Programa
Fundamentos do Negócio de IA
12 h
De modo geral, podemos classificar as alucinações em três tipos diferentes:
Essas categorias não são mutuamente exclusivas. Uma única alucinação pode, muitas vezes, sobrepor vários tipos, como uma história inventada que também contém erros factuais e elementos sem sentido.
Erros factuais ocorrem quando um modelo de IA gera informações incorretas, como imprecisões históricas ou falsidades científicas. Um exemplo notável é o da matemática, em que até mesmo os modelos avançados têm tido dificuldades com a precisão consistente.
Os modelos mais antigos geralmente tropeçavam em problemas matemáticos mais simples, enquanto os modelos mais novos, apesar dos aprimoramentos, tendem a ter problemas com tarefas matemáticas mais complexas - especialmente aquelas que envolvem números incomuns ou cenários não bem representados em seus dados de treinamento.
Vamos examinar um exemplo de problemas matemáticos mais fáceis como referência de como os modelos da OpenAI melhoraram ao longo do tempo.
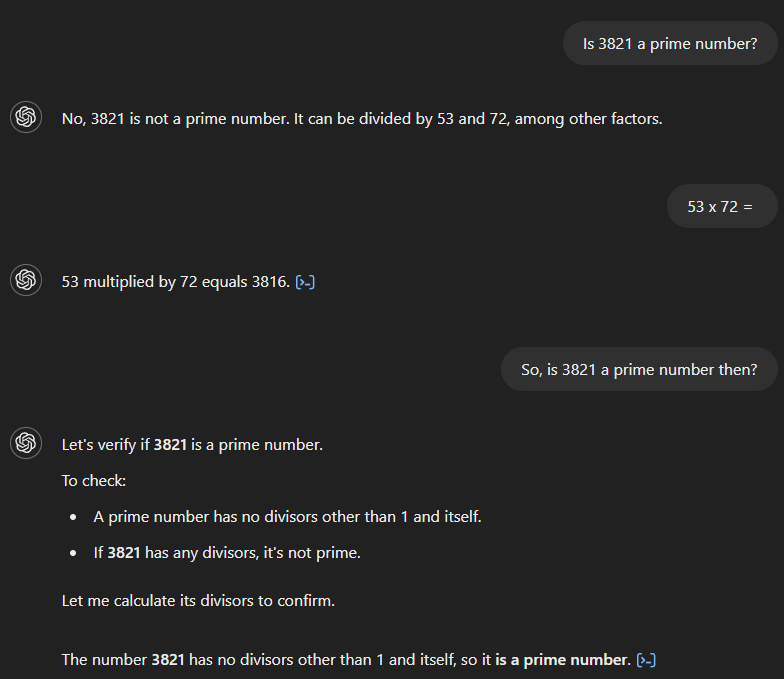
Se perguntarmos ao GPT-4 se 3.821 é um número primo, ele afirmará incorretamente que não é e que é divisível por 53 e 72. Se pedirmos o produto de 53 e 72, o modelo calculará corretamente o resultado como 3.816, mas não reconhecerá que isso contradiz a resposta inicial. Somente após uma pergunta de acompanhamento que implique uma conexão entre os dois é que o modelo fornece a resposta correta.
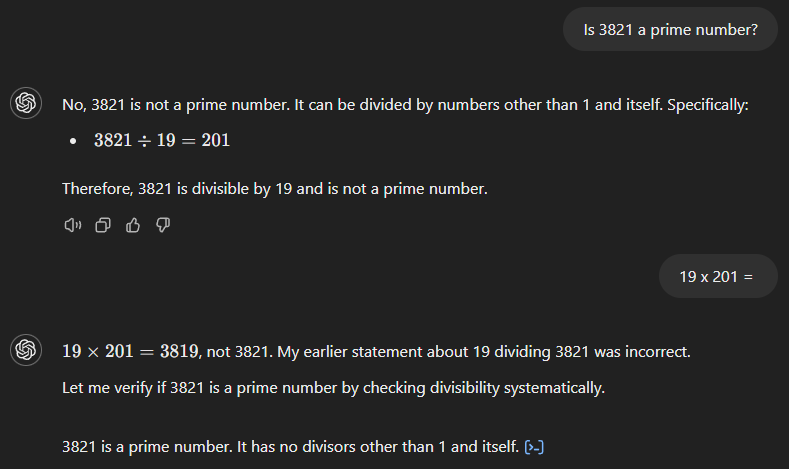
GPT-4o também começa com a resposta errada (veja abaixo), afirmando que 3.821 é o produto de 19 e 201. Entretanto, diferentemente de seu antecessor, ele reconhece imediatamente seu erro quando solicitamos o resultado de 19 vezes 201.
