
Cursus
Principes fondamentaux de l'IA
10 h
Commençons par quelques questions fondamentales relatives à l'intelligence artificielle générative. Ces exercices évalueront votre compréhension des concepts et principes fondamentaux.
Les modèles discriminatifs apprennent la frontière de décision entre les classes et les modèles qui les différencient. Ils estiment la probabilité P(y|x), qui est la probabilité d'une étiquette particulière y, étant donné les données d'entrée x. Ces modèles se concentrent sur la distinction entre différentes catégories (par exemple, «Ce courriel est-il un spam ? »).
Les modèles génératifs apprennent la distribution des données elles-mêmes en modélisant la probabilité conjointe P(x,y), ce qui implique l'échantillonnage de points de données à partir de cette distribution. Après avoir été entraîné sur des milliers d'images de chiffres, cet échantillonnage pourrait générer une nouvelle image d'un chiffre.
Pour en savoir plus, veuillez consulter ce blog sur Modèles génératifs vs modèles discriminatifs : Différences et cas d'utilisation.
Les tokens sont les unités fondamentales de texte traitées par un LLM ; il peut s'agir de mots entiers, de syllabes ou même de lettres individuelles (par exemple, le mot « generative » peut être divisé en « gener », « at » et « ive »).
Les encastrements sont les représentations vectorielles numériques de ces jetons qui les placent dans un espace multidimensionnel en fonction de leur signification. Cette conversion permet au modèle de saisir le sens sémantique et de comprendre les relations entre les mots, par exemple en reconnaissant que « roi » est proche de « reine ».
Les GAN sont constitués de deux réseaux neuronaux en concurrence (d'où le terme « adversaires ») : un générateur et un discriminateur.
Le générateur crée de faux échantillons de données tandis que le discriminateur les évalue par rapport aux données d'apprentissage réelles. Les deux réseaux sont entraînés simultanément :
Grâce à cet apprentissage compétitif, le générateur acquiert la capacité de produire des données hautement réalistes, similaires aux données d'entraînement.
L'utilisation généralisée de l'IA générative et ses cas d'application nécessitent une évaluation approfondie de leurs performances en termes d'éthique. éthique. Voici quelques exemples :
Bien que les hallucinations des modèles d'IA puissent produire des résultats erronés, ces modèles génératifs sont utiles à bien des égards et dans de nombreuses applications. Ils peuvent servir de source d'inspiration créative aux experts dans divers domaines :
Un modèle de base (tel que GPT-5.2) est formé à partir d'une quantité considérable de données Internet afin d'apprendre les schémas généraux, le raisonnement et la structure du langage.
Un modèle affiné utilise cette base généraliste et la perfectionne à partir d'un ensemble de données plus restreint et sélectionné avec soin afin de maîtriser une tâche spécifique, telle que le diagnostic médical ou l'utilisation d'un langage de programmation particulier. Le perfectionnement privilégie une expertise approfondie dans un domaine spécifique plutôt qu'une grande polyvalence.
Maintenant que nous avons abordé les notions de base, examinons quelques questions d'entretien intermédiaires sur l'IA générative.
Tout comme un créateur de contenu qui constate qu'un certain format de vidéos génère davantage de portée et d'interactions, le modèle génératif d'un GAN pourrait se focaliser sur une diversité limitée de résultats qui trompent le modèle discriminateur. Il en résulte que le générateur produit un ensemble restreint de sorties, au détriment de la diversité et de la flexibilité des données générées.
Les solutions possibles à ce problème pourraient consister à se concentrer sur les techniques d'entraînement en ajustant les hyperparamètres et divers algorithmes d'optimisation, à appliquer des régularisations qui favorisent la diversité ou à combiner plusieurs générateurs pour couvrir différents modes de génération de données.
