programa
Fundamentos del negocio de la IA
12 h
A grandes rasgos, podemos clasificar las alucinaciones en tres tipos diferentes:
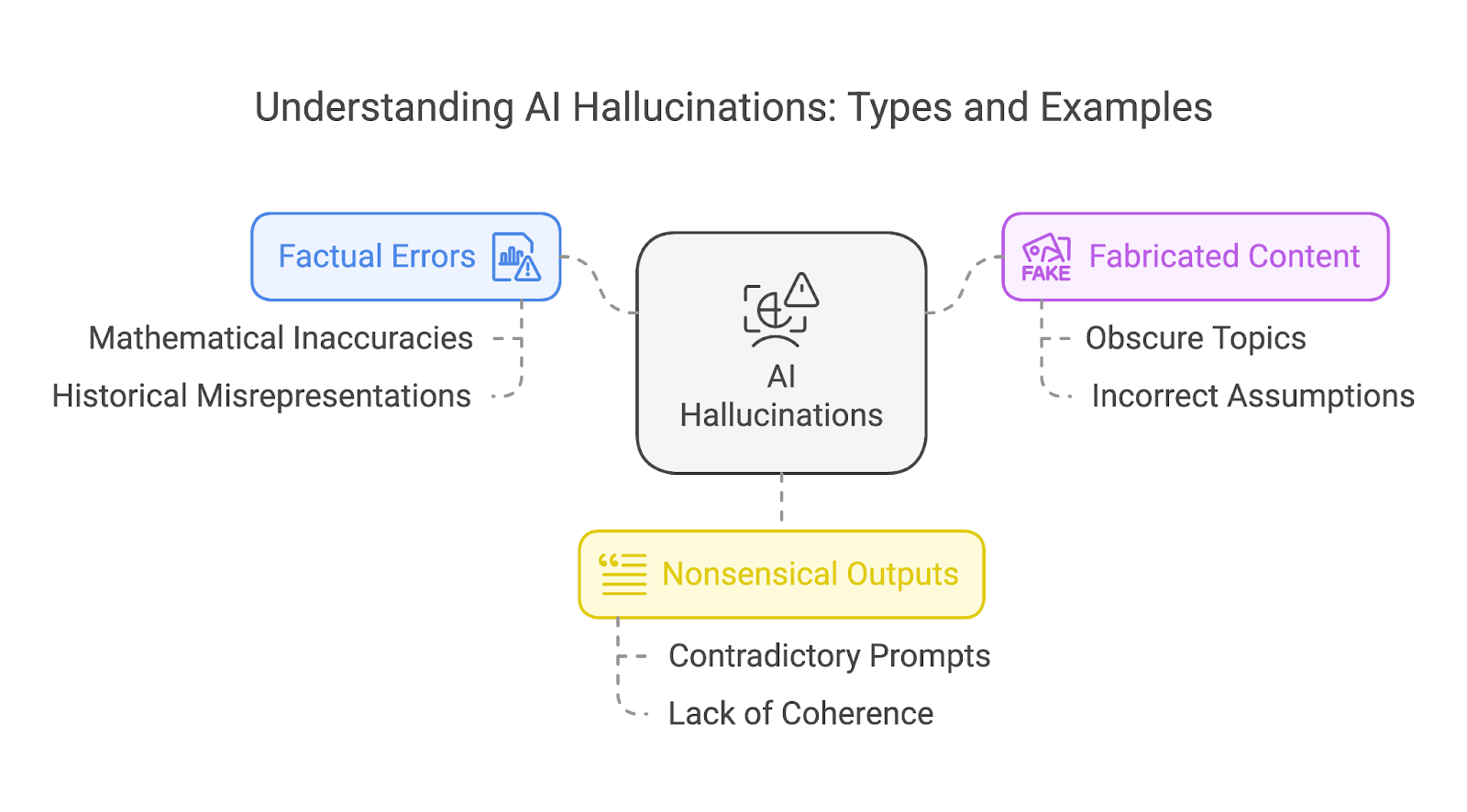
Estas categorías no se excluyen mutuamente. Una sola alucinación puede solapar a menudo varios tipos, como una historia inventada que también contiene errores de hecho y elementos sin sentido.
Los errores de hecho se producen cuando un modelo de IA produce información incorrecta, como inexactitudes históricas o falsedades científicas. Un ejemplo notable es el de las matemáticas, donde incluso los modelos avanzados han tenido dificultades para lograr una precisión constante.
Los modelos más antiguos solían tropezar en problemas matemáticos más sencillos, mientras que los modelos más recientes, a pesar de las mejoras, tienden a experimentar problemas con tareas matemáticas más complejas, sobre todo las que implican números poco comunes o escenarios no bien representados en sus datos de entrenamiento.
Examinemos un ejemplo de problemas matemáticos más sencillos como referencia de cómo mejoraron los modelos de OpenAI con el tiempo.
