
Program
Dasar-Dasar Kecerdasan Buatan
10 Hr
Mari mulai dengan beberapa pertanyaan wawancara AI Generatif yang mendasar. Ini akan menguji pemahaman Anda tentang konsep dan prinsip inti.
Model diskriminatif mempelajari batas keputusan antar kelas dan pola yang membedakannya. Model ini mengestimasi probabilitas P(y|x), yaitu probabilitas label tertentu y, diberikan data masukan x. Model ini berfokus membedakan kategori berbeda (misalnya, 'Apakah email ini spam?').
Model generatif mempelajari distribusi data itu sendiri dengan memodelkan probabilitas gabungan P(x,y), yang melibatkan pengambilan sampel titik data dari distribusi ini. Setelah dilatih pada ribuan gambar digit, pengambilan sampel ini dapat menghasilkan gambar digit baru.
Baca lebih lanjut di blog ini tentang Generative vs Discriminative Models: Differences & Use Cases.
Token adalah unit dasar teks yang diproses LLM; bisa berupa kata utuh, suku kata, atau bahkan huruf individual (misalnya, kata "generative" bisa dipecah menjadi "gener", "at", "ive").
Embedding adalah representasi vektor numerik dari token-token tersebut yang menempatkannya dalam ruang multi-dimensi berdasarkan maknanya. Konversi ini memungkinkan model menangkap makna semantik dan memahami hubungan antar kata, misalnya mengenali bahwa "king" dekat dengan "queen".
GAN terdiri dari dua jaringan saraf yang saling berkompetisi (karena itu disebut Adversarial): generator dan discriminator.
Generator membuat sampel data palsu sementara discriminator mengevaluasinya terhadap data latih yang asli. Kedua jaringan dilatih secara simultan:
Melalui pembelajaran kompetitif ini, generator menjadi andal menghasilkan data yang sangat realistis dan mirip dengan data latih.
Penggunaan GenAI yang meluas dan berbagai kasus penggunaannya memerlukan evaluasi menyeluruh terhadap kinerjanya dari sisi etika. Beberapa contohnya meliputi:
Walau halusinasi model AI bisa menghasilkan keluaran keliru, model generatif bermanfaat dalam banyak hal dan penggunaan. Model ini dapat menjadi inspirasi kreatif bagi para ahli di berbagai bidang:
Sebuah Foundation Model (seperti GPT-5.2) dilatih pada sejumlah besar data internet yang luas untuk mempelajari pola umum, penalaran, dan struktur bahasa.
Model Fine-Tuned mengambil basis generalis ini dan melatihnya lebih lanjut pada dataset yang lebih kecil dan terkurasi untuk menguasai tugas spesifik, seperti diagnosis medis atau berbicara dalam bahasa pemrograman tertentu. Fine-tuning menukar keserbabisa luas dengan keahlian yang lebih mendalam di bidang tertentu.
Setelah membahas dasar-dasarnya, mari jelajahi beberapa pertanyaan wawancara AI generatif tingkat menengah.
Layaknya kreator konten yang mendapati format video tertentu menghasilkan jangkauan dan interaksi lebih besar, model generatif dalam GAN bisa menjadi terpaku pada keragaman keluaran yang terbatas yang mampu mengecoh model discriminator. Akibatnya generator menghasilkan set keluaran yang kecil, mengorbankan keragaman dan fleksibilitas data yang dihasilkan.
Solusi yang mungkin mencakup fokus pada teknik pelatihan dengan menyesuaikan hiperparameter dan berbagai algoritme optimisasi, menerapkan regularisasi yang mendorong keragaman, atau menggabungkan beberapa generator untuk mencakup berbagai mode generasi data.
