Lernpfad
KI-Grundlagen für Unternehmen
12 Std.
Wir können Halluzinationen grob in drei verschiedene Arten einteilen:
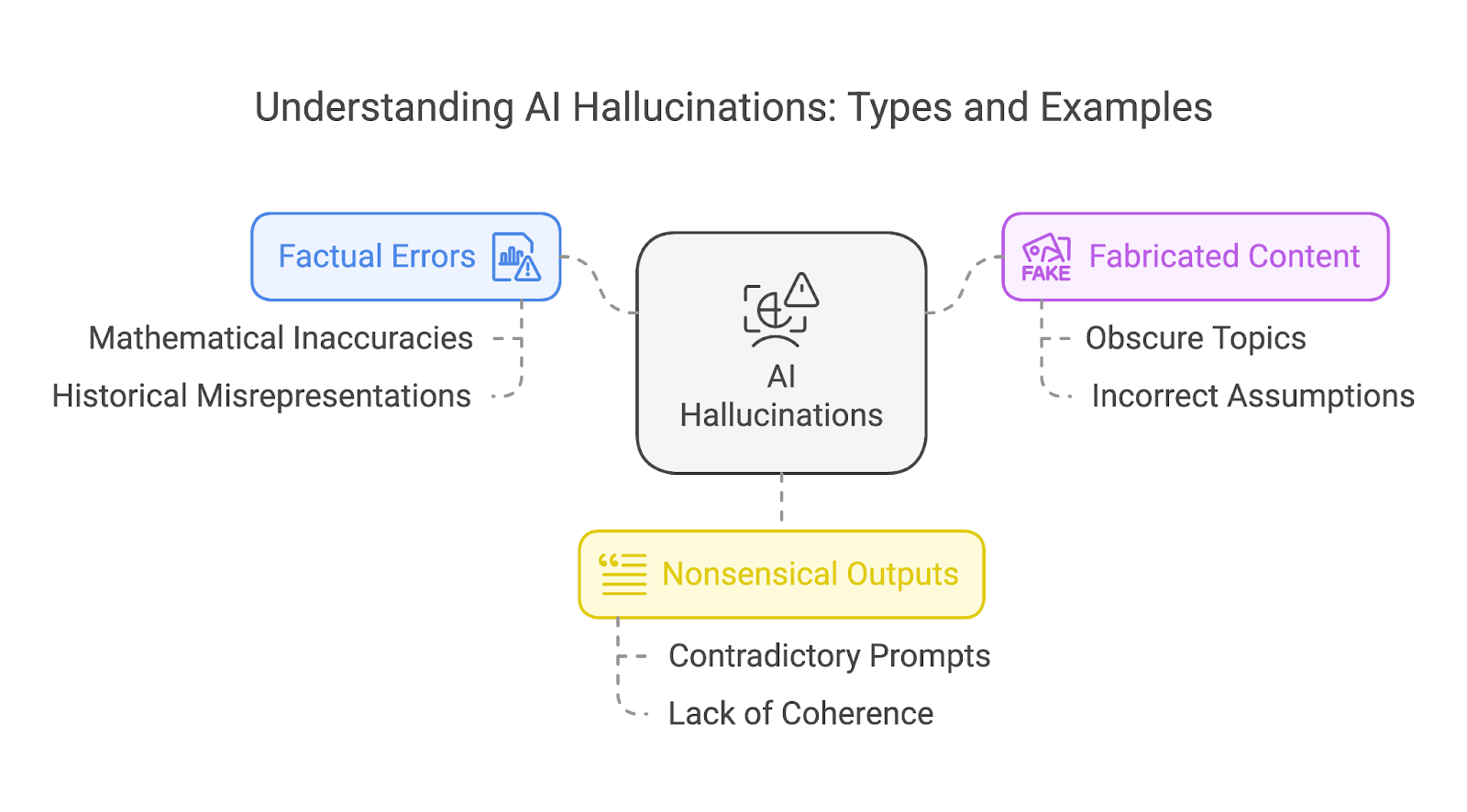
Diese Kategorien schließen sich nicht gegenseitig aus. Eine einzelne Halluzination kann sich oft mit mehreren Typen überschneiden, z. B. eine erfundene Geschichte, die auch sachliche Fehler und unsinnige Elemente enthält.
Faktische Fehler treten auf, wenn ein KI-Modell falsche Informationen ausgibt, z. B. historische Ungenauigkeiten oder wissenschaftliche Unwahrheiten. Ein bemerkenswertes Beispiel ist die Mathematik, in der selbst fortgeschrittene Modelle Schwierigkeiten mit der Genauigkeit haben.
Ältere Modelle stolperten oft über einfachere mathematische Probleme, während neuere Modelle trotz Verbesserungen dazu neigen, Probleme mit komplexeren mathematischen Aufgaben zu haben - vor allem mit ungewöhnlichen Zahlen oder Szenarien, die in ihren Trainingsdaten nicht gut repräsentiert sind.
Schauen wir uns ein Beispiel mit einfacheren mathematischen Problemen an, um zu sehen, wie sich die Modelle von OpenAI im Laufe der Zeit verbessert haben.