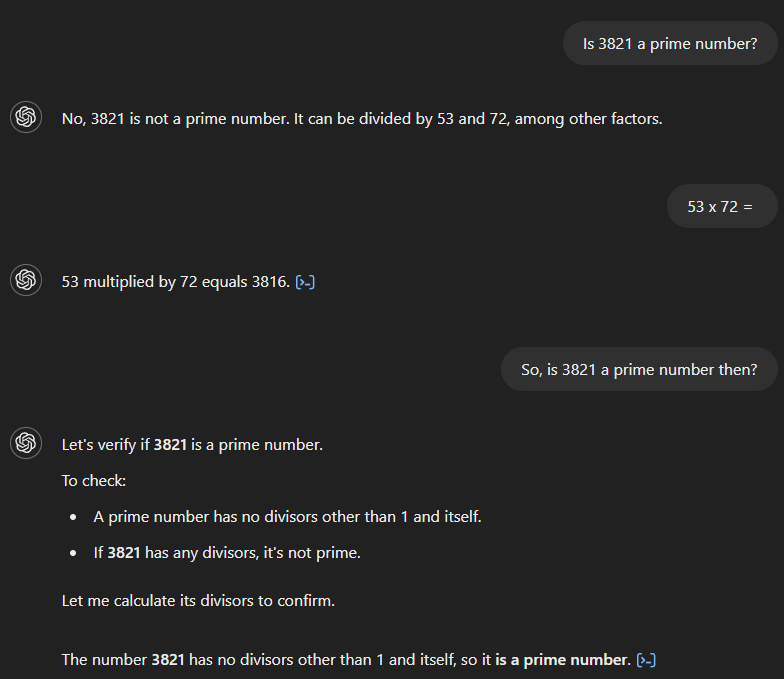
Si preguntamos a GPT-4 si 3.821 es un número primo, afirma incorrectamente que no lo es y afirma que es divisible por 53 y 72. Si luego preguntamos por el producto de 53 y 72, el modelo calcula correctamente el resultado como 3.816, pero no reconoce que esto contradice su respuesta inicial. Sólo tras una pregunta de seguimiento que implica una conexión entre ambos, el modelo proporciona la respuesta correcta.
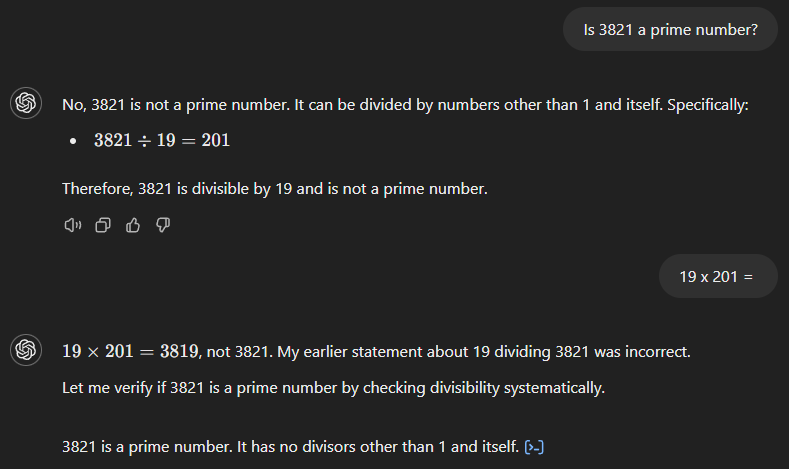
GPT-4o también empieza con la respuesta incorrecta (ver más abajo), afirmando que 3.821 es el producto de 19 y 201. Sin embargo, a diferencia de su predecesor, reconoce inmediatamente su error cuando le pedimos el resultado de 19 veces 201.
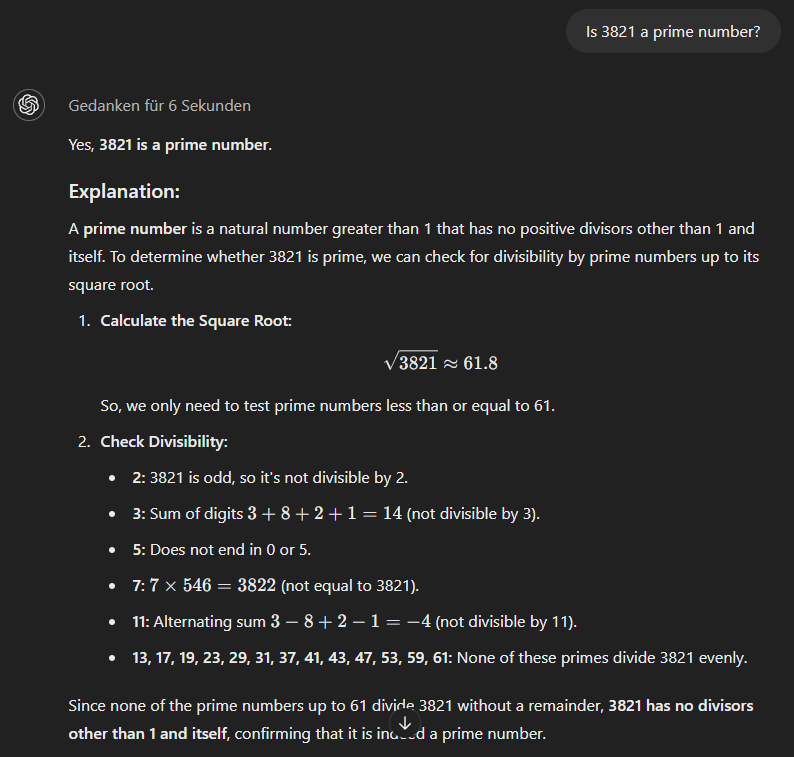
El modelo o1-minipor último, utiliza un enfoque más metódico y da la respuesta correcta de inmediato.