Sebuah Variational Autoencoder (VAE) adalah jenis model generatif yang belajar mengenkode data masukan ke ruang laten dan mendekodenya kembali untuk merekonstruksi data masukan asli. VAE adalah model encoder-decoder:
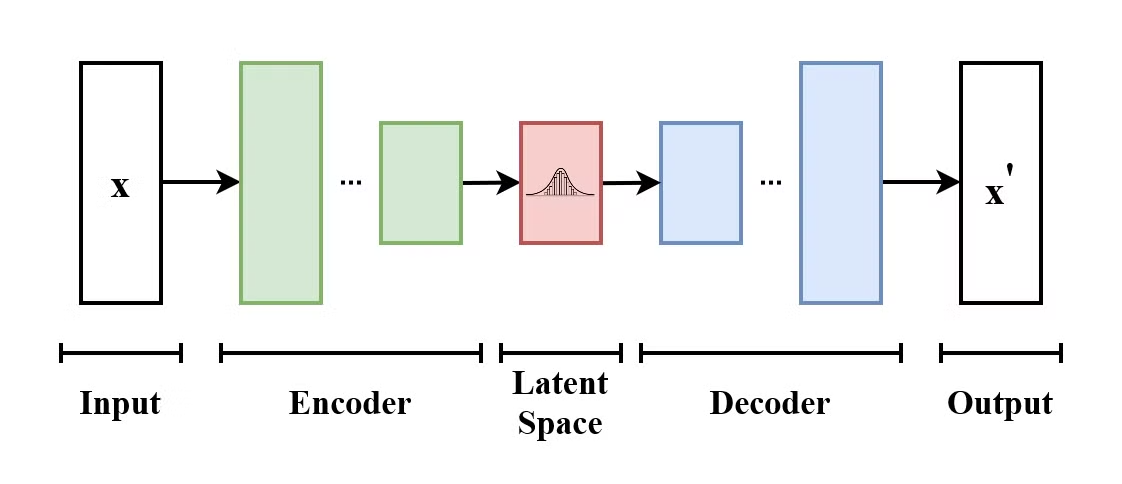
Struktur Variational Autoencoder. (Sumber: Wikimedia Commons)
Yang membedakan VAE dari autoencoder tradisional adalah VAE mendorong ruang laten untuk mengikuti distribusi yang diketahui (seperti Gaussian). Ini membuatnya lebih berguna untuk menghasilkan data baru dengan mengambil sampel dari ruang laten ini.
RAG menghubungkan model ke sumber data eksternal (seperti wiki perusahaan Anda) untuk mengambil fakta terbaru tanpa melatih ulang model. Parameter model tetap sama; model hanya mendapat akses ke data tambahan.
Fine-tuning memodifikasi bobot internal model untuk mengubah cara model berbicara, berperilaku, atau bernalar, tetapi tidak bagus untuk menambahkan pengetahuan faktual baru.
Gunakan RAG ketika Anda memerlukan fakta terbaru (berita, data perusahaan privat) atau sitasi spesifik. Gunakan fine-tuning ketika Anda perlu model mempelajari "perilaku" baru, bahasa, atau format keluaran tertentu (mis., berbicara dalam kode SQL).
Menilai sampel yang dihasilkan adalah tugas kompleks yang bergantung pada modalitas data (gambar, teks, video, dll.). Tradisionalnya, metrik teks seperti akurasi tidak memadai untuk tugas kreatif karena hanya memeriksa tumpang tindih kata, bukan makna.
Tolok ukur dan papan peringkat LLM menggunakan tes standar untuk mengukur seberapa baik model menangani tugas tertentu. Ini membantu membandingkan model dan melacak kemajuan dalam atau lintas modalitas.
LLM-as-a-Judge adalah kerangka evaluasi modern di mana model "guru" yang sangat mumpuni (seperti Gemini 3) menilai keluaran model yang lebih kecil berdasarkan kriteria tertentu, termasuk ketepatan, kebermanfaatan, dan nada. Ini menyediakan cara berskala untuk mendekati preferensi manusia tanpa kelambatan dan biaya tinjauan manusia manual.