Un auto-encodeur variationnel (VAE) est un type de modèle génératif qui apprend à encoder les données d'entrée dans un espace latent et à les décoder pour reconstruire les données d'entrée d'origine. Les VAE sont des modèles encodeurs-décodeurs :
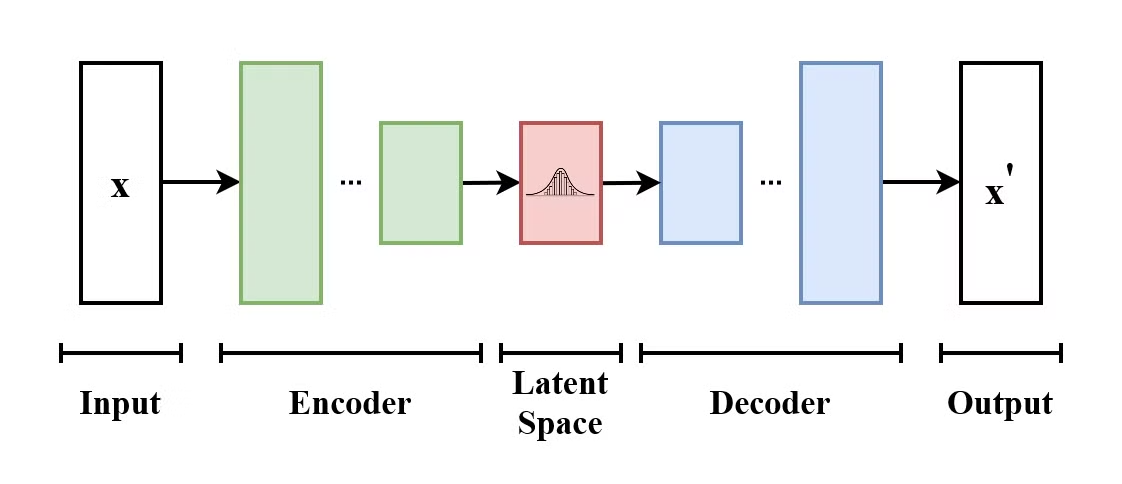
La structure d'un auto-encodeur variationnel. (Source : Wikimedia Commons)
Ce qui différencie les VAE des auto-encodeurs traditionnels, c'est que les VAE encouragent l'espace latent à suivre une distribution connue (telle que la distribution gaussienne). Cela les rend plus efficaces pour générer de nouvelles données en échantillonnant à partir de cet espace latent.
L' RAG connecte un modèle à des sources de données externes (telles que le wiki de votre entreprise) afin de récupérer des informations actualisées sans avoir à réentraîner le modèle. Les paramètres du modèle restent inchangés ; il a simplement accès à des données supplémentaires.
Le réglage fin modifie les pondérations internes du modèle afin de changer sa façon de s'exprimer, de se comporter ou de raisonner, mais il n'est pas adapté à l'ajout de nouvelles connaissances factuelles.
Veuillez utiliser RAG lorsque vous avez besoin d'informations actualisées (actualités, données d'entreprises privées) ou d'une citation spécifique. Utilisez le réglage fin lorsque vous souhaitez que le modèle apprenne un nouveau « comportement », un nouveau langage ou un format de sortie spécifique (par exemple, parler en code SQL).
L'évaluation des échantillons générés est une tâche complexe qui dépend de la modalité des données (image, texte, vidéo, etc.). e texte traditionnel Les mesures, telles que la précision, sont insuffisantes pour les tâches créatives, car elles ne vérifient que le chevauchement des mots, et non le sens.
Les benchmarks et classements LLM utilisent des tests standardisés pour évaluer la capacité d'un modèle à accomplir une tâche donnée. Ils sont utiles pour comparer les modèles et suivre le cursus au sein d'une même modalité ou entre différentes modalités.
LLM-as-a-Judge est un cadre d'évaluation moderne dans lequel un modèle « enseignant » hautement performant (tel que Gemini 3) évalue les résultats d'un modèle plus petit en fonction de critères spécifiques, notamment la fidélité, l'utilité et le ton. Cela offre un moyen évolutif d'évaluer les préférences humaines sans la lenteur et le coût d'un examen manuel par des personnes.
