
Programa
Fundamentos da IA
10 h
Vamos começar com algumas perguntas básicas sobre IA generativa para entrevistas. Isso vai testar o quanto você entendeu os conceitos e princípios básicos.
Os modelos discriminativos aprendem a linha divisória entre as classes e os padrões que as diferenciam. Eles calculam a probabilidade P(y|x), que é a chance de um rótulo específico y, considerando os dados de entrada x. Esses modelos se concentram em distinguir entre diferentes categorias (por exemplo,“Este e-mail é spam?”).
Os modelos generativos aprendem a distribuição dos dados modelando a probabilidade conjunta P(x,y), que envolve a amostragem de pontos de dados dessa distribuição. Depois de ser treinado com milhares de imagens de dígitos, essa amostragem pode criar uma nova imagem de um dígito.
Leia mais neste blog em Modelos generativos vs. discriminativos: Diferenças e casos de uso.
Os tokens são as unidades básicas de texto que um LLM processa; podem ser palavras inteiras, sílabas ou até letras individuais (por exemplo, a palavra “generative” pode ser dividida em “gener”, “at”, “ive”).
Embeddings são representações numéricas vetoriais desses tokens que os colocam em um espaço multidimensional com base em seu significado. Essa conversão permite que o modelo capte o significado semântico e entenda as relações entre as palavras, por exemplo, reconhecendo que “rei” está próximo de “rainha”.
As GANs são feitas de duas redes neurais que competem entre si (daí o nome Adversarial): um gerador e um discriminador.
O gerador cria amostras de dados falsos enquanto o discriminador os avalia em relação aos dados de treinamento reais. As duas redes são treinadas ao mesmo tempo:
Com esse aprendizado competitivo, o gerador fica craque em criar dados super realistas, parecidos com os dados de treinamento.
O uso generalizado da GenAI e seus casos de uso exigem uma avaliação cuidadosa do desempenho em termos de ética. Alguns exemplos incluem:
Embora as alucinações dos modelos de IA possam gerar resultados errados, esses modelos generativos são úteis em muitos aspectos e usos. Eles podem servir de inspiração criativa para especialistas em várias áreas:
Um modelo básico (como o GPT-5.2) é treinado com um monte de dados da internet pra aprender padrões gerais, raciocínio e estrutura da linguagem.
Um modelo ajustado pega essa base geral e treina ainda mais em um conjunto de dados menor e selecionado para dominar uma tarefa específica, como diagnóstico médico ou falar em uma linguagem de codificação específica. O aperfeiçoamento troca uma grande versatilidade por um conhecimento mais profundo em uma área específica.
Agora que já falamos sobre o básico, vamos ver algumas perguntas intermediárias sobre IA generativa para entrevistas.
Assim como um criador de conteúdo que descobre que um certo formato de vídeo gera mais alcance e interações, o modelo generativo de uma GAN pode acabar ficando preso a uma diversidade limitada de resultados que enganam o modelo discriminador. Isso faz com que o gerador produza um pequeno conjunto de resultados, prejudicando a diversidade e a flexibilidade dos dados gerados.
Algumas soluções possíveis pra isso podem ser focar em técnicas de treinamento, ajustando os hiperparâmetros e vários algoritmos de otimização, aplicando regularizações que promovam a diversidade ou combinando vários geradores pra cobrir diferentes modos de gerar dados.
Um Autoencoder Variacional (VAE) é um tipo de modelo generativo que aprende a codificar dados de entrada em um espaço latente e decodificá-los de volta para reconstruir os dados de entrada originais. VAEs são modelos codificadores-decodificadores:
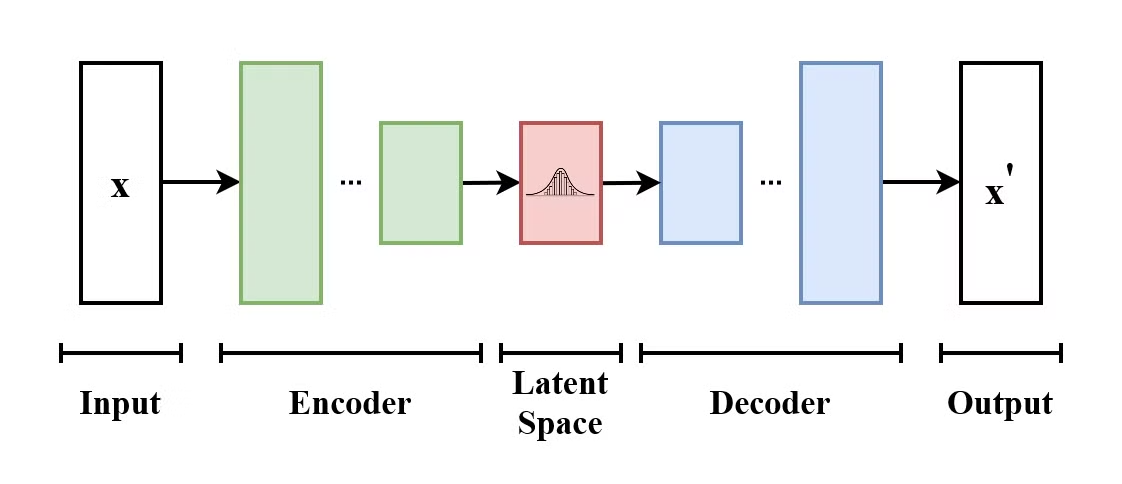
A estrutura de um Autoencoder Variacional. (Fonte: Wikimedia Commons)
O que faz os VAEs diferentes dos autoencoders tradicionais é que o VAE incentiva o espaço latente a seguir uma distribuição conhecida (como a gaussiana). Isso faz com que sejam mais úteis para gerar novos dados por meio da amostragem desse espaço latente.
