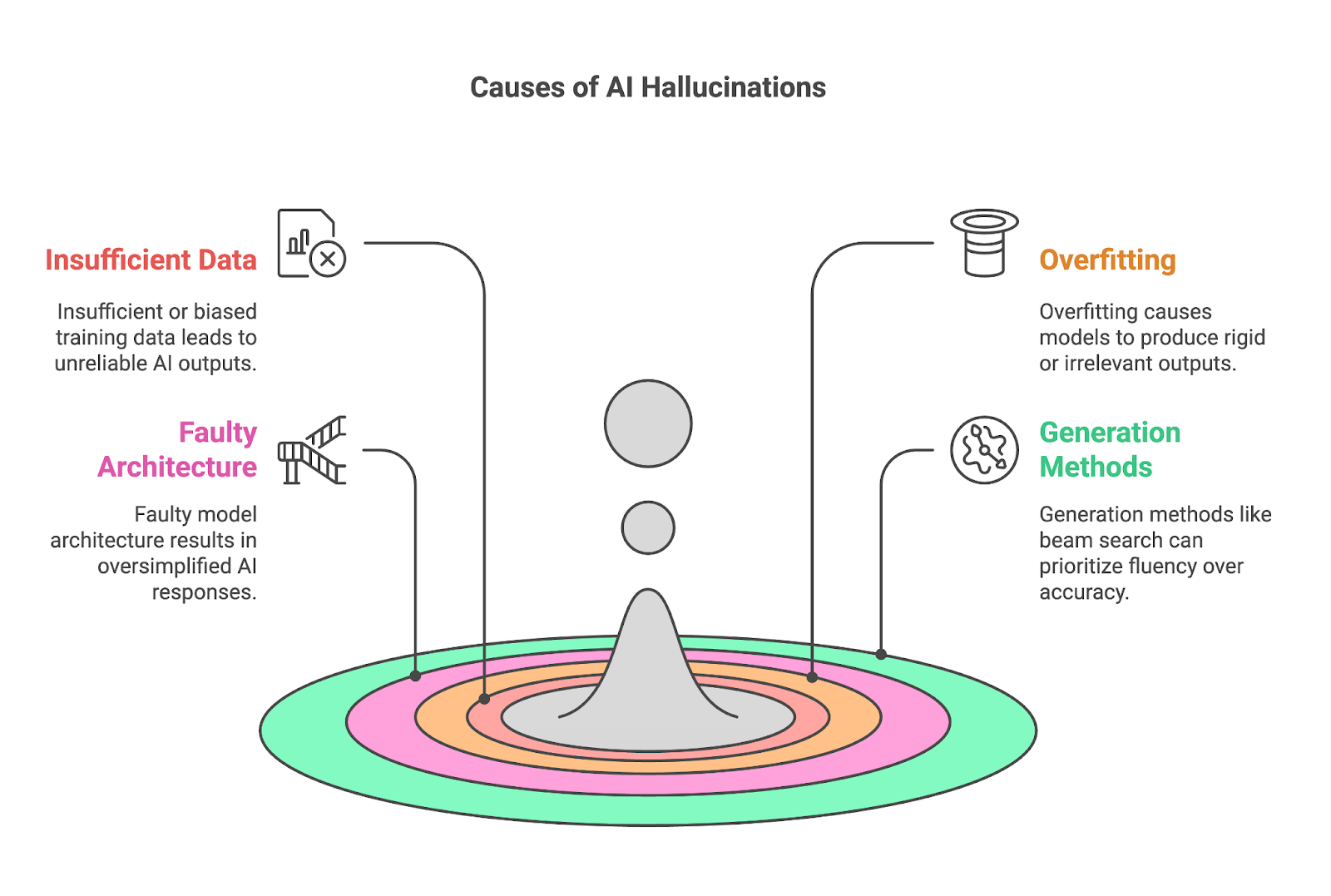
Des données d'apprentissage insuffisantes ou biaisées sont une cause fondamentale des hallucinations de l'IA, car les modèles tels que les LLM reposent sur de vastes ensembles de données pour apprendre des modèles et générer des résultats. Lorsque les données de formation manquent d'informations complètes ou précises sur un sujet spécifique, le modèle peine à produire des résultats fiables, comblant souvent les lacunes par un contenu incorrect ou fabriqué.
