
Programma
Nozioni di base sull'intelligenza artificiale
10 h
Partiamo da alcune domande fondamentali sull’IA generativa. Queste verificano la tua comprensione dei concetti e dei principi chiave.
I modelli discriminativi apprendono il confine decisionale tra le classi e i pattern che le differenziano. Stimano la probabilità P(y|x), cioè la probabilità di un’etichetta specifica y dato l’input x. Questi modelli si concentrano nel distinguere tra categorie diverse (ad es. “Questa email è spam?”).
I modelli generativi apprendono la distribuzione dei dati stessi modellando la probabilità congiunta P(x,y), che implica il campionamento di punti dati da questa distribuzione. Dopo l’addestramento su migliaia di immagini di cifre, tale campionamento può produrre una nuova immagine di una cifra.
Leggi di più in questo blog su Modelli generativi vs discriminativi: differenze e casi d’uso.
I token sono le unità fondamentali di testo che un LLM elabora; possono essere parole intere, sillabe o persino singole lettere (per esempio, la parola "generative" potrebbe essere suddivisa in "gener", "at", "ive").
Gli embedding sono rappresentazioni vettoriali numeriche di quei token che li collocano in uno spazio multidimensionale in base al loro significato. Questa conversione consente al modello di cogliere il significato semantico e comprendere le relazioni tra le parole, ad esempio riconoscendo che "king" è vicino a "queen".
Le GAN sono composte da due reti neurali che competono tra loro (da qui il termine Adversarial): un generatore e un discriminatore.
Il generatore crea campioni di dati falsi mentre il discriminatore li valuta rispetto ai dati reali di training. Le due reti vengono addestrate simultaneamente:
Attraverso questo apprendimento competitivo, il generatore diventa abile nel produrre dati altamente realistici simili a quelli di training.
L’ampio uso della GenAI e dei suoi casi d’uso richiede una valutazione accurata delle prestazioni in termini di etica. Alcuni esempi includono:
Sebbene le allucinazioni dei modelli di IA possano produrre output errati, questi modelli generativi sono utili in molti ambiti e usi. Possono essere impiegati come fonte di ispirazione creativa per esperti in vari campi:
Un Foundation Model (come GPT-5.2) è addestrato su enormi quantità di dati generici dal web per apprendere pattern generali, ragionamento e struttura del linguaggio.
Un modello Fine-Tuned parte da questa base generalista e viene addestrato ulteriormente su un dataset più piccolo e curato per padroneggiare un compito specifico, come la diagnosi medica o parlare in un particolare linguaggio di programmazione. Il fine-tuning scambia la versatilità ampia con una competenza più profonda in un dominio specifico.
Ora che abbiamo coperto le basi, esploriamo alcune domande intermedie sull’IA generativa.
Così come un creator che scopre che un certo formato di video porta più visibilità e interazioni, il modello generativo di una GAN può fissarsi su una limitata varietà di output che ingannano il discriminatore. Il risultato è che il generatore produce un insieme ridotto di output, a scapito della diversità e della flessibilità dei dati generati.
Possibili soluzioni includono concentrarsi sulle tecniche di training regolando iperparametri e algoritmi di ottimizzazione, applicare regolarizzazioni che promuovano la diversità o combinare più generatori per coprire modalità diverse di generazione dei dati.
