
Programma
Nozioni di base sull'intelligenza artificiale
10 h
I large language model (LLM) sono diventati sempre più importanti nell’intelligenza artificiale, con applicazioni in diversi settori.
Con l’aumentare della domanda di professionisti con competenze sugli LLM, questo articolo fornisce un set completo di domande e risposte da colloquio, che coprono concetti fondamentali, tecniche avanzate e applicazioni pratiche.
Se ti stai preparando per un colloquio di lavoro o vuoi semplicemente ampliare le tue conoscenze, questo articolo ti sarà utile.
Per comprendere gli LLM, è importante partire dai concetti fondamentali. Queste domande iniziali coprono aspetti essenziali come l’architettura, i meccanismi chiave e le sfide tipiche, offrendo una base solida per approfondire argomenti più avanzati.
L’architettura Transformer è un modello di deep learning introdotto da Vaswani et al. nel 2017, progettato per gestire dati sequenziali con maggiore efficienza e prestazioni rispetto a modelli precedenti come le reti neurali ricorrenti (RNN) e le long short-term memory (LSTM).
Si basa su meccanismi di self-attention per processare gli input in parallelo, risultando altamente scalabile e capace di catturare dipendenze a lungo raggio.
Negli LLM, l’architettura Transformer costituisce la spina dorsale, permettendo ai modelli di elaborare grandi quantità di testo in modo efficiente e generare output testuali coerenti e rilevanti rispetto al contesto.
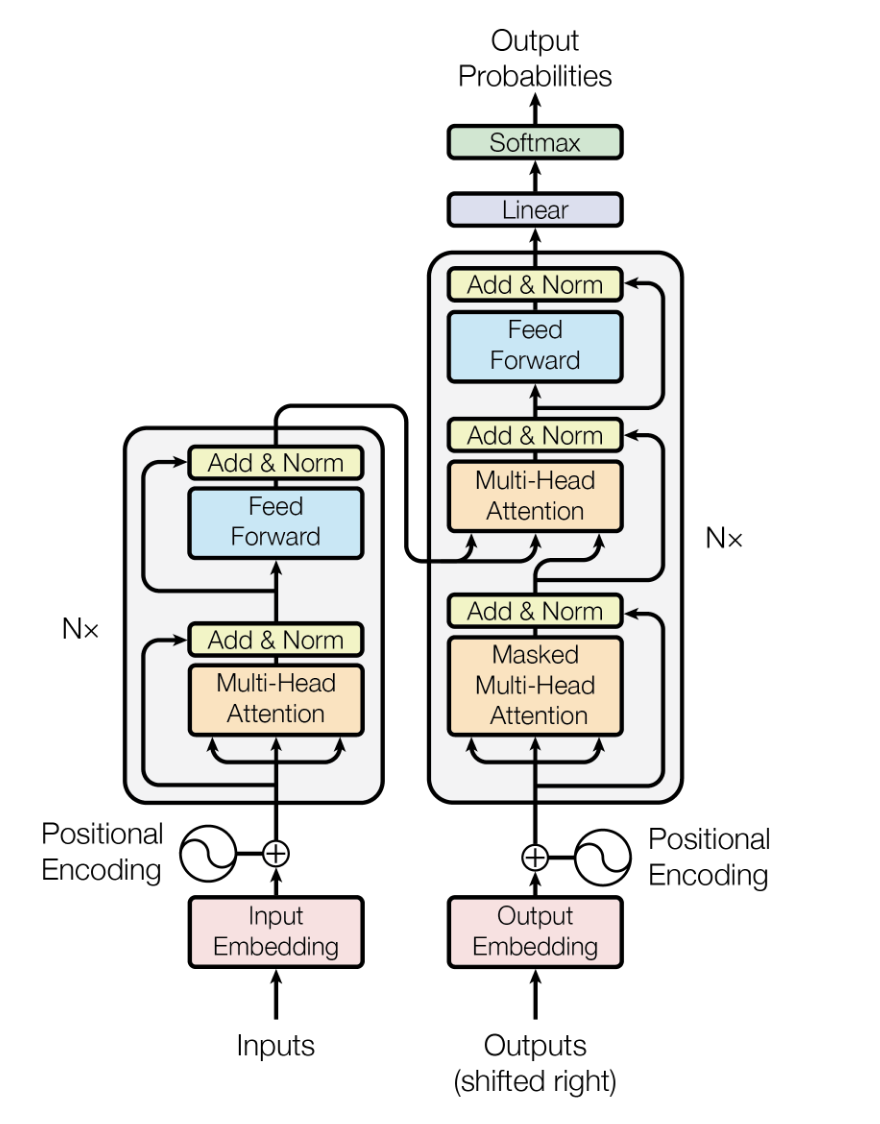
L’architettura del modello Transformer. Fonte
La finestra di contesto negli LLM indica l’intervallo di testo (in termini di token o parole) che il modello può considerare in un’unica volta quando genera o comprende il linguaggio. L’importanza della finestra di contesto risiede nel suo impatto sulla capacità del modello di produrre risposte logiche e pertinenti.