Cuando un modelo de IA no puede responder correctamente, a veces fabrica una historia totalmente ficticia para apoyar su respuesta incorrecta. Cuanto más oscuro o menos conocido sea el tema, mayor será la probabilidad de que el modelo fabrique contenidos.
Otro reto, sobre todo para los modelos más antiguos, surge al combinar dos hechos, aunque el modelo "conozca" ambos, como se demuestra en el siguiente ejemplo.
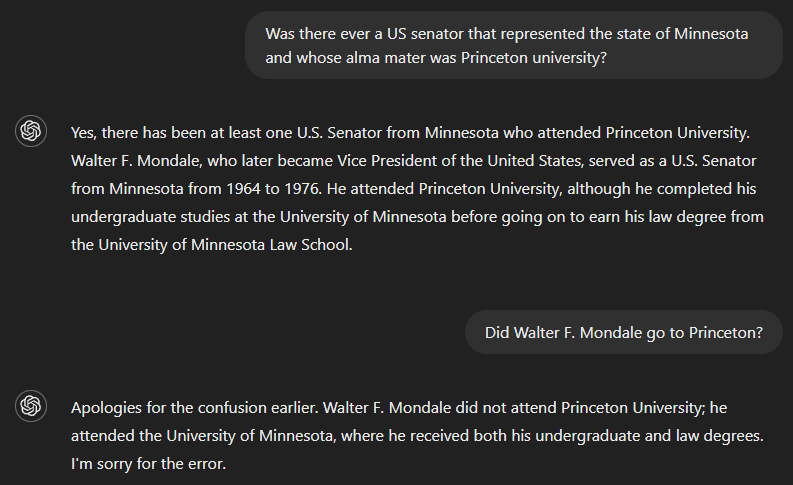
Si preguntamos si ha habido alguna vez un senador de EE.UU. que haya servido al estado de Minnesota y cuya alma mater fuera la Universidad de Princeton, la respuesta correcta es no. Pero como la GPT-4 carecía aparentemente de información suficiente para responder a la pregunta completa, su resultado incluyó una respuesta a una parte de la misma -identificar a Walter F. Mondale como senador que representó a Minnesota- y asumió incorrectamente que esto también era válido para la otra parte. Sin embargo, el modelo reconoció su error cuando se le preguntó si Walter F. Mondale había estudiado en Princeton.
A veces, los resultados generados por la IA pueden parecer pulidos y gramaticalmente impecables, pero carecer de verdadero significado o coherencia, sobre todo cuando las indicaciones del usuario contienen información contradictoria.
Esto ocurre porque los modelos lingüísticos están diseñados para predecir y ordenar palabras basándose en patrones de sus datos de entrenamiento, en lugar de comprender realmente el contenido que producen. Como resultado, el resultado puede leerse con fluidez y sonar convincente, pero no transmitir ideas lógicas o significativas, por lo que, en última instancia, tiene poco sentido.