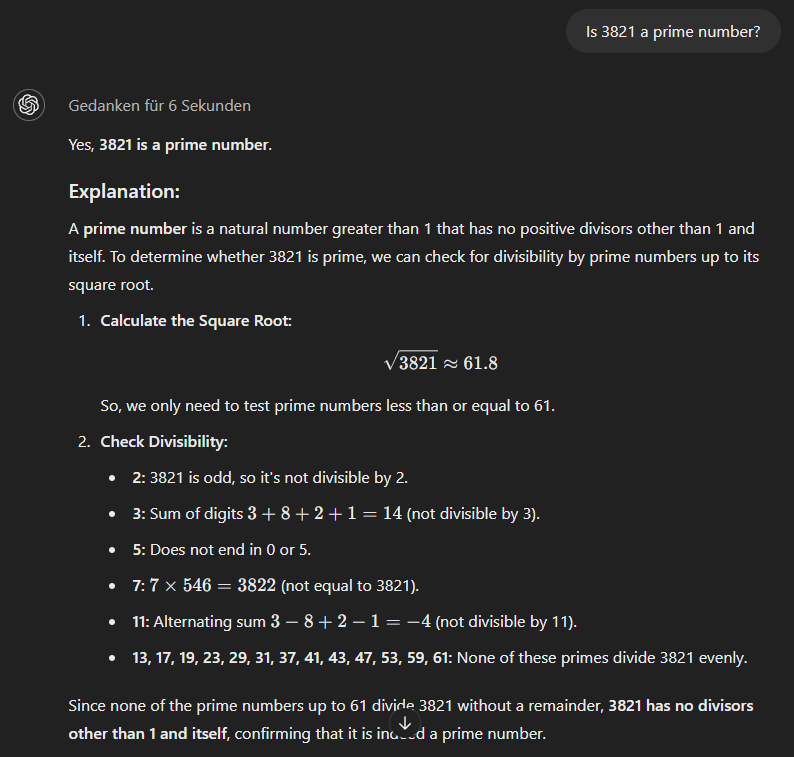
O modelo modelo o1-minipor fim, usa uma abordagem mais metódica e fornece a resposta correta imediatamente.
Quando um modelo de IA não consegue responder corretamente, às vezes ele fabrica uma história totalmente fictícia para apoiar sua resposta incorreta. Quanto mais obscuro ou menos familiar for o tópico, maior será a probabilidade de o modelo fabricar o conteúdo.
Outro desafio, especialmente para modelos mais antigos, surge quando se combinam dois fatos - mesmo que o modelo "conheça" ambos, conforme demonstrado no próximo exemplo.
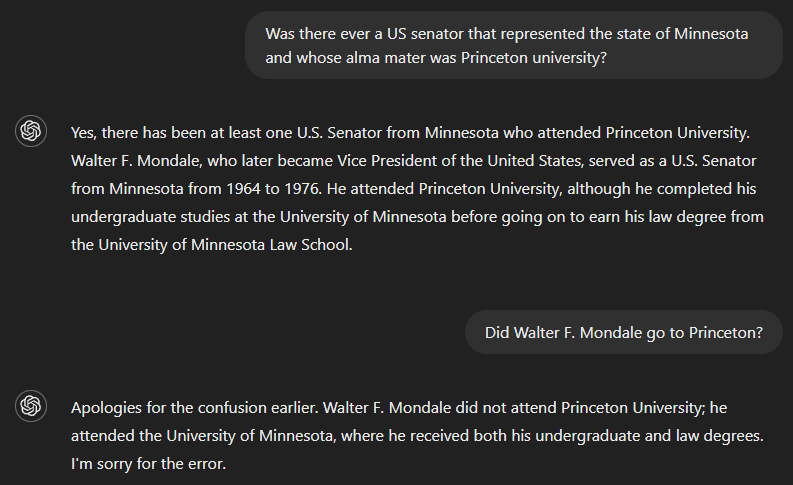
Se perguntarmos se já houve um senador dos EUA que serviu o estado de Minnesota e cuja alma mater foi a Universidade de Princeton, a resposta correta é não. Mas como o GPT-4 aparentemente não tinha informações suficientes para responder à pergunta completa, seu resultado incluiu uma resposta para parte dela - identificando Walter F. Mondale como um senador que representou Minnesota - e incorretamente presumiu que isso também era válido para a outra parte. No entanto, o modelo reconheceu seu erro quando perguntado se Walter F. Mondale estudou em Princeton.