Meningkatkan stabilitas dan konvergensi pelatihan GAN penting untuk menghindari mode collapse, memastikan pelatihan efisien, dan mencapai hasil yang baik. Berikut beberapa teknik untuk meningkatkannya:
Ada beberapa teknik umum untuk mengendalikan gaya keluaran GenAI:
Memastikan model tidak bias dan adil memerlukan penyesuaian iteratif dan pemantauan di setiap fase.
Pertama, kontaminasi data harus dicegah dengan memastikan tidak ada data uji yang bocor ke data latih. Jika terjadi, model akan dilatih untuk menghafal data alih-alih menggeneralisasinya.
Selanjutnya, kita harus memastikan data latih seberagam dan seinklusif mungkin. Selama pelatihan, kita bisa membimbing model menuju generasi yang lebih adil dengan memasukkan tujuan keadilan ke dalam fungsi loss.
Keluaran model harus dipantau secara berkala untuk mendeteksi bias. Untuk membangun kepercayaan publik, membantu bila proses pengambilan keputusan model, detail dataset, dan langkah prapemrosesan dibuat setransparan mungkin.
Dalam konteks model Generatif, ruang laten adalah ruang berdimensi lebih rendah yang menangkap fitur esensial data sedemikian rupa sehingga masukan yang mirip dipetakan lebih dekat satu sama lain. Mengambil sampel dari ruang laten ini memungkinkan model menghasilkan data baru dan memanipulasi atribut atau fitur spesifik (menghasilkan variasi gambar).
Ruang laten adalah kunci untuk menghasilkan keluaran yang dapat dikendalikan, setia pada data latih, dan beragam.
Gagasan utama pembelajaran swasupervisi adalah memanfaatkan korpus data tanpa label yang sangat besar untuk mempelajari representasi yang berguna tanpa perlu pelabelan manual. Model seperti BERT dan GPT dilatih dengan metode swasupervisi seperti prediksi token berikutnya, serta mempelajari struktur dan semantik bahasa. Ini mengurangi ketergantungan pada data berlabel, yang mahal dan memakan waktu untuk diperoleh, sehingga memungkinkan model memanfaatkan dataset tanpa label yang luas untuk pelatihan.
Melatih ulang model raksasa berparameter 70 miliar sangat mahal dan lambat bagi sebagian besar organisasi. Low-Rank Adaptation (LoRA) mengatasinya dengan membekukan bobot model utama dan hanya melatih lapisan "adapter" kecil (sering kurang dari 1% dari total parameter) yang ditempatkan di atasnya. Ini memungkinkan Anda menyajikan puluhan model "kustom" berbeda dari satu model dasar, secara drastis mengurangi biaya komputasi dan kebutuhan penyimpanan.
Bagi yang mengejar peran lebih senior atau ingin menunjukkan pemahaman mendalam tentang AI Generatif, mari jelajahi beberapa pertanyaan wawancara tingkat lanjut.
Diffusion Models bekerja terutama dengan menambahkan noise secara bertahap ke sebuah gambar hingga hanya tersisa noise—lalu mempelajari cara membalik proses ini untuk menghasilkan sampel baru dari noise. Proses ini disebut difusi. Model ini populer karena kemampuannya menghasilkan gambar yang berkualitas tinggi dan sangat detail.

Generasi sebuah gambar melalui langkah-langkah difusi. (Sumber: Wikimedia Commons)
Proses pelatihan model ini mencakup dua langkah:
Berbeda dengan GAN lama yang sering mengalami instabilitas pelatihan, model difusi lebih stabil dan dapat diskalakan, meski bisa lebih lambat karena sifatnya yang iteratif.
Varian modern seperti latent diffusion beroperasi di "ruang laten" terkompresi untuk mempercepat generasi, dan arsitektur flow matching kini menggantikan difusi standar demi kinerja yang lebih baik.
Arsitektur transformer yang diperkenalkan dalam makalah “Attention is All You Need”, merevolusi bidang AI generatif, khususnya dalam pemrosesan bahasa alami (NLP).