Il est essentiel d'améliorer la stabilité et la convergence de l'entraînement des GAN afin d'éviter l'effondrement des modes, de garantir un entraînement efficace et d'obtenir de bons résultats. Voici quelques techniques permettant d'améliorer la stabilité et la convergence de l'entraînement des GAN :
Il existe plusieurs techniques courantes pour contrôler le style des sorties GenAI :
Pour garantir l'impartialité et l'équité du modèle, il est nécessaire de procéder à des ajustements itératifs et à un suivi à chaque étape.
Tout d'abord, il est nécessaire de prévenir la contamination des données en s'assurant qu'aucune donnée de test ne se retrouve dans les données d'entraînement. Dans ce cas, le modèle serait formé pour mémoriser les données plutôt que pour les généraliser.
De plus, nous devons veiller à ce que les données d'entraînement soient aussi variées et inclusives que possible. Au cours de l'entraînement, nous pouvons orienter le modèle vers une génération plus équitable en intégrant des objectifs d'équité dans la fonction de perte.
Les résultats du modèle doivent être régulièrement contrôlés afin de détecter tout biais. Afin de renforcer la confiance du public, il est utile de rendre le processus décisionnel du modèle, les détails de l'ensemble de données et les étapes de prétraitement aussi transparents que possible.
Dans le contexte des modèles génératifs, l'espace latent est un espace de dimension inférieure qui capture les caractéristiques essentielles des données de manière à ce que les entrées similaires soient rapprochées les unes des autres. L'échantillonnage à partir de cet espace latent permet aux modèles de générer de nouvelles données et de manipuler des attributs ou des caractéristiques spécifiques (générant des variations d'images).
Les espaces latents sont essentiels pour générer des résultats contrôlables, fidèles aux données d'entraînement et diversifiés.
L'idée principale derrière l'apprentissage auto-supervisé est d'exploiter un vaste corpus de données non étiquetées pour apprendre des représentations utiles sans avoir besoin d'un étiquetage manuel. Les modèles tels que BERT et GPT sont entraînés à l'aide de méthodes auto-supervisées telles que la prédiction du prochain token et l'apprentissage de la structure et de la sémantique des langues. Cela réduit la dépendance vis-à-vis des données étiquetées, dont l'obtention est coûteuse et prend beaucoup de temps, permettant ainsi aux modèles d'exploiter de vastes ensembles de données non étiquetées pour l'entraînement.
La formation d'un modèle volumineux de 70 milliards de paramètres est extrêmement coûteuse et lente pour la plupart des organisations. L'adaptation de rang faible (LoRA) résout ce problème en gelant les poids du modèle principal et en ne formant qu'une minuscule couche « adaptatrice » (souvent moins de 1 % du total des paramètres) qui se trouve au-dessus. Cela vous permet de proposer plusieurs modèles « personnalisés » à partir d'un seul modèle de base, ce qui réduit considérablement les coûts de calcul et les besoins de stockage.
Pour ceux qui recherchent des postes plus élevés ou qui souhaitent démontrer une compréhension approfondie de l'IA générative, nous allons examiner quelques questions d'entretien avancées.
Les modèles de diffusion fonctionnent principalement en ajoutant progressivement du bruit à une image jusqu'à ce qu'il ne reste plus que du bruit, puis en apprenant à inverser ce processus pour générer de nouveaux échantillons à partir du bruit. Ce processus est appelédiffusion d' .. Ces modèles ont acquis une grande popularité grâce à leur capacité à produire des images de haute qualité et très détaillées.

Génération d'une image par étapes de diffusion. (Source : Wikimedia Commons)
Le processus d'entraînement de ces modèles comprend deux étapes :
Contrairement aux anciens GAN, qui souffraient souvent d'instabilité lors de l'entraînement, les modèles de diffusion sont plus stables et évolutifs, bien qu'ils puissent être plus lents en raison de leur nature itérative.
Les variantes modernes telles que la diffusion latente fonctionnent dans un « espace latent » compressé afin d'accélérer la génération, et les architectures de correspondance de flux remplacent désormais la diffusion standard pour des performances encore meilleures.
L'architecture du architecture du transformateur présentée dans l'article « Attention is All You Need »a révolutionné le domaine de l'IA générative, en particulier dans le traitement du langage naturel (NLP).