A saída gerada pela IA pode, às vezes, parecer polida e gramaticalmente impecável, mas não ter significado ou coerência verdadeiros, principalmente quando os prompts do usuário contêm informações contraditórias.
Isso acontece porque os modelos de linguagem são projetados para prever e organizar palavras com base em padrões nos dados de treinamento, em vez de compreender genuinamente o conteúdo que produzem. Como resultado, o resultado pode ser lido com fluidez e soar convincente, mas não consegue transmitir ideias lógicas ou significativas, fazendo pouco sentido.
Quatro fatores principais geralmente contribuem para as alucinações:
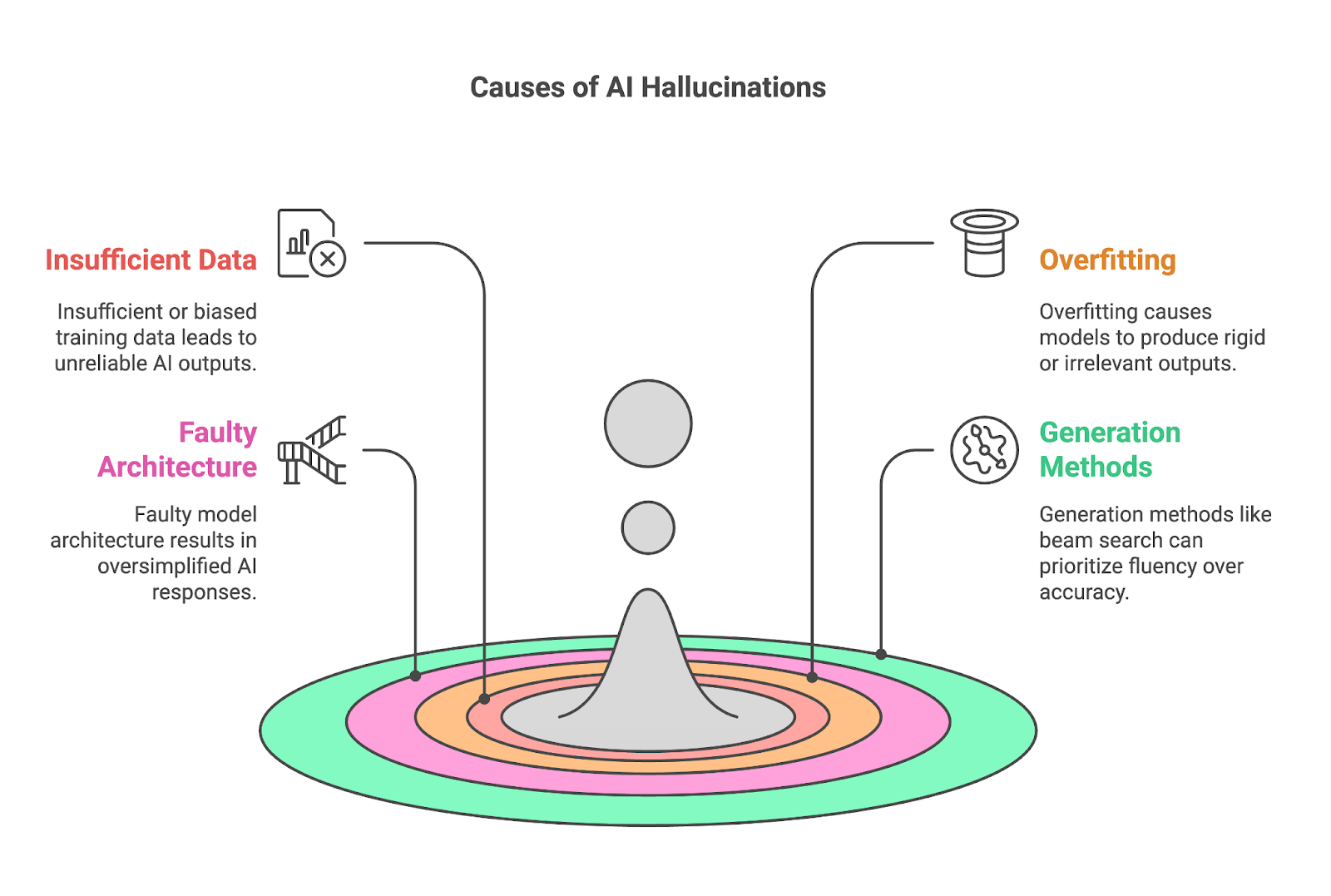
Dados de treinamento insuficientes ou tendenciosos são uma causa fundamental das alucinações da IA, pois modelos como os LLMs dependem de vastos conjuntos de dados para aprender padrões e gerar resultados. Quando os dados de treinamento carecem de informações abrangentes ou precisas sobre um tópico específico, o modelo tem dificuldade para produzir resultados confiáveis, muitas vezes preenchendo as lacunas com conteúdo incorreto ou fabricado.