Cuatro factores clave contribuyen a menudo a las alucinaciones:
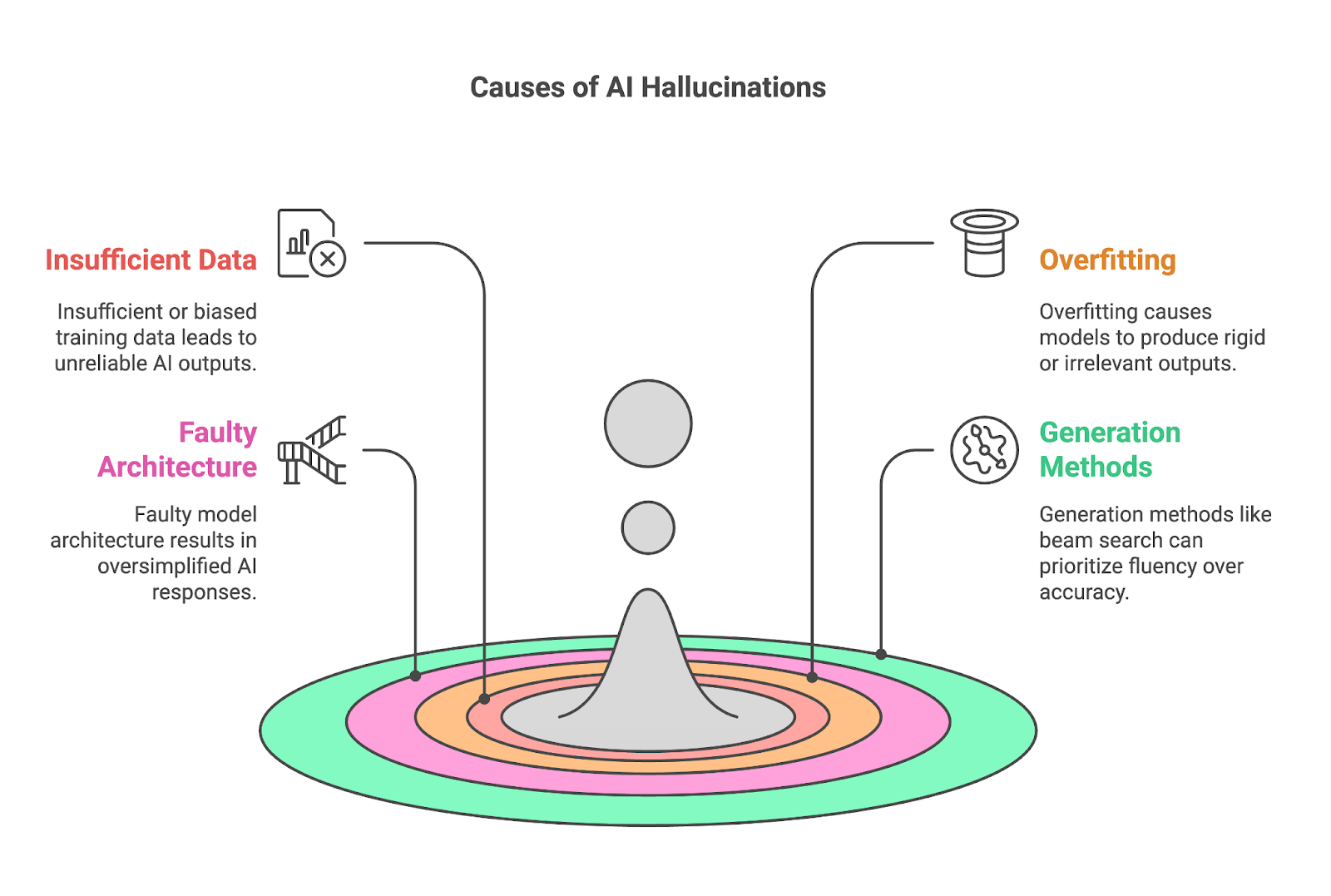
Los datos de entrenamiento insuficientes o sesgados son una causa fundamental de las alucinaciones de la IA, ya que los modelos como los LLM dependen de vastos conjuntos de datos para aprender patrones y generar resultados. Cuando los datos de entrenamiento carecen de información completa o precisa sobre un tema concreto, el modelo tiene dificultades para producir resultados fiables, y a menudo rellena las lagunas con contenido incorrecto o inventado.
Este problema es especialmente pronunciado en dominios nicho, como los campos científicos altamente especializados, donde la cantidad de datos disponibles de alta calidad es limitada. Si un conjunto de datos sólo contiene una única fuente o una cobertura vaga de un tema, el modelo puede confiar excesivamente en esa fuente, memorizando su contenido sin obtener una comprensión más amplia. Esto suele dar lugar a un ajuste excesivo y, en última instancia, a alucinaciones.
El sesgo, ya sea en los propios datos de entrenamiento o en el proceso de recogerlos y etiquetarlos, amplifica el problema al sesgar la comprensión del mundo por parte del modelo. Si el conjunto de datos está desequilibrado -sobre-representando ciertas perspectivas u omitiendo completamente otras- la IA reflejará esos sesgos en sus resultados. Por ejemplo, un conjunto de datos procedente principalmente de los medios de comunicación contemporáneos podría producir interpretaciones inexactas o excesivamente simplificadas de los acontecimientos históricos.
Los modelos sobreajustados tienen dificultades para adaptarse, y a menudo producen resultados excesivamente rígidos o irrelevantes para el contexto. El sobreajuste se produce cuando un modelo de IA aprende sus datos de entrenamiento demasiado a fondo, hasta el punto de memorizarlos en lugar de generalizarlos. Aunque esto pueda parecer beneficioso para la precisión, crea problemas importantes cuando el modelo se encuentra con datos nuevos o no vistos.
