
Program
AI Temelleri
10 sa
Önce bazı temel Üretken Yapay Zeka mülakat sorularıyla başlayalım. Bunlar, temel kavram ve ilkeleri ne kadar anladığınızı ölçer.
Ayrıştırıcı modeller sınıflar arasındaki karar sınırını ve onları ayırt eden örüntüleri öğrenir. P(y|x) yani belirli bir etiketin y olma olasılığını, verilen girdi verisi x için tahmin eder. Bu modeller farklı kategorileri ayırt etmeye odaklanır (ör. 'Bu e-posta spam mi?').
Üretici modeller verinin dağılımını, ortak olasılığı modelleyerek P(x,y) öğrenir; bu, bu dağılımdan veri örnekleri üretmeyi içerir. Binlerce rakam görüntüsüyle eğitildikten sonra, bu örnekleme yeni bir rakam görüntüsü üretebilir.
Daha fazlası için şu blogu okuyun: Üretici ve Ayrıştırıcı Modeller: Farklar ve Kullanım Alanları.
Token'lar, bir LLM'in işlediği metnin temel birimleridir; tüm sözcükler, heceler veya tek tek harfler olabilir (örneğin, "generative" kelimesi "gener", "at", "ive" olarak bölünebilir).
Gömme vektörleri, bu token'ların anlamlarına göre çok boyutlu bir uzaya yerleştirilen sayısal temsilleridir. Bu dönüşüm, modelin anlamsal anlamı yakalamasını ve sözcükler arasındaki ilişkileri anlamasını sağlar; örneğin "king" ile "queen" arasındaki yakınlığı fark etmek gibi.
GAN'ler iki sinir ağının birlikte rekabet etmesiyle (Adversarial kelimesi buradan gelir) oluşturulur: bir üretici (generator) ve bir ayrıştırıcı (discriminator).
Üretici sahte veri örnekleri oluştururken ayrıştırıcı bunları gerçek eğitim verisiyle karşılaştırarak değerlendirir. İki ağ eşzamanlı olarak eğitilir:
Bu rekabetçi öğrenme sayesinde üretici, eğitim verisine benzer son derece gerçekçi veriler üretme konusunda ustalaşır.
GenAI'nın yaygın kullanımı ve kullanım senaryoları, performanslarının etik açısından kapsamlı şekilde değerlendirilmesini gerektirir. Bazı örnekler şunlardır:
Her ne kadar AI modellerinin halüsinasyonları hatalı çıktılar üretebilse de, bu üretici modeller birçok açıdan ve kullanımda faydalıdır. Çeşitli alanlardaki uzmanlara yaratıcı ilham olarak kullanılabilirler:
Bir Temel Model (GPT-5.2 gibi), genel örüntüleri, akıl yürütmeyi ve dil yapısını öğrenmek için geniş internet verisi üzerinde eğitilir.
İnce Ayarlı bir model, bu genelist tabanı alır ve daha küçük, seçilmiş bir veri kümesi üzerinde belirli bir görevi (örneğin tıbbi teşhis veya belirli bir kodlama dilinde konuşma) ustalıkla yapacak şekilde daha ileri eğitilir. İnce ayar, geniş çok yönlülüğü belirli bir alanda derin uzmanlıkla değiş tokuş eder.
Artık temelleri ele aldığımıza göre, orta düzey üretken yapay zeka mülakat sorularını inceleyelim.
Nasıl ki bir içerik üretici, belirli bir video formatının daha fazla erişim ve etkileşim getirdiğini fark edip buna saplanabiliyorsa, bir GAN'in üretici modeli de ayrıştırıcı modeli kandıran sınırlı çeşitlilikte çıktılara takılı kalabilir. Bu, üreticinin az sayıda çıktı üretmesine ve üretilen verinin çeşitlilik ve esnekliğinin kaybolmasına yol açar.
Olası çözümler arasında, hiperparametreleri ve çeşitli optimizasyon algoritmalarını ayarlayarak eğitim tekniklerine odaklanmak, çeşitliliği teşvik eden düzenlileştirmeler uygulamak veya farklı üretim modlarını kapsamak için birden fazla üreticiyi birleştirmek sayılabilir.