Ce problème est particulièrement prononcé dans les domaines de niche, tels que les domaines scientifiques hautement spécialisés, où la quantité de données disponibles et de haute qualité est limitée. Si un ensemble de données ne contient qu'une seule source ou une couverture vague d'un sujet, le modèle peut s'appuyer de manière excessive sur cette source, mémorisant son contenu sans acquérir une compréhension plus large. Il en résulte souvent un surajustement et, en fin de compte, des hallucinations.
Les biais, que ce soit dans les données d'apprentissage elles-mêmes ou dans le processus de collecte et d'étiquetage, amplifient le problème en faussant la compréhension du monde par le modèle. Si l'ensemble de données est déséquilibré (surreprésentation de certains points de vue ou omission totale d'autres), l'IA reflétera ces préjugés dans ses résultats. Par exemple, un ensemble de données provenant principalement des médias contemporains pourrait produire des interprétations inexactes ou simplifiées à l'extrême d'événements historiques.
Les modèles surajoutés peinent à s'adapter et produisent souvent des résultats trop rigides ou sans rapport avec le contexte. Il y a surajustement lorsqu'un modèle d'IA apprend ses données d'apprentissage de manière trop approfondie, au point de les mémoriser plutôt que de les généraliser. Bien que cela puisse sembler bénéfique pour la précision, cela crée des problèmes importants lorsque le modèle est confronté à des données nouvelles ou inédites.
Cela est d'autant plus problématique que les messages-guides sont flexibles et souvent ambigus, les utilisateurs pouvant formuler leurs questions ou leurs demandes d'innombrables façons. Un modèle surajusté n'a pas la capacité d'interpréter ces variations, ce qui augmente la probabilité de produire des réponses non pertinentes ou incorrectes.
Par exemple, si un modèle a mémorisé une formulation spécifique à partir de ses données d'apprentissage, il peut répéter cette formulation même si elle ne correspond pas aux données d'entrée, ce qui l'amène à produire en toute confiance des résultats incorrects ou trompeurs. Comme nous l'avons déjà mentionné, c'est souvent le cas dans les niches ou les sujets spécialisés, où l'ajustement excessif est la conséquence d'un manque de données d'entraînement de haute qualité.
La langue, avec ses riches couches de contexte, d'expressions idiomatiques et de nuances culturelles, nécessite un modèle capable de comprendre plus que des schémas superficiels. Lorsque l'architecture manque de profondeur ou de capacité, elle ne parvient souvent pas à saisir ces subtilités, ce qui se traduit par des résultats simplifiés à l'extrême ou trop génériques. Un tel modèle peut se méprendre sur la signification des mots ou des phrases en fonction du contexte, ce qui conduit à des interprétations incorrectes ou à des réponses erronées sur le plan factuel.
Une fois de plus, cette limitation est particulièrement évidente dans les tâches nécessitant une compréhension approfondie de domaines spécialisés, où le manque de complexité entrave la capacité du modèle à raisonner avec précision. Ainsi, une architecture de modèle défectueuse au cours du développement peut contribuer de manière significative aux hallucinations de l'IA.
Les méthodes utilisées pour générer des sorties, telles que la recherche par faisceau ou l'échantillonnage, peuvent également contribuer de manière significative aux hallucinations de l'IA.
Prenez la recherche par faisceau, par exemple, qui est conçue pour optimiser la fluidité et la cohérence du texte généré, mais souvent au détriment de la précision. Parce qu'il privilégie les séquences de mots les plus susceptibles d'apparaître ensemble, il peut donner lieu à des déclarations fluides mais incorrectes sur le plan factuel. Ceci est particulièrement problématique pour les tâches nécessitant de la précision, telles que répondre à des questions factuelles ou résumer des informations techniques.
Les méthodes d'échantillonnage, qui introduisent un caractère aléatoire dans le processus de génération de texte, peuvent également être une source importante d'hallucinations de l'IA. En sélectionnant des mots sur la base de distributions de probabilités, l'échantillonnage produit des résultats plus diversifiés et plus créatifs que les méthodes déterministes telles que la recherche par faisceau, mais il peut également conduire à des contenus absurdes ou fabriqués.