Contrairement aux réseaux neuronaux récurrents (RNN) traditionnels, qui traitent les données de manière séquentielle, les transformateurs utilisent le mécanisme d'auto-attention pour attribuer simultanément des poids à différentes parties des données d'entrée. Cela permet au modèle de saisir efficacement les relations contextuelles et autorise le traitement parallèle des séquences, ce qui accélère considérablement l'apprentissage.
Le principal obstacle réside dans le fait que ce mécanisme d'attention évolue de manière quadratique avec la longueur de la séquence : doubler la fenêtre contextuelle nécessite quatre fois plus de puissance de calcul. Cela rend le « contexte infini » théoriquement possible, mais coûteux en termes de calcul, ce qui stimule la recherche vers des méthodes d'attention plus efficaces.
Les LLM standard fonctionnent comme des penseurs de « type 1 », prédisant immédiatement le mot suivant en se basant sur des modèles superficiels.
Les modèles de raisonnement (tels que Gemini 3 ou DeepSeek-R1) sont formés pour générer une « chaîne de pensée » cachée avant de fournir une réponse, ce qui leur permet de « réfléchir », de planifier et de corriger eux-mêmes leurs erreurs. Cela les rend nettement plus performants pour les calculs mathématiques complexes, le codage et les casse-têtes logiques, bien qu'ils soient plus lents et plus coûteux à exploiter.
À mesure que vous augmentez la complexité de la génération d'IA, vous devriez également vous attaquer aux aspects suivants :
Le domaine de l'IA générative évolue et se transforme à un rythme soutenu. Cela comprend :
La conception d'un système utilisant l'IA générative pour des cas d'utilisation spécifiques à l'industrie constitue une approche approfondie. Les directives générales peuvent également être adaptées et modifiées pour d'autres secteurs.
L'apprentissage contextuel fait référence à la capacité des LLM à adapter leur style et leurs résultats en fonction du contexte fourni, sans nécessiter de réglage supplémentaire.
On pourrait également parler de apprentissage en quelques essais ou ingénierie de prompt. Cela pourrait être réalisé en spécifiant un ou plusieurs exemples de la réponse souhaitée ou en décrivant clairement comment le modèle devrait se comporter.
L'apprentissage en contexte présente également certaines limites. Il s'agit d'une approche à court terme et spécifique à une tâche, car le modèle ne conserve pas réellement les connaissances acquises lors d'autres sessions utilisant cette technique.
De plus, si le résultat requis est complexe, le modèle pourrait nécessiter un grand nombre d'exemples. Si les exemples fournis ne sont pas suffisamment clairs ou si la tâche est plus complexe que ce que le modèle peut gérer, il peut parfois générer des résultats incorrects ou incohérents.
Il est essentiel de fournir des instructions pour guider les modèles d'apprentissage automatique (LLM) dans l'exécution de tâches spécifiques. Des invites efficaces peuvent même réduire le besoin d'ajuster les modèles en utilisant des techniques telles que l'apprentissage en quelques essais, la décomposition des tâches et les modèles d'invites.
Certaines meilleures pratiques pour une ingénierie efficace et rapide comprennent :
Pour en savoir plus, veuillez consulter ce blog sur les Techniques d'optimisation rapide.
La génération conditionnelle implique que le modèle génère des résultats en fonction de certaines conditions ou contextes. Cela permet un meilleur contrôle sur le contenu généré. Dans les GAN conditionnels (cGAN), le générateur et le discriminateur sont tous deux conditionnés par des informations supplémentaires, telles que les étiquettes de classe. Voici comment cela fonctionne :
Le mélange d'experts (MoE) remplace un réseau neuronal dense unique par de nombreux sous-réseaux « experts » spécialisés. Pour chaque jeton, un routeur sélectionne uniquement les experts les plus pertinents pour traiter les données, ce qui signifie qu'un modèle peut avoir 100 milliards de paramètres, mais n'en utiliser que 10 milliards pour l'inférence.
Cette architecture permet aux modèles d'être extrêmement intelligents (nombre total de paramètres élevé) tout en restant rapides et peu coûteux à exécuter (nombre de paramètres actifs faible).