Tidak seperti recurrent neural network (RNN) tradisional yang memproses data secara berurutan, transformer menggunakan mekanisme self-attention untuk memberi bobot pada bagian-bagian berbeda dari masukan secara simultan. Ini memungkinkan model menangkap hubungan kontekstual secara efektif dan memungkinkan pemrosesan paralel urutan, yang secara signifikan mempercepat pelatihan.
Hambatan utama adalah mekanisme attention ini diskalakan secara kuadrat dengan panjang urutan—menggandakan context window memerlukan empat kali komputasi. Ini membuat "konteks tak terbatas" secara teoritis memungkinkan namun mahal secara komputasi, mendorong riset ke metode attention yang lebih efisien.
LLM standar bertindak sebagai pemikir "Sistem 1", memprediksi kata berikutnya secara langsung berdasarkan pola permukaan.
Reasoning Model (seperti Gemini 3 atau DeepSeek-R1) dilatih untuk menghasilkan "rantai pemikiran" tersembunyi sebelum memberikan jawaban, memungkinkan mereka "berpikir", merencanakan, dan mengoreksi diri. Ini membuatnya jauh lebih baik dalam matematika kompleks, pengodean, dan teka-teki logika, meski lebih lambat dan lebih mahal dijalankan.
Saat Anda meningkatkan kompleksitas generasi AI, Anda juga harus menangani:
Bidang GenAI berkembang dan bertransformasi dengan cepat. Ini mencakup:
Merancang sistem yang menggunakan AI generatif untuk kasus penggunaan khusus industri membutuhkan pendekatan menyeluruh. Pedoman umum dapat disesuaikan dan dimodifikasi lintas industri lainnya.
In-context learning mengacu pada kemampuan LLM untuk memodifikasi gaya dan keluarannya berdasarkan konteks yang diberikan tanpa perlu fine-tuning tambahan.
Ini juga dapat disebut sebagai few-shot learning atau prompt engineering. Ini dapat dicapai dengan menentukan satu atau banyak contoh respons yang diinginkan atau dengan menjelaskan dengan jelas bagaimana model harus berperilaku.
In-context learning juga memiliki keterbatasan. Ini bersifat jangka pendek dan spesifik tugas, karena model tidak benar-benar mempertahankan pengetahuan pada sesi lain saat menggunakan teknik ini.
Selain itu, jika keluaran yang diperlukan kompleks, model mungkin membutuhkan banyak contoh. Jika contoh yang diberikan kurang jelas atau tugasnya lebih sulit daripada kemampuan model, terkadang model menghasilkan keluaran yang salah atau tidak koheren.
Prompting penting untuk mengarahkan LLM dalam merespons tugas tertentu. Prompt yang efektif bahkan dapat mengurangi kebutuhan fine-tuning model dengan menggunakan teknik seperti few-shot learning, dekomposisi tugas, dan templat prompt.
Beberapa praktik terbaik untuk prompt engineering yang efektif meliputi:
Baca lebih lanjut di blog ini tentang Prompt Optimization Techniques.
Conditional Generation melibatkan model yang menghasilkan keluaran berdasarkan kondisi atau konteks tertentu. Ini memungkinkan kontrol lebih atas konten yang dihasilkan. Dalam Conditional GAN (cGAN), baik generator maupun discriminator dikondisikan pada informasi tambahan, seperti label kelas. Cara kerjanya:
Mixture of Experts (MoE) menggantikan satu jaringan saraf padat dengan banyak sub-jaringan "ahli" yang terspesialisasi. Untuk setiap token, sebuah router memilih hanya ahli yang paling relevan untuk memproses data, artinya sebuah model bisa memiliki 100 miliar parameter tetapi hanya menggunakan 10 miliar saat inferensi.
Arsitektur ini memungkinkan model sangat cerdas (jumlah parameter total tinggi) sekaligus tetap cepat dan murah dijalankan (jumlah parameter aktif rendah).