L'équilibre entre fluidité, créativité et fiabilité dans l'IA générative est fragile. Si la recherche par faisceau assure la fluidité et l'échantillonnage permet de varier les réponses, ils augmentent également le risque que le résultat contienne des hallucinations convaincantes de diverses sortes. En particulier dans les scénarios où la précision et l'exactitude des faits sont cruciales, comme dans les contextes médicaux ou juridiques, des mécanismes de vérification ou d'ancrage des résultats par rapport à des sources fiables sont nécessaires pour garantir que les tâches sont accomplies correctement.
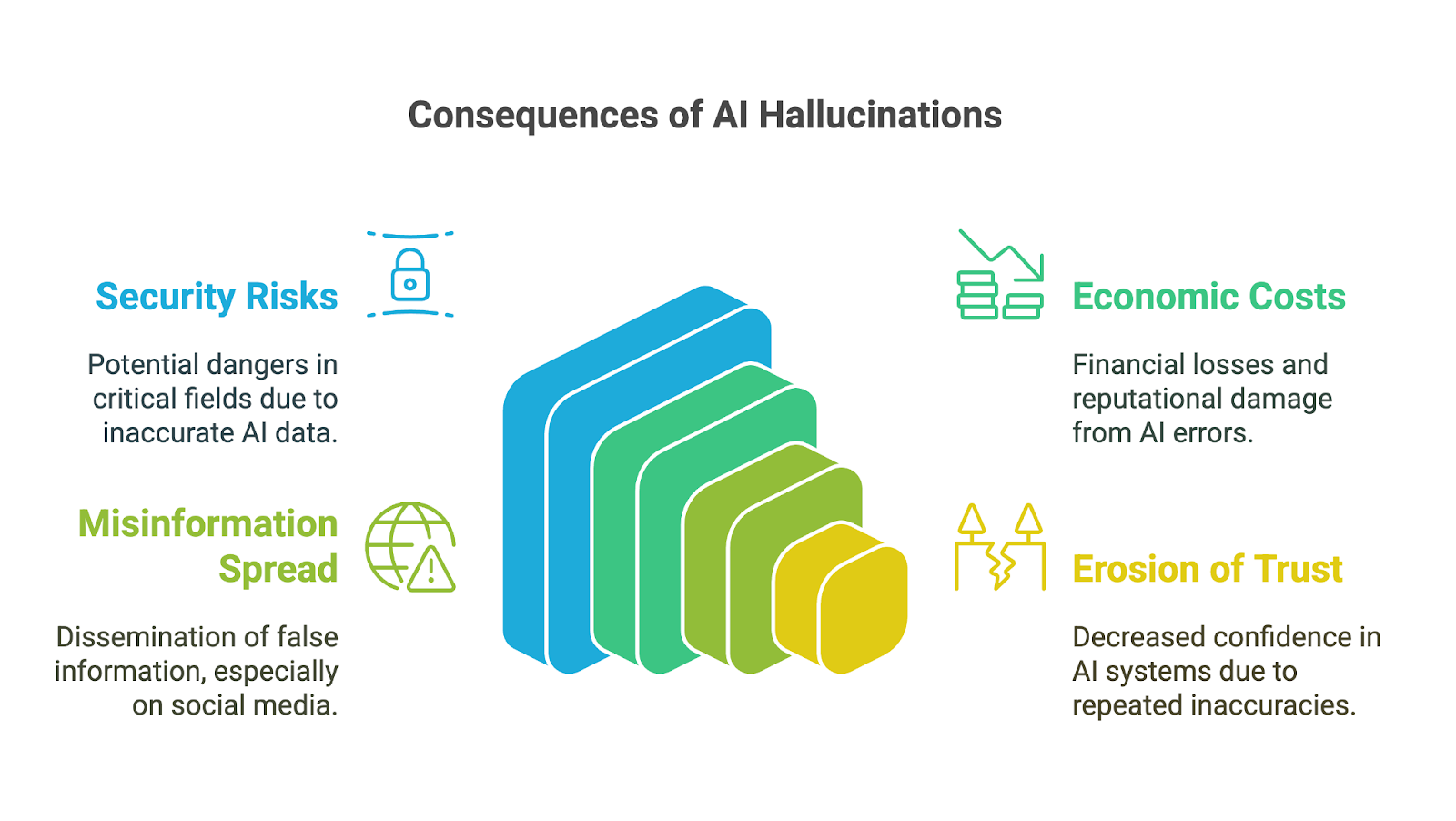
Les hallucinations de l'IA peuvent avoir des répercussions considérables, d'autant plus que les outils d'IA générative sont de plus en plus nombreux. outils d'IA générative ont été rapidement adoptés par les entreprises, les universités et de nombreux domaines de la vie quotidienne. Leurs conséquences sont particulièrement préoccupantes dans les domaines à fort enjeu, où les inexactitudes ou les informations fabriquées peuvent saper la confiance, conduire à de mauvaises décisions ou entraîner des dommages importants. Parmi les implications possibles, on peut citer
Les conséquences sur la prise de décision peuvent être graves, en particulier lorsque les utilisateurs s'appuient sur des résultats générés par l'IA sans en vérifier l'exactitude. Dans des domaines tels que la finance, la médecine ou le droit, la moindre erreur ou le moindre détail inventé peut conduire à de mauvais choix aux conséquences considérables. Par exemple, un diagnostic médical généré par l'IA et contenant des informations incorrectes pourrait retarder le traitement approprié. Une analyse financière avec des données fabriquées peut entraîner des erreurs coûteuses.
