
Program
AI Temelleri
10 sa
Büyük dil modelleri (LLM'ler) yapay zekâda giderek daha önemli hale geldi ve çeşitli sektörlerde uygulama alanı buldu.
LLM uzmanlığına sahip profesyonellere olan talep arttıkça, bu makale temel kavramları, ileri teknikleri ve pratik uygulamaları kapsayan kapsamlı bir mülakat soru ve cevap seti sunar.
Bir iş görüşmesine hazırlanıyor ya da yalnızca bilginizi genişletmek istiyorsanız, bu makale işinize yarayacaktır.
LLM'leri anlamak için temel kavramlarla başlamak önemlidir. Bu temeller, mimari, kilit mekanizmalar ve tipik zorluklar gibi önemli yönleri kapsar ve daha ileri konuları öğrenmek için sağlam bir temel sağlar.
Transformer mimarisi, Vaswani ve ark. tarafından 2017'de tanıtılan, sıralı verileri önceki modellere (tekrarlayan sinir ağları - RNN ve uzun-kısa süreli bellek - LSTM gibi) kıyasla daha verimli ve performanslı şekilde işlemek üzere tasarlanmış bir derin öğrenme modelidir.
Girdiyi paralel olarak işlemek için öz-dikkat (self-attention) mekanizmalarına dayanır; bu da onu yüksek ölçeklenebilir kılar ve uzun menzilli bağımlılıkları yakalayabilmesini sağlar.
LLM'lerde Transformer mimarisi, modellerin büyük miktarda metni verimli şekilde işlemesini ve bağlama uygun, tutarlı çıktılar üretmesini sağlayan omurgayı oluşturur.
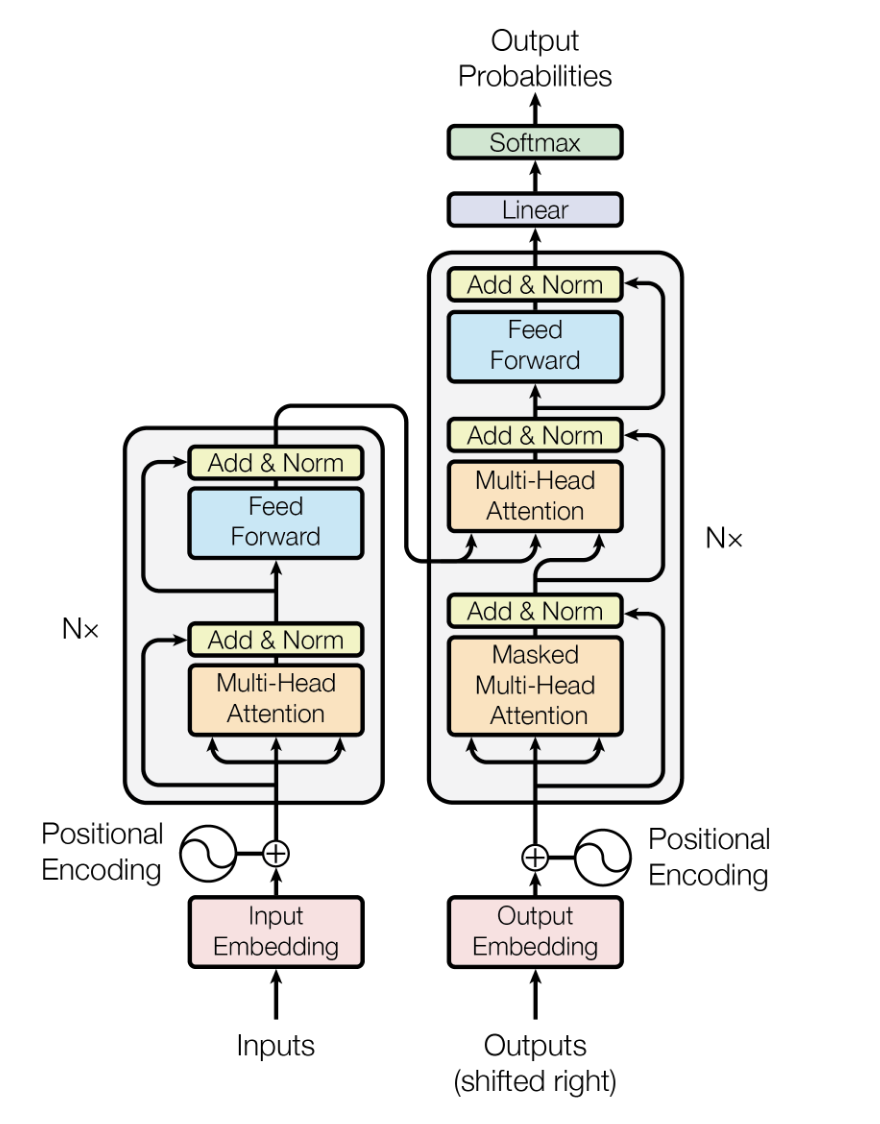
Transformer model mimarisi. Kaynak
LLM'lerdeki bağlam penceresi, modelin dil üretirken veya anlarken aynı anda dikkate alabileceği metin aralığını (token veya kelime cinsinden) ifade eder. Bağlam penceresinin önemi, modelin mantıklı ve ilgili yanıtlar üretebilme becerisi üzerindeki etkisinden kaynaklanır.