O RAG ( ) conecta um modelo a fontes de dados externas (como o wiki da sua empresa) para buscar informações atualizadas sem precisar treinar o modelo de novo. Os parâmetros do modelo continuam os mesmos; ele só tem acesso a dados adicionais.
O ajuste fino mexe nos pesos internos do modelo pra mudar como ele fala, age ou raciocina, mas não é legal pra adicionar novos conhecimentos factuais.
Use o RAG quando precisar de informações atualizadas (notícias, dados de empresas privadas) ou uma citação específica. Use o ajuste fino quando precisar que o modelo aprenda um novo “comportamento”, idioma ou formato de saída específico (por exemplo, falar em código SQL).
Avaliar as amostras geradas é uma tarefa complicada que depende do tipo de dados (imagem, texto, vídeo, etc.). Ttexto tradicional métricas, como a precisão, não são suficientes para tarefas criativas, porque só verificam a sobreposição de palavras, e não o significado.
Os benchmarks e rankings do LLM usam testes padronizados para medir o desempenho de um modelo em uma determinada tarefa. Eles são úteis para comparar modelos e para programar o progresso dentro ou entre modalidades.
LLM-as-a-Judge é uma estrutura de avaliação moderna em que um modelo “professor” super capaz (como o Gemini 3) avalia os resultados de um modelo menor com base em critérios específicos, incluindo fidelidade, utilidade e tom. Isso oferece uma maneira escalável de aproximar as preferências humanas sem a lentidão e o custo da revisão manual.
Melhorar a estabilidade e a convergência do treinamento GAN é importante para evitar o colapso do modo, garantir um treinamento eficiente e alcançar bons resultados. Aqui estão algumas técnicas para melhorar a estabilidade e a convergência do treinamento GAN:
Tem várias técnicas comuns pra controlar o estilo das saídas da GenAI:
Garantir que o modelo seja imparcial e justo requer ajustes e monitoramento contínuos em cada fase.
Primeiro, é preciso evitar a contaminação dos dados, garantindo que nenhum dado de teste vaze para os dados de treinamento. Nesse caso, o modelo seria treinado para memorizar os dados, em vez de generalizá-los.
Além disso, temos que garantir que os dados de treinamento sejam o mais variados e inclusivos possível. Durante o treinamento, podemos orientar o modelo para uma geração mais justa, incorporando objetivos de justiça na função de perda.
Os resultados do modelo devem ser monitorados regularmente para verificar se há algum viés. Para ganhar a confiança do público, é legal deixar o processo de tomada de decisão do modelo, os detalhes do conjunto de dados e as etapas de pré-processamento o mais transparentes possível.
No contexto dos modelos generativos, o espaço latente é um espaço de dimensão inferior que capta as características essenciais dos dados de forma que entradas semelhantes sejam mapeadas mais próximas umas das outras. A amostragem desse espaço latente permite que os modelos criem novos dados e mexam em atributos ou características específicas (gerando variações de imagens).
Os espaços latentes são essenciais para gerar resultados que sejam controláveis, fiéis aos dados de treinamento e diversificados.
A ideia principal por trás do aprendizado auto-supervisionado é usar um monte de dados sem rótulos para aprender representações úteis sem precisar rotular manualmente. Modelos como BERT e GPT são treinados por métodos auto-supervisionados, como previsão do próximo token e aprendizado da estrutura e da semântica das línguas. Isso reduz a dependência de dados rotulados, que são caros e demorados de se obter, permitindo essencialmente que os modelos aproveitem vastos conjuntos de dados não rotulados para treinamento.
Treinar de novo um modelo enorme com 70 bilhões de parâmetros é muito caro e demorado para a maioria das organizações. A Adaptação de Baixo Rank (LoRA) resolve isso congelando os pesos do modelo principal e treinando apenas uma pequena camada “adaptadora” (geralmente menos de 1% do total de parâmetros) que fica na parte superior. Isso permite que você ofereça várias versões “personalizadas” a partir de um único modelo básico, reduzindo bastante o custo computacional e as necessidades de armazenamento.
Pra quem tá procurando cargos mais seniores ou quer mostrar que entende bem de IA Generativa, vamos ver algumas perguntas avançadas pra entrevista.
Os modelos de difusão funcionam principalmente adicionando ruído gradualmente a uma imagem até que só reste ruído — e, em seguida, aprendendo como reverter esse processo para gerar novas amostras a partir do ruído. Esse processo é chamado dedifusão e e. Esses modelos ficaram famosos por conseguirem imagens de alta qualidade e superdetalhadas.

Criação de uma imagem por meio de etapas de difusão. (Fonte: Wikimedia Commons)
O processo de treinamento desses modelos tem duas etapas:
Diferente das GANs mais antigas, que muitas vezes tinham problemas de instabilidade no treinamento, os modelos de difusão são mais estáveis e escaláveis, embora possam ser mais lentos por causa da sua natureza iterativa.
Variantes modernas, como a difusão latente, funcionam num “espaço latente” compactado para acelerar a geração, e as arquiteturas de correspondência de fluxo estão agora substituindo a difusão padrão para um desempenho ainda melhor.
A arquitetura do transformador apresentada no artigo “Attention is All You Need”, revolucionou o campo da IA generativa, especialmente no processamento de linguagem natural (NLP).
Diferente das redes neurais recorrentes (RNNs) tradicionais, que processam dados de forma sequencial, os transformadores usam o mecanismo de autoatenção para atribuir pesos a diferentes partes dos dados de entrada ao mesmo tempo. Isso permite que o modelo capte relações contextuais de forma eficaz e possibilita o processamento paralelo de sequências, o que acelera significativamente o treinamento.
O principal problema é que esse mecanismo de atenção cresce de forma quadrática com o comprimento da sequência — dobrar a janela de contexto exige quatro vezes mais computação. Isso torna o “contexto infinito” teoricamente possível, mas computacionalmente caro, levando a pesquisas sobre métodos de atenção mais eficientes.
Os LLMs padrão funcionam como pensadores do “Sistema 1”, prevendo a próxima palavra imediatamente com base em padrões superficiais.
Modelos de raciocínio (como Gemini 3 ou DeepSeek-R1) são treinados para criar uma “cadeia de pensamentos” escondida antes de dar uma resposta, o que permite que eles “pensem”, planejem e corrijam seus próprios erros. Isso faz com que eles sejam bem melhores em matemática complexa, programação e quebra-cabeças lógicos, embora sejam mais lentos e caros de operar.
À medida que você aumenta a complexidade da geração de IA, você também deve lidar com:
O campo da GenAI está evoluindo e se transformando rapidamente. Isso inclui:
Projetar um sistema que usa IA generativa para casos de uso específicos do setor é uma abordagem completa. As diretrizes gerais também podem ser ajustadas e modificadas em outros setores.
A aprendizagem contextual refere-se à capacidade dos LLMs de modificar seu estilo e resultados com base no contexto fornecido, sem a necessidade de ajustes adicionais.
Também pode ser chamado de aprendizado com poucos exemplos ou engenharia de prompt. Isso pode ser feito especificando um ou vários exemplos da resposta desejada ou descrevendo claramente como o modelo deve se comportar.
A aprendizagem contextual também tem suas limitações. É de curto prazo e específico para cada tarefa, já que o modelo não retém nenhum conhecimento em outras sessões de uso dessa técnica.
Além disso, se o resultado esperado for complexo, o modelo pode precisar de um monte de exemplos. Se os exemplos fornecidos não forem claros o suficiente ou a tarefa for mais difícil do que o modelo consegue lidar, ele pode, às vezes, gerar resultados incorretos ou incoerentes.
O prompt é importante para orientar os LLMs a responder a tarefas específicas. Prompts eficazes podem até diminuir a necessidade de ajustar modelos usando técnicas como aprendizado com poucos exemplos, decomposição de tarefas e modelos de prompts.