Bir Varyasyonel Otokodlayıcı (VAE), girdi verisini bir gizil (latent) uzaya kodlamayı ve oradan çözerek özgün girdiyi yeniden oluşturmeyi öğrenen bir tür üretici modeldir. VAE'ler kodlayıcı-çözücü modellerdir:
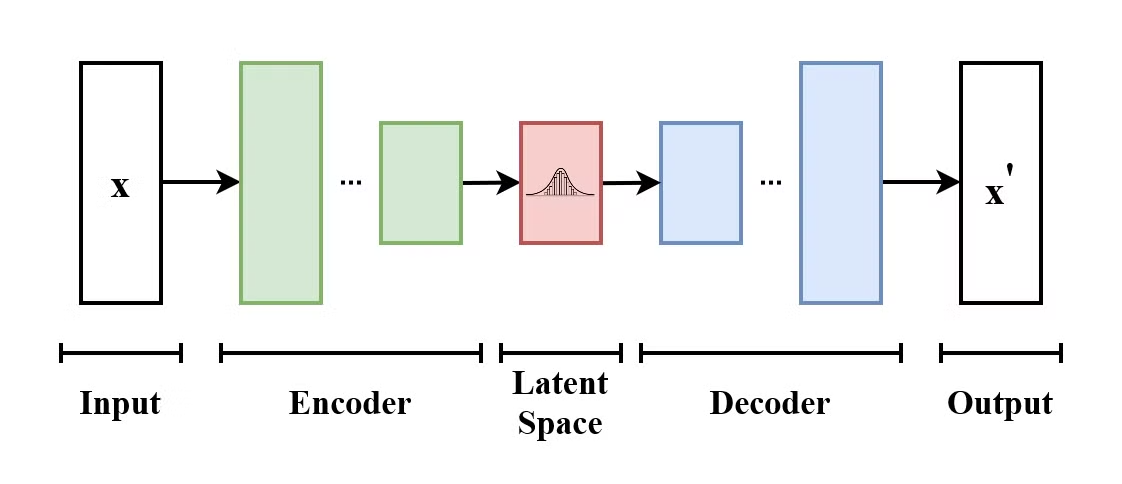
Varyasyonel Otokodlayıcının yapısı. (Kaynak: Wikimedia Commons)
VAE'leri geleneksel otokodlayıcılardan ayıran, gizil uzayın bilinen bir dağılımı (örneğin Gauss) takip etmesini teşvik etmesidir. Bu da, gizil uzaydan örnekleyerek yeni veri üretmekte daha kullanışlı olmalarını sağlar.
RAG bir modeli, yeniden eğitmeden güncel gerçekleri çekmek için harici veri kaynaklarına (örneğin şirket vikinize) bağlar. Modelin parametreleri aynı kalır; yalnızca ek verilere erişir.
İnce ayar, modelin iç ağırlıklarını, nasıl konuştuğunu, davrandığını veya akıl yürüttüğünü değiştirecek şekilde ayarlar; ancak yeni olgusal bilgi eklemede iyi değildir.
Güncel bilgilere (haberler, özel şirket verisi) veya belirli bir atfa ihtiyaç duyduğunuzda RAG kullanın. Modelin yeni bir "davranış"ı, dili veya belirli bir çıktı formatını (ör. SQL ile konuşma) öğrenmesi gerektiğinde ince ayarı kullanın.
Üretilen örnekleri değerlendirmek, veri kipine (görsel, metin, video vb.) bağlı karmaşık bir görevdir. Geleneksel metin metrikleri (doğruluk gibi) yaratıcı görevler için yetersizdir; çünkü anlamı değil, yalnızca sözcük örtüşmesini kontrol ederler.
LLM kıyasları ve lider tabloları, bir modelin belirli bir görevi ne kadar iyi yerine getirdiğini ölçmek için standartlaştırılmış testler kullanır. Modelleri karşılaştırmak ve kipler içinde/arasındaki ilerlemeyi takip etmek için faydalıdırlar.
LLM-as-a-Judge, Gemini 3 gibi çok yetkin bir "öğretmen" modelin, daha küçük bir modelin çıktısını doğruya bağlılık, faydalılık ve ton gibi belirli ölçütlere göre notladığı modern bir değerlendirme çerçevesidir. Bu, manuel insan incelemesinin yavaşlığı ve maliyeti olmadan insan tercihlerini yaklaşık olarak ölçekli biçimde elde etmeyi sağlar.