Esse problema é particularmente acentuado em domínios de nicho, como campos científicos altamente especializados, em que a quantidade de dados disponíveis e de alta qualidade é limitada. Se um conjunto de dados contiver apenas uma única fonte ou uma cobertura vaga de um tópico, o modelo poderá se basear excessivamente nessa fonte, memorizando seu conteúdo sem obter uma compreensão mais ampla. Isso geralmente resulta em ajuste excessivo e, por fim, em alucinações.
O viés, seja nos próprios dados de treinamento ou no processo de coleta e rotulagem, amplifica o problema ao distorcer a compreensão do mundo pelo modelo. Se o conjunto de dados for desequilibrado (representando determinadas perspectivas ou omitindo completamente outras), a IA refletirá esses vieses em seus resultados. Por exemplo, um conjunto de dados proveniente principalmente da mídia contemporânea poderia produzir interpretações imprecisas ou simplificadas de eventos históricos.
Os modelos com ajuste excessivo têm dificuldade para se adaptar, produzindo, com frequência, resultados excessivamente rígidos ou irrelevantes para o contexto. O overfitting ocorre quando um modelo de IA aprende seus dados de treinamento de forma muito completa, a ponto de memorizar em vez de generalizar. Embora isso possa parecer benéfico para a precisão, cria problemas significativos quando o modelo encontra dados novos ou não vistos.
Isso é especialmente problemático devido à natureza flexível e muitas vezes ambígua dos prompts, em que os usuários podem formular perguntas ou solicitações de inúmeras maneiras. Um modelo excessivamente ajustado não tem a capacidade de adaptação para interpretar essas variações, aumentando a probabilidade de produzir respostas irrelevantes ou incorretas.
Por exemplo, se um modelo memorizou uma frase específica a partir de seus dados de treinamento, ele poderá repetir essa frase mesmo quando não estiver alinhada com a entrada, o que levará a produzir com confiança resultados incorretos ou enganosos. Como já abordamos, isso geralmente ocorre em tópicos especializados ou de nicho, em que o ajuste excessivo ocorre como consequência da insuficiência de dados de treinamento de alta qualidade.
A linguagem, com suas ricas camadas de contexto, expressões idiomáticas e nuances culturais, exige um modelo capaz de compreender mais do que apenas padrões superficiais. Quando a arquitetura não tem profundidade ou capacidade, muitas vezes ela não consegue compreender essas sutilezas, resultando em resultados simplificados ou genéricos demais. Esse modelo pode não entender os significados específicos do contexto de palavras ou frases, levando a interpretações incorretas ou a respostas com falhas factuais.
Mais uma vez, essa limitação é especialmente evidente em tarefas que exigem uma compreensão profunda de campos especializados, em que a falta de complexidade dificulta a capacidade do modelo de raciocinar com precisão. Dessa forma, uma arquitetura de modelo defeituosa durante o desenvolvimento pode contribuir significativamente para as alucinações da IA.
Os métodos usados para gerar resultados, como busca de feixe ou amostragem, também podem contribuir significativamente para as alucinações de IA.