In generale, una finestra di contesto più ampia permette al modello di considerare più informazioni, favorendo una migliore comprensione e generazione del testo, soprattutto in conversazioni complesse o lunghe. Tuttavia, aumenta anche i requisiti computazionali, richiedendo un equilibrio tra prestazioni ed efficienza.
Inoltre, ricerche recenti mostrano che molti modelli degradano nelle prestazioni ben prima dei limiti dichiarati. I modelli possono manifestare il fenomeno del "lost in the middle", in cui le informazioni al centro del contesto vengono ignorate o de-prioritizzate. Pertanto, un contesto curato e pertinente in finestre più piccole spesso supera l’uso di finestre più grandi riempite di rumore.
Tra i comuni obiettivi di pre-training per gli LLM ci sono il masked language modeling (MLM) e il language modeling autoregressivo. Nell’MLM, alcune parole di una frase vengono mascherate a caso e il modello viene addestrato a prevederle in base al contesto circostante. Questo aiuta il modello a comprendere il contesto bidirezionale.
Il language modeling autoregressivo consiste nel prevedere la parola successiva in una sequenza, addestrando il modello a generare testo un token alla volta. Entrambi gli obiettivi permettono al modello di apprendere schemi linguistici e semantica da ampi corpora, fornendo una base solida per il fine-tuning su compiti specifici.
Il fine-tuning, nel contesto degli LLM, consiste nel prendere un modello pre-addestrato e addestrarlo ulteriormente su un dataset più piccolo e specifico per il compito. Questo processo aiuta il modello ad adattare la comprensione linguistica generale alle sfumature dell’applicazione specifica, migliorandone così le prestazioni.
È una tecnica importante perché sfrutta l’ampia conoscenza linguistica acquisita durante il pre-training, modificando al contempo il modello per ottenere buoni risultati su applicazioni specifiche, come l’analisi del sentiment, il riassunto di testi o il question answering.
L’uso degli LLM comporta diverse sfide, tra cui:
Gli LLM gestiscono parole o token fuori vocabolario (OOV) usando tecniche come la tokenizzazione a sotto-parole (ad es. Byte Pair Encoding, BPE, e WordPiece). Queste tecniche suddividono parole sconosciute in unità sub-lessicali più piccole e note che il modello può processare.
Questo approccio garantisce che, anche se una parola non è stata vista in addestramento, il modello possa comunque comprendere e generare testo basandosi sulle sue parti costitutive, migliorando flessibilità e robustezza.
Gli strati di embedding sono una componente significativa degli LLM utilizzata per convertire dati categorici, come le parole, in rappresentazioni vettoriali dense. Questi embedding catturano le relazioni semantiche tra le parole rappresentandole in uno spazio vettoriale continuo, dove parole simili risultano più vicine. L’importanza degli embedding negli LLM include:
I positional encoding indicano ai transformer la posizione di ciascun token nella sequenza.
I tradizionali positional encoding sinusoidali (da Vaswani et al., 2017) usavano funzioni matematiche fisse per codificare staticamente le posizioni. I Rotary Position Embeddings (RoPE), introdotti più recentemente, sono diventati lo standard nei moderni LLM perché offrono proprietà fondamentalmente superiori.
RoPE funziona rappresentando le posizioni come angoli di rotazione in uno spazio vettoriale complesso, ruotando gli embedding dei token di un angolo proporzionale alla loro posizione. Questo approccio geometrico è più efficiente e supporta naturalmente l’interpolazione verso sequenze più lunghe di quelle viste in addestramento, una capacità cruciale per estendere le finestre di contesto. Modelli come GPT-5.2 e Gemini 3 usano RoPE come positional encoding.
Sulla base dei concetti di base, le domande di livello intermedio approfondiscono le tecniche pratiche usate per ottimizzare le prestazioni degli LLM e affrontare sfide legate all’efficienza computazionale e all’interpretabilità del modello.
Il concetto di attention negli LLM è un metodo che consente al modello di concentrarsi su parti diverse della sequenza di input durante le previsioni. Assegna dinamicamente pesi agli altri token in input, evidenziando quelli più rilevanti per il compito corrente.
Viene implementato tramite self-attention, in cui il modello calcola gli score di attenzione per ciascun token rispetto a tutti gli altri token della sequenza, permettendo di catturare dipendenze indipendentemente dalla distanza.
