
programa
Fundamentos de la IA
10 h
Comencemos con algunas preguntas básicas para entrevistas sobre IA generativa. Estas pruebas evaluarán tu comprensión de los conceptos y principios fundamentales.
Los modelos discriminativos aprenden la frontera de decisión entre clases y los patrones que las diferencian. Estiman la probabilidad P(y|x), que es la probabilidad de una etiqueta concreta y, dados los datos de entrada x. Estos modelos se centran en distinguir entre diferentes categorías (por ejemplo,«¿Es este correo electrónico spam?»).
Los modelos generativos aprenden la distribución de los datos mismos mediante el modelado de la probabilidad conjunta P(x,y), lo que implica el muestreo de puntos de datos de esta distribución. Tras ser entrenado con miles de imágenes de dígitos, este muestreo podría producir una nueva imagen de un dígito.
Más información en este blog sobre « » ( Modelos generativos frente a discriminativos): Diferencias y casos de uso.
Los tokens son las unidades fundamentales de texto que procesa un LLM; pueden ser palabras completas, sílabas o incluso letras individuales (por ejemplo, la palabra «generative» podría dividirse en «gener», «at» e «ive»).
Las incrustaciones son representaciones vectoriales numéricas de esos tokens que los sitúan en un espacio multidimensional basado en su significado. Esta conversión permite al modelo captar el significado semántico y comprender las relaciones entre las palabras, por ejemplo, reconociendo que «rey» está relacionado con «reina».
Las GAN están formadas por dos redes neuronales que compiten entre sí (de ahí el término «adversarial», que significa «adversario»): un generador y un discriminador.
El generador crea muestras de datos falsos, mientras que el discriminador los evalúa comparándolos con los datos de entrenamiento reales. Las dos redes se entrenan simultáneamente:
A través de este aprendizaje competitivo, el generador adquiere destreza en la producción de datos muy realistas que son similares a los datos de entrenamiento.
El uso generalizado de la GenAI y sus casos de aplicación requieren una evaluación exhaustiva de su rendimiento en términos de ética. Algunos ejemplos son:
Aunque las alucinaciones de los modelos de IA pueden producir resultados erróneos, estos modelos generativos son útiles en muchos aspectos y usos. Pueden servir de inspiración creativa a los expertos en diversos campos:
Un modelo base (como GPT-5.2) se entrena con grandes cantidades de datos generales de Internet para aprender patrones generales, razonamiento y estructura lingüística.
Un modelo ajustado toma esta base generalista y lo entrena aún más en un conjunto de datos más pequeño y seleccionado para dominar una tarea específica, como el diagnóstico médico o hablar en un lenguaje de programación específico. El perfeccionamiento cambia la versatilidad general por una mayor especialización en un campo específico.
Ahora que ya hemos cubierto los conceptos básicos, exploremos algunas preguntas intermedias sobre IA generativa para entrevistas.
Al igual que un creador de contenido que descubre que un determinado formato de vídeo genera más alcance e interacciones, el modelo generativo de una GAN podría fijarse en una diversidad limitada de resultados que engañan al modelo discriminador. Esto hace que el generador produzca un conjunto reducido de resultados, lo que merma la diversidad y la flexibilidad de los datos generados.
Las posibles soluciones a este problema podrían centrarse en técnicas de entrenamiento mediante el ajuste de los hiperparámetros y diversos algoritmos de optimización, la aplicación de regularizaciones que promuevan la diversidad o la combinación de múltiples generadores para cubrir diferentes modos de generación de datos.
Un autocodificador variacional (VAE) es un tipo de modelo generativo que aprende a codificar datos de entrada en un espacio latente y a descodificarlos para reconstruir los datos de entrada originales. Los VAE son modelos codificador-decodificador:
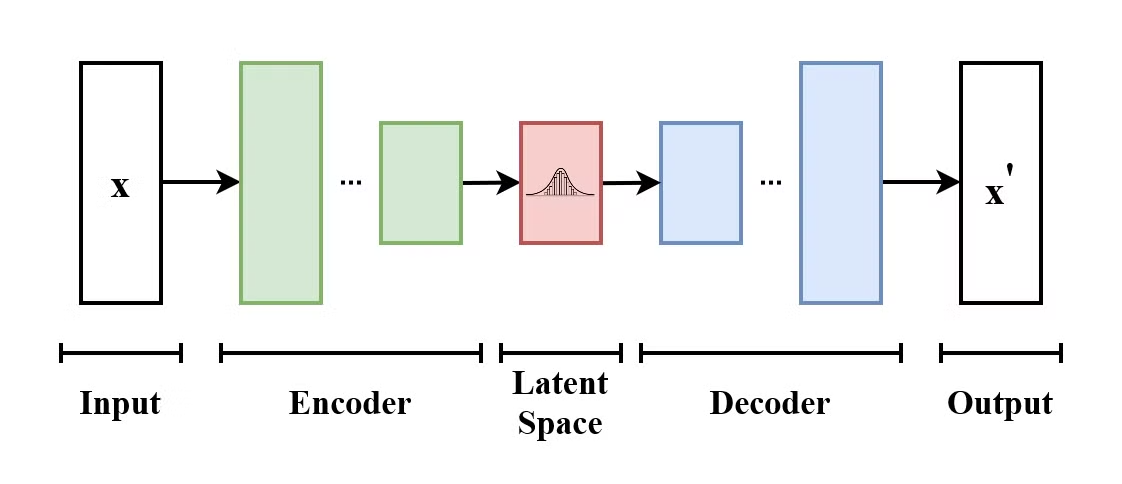
La estructura de un autoencoder variacional. (Fuente: Wikimedia Commons)
Lo que diferencia a los VAE de los autoencoders tradicionales es que los VAE fomentan que el espacio latente siga una distribución conocida (como la gaussiana). Esto los hace más útiles para generar nuevos datos mediante el muestreo de este espacio latente.
RAG ( ) conecta un modelo con fuentes de datos externas (como la wiki de tu empresa) para obtener información actualizada sin necesidad de volver a entrenar el modelo. Los parámetros del modelo siguen siendo los mismos; solo que ahora tiene acceso a datos adicionales.
El ajuste fino modifica los pesos internos del modelo para cambiar la forma en que habla, se comporta o razona, pero no es adecuado para añadir nuevos conocimientos fácticos.
Utiliza RAG cuando necesites datos actualizados (noticias, datos de empresas privadas) o una cita específica. Utiliza el ajuste fino cuando necesites que el modelo aprenda un nuevo «comportamiento», idioma o formato de salida específico (por ejemplo, hablar en código SQL).
La evaluación de las muestras generadas es una tarea compleja que depende de la modalidad de los datos (imagen, texto, vídeo, etc.). TTexto tradicional métricas, como la precisión, son insuficientes para tareas creativas porque solo comprueban la superposición de palabras, no el significado.
Los puntos de referencia y las tablas de clasificación de LLM utilizan pruebas estandarizadas para medir la eficacia con la que un modelo realiza una tarea determinada. Son útiles para comparar modelos y realizar un programa del progreso dentro de una misma modalidad o entre diferentes modalidades.
LLM-as-a-Judge es un marco de evaluación moderno en el que un modelo «profesor» altamente capacitado (como Gemini 3) califica los resultados de un modelo más pequeño basándose en criterios específicos, como la fidelidad, la utilidad y el tono. Esto proporciona una forma escalable de aproximarse a las preferencias humanas sin la lentitud y el coste que supone la revisión manual por parte de personas.
Mejorar la estabilidad y la convergencia del entrenamiento de las GAN es importante para evitar el colapso modal, garantizar un entrenamiento eficiente y obtener buenos resultados. A continuación, se describen algunas técnicas para mejorar la estabilidad y la convergencia del entrenamiento de GAN:
Existen varias técnicas comunes para controlar el estilo de los resultados de GenAI:
Para garantizar que el modelo sea imparcial y justo, es necesario realizar ajustes iterativos y supervisar cada fase.
En primer lugar, es necesario evitar la contaminación de los datos asegurándote de que ningún dato de prueba se filtre en los datos de entrenamiento. En ese caso, el modelo se entrenaría para memorizar los datos en lugar de generalizarlos.
Además, debemos asegurarnos de que los datos de entrenamiento sean lo más diversos e inclusivos posible. Durante el entrenamiento, podemos orientar el modelo hacia una generación más justa incorporando objetivos de equidad en la función de pérdida.
Los resultados del modelo deben supervisarse periódicamente para detectar posibles sesgos. Para generar confianza en el público, es útil que el proceso de toma de decisiones del modelo, los detalles del conjunto de datos y los pasos de preprocesamiento sean lo más transparentes posible.
En el contexto de los modelos generativos, el espacio latente es un espacio de menor dimensión que captura las características esenciales de los datos de tal manera que las entradas similares se mapean más cerca unas de otras. El muestreo de este espacio latente permite a los modelos generar nuevos datos y manipular atributos o características específicos (generando variaciones de imágenes).
Los espacios latentes son fundamentales para generar resultados controlables, fieles a los datos de entrenamiento y diversos.
La idea clave detrás del aprendizaje auto-supervisado es aprovechar un vasto corpus de datos sin etiquetar para aprender representaciones útiles sin necesidad de etiquetado manual. Modelos como BERT y GPT se entrenan mediante métodos auto-supervisados, como la predicción del siguiente token y el aprendizaje de la estructura y la semántica de los idiomas. Esto reduce la dependencia de los datos etiquetados, cuya obtención resulta costosa y lleva mucho tiempo, lo que permite a los modelos aprovechar grandes conjuntos de datos sin etiquetar para el entrenamiento.
Reentrenar un modelo masivo de 70 000 millones de parámetros resulta prohibitivamente caro y lento para la mayoría de las organizaciones. La adaptación de rango bajo (LoRA) resuelve este problema congelando los pesos del modelo principal y entrenando únicamente una pequeña capa «adaptadora» (a menudo menos del 1 % del total de parámetros) que se sitúa en la parte superior. Esto te permite ofrecer docenas de modelos «personalizados» diferentes a partir de un único modelo base, lo que reduce drásticamente el coste computacional y las necesidades de almacenamiento.
Para aquellos que buscan puestos de mayor responsabilidad o que desean demostrar un profundo conocimiento de la IA generativa, veamos algunas preguntas avanzadas para entrevistas.
Los modelos de difusión funcionan principalmente añadiendo ruido gradualmente a una imagen hasta que solo queda ruido, y luego aprendiendo a invertir este proceso para generar nuevas muestras a partir del ruido. Este proceso se denominadifusión e e. Estos modelos han ganado popularidad por su capacidad para generar imágenes de alta calidad y gran detalle.

Generación de una imagen mediante pasos de difusión. (Fuente: Wikimedia Commons)
El proceso de entrenamiento de estos modelos incluye dos pasos:
A diferencia de las GAN más antiguas, que a menudo adolecían de inestabilidad en el entrenamiento, los modelos de difusión son más estables y escalables, aunque pueden ser más lentos debido a su naturaleza iterativa.
Las variantes modernas, como la difusión latente, operan en un «espacio latente» comprimido para acelerar la generación, y las arquitecturas de coincidencia de flujos están sustituyendo ahora a la difusión estándar para obtener un rendimiento aún mejor.
La arquitectura del transformador presentada en el artículo «Attention is All You Need», ha revolucionado el campo de la IA generativa, especialmente en el procesamiento del lenguaje natural (NLP).
A diferencia de las redes neuronales recurrentes (RNN) tradicionales, que procesan los datos de forma secuencial, los transformadores utilizan el mecanismo de autoatención para atribuir pesos a diferentes partes de los datos de entrada simultáneamente. Esto permite que el modelo capte eficazmente las relaciones contextuales y permite el procesamiento paralelo de secuencias, lo que acelera considerablemente el entrenamiento.
El principal obstáculo es que este mecanismo de atención se escala cuadráticamente con la longitud de la secuencia: duplicar la ventana de contexto requiere cuatro veces más capacidad de cálculo. Esto hace que el «contexto infinito» sea teóricamente posible, pero computacionalmente costoso, lo que impulsa la investigación hacia métodos de atención más eficientes.
Los LLM estándar actúan como pensadores del «Sistema 1», prediciendo la siguiente palabra inmediatamente basándose en patrones superficiales.
Los modelos de razonamiento (como Gemini 3 o DeepSeek-R1) están entrenados para generar una «cadena de pensamiento» oculta antes de dar una respuesta, lo que les permite «pensar», planificar y autocorregir errores. Esto los hace significativamente mejores en matemáticas complejas, codificación y rompecabezas lógicos, aunque son más lentos y más caros de ejecutar.
A medida que aumentas la complejidad de la generación de IA, también debes abordar:
El campo de la GenAI está evolucionando y transformándose a un ritmo vertiginoso. Esto incluye:
Diseñar un sistema que utilice IA generativa para casos de uso específicos de la industria es un enfoque exhaustivo. Las directrices generales también pueden adaptarse y modificarse para otros sectores.
El aprendizaje en contexto se refiere a la capacidad de los LLM para modificar su estilo y resultados en función del contexto proporcionado sin necesidad de un ajuste adicional.
También se podría denominar aprendizaje con pocos ejemplos o ingeniería de prompts. Esto podría lograrse especificando uno o varios ejemplos de la respuesta deseada o describiendo claramente cómo debe comportarse el modelo.
El aprendizaje en contexto también tiene sus limitaciones. Es a corto plazo y específico para cada tarea, ya que el modelo no retiene realmente ningún conocimiento en otras sesiones en las que se utiliza esta técnica.
Además, si el resultado requerido es complejo, es posible que el modelo necesite un gran número de ejemplos. Si los ejemplos proporcionados no son lo suficientemente claros o la tarea es más difícil de lo que el modelo puede manejar, a veces puede generar resultados incorrectos o incoherentes.
Las indicaciones son importantes para dirigir a los LLM a responder a tareas específicas. Las indicaciones eficaces pueden incluso mitigar la necesidad de ajustar los modelos mediante el uso de técnicas como el aprendizaje con pocos ejemplos, la descomposición de tareas y las plantillas de indicaciones.
Algunas mejores prácticas para una ingeniería eficaz y rápida incluyen:
Lee más en este blog sobre Técnicas de optimización rápida.
La generación condicional implica que el modelo genere resultados basados en determinadas condiciones o contextos. Esto permite un mayor control sobre el contenido generado. En las GAN condicionales (cGAN), tanto el generador como el discriminador están condicionados por información adicional, como las etiquetas de clase. Así es como funciona:
La mezcla de expertos (MoE) sustituye una única red neuronal densa por muchas subredes «expertas» especializadas. Para cualquier token dado, un enrutador selecciona solo a los expertos más relevantes para procesar los datos, lo que significa que un modelo puede tener 100 000 millones de parámetros, pero solo utilizar 10 000 millones para la inferencia.
Esta arquitectura permite que los modelos sean increíblemente inteligentes (alto número total de parámetros) y, al mismo tiempo, rápidos y económicos de ejecutar (bajo número de parámetros activos).
Si estás realizando una entrevista para un puesto de ingeniero de IA centrado en la IA generativa, prepárate para responder preguntas que evalúen tu capacidad para diseñar, implementar y desplegar modelos generativos.
Un chatbot estándar es pasivo: recibe una consulta y genera una respuesta de texto basada en su entrenamiento.
Un flujo de trabajo agencial proporciona al LLM acceso a herramientas (como un navegador web, un intérprete de código o una API) y la autonomía necesaria para planificar un proceso de varios pasos con el fin de alcanzar un objetivo. El agente podría planear buscar en la web, analizar los datos con código Python y luego escribir un informe, repitiendo el proceso hasta completar la tarea.
Garantizar la seguridad y la solidez de los LLM plantea varios retos. Uno de los principales retos es la posibilidad de generar resultados perjudiciales o sesgados, ya que estos modelos se entrenan con fuentes de datos enormes o incluso sin filtrar y pueden producir contenidos tóxicos o engañosos.
Otro problema importante del contenido generado por LLM es el peligro de las alucinaciones, es decir, que el modelo genere contenido que suena convincente pero que, en realidad, es información incorrecta. Otro reto es la seguridad frente a indicaciones adversas que violan las medidas de seguridad del modelo y producen respuestas dañinas o poco éticas, como se ha demostrado en numerosas ocasiones en relación con diversos modelos.
La incorporación de filtros de seguridad y capas de moderación puede ayudar a identificar y eliminar el contenido perjudicial que se está generando. La supervisión continua por parte de personas mejora aún más la seguridad del modelo.
Además, los ingenieros deben implementar barreras de protección explícitas (como NeMo Guardrails o Llama Guard) que se interponen entre el usuario y el modelo. Estos sistemas analizan las entradas para bloquear los intentos de inyección de comandos o la filtración de información de identificación personal (PII) y analizan las salidas para detectar respuestas tóxicas o alucinatorias antes de que lleguen al usuario. Esto crea una capa de seguridad determinista que funciona independientemente de la naturaleza probabilística del modelo.
Responder a esta pregunta depende en gran medida de tus proyectos y experiencias. Sin embargo, puedes tener en cuenta estos puntos al responder preguntas como esta:
Al igual que la pregunta anterior, esta pregunta puede responderse basándose en tu experiencia, pero también teniendo en cuenta lo siguiente:
Incluso con ventanas de contexto masivas (por ejemplo, 1 millón de tokens), los LLM a menudo tienen dificultades para recuperar información oculta en medio de la solicitud, dando prioridad al principio y al final.
Los ingenieros mitigan este problema utilizando algoritmos inteligentes de reclasificación que mueven los fragmentos recuperados más críticos al principio o al final de la ventana de contexto. Otra estrategia es el algoritmo «map-reduce», en el que el modelo resume secciones del documento largo de forma independiente antes de combinarlas para obtener una respuesta final.
La creación de un sistema RAG requiere un enfoque sistemático. Así es como podría ser el proceso:
La respuesta depende también de tus preferencias personales, pero aquí tienes algunos temas que puedes mencionar:
A medida que la IA generativa encuentra formas de influir en diversos aspectos de nuestras vidas y carreras profesionales, es fundamental mantener una mirada curiosa sobre los temas esenciales. Aunque las posibles preguntas sobre GenAI que se pueden plantear durante una entrevista dependen del puesto y la empresa concretos, he intentado recopilar 30 preguntas y respuestas para ayudarte a empezar a preparar tu entrevista.
Para explorar más preguntas de entrevista, recomiendo estos blogs:
¡Aprende IA con estos cursos!
programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
14 min
blog
Adel Nehme
15 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
11 min