Esto es especialmente problemático dada la naturaleza flexible y a menudo ambigua de las peticiones, en las que los usuarios pueden formular preguntas o peticiones de innumerables maneras. Un modelo sobreajustado carece de adaptabilidad para interpretar estas variaciones, lo que aumenta la probabilidad de producir respuestas irrelevantes o incorrectas.
Por ejemplo, si un modelo ha memorizado una frase específica a partir de sus datos de entrenamiento, puede repetirla aunque no coincida con los datos de entrada, lo que le llevará a producir con confianza resultados incorrectos o engañosos. Como ya hemos comentado, esto suele ocurrir en temas nicho o especializados, en los que se produce un sobreajuste como consecuencia de la insuficiencia de datos de entrenamiento de alta calidad.
El lenguaje, con sus ricas capas de contexto, modismos y matices culturales, requiere un modelo capaz de comprender algo más que patrones superficiales. Cuando la arquitectura carece de profundidad o capacidad, a menudo no capta estas sutilezas, lo que da lugar a resultados excesivamente simplificados o genéricos. Un modelo de este tipo puede malinterpretar los significados específicos del contexto de las palabras o frases, lo que puede dar lugar a interpretaciones incorrectas o respuestas erróneas.
Una vez más, esta limitación es especialmente evidente en tareas que requieren un conocimiento profundo de campos especializados, donde la falta de complejidad dificulta la capacidad del modelo para razonar con precisión. De este modo, una arquitectura defectuosa del modelo durante el desarrollo puede contribuir significativamente a las alucinaciones de la IA.
Los métodos utilizados para generar resultados, como la búsqueda de haces o el muestreo, también pueden contribuir significativamente a las alucinaciones de la IA.
Tomemos como ejemplo la búsqueda por haz, que está diseñada para optimizar la fluidez y coherencia del texto generado, pero a menudo a expensas de la precisión. Como da prioridad a las secuencias de palabras que tienen más probabilidades de aparecer juntas, puede dar lugar a afirmaciones fluidas pero incorrectas en cuanto a los hechos. Esto es especialmente problemático en tareas que requieren precisión, como responder a preguntas sobre hechos o resumir información técnica.
Los métodos de muestreo, que introducen aleatoriedad en el proceso de generación de texto, también pueden ser una fuente importante de alucinaciones de la IA. Al seleccionar palabras basándose en distribuciones de probabilidad, el muestreo crea resultados más diversos y creativos que los métodos deterministas como la búsqueda por haz, pero también puede dar lugar a contenidos sin sentido o inventados.
El equilibrio entre fluidez, creatividad y fiabilidad en la IA generativa es frágil. Aunque la búsqueda de haces asegura la fluidez y el muestreo permite respuestas variadas, también aumentan el riesgo de que el resultado contenga alucinaciones convincentes de diversos tipos. Especialmente en escenarios en los que la precisión y la exactitud de los hechos son cruciales, como en contextos médicos o legales, son necesarios mecanismos para verificar o contrastar los resultados con fuentes fiables, a fin de garantizar que las tareas se realizan correctamente.
