
Track
AI Fundamentals
10 hr
Let's start with some foundational Generative AI interview questions. These will test your understanding of the core concepts and principles.
Discriminative models learn the decision boundary between classes and patterns that differentiate them. They estimate the probability P(y|x), which is the probability of a particular label y, given the input data x. These models focus on distinguishing between different categories (e.g., 'Is this email spam?').
Generative models learn the distribution of the data itself by modeling the joint probability P(x,y), which involves sampling data points from this distribution. After being trained on thousands of images of digits, this sampling could produce a new image of a digit.
Read more in this blog on Generative vs Discriminative Models: Differences & Use Cases.
Tokens are the fundamental units of text that an LLM processes; they can be whole words, syllables, or even individual letters (for example, the word "generative" might be split into "gener", "at", "ive").
Embeddings are the numerical vector representations of those tokens that place them in a multi-dimensional space based on their meaning. This conversion enables the model to capture semantic meaning and understand relationships between words, for example, recognizing that "king" is close to "queen".
GANs are constructed of two neural networks competing together (hence the word Adversarial): a generator and a discriminator.
The generator creates fake data samples while the discriminator evaluates them against the real training data. The two networks are trained simultaneously:
Through this competitive learning, the generator becomes skilled at producing highly realistic data that is similar to the training data.
The widespread use of GenAI and its use cases requires a thorough evaluation of their performance in terms of ethics. Some examples include:
While the hallucination of AI models could produce faulty outputs, these generative models are helpful in many terms and uses. They can be used as a creative inspiration to the experts in various fields:
A Foundation Model (like GPT-5.2) is trained on massive amounts of broad internet data to learn general patterns, reasoning, and language structure.
A Fine-Tuned model takes this generalist base and trains it further on a smaller, curated dataset to master a specific task, such as medical diagnosis or speaking in a specific coding language. Fine-tuning trades broad versatility for deeper expertise in a specific field.
Now that we've covered the basics, let's explore some intermediate generative AI interview questions.
Just like a content creator who finds a certain format of videos results in more reach and interactions, the generative model of a GAN could likely become fixated on a limited diversity of outputs that deceives the discriminator model. This results in the generator producing a small set of outputs, costing the diversity and flexibility of the generated data.
Possible solutions to this could be focusing on training techniques by adjusting the hyperparameters and various optimization algorithms, applying regularizations that promote diversity, or combining multiple generators to cover different modes of generating data.
A Variational Autoencoder (VAE) is a type of generative model that learns to encode input data into a latent space and decode it back to reconstruct the original input data. VAEs are encoder-decoder models:
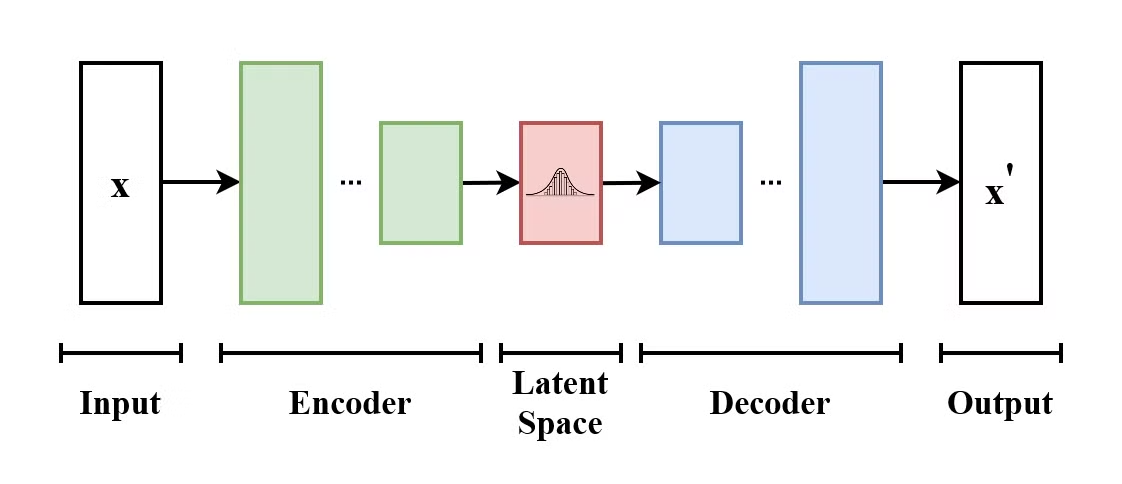
The structure of a Variational Autoencoder. (Source: Wikimedia Commons)
What makes VAEs different from traditional autoencoders, is that VAE encourages the latent space to follow a known distribution (such as Gaussian). This makes them more useful for generating new data by sampling from this latent space.