Genel olarak, daha büyük bir bağlam penceresi modelin daha fazla bağlamı dikkate almasını sağlar; bu da özellikle karmaşık veya uzun konuşmalarda daha iyi anlama ve metin üretimine yol açar. Ancak bu durum hesaplama gereksinimlerini de artırır; dolayısıyla performans ve verimlilik arasında bir denge gerekir.
Ayrıca, son araştırmalar birçok modelin ilan edilen sınırlarına gelmeden çok önce performansının düştüğünü gösteriyor. Modeller, bağlamın ortasındaki bilginin göz ardı edildiği veya arka plana itildiği "arada kaybolma" olgusunu sergileyebilir. Bu nedenle, özenle seçilmiş, ilgili bağlamın küçük pencerelerde kullanılması, büyük pencereleri gürültüyle doldurmaktan çoğu zaman daha iyi sonuç verir.
LLM'ler için yaygın ön eğitim hedefleri maskeleme tabanlı dil modelleme (MLM) ve otoregresif dil modellemedir. MLM'de bir cümledeki rastgele kelimeler maskelenir ve modelden, çevreleyen bağlama dayanarak bu maskelenmiş kelimeleri tahmin etmesi istenir. Bu, modelin iki yönlü bağlamı anlamasına yardımcı olur.
Otoregresif dil modellemede, model bir dizideki bir sonraki kelimeyi tahmin eder ve metni her seferinde bir token üretecek şekilde eğitilir. Her iki hedef de modelin büyük metin derlemelerinden dil kalıplarını ve anlamsal yapıları öğrenmesini sağlar ve belirli görevlere ince ayar için sağlam bir temel sunar.
İnce ayar, önceden eğitilmiş bir modelin alınarak daha küçük ve göreve özgü bir veri kümesi üzerinde yeniden eğitilmesidir. Bu süreç, modelin genel dil anlayışını belirli uygulamanın nüanslarına uyarlamasına yardımcı olur ve performansı artırır.
Bu, ön eğitim sırasında edinilen geniş dil bilgisinden yararlanırken modeli duygu analizi, metin özetleme veya soru-cevap gibi belirli uygulamalarda iyi performans gösterecek şekilde uyarladığı için önemli bir tekniktir.
LLM kullanımı çeşitli zorluklar içerir, örneğin:
LLM'ler, Byte Pair Encoding (BPE) ve WordPiece gibi alt birim (subword) tokenleştirme tekniklerini kullanarak sözlük dışı (OOV) kelime veya tokenları ele alır. Bu teknikler, bilinmeyen kelimeleri modelin işleyebileceği daha küçük, bilinen alt birimlere böler.
Bu yaklaşım, bir kelime eğitim sırasında görülmemiş olsa bile modelin, parçalarına dayanarak metni anlayıp üretebilmesini sağlar; böylece esneklik ve sağlamlık artar.