Un Variational Autoencoder (VAE) è un tipo di modello generativo che impara a codificare i dati di input in uno spazio latente e a decodificarli per ricostruire l’input originale. I VAE sono modelli encoder-decoder:
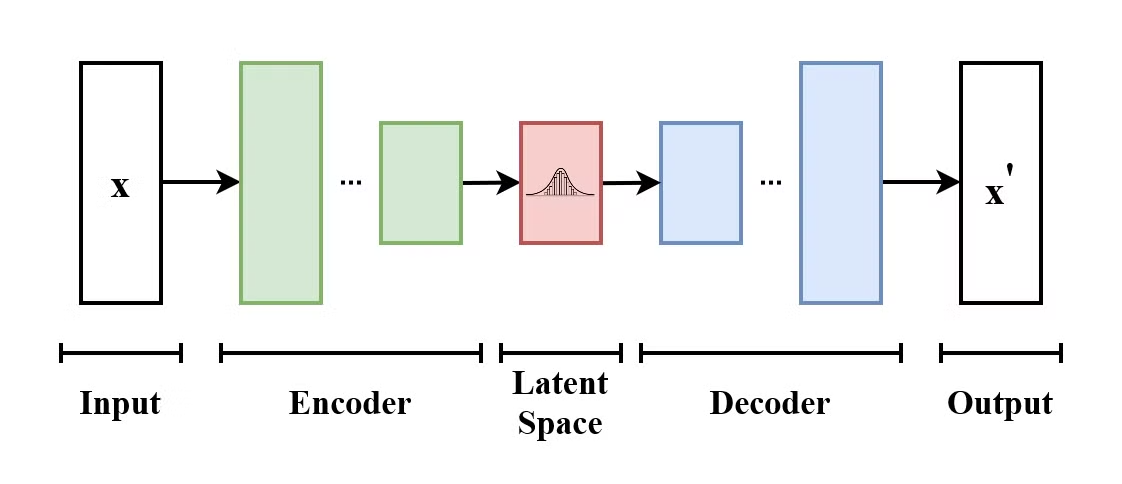
La struttura di un Variational Autoencoder. (Fonte: Wikimedia Commons)
La differenza rispetto agli autoencoder tradizionali è che il VAE incoraggia lo spazio latente a seguire una distribuzione nota (come la gaussiana). Questo li rende più utili per generare nuovi dati campionando da questo spazio latente.
RAG collega un modello a fonti di dati esterne (come la wiki aziendale) per recuperare fatti aggiornati senza riaddestrare il modello. I parametri del modello restano invariati; ha semplicemente accesso a dati aggiuntivi.
Il fine-tuning modifica i pesi interni del modello per cambiare come parla, si comporta o ragiona, ma non è adatto ad aggiungere nuove conoscenze fattuali.
Usa RAG quando ti servono fatti aggiornati (notizie, dati aziendali privati) o una citazione specifica. Usa il fine-tuning quando vuoi che il modello apprenda un nuovo “comportamento”, linguaggio o formato di output specifico (ad es. parlare in SQL).
Valutare i campioni generati è un compito complesso che dipende dalla modalità dei dati (immagine, testo, video, ecc.). Le tradizionali metriche testuali, come l’accuratezza, sono insufficienti per compiti creativi perché verificano solo la sovrapposizione di parole, non il significato.
Benchmark e classifiche LLM usano test standardizzati per misurare quanto bene un modello gestisce un dato compito. Sono utili per confrontare i modelli e tracciare i progressi all’interno o tra modalità.
LLM-as-a-Judge è un framework di valutazione moderno in cui un modello “insegnante” molto capace (come Gemini 3) valuta gli output di un modello più piccolo in base a criteri specifici, inclusi aderenza ai fatti, utilità e tono. Fornisce un modo scalabile per approssimare le preferenze umane senza la lentezza e i costi della revisione manuale.
Migliorare stabilità e convergenza è importante per evitare il mode collapse, garantire un training efficiente e ottenere buoni risultati. Ecco alcune tecniche utili:
Esistono diverse tecniche comuni per controllare lo stile degli output GenAI:
Garantire che il modello sia imparziale ed equo richiede aggiustamenti e monitoraggio iterativi in ogni fase.
Innanzitutto, bisogna prevenire la contaminazione dei dati assicurandosi che i dati di test non finiscano in training. In tal caso, il modello imparerebbe a memorizzare i dati anziché generalizzarli.
Inoltre, dobbiamo garantire che i dati di training siano il più possibile diversificati e inclusivi. Durante l’addestramento, possiamo guidare il modello verso una generazione più equa incorporando obiettivi di fairness nella funzione di perdita.
Gli output del modello devono essere regolarmente monitorati per individuare bias. Per costruire fiducia pubblica, aiuta rendere il più trasparente possibile il processo decisionale del modello, i dettagli del dataset e gli step di pre-processing.
Nel contesto dei modelli generativi, lo spazio latente è uno spazio a dimensionalità inferiore che cattura le caratteristiche essenziali dei dati in modo che input simili vengano mappati più vicini tra loro. Campionare da questo spazio consente ai modelli di generare nuovi dati e manipolare attributi o caratteristiche specifiche (generando variazioni di immagini).
Gli spazi latenti sono fondamentali per generare output controllabili, fedeli ai dati di training e diversificati.