RAG connects a model to external data sources (like your company wiki) to fetch up-to-date facts without retraining the model. The model's parameters stay the same; it just has access to additional data.
Fine-tuning modifies the model's internal weights to change how it speaks, behaves, or reasons, but it is not good for adding new factual knowledge.
Use RAG when you need up-to-date facts (news, private company data) or a specific citation. Use fine-tuning when you need the model to learn a new "behavior," language, or specific output format (e.g., speaking in SQL code).
Assessing the generated samples is a complex task that depends on the data modality (image, text, video, etc.). Traditional text metrics, such as accuracy, are insufficient for creative tasks because they only check for word overlap, not meaning.
LLM benchmarks and leaderboards use standardized tests to measure how well a model handles a given task. They are helpful to compare models and track progress within or across modalities.
LLM-as-a-Judge is a modern evaluation framework where a highly capable "teacher" model (such as Gemini 3) grades the outputs of a smaller model based on specific criteria, including faithfulness, helpfulness, and tone. This provides a scalable way to approximate human preference without the slowness and cost of manual human review.
Improving the stability and convergence of GAN training is important for avoiding mode collapse, ensuring efficient training, and achieving good results. Here are some techniques to improve the stability and convergence of GAN training:
There are several common techniques to control the style of the GenAI outputs:
Ensuring the model is unbiased and fair requires iterative adjustments and monitoring through each phase.
First, data contamination needs to be prevented by making sure that no test data leaks into training data. In that case, the model would be trained to memorize the data rather than to generalize from it.
Further, we have to ensure the training data is as diverse and inclusive as possible. During training, we can guide the model towards a fairer generation by incorporating fairness objectives into the loss function.
The model outputs must be regularly monitored for bias. To build public trust, it helps to make the model’s decision-making process, dataset details, and the preprocessing steps as transparent as possible.
In the context of Generative models, latent space is a lower-dimensional space that captures the essential features of the data in a way that similar inputs are mapped closer to each other. Sampling from this latent space allows the models to generate new data and manipulate specific attributes or features (generating variations of images).
Latent spaces are key to generating outputs that are controllable, true to the training data, and diverse.
The key idea behind self-supervised learning is to leverage a vast corpus of unlabeled data to learn useful representations without the need for manual labeling. Models such as BERT and GPT are trained by self-supervised methods such as next-token prediction, and learning the structure and the semantics of languages. This reduces the reliance on labeled data, which is costly and time-consuming to obtain, essentially allowing models to leverage vast unlabeled datasets for training.
Retraining a massive 70-billion parameter model is prohibitively expensive and slow for most organizations. Low-Rank Adaptation (LoRA) solves this by freezing the main model weights and only training a tiny "adapter" layer (often less than 1% of the total parameters) that sits on top. This allows you to serve dozens of different "custom" models from a single base model, drastically reducing computational cost and storage needs.
For those seeking more senior roles or aiming to showcase a deep understanding of Generative AI, let's explore some advanced interview questions.
Diffusion Models work primarily by gradually adding noise to an image until only noise remains—and then learning how to reverse this process to generate new samples from noise. This process is called diffusion. These models have gained popularity for their ability to output high-quality and highly detailed images.

Generation of an image through diffusion steps. (Source: Wikimedia Commons)
The process of training these models includes two steps:
Unlike older GANs, which often suffered from training instability, diffusion models are more stable and scalable, though they can be slower due to their iterative nature.
Modern variants like latent diffusion operate in a compressed "latent space" to speed up generation, and flow matching architectures are now replacing standard diffusion for even better performance.
The transformer architecture introduced in the paper “Attention is All You Need”, has revolutionized the field of generative AI, particularly in natural language processing (NLP).
Unlike traditional recurrent neural networks (RNNs), which process data in a sequential manner, transformers use the self-attention mechanism to attribute weights to different parts of the input data simultaneously. This enables the model to capture contextual relationships effectively and allows for parallel processing of sequences, which significantly speeds up training.
The main bottleneck is that this attention mechanism scales quadratically with sequence length—doubling the context window requires four times the compute. This makes "infinite context" theoretically possible but computationally expensive, driving research into more efficient attention methods.
Standard LLMs act as "System 1" thinkers, predicting the next word immediately based on surface-level patterns.
Reasoning Models (like Gemini 3 or DeepSeek-R1) are trained to generate a hidden "Chain of Thought" before outputting an answer, allowing them to "think," plan, and self-correct mistakes. This makes them significantly better at complex math, coding, and logic puzzles, though they are slower and more expensive to run.
As you increase the complexity of AI generation, you should also tackle:
The field of GenAI is evolving and reshaping at a fast pace. This includes:
Designing a system that uses generative AI for industry-specific use cases is a thorough approach. The general guidelines can be adjusted and modified across other industries as well.
In-context learning refers to the ability of LLMs to modify their style and outputs based on the provided context without the need for additional fine-tuning.
It could also be referred to as few-shot learning or prompt engineering. This could be achieved by specifying one or many examples of the desired response or by clearly describing how the model should behave.
In-context learning also comes with its limitations. It is short-term and task-specific, as the model does not really retain any knowledge in other sessions of using this technique.
Additionally, if the required output is complex, the model might need a large number of examples. If the provided examples are not clear enough or the task is more difficult than what the model can handle, it can sometimes generate incorrect or incoherent outputs.
Prompting is important in directing LLMs to respond to specific tasks. Effective prompts can even mitigate the need for fine-tuning models by using techniques such as few-shot learning, task decomposition, and prompt templates.
Some best practices for effective, prompt engineering include:
Read more in this blog on Prompt Optimization Techniques.
Conditional Generation involves the model generating outputs based on certain conditions or contexts. This allows more control over the generated content. In Conditional GANs (cGANs), both the generator and discriminator are conditioned on additional information, such as class labels. Here's how it works:
Mixture of Experts (MoE) replaces a single dense neural network with many specialized "expert" sub-networks. For any given token, a router selects only the most relevant experts to process the data, meaning a model might have 100 billion parameters but only use 10 billion for inference.
This architecture allows models to be incredibly smart (high total parameter count) while remaining fast and cheap to run (low active parameter count).
If you're interviewing for an AI engineering role with a focus on generative AI, expect questions that assess your ability to design, implement, and deploy generative models.
A standard chatbot is passive: it receives a query and outputs a text answer based on its training.
An agentic workflow gives the LLM access to tools (like a web browser, code interpreter, or API) and the autonomy to plan a multi-step process to solve a goal. The agent might plan to search the web, analyze the data with Python code, and then write a report, looping until the task is complete.
Ensuring the safety and robustness of LLMs comes with several challenges. A primary challenge includes the potential of generating outputs that are harmful or biased, as these models are trained on vast or even unfiltered data sources and may produce toxic or misleading content.
Another major issue with LLM-generated content is the danger of hallucination, where the model generates confidently sounding content that is, in fact, incorrect information. Another challenge is the security against adversarial prompts that violate the model’s safety measures and produce harmful or unethical responses, as has been proven many times regarding various models.
Incorporating safety filters and moderation layers can help identify and remove harmful content that is being generated. Ongoing human-in-the-loop oversight further enhances model safety.
In addition to that, engineers must implement explicit Guardrails (like NeMo Guardrails or Llama Guard) that sit between the user and the model. These systems scan inputs to block prompt injection attempts or PII (Personally Identifiable Information) leakage and scan outputs to catch toxic or hallucinatory responses before they reach the user. This creates a deterministic safety layer that operates independently of the model’s probabilistic nature.
Answering this question is really subjective to your projects and experiences. You can, however, keep these points in mind when answering questions like this:
Just as the question above, this question can be answered based on your experience, but by also keeping in mind to:
Even with massive context windows (e.g., 1 million tokens), LLMs often struggle to retrieve information buried in the middle of the prompt, prioritizing the start and end.
Engineers mitigate this by using intelligent re-ranking algorithms that move the most critical retrieved chunks to the beginning or end of the context window. Another strategy is the "map-reduce" algorithm, where the model summarizes sections of the long document independently before combining them for a final answer.
Building a RAG system requires a systematic approach. Here's how the pipeline could look:
The answer depends here as well on your personal preferences, but here are some topics you can mention:
As Generative AI is finding ways to influence various aspects of our lives and careers, it is vital to keep a curious eye on the essential topics. While the potential GenAI questions that can be asked during an interview depend on the specific role and company, I have tried to sample 30 questions and answers to help you get started on your interview prep journey.
To explore more interview questions, I recommend these blogs:
Learn AI with these courses!
Track
Course
Course
blog
Vinod Chugani
15 min
blog
Ryan Ong
15 min
blog
Stanislav Karzhev
15 min
blog
Abid Ali Awan
15 min
blog
Dimitri Didmanidze
15 min
blog
Don Kaluarachchi
14 min