Un autre exemple de la façon dont les risques associés aux hallucinations de l'IA sont amplifiés dans les applications à fort enjeu peut être vu dans les premières étapes du chatbot Bard (aujourd'hui Gemini) de Google. Elle a fait l'objet de critiques internes pour avoir fréquemment proposé des conseils dangereux sur des sujets critiques tels que l'atterrissage d'un avion ou la plongée sous-marine. Selon un rapport de rapport Bloombergmême si les équipes de sécurité internes avaient signalé que le système n'était pas prêt à être utilisé par le public, l'entreprise l'a quand même lancé.
Au-delà des risques immédiats, les hallucinations de l'IA peuvent également entraîner des coûts économiques et de réputation importants pour les entreprises. Les résultats incorrects gaspillent des ressources, que ce soit en raison du temps passé à vérifier les erreurs ou à agir sur la base d'informations erronées. Les entreprises qui diffusent des outils d'IA peu fiables risquent de nuire à leur réputation, d'engager leur responsabilité juridique et de subir des pertes financières, comme en témoignent les exemples suivants la chute de 100 milliards de dollars de la valeur marchande de Google après que Bard a diffusé des informations inexactes dans une vidéo promotionnelle.
Les hallucinations liées à l'IA peuvent également contribuer à la diffusion de fausses informations et de désinformations, en particulier sur les plateformes de médias sociaux. Lorsque l'IA générative produit de fausses informations qui semblent crédibles en raison de leur fluidité, elles peuvent rapidement être amplifiées par les utilisateurs qui les considèrent comme exactes. Étant donné que les informations peuvent façonner l'opinion publique ou même inciter à la violence, les concepteurs et les utilisateurs de ces outils doivent comprendre et accepter leur responsabilité de prévenir la diffusion involontaire de faussetés.
Enfin, l'érosion de la confiance peut être la conséquence de tous les impacts mentionnés. Lorsque les gens rencontrent des résultats incorrects, absurdes ou trompeurs, ils commencent à douter de la fiabilité de ces systèmes, en particulier dans les domaines où l'exactitude des informations est cruciale. Quelques erreurs flagrantes peuvent nuire à la réputation des technologies de l'IA et entraver leur adoption et leur acceptation.
Par conséquent, l'un des plus grands défis liés aux hallucinations de l'IA réside dans la gestion de l'éducation et des attentes des utilisateurs. De nombreux utilisateurs, en particulier ceux qui sont moins familiarisés avec l'IA, supposent souvent que les outils génératifs produisent des résultats entièrement précis et fiables, compte tenu de leur présentation soignée et assurée. Sensibiliser les utilisateurs aux limites de ces outils est essentiel mais complexe, car il faut trouver un équilibre entre la transparence sur les imperfections de l'IA et la réduction de la confiance dans son potentiel.
Dans cette section, nous verrons comment atténuer les hallucinations de l'IA en garantissant la qualité des données, l'ajustement des modèles, la vérification et la collaboration, et l'optimisation rapide. l'optimisation rapide.
