
Leerpad
AI-basisprincipes
10 Hr
Laten we beginnen met een paar fundamentele interviewvragen over generatieve AI. Deze toetsen je begrip van de kernconcepten en -principes.
Discriminatieve modellen leren de beslissingsgrens tussen klassen en patronen die ze van elkaar onderscheiden. Ze schatten de waarschijnlijkheid P(y|x), de kans op een bepaald label y gegeven de inputdata x. Deze modellen focussen op het onderscheiden van verschillende categorieën (bijv. ‘Is deze e-mail spam?’).
Generatieve modellen leren de verdeling van de data zelf door de gezamenlijke waarschijnlijkheid te modelleren P(x,y), wat inhoudt dat ze datapuntjes uit deze verdeling samplen. Na training op duizenden afbeeldingen van cijfers kan dit samplen een nieuwe afbeelding van een cijfer opleveren.
Lees meer in deze blog over Generative vs Discriminative Models: Differences & Use Cases.
Tokens zijn de fundamentele teksteenheden die een LLM verwerkt; het kunnen hele woorden, lettergrepen of zelfs individuele letters zijn (bijvoorbeeld, het woord "generative" kan worden opgesplitst in "gener", "at", "ive").
Embeddings zijn de numerieke vectorrepresentaties van die tokens die ze plaatsen in een multidimensionale ruimte op basis van hun betekenis. Deze conversie stelt het model in staat semantische betekenis te vangen en relaties tussen woorden te begrijpen, bijvoorbeeld herkennen dat "king" dicht bij "queen" ligt.
GAN’s bestaan uit twee concurrerende neurale netwerken (vandaar Adversarial): een generator en een discriminator.
De generator maakt valse datasamples, terwijl de discriminator ze vergelijkt met de echte trainingsdata. De twee netwerken worden gelijktijdig getraind:
Door dit competitieve leerproces wordt de generator vaardig in het produceren van zeer realistische data die lijkt op de trainingsdata.
Het brede gebruik van GenAI en de toepassingen ervan vraagt om een grondige evaluatie van de prestaties op het gebied van ethiek. Voorbeelden zijn onder meer:
Hoewel hallucinaties van AI-modellen foutieve output kunnen opleveren, zijn deze generatieve modellen in veel opzichten nuttig. Ze kunnen dienen als creatieve inspiratie voor experts in uiteenlopende domeinen:
Een Foundation Model (zoals GPT-5.2) is getraind op enorme hoeveelheden brede internetdata om algemene patronen, redeneren en taalstructuur te leren.
Een fijn-afgesteld model neemt deze generalistische basis en traint verder op een kleinere, samengestelde dataset om een specifieke taak te beheersen, zoals medische diagnose of spreken in een specifieke programmeertaal. Fine-tuning ruilt brede veelzijdigheid in voor diepere expertise in een specifiek domein.
Nu we de basis hebben behandeld, gaan we verder met enkele intermediate interviewvragen over generatieve AI.
Net zoals een contentmaker kan ontdekken dat een bepaalde videoformule meer bereik en interactie oplevert, kan de generator in een GAN gefixeerd raken op een beperkte variatie aan outputs die de discriminator misleidt. Daardoor produceert de generator een kleine set outputs, ten koste van de diversiteit en flexibiliteit van de gegenereerde data.
Mogelijke oplossingen zijn het verfijnen van trainingstechnieken door hyperparameters en optimalisatie-algoritmen aan te passen, regularisaties toe te passen die diversiteit bevorderen, of meerdere generators te combineren om verschillende modi van datageneratie te dekken.
