
Tracks
Cơ bản về Trí tuệ Nhân tạo
10 giờ
Hãy bắt đầu với một số câu hỏi nền tảng về AI tạo sinh. Chúng sẽ kiểm tra mức độ hiểu biết của bạn về các khái niệm và nguyên tắc cốt lõi.
Mô hình phân biệt học ranh giới quyết định giữa các lớp và các mẫu giúp phân biệt chúng. Chúng ước lượng xác suất P(y|x), tức xác suất của nhãn y cụ thể khi biết dữ liệu đầu vào x. Các mô hình này tập trung vào việc phân biệt giữa các danh mục khác nhau (ví dụ: "Email này có phải spam không?").
Mô hình tạo sinh học phân phối của chính dữ liệu bằng cách mô hình hóa xác suất đồng thời P(x,y), bao gồm việc lấy mẫu các điểm dữ liệu từ phân phối này. Sau khi được huấn luyện trên hàng nghìn ảnh chữ số, việc lấy mẫu này có thể sinh ra một ảnh chữ số mới.
Đọc thêm trong blog này về Mô hình tạo sinh vs mô hình phân biệt: Khác nhau & Trường hợp sử dụng.
Token là các đơn vị văn bản cơ bản mà một LLM xử lý; chúng có thể là từ hoàn chỉnh, âm tiết, hoặc thậm chí từng chữ cái (ví dụ, từ "generative" có thể được tách thành "gener", "at", "ive").
Embedding là các biểu diễn vectơ số của những token đó, đặt chúng vào một không gian đa chiều dựa trên ý nghĩa. Việc chuyển đổi này giúp mô hình nắm bắt ngữ nghĩa và hiểu mối quan hệ giữa các từ, chẳng hạn nhận ra "king" gần với "queen".
GAN gồm hai mạng nơ-ron cạnh tranh với nhau (vì vậy mới có chữ Adversarial): một bộ sinh (generator) và một bộ phân biệt (discriminator).
Bộ sinh tạo ra mẫu dữ liệu giả, còn bộ phân biệt đánh giá chúng so với dữ liệu huấn luyện thật. Hai mạng được huấn luyện đồng thời:
Thông qua học cạnh tranh, bộ sinh dần thành thạo trong việc tạo dữ liệu rất chân thực, tương tự dữ liệu huấn luyện.
Việc sử dụng rộng rãi GenAI và các trường hợp ứng dụng của nó đòi hỏi đánh giá kỹ lưỡng hiệu năng về mặt đạo đức. Một số ví dụ gồm:
Mặc dù hiện tượng ảo giác của các mô hình AI có thể tạo ra đầu ra sai lệch, các mô hình tạo sinh lại hữu ích ở nhiều khía cạnh và mục đích. Chúng có thể được dùng như nguồn cảm hứng sáng tạo cho chuyên gia ở nhiều lĩnh vực:
Một Mô hình Nền tảng (như GPT-5.2) được huấn luyện trên lượng lớn dữ liệu internet rộng để học các mẫu tổng quát, suy luận và cấu trúc ngôn ngữ.
Một mô hình Fine-Tuned lấy nền tảng tổng quát này và huấn luyện tiếp trên một tập dữ liệu nhỏ hơn, được chọn lọc để làm chủ một nhiệm vụ cụ thể, như chẩn đoán y khoa hoặc nói bằng một ngôn ngữ lập trình cụ thể. Fine-tuning đánh đổi tính đa năng rộng cho mức độ chuyên sâu hơn trong một lĩnh vực cụ thể.
Sau khi đã bao quát những điều cơ bản, hãy khám phá một số câu hỏi phỏng vấn AI tạo sinh ở mức trung cấp.
Tương tự như một nhà sáng tạo nội dung thấy định dạng video nào đó mang lại nhiều lượt tiếp cận và tương tác hơn, bộ sinh của GAN có thể bị ám ảnh vào một số ít kiểu đầu ra đánh lừa được bộ phân biệt. Hệ quả là bộ sinh chỉ tạo một tập đầu ra nhỏ, làm giảm tính đa dạng và linh hoạt của dữ liệu sinh ra.
Các giải pháp có thể gồm tập trung vào kỹ thuật huấn luyện bằng cách điều chỉnh siêu tham số và các thuật toán tối ưu khác nhau, áp dụng các quy chuẩn hoá (regularization) khuyến khích đa dạng, hoặc kết hợp nhiều bộ sinh để bao phủ các "mode" sinh dữ liệu khác nhau.