Gömme katmanları, kelime gibi kategorik verileri yoğun vektör temsillerine dönüştürmek için LLM'lerde kullanılan önemli bir bileşendir. Bu gömmeler, kelimeleri benzer kelimelerin daha yakın konumlandığı sürekli bir vektör uzayında temsil ederek aralarındaki anlamsal ilişkileri yakalar. LLM'lerde gömme katmanlarının önemi şunları içerir:
Konumsal kodlamalar, transformerlara her tokenın dizide nerede bulunduğunu söyler.
Geleneksel sinüzoidal konumsal kodlamalar (Vaswani ve ark., 2017), konumları statik olarak kodlamak için sabit matematiksel fonksiyonlar kullanırdı. Daha yakın zamanda tanıtılan Rotary Position Embeddings (RoPE), temelde üstün özellikler sunduğu için modern LLM'lerde standart haline geldi.
RoPE, konumları karmaşık vektör uzayında dönme açıları olarak temsil ederek, token gömmelerini konumlarına orantılı bir açıyla döndürerek çalışır. Bu geometrik yaklaşım daha verimlidir ve eğitim sırasında görülenlerden daha uzun dizilere doğal olarak enterpolasyon yapmayı destekler; bu da bağlam pencerelerini genişletmek için kritik bir yetenektir. GPT-5.2 ve Gemini 3 gibi modeller, konumsal kodlama olarak RoPE kullanır.
Temel kavramların üzerine inşa edilen orta düzey sorular, LLM performansını optimize etmek için kullanılan pratik tekniklere ve hesaplama verimliliği ile model yorumlanabilirliğiyle ilgili zorluklara odaklanır.
LLM'lerde dikkat kavramı, modelin tahmin yaparken girdi dizisinin farklı bölümlerine odaklanmasına olanak tanıyan bir yöntemdir. Girdideki diğer tokenlara dinamik olarak ağırlıklar atar ve mevcut görev için en ilgili olanları öne çıkarır.
Bu, öz-dikkat kullanılarak uygulanır; model, dizideki her token için diğer tüm tokenlara göre dikkat skorları hesaplar ve böylece mesafeden bağımsız olarak bağımlılıkları yakalayabilir.
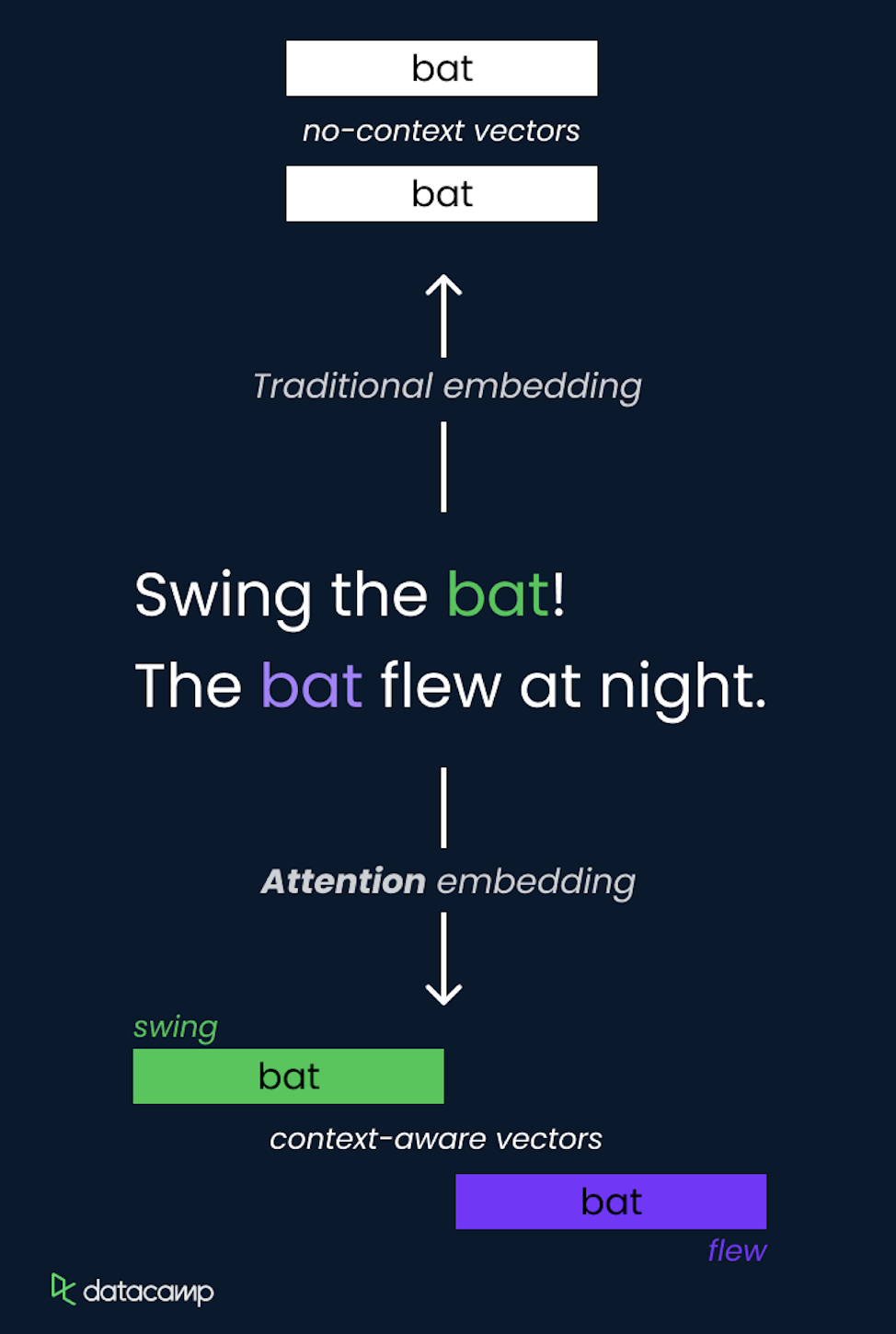
Öz-dikkat mekanizması, Transformer mimarisinin temel bir bileşenidir; bilgiyi verimli işlemeyi ve uzun menzilli ilişkileri yakalamayı sağlar.