Een Variational Autoencoder (VAE) is een type generatief model dat leert om inputdata te encoderen naar een latente ruimte en deze weer te decoderen om de originele input te reconstrueren. VAE’s zijn encoder-decoder-modellen:
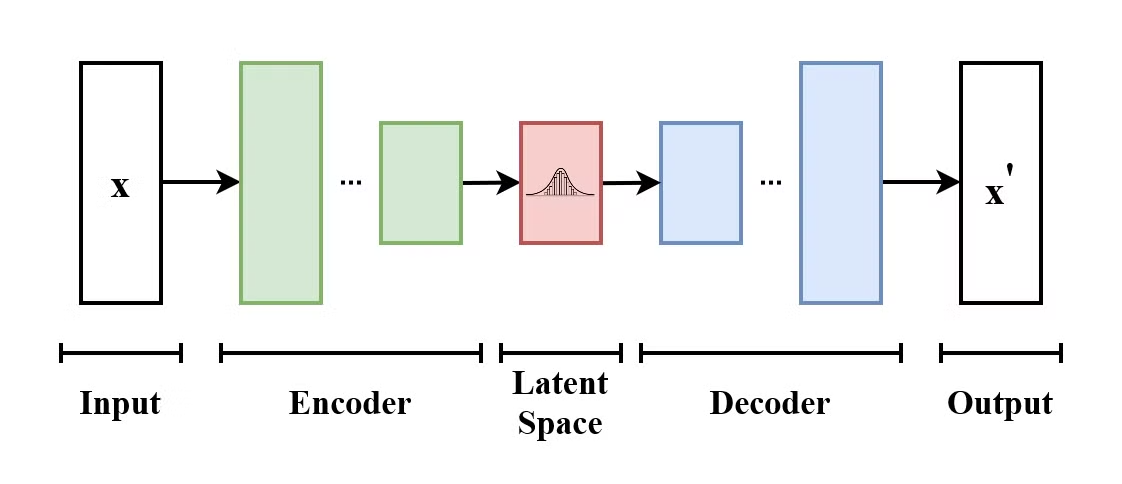
De structuur van een Variational Autoencoder. (Bron: Wikimedia Commons)
Wat VAE’s onderscheidt van traditionele autoencoders is dat een VAE de latente ruimte stimuleert om een bekende verdeling (zoals Gaussisch) te volgen. Dit maakt ze geschikter voor het genereren van nieuwe data door te samplen uit deze latente ruimte.
RAG verbindt een model met externe databronnen (zoals de wiki van je bedrijf) om actuele feiten op te halen zonder het model te hertrainen. De parameters van het model blijven hetzelfde; het krijgt alleen toegang tot extra data.
Fine-tuning past de interne gewichten van het model aan om te veranderen hoe het spreekt, zich gedraagt of redeneert, maar is niet geschikt om nieuwe feitelijke kennis toe te voegen.
Gebruik RAG wanneer je actuele feiten nodig hebt (nieuws, private bedrijfsdata) of een specifieke bronvermelding. Gebruik fine-tuning wanneer je wilt dat het model een nieuw "gedrag", een taal of een specifiek outputformaat leert (bijv. spreken in SQL-code).
Het beoordelen van gegenereerde samples is complex en hangt af van de datamodaliteit (beeld, tekst, video, enz.). Traditionele tekst-metrics, zoals nauwkeurigheid, zijn onvoldoende voor creatieve taken omdat ze alleen woordoverlap checken, niet de betekenis.
LLM-benchmarks en leaderboards gebruiken gestandaardiseerde tests om te meten hoe goed een model een bepaalde taak aan kan. Ze zijn nuttig om modellen te vergelijken en voortgang te volgen binnen of over modaliteiten heen.
LLM-as-a-Judge is een modern evaluatiekader waarbij een zeer capabel "leraren"-model (zoals Gemini 3) de output van een kleiner model beoordeelt op specifieke criteria, waaronder betrouwbaarheid, behulpzaamheid en toon. Dit biedt een schaalbare manier om menselijke voorkeur te benaderen zonder de traagheid en kosten van handmatige beoordeling.
Het verbeteren van stabiliteit en convergentie bij GAN-training is belangrijk om mode collapse te voorkomen, efficiënt te trainen en goede resultaten te behalen. Enkele technieken:
Er zijn verschillende veelgebruikte technieken om de stijl van GenAI-outputs te sturen:
Zorgen dat het model onbevooroordeeld en eerlijk is, vereist iteratieve aanpassing en monitoring in elke fase.
Allereerst moet datacontaminatie worden voorkomen door ervoor te zorgen dat geen testdata in de trainingsdata terechtkomt. Anders leert het model de data te memoriseren in plaats van te generaliseren.
Verder moet de trainingsdata zo divers en inclusief mogelijk zijn. Tijdens training kunnen we het model richting eerlijkere generatie sturen door fairness-doelstellingen in de verliesfunctie op te nemen.
De modeluitvoer moet regelmatig op bias worden gemonitord. Om publiek vertrouwen op te bouwen helpt het om het beslissingsproces van het model, details over de dataset en de preprocess-stappen zo transparant mogelijk te maken.
In de context van generatieve modellen is de latente ruimte een lager-dimensionale ruimte die de essentiële kenmerken van de data vastlegt, zodanig dat vergelijkbare inputs dichter bij elkaar worden geprojecteerd. Samplen uit deze latente ruimte stelt modellen in staat nieuwe data te genereren en specifieke attributen of kenmerken te manipuleren (variaties van afbeeldingen genereren).
Latente ruimten zijn cruciaal om outputs te genereren die stuurbaar, trouw aan de trainingsdata en divers zijn.