GAN eğitiminde kararlılığı ve yakınsamayı iyileştirmek, mod çökmesini önlemek, verimli eğitim sağlamak ve iyi sonuçlar elde etmek için önemlidir. İşte kararlılığı ve yakınsamayı artırmaya yönelik bazı teknikler:
GenAI çıktılarının üslubunu kontrol etmek için yaygın birkaç teknik vardır:
Modelin önyargısız ve adil olmasını sağlamak, her aşamada yinelenen ayarlamalar ve izleme gerektirir.
Öncelikle, test verisinin eğitim verisine sızmadığından emin olarak veri kontaminasyonu engellenmelidir. Aksi halde model, genellemek yerine veriyi ezberleyecektir.
Ayrıca eğitim verisinin mümkün olduğunca çeşitli ve kapsayıcı olması sağlanmalıdır. Eğitim sırasında, kayıp fonksiyonuna adalet hedefleri ekleyerek modeli daha adil üretime yönlendirebiliriz.
Model çıktıları düzenli olarak önyargı açısından izlenmelidir. Kamu güvenini artırmak için modelin karar verme sürecini, veri kümesi ayrıntılarını ve ön işleme adımlarını olabildiğince şeffaf kılmak faydalıdır.
Üretici modeller bağlamında gizil uzay, verinin temel özelliklerini yakalayan ve benzer girdilerin birbirine daha yakın eşlendiği daha düşük boyutlu bir uzaydır. Bu gizil uzaydan örnekleme yapmak, modellere yeni veriler üretme ve belirli öznitelikleri veya özellikleri (görsel varyasyonları üretme) manipüle etme olanağı verir.
Gizil uzaylar, kontrol edilebilir, eğitime sadık ve çeşitli çıktılar üretmenin anahtarıdır.
Öz denetimli öğrenmenin temel fikri, elle etiketlemeye gerek kalmadan yararlı temsiller öğrenmek için geniş etiketlenmemiş veri derlemlerinden yararlanmaktır. BERT ve GPT gibi modeller, sonraki token tahmini ve dilin yapı ve anlamsal özelliklerini öğrenme gibi öz denetimli yöntemlerle eğitilir. Bu, elde edilmesi maliyetli ve zaman alıcı olan etiketli veriye bağımlılığı azaltır ve modellerin eğitim için geniş etiketlenmemiş veri kümelerinden yararlanmasını sağlar.
70 milyar parametreli devasa bir modeli yeniden eğitmek çoğu kurum için son derece pahalı ve yavaştır. Low-Rank Adaptation (LoRA), ana model ağırlıklarını dondurup yalnızca üstte yer alan küçük bir "adaptör" katmanını (genellikle toplam parametrelerin %1'inden az) eğiterek bunu çözer. Bu sayede tek bir temel modelden onlarca farklı "özel" modeli sunabilir, hesaplama maliyetini ve depolama ihtiyaçlarını ciddi biçimde azaltabilirsiniz.
Daha kıdemli rolleri hedefleyenler veya Üretken Yapay Zeka konusunda derin bir anlayış sergilemek isteyenler için, bazı ileri düzey mülakat sorularını inceleyelim.
Difüzyon Modelleri, temelde bir görsele kademeli olarak gürültü ekleyip yalnızca gürültü kalana dek bunu sürdürerek ve ardından bu süreci tersine çevirmeyi öğrenerek gürültüden yeni örnekler üretir. Bu sürece difüzyon denir. Bu modeller, yüksek kaliteli ve çok ayrıntılı görseller üretebilme becerileriyle popülerlik kazanmıştır.

Difüzyon adımlarıyla bir görselin üretilmesi. (Kaynak: Wikimedia Commons)
Bu modellerin eğitimi iki adımdan oluşur:
Eğitim kararsızlığıyla sıklıkla boğuşan eski GAN'lerin aksine, difüzyon modelleri daha kararlı ve ölçeklenebilirdir; ancak yinelemeli doğaları nedeniyle daha yavaş olabilirler.
Güncel varyantlar olan gizil difüzyon, üretimi hızlandırmak için sıkıştırılmış bir "gizil uzay"da çalışır ve flow matching mimarileri, daha da iyi performans için standart difüzyonun yerini almaya başlamıştır.
Transformer mimarisi, “Attention is All You Need” makalesinde tanıtılmış olup, özellikle doğal dil işleme (NLP) alanında üretken yapay zekayı dönüştürmüştür.