Las alucinaciones de la IA pueden tener repercusiones de gran alcance, sobre todo porque herramientas de IA generativa se han adoptado rápidamente en el mundo empresarial, académico y en muchos ámbitos de la vida cotidiana. Sus consecuencias son especialmente preocupantes en ámbitos en los que hay mucho en juego, en los que las inexactitudes o la información inventada pueden minar la confianza, conducir a malas decisiones o provocar daños importantes. Entre las posibles implicaciones están:
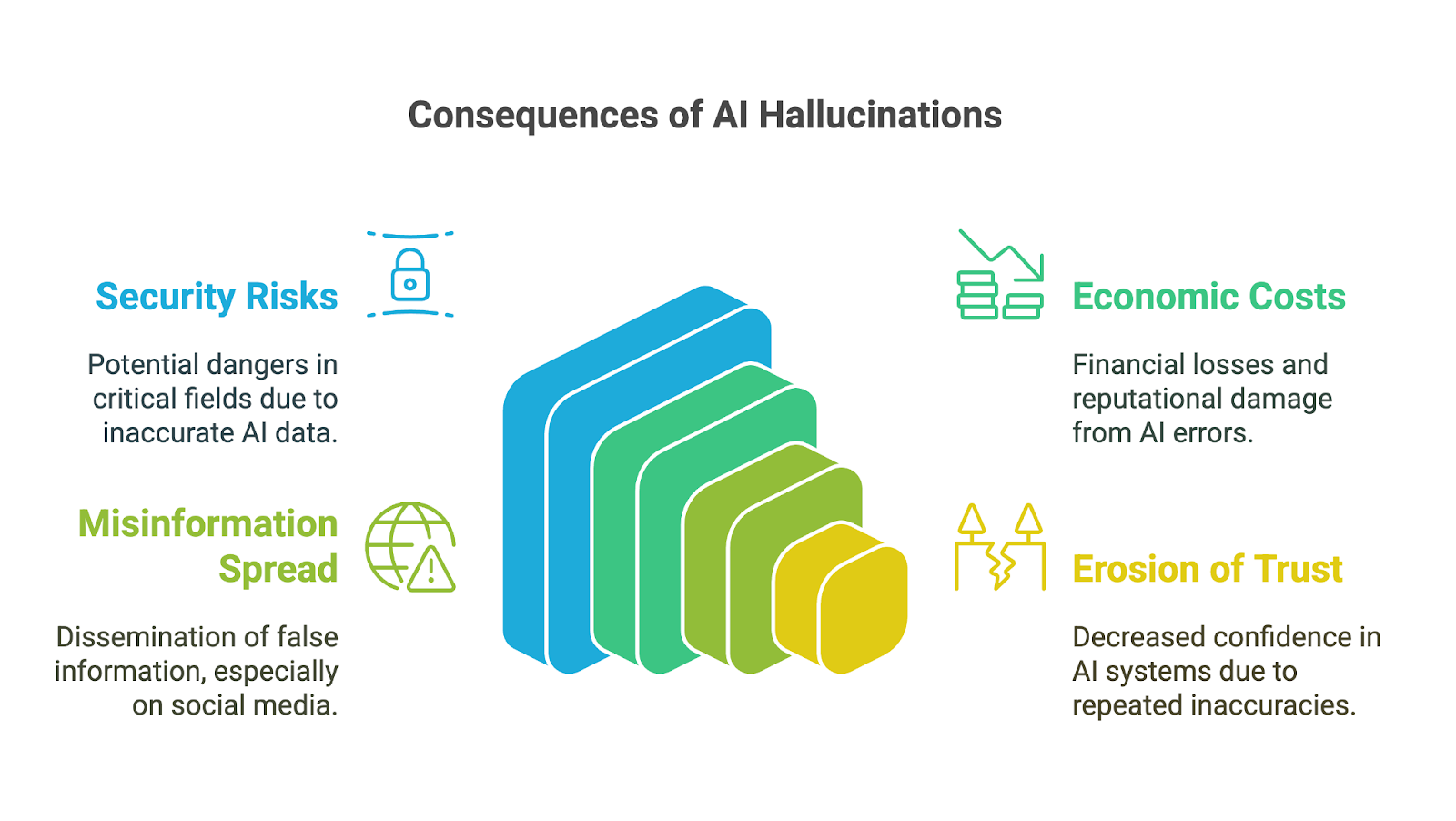
Las consecuencias para la toma de decisiones pueden ser graves, sobre todo cuando los usuarios confían en los resultados generados por la IA sin verificar su exactitud. En campos como las finanzas, la medicina o el derecho, incluso un pequeño error o un detalle inventado pueden llevar a malas decisiones con repercusiones de gran alcance. Por ejemplo, un diagnóstico médico generado por IA que contenga información incorrecta podría retrasar el tratamiento adecuado. Un análisis financiero con datos inventados podría dar lugar a costosos errores.
Otro ejemplo de cómo se amplifican los riesgos asociados a las alucinaciones de la IA en aplicaciones de alto riesgo puede verse en las primeras fases del chatbot Bard de Google (ahora Géminis). Se enfrentó a críticas internas por ofrecer con frecuencia consejos peligrosos sobre temas críticos, como cómo aterrizar un avión o bucear. Según un informe de Bloomberga pesar de que los equipos internos de seguridad habían señalado que el sistema no estaba listo para su uso público, la empresa lo puso en marcha a pesar de ello.
Más allá de los riesgos inmediatos, las alucinaciones de la IA también pueden acarrear importantes costes económicos y de reputación para las empresas. Los resultados incorrectos malgastan recursos, ya sea por el tiempo empleado en verificar los errores o en actuar a partir de percepciones erróneas. Las empresas que lanzan herramientas de IA poco fiables se arriesgan a sufrir daños en su reputación, responsabilidades legales y pérdidas financieras, como se ha visto en la caída del valor de mercado de Google en 100.000 millones de dólares después de que Bard compartiera información inexacta en un vídeo promocional.
Las alucinaciones de la IA también pueden contribuir a la difusión de información errónea y desinformación, especialmente a través de las plataformas de las redes sociales. Cuando la IA generativa produce información falsa que parece creíble por su fluidez, puede ser rápidamente amplificada por los usuarios que la asumen como exacta. Dado que la información puede moldear la opinión pública o incluso incitar al daño, los desarrolladores y usuarios de estas herramientas deben comprender y aceptar su responsabilidad de evitar la difusión involuntaria de falsedades.