Het kernidee van self-supervised learning is een enorme hoeveelheid ongestructureerde, ongelabelde data benutten om bruikbare representaties te leren zonder handmatige labeling. Modellen zoals BERT en GPT worden getraind met self-supervised methoden zoals next-token prediction en het leren van structuur en semantiek van talen. Dit vermindert de afhankelijkheid van gelabelde data, die kostbaar en tijdrovend is, en stelt modellen in staat om enorme ongelabelde datasets te benutten voor training.
Het hertrainen van een massaal model met 70 miljard parameters is voor de meeste organisaties prohibitief duur en traag. Low-Rank Adaptation (LoRA) lost dit op door de hoofdgewichten van het model te bevriezen en alleen een piepkleine "adapter"-laag te trainen (vaak minder dan 1% van het totale aantal parameters) die erbovenop zit. Zo kun je tientallen verschillende "aangepaste" modellen serveren vanuit één basismodel, wat de rekenkosten en opslagbehoefte drastisch verlaagt.
Voor wie op zoek is naar seniorrollen of een diep begrip van generatieve AI wil tonen, volgen hier enkele geavanceerde vragen.
Diffusiemodellen werken voornamelijk door geleidelijk ruis toe te voegen aan een afbeelding totdat alleen ruis overblijft—en vervolgens te leren hoe je dit proces omkeert om nieuwe samples uit ruis te genereren. Dit proces heet diffusie. Deze modellen zijn populair vanwege hun vermogen om afbeeldingen van hoge kwaliteit en met veel detail te produceren.

Generatie van een afbeelding via diffusie-stappen. (Bron: Wikimedia Commons)
Het trainen van deze modellen omvat twee stappen:
In tegenstelling tot oudere GAN’s, die vaak kampten met instabiele training, zijn diffusiemodellen stabieler en schaalbaarder, al kunnen ze door hun iteratieve aard trager zijn.
Moderne varianten zoals latente diffusie werken in een gecomprimeerde "latente ruimte" om de generatie te versnellen, en flow matching-architecturen vervangen nu standaarddiffusie voor nog betere prestaties.
De Transformer-architectuur, geïntroduceerd in de paper “Attention is All You Need”, heeft het veld van generatieve AI revolutionair veranderd, vooral in natural language processing (NLP).
In tegenstelling tot traditionele recurrente neurale netwerken (RNN’s), die data sequentieel verwerken, gebruiken Transformers self-attention om gewichten toe te kennen aan verschillende delen van de inputdata tegelijk. Dit stelt het model in staat contextuele relaties effectief vast te leggen en maakt parallelle verwerking van sequenties mogelijk, wat de training aanzienlijk versnelt.
De grootste bottleneck is dat dit aandachtmechanisme kwadratisch schaalt met de sequentielengte—het verdubbelen van de contextwindow vereist vier keer zoveel compute. Daardoor is “oneindige context” theoretisch mogelijk maar computationeel kostbaar, wat onderzoek aanjaagt naar efficiëntere attention-methoden.
Standaard LLM’s handelen als "System 1"-denkers: ze voorspellen direct het volgende woord op basis van oppervlakkige patronen.
Reasoning-modellen (zoals Gemini 3 of DeepSeek-R1) zijn getraind om een verborgen "Chain of Thought" te genereren voordat ze een antwoord geven, waardoor ze kunnen "denken", plannen en fouten zelf corrigeren. Hierdoor presteren ze aanzienlijk beter bij complexe wiskunde, coderen en logische puzzels, al zijn ze trager en duurder in gebruik.
Naarmate je de complexiteit van AI-generatie opvoert, moet je ook het volgende aanpakken:
Het GenAI-veld evolueert en verandert razendsnel. Dit omvat:
Het ontwerpen van een systeem dat generatieve AI gebruikt voor sectorspecifieke use-cases vergt een grondige aanpak. De algemene richtlijnen kunnen ook voor andere sectoren worden aangepast.
In-context learning verwijst naar het vermogen van LLM’s om hun stijl en output aan te passen op basis van de gegeven context zonder extra fine-tuning.
Het kan ook worden aangeduid als few-shot learning of prompt engineering. Dit kan door één of meerdere voorbeelden van de gewenste respons te geven of door duidelijk te beschrijven hoe het model zich moet gedragen.
In-context learning heeft ook beperkingen. Het is kortstondig en taakgebonden, omdat het model geen kennis behoudt in andere sessies van deze techniek.
Bovendien kan het model bij complexe vereiste output veel voorbeelden nodig hebben. Als de voorbeelden niet duidelijk genoeg zijn of de taak moeilijker is dan wat het model aankan, kan het soms onjuiste of inconsistente output genereren.