Tokenleştirme, ham metni kelime, alt birim veya karakter olabilen daha küçük birimlere (tokenlara) dönüştürür.
LLM işleminde tokenleştirmenin rolü kritiktir, çünkü metni modelin anlayıp işleyebileceği bir formata dönüştürür.
Etkili tokenleştirme, nadir kelimeler ve farklı diller dâhil olmak üzere çok çeşitli girdilerin yönetilebilir parçalara ayrılmasını sağlayarak modelin bunlarla başa çıkabilmesini temin eder. Bu adım, girdi standardizasyonu sağlar ve modelin veride anlamlı kalıpları öğrenmesine yardımcı olduğu için eğitim ve çıkarımda (inference) gereklidir.
Araştırmacılar ve uygulayıcılar, bir LLM'in performansını ölçmek için çok sayıda değerlendirme metriği geliştirmiştir. Klasik metrikler şunlardır:
Geleneksel metriklerin ötesinde, uygulayıcılar artık farklı amaçlar için standartlaştırılmış kıyaslamalar kullanıyor; örneğin MMLU (57 görevli bilgi testi), MMMU-Pro (çok modlu akıl yürütme) ve HumanEval (kod üretimi). Ayrıca, LMArena gibi liderlik tabloları LLM'leri insan tercihlerine göre sıralar. Yayına alınmış sistemlerde, gerçek dünyadaki halüsinasyon oranlarını, gecikmeyi ve token verimliliğini ölçmek kritik hale gelmiştir.
Bir LLM'in çıktılarını kontrol etmek için çeşitli teknikler kullanılabilir, örneğin:
LLM'lerin hesaplama maliyetini azaltmak için şunları kullanabiliriz:
Model yorumlanabilirliği, bir LLM'in kararları nasıl aldığını anlamak için gereklidir; bu da güven inşa etmek, hesap verebilirliği sağlamak ve önyargıları tespit edip azaltmak açısından önemlidir. Yorumlanabilirlik farklı yaklaşımlarla sağlanabilir, örneğin:
LLM'ler, mimarileri sayesinde; özellikle de tüm tokenları aynı anda dikkate almalarını sağlayan öz-dikkat mekanizmasıyla uzun vadeli bağımlılıkları ele alır. Uzak tokenlara dikkat edebilme yeteneği, LLM'lerin uzun bağlamlar boyunca ilişkileri ve bağımlılıkları yakalamasına yardımcı olur.
Ayrıca, Transformer-XL ve Longformer gibi gelişmiş modeller, bağlam penceresini genişletmek ve daha uzun dizileri daha etkili şekilde yönetmek için özel olarak tasarlanmıştır; böylece uzun vadeli bağımlılıkların daha iyi ele alınması sağlanır.
Modern üretim modelleri, uzun vadeli bağımlılıkları ele almak ve genişleyen bağlam pencereleriyle bozulan performansı karşılamak için daha gelişmiş stratejiler kullanır; örneğin:
RAG, metin üretimi sırasında dış kaynaklardan ilgili bilgileri getirmek için getirme (retrieval) mekanizmalarını üretici modellerle birleştirir. Bu yaklaşım, doğrudan iki kritik LLM kısıtını ele alır: halüsinasyon ve bilginin güncelliği. Geleneksel RAG nispeten basit getirme ve üretim hatları kullanır; ancak "RAG 2.0" evresinde önemli ölçüde daha sofistike hale gelmiştir.
RAG 2.0'ın temel özellikleri şunlardır:
RAG 2.0, LLM'lerle birlikte kullanıldığında, temel modellere kıyasla üretim sistemlerinde halüsinasyon oranlarını %40-60 azaltır.
LLM'lerde ileri düzey kavramları anlamak, bu modellerin başarabileceklerinin sınırlarını zorlamak isteyen profesyoneller için faydalıdır. Bu bölüm, alandaki karmaşık konuları ve sık karşılaşılan zorlukları inceler.
Few-shot öğrenme, LLM'lerin yalnızca birkaç örnek kullanarak yeni görevleri öğrenip gerçekleştirme becerisini ifade eder. Bu yetenek, LLM'in kapsamlı ön eğitim bilgisinden yararlanarak az sayıdaki örnekten genelleme yapmasını sağlar.
Few-shot öğrenmenin başlıca avantajları; büyük göreve özgü veri kümelerine olan ihtiyacı en aza indirerek veri gereksinimlerini azaltması, modele minimum ince ayarla çeşitli görevlere uyum sağlama esnekliği kazandırması ve daha düşük veri gereksinimleri ile daha kısa eğitim sürelerinin veri toplama ve hesaplama kaynaklarında önemli maliyet tasarruflarına dönüşmesidir.
Otoregresif ve maskeleme tabanlı dil modelleri, ağırlıklı olarak tahmin yaklaşımları ve görev uygunlukları açısından farklılaşır. GPT-5.2, Claude 4.5 Opus ve Gemini 3 gibi otoregresif modeller, önceki kelimelere dayanarak bir dizideki bir sonraki kelimeyi tahmin eder ve metni her seferinde bir token üreterek oluşturur.
Bu modeller özellikle metin üretimi görevleri için uygundur. Buna karşılık, BERT gibi maskeleme tabanlı dil modelleri, bir cümledeki kelimeleri rastgele maskeler ve modelden, çevreleyen bağlama dayanarak bu maskelenmiş kelimeleri tahmin etmesini ister. Bu iki yönlü yaklaşım, modelin bağlamı her iki yönden de anlamasını sağlar ve onu metin sınıflandırma ve soru-cevap görevleri için ideal kılar.
Harici bilginin bir LLM'e dahil edilmesi birkaç yöntemle sağlanabilir:
LLM'leri üretime almak çeşitli zorluklar içerir:
Model bozulması, temel veri dağılımındaki değişiklikler nedeniyle bir LLM'in performansının zamanla düşmesi durumunda ortaya çıkar. Model bozulmasını ele almak için performansı korumak üzere güncellenmiş verilerle düzenli yeniden eğitim gerekir. Bozulma işaretlerini tespit etmek ve model performansını izlemek için sürekli izleme şarttır.
Artımlı öğrenme teknikleri, modelin daha önce öğrendiği bilgileri unutmadan yeni verilerden öğrenmesini sağlar. Ayrıca, A/B testleri mevcut modelin performansını yeni sürümlerle karşılaştırır ve tam yayına almadan önce potansiyel iyileştirmelerin belirlenmesine yardımcı olur.
LLM'lerin etik kullanımını sağlamak için çeşitli teknikler uygulanabilir:
LLM'lerle kullanılan verilerin güvenliğini sağlamak, çeşitli önlemlerin uygulanmasını gerektirir. Buna, yetkisiz erişime karşı koruma için beklemede ve aktarım sırasında verilerin şifrelenmesi dâhildir. Hassas verilere yalnızca yetkili personelin erişebilmesini sağlamak için sıkı erişim kontrolleri gereklidir.
Eğitim veya çıkarım öncesinde kişisel olarak tanımlanabilir bilgilerin (PII) kaldırılması için verilerin anonimleştirilmesi de kritiktir. Ayrıca GDPR veya CCPA gibi veri koruma düzenlemelerine uyum, hukuki sorunlardan kaçınmak için zorunludur.
Bu önlemler, veri bütünlüğünü, gizliliğini ve erişilebilirliğini korumaya yardımcı olur. Bu koruma, kullanıcı güvenini sürdürmek ve düzenleyici standartlara uymak için kritiktir.
RLHF, bir LLM'i insan değerlendiricilerden alınan geri bildirimi dahil ederek çıktıları insan tercihleriyle hizalayacak şekilde eğitmeye yönelik bir tekniktir. Bu yinelemeli süreç, modelin yalnızca doğru değil aynı zamanda güvenli, önyargısız ve faydalı yanıtlar üretmeyi öğrenmesine yardımcı olur.
Bununla birlikte RLHF, bazı zorluklar barındırır. Bunlardan biri, insan geri bildirimindeki potansiyel önyargıdır; farklı değerlendiriciler farklı tercih ve yorumlara sahip olabilir.
Bir diğer zorluk, geri bildirim sürecinin ölçeklenebilirliğidir; büyük miktarda insan geri bildirimi toplamak ve bunları dahil etmek zaman alıcı ve maliyetli olabilir. Ek olarak, RLHF'de kullanılan ödül modelinin istenen davranış ve değerleri doğru şekilde yakalamasını sağlamak güçtür. PPO (Proximal Policy Optimization) optimizasyon adımı, karmaşıklık ekler ve eğitim sırasında kararsızlığa neden olabilir.
RLHF'in birçok sınırlamasını ele alan modern alternatifler ortaya çıkmıştır:
Çoğu üretim modeli, saf PPO tabanlı RLHF yerine DPO, RLAIF veya hibrit kombinasyonlar kullanır.
Bilgi temelli halüsinasyonlar, modelin doğru bilgilere sahip olmadığı (veya bilgilerin güncel olmadığı) durumlarda, kulağa makul gelen bilgileri uydurmasıyla ortaya çıkar. Çözümler genellikle şunları içerir:
Mantık temelli halüsinasyonlar, modelin ilgili bilgiye sahip olduğu ancak hatalı akıl yürüttüğü veya tutarsızlıklar ürettiği durumlarda görülür. Yaygın çözümler şunlardır:
Bugün LLM'lerde Transformerlar baskın olsa da, Mamba gibi durum uzayı modelleri (SSM'ler), temelde farklı hesaplama ve performans özelliklerine sahip rekabetçi bir mimari paradigma olarak ortaya çıktı. Her ikisini de anlamak, modern LLM profesyonelleri için giderek daha önemli hale geliyor.
Transformerlar:
Durum Uzayı Modelleri (Mamba, Mamba-2):
Son araştırmalar, Transformerlar ile SSM'lerin doğrudan rakip olmaktan ziyade tamamlayıcı olduğunu; farklı kullanım alanları ve kısıtların farklı mimarileri tercih ettirdiğini gösteriyor. Transformerlar, genel amaçlı LLM'ler için pratik seçim olmaya devam ediyor ve şimdilik muhtemelen baskın olacak. Farklı hesaplama ve görev gereksinimleri için uzmanlaşmış modellerin yer aldığı bir hibrit gelecek olasıdır.
Prompt mühendisliği, LLM'lerden yararlanmanın önemli bir yönüdür. Modelden istenen yanıtları üretmek için kesin ve etkili istemler hazırlamayı içerir. Bu bölüm, prompt mühendislerinin karşılaşabileceği temel soruları inceler.
Prompt mühendisliği, LLM'leri doğru ve ilgili çıktılar üretmeye yönlendirmek için istemlerin tasarlanması ve iyileştirilmesini içerir. LLM'lerle çalışırken kritiktir; çünkü istemin kalitesi, modelin performansını doğrudan etkiler.
Etkili istemler, modelin görevi anlama, doğru ve ilgili yanıtlar üretme yeteneğini artırabilir ve hataların olasılığını azaltabilir.
Prompt mühendisliği, metin üretiminden karmaşık problem çözmeye kadar çeşitli uygulamalarda LLM'lerden en yüksek faydayı almak için gereklidir.
Bir istemin etkinliğini değerlendirmek şunları içerir:
Yinelemeli prompt iyileştirme şunları içerir:
Prompt mühendisliği sürecini kolaylaştırabilecek çeşitli araç ve çerçeveler vardır:
Bu soru, LLM tarafından üretilen içeriğin etik ve pratik yönlerine odaklanır. Güçlü bir yanıt, bu sorunların farkında olunduğunu gösterir ve aşağıdaki gibi teknikleri tartışır.
Halüsinasyon azaltma teknikleri:
Önyargı azaltma teknikleri:
Prompt şablonları, genellikle belirli bilgiler veya talimatlar için yer tutucular içeren yapılandırılmış bir istem formatı sağlar. Farklı görev ve senaryolarda yeniden kullanılabilirler; bu da prompt tasarımında tutarlılığı ve verimliliği artırır.
İyi bir yanıt, prompt şablonlarının en iyi uygulamaları kapsayacak, alan-özel bilgiyi içerecek ve çeşitli uygulamalar için etkili istemler üretme sürecini kolaylaştıracak şekilde nasıl kullanılabileceğini açıklar.
Tokenleştirici, LLM'in girdi istemini nasıl yorumlayıp işleyeceğinde kritik rol oynar. Farklı tokenleştiricilerin farklı sözlük boyutları vardır ve sözlük dışı (OOV) kelimeleri farklı şekilde ele alırlar. Byte Pair Encoding (BPE) gibi bir alt birim tokenleştirici, OOV kelimeleri daha küçük alt birimlere bölerek işleyebilirken, kelime tabanlı bir tokenleştirici bunları bilinmeyen tokenlar olarak ele alabilir.
Tokenleştirici seçimi, çeşitli şekillerde model performansını etkileyebilir. Örneğin, alt birim tokenleştirici nadir veya teknik terimlerin anlamını yakalamada daha etkili olabilirken, kelime tabanlı bir tokenleştirici genel amaçlı dil görevleri için daha basit ve hızlı olabilir.
Prompt mühendisliğinde tokenleştirici seçimi, istemlerin nasıl yapılandırılacağını etkileyebilir. Örneğin, alt birim tokenleştirici kullanıyorsanız, kelimelerin alt birimlere nasıl bölündüğüne daha fazla dikkat ederek modelin amaçlanan anlamı yakalamasını sağlamanız gerekebilir.
Aracı istemleme, modelin bir hedefi tamamlayana kadar plan yapan, eyleme geçen (örneğin araçlar/API'ler çağıran veya belgeleri getiren), sonuçları gözlemleyen ve yineleyen bir “ajan” gibi davranması talimatını veren bir istem tasarım yaklaşımıdır.
Geleneksel prompt mühendisliği, net talimatlar, örnekler ve biçim kısıtlarıyla tek seferde mümkün olan en iyi yanıtı almaya çalışırken; aracı istemleme, çok adımlı bir kontrol döngüsünü (planla → uygula → gözlemle → iyileştir) vurgular.
Özellikle doğruluğun, modelin yalnızca dahili bilgisine güvenmek yerine harici sistemlerle (veritabanları, arama, kod yürütme) etkileşim kurmasına veya ara sonuçları doğrulamasına bağlı olduğu görevlerde kullanışlıdır.
İyi aracı istemler genellikle amacı, mevcut araçları/eylemleri, hangi eylemin seçileceğine nasıl karar verileceğini ve ne zaman durulacağını tanımlar. Halüsinasyonları azaltmak ve güvenilirliği artırmak için açık doğrulama adımları (ör. “getirilen kaynakları kontrol et” veya “nihai yanıttan önce yeniden hesapla”) eklemek de yaygındır.
LLM'ler hakkında daha fazlasını öğrenin!
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