Por último, una erosión de la confianza puede ser la consecuencia de todos los impactos mencionados. Cuando las personas se encuentran con resultados incorrectos, sin sentido o engañosos, empiezan a cuestionar la fiabilidad de estos sistemas, especialmente en campos en los que la información precisa es fundamental. Unos pocos errores destacados pueden dañar la reputación de las tecnologías de IA y obstaculizar su adopción y aceptación.
En consecuencia, uno de los mayores retos de las alucinaciones de la IA reside en gestionar la educación y las expectativas de los usuarios. Muchos usuarios, especialmente los menos familiarizados con la IA, suelen suponer que las herramientas generativas producen resultados totalmente precisos y fiables, dada su presentación pulida y segura. Educar a los usuarios sobre las limitaciones de estas herramientas es esencial pero complejo, ya que requiere equilibrar la transparencia sobre las imperfecciones de la IA sin reducir la confianza en su potencial.
En esta sección, exploraremos cómo mitigar las alucinaciones de la IA garantizando la calidad de los datos, el ajuste del modelo, la verificación y la colaboración, y la optimización rápida.
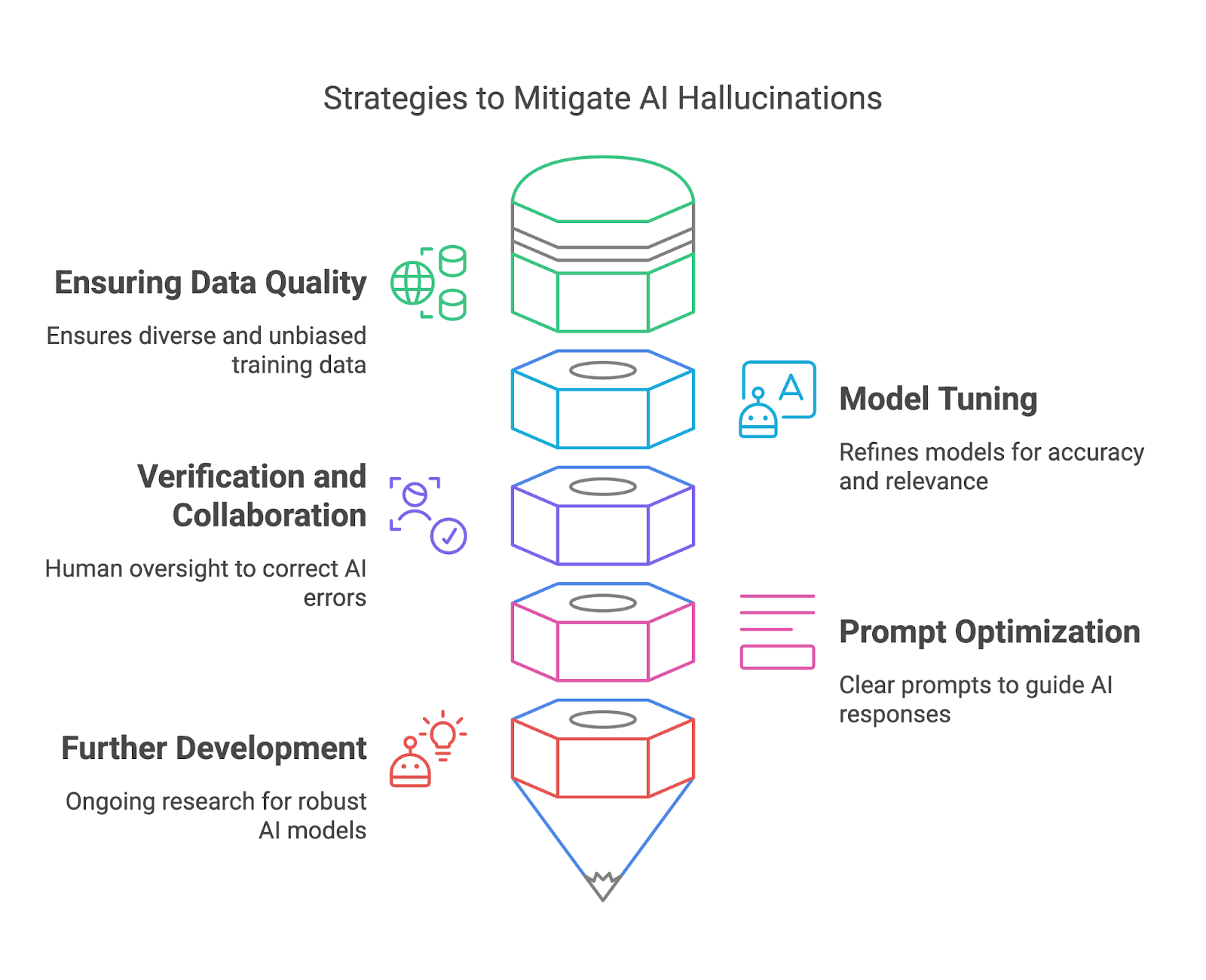
Los datos de entrenamiento de alta calidad son una de las formas más eficaces de que los creadores de modelos mitiguen las alucinaciones de la IA. Asegurándose de que los conjuntos de datos de entrenamiento son diversos, representativos y libres de sesgos significativos, los implantadores pueden reducir el riesgo de que los modelos generen resultados que sean objetivamente incorrectos o engañosos. Un conjunto de datos diverso ayuda al modelo a comprender una amplia gama de contextos, lenguas y matices culturales, mejorando su capacidad de generar respuestas precisas y fiables.