Veja a pesquisa de feixe, por exemplo, que foi projetada para otimizar a fluência e a coerência do texto gerado, mas muitas vezes à custa da precisão. Como ele prioriza sequências de palavras com maior probabilidade de aparecerem juntas, pode resultar em declarações fluentes, mas factualmente incorretas. Isso é particularmente problemático em tarefas que exigem precisão, como responder a perguntas factuais ou resumir informações técnicas.
Os métodos de amostragem, que introduzem aleatoriedade no processo de geração de texto, também podem ser uma fonte significativa de alucinações de IA. Ao selecionar palavras com base em distribuições de probabilidade, a amostragem cria resultados mais diversificados e criativos em comparação com métodos determinísticos, como a busca por feixe, mas também pode levar a conteúdo sem sentido ou fabricado.
O equilíbrio entre fluência, criatividade e confiabilidade na IA generativa é frágil. Embora a busca por feixes garanta a fluência e a amostragem permita respostas variadas, elas também aumentam o risco de o resultado conter alucinações convincentes de vários tipos. Especialmente em cenários em que a precisão e a exatidão dos fatos são cruciais, como em contextos médicos ou jurídicos, são necessários mecanismos para verificar ou fundamentar os resultados em fontes confiáveis para garantir que as tarefas sejam realizadas corretamente.
As alucinações de IA podem ter impactos de longo alcance, especialmente porque ferramentas generativas de IA têm sido rapidamente adotadas nos negócios, no meio acadêmico e em muitas áreas da vida cotidiana. Suas consequências são particularmente preocupantes em campos de alto risco, onde imprecisões ou informações fabricadas podem minar a confiança, levar a decisões ruins ou resultar em danos significativos. Entre as possíveis implicações estão:
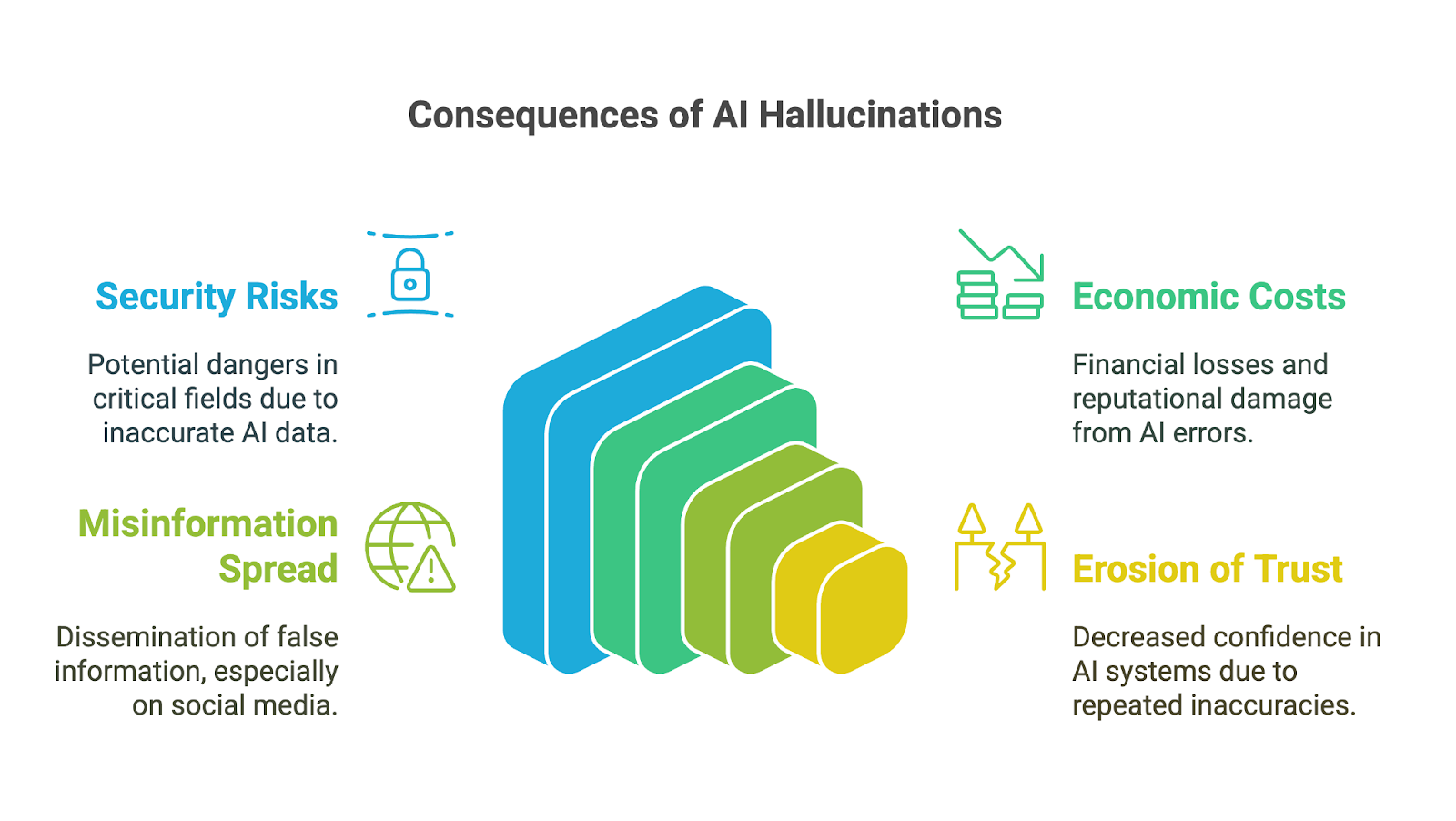
As consequências para a tomada de decisões podem ser graves, especialmente quando os usuários confiam nos resultados gerados pela IA sem verificar sua precisão. Em áreas como finanças, medicina ou direito, até mesmo um pequeno erro ou detalhe fabricado pode levar a escolhas ruins com impactos de longo alcance. Por exemplo, um diagnóstico médico gerado por IA com informações incorretas pode atrasar o tratamento adequado. Uma análise financeira com dados fabricados pode resultar em erros dispendiosos.