Geleneksel yinelemeli sinir ağlarının (RNN) veriyi sıralı şekilde işlemesinin aksine, transformer'lar öz-dikkat (self-attention) mekanizmasını kullanarak girdinin farklı bölümlerine aynı anda ağırlık atar. Bu, bağlamsal ilişkileri etkili biçimde yakalamayı sağlar ve dizilerin paralel işlenmesine olanak vererek eğitimi önemli ölçüde hızlandırır.
Temel darboğaz, bu dikkat mekanizmasının dizi uzunluğuyla karesel olarak ölçeklenmesidir—bağlam penceresini iki katına çıkarmak, hesaplamayı dört katına çıkarır. Bu da "sonsuz bağlamı" teoride mümkün, fakat hesaplama açısından pahalı kılar ve daha verimli dikkat yöntemlerine yönelik araştırmaları tetikler.
Standart LLM'ler "Sistem 1" düşünürler olarak hareket eder; yüzey düzeyindeki örüntülere dayanarak bir sonraki kelimeyi anında tahmin ederler.
Akıl Yürütme Modelleri (Gemini 3 veya DeepSeek-R1 gibi), yanıt vermeden önce gizli bir "Düşünce Zinciri" üretmek üzere eğitilir; bu da onların "düşünmesine", plan yapmasına ve hatalarını kendi kendine düzeltmesine olanak tanır. Bu, onları karmaşık matematik, kodlama ve mantık bulmacalarında belirgin biçimde daha iyi kılar; ancak çalıştırılmaları daha yavaş ve daha pahalıdır.
AI üretiminin karmaşıklığını artırdıkça şu konuları da ele almalısınız:
GenAI alanı hızlı bir şekilde evrilip yeniden şekilleniyor. Buna şunlar dahildir:
Sektöre özgü kullanım senaryoları için üretken yapay zekayı kullanan bir sistem tasarlamak kapsamlı bir yaklaşımdır. Genel yönergeler, diğer sektörlere göre uyarlanıp değiştirilebilir.
Bağlam içi öğrenme, LLM'lerin ek ince ayara gerek olmadan sağlanan bağlama göre üslup ve çıktısını değiştirme yeteneğidir.
few-shot öğrenme veya prompt mühendisliği olarak da adlandırılabilir. Bu, istenen yanıtın bir veya birden çok örneğini belirtmekle ya da modelin nasıl davranması gerektiğini açıkça tarif etmekle sağlanabilir.
Bağlam içi öğrenmenin sınırlamaları da vardır. Kısa vadelidir ve göreve özeldir; çünkü model, bu tekniği kullandığınız diğer oturumlarda gerçekten bir bilgi tutmaz.
Ayrıca, istenen çıktı karmaşıksa, model çok sayıda örneğe ihtiyaç duyabilir. Verilen örnekler yeterince açık değilse veya görev modelin kapasitesini aşıyorsa, bazen hatalı veya tutarsız çıktılar üretebilir.
İstemleme, LLM'leri belirli görevlere yanıt vermeye yönlendirmede önemlidir. Etkili istemler, few-shot öğrenme, görev ayrıştırma ve istem şablonları gibi tekniklerle modelin ince ayar ihtiyacını bile azaltabilir.
Etkili prompt mühendisliği için bazı en iyi uygulamalar şunlardır:
Daha fazlası için şu blogu okuyun: İstem Optimizasyon Teknikleri.
Koşullu Üretim, modelin belirli koşullar veya bağlamlara göre çıktı üretmesini içerir. Bu, üretilen içerik üzerinde daha fazla kontrol sağlar. Koşullu GAN'lerde (cGAN) hem üretici hem de ayrıştırıcı, sınıf etiketleri gibi ek bilgilerle koşullandırılır. Nasıl çalıştığı şöyledir:
Mixture of Experts (MoE), tek bir yoğun sinir ağı yerine birçok uzmanlaşmış "uzman" alt ağı kullanır. Her bir token için bir yönlendirici, veriyi işlemesi adına yalnızca en alakalı uzmanları seçer; bu da bir modelin 100 milyar parametresi olsa bile çıkarımda yalnızca 10 milyarını kullanabileceği anlamına gelir.
Bu mimari, modellerin inanılmaz derecede zeki (yüksek toplam parametre sayısı) olurken aynı zamanda hızlı ve ucuz çalışmasını (düşük aktif parametre sayısı) sağlar.
Üretken yapay zekaya odaklanan bir AI mühendisliği rolü için mülakata giriyorsanız, üretici modelleri tasarlama, uygulama ve dağıtma yeteneğinizi değerlendiren sorular bekleyin.
Standart bir sohbet botu pasiftir: bir sorgu alır ve eğitimi temelinde metin bir yanıt üretir.
Ajanslı bir iş akışı, LLM'e araçlara (web tarayıcı, kod yorumlayıcı veya API gibi) erişim ve bir hedefi çözmek için çok adımlı bir süreç planlama özerkliği verir. Ajan, web'de arama yapmayı, veriyi Python koduyla analiz etmeyi ve ardından bir rapor yazmayı planlayabilir; görev tamamlanana kadar döngüyü sürdürebilir.
LLM'lerin güvenliğini ve sağlamlığını sağlamak çeşitli zorluklar barındırır. Birincil zorluk, bu modellerin geniş hatta filtrelenmemiş veri kaynaklarıyla eğitilmeleri nedeniyle zararlı veya önyargılı çıktılar üretme potansiyelidir; toksik veya yanıltıcı içerik üretebilirler.
LLM kaynaklı içeriğin bir diğer büyük sorunu, modelin gerçekte yanlış olan bilgileri kendinden emin bir üslupla üretmesi anlamına gelen halüsinasyon tehlikesidir. Bir başka zorluk da, modelin güvenlik önlemlerini ihlal edip zararlı veya etik dışı yanıtlar üreten düşmanca istemlere karşı güvenliktir; bu, çeşitli modellerde defalarca kanıtlanmıştır.
Güvenlik filtreleri ve moderasyon katmanları eklemek, üretilen zararlı içeriği tespit etmeye ve kaldırmaya yardımcı olabilir. Sürekli insan denetimi (human-in-the-loop) model güvenliğini daha da artırır.
Buna ek olarak mühendisler, kullanıcı ile model arasına yerleştirilen açık Guardrails (NeMo Guardrails veya Llama Guard gibi) uygulamalıdır. Bu sistemler, girdileri prompt enjeksiyonu girişimleri veya KKB (Kişisel Kimlik Bilgileri) sızıntıları için tarar ve çıktıları, kullanıcıya ulaşmadan önce toksik veya halüsinatif yanıtları yakalamak için tarar. Bu, modelin olasılıksal doğasından bağımsız çalışan deterministik bir güvenlik katmanı oluşturur.
Bu sorunun yanıtı, projelerinize ve deneyimlerinize oldukça özeldir. Yine de aşağıdaki noktaları aklınızda tutabilirsiniz:
Yukarıdaki soruda olduğu gibi, bu soru da deneyiminize dayalı yanıtlanabilir; ancak şunları da aklınızda bulundurun:
Bağlam pencereleri çok büyük olsa bile (ör. 1 milyon token), LLM'ler sıklıkla istemin ortasına gömülü bilgiyi getirmekte zorlanır; başlangıç ve sona öncelik verir.
Mühendisler bunu, en kritik getirilen parçaları bağlam penceresinin başına veya sonuna taşıyan akıllı yeniden sıralama algoritmalarıyla hafifletir. Bir diğer strateji, uzun belgenin bölümlerini modelin bağımsız olarak özetlediği ve ardından bunları nihai bir yanıt için birleştirdiği "harita-azalt" (map-reduce) algoritmasıdır.
Bir RAG sistemi kurmak sistematik bir yaklaşım gerektirir. Hat şu şekilde görünebilir:
Yanıt burada da kişisel tercihlere bağlıdır; ancak şu başlıklardan bahsedebilirsiniz:
Üretken Yapay Zeka, hayatımızın ve kariyerlerimizin çeşitli yönlerini etkilemenin yollarını buldukça, temel konulara meraklı bir gözle bakmak hayati önem taşır. Bir mülakatta sorulabilecek olası GenAI soruları belirli role ve şirkete bağlı olsa da, mülakat hazırlık yolculuğunuza başlamanıza yardımcı olmak için 30 soru ve yanıtı örneklemeye çalıştım.
Daha fazla mülakat sorusu keşfetmek için şu blogları öneririm:
Bu kurslarla AI öğrenin!
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