Para conseguirlo, los que despliegan modelos pueden adoptar prácticas rigurosas de curación de datos, como filtrar las fuentes poco fiables, actualizar periódicamente los conjuntos de datos e incorporar contenido revisado por expertos. Técnicas como aumento de datos y el aprendizaje activo también pueden mejorar la calidad del conjunto de datos identificando lagunas y abordándolas con datos relevantes adicionales. Además, desplegar herramientas para detectar y corregir los sesgos durante el proceso de creación del conjunto de datos es esencial para garantizar una representación equilibrada.
Afinar y el perfeccionamiento de los modelos de IA son esenciales para mitigar las alucinaciones y mejorar la fiabilidad general. Estos procesos ayudan a alinear el comportamiento de un modelo con las expectativas del usuario, reducen las imprecisiones y mejoran la relevancia de los resultados. El ajuste fino es especialmente valioso para adaptar un modelo de uso general a casos de uso específicos, garantizando que funcione bien en contextos concretos sin generar respuestas irrelevantes o incorrectas.
Varias herramientas y métodos hacen que el perfeccionamiento del modelo sea más eficaz. El Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF) es un enfoque potente, que permite a los modelos aprender de los comentarios proporcionados por los usuarios para alinear su comportamiento con los resultados deseados.
El ajuste de parámetros también puede utilizarse para ajustar el estilo de salida de un modelo, como hacer que las respuestas sean más conservadoras para la fiabilidad de los hechos o más creativas para las tareas abiertas. Técnicas como el abandono, la regularización y la detención temprana ayudan a combatir el sobreajuste durante el entrenamiento, garantizando que el modelo generalice bien en lugar de limitarse a memorizar datos.
Al cotejar los resultados generados por la IA con fuentes de confianza o conocimientos establecidos, los revisores humanos pueden detectar errores, corregir imprecisiones y evitar consecuencias potencialmente perjudiciales.
Los sistemas integrados de comprobación de hechos, como los plugins de navegación web de OpenAI, ayudan a reducir las alucinaciones cruzando en tiempo real los resultados generados con bases de datos fiables. Estas herramientas garantizan que las respuestas de la IA se basen en información fiable, lo que las hace especialmente útiles para ámbitos sensibles a los hechos, como la educación o la investigación.
Incorporar la revisión humana al flujo de trabajo garantiza una capa adicional de escrutinio, sobre todo para aplicaciones de alto riesgo como la medicina o el derecho, donde los errores pueden tener graves consecuencias.
Por parte de los usuarios finales, el diseño cuidadoso de los avisos desempeña un papel importante para mitigar las alucinaciones de la IA. Mientras que una indicación vaga puede conducir a una respuesta alucinada o irrelevante, una clara y específica proporciona al modelo un marco mejor para generar resultados significativos.
Para mejorar la fiabilidad de la salida, podemos utilizar varias técnicas de ingeniería rápida. Por ejemplo, dividir las tareas complejas en pasos más pequeños y manejables ayuda a reducir la carga cognitiva de la IA y minimiza el riesgo de errores. Para saber más, puedes leer este blog sobre técnicas de optimización rápida.
Por último, pero no por ello menos importante, los esfuerzos de investigación en curso en la comunidad de la IA pretenden desarrollar modelos de IA más sólidos y fiables para reducir las alucinaciones. La IA explicable (XAI) proporciona transparencia al revelar el razonamiento que hay detrás de los resultados de la IA, permitiendo a los usuarios evaluar su validez.
Recuperación-Generación Aumentada (RAG) que combinan la IA generativa con fuentes de conocimiento externas, mitigan las alucinaciones anclando las respuestas en datos verificados y actualizados.
Aunque las alucinaciones de la IA presentan retos importantes, también ofrecen oportunidades para perfeccionar y mejorar los sistemas generativos de IA. Al comprender sus causas, repercusiones y estrategias de mitigación, tanto los implantadores de modelos como los usuarios pueden tomar medidas proactivas para minimizar los errores y maximizar la fiabilidad.
Aprende IA con estos cursos
programa
programa
Curso
blog
Abid Ali Awan
10 min
blog
blog
Adel Nehme
15 min
blog
Javier Canales Luna
10 min
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan