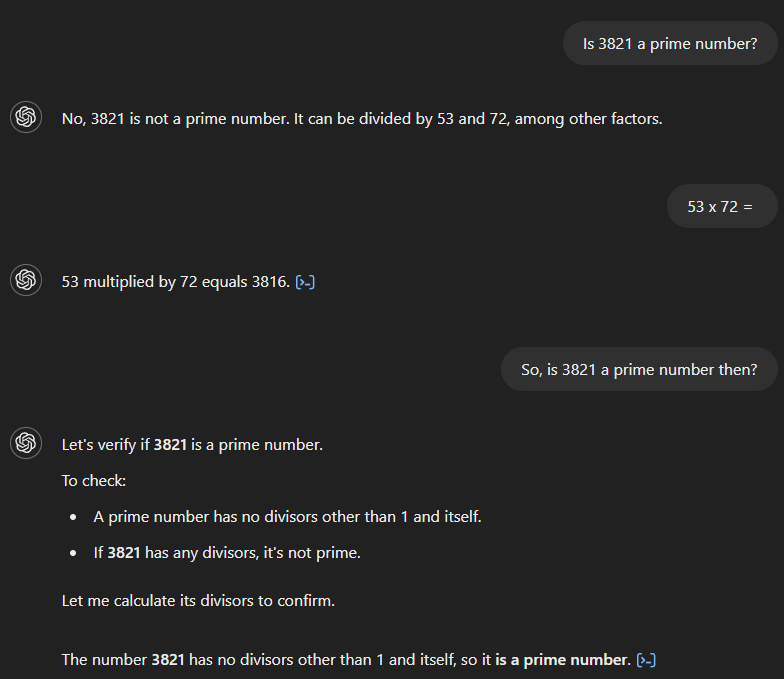
Wenn wir GPT-4 fragen, ob 3.821 eine Primzahl ist, sagt es fälschlicherweise, dass sie es nicht ist und behauptet, sie sei durch 53 und 72 teilbar. Wenn wir dann nach dem Produkt von 53 und 72 fragen, berechnet das Modell das Ergebnis korrekt als 3.816, erkennt aber nicht, dass dies seiner ursprünglichen Antwort widerspricht. Erst nach einer Folgefrage, die einen Zusammenhang zwischen den beiden Themen andeutet, gibt das Modell die richtige Antwort.
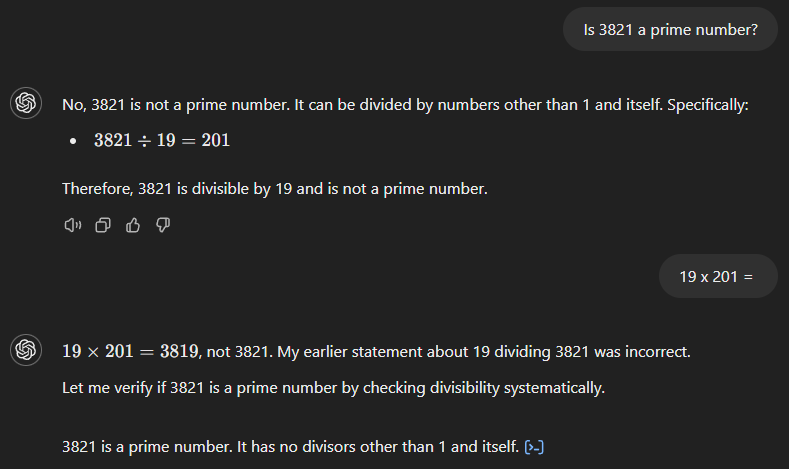
GPT-4o beginnt ebenfalls mit der falschen Antwort (siehe unten) und behauptet, dass 3.821 das Produkt aus 19 und 201 ist. Im Gegensatz zu seinem Vorgänger erkennt es jedoch sofort seinen Fehler, wenn wir nach dem Ergebnis von 19 mal 201 fragen.
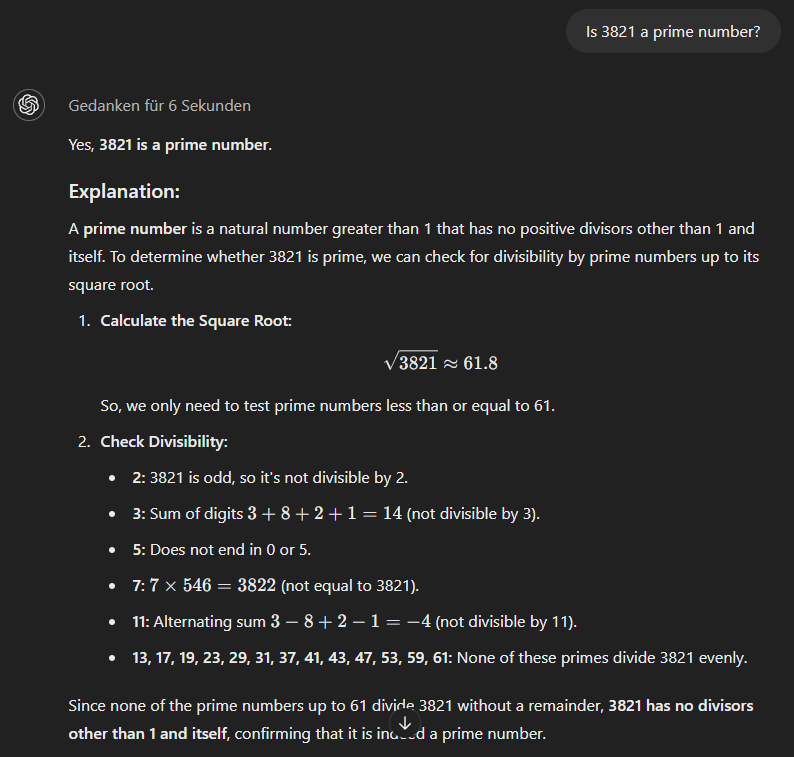
Das o1-mini-Modellschließlich verwendet einen methodischeren Ansatz und gibt sofort die richtige Antwort.
Wenn ein KI-Modell nicht richtig antworten kann, erfindet es manchmal eine völlig fiktive Geschichte, um seine falsche Antwort zu untermauern. Je undurchsichtiger oder weniger vertraut das Thema ist, desto höher ist die Wahrscheinlichkeit, dass das Modell Inhalte fabriziert.
Eine weitere Herausforderung, vor allem für ältere Modelle, ergibt sich, wenn zwei Fakten kombiniert werden - selbst wenn das Modell beide "kennt", wie im nächsten Beispiel gezeigt wird.
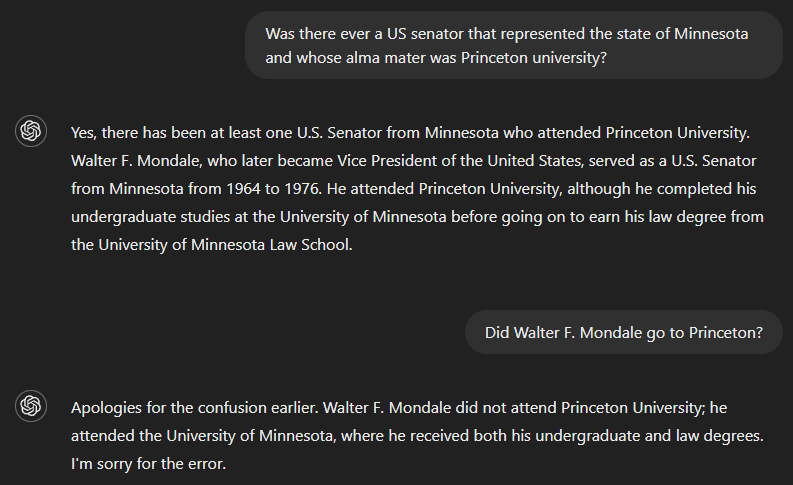
Wenn wir fragen, ob es jemals einen US-Senator gab, der dem Bundesstaat Minnesota diente und dessen Alma Mater die Princeton University war, lautet die richtige Antwort nein. Da GPT-4 aber anscheinend nicht genügend Informationen hatte, um die Frage vollständig zu beantworten, hat es einen Teil der Frage beantwortet - Walter F. Mondale als Senator, der Minnesota vertreten hat - und fälschlicherweise angenommen, dass dies auch für den anderen Teil gilt. Das Modell erkannte jedoch seinen Fehler, als es gefragt wurde, ob Walter F. Mondale in Princeton war.
KI-generierte Ausgaben können manchmal ausgefeilt und grammatikalisch einwandfrei erscheinen, während es ihnen an echter Bedeutung oder Kohärenz mangelt, insbesondere wenn die Eingabeaufforderungen des Nutzers widersprüchliche Informationen enthalten.
Das liegt daran, dass Sprachmodelle so konzipiert sind, dass sie Wörter auf der Grundlage von Mustern in ihren Trainingsdaten vorhersagen und anordnen, anstatt den Inhalt, den sie produzieren, wirklich zu verstehen. Das kann dazu führen, dass sich der Text zwar flüssig liest und überzeugend klingt, aber keine logischen oder sinnvollen Ideen vermittelt und letztlich wenig Sinn ergibt.
Vier wichtige Faktoren tragen oft zu Halluzinationen bei:
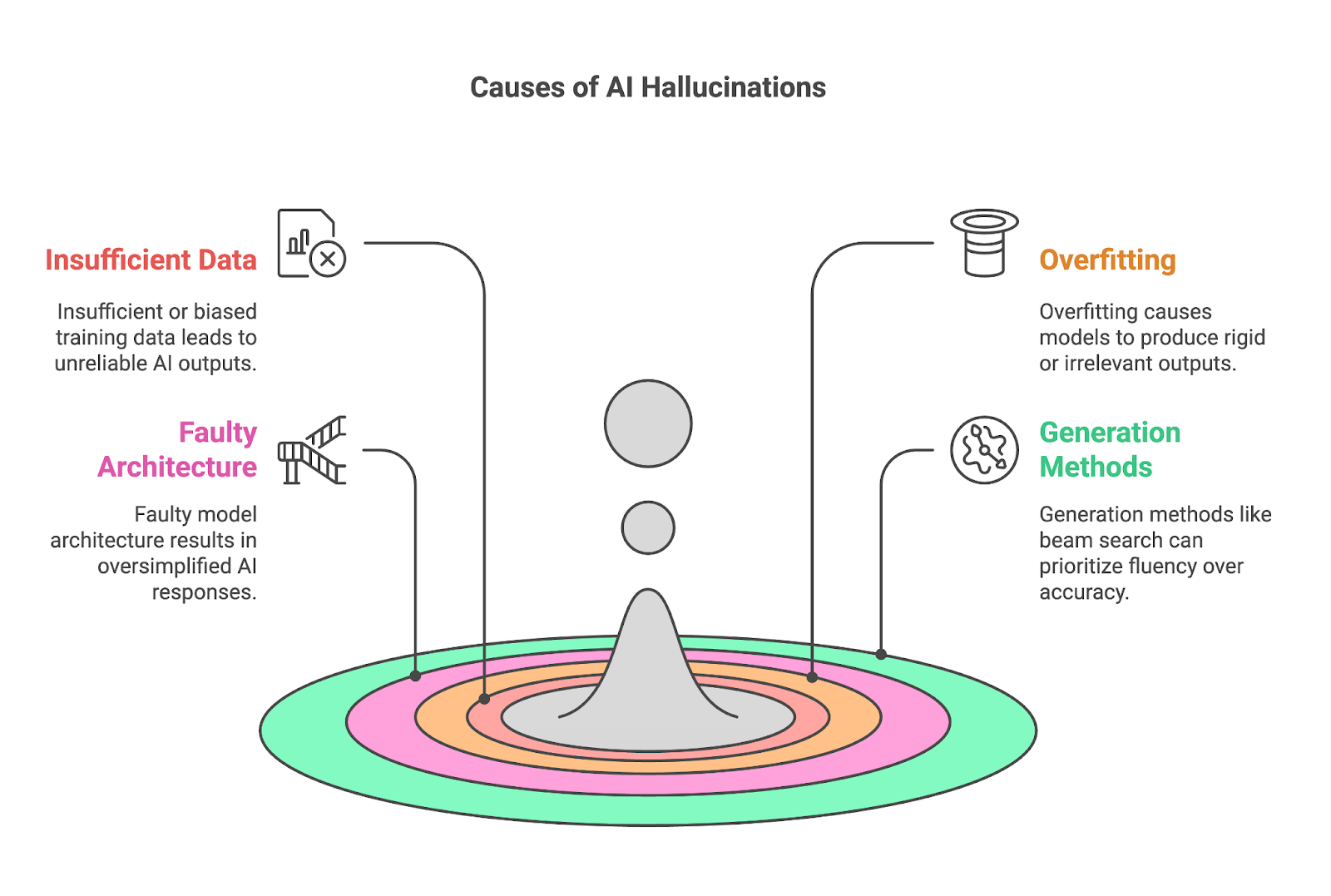
Unzureichende oder verzerrte Trainingsdaten sind eine wesentliche Ursache für KI-Halluzinationen, da Modelle wie LLMs auf riesige Datensätze angewiesen sind, um Muster zu lernen und Ergebnisse zu erzeugen. Wenn die Trainingsdaten keine umfassenden oder genauen Informationen über ein bestimmtes Thema enthalten, hat das Modell Schwierigkeiten, zuverlässige Ergebnisse zu erzielen und füllt die Lücken oft mit falschen oder erfundenen Inhalten.
Dieses Problem ist besonders ausgeprägt in Nischenbereichen, wie z.B. in hochspezialisierten wissenschaftlichen Bereichen, in denen die Menge an verfügbaren, hochwertigen Daten begrenzt ist. Wenn ein Datensatz nur eine einzige Quelle oder eine vage Abdeckung eines Themas enthält, kann es sein, dass sich das Modell zu sehr auf diese Quelle verlässt und sich deren Inhalt merkt, ohne ein breiteres Verständnis zu erlangen. Das führt oft zu einer Überanpassung und letztlich zu Halluzinationen.
Voreingenommenheit, sei es bei den Trainingsdaten selbst oder beim Sammeln und Kennzeichnen der Daten, verstärkt das Problem, indem es das Verständnis des Modells von der Welt verzerrt. Wenn der Datensatz unausgewogen ist, d.h. bestimmte Perspektiven überrepräsentiert sind oder andere komplett ausgelassen werden, wird die KI diese Verzerrungen in ihren Ergebnissen widerspiegeln. Ein Datensatz, der hauptsächlich aus zeitgenössischen Medien stammt, könnte zum Beispiel ungenaue oder zu vereinfachte Interpretationen historischer Ereignisse liefern.
Überangepasste Modelle können sich nur schwer anpassen und produzieren oft Ergebnisse, die entweder zu starr oder für den Kontext irrelevant sind. Überanpassung liegt vor, wenn ein KI-Modell seine Trainingsdaten zu gründlich lernt, so dass es sich eher einprägt als verallgemeinert. Das mag zwar für die Genauigkeit von Vorteil sein, führt aber zu erheblichen Problemen, wenn das Modell auf neue oder ungesehene Daten trifft.
Das ist besonders problematisch, da die Eingabeaufforderungen flexibel und oft mehrdeutig sind und die Nutzer/innen ihre Fragen oder Wünsche auf unzählige Arten formulieren können. Einem überangepassten Modell fehlt die Anpassungsfähigkeit, um diese Schwankungen zu interpretieren, was die Wahrscheinlichkeit erhöht, dass es irrelevante oder falsche Antworten liefert.
Wenn sich ein Modell zum Beispiel eine bestimmte Formulierung aus den Trainingsdaten gemerkt hat, kann es diese wiederholen, auch wenn sie nicht mit der Eingabe übereinstimmt, was dazu führt, dass es mit Sicherheit falsche oder irreführende Ergebnisse produziert. Wie wir bereits erwähnt haben, ist dies häufig bei Nischen- oder Spezialthemen der Fall, bei denen es zu einer Überanpassung kommt, weil nicht genügend hochwertige Trainingsdaten vorliegen.
Die Sprache mit ihren zahlreichen Kontexten, Redewendungen und kulturellen Nuancen erfordert ein Modell, das mehr als nur oberflächliche Muster verstehen kann. Wenn es der Architektur an Tiefe oder Kapazität mangelt, kann sie diese Feinheiten oft nicht erfassen, was zu vereinfachten oder zu generischen Ergebnissen führt. Ein solches Modell kann die kontextspezifische Bedeutung von Wörtern oder Sätzen missverstehen, was zu falschen Interpretationen oder sachlich fehlerhaften Antworten führt.
Auch diese Einschränkung zeigt sich vor allem bei Aufgaben, die ein tiefes Verständnis von Fachgebieten erfordern, wo die fehlende Komplexität die Fähigkeit des Modells, genau zu argumentieren, behindert. Auf diese Weise kann eine fehlerhafte Modellarchitektur während der Entwicklung erheblich zu KI-Halluzinationen beitragen.
Auch die Methoden, die zur Erzeugung von Ergebnissen verwendet werden, wie z.B. die Balkensuche oder das Sampling, können erheblich zu KI-Halluzinationen beitragen.
Ein Beispiel ist die Balkensuche, die darauf abzielt, den Fluss und die Kohärenz des generierten Textes zu optimieren, aber oft auf Kosten der Genauigkeit. Da sie Wortfolgen bevorzugt, die am wahrscheinlichsten zusammen vorkommen, kann sie zu flüssigen, aber sachlich falschen Aussagen führen. Das ist besonders problematisch bei Aufgaben, die Präzision erfordern, wie z.B. das Beantworten von Sachfragen oder das Zusammenfassen technischer Informationen.
Sampling-Methoden, die Zufälligkeit in den Textgenerierungsprozess bringen, können ebenfalls eine wichtige Quelle für KI-Halluzinationen sein. Durch die Auswahl von Wörtern auf der Grundlage von Wahrscheinlichkeitsverteilungen erzeugt Sampling im Vergleich zu deterministischen Methoden wie der Balkensuche vielfältigere und kreativere Ergebnisse, aber es kann auch zu unsinnigen oder erfundenen Inhalten führen.
Das Gleichgewicht zwischen Geläufigkeit, Kreativität und Zuverlässigkeit in der generativen KI ist fragil. Die Balkensuche gewährleistet zwar einen flüssigen Ablauf und das Sampling ermöglicht vielfältige Antworten, aber sie erhöht auch das Risiko, dass die Ergebnisse überzeugende Halluzinationen verschiedener Art enthalten. Vor allem in Szenarien, in denen es auf Präzision und sachliche Richtigkeit ankommt, wie z.B. im medizinischen oder juristischen Bereich, sind Mechanismen zur Überprüfung oder Abgleichung der Ergebnisse mit zuverlässigen Quellen notwendig, um sicherzustellen, dass die Aufgaben korrekt erfüllt werden.
KI-Halluzinationen können weitreichende Auswirkungen haben, insbesondere da generative KI-Tools in der Wirtschaft, in der Wissenschaft und in vielen Bereichen des täglichen Lebens schnell Einzug gehalten haben. Die Folgen sind besonders in Bereichen, in denen viel auf dem Spiel steht, besorgniserregend: Ungenauigkeiten oder gefälschte Informationen können das Vertrauen untergraben, zu schlechten Entscheidungen führen oder erheblichen Schaden anrichten. Zu den möglichen Folgen gehören:
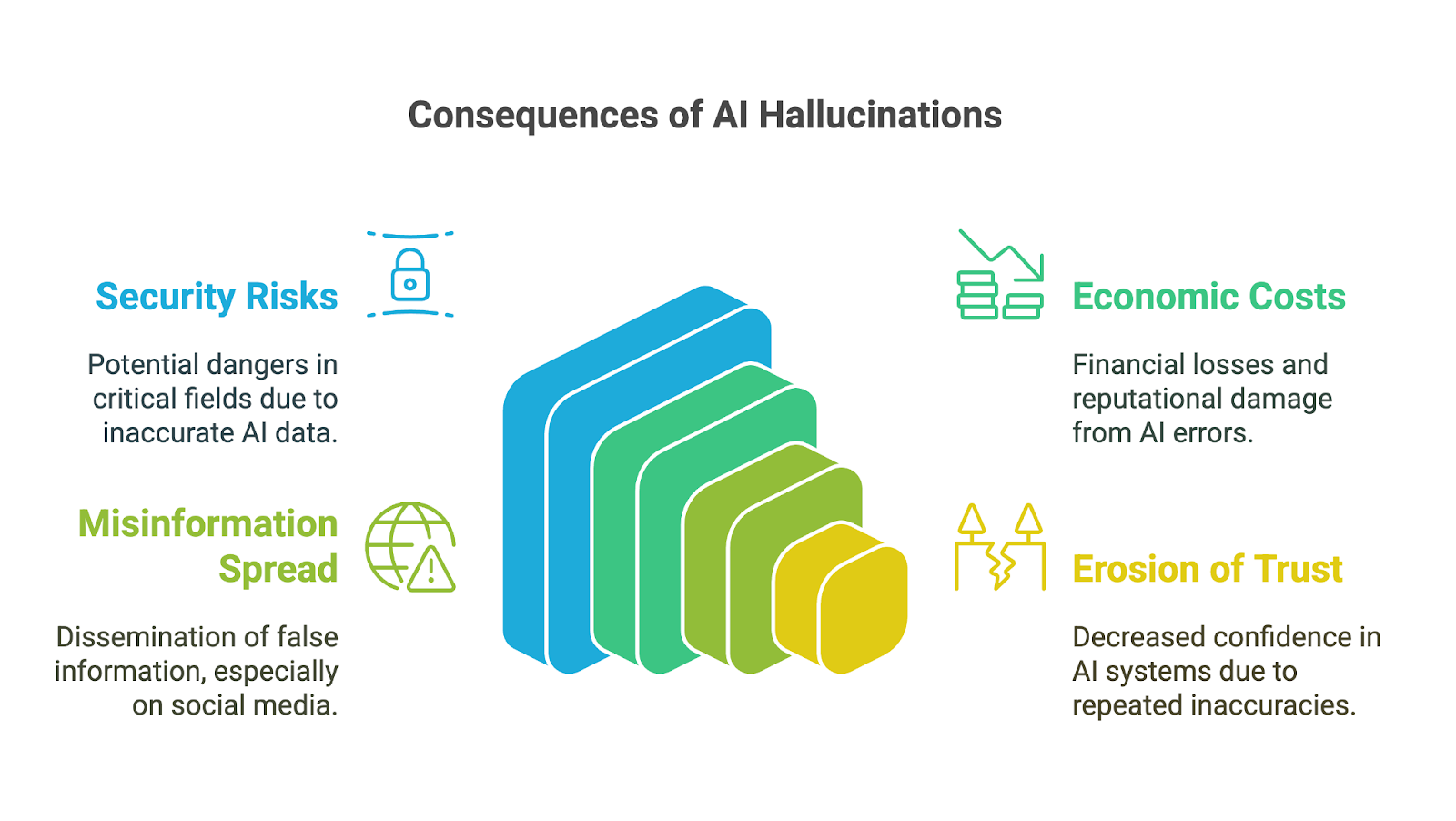
Das kann schwerwiegende Folgen für die Entscheidungsfindung haben, vor allem wenn sich die Nutzer/innen auf KI-generierte Ergebnisse verlassen, ohne deren Genauigkeit zu überprüfen. In Bereichen wie Finanzen, Medizin oder Recht kann schon ein kleiner Fehler oder ein erfundenes Detail zu schlechten Entscheidungen mit weitreichenden Folgen führen. Zum Beispiel könnte eine von der KI erstellte medizinische Diagnose mit falschen Informationen die richtige Behandlung verzögern. Eine Finanzanalyse mit gefälschten Daten kann zu kostspieligen Fehlern führen.
Ein weiteres Beispiel dafür, wie sich die mit KI-Halluzinationen verbundenen Risiken bei Anwendungen mit hohem Einsatz verstärken, ist die Frühphase von Googles Chatbot Bard (jetzt Gemini). Sie wurde intern kritisiert, weil sie häufig gefährliche Ratschläge zu kritischen Themen wie der Landung eines Flugzeugs oder dem Tauchen gab. Laut einem Bloomberg-BerichtObwohl interne Sicherheitsteams das System als nicht einsatzbereit für die Öffentlichkeit eingestuft hatten, führte das Unternehmen es trotzdem ein.
Abgesehen von den unmittelbaren Risiken können KI-Halluzinationen auch zu erheblichen wirtschaftlichen und rufschädigenden Kosten für Unternehmen führen. Falsche Ergebnisse verschwenden Ressourcen, sei es durch Zeitaufwand für die Überprüfung von Fehlern oder durch das Handeln auf Basis falscher Erkenntnisse. Unternehmen, die unzuverlässige KI-Tools veröffentlichen, riskieren Reputationsschäden, rechtliche Verpflichtungen und finanzielle Verluste, wie der Google's 100 Milliarden Dollar Marktwertverlust nachdem Bard ungenaue Informationen in einem Werbevideo verbreitet hatte.
KI-Halluzinationen können auch zur Verbreitung von Fehlinformationen und Desinformationen beitragen, insbesondere über Social-Media-Plattformen. Wenn generative KI falsche Informationen produziert, die aufgrund ihrer Geläufigkeit glaubwürdig erscheinen, können sie schnell von Nutzerinnen und Nutzern weiterverbreitet werden, die annehmen, dass sie korrekt sind. Da Informationen die öffentliche Meinung beeinflussen oder sogar Schaden anrichten können, müssen Entwickler und Nutzer dieser Tools ihre Verantwortung verstehen und akzeptieren, um die unbeabsichtigte Verbreitung von Unwahrheiten zu verhindern.
Schließlich kann eine Erosion des Vertrauens die Folge all der genannten Auswirkungen sein. Wenn Menschen auf falsche, unsinnige oder irreführende Ausgaben stoßen, beginnen sie, die Zuverlässigkeit dieser Systeme in Frage zu stellen, vor allem in Bereichen, in denen genaue Informationen entscheidend sind. Ein paar prominente Fehler können den Ruf von KI-Technologien schädigen und ihre Einführung und Akzeptanz behindern.
Dementsprechend liegt eine der größten Herausforderungen bei KI-Halluzinationen im Umgang mit der Aufklärung und den Erwartungen der Nutzer. Viele Nutzerinnen und Nutzer, vor allem diejenigen, die mit KI weniger vertraut sind, gehen oft davon aus, dass generative Werkzeuge aufgrund ihrer ausgefeilten und selbstbewussten Präsentation absolut genaue und zuverlässige Ergebnisse liefern. Es ist wichtig, die Nutzer/innen über die Grenzen dieser Werkzeuge aufzuklären, aber auch komplex, denn es muss ein Gleichgewicht zwischen Transparenz über die Unzulänglichkeiten der KI und dem Vertrauen in ihr Potenzial gefunden werden.
In diesem Abschnitt werden wir untersuchen, wie wir KI-Halluzinationen durch Sicherstellung der Datenqualität, Modellabstimmung, Verifizierung und Zusammenarbeit sowie zeitnahe Optimierung.
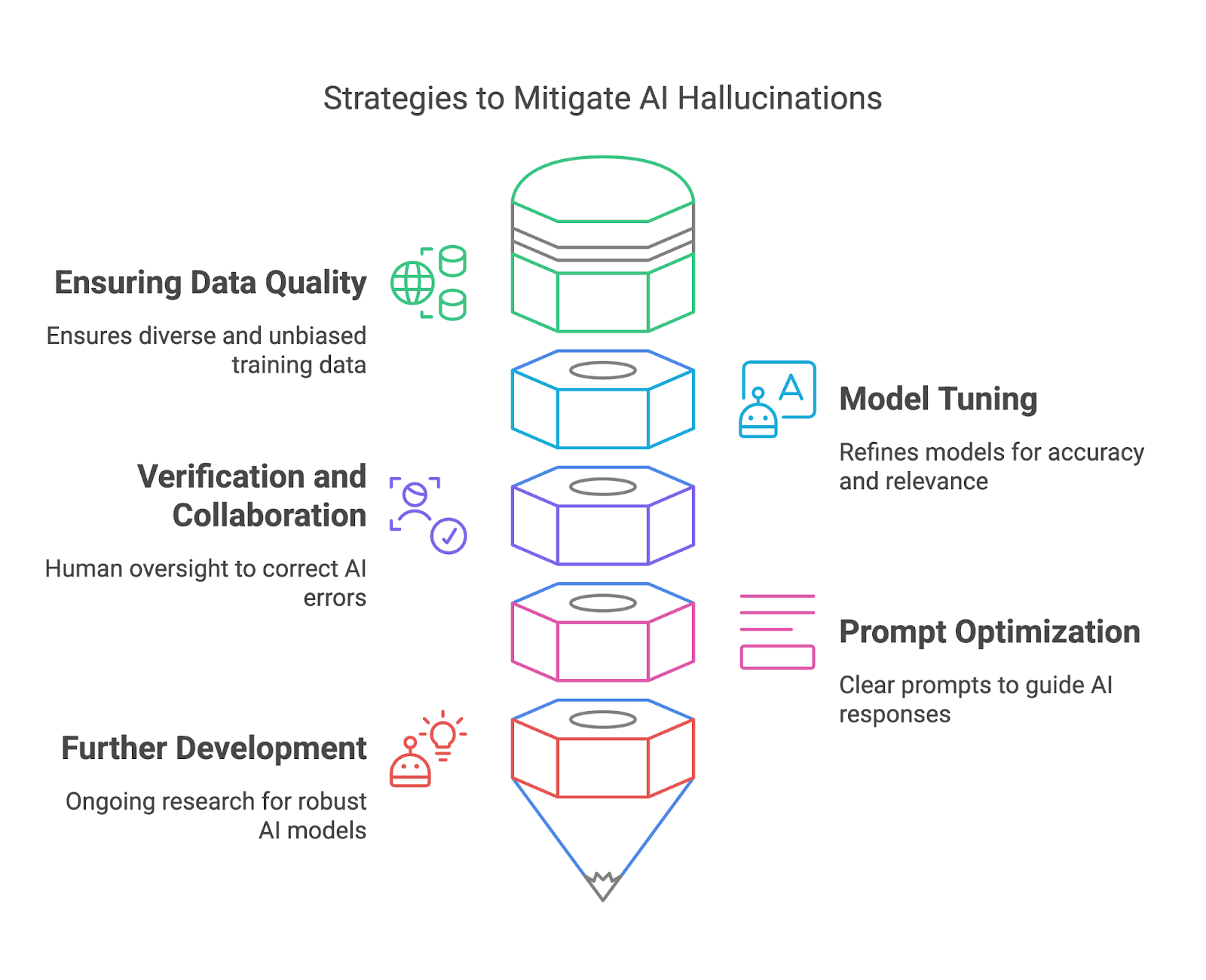
Qualitativ hochwertige Trainingsdaten sind eine der effektivsten Möglichkeiten für Modellentwickler, KI-Halluzinationen abzuschwächen. Indem sie sicherstellen, dass die Trainingsdatensätze vielfältig, repräsentativ und frei von signifikanten Verzerrungen sind, können sie das Risiko verringern, dass die Modelle Ergebnisse erzeugen, die sachlich falsch oder irreführend sind. Ein vielfältiger Datensatz hilft dem Modell, eine große Bandbreite an Kontexten, Sprachen und kulturellen Nuancen zu verstehen, was seine Fähigkeit verbessert, genaue und zuverlässige Antworten zu geben.
Um dies zu erreichen, können die Modellentwickler strenge Verfahren zur Datenkuratierung anwenden, z. B. unzuverlässige Quellen herausfiltern, Datensätze regelmäßig aktualisieren und von Experten geprüfte Inhalte einbeziehen. Techniken wie Datenerweiterung und aktives Lernen können die Qualität von Datensätzen verbessern, indem sie Lücken aufdecken und sie mit zusätzlichen relevanten Daten füllen. Darüber hinaus ist der Einsatz von Instrumenten zur Erkennung und Korrektur von Verzerrungen während des Erstellungsprozesses von Datensätzen wichtig, um eine ausgewogene Darstellung zu gewährleisten.
Die Feinabstimmung und die Verfeinerung von KI-Modellen sind wichtig, um Halluzinationen zu verringern und die allgemeine Zuverlässigkeit zu verbessern. Diese Prozesse helfen dabei, das Verhalten eines Modells an die Erwartungen der Nutzer anzupassen, Ungenauigkeiten zu reduzieren und die Relevanz der Ergebnisse zu verbessern. Die Feinabstimmung ist besonders wertvoll, wenn es darum geht, ein allgemeines Modell an bestimmte Anwendungsfälle anzupassen und sicherzustellen, dass es in bestimmten Kontexten gut funktioniert, ohne irrelevante oder falsche Antworten zu erzeugen.
Verschiedene Werkzeuge und Methoden machen die Modellverfeinerung effektiver. Verstärkungslernen aus menschlichem Feedback (RLHF) ist ein leistungsfähiger Ansatz, der es Modellen ermöglicht, aus dem Feedback der Nutzer/innen zu lernen und ihr Verhalten an den gewünschten Ergebnissen auszurichten.
Die Einstellung der Parameter kann auch verwendet werden, um den Ausgabestil eines Modells anzupassen, z. B. um die Antworten konservativer für faktische Zuverlässigkeit oder kreativer für offene Aufgaben zu gestalten. Techniken wie Dropout, Regularisierung und frühzeitiges Stoppen helfen dabei, die Überanpassung während des Trainings zu bekämpfen und sicherzustellen, dass das Modell gut verallgemeinert, anstatt sich einfach nur Daten zu merken.
Durch den Abgleich von KI-Ergebnissen mit vertrauenswürdigen Quellen oder gesichertem Wissen können menschliche Prüfer Fehler erkennen, Ungenauigkeiten korrigieren und potenziell schädliche Folgen verhindern.
Integrierte Fact-Checking-Systeme wie die Web-Browsing-Plugins von OpenAI helfen dabei, Halluzinationen zu reduzieren, indem sie die generierten Ergebnisse in Echtzeit mit vertrauenswürdigen Datenbanken abgleichen. Diese Tools stellen sicher, dass KI-Antworten auf verlässlichen Informationen beruhen, was sie für faktensensible Bereiche wie Bildung oder Forschung besonders nützlich macht.
Die Integration der menschlichen Überprüfung in den Arbeitsablauf gewährleistet eine zusätzliche Kontrollebene, insbesondere bei wichtigen Anwendungen wie Medizin oder Recht, wo Fehler schwerwiegende Folgen haben können.
Auf der Seite der Endnutzer/innen spielt die sorgfältige Gestaltung der Eingabeaufforderung eine wichtige Rolle, um KI-Halluzinationen abzuschwächen. Während eine vage Aufforderung zu einer halluzinierten oder irrelevanten Antwort führen kann, gibt eine klare und spezifische Aufforderung dem Modell einen besseren Rahmen, um sinnvolle Ergebnisse zu generieren.
Um die Zuverlässigkeit der Produktion zu erhöhen, können wir verschiedene Techniken zur schnellen Entwicklung einsetzen. Die Aufteilung komplexer Aufgaben in kleinere, überschaubare Schritte hilft zum Beispiel, die kognitive Belastung der KI zu verringern und das Fehlerrisiko zu minimieren. Um mehr zu erfahren, kannst du diesen Blog lesen über prompte Optimierungstechniken.
Nicht zuletzt zielen die laufenden Forschungsbemühungen in der KI-Gemeinschaft darauf ab, robustere und zuverlässigere KI-Modelle zur Reduzierung von Halluzinationen zu entwickeln. Erklärbare KI (XAI) sorgt für Transparenz, indem sie die Gründe für die KI-Ergebnisse offenlegt und es den Nutzern ermöglicht, deren Gültigkeit zu beurteilen.
Retrieval-Augmented Generation (RAG) Systeme, die generative KI mit externen Wissensquellen kombinieren, mildern Halluzinationen ab, indem sie die Antworten in verifizierten und aktuellen Daten verankern.
KI-Halluzinationen stellen zwar eine große Herausforderung dar, bieten aber auch die Möglichkeit, generative KI-Systeme zu verfeinern und zu verbessern. Indem sie die Ursachen, Auswirkungen und Strategien zur Schadensbegrenzung verstehen, können sowohl Modellentwickler als auch -nutzer proaktive Schritte unternehmen, um Fehler zu minimieren und die Zuverlässigkeit zu maximieren.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Derrick Mwiti
Tutorial
Allan Ouko
Tutorial
Mark Pedigo
Tutorial
Moez Ali