Một Variational Autoencoder (VAE) là một loại mô hình tạo sinh học cách mã hoá dữ liệu đầu vào vào không gian tiềm ẩn và giải mã ngược để tái tạo dữ liệu gốc. VAE là các mô hình mã hoá - giải mã:
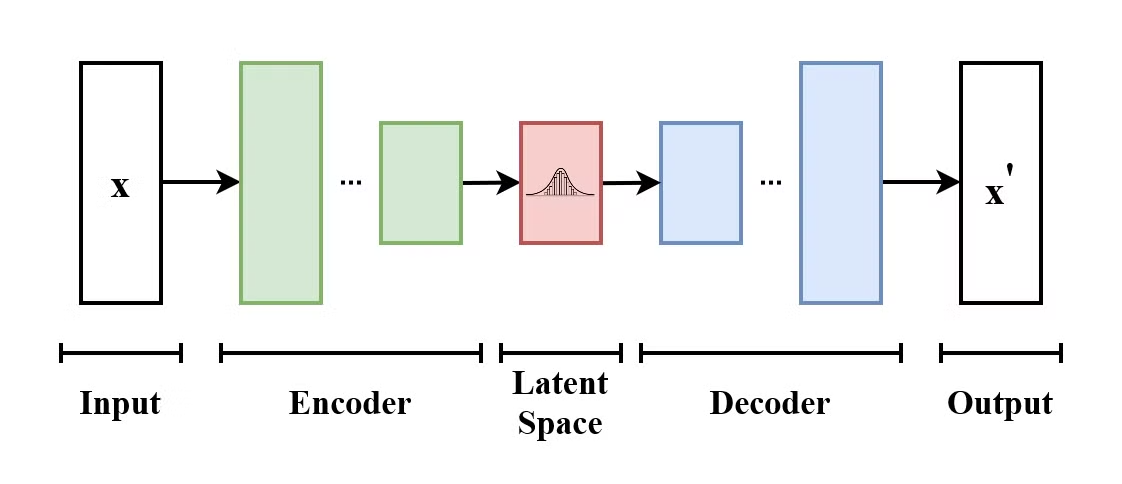
Cấu trúc của Variational Autoencoder. (Nguồn: Wikimedia Commons)
Điểm khác biệt của VAE so với autoencoder truyền thống là VAE khuyến khích không gian tiềm ẩn tuân theo một phân phối đã biết (như Gaussian). Điều này khiến chúng hữu ích hơn trong việc sinh dữ liệu mới bằng cách lấy mẫu từ không gian tiềm ẩn này.
RAG kết nối mô hình với các nguồn dữ liệu bên ngoài (như wiki công ty của bạn) để truy xuất thông tin cập nhật mà không cần huấn luyện lại mô hình. Tham số của mô hình giữ nguyên; nó chỉ được truy cập thêm dữ liệu.
Fine-tuning sửa đổi trọng số bên trong của mô hình để thay đổi cách nó nói, hành xử hoặc suy luận, nhưng không phù hợp để bổ sung kiến thức thực tế mới.
Dùng RAG khi bạn cần thông tin cập nhật (tin tức, dữ liệu riêng của công ty) hoặc trích dẫn cụ thể. Dùng fine-tuning khi bạn cần mô hình học một "hành vi" mới, ngôn ngữ, hoặc định dạng đầu ra cụ thể (ví dụ: nói bằng mã SQL).
Đánh giá các mẫu được sinh là nhiệm vụ phức tạp và phụ thuộc vào kiểu dữ liệu (hình ảnh, văn bản, video, v.v.). Những chỉ số văn bản truyền thống như độ chính xác là chưa đủ cho các tác vụ sáng tạo vì chúng chỉ kiểm tra độ trùng từ, không phải ý nghĩa.
Bộ chuẩn và bảng xếp hạng LLM dùng các bài kiểm tra chuẩn hoá để đo mức độ mô hình xử lý một nhiệm vụ. Chúng hữu ích để so sánh mô hình và theo dõi tiến bộ trong hoặc giữa các kiểu dữ liệu.
LLM-as-a-Judge là khung đánh giá hiện đại, nơi một mô hình "giáo viên" rất mạnh (như Gemini 3) chấm điểm đầu ra của một mô hình nhỏ hơn dựa trên các tiêu chí cụ thể, bao gồm tính trung thực, hữu ích và giọng điệu. Điều này cung cấp cách tiếp cận quy mô để xấp xỉ sở thích của con người mà không chậm và tốn kém như đánh giá thủ công.
Cải thiện độ ổn định và hội tụ khi huấn luyện GAN quan trọng để tránh mode collapse, đảm bảo huấn luyện hiệu quả và đạt kết quả tốt. Dưới đây là một số kỹ thuật:
Có một số kỹ thuật phổ biến để kiểm soát phong cách đầu ra GenAI:
Đảm bảo mô hình không thiên lệch và công bằng cần các điều chỉnh lặp lại và giám sát qua từng giai đoạn.
Trước tiên, cần ngăn ô nhiễm dữ liệu bằng cách đảm bảo không có dữ liệu kiểm thử rò rỉ vào dữ liệu huấn luyện. Khi đó, mô hình sẽ học thuộc lòng dữ liệu thay vì khái quát hoá.
Tiếp theo, cần đảm bảo dữ liệu huấn luyện đa dạng và bao quát nhất có thể. Trong quá trình huấn luyện, ta có thể dẫn hướng mô hình tới sinh đầu ra công bằng hơn bằng cách đưa các mục tiêu công bằng vào hàm mất mát.
Đầu ra của mô hình phải được theo dõi thường xuyên để phát hiện thiên lệch. Để xây dựng niềm tin công chúng, nên minh bạch quy trình ra quyết định của mô hình, chi tiết tập dữ liệu và các bước tiền xử lý ở mức có thể.
Trong bối cảnh mô hình tạo sinh, không gian tiềm ẩn là không gian chiều thấp hơn nắm bắt các đặc trưng cốt lõi của dữ liệu theo cách các đầu vào tương tự được ánh xạ gần nhau. Lấy mẫu từ không gian này cho phép mô hình sinh dữ liệu mới và thao tác các thuộc tính/đặc trưng cụ thể (tạo biến thể ảnh).
Không gian tiềm ẩn là chìa khóa để tạo ra đầu ra có thể kiểm soát, trung thành với dữ liệu huấn luyện và đa dạng.
Ý tưởng cốt lõi của học tự giám sát là tận dụng kho dữ liệu không gán nhãn khổng lồ để học biểu diễn hữu ích mà không cần gán nhãn thủ công. Các mô hình như BERT và GPT được huấn luyện bằng các phương pháp tự giám sát như dự đoán token tiếp theo, học cấu trúc và ngữ nghĩa ngôn ngữ. Điều này giảm phụ thuộc vào dữ liệu có nhãn, vốn tốn kém và mất thời gian để thu thập, qua đó cho phép mô hình tận dụng các tập dữ liệu không gán nhãn lớn cho huấn luyện.
Huấn luyện lại một mô hình khổng lồ 70 tỷ tham số là quá đắt đỏ và chậm đối với hầu hết tổ chức. Low-Rank Adaptation (LoRA) giải quyết bằng cách đóng băng trọng số chính của mô hình và chỉ huấn luyện một lớp "adapter" nhỏ (thường dưới 1% tổng tham số) đặt chồng lên. Điều này cho phép bạn phục vụ hàng chục mô hình "tùy biến" khác nhau từ một mô hình nền tảng duy nhất, giảm mạnh chi phí tính toán và nhu cầu lưu trữ.
Dành cho những ai tìm kiếm vai trò cấp cao hơn hoặc muốn thể hiện hiểu biết sâu về AI tạo sinh, hãy khám phá một số câu hỏi phỏng vấn nâng cao.
Mô hình khuếch tán hoạt động chủ yếu bằng cách dần thêm nhiễu vào ảnh cho đến khi chỉ còn nhiễu—và sau đó học cách đảo ngược quá trình này để sinh mẫu mới từ nhiễu. Quá trình này gọi là diffusion. Các mô hình này nổi tiếng nhờ khả năng tạo ảnh chất lượng cao và chi tiết.

Quy trình sinh ảnh qua các bước khuếch tán. (Nguồn: Wikimedia Commons)
Quy trình huấn luyện các mô hình này gồm hai bước:
Khác với GAN cũ thường gặp bất ổn huấn luyện, mô hình khuếch tán ổn định và mở rộng tốt hơn, dù có thể chậm hơn do tính chất lặp.
Các biến thể hiện đại như khuếch tán tiềm ẩn hoạt động trong "không gian tiềm ẩn" nén để tăng tốc sinh, và kiến trúc flow matching hiện đang thay thế khuếch tán chuẩn để đạt hiệu năng tốt hơn nữa.