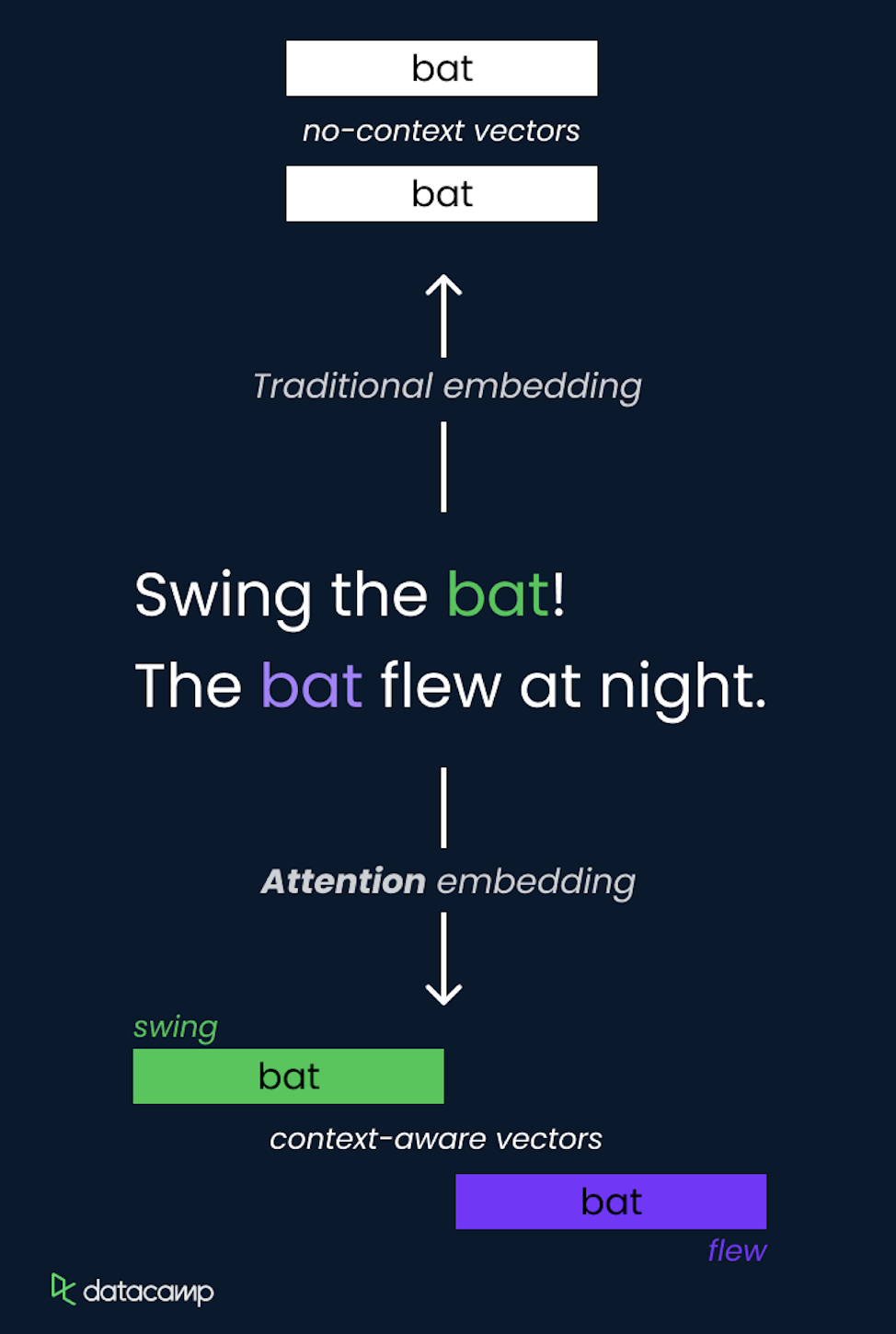
Il meccanismo di self-attention è un componente centrale dell’architettura Transformer, che le consente di elaborare informazioni in modo efficiente e catturare relazioni a lungo raggio.
La tokenizzazione converte il testo grezzo in unità più piccole chiamate token, che possono essere parole, sotto-parole o caratteri.
Il ruolo della tokenizzazione nell’elaborazione degli LLM è fondamentale perché trasforma il testo in un formato che il modello può comprendere ed elaborare.
Una tokenizzazione efficace assicura che il modello riesca a gestire un’ampia varietà di input, inclusi termini rari e lingue diverse, suddividendoli in parti gestibili. Questo passaggio è necessario per un addestramento e un’inferenza ottimali, poiché standardizza l’input e aiuta il modello a imparare pattern significativi nei dati.
Ricercatori e professionisti hanno sviluppