
programa
Fundamentos de la IA
10 h
Los modelos de lenguaje grandes (LLM) han cobrado cada vez más importancia en la inteligencia artificial, con aplicaciones en diversos sectores.
A medida que crece la demanda de profesionales con experiencia en LLM, este artículo ofrece un conjunto completo de preguntas y respuestas para entrevistas, que abarca conceptos fundamentales, técnicas avanzadas y aplicaciones prácticas.
Si te estás preparando para una entrevista de trabajo o simplemente deseas ampliar tus conocimientos, este artículo te resultará útil.
Para comprender los LLM, es importante empezar por los conceptos fundamentales. Estas preguntas fundamentales abarcan aspectos esenciales como la arquitectura, los mecanismos clave y los retos típicos, lo que proporciona una base sólida para aprender temas más avanzados.
La arquitectura Transformer es un modelo de aprendizaje profundo introducido por Vaswani et alen 2017, diseñado para manejar datos secuenciales con mayor eficiencia y rendimiento que los modelos anteriores, como las redes neuronales recurrentes (RNN) y las redes neuronales con memoria a corto y largo plazo (LSTM).
Se basa en mecanismos de autoatención para procesar los datos de entrada en paralelo, lo que te hace altamente escalable y capaz de capturar dependencias de largo alcance.
En los LLM, la arquitectura Transformer constituye la columna vertebral, lo que permite a los modelos procesar grandes cantidades de datos de texto de manera eficiente y generar resultados de texto coherentes y relevantes desde el punto de vista contextual.
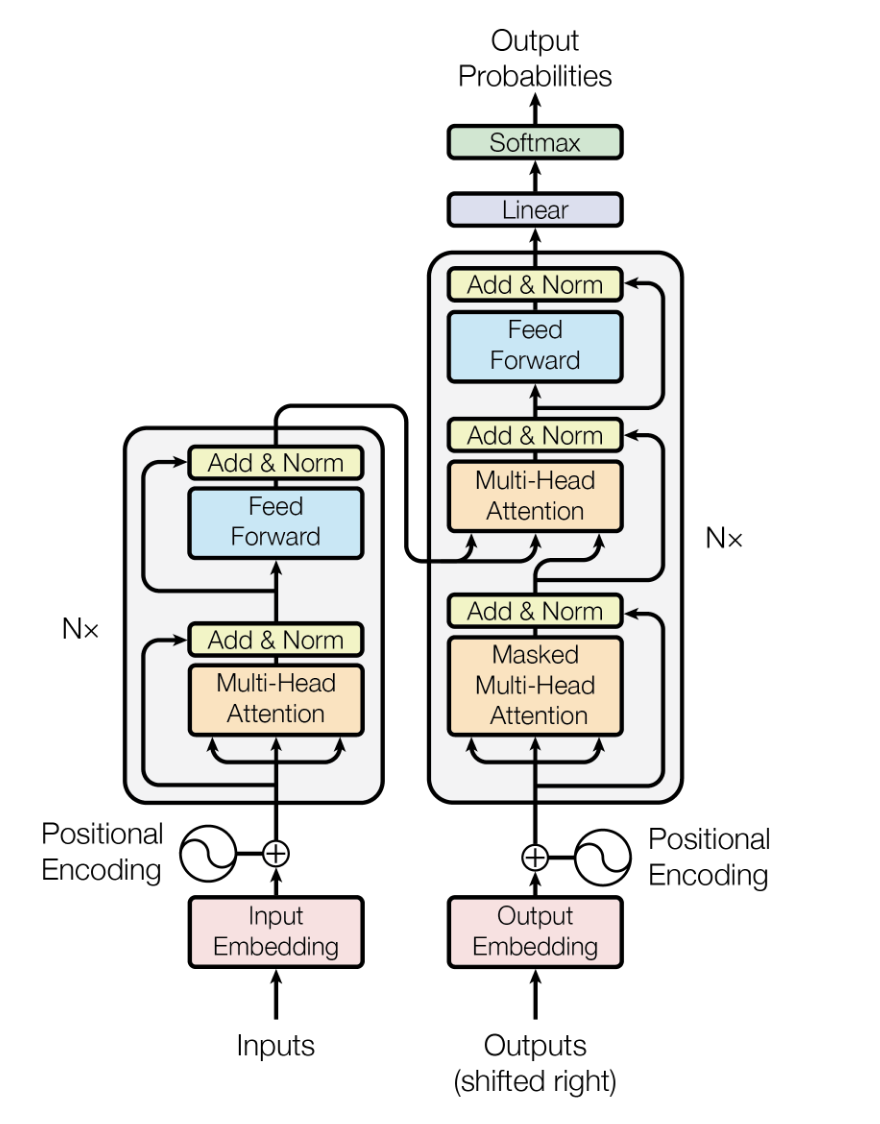
La arquitectura del modelo Transformer. Fuente
La ventana de contexto en los LLM se refiere al rango de texto (en términos de tokens o palabras) que el modelo puede considerar a la vez al generar o comprender el lenguaje. La importancia de la ventana de contexto radica en su impacto en la capacidad del modelo para generar respuestas lógicas y relevantes.
Por lo general, una ventana de contexto más amplia permite al modelo tener en cuenta más contexto, lo que se traduce en una mejor comprensión y generación de texto, especialmente en conversaciones complejas o largas. Sin embargo, también aumenta los requisitos computacionales, lo que lo convierte en un equilibrio entre rendimiento y eficiencia.
Además, investigaciones recientes revelan que los modelos de most muestran un rendimiento degradado mucho antes de alcanzar los límites anunciados. Los modelos pueden presentar un fenómeno de «pérdida en el medio», en el que la información del centro del contexto se ignora o se deja de priorizar. Por lo tanto,un contexto relevante y seleccionado en ventanas más pequeñas suele funcionar mejor que llenar ventanas más grandes con ruido.
Los objetivos comunes previos al entrenamiento para los LLM incluyen el modelado de lenguaje enmascarado (MLM) y el modelado de lenguaje autorregresivo. En MLM, se ocultan palabras aleatorias en una frase y se entrena al modelo para que prediga las palabras ocultas basándose en el contexto circundante. Esto ayuda al modelo a comprender el contexto bidireccional.
El modelado autorregresivo del lenguaje consiste en predecir la siguiente palabra de una secuencia y entrenar al modelo para que genere texto de un token en un momento dado. Ambos objetivos permiten al modelo aprender patrones lingüísticos y semánticos a partir de grandes corpus, lo que proporciona una base sólida para ajustar tareas específicas.
Aprende a trabajar con LLMs en Python directamente en tu navegador

El ajuste fino en el contexto de los LLM implica tomar un modelo preentrenado y seguir entrenándolo con un conjunto de datos más pequeño y específico para la tarea. Este proceso ayuda al modelo a adaptar su comprensión general del lenguaje a los matices de la aplicación específica, mejorando así el rendimiento.
Esta es una técnica importante porque aprovecha los amplios conocimientos lingüísticos adquiridos durante el entrenamiento previo, al tiempo que modifica el modelo para que funcione bien en aplicaciones específicas, como el análisis de sentimientos, la síntesis de textos o la respuesta a preguntas.
El uso de los LLM plantea varios retos, entre ellos:
Los LLM gestionan las palabras o tokens fuera del vocabulario (OOV) utilizando técnicas como la tokenización de subpalabras (por ejemplo, Byte Pair Encoding o BPE, y WordPiece). Estas técnicas descomponen las palabras desconocidas en unidades más pequeñas y conocidas que el modelo puede procesar.
Este enfoque garantiza que, aunque una palabra no aparezca durante el entrenamiento, el modelo pueda seguir comprendiendo y generando texto basándose en sus partes constitutivas, lo que mejora la flexibilidad y la solidez.
Las capas de incrustación son un componente importante de los LLM que se utilizan para convertir datos categóricos, como las palabras, en representaciones vectoriales densas. Estas incrustaciones capturan las relaciones semánticas entre las palabras representándolas en un espacio vectorial continuo en el que las palabras similares muestran una mayor proximidad. La importancia de incorporar capas en los LLM incluye:
Las codificaciones posicionales indican a los transformadores dónde se encuentra cada token en la secuencia.
Codificaciones posicionales sinusoidales tradicionales (de Vaswani et al. 2017) utilizaron funciones matemáticas fijas para codificar posiciones de forma estática. Las incrustaciones de posición rotatoria (RoPE), introducidas más recientemente, se han convertido en el estándar en los LLM modernos porque ofrecen propiedades fundamentalmente superiores.
RoPE funciona representando posiciones como ángulos de rotación en un espacio vectorial complejo, rotando las incrustaciones de tokens en un ángulo proporcional a su posición. Este enfoque geométrico es más eficiente y admite de forma natural la interpolación a secuencias más largas que las observadas durante el entrenamiento, lo cual es una capacidad fundamental para ampliar las ventanas de contexto. Modelos como GPT-5.2 y Gemini 3 utilizan RoPE como codificación posicional.
Partiendo de conceptos básicos, las preguntas de nivel intermedio profundizan en las técnicas prácticas utilizadas para optimizar el rendimiento de los modelos LLM y abordar los retos relacionados con la eficiencia computacional y la interpretabilidad de los modelos.
El concepto de atención en los LLM es un método que permite al modelo centrarse en diferentes partes de la secuencia de entrada al realizar predicciones. Asigna dinámicamente pesos a otros tokens en la entrada, resaltando los más relevantes para la tarea actual.
Esto se implementa utilizando la autoatención, donde el modelo calcula las puntuaciones de atención para cada token en relación con todos los demás tokens de la secuencia, lo que te permite capturar las dependencias independientemente de su distancia.
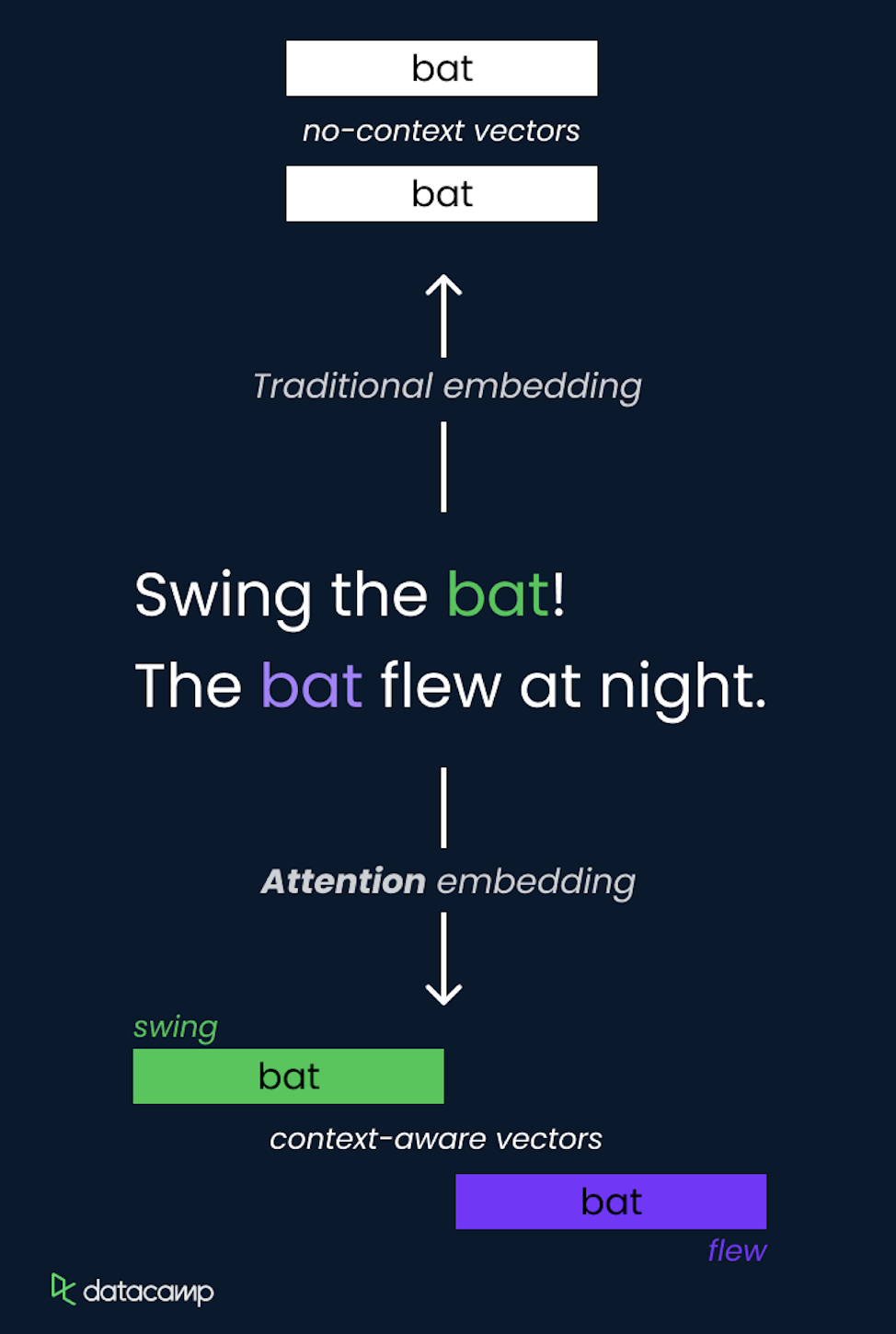
El mecanismo de autoatención es un componente fundamental de la arquitectura Transformer, que te permite procesar información de manera eficiente y captar relaciones de largo alcance.
La tokenización convierte el texto sin procesar en unidades más pequeñas llamadas tokens, que pueden ser palabras, subpalabras o caracteres.
El papel de la tokenización en el procesamiento de LLM es fundamental, ya que transforma el texto en un formato que el modelo puede comprender y procesar.
Una tokenización eficaz garantiza que el modelo pueda manejar una amplia gama de entradas, incluidas palabras poco frecuentes y diferentes idiomas, al dividirlas en partes manejables. Este paso es necesario para un entrenamiento y una inferencia óptimos, ya que estandariza la entrada y ayuda al modelo a aprender patrones significativos en los datos.
Los investigadores y profesionales han desarrollado numerosas métricas de evaluación para medir el rendimiento de un LLM. Las métricas clásicas incluyen:
Más allá de las métricas tradicionales, los profesionales utilizan ahora puntos de referencia estandarizados para diferentes fines, como MMLU (prueba de conocimientos de 57 tareas), MMMU-Pro (razonamiento multimodal) y HumanEval (generación de código). Además, las tablas de clasificación como LMArena clasifican los LLM según las preferencias humanas. En los sistemas implementados, se ha vuelto esencial medir las tasas de alucinación en el mundo real, la latencia y la eficiencia de los tokens.
Se pueden utilizar varias técnicas para controlar la salida de un LLM, entre ellas:
Para reducir el coste computacional de los LLM, podemos emplear:
La interpretabilidad del modelo es esencial para comprender cómo toma decisiones un LLM, lo cual es importante para generar confianza, garantizar la responsabilidad e identificar y mitigar los sesgos. Para lograr la interpretabilidad se pueden adoptar diferentes enfoques, tales como:
Los LLM gestionan las dependencias a largo plazo en el texto a través de su arquitectura, en particular el mecanismo de autoatención, que les permite considerar todos los tokens de la secuencia de entrada simultáneamente. Esta capacidad para prestar atención a tokens distantes ayuda a los LLM a captar relaciones y dependencias en contextos largos.
Además, los modelos avanzados como Transformer-XL y Longformer están diseñados específicamente para ampliar la ventana de contexto y gestionar secuencias más largas de forma más eficaz, lo que garantiza un mejor manejo de las dependencias a largo plazo.
Los modelos de producción modernos utilizan estrategias más avanzadas para gestionar las dependencias a largo plazo y contrarrestar la degradación del rendimiento con ventanas de contexto ampliadas, tales como:
RAG combina mecanismos de recuperación con modelos generativos para obtener información relevante de fuentes externas durante la generación de texto. Este enfoque aborda directamente dos limitaciones críticas del LLM: las alucinaciones y la actualidad del conocimiento. El RAG tradicional utiliza procesos de recuperación y generación relativamente sencillos, pero en su evolución hacia el «RAG 2.0», se ha vuelto mucho más sofisticado.
Las características principales de RAG 2.0 incluyen:
RAG 2.0, combinado con LLM, reduce eficazmente las tasas de alucinación entre un 40 % y un 60 % en los sistemas de producción en comparación con los modelos básicos.
Comprender los conceptos avanzados de los LLM resulta útil para los profesionales que desean ampliar los límites de lo que estos modelos pueden lograr. En esta sección se analizan temas complejos y retos comunes a los que te enfrentas en este campo.
El aprendizaje con pocos ejemplos en los LLM se refiere a la capacidad del modelo para aprender y realizar nuevas tareas utilizando solo unos pocos ejemplos. Esta capacidad aprovecha el amplio conocimiento preentrenado del LLM, lo que te permite generalizar a partir de un pequeño número de casos.
Las principales ventajas del aprendizaje con pocos ejemplos incluyen la reducción de los requisitos de datos, ya que se minimiza la necesidad de grandes conjuntos de datos específicos para cada tarea, una mayor flexibilidad, lo que permite que el modelo se adapte a diversas tareas con un ajuste mínimo, y la rentabilidad, ya que los menores requisitos de datos y la reducción de los tiempos de formación se traducen en un ahorro significativo de costes en la recopilación de datos y los recursos computacionales.
Los modelos de lenguaje autorregresivos y enmascarados difieren principalmente en su enfoque de predicción y en su idoneidad para las tareas. Los modelos autorregresivos, como GPT-5.2, Claude 4.5 Opus y Gemini 3, predicen la siguiente palabra de una secuencia basándose en las palabras anteriores, generando texto un token cada vez.
Estos modelos son especialmente adecuados para tareas de generación de texto. Por el contrario, los modelos de lenguaje enmascarados, como BERT, enmascaran aleatoriamente palabras en una frase y entrenan el modelo para predecir estas palabras enmascaradas basándose en el contexto circundante. Este enfoque bidireccional ayuda al modelo a comprender el contexto desde ambas direcciones, lo que lo hace ideal para tareas de clasificación de texto y respuesta a preguntas.
La incorporación de conocimientos externos en un LLM puede lograrse mediante varios métodos:
La implementación de LLM en producción plantea varios retos:
La degradación del modelo se produce cuando el rendimiento de un LLM disminuye con el tiempo debido a cambios en la distribución de los datos subyacentes. El manejo de la degradación del modelo implica un reentrenamiento periódico con datos actualizados para mantener el rendimiento. Es necesario realizar un seguimiento continuo para controlar el rendimiento del modelo y detectar signos de degradación.
Las técnicas de aprendizaje incremental permiten que el modelo aprenda a partir de datos nuevos sin olvidar la información aprendida anteriormente. Además, las pruebas A/B comparan el rendimiento del modelo actual con las nuevas versiones y ayudan a identificar posibles mejoras antes de la implementación completa.
Para garantizar el uso ético de los LLM, se pueden implementar varias técnicas:
Para proteger los datos utilizados con los LLM es necesario implementar diversas medidas. Esto incluye el uso de técnicas de cifrado para los datos en reposo y en tránsito con el fin de protegerlos contra el acceso no autorizado. Es necesario aplicar controles de acceso estrictos para garantizar que solo el personal autorizado pueda acceder a los datos confidenciales.
También es fundamental anonimizar los datos para eliminar la información de identificación personal (PII) antes de utilizarlos para el entrenamiento o la inferencia. Además, el cumplimiento de las normativas de protección de datos, como el RGPD o la CCPA, es esencial para evitar problemas legales.
Estas medidas ayudan a proteger la integridad, confidencialidad y disponibilidad de los datos. Esta protección es fundamental para mantener la confianza de los usuarios y cumplir con las normas reglamentarias.
RLHF ( ) es una técnica que consiste en entrenar un LLM para alinear sus resultados con las preferencias humanas mediante la incorporación de comentarios de evaluadores humanos. Este proceso iterativo ayuda al modelo a aprender a generar respuestas que no solo son precisas, sino también seguras, imparciales y útiles.
Sin embargo, RLHF plantea algunos retos. Un reto es la posibilidad de sesgo en la retroalimentación humana, ya que diferentes evaluadores pueden tener preferencias e interpretaciones diferentes.
Otro reto es la escalabilidad del proceso de retroalimentación, ya que recopilar e incorporar grandes cantidades de retroalimentación humana puede llevar mucho tiempo y resultar costoso. Además, garantizar que el modelo de recompensa utilizado en RLHF refleje con precisión los comportamientos y valores deseados puede resultar complicado. El paso de optimización PPO (optimización de políticas proximales) añade complejidad y puede introducir inestabilidad durante el entrenamiento.
Han surgido alternativas modernas que abordan muchas de las limitaciones de RLHF:
La mayoría de los modelos de producción utilizan DPO, RLAIF o combinaciones híbridas en lugar de RLHF basado exclusivamente en PPO.
Las alucinaciones basadas en el conocimiento se producen cuando el modelo no dispone de los datos correctos (o tiene datos obsoletos), por lo que inventa información que parece plausible. Las correcciones suelen incluir:
Las alucinaciones basadas en la lógica se producen cuando el modelo dispone de información relevante, pero razona de forma incorrecta o genera inconsistencias. Las soluciones más comunes son:
Aunque los transformadores dominan los LLM en la actualidad, los modelos de espacio de estado (SSM), como Mamba, han surgido como un paradigma arquitectónico competitivo con propiedades computacionales y de rendimiento fundamentalmente diferentes. Comprender ambos aspectos es cada vez más importante para los profesionales modernos del LLM.
Transformers:
Modelos de espacio de estados (Mamba, Mamba-2):
Investigaciones recientes demuestran que los transformadores y los SSM son complementarios en lugar de directamente competitivos, con diferentes casos de uso y limitaciones que favorecen diferentes arquitecturas. Los transformadores siguen siendo la opción más práctica para los LLM de uso general y probablemente seguirán dominando el mercado por ahora. Es probable que el futuro sea híbrido, con modelos especializados para diferentes requisitos computacionales y tareas.
La ingeniería de prompts es un aspecto importante de la utilización de los LLM. Implica la elaboración de indicaciones precisas y eficaces para generar las respuestas deseadas del modelo. En esta sección se examinan cuestiones clave que pueden surgir a los ingenieros.
La ingeniería de indicaciones consiste en diseñar y perfeccionar indicaciones para guiar a los LLM en la generación de resultados precisos y relevantes. Es fundamental para trabajar con LLM, ya que la calidad de la indicación influye directamente en el rendimiento del modelo.
Las indicaciones eficaces pueden mejorar la capacidad del modelo para comprender la tarea, generar respuestas precisas y relevantes, y reducir la probabilidad de errores.
La ingeniería de prompts es esencial para maximizar la utilidad de los LLM en diversas aplicaciones, desde la generación de texto hasta tareas complejas de resolución de problemas.
Evaluar la eficacia de una indicación implica:
El refinamiento iterativo de las indicaciones implica:
Existen varias herramientas y marcos que pueden agilizar el proceso de ingeniería de prompts:
Esta pregunta aborda las cuestiones éticas y prácticas del contenido generado por LLM. Una respuesta sólida demostraría que eres consciente de estos problemas y abordaría técnicas como las siguientes.
Técnicas para mitigar las alucinaciones:
Técnicas de mitigación del sesgo:
Las plantillas de indicaciones proporcionan un formato estructurado para las indicaciones, que a menudo incluyen marcadores de posición para información o instrucciones específicas. Se pueden reutilizar en diferentes tareas y escenarios, lo que mejora la coherencia y la eficiencia en el diseño de mensajes.
Una buena respuesta explicaría cómo se pueden utilizar las plantillas de indicaciones para resumir las mejores prácticas, incorporar conocimientos específicos del ámbito y optimizar el proceso de generación de indicaciones eficaces para diversas aplicaciones.
El tokenizador desempeña un papel crucial en la forma en que el LLM interpreta y procesa la entrada. Los diferentes tokenizadores tienen distintos tamaños de vocabulario y tratan las palabras fuera del vocabulario (OOV) de manera diferente. Un tokenizador de subpalabras como Byte Pair Encoding (BPE) puede manejar palabras OOV dividiéndolas en unidades de subpalabras más pequeñas, mientras que un tokenizador basado en palabras podría tratarlas como tokens desconocidos.
La elección del tokenizador puede afectar al rendimiento del modelo de varias maneras. Por ejemplo, un tokenizador de subpalabras puede ser más eficaz para captar el significado de términos poco comunes o técnicos, mientras que un tokenizador basado en palabras puede ser más sencillo y rápido para tareas lingüísticas de uso general.
En la ingeniería de prompts, la elección del tokenizador puede influir en la forma en que estructuras tus prompts. Por ejemplo, si utilizas un tokenizador de subpalabras, es posible que debas prestar más atención a cómo se dividen las palabras en subpalabras para garantizar que el modelo capte el significado deseado.
La incitación agencial es un enfoque de diseño de incitaciones en el que se instruye al modelo para que actúe como un «agente» capaz de planificar, realizar acciones (por ejemplo, llamar a herramientas/API o recuperar documentos), observar los resultados y repetir el proceso hasta completar un objetivo.
A diferencia de la ingeniería de indicaciones tradicional, que principalmente intenta obtener la mejor respuesta posible de una sola vez mediante instrucciones claras, ejemplos y restricciones de formato, las indicaciones agentivas hacen hincapié en un bucle de control de varios pasos (planificar → actuar → observar → perfeccionar).
Es especialmente útil para tareas en las que la corrección depende de la interacción con sistemas externos (bases de datos, búsquedas, ejecución de código) o de la verificación de resultados intermedios, en lugar de basarse únicamente en el conocimiento interno del modelo.
Las buenas indicaciones de agencia suelen definir el objetivo, las herramientas/acciones disponibles, cómo decidir qué acción tomar y cuándo detenerte. También es habitual añadir pasos de verificación explícitos (por ejemplo, «comprobar las fuentes recuperadas» o «recalcular antes de dar la respuesta definitiva») para reducir las alucinaciones y mejorar la fiabilidad.
¡Más información sobre los LLM!
programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
Tutorial
Josep Ferrer


