
Track
AI Fundamentals
10 hr
Large language models (LLMs) have become increasingly important in artificial intelligence, with applications across various industries.
As the demand for professionals with LLM expertise grows, this article provides a comprehensive set of interview questions and answers, covering fundamental concepts, advanced techniques, and practical applications.
If you’re preparing for a job interview or simply want to expand your knowledge, this article will be useful.
To understand LLMs, it's important to start with the fundamental concepts. These foundational questions cover essential aspects such as architecture, key mechanisms, and typical challenges, providing a solid base for learning more advanced topics.
The Transformer architecture is a deep learning model introduced by Vaswani et al. in 2017, designed to handle sequential data with improved efficiency and performance than previous models like recurrent neural networks (RNNs) and long short-term memory (LSTMs).
It relies on self-attention mechanisms to process input data in parallel, making it highly scalable and capable of capturing long-range dependencies.
In LLMs, the Transformer architecture forms the backbone, enabling models to process large amounts of text data efficiently and generate contextually relevant and coherent text outputs.
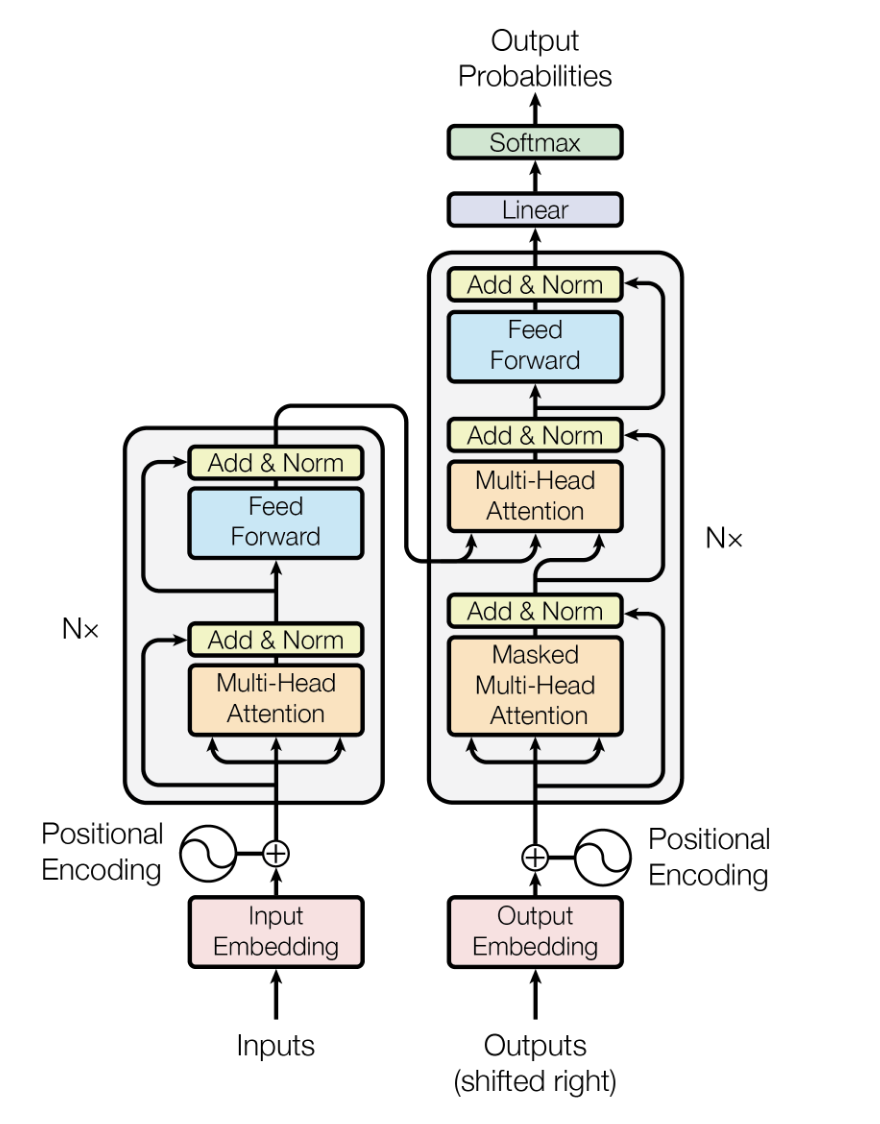
The Transformer model architecture. Source
The context window in LLMs refers to the range of text (in terms of tokens or words) that the model can consider at once when generating or understanding language. The significance of the context window lies in its impact on the model's ability to generate logical and relevant responses.
Generally, a larger context window allows the model to consider more context, leading to better understanding and text generation, especially in complex or lengthy conversations. However, it also increases computational requirements, making it a balance between performance and efficiency.
Additionally, recent research reveals that most models show degraded performance well before their advertised limits. Models can exhibit a "lost in the middle" phenomenon where information in the context center gets ignored or deprioritized. Therefore, curated, relevant context in smaller windows often outperforms filling larger windows with noise.
Common pre-training objectives for LLMs include masked language modeling (MLM) and autoregressive language modeling. In MLM, random words in a sentence are masked, and the model is trained to predict the masked words based on the surrounding context. This helps the model understand the bidirectional context.
Autoregressive language modeling involves predicting the next word in a sequence and training the model to generate text one token at a time. Both objectives enable the model to learn language patterns and semantics from large corpora, providing a solid foundation for fine-tuning specific tasks.
Learn how to work with LLMs in Python right in your browser

Fine-tuning in the context of LLMs involves taking a pre-trained model and further training it on a smaller, task-specific dataset. This process helps the model adapt its general language understanding to the nuances of the specific application, thereby improving performance.
This is an important technique because it leverages the broad language knowledge acquired during pre-training while modifying the model to perform well on specific applications, such as sentiment analysis, text summarization, or question-answering.
Using LLMs comes with several challenges, including:
LLMs handle out-of-vocabulary (OOV) words or tokens using techniques like subword tokenization (e.g., Byte Pair Encoding or BPE, and WordPiece). These techniques break down unknown words into smaller, known subword units that the model can process.
This approach ensures that even if a word is not seen during training, the model can still understand and generate text based on its constituent parts, improving flexibility and robustness.
Embedding layers are a significant component in LLMs used to convert categorical data, such as words, into dense vector representations. These embeddings capture semantic relationships between words by representing them in a continuous vector space where similar words exhibit stronger proximity. The importance of embedding layers in LLMs includes:
Positional encodings tell transformers where each token is located in the sequence.
Traditional sinusoidal positional encodings (from Vaswani et al. 2017) used fixed mathematical functions to encode positions statically. Rotary Position Embeddings (RoPE), introduced more recently, have become the standard in modern LLMs because they offer fundamentally superior properties.
RoPE works by representing positions as rotation angles in complex vector space, rotating token embeddings by an angle proportional to their position. This geometric approach is more efficient and naturally supports interpolation to longer sequences than those seen during training, which is a critical capability for extending context windows. Models like GPT-5.2 and Gemini 3 use RoPE as their positional encoding.
Building upon basic concepts, intermediate-level questions delve into the practical techniques used to optimize LLM performance and address challenges related to computational efficiency and model interpretability.
The concept of attention in LLMs is a method that allows the model to focus on different parts of the input sequence when making predictions. It dynamically assigns weights to other tokens in the input, highlighting the most relevant ones for the current task.
This is implemented using self-attention, where the model calculates attention scores for each token relative to all other tokens in the sequence, allowing it to capture dependencies regardless of their distance.
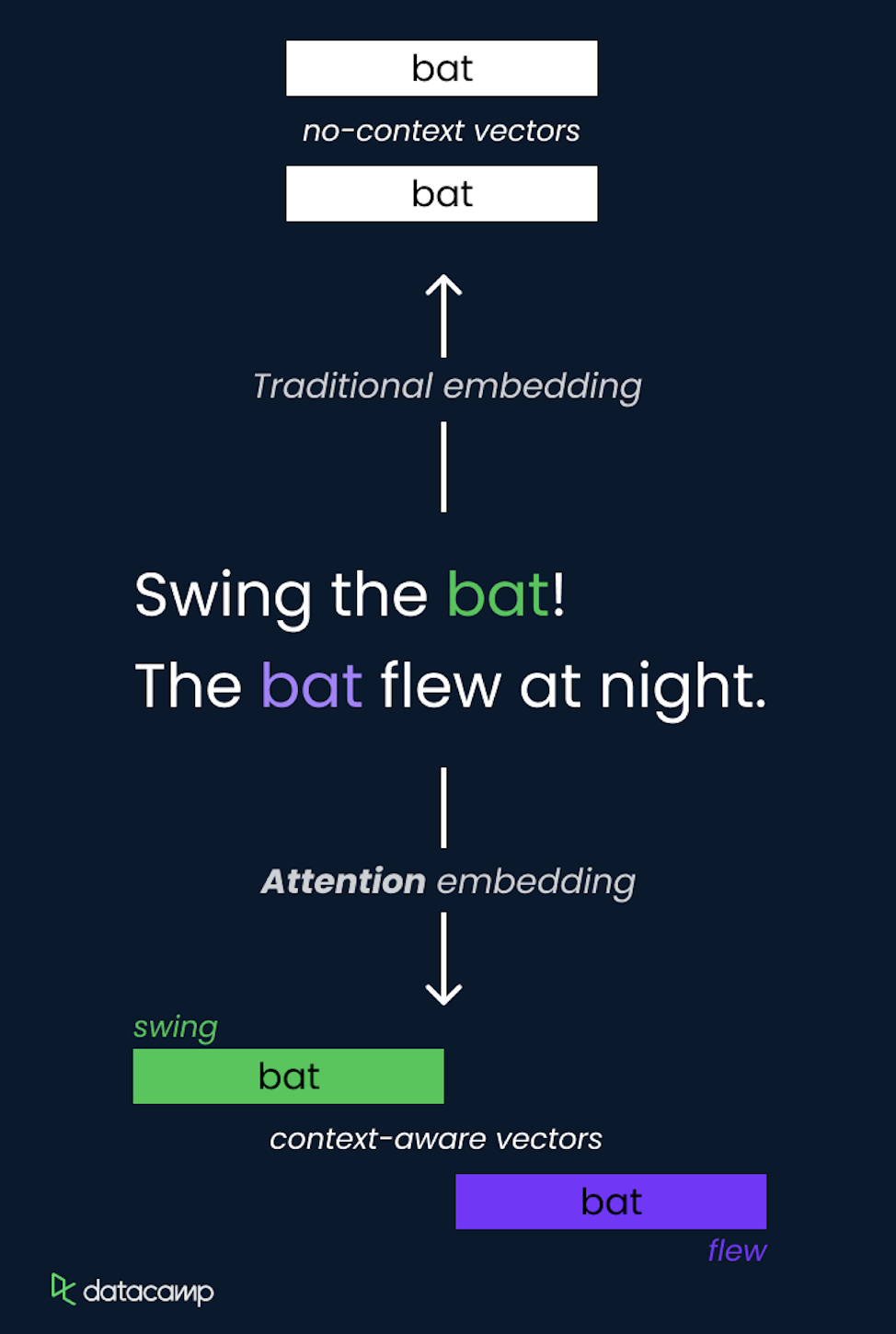
The self-attention mechanism is a core component of the Transformer architecture, enabling it to process information efficiently and capture long-range relationships.
Tokenization converts raw text into smaller units called tokens, which can be words, subwords, or characters.
The role of tokenization in LLM processing is vital as it transforms text into a format that the model can understand and process.
Effective tokenization ensures that the model can handle a diverse range of inputs, including rare words and different languages, by breaking them down into manageable pieces. This step is necessary for optimal training and inference, as it standardizes the input and helps the model learn meaningful patterns in the data.
Researchers and practitioners have developed numerous evaluation metrics to gauge the performance of an LLM. Classic metrics include:
Beyond traditional metrics, practitioners now use standardized benchmarks for different purposes, such as MMLU (57-task knowledge test), MMMU-Pro (multimodal reasoning), and HumanEval (code generation). Additionally, leaderboards like LMArena rank LLMs by human preference. For deployed systems, measuring real-world hallucination rates, latency, and token efficiency has become essential.
Several techniques can be used to control the output of an LLM, including:
To reduce the computational cost of LLMs, we can employ:
Model interpretability is essential for understanding how an LLM makes decisions, which is important for building trust, ensuring accountability, and identifying and mitigating biases. Achieving interpretability can involve different approaches, such as:
LLMs handle long-term dependencies in text through their architecture, particularly the self-attention mechanism, which allows them to consider all tokens in the input sequence simultaneously. This ability to attend to distant tokens helps LLMs capture relationships and dependencies over long contexts.
Additionally, advanced models like the Transformer-XL and Longformer are specifically designed to extend the context window and manage longer sequences more effectively, ensuring better handling of long-term dependencies.
Modern production models use more advanced strategies to handle long-term dependencies and counteract degrading performance with expanding context windows, such as:
RAG combines retrieval mechanisms with generative models to fetch relevant information from external sources during text generation. This approach directly addresses two critical LLM limitations: hallucination and knowledge currency. Traditional RAG uses relatively simple retrieval and generation pipelines, but in its evolution to "RAG 2.0", it has become significantly more sophisticated.
Key features of RAG 2.0 include:
RAG 2.0, combined with LLMs, effectively reduces hallucination rates by 40-60% in production systems compared to base models.
Understanding advanced concepts in LLMs is useful for professionals who aim to push the boundaries of what these models can achieve. This section explores complex topics and common challenges faced in the field.
Few-shot learning in LLMs refers to the model's ability to learn and perform new tasks using only a few examples. This capability leverages the LLM's extensive pre-trained knowledge, enabling it to generalize from a small number of instances.
The primary advantages of few-shot learning include reduced data requirements, as the need for large task-specific datasets is minimized, increased flexibility, allowing the model to adapt to various tasks with minimal fine-tuning, and cost efficiency, as lower data requirements and reduced training times translate to significant cost savings in data collection and computational resources.
Autoregressive and masked language models differ mainly in their prediction approach and task suitability. Autoregressive models, like GPT-5.2, Claude 4.5 Opus, and Gemini 3, predict the next word in a sequence based on the preceding words, generating text one token at a time.
These models are particularly well-suited for text-generation tasks. In contrast, masked language models, such as BERT, randomly mask words in a sentence and train the model to predict these masked words based on the surrounding context. This bidirectional approach helps the model understand context from both directions, making it ideal for text classification and question-answering tasks.
Incorporating external knowledge into an LLM can be achieved through several methods:
Deploying LLMs in production involves various challenges:
Model degradation occurs when the performance of an LLM declines over time due to changes in the underlying data distribution. Handling model degradation involves regular retraining with updated data to maintain performance. Continuous monitoring is necessary to track the model’s performance and detect signs of degradation.
Incremental learning techniques allow the model to learn from new data without forgetting previously learned information. Additionally, A/B testing compares the current model's performance with new versions and helps identify potential improvements before full deployment.
To ensure the ethical use of LLMs, several techniques can be implemented:
Securing data used with LLMs requires implementing various measures. These include using encryption techniques for data at rest and in transit to protect against unauthorized access. Strict access controls are necessary to ensure that only authorized personnel can access sensitive data.
Anonymizing data to remove personally identifiable information (PII) before using it for training or inference is also crucial. Additionally, compliance with data protection regulations like GDPR or CCPA is essential to avoid legal issues.
These measures help protect data integrity, confidentiality, and availability. This protection is critical for maintaining user trust and adhering to regulatory standards.
RLHF is a technique that involves training an LLM to align its outputs with human preferences by incorporating feedback from human evaluators. This iterative process helps the model learn to generate responses that are not only accurate but also safe, unbiased, and helpful.
However, RLHF comes with challenges. One challenge is the potential for bias in the human feedback, as different evaluators might have varying preferences and interpretations.
Another challenge is the scalability of the feedback process, as collecting and incorporating large amounts of human feedback can be time-consuming and expensive. Additionally, ensuring that the reward model used in RLHF accurately captures the desired behaviors and values can be tricky. The PPO (Proximal Policy Optimization) optimization step adds complexity and can introduce instability during training.
Modern alternatives have emerged that address many of RLHF's limitations:
Most production models use DPO, RLAIF, or hybrid combinations rather than pure PPO-based RLHF.
Knowledge-based hallucinations happen when the model doesn’t have the right facts (or has outdated facts), so it invents plausible-sounding information. Fixes typically involve:
Logic-based hallucinations happen when the model has relevant information but reasons incorrectly or produces inconsistencies. Common fixes are:
While Transformers dominate LLMs today, state-space models (SSMs) like Mamba have emerged as a competitive architectural paradigm with fundamentally different computational and performance properties. Understanding both is increasingly important for modern LLM professionals.
Transformers:
State-Space Models (Mamba, Mamba-2):
Recent research demonstrates that Transformers and SSMs are complementary rather than directly competitive, with different use cases and constraints favoring different architectures. Transformers remain the practical choice for general-purpose LLMs and will likely continue dominating for now. A hybrid future is likely, with specialized models for different computational and task requirements.
Prompt engineering is an important aspect of utilizing LLMs. It involves crafting precise and effective prompts to generate desired responses from the model. This section examines key questions that prompt engineers may encounter.
Prompt engineering involves designing and refining prompts to guide LLMs in generating accurate and relevant outputs. It’s vital for working with LLMs because the quality of the prompt directly impacts the model's performance.
Effective prompts can enhance the model's ability to understand the task, generate accurate and relevant responses, and reduce the likelihood of errors.
Prompt engineering is essential for maximizing the utility of LLMs in various applications, from text generation to complex problem-solving tasks.
Evaluating the effectiveness of a prompt involves:
Iterative prompt refinement involves:
Several tools and frameworks can streamline the prompt engineering process:
This question addresses the ethical and practical issues of LLM-generated content. A strong answer would demonstrate awareness of these problems and discuss techniques like the following.
Hallucination mitigation techniques:
Bias mitigation techniques:
Prompt templates provide a structured format for prompts, often including placeholders for specific information or instructions. They can be reused across different tasks and scenarios, improving consistency and efficiency in prompt design.
A good answer would explain how prompt templates can be used to encapsulate best practices, incorporate domain-specific knowledge, and streamline the process of generating effective prompts for various applications.
The tokenizer plays a crucial role in how the LLM interprets and processes the input prompt. Different tokenizers have varying vocabulary sizes and handle out-of-vocabulary (OOV) words differently. A subword tokenizer like Byte Pair Encoding (BPE) can handle OOV words by breaking them into smaller subword units, while a word-based tokenizer might treat them as unknown tokens.
The choice of tokenizer can impact model performance in several ways. For instance, a subword tokenizer might be more effective in capturing the meaning of rare or technical terms, while a word-based tokenizer might be simpler and faster for general-purpose language tasks.
In prompt engineering, the choice of tokenizer can influence how you structure your prompts. For example, if you're using a subword tokenizer, you might need to pay more attention to how words are split into subwords to ensure that the model captures the intended meaning.
Agentic prompting is a prompt design approach where the model is instructed to act like an “agent” that can plan, take actions (for example, call tools/APIs or retrieve documents), observe the results, and iterate until it completes an objective.
Unlike traditional prompt engineering, which mainly tries to get the best possible response in one shot through clear instructions, examples, and formatting constraints, agentic prompting emphasizes a multi-step control loop (plan → act → observe → refine).
It’s especially useful for tasks where correctness depends on interacting with external systems (databases, search, code execution) or verifying intermediate results rather than relying on the model’s internal knowledge alone.
Good agentic prompts usually define the objective, available tools/actions, how to decide which action to take, and when to stop. It’s also common to add explicit verification steps (e.g., “check retrieved sources” or “recompute before final answer”) to reduce hallucinations and improve reliability.
Learn more about LLMs!
Track
Course
Course
blog
Vinod Chugani
15 min
blog
Hesam Sheikh Hassani
15 min
blog
Ryan Ong
15 min
blog
Abid Ali Awan
15 min
blog
Zoumana Keita
15 min
blog
Vinod Chugani
14 min