Jika Anda diwawancarai untuk peran rekayasa AI dengan fokus pada AI generatif, harapkan pertanyaan yang menilai kemampuan Anda merancang, mengimplementasikan, dan menerapkan model generatif.
Chatbot standar bersifat pasif: menerima pertanyaan dan menghasilkan jawaban teks berdasarkan pelatihannya.
Sebuah alur kerja agentic memberi LLM akses ke alat (seperti peramban web, interpreter kode, atau API) dan otonomi untuk merencanakan proses multi-langkah guna menyelesaikan tujuan. Agen dapat merencanakan untuk menelusuri web, menganalisis data dengan kode Python, lalu menulis laporan, berulang hingga tugas tuntas.
Memastikan keamanan dan ketangguhan LLM memiliki beberapa tantangan. Tantangan utama mencakup potensi menghasilkan keluaran yang berbahaya atau bias, karena model ini dilatih pada sumber data yang luas bahkan tidak tersaring dan dapat menghasilkan konten toksik atau menyesatkan.
Isu besar lainnya pada konten yang dihasilkan LLM adalah bahaya halusinasi, ketika model menghasilkan konten yang terdengar meyakinkan namun sebenarnya salah. Tantangan lain adalah keamanan terhadap prompt adversarial yang melanggar langkah-langkah keamanan model dan menghasilkan respons berbahaya atau tidak etis, seperti yang telah terbukti berkali-kali pada berbagai model.
Memasukkan filter keamanan dan lapisan moderasi dapat membantu mengidentifikasi dan menghapus konten berbahaya yang dihasilkan. Pengawasan human-in-the-loop yang berkelanjutan semakin meningkatkan keamanan model.
Selain itu, insinyur harus menerapkan Guardrails eksplisit (seperti NeMo Guardrails atau Llama Guard) yang berada di antara pengguna dan model. Sistem ini memindai masukan untuk memblokir upaya prompt injection atau kebocoran PII (Personally Identifiable Information) dan memindai keluaran untuk menangkap respons yang toksik atau berhalusinasi sebelum sampai ke pengguna. Ini menciptakan lapisan keamanan deterministik yang beroperasi secara independen dari sifat probabilistik model.
Menjawab pertanyaan ini sangat subjektif terhadap proyek dan pengalaman Anda. Namun, Anda dapat mengingat poin-poin ini saat menjawab pertanyaan seperti ini:
Seperti halnya pertanyaan di atas, pertanyaan ini dapat dijawab berdasarkan pengalaman Anda, namun juga dengan tetap mengingat untuk:
Bahkan dengan context window yang sangat besar (mis., 1 juta token), LLM sering kesulitan mengambil informasi yang terkubur di tengah prompt, memprioritaskan bagian awal dan akhir.
Insinyur mengatasinya dengan menggunakan algoritme re-ranking cerdas yang memindahkan potongan yang paling kritis ke awal atau akhir context window. Strategi lain adalah algoritme "map-reduce", di mana model merangkum bagian-bagian dokumen panjang secara terpisah sebelum menggabungkannya untuk jawaban akhir.
Membangun sistem RAG memerlukan pendekatan sistematis. Berikut gambaran pipelinenya:
Jawabannya juga bergantung pada preferensi pribadi Anda, namun berikut beberapa topik yang bisa disebutkan:
Karena AI Generatif semakin memengaruhi berbagai aspek kehidupan dan karier kita, penting untuk terus mencermati topik-topik esensial. Walau pertanyaan GenAI yang mungkin ditanyakan saat wawancara bergantung pada peran dan perusahaan spesifik, saya telah mencoba merangkum 30 pertanyaan dan jawaban untuk membantu Anda memulai perjalanan persiapan wawancara.
Untuk mengeksplorasi lebih banyak pertanyaan wawancara, saya merekomendasikan blog berikut:
Pelajari AI dengan kursus-kursus ini!
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