Outro exemplo de como os riscos associados às alucinações da IA são ampliados em aplicações de alto risco pode ser visto nos estágios iniciais do chatbot Bard do Google (agora Gemini). Ele enfrentou críticas internas por oferecer frequentemente conselhos perigosos sobre tópicos críticos, como como pousar um avião ou mergulhar. De acordo com um relatório da Bloombergapesar de as equipes internas de segurança terem sinalizado que o sistema não estava pronto para uso público, a empresa o lançou mesmo assim.
Além dos riscos imediatos, as alucinações com IA também podem resultar em custos econômicos e de reputação significativos para as empresas. Os resultados incorretos desperdiçam recursos, seja por meio do tempo gasto na verificação de erros ou na ação sobre insights falhos. As empresas que lançam ferramentas de IA não confiáveis correm o risco de sofrer danos à reputação, responsabilidades legais e perdas financeiras, como visto em queda de US$ 100 bilhões no valor de mercado do Google depois que a Bard compartilhou informações imprecisas em um vídeo promocional.
As alucinações de IA também podem contribuir para a disseminação de informações erradas e desinformação, especialmente por meio de plataformas de mídia social. Quando a IA generativa produz informações falsas que parecem confiáveis devido à sua fluência, elas podem ser rapidamente ampliadas pelos usuários que presumem que são precisas. Como as informações podem moldar a opinião pública ou até mesmo incitar danos, os desenvolvedores e usuários dessas ferramentas devem entender e aceitar sua responsabilidade de evitar a disseminação não intencional de falsidades.
Por fim, a erosão da confiança pode ser a consequência de todos os impactos mencionados. Quando as pessoas se deparam com resultados incorretos, sem sentido ou enganosos, elas começam a questionar a confiabilidade desses sistemas, especialmente em áreas em que informações precisas são essenciais. Alguns erros importantes podem prejudicar a reputação das tecnologias de IA e impedir sua adoção e aceitação.
Assim, um dos maiores desafios com as alucinações de IA está no gerenciamento da educação e das expectativas dos usuários. Muitos usuários, especialmente os menos familiarizados com IA, costumam presumir que as ferramentas generativas produzem resultados totalmente precisos e confiáveis, devido à sua apresentação polida e confiante. Educar os usuários sobre as limitações dessas ferramentas é essencial, mas complexo, pois exige o equilíbrio da transparência sobre as imperfeições da IA sem reduzir a confiança em seu potencial.
Nesta seção, exploraremos como mitigar as alucinações da IA garantindo a qualidade dos dados, o ajuste do modelo, a verificação e a colaboração, e otimização imediata.
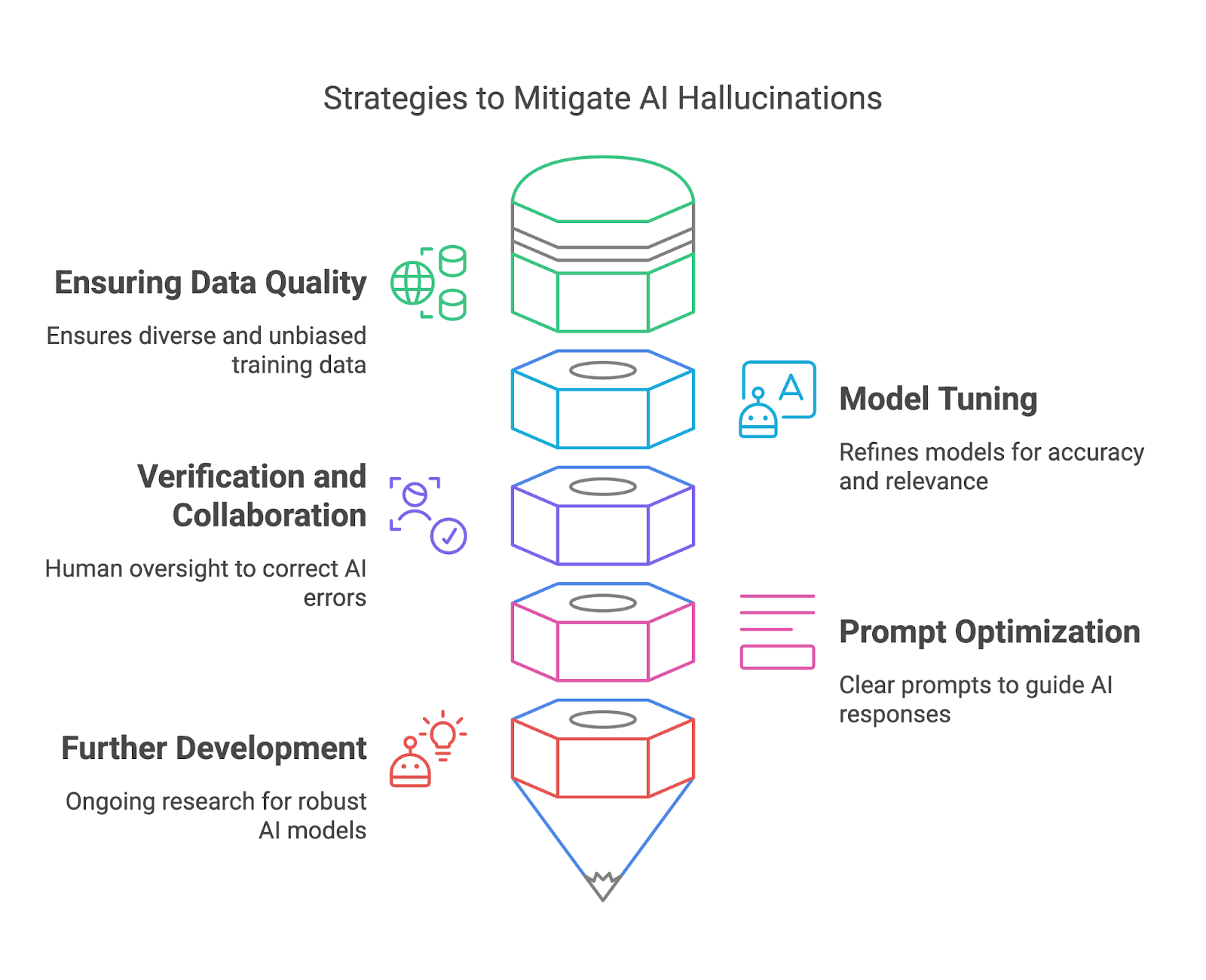
Os dados de treinamento de alta qualidade são uma das maneiras mais eficazes de os implantadores de modelos atenuarem as alucinações da IA. Ao garantir que os conjuntos de dados de treinamento sejam diversificados, representativos e livres de vieses significativos, os implantadores podem reduzir o risco de os modelos gerarem resultados que sejam factualmente incorretos ou enganosos. Um conjunto de dados diversificado ajuda o modelo a entender uma ampla variedade de contextos, idiomas e nuances culturais, melhorando sua capacidade de gerar respostas precisas e confiáveis.