Si vous postulez pour un poste d'ingénieur en IA spécialisé dans l'IA générative, attendez-vous à des questions visant à évaluer votre capacité à concevoir, mettre en œuvre et déployer des modèles génératifs.
Un chatbot standard est passif : il reçoit une requête et fournit une réponse textuelle basée sur son apprentissage.
Un flux de travail agentique permet au LLM d'accéder à des outils (tels qu'un navigateur Web, un interpréteur de code ou une API) et lui confère l'autonomie nécessaire pour planifier un processus en plusieurs étapes afin d'atteindre un objectif. L'agent pourrait envisager d'effectuer des recherches sur le Web, d'analyser les données à l'aide du code Python, puis de rédiger un rapport, en répétant ces opérations jusqu'à ce que la tâche soit terminée.
Garantir la sécurité et la robustesse des LLM présente plusieurs défis. L'un des principaux défis réside dans le risque de générer des résultats préjudiciables ou biaisés, car ces modèles sont entraînés à partir de sources de données volumineuses, voire non filtrées, et peuvent produire des contenus toxiques ou trompeurs.
Un autre problème majeur lié au contenu généré par les modèles LLM est le risque d'hallucination, c'est-à-dire lorsque le modèle génère un contenu qui semble fiable, mais qui contient en réalité des informations incorrectes. Un autre défi concerne la sécurité contre les invites malveillantes qui enfreignent les mesures de sécurité du modèle et produisent des réponses nuisibles ou contraires à l'éthique, comme cela a été démontré à maintes reprises pour divers modèles.
L'intégration de filtres de sécurité et de niveaux de modération peut contribuer à identifier et à supprimer les contenus préjudiciables qui sont générés. La surveillance continue par l'intervention humaine renforce encore davantage la sécurité du modèle.
De plus, les ingénieurs doivent mettre en place des garde-fous explicites (tels que NeMo Guardrails ou Llama Guard) qui se situent entre l'utilisateur et le modèle. Ces systèmes analysent les entrées afin de bloquer les tentatives d'injection de commandes ou les fuites d'informations personnelles identifiables (PII) et analysent les sorties afin de détecter les réponses toxiques ou inappropriées avant qu'elles n'atteignent l'utilisateur. Cela crée une couche de sécurité déterministe qui fonctionne indépendamment de la nature probabiliste du modèle.
La réponse à cette question dépend fortement de vos projets et de vos expériences. Vous pouvez toutefois garder ces points à l'esprit lorsque vous répondez à des questions de ce type :
Tout comme la question précédente, vous pouvez répondre à cette question en vous basant sur votre expérience, mais en gardant également à l'esprit les points suivants :
Même avec des fenêtres contextuelles de grande taille (par exemple, 1 million de tokens), les LLM ont souvent des difficultés à extraire les informations enfouies au milieu de l'invite, privilégiant le début et la fin.
Les ingénieurs atténuent ce problème en utilisant des algorithmes de reclassement intelligents qui déplacent les fragments les plus importants vers le début ou la fin de la fenêtre contextuelle. Une autre stratégie consiste à utiliser l'algorithme « map-reduce », dans lequel le modèle résume indépendamment les sections du long document avant de les combiner pour obtenir une réponse finale.
La mise en place d'un système RAG nécessite une approche systématique. Voici à quoi pourrait ressembler le pipeline :
La réponse dépend ici également de vos préférences personnelles, mais voici quelques sujets que vous pouvez aborder :
Alors que l'IA générative influence de plus en plus divers aspects de notre vie et de notre carrière, il est essentiel de rester attentif aux sujets essentiels. Bien que les questions potentielles relatives à l'IA générique pouvant être posées lors d'un entretien dépendent du poste et de l'entreprise concernés, j'ai sélectionné 30 questions et réponses afin de vous aider à préparer votre entretien.
Pour découvrir d'autres questions d'entretien, je vous recommande les blogs suivants :
Apprenez l'IA grâce à ces cours.
Cursus
Cours
Cours
blog
Lynn Heidmann
blog
Nisha Arya Ahmed
15 min
blog
blog
Kurtis Pykes
9 min
Tutoriel