Algumas melhores práticas para uma engenharia eficaz e rápida incluem:
Leia mais neste blog sobre Técnicas de otimização de prompt.
A geração condicional envolve o modelo gerando resultados com base em certas condições ou contextos. Isso permite um maior controle sobre o conteúdo gerado. Nas GANs condicionais (cGANs), tanto o gerador quanto o discriminador são condicionados por informações adicionais, como rótulos de classe. Funciona assim:
A Mistura de Especialistas (MoE) substitui uma única rede neural densa por várias sub-redes “especializadas”. Para qualquer token, um roteador escolhe só os especialistas mais relevantes para processar os dados, ou seja, um modelo pode ter 100 bilhões de parâmetros, mas usar só 10 bilhões para inferência.
Essa arquitetura permite que os modelos sejam super inteligentes (alto número total de parâmetros), mas continuem rápidos e baratos de rodar (baixo número de parâmetros ativos).
Se você estiver sendo entrevistado para uma vaga de engenheiro de IA com foco em IA generativa, espere perguntas que avaliem sua capacidade de projetar, implementar e implantar modelos generativos.
Um chatbot padrão é passivo: ele recebe uma pergunta e responde com um texto baseado no que aprendeu.
Um fluxo de trabalho agênico dá ao LLM acesso a ferramentas (como um navegador da web, interpretador de código ou API) e a autonomia para planejar um processo de várias etapas para resolver um objetivo. O agente pode planejar pesquisar na web, analisar os dados com código Python e, em seguida, escrever um relatório, repetindo o processo até que a tarefa seja concluída.
Garantir a segurança e a robustez dos LLMs traz vários desafios. Um dos principais desafios é a possibilidade de gerar resultados prejudiciais ou tendenciosos, já que esses modelos são treinados com fontes de dados enormes ou até mesmo sem filtragem e podem produzir conteúdo tóxico ou enganoso.
Outro problema importante com o conteúdo gerado por LLM é o risco de alucinação, em que o modelo gera conteúdo que parece confiável, mas que, na verdade, contém informações incorretas. Outro desafio é a segurança contra prompts adversários que violam as medidas de segurança do modelo e produzem respostas prejudiciais ou antiéticas, como já foi comprovado várias vezes em relação a vários modelos.
Incorporar filtros de segurança e camadas de moderação pode ajudar a identificar e remover conteúdo prejudicial que está sendo gerado. A supervisão humana contínua melhora ainda mais a segurança do modelo.
Além disso, os engenheiros precisam implementar proteções explícitas (como NeMo Guardrails ou Llama Guard) que ficam entre o usuário e o modelo. Esses sistemas verificam as entradas para bloquear tentativas de injeção de prompt ou vazamento de PII (Informações de Identificação Pessoal) e verificam as saídas para detectar respostas tóxicas ou alucinatórias antes que elas cheguem ao usuário. Isso cria uma camada de segurança determinística que funciona de forma independente da natureza probabilística do modelo.
A resposta a essa pergunta depende muito dos seus projetos e experiências. Mas dá pra ter isso em mente quando responder perguntas assim:
Assim como a pergunta acima, essa pergunta pode ser respondida com base na sua experiência, mas também tendo em mente que:
Mesmo com janelas de contexto enormes (por exemplo, 1 milhão de tokens), os LLMs muitas vezes têm dificuldade em recuperar informações escondidas no meio do prompt, priorizando o início e o fim.
Os engenheiros resolvem isso usando algoritmos inteligentes de reclassificação que movem os trechos mais importantes para o começo ou o fim da janela de contexto. Outra estratégia é o algoritmo “map-reduce”, em que o modelo resume partes do documento longo de forma independente antes de juntá-las para chegar a uma resposta final.
Construir um sistema RAG precisa de uma abordagem sistemática. Aqui está como o pipeline poderia ser:
A resposta depende também das suas preferências pessoais, mas aqui estão alguns tópicos que você pode mencionar:
Como a IA generativa está encontrando maneiras de influenciar vários aspectos de nossas vidas e carreiras, é vital manter um olhar curioso sobre os tópicos essenciais. Embora as possíveis perguntas sobre IA genérica que podem ser feitas durante uma entrevista dependam da função e da empresa específicas, tentei selecionar 30 perguntas e respostas para ajudá-lo a começar a se preparar para a entrevista.
Pra ver mais perguntas de entrevista, recomendo esses blogs:
Aprenda IA com esses cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
14 min
blog
Adel Nehme
15 min
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Matt Crabtree
8 min
blog
Abid Ali Awan
11 min