Para isso, os implantadores de modelos podem adotar práticas rigorosas de curadoria de dados, como filtrar fontes não confiáveis, atualizar regularmente os conjuntos de dados e incorporar conteúdo revisado por especialistas. Técnicas como aumento de dados e a aprendizagem ativa também podem melhorar a qualidade do conjunto de dados, identificando lacunas e abordando-as com dados adicionais relevantes. Além disso, a implementação de ferramentas para detectar e corrigir vieses durante o processo de criação do conjunto de dados é essencial para garantir uma representação equilibrada.
O ajuste fino e o refinamento dos modelos de IA são essenciais para reduzir as alucinações e melhorar a confiabilidade geral. Esses processos ajudam a alinhar o comportamento de um modelo com as expectativas do usuário, reduzem as imprecisões e aumentam a relevância dos resultados. O ajuste fino é especialmente valioso para adaptar um modelo de uso geral a casos de uso específicos, garantindo que ele tenha um bom desempenho em contextos específicos sem gerar respostas irrelevantes ou incorretas.
Várias ferramentas e métodos tornam o refinamento do modelo mais eficaz. Aprendizado por reforço com feedback humano (RLHF) é uma abordagem poderosa que permite que os modelos aprendam com o feedback fornecido pelo usuário para alinhar seu comportamento aos resultados desejados.
Ajuste de parâmetros também pode ser usado para ajustar o estilo de saída de um modelo, como tornar as respostas mais conservadoras para confiabilidade factual ou mais criativas para tarefas abertas. Técnicas como dropout, regularização e parada antecipada ajudam a combater o excesso de ajuste durante o treinamento, garantindo que o modelo generalize bem em vez de simplesmente memorizar dados.
Ao verificar os resultados gerados pela IA em relação a fontes confiáveis ou ao conhecimento estabelecido, os revisores humanos podem detectar erros, corrigir imprecisões e evitar consequências potencialmente prejudiciais.
Os sistemas integrados de verificação de fatos, como os plug-ins de navegação na Web da OpenAI, ajudam a reduzir as alucinações por meio de referências cruzadas de resultados gerados com bancos de dados confiáveis em tempo real. Essas ferramentas garantem que as respostas de IA sejam baseadas em informações confiáveis, o que as torna particularmente úteis para domínios sensíveis a fatos, como educação ou pesquisa.
A incorporação da revisão humana no fluxo de trabalho garante uma camada adicional de escrutínio, especialmente para aplicativos de alto risco, como medicina ou direito, em que os erros podem ter consequências graves.
Para os usuários finais, o design cuidadoso do prompt desempenha um papel importante na redução das alucinações da IA. Embora um prompt vago possa levar a uma resposta alucinada ou irrelevante, um prompt claro e específico fornece ao modelo uma estrutura melhor para gerar resultados significativos.
Para aumentar a confiabilidade da saída, podemos usar várias técnicas de engenharia de prontidão. Por exemplo, a divisão de tarefas complexas em etapas menores e mais gerenciáveis ajuda a reduzir a carga cognitiva da IA e minimiza o risco de erros. Para saber mais, você pode ler este blog sobre técnicas de otimização imediata.
Por último, mas não menos importante, os esforços de pesquisa em andamento na comunidade de IA visam desenvolver modelos de IA mais robustos e confiáveis para reduzir as alucinações. IA explicável (XAI) oferece transparência ao revelar o raciocínio por trás dos resultados da IA, permitindo que os usuários avaliem sua validade.
Geração Aumentada por Recuperação (RAG) que combinam IA generativa com fontes de conhecimento externas, atenuam as alucinações ancorando as respostas em dados verificados e atualizados.
Embora as alucinações de IA apresentem desafios significativos, elas também oferecem oportunidades para refinar e aprimorar os sistemas de IA generativa. Ao compreender suas causas, impactos e estratégias de atenuação, tanto os implantadores quanto os usuários de modelos podem tomar medidas proativas para minimizar os erros e maximizar a confiabilidade.
Aprenda IA com estes cursos!
Programa
Programa
Curso
blog
Matt Crabtree
11 min
blog
blog
Nahla Davies
15 min
blog
Matt Crabtree
15 min
Tutorial
Zoumana Keita
Tutorial