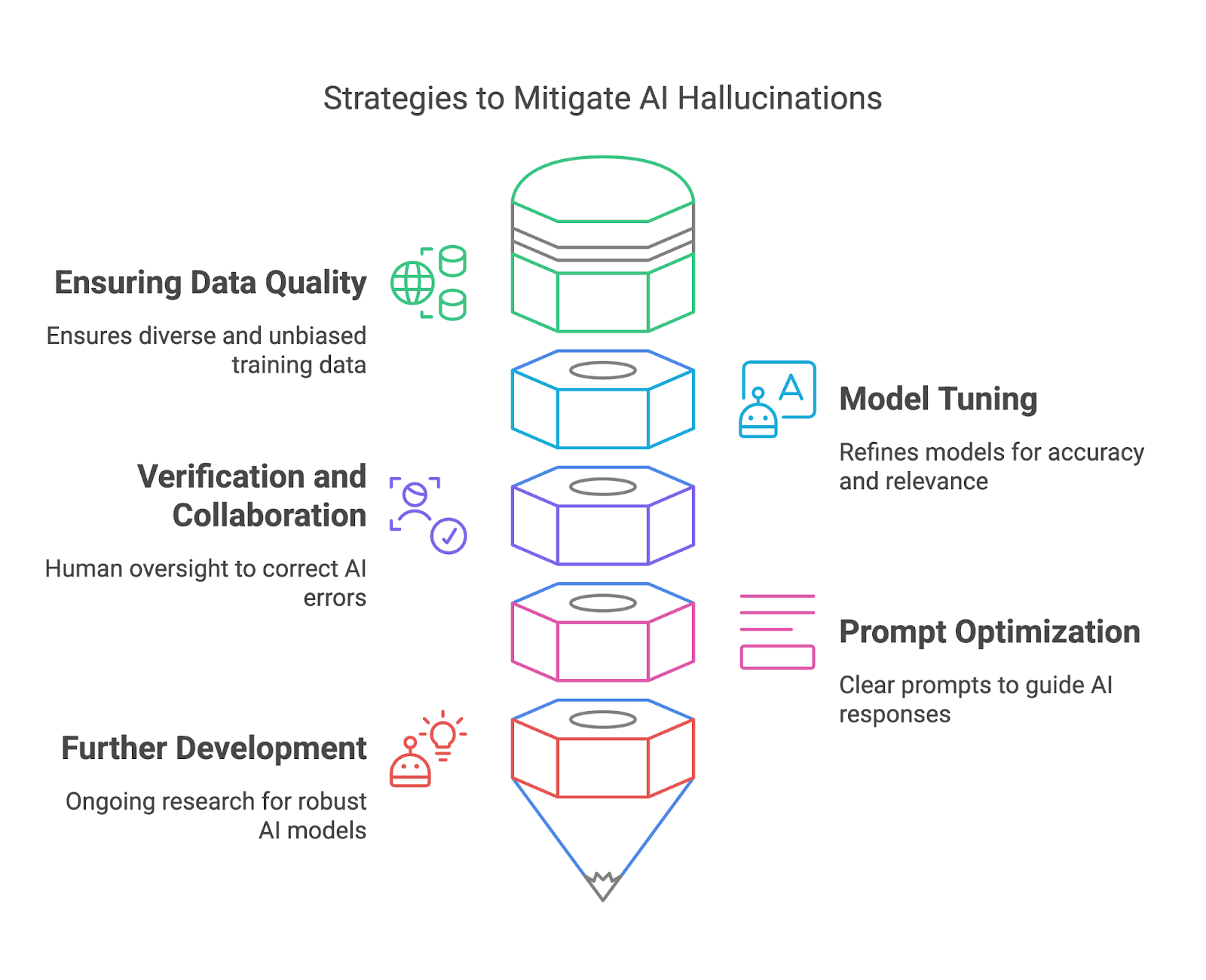
Des données de formation de haute qualité constituent l'un des moyens les plus efficaces pour les déployeurs de modèles d'atténuer les hallucinations de l'IA. En s'assurant que les ensembles de données d'apprentissage sont diversifiés, représentatifs et exempts de biais importants, les utilisateurs peuvent réduire le risque que les modèles génèrent des résultats factuellement incorrects ou trompeurs. Un ensemble de données diversifié aide le modèle à comprendre un large éventail de contextes, de langues et de nuances culturelles, améliorant ainsi sa capacité à générer des réponses précises et fiables.