Prompting is belangrijk om LLM’s te sturen naar specifieke taken. Effectieve prompts kunnen de noodzaak van fine-tuning verminderen met technieken zoals few-shot learning, taakdecompositie en prompttemplates.
Enkele best practices voor effectieve prompt engineering:
Lees meer in deze blog over Prompt Optimization Techniques.
Conditionele generatie houdt in dat het model output genereert op basis van bepaalde voorwaarden of context. Dit biedt meer controle over de gegenereerde content. In cGAN’s worden zowel de generator als de discriminator geconditioneerd op extra informatie, zoals klasselabels. Zo werkt het:
Mixture of Experts (MoE) vervangt één dicht neuraal netwerk door veel gespecialiseerde "expert"-subnetwerken. Voor een gegeven token selecteert een router alleen de meest relevante experts om de data te verwerken, waardoor een model 100 miljard parameters kan hebben maar er voor inferentie slechts 10 miljard actief gebruikt.
Deze architectuur maakt modellen extreem slim (hoog totaal aantal parameters) terwijl ze snel en goedkoop blijven draaien (laag actief aantal parameters).
Als je solliciteert naar een AI-engineeringrol met focus op generatieve AI, kun je vragen verwachten die je vermogen toetsen om generatieve modellen te ontwerpen, implementeren en uit te rollen.
Een standaard chatbot is passief: hij ontvangt een vraag en geeft een tekstantwoord op basis van zijn training.
Een agentische workflow geeft de LLM toegang tot tools (zoals een webbrowser, code-interpreter of API) en de autonomie om een meerstappenplan te maken om een doel op te lossen. De agent kan plannen om het web te doorzoeken, de data met Python-code te analyseren en vervolgens een rapport te schrijven, en dit herhalen tot de taak voltooid is.
Het waarborgen van de veiligheid en robuustheid van LLM’s brengt verschillende uitdagingen met zich mee. Een primaire uitdaging is de potentiële generatie van schadelijke of bevooroordeelde output, aangezien deze modellen zijn getraind op enorme of zelfs ongefilterde databronnen en toxische of misleidende content kunnen produceren.
Een ander groot probleem met LLM-output is het gevaar van hallucinatie, waarbij het model zelfverzekerd klinkende content genereert die feitelijk onjuist is. Ook de beveiliging tegen adversarial prompts die de veiligheidsmaatregelen omzeilen en schadelijke of onethische reacties uitlokken, is een uitdaging, zoals herhaaldelijk is aangetoond bij diverse modellen.
Het opnemen van veiligheidsfilters en moderatielagen kan helpen om schadelijke content in de kiem te smoren. Voortdurende human-in-the-loop-toezicht verhoogt de veiligheid verder.
Daarnaast moeten engineers expliciete Guardrails (zoals NeMo Guardrails of Llama Guard) implementeren die tussen de gebruiker en het model in zitten. Deze systemen scannen input om prompt injection-pogingen of PII-lekken (Persoonlijk Identificeerbare Informatie) te blokkeren en scannen output om toxische of hallucinatoire reacties te onderscheppen voordat ze de gebruiker bereiken. Zo ontstaat een deterministische veiligheidslaag die onafhankelijk werkt van de probabilistische aard van het model.
Het antwoord op deze vraag is sterk afhankelijk van je projecten en ervaring. Je kunt echter deze punten in gedachten houden bij het antwoorden:
Net als de vraag hierboven kun je dit beantwoorden op basis van je ervaring, maar houd ook rekening met het volgende:
Zelfs met enorme contextvensters (bijv. 1 miljoen tokens) hebben LLM’s vaak moeite om informatie in het midden van de prompt terug te vinden; ze geven prioriteit aan het begin en einde.
Engineers mitigeren dit met slimme re-ranking-algoritmen die de belangrijkste teruggehaalde stukken naar het begin of het einde van het contextvenster verplaatsen. Een andere strategie is het "map-reduce"-algoritme, waarbij het model secties van het lange document afzonderlijk samenvat voordat ze worden gecombineerd tot een eindantwoord.
Het bouwen van een RAG-systeem vereist een systematische aanpak. Zo kan de pijplijn eruitzien:
Het antwoord hangt ook hier af van je persoonlijke voorkeuren, maar dit zijn onderwerpen die je kunt noemen:
Nu generatieve AI allerlei aspecten van ons leven en werk beïnvloedt, is het essentieel om nieuwsgierig te blijven naar de kernonderwerpen. Hoewel de mogelijke GenAI-vragen tijdens een interview afhangen van de specifieke rol en het bedrijf, heb ik 30 vragen en antwoorden verzameld om je op weg te helpen met je voorbereidingen.
Voor meer interviewvragen raad ik deze blogs aan:
Leer AI met deze cursussen!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