L’idea chiave del self-supervised learning è sfruttare un vasto corpus di dati non etichettati per apprendere rappresentazioni utili senza bisogno di annotazioni manuali. Modelli come BERT e GPT sono addestrati con metodi self-supervised come la predizione del token successivo, apprendendo struttura e semantica delle lingue. Questo riduce la dipendenza da dati etichettati, costosi e lenti da ottenere, consentendo di fatto di sfruttare enormi dataset non etichettati per l’addestramento.
Riaddestrare un modello enorme da 70 miliardi di parametri è proibitivamente costoso e lento per la maggior parte delle organizzazioni. Low-Rank Adaptation (LoRA) risolve congelando i pesi del modello principale e addestrando solo un piccolo livello “adapter” (spesso meno dell’1% dei parametri totali) che si sovrappone. Ciò consente di servire dozzine di modelli “custom” partendo da un unico modello base, riducendo drasticamente costi computazionali e necessità di storage.
Per chi punta a ruoli più senior o vuole dimostrare una comprensione profonda della GenAI, esploriamo alcune domande avanzate.
I modelli di diffusione operano aggiungendo gradualmente rumore a un’immagine finché non resta solo rumore—per poi imparare a invertire questo processo per generare nuovi campioni a partire dal rumore. Questo processo è detto diffusione. Questi modelli sono popolari per la capacità di produrre immagini di alta qualità e molto dettagliate.

Generazione di un’immagine attraverso step di diffusione. (Fonte: Wikimedia Commons)
Il training di questi modelli include due step:
A differenza delle vecchie GAN, spesso affette da instabilità nel training, i modelli di diffusione sono più stabili e scalabili, sebbene possano essere più lenti per via della natura iterativa.
Varianti moderne come la diffusione latente operano in uno “spazio latente” compresso per accelerare la generazione, e le architetture di flow matching stanno sostituendo la diffusione standard per prestazioni ancora migliori.
L’architettura transformer introdotta nell’articolo “Attention is All You Need” ha rivoluzionato il campo dell’IA generativa, in particolare nell’elaborazione del linguaggio naturale (NLP).
A differenza delle RNN tradizionali, che elaborano i dati in modo sequenziale, i transformer usano il meccanismo di self-attention per attribuire pesi a diverse parti dell’input simultaneamente. Ciò consente al modello di catturare efficacemente le relazioni contestuali e di elaborare in parallelo le sequenze, accelerando notevolmente l’addestramento.
Il principale collo di bottiglia è che questo meccanismo di attenzione scala quadraticamente con la lunghezza della sequenza—raddoppiare la context window richiede quattro volte il compute. Ciò rende l’“infinite context” teoricamente possibile ma computazionalmente costoso, spingendo la ricerca verso metodi di attenzione più efficienti.
Gli LLM standard agiscono come pensatori “Sistema 1”, prevedendo immediatamente la parola successiva basandosi su pattern superficiali.
I Reasoning Model (come Gemini 3 o DeepSeek-R1) sono addestrati a generare una “Chain of Thought” nascosta prima di fornire una risposta, permettendo loro di “pensare”, pianificare e autocorreggere gli errori. Questo li rende notevolmente migliori in matematica complessa, coding e rompicapi logici, sebbene siano più lenti e costosi da eseguire.
Aumentando la complessità della generazione con l’IA, dovresti anche affrontare:
Il campo della GenAI si evolve e si ridefinisce rapidamente. Questo include:
Progettare un sistema che usi la GenAI per casi d’uso specifici di settore richiede un approccio accurato. Le linee guida generali possono essere adattate e modificate anche per altri settori.
L’in-context learning è la capacità degli LLM di modificare stile e output in base al contesto fornito senza necessità di ulteriore fine-tuning.
Può essere chiamato anche few-shot learning o prompt engineering. Si ottiene specificando uno o più esempi della risposta desiderata o descrivendo chiaramente come il modello dovrebbe comportarsi.
L’in-context learning ha anche limitazioni. È a breve termine e specifico del compito, poiché il modello non “trattiene” realmente la conoscenza in altre sessioni di utilizzo di questa tecnica.
Inoltre, se l’output richiesto è complesso, il modello potrebbe aver bisogno di molti esempi. Se gli esempi non sono abbastanza chiari o il compito è più difficile di quanto il modello possa gestire, talvolta può generare output errati o incoerenti.
Il prompting è importante per indirizzare gli LLM a svolgere compiti specifici. Prompt efficaci possono persino ridurre la necessità di fine-tuning usando tecniche come few-shot learning, scomposizione del compito e template di prompt.
Alcune best practice per un prompt engineering efficace includono:
Leggi di più in questo blog su Tecniche di ottimizzazione dei prompt.
La Generazione Condizionata prevede che il modello generi output basandosi su determinate condizioni o contesti. Questo consente un maggiore controllo sui contenuti generati. Nelle Conditional GAN (cGAN), sia il generatore che il discriminatore sono condizionati da informazioni aggiuntive, come le etichette di classe. Funziona così:
La Mixture of Experts (MoE) sostituisce una singola rete neurale densa con molte sotto-reti specializzate “expert”. Per ogni token, un router seleziona solo gli expert più rilevanti per elaborare i dati, per cui un modello può avere 100 miliardi di parametri ma usarne solo 10 miliardi in inferenza.
Questa architettura consente ai modelli di essere estremamente intelligenti (alto numero totale di parametri) restando al contempo veloci ed economici da eseguire (basso numero di parametri attivi).
Se stai sostenendo un colloquio per un ruolo di AI engineering con focus sulla GenAI, aspettati domande che valutino la tua capacità di progettare, implementare e mettere in produzione modelli generativi.
Un chatbot standard è passivo: riceve una richiesta e restituisce una risposta testuale in base al suo training.
Un workflow agentico dà all’LLM accesso a strumenti (come un browser web, un interprete di codice o un’API) e l’autonomia di pianificare un processo multi-step per raggiungere un obiettivo. L’agente può pianificare di cercare sul web, analizzare i dati con codice Python e poi scrivere un report, iterando finché il compito non è completato.
Garantire sicurezza e robustezza degli LLM comporta diverse sfide. Una primaria riguarda il potenziale di generare output dannosi o distorti, poiché questi modelli sono addestrati su fonti ampie o persino non filtrate e possono produrre contenuti tossici o fuorvianti.
Un altro problema rilevante dei contenuti generati dagli LLM è il rischio di allucinazione, quando il modello genera contenuti con tono sicuro che però sono informazioni errate. Un’ulteriore sfida è la sicurezza contro prompt avversari che violano le misure di sicurezza del modello e producono risposte dannose o non etiche, come dimostrato più volte su vari modelli.
Integrare filtri di sicurezza e livelli di moderazione può aiutare a individuare e rimuovere contenuti dannosi generati. Un monitoraggio continuo con human-in-the-loop migliora ulteriormente la sicurezza del modello.
Inoltre, gli ingegneri devono implementare espliciti Guardrail (come NeMo Guardrails o Llama Guard) che si interpongono tra utente e modello. Questi sistemi analizzano gli input per bloccare tentativi di prompt injection o fuoriuscita di PII (dati personali identificabili) e analizzano gli output per intercettare risposte tossiche o allucinatorie prima che raggiungano l’utente. Questo crea un livello di sicurezza deterministico che opera indipendentemente dalla natura probabilistica del modello.
La risposta è molto soggettiva rispetto ai tuoi progetti ed esperienze. Puoi però tenere a mente questi punti quando rispondi a domande simili:
Come per la domanda precedente, puoi rispondere in base alla tua esperienza, tenendo però a mente di:
Anche con context window enormi (ad es. 1 milione di token), gli LLM spesso faticano a recuperare informazioni sepolte nel mezzo del prompt, dando priorità a inizio e fine.
Gli ingegneri mitigano con algoritmi di re-ranking intelligenti che spostano i chunk recuperati più critici all’inizio o alla fine della finestra di contesto. Un’altra strategia è l’algoritmo “map-reduce”, in cui il modello riassume sezioni del documento lungo in modo indipendente prima di combinarle per una risposta finale.
Costruire un sistema RAG richiede un approccio sistematico. Ecco come potrebbe essere la pipeline:
La risposta qui dipende dalle preferenze personali, ma ecco alcuni temi che puoi menzionare:
Poiché l’IA generativa sta trovando modi per influenzare vari aspetti delle nostre vite e carriere, è vitale mantenere uno sguardo curioso sugli argomenti essenziali. Sebbene le possibili domande su GenAI in un colloquio dipendano dallo specifico ruolo e dall’azienda, ho cercato di raccogliere 30 domande e risposte per aiutarti a iniziare la preparazione.
Per esplorare altre domande da colloquio, consiglio questi blog:
Impara l’IA con questi corsi!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