Kiến trúc transformer được giới thiệu trong bài báo "Attention is All You Need" đã cách mạng hoá lĩnh vực AI tạo sinh, đặc biệt trong xử lý ngôn ngữ tự nhiên (NLP).
Khác với mạng nơ-ron hồi quy (RNN) truyền thống xử lý dữ liệu tuần tự, transformer dùng cơ chế tự chú ý để gán trọng số cho các phần khác nhau của đầu vào đồng thời. Điều này cho phép mô hình nắm bắt quan hệ ngữ cảnh hiệu quả và xử lý song song chuỗi, giúp tăng tốc huấn luyện đáng kể.
Nút thắt chính là cơ chế chú ý này có độ phức tạp tăng theo bình phương độ dài chuỗi—nhân đôi cửa sổ ngữ cảnh đòi hỏi bốn lần tài nguyên tính toán. Điều này khiến "ngữ cảnh vô hạn" về lý thuyết là khả thi nhưng rất tốn kém, thúc đẩy nghiên cứu về phương pháp chú ý hiệu quả hơn.
LLM tiêu chuẩn hoạt động như "Hệ 1": dự đoán từ tiếp theo ngay lập tức dựa trên các mẫu bề mặt.
Mô hình Suy luận (như Gemini 3 hoặc DeepSeek-R1) được huấn luyện để tạo ra một "Chuỗi suy nghĩ" ẩn trước khi đưa ra câu trả lời, cho phép chúng "suy nghĩ", lập kế hoạch và tự sửa lỗi. Điều này giúp chúng vượt trội trong toán phức tạp, lập trình và câu đố logic, dù chậm hơn và tốn chi phí chạy hơn.
Khi tăng độ phức tạp của việc sinh bằng AI, bạn cũng cần giải quyết:
Lĩnh vực GenAI đang phát triển và tái định hình rất nhanh. Bao gồm:
Thiết kế hệ thống dùng AI tạo sinh cho các bài toán theo ngành là một cách tiếp cận toàn diện. Các hướng dẫn chung có thể điều chỉnh và áp dụng sang ngành khác.
Học trong ngữ cảnh là khả năng của LLM điều chỉnh phong cách và đầu ra dựa trên ngữ cảnh được cung cấp mà không cần tinh chỉnh thêm.
Nó cũng có thể được gọi là few-shot learning hoặc kỹ thuật nhắc lệnh. Có thể đạt được bằng cách nêu một hoặc nhiều ví dụ về phản hồi mong muốn hoặc mô tả rõ ràng cách mô hình nên hành xử.
Học trong ngữ cảnh cũng có hạn chế. Nó mang tính ngắn hạn và theo tác vụ, vì mô hình không thực sự giữ lại kiến thức trong các phiên khác khi dùng kỹ thuật này.
Ngoài ra, nếu đầu ra yêu cầu phức tạp, mô hình có thể cần nhiều ví dụ. Nếu ví dụ cung cấp không đủ rõ hoặc tác vụ khó hơn khả năng của mô hình, đôi khi nó có thể sinh đầu ra sai hoặc rời rạc.
Prompt đóng vai trò quan trọng trong việc định hướng LLM phản hồi theo tác vụ cụ thể. Prompt hiệu quả thậm chí có thể giảm nhu cầu tinh chỉnh mô hình bằng cách dùng các kỹ thuật như few-shot learning, phân rã nhiệm vụ và mẫu prompt.
Một số thực hành tốt nhất cho prompt engineering hiệu quả gồm:
Đọc thêm trong blog về Kỹ thuật tối ưu hoá prompt.
Sinh có điều kiện là việc mô hình tạo đầu ra dựa trên các điều kiện hoặc ngữ cảnh nhất định. Điều này cho phép kiểm soát nội dung sinh ra tốt hơn. Trong cGAN, cả bộ sinh và bộ phân biệt đều được điều kiện hoá bởi thông tin bổ sung như nhãn lớp. Cách hoạt động:
Mixture of Experts (MoE) thay thế một mạng dày đặc duy nhất bằng nhiều mạng con "chuyên gia" chuyên biệt. Với mỗi token, một bộ định tuyến chọn chỉ các chuyên gia liên quan nhất để xử lý dữ liệu, nghĩa là một mô hình có thể có 100 tỷ tham số nhưng chỉ dùng 10 tỷ khi suy luận.
Kiến trúc này cho phép mô hình rất thông minh (tổng tham số cao) trong khi vẫn chạy nhanh và rẻ (số tham số hoạt động thấp).
Nếu bạn phỏng vấn cho vai trò kỹ sư AI tập trung vào AI tạo sinh, hãy kỳ vọng các câu hỏi đánh giá khả năng thiết kế, triển khai và đưa mô hình tạo sinh vào vận hành.
Một chatbot tiêu chuẩn mang tính thụ động: nhận truy vấn và đưa ra câu trả lời văn bản dựa trên những gì đã được huấn luyện.
Một quy trình tác nhân trao cho LLM quyền truy cập công cụ (như trình duyệt web, trình thông dịch mã, hoặc API) và khả năng tự chủ để lên kế hoạch quy trình nhiều bước nhằm giải quyết mục tiêu. Tác nhân có thể lên kế hoạch tìm kiếm web, phân tích dữ liệu bằng mã Python, rồi viết báo cáo, lặp lại cho đến khi hoàn tất nhiệm vụ.
Đảm bảo an toàn và độ vững cho LLM đi kèm nhiều thách thức. Thách thức chính gồm khả năng sinh đầu ra gây hại hoặc thiên lệch, vì các mô hình được huấn luyện trên nguồn dữ liệu khổng lồ hoặc thậm chí không lọc và có thể tạo nội dung độc hại hoặc gây hiểu lầm.
Một vấn đề lớn khác với nội dung do LLM tạo là nguy cơ ảo giác, khi mô hình tạo ra nội dung nghe có vẻ rất tự tin nhưng thực ra sai. Thách thức nữa là bảo mật trước các prompt đối kháng phá vỡ biện pháp an toàn của mô hình và tạo ra phản hồi có hại hoặc phi đạo đức, điều đã được chứng minh nhiều lần với các mô hình khác nhau.
Tích hợp các bộ lọc an toàn và lớp kiểm duyệt có thể giúp xác định và loại bỏ nội dung có hại được sinh ra. Giám sát con người liên tục trong vòng lặp càng tăng cường an toàn mô hình.
Ngoài ra, kỹ sư phải triển khai Guardrails rõ ràng (như NeMo Guardrails hoặc Llama Guard) đặt giữa người dùng và mô hình. Các hệ thống này quét đầu vào để chặn tấn công prompt injection hoặc rò rỉ PII (thông tin nhận dạng cá nhân) và quét đầu ra để bắt các phản hồi độc hại hoặc ảo giác trước khi đến tay người dùng. Điều này tạo một lớp an toàn tất định vận hành độc lập với bản chất xác suất của mô hình.
Câu trả lời phụ thuộc vào dự án và trải nghiệm của bạn. Tuy nhiên, bạn có thể lưu ý các điểm sau khi trả lời dạng câu hỏi này:
Tương tự câu trên, câu này có thể trả lời dựa trên kinh nghiệm của bạn, nhưng cũng nên lưu ý:
Ngay cả với cửa sổ ngữ cảnh rất lớn (ví dụ 1 triệu token), LLM thường gặp khó trong việc truy xuất thông tin bị chôn giữa prompt, ưu tiên phần đầu và cuối.
Kỹ sư khắc phục bằng cách dùng thuật toán xếp hạng lại thông minh để di chuyển những đoạn truy xuất quan trọng nhất lên đầu hoặc cuối cửa sổ ngữ cảnh. Chiến lược khác là thuật toán "map-reduce", nơi mô hình tóm tắt từng phần tài liệu dài một cách độc lập trước khi kết hợp cho câu trả lời cuối.
Xây dựng hệ thống RAG đòi hỏi cách tiếp cận có hệ thống. Pipeline có thể như sau:
Câu trả lời cũng phụ thuộc sở thích cá nhân, nhưng đây là vài chủ đề bạn có thể đề cập:
Khi AI tạo sinh ngày càng ảnh hưởng đến nhiều mặt cuộc sống và sự nghiệp của chúng ta, việc giữ tinh thần tò mò với các chủ đề thiết yếu là rất quan trọng. Dù câu hỏi GenAI trong phỏng vấn phụ thuộc vào vai trò và công ty cụ thể, tôi đã cố gắng chọn lọc 30 câu hỏi và đáp án để giúp bạn bắt đầu hành trình chuẩn bị phỏng vấn.
Để khám phá thêm câu hỏi phỏng vấn, tôi gợi ý các blog sau:
Học AI với các khóa học này!
Tracks
Courses
Courses