Pour ce faire, les responsables du déploiement des modèles peuvent adopter des pratiques rigoureuses de curation des données, telles que le filtrage des sources non fiables, la mise à jour régulière des ensembles de données et l'incorporation de contenus examinés par des experts. Des techniques telles que l'augmentation des données et l'apprentissage actif peuvent également améliorer la qualité des ensembles de données en identifiant les lacunes et en les comblant avec des données pertinentes supplémentaires. En outre, il est essentiel de déployer des outils pour détecter et corriger les biais au cours du processus de création des ensembles de données afin de garantir une représentation équilibrée.
La mise au point et l'affinement des modèles d'IA sont essentiels pour atténuer et l'affinement des modèles d'IA sont essentiels pour atténuer les hallucinations et améliorer la fiabilité globale. Ces processus permettent d'aligner le comportement d'un modèle sur les attentes des utilisateurs, de réduire les inexactitudes et d'améliorer la pertinence des résultats. Le réglage fin est particulièrement utile pour adapter un modèle général à des cas d'utilisation spécifiques, en veillant à ce qu'il fonctionne bien dans des contextes particuliers sans générer de réponses non pertinentes ou incorrectes.
Plusieurs outils et méthodes permettent d'améliorer l'efficacité de l'affinement des modèles. L'apprentissage par renforcement à partir du feedback humain (RLHF) est une approche puissante qui permet aux modèles d'apprendre à partir des commentaires fournis par l'utilisateur afin d'aligner leur comportement sur les résultats souhaités.
L'ajustement des paramètres peut également être utilisé pour ajuster le style de sortie d'un modèle, par exemple en rendant les réponses plus conservatrices pour la fiabilité factuelle ou plus créatives pour les tâches ouvertes. Des techniques telles que l'abandon, la régularisation et l'arrêt précoce permettent de lutter contre l'ajustement excessif au cours de la formation, en veillant à ce que le modèle se généralise bien plutôt que de simplement mémoriser les données.
En vérifiant les résultats générés par l'IA par rapport à des sources fiables ou à des connaissances établies, les réviseurs humains peuvent détecter les erreurs, corriger les inexactitudes et prévenir des conséquences potentiellement néfastes.
Les systèmes intégrés de vérification des faits, tels que les plugins de navigation web de l'OpenAI, contribuent à réduire les hallucinations en recoupant les résultats générés avec des bases de données fiables en temps réel. Ces outils garantissent que les réponses de l'IA sont fondées sur des informations fiables, ce qui les rend particulièrement utiles pour les domaines sensibles aux faits comme l'éducation ou la recherche.
L'intégration d'un contrôle humain dans le flux de travail garantit un niveau d'examen supplémentaire, en particulier pour les applications à fort enjeu comme la médecine ou le droit, où les erreurs peuvent avoir de graves conséquences.
Du côté des utilisateurs finaux, une conception minutieuse de l'invite joue un rôle important dans l'atténuation des hallucinations de l'IA. Alors qu'une question vague peut conduire à une réponse hallucinée ou non pertinente, une question claire et précise donne au modèle un meilleur cadre pour générer des résultats significatifs.
Pour améliorer la fiabilité de la production, nous pouvons utiliser plusieurs techniques d'ingénierie rapide. Par exemple, la décomposition de tâches complexes en étapes plus petites et plus faciles à gérer permet de réduire la charge cognitive de l'IA et de minimiser le risque d'erreurs. Pour en savoir plus, vous pouvez lire ce blog sur les les techniques d'optimisation rapide.
Enfin, les efforts de recherche en cours dans la communauté de l'IA visent à développer des modèles d'IA plus robustes et plus fiables pour réduire les hallucinations. L'IA explicable (XAI) assure la transparence en révélant le raisonnement qui sous-tend les résultats de l'IA, ce qui permet aux utilisateurs d'en évaluer la validité.
Génération améliorée par récupération (RAG) qui associent l'IA générative à des sources de connaissances externes, atténuent les hallucinations en ancrant les réponses dans des données vérifiées et actualisées.
Si les hallucinations de l'IA présentent des défis importants, elles offrent également des possibilités d'affiner et d'améliorer les systèmes d'IA générative. En comprenant leurs causes, leurs impacts et les stratégies d'atténuation, les utilisateurs et les déployeurs de modèles peuvent prendre des mesures proactives pour minimiser les erreurs et maximiser la fiabilité.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours
blog
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
Tutoriel
Tutoriel
Derrick Mwiti
Tutoriel
DataCamp Team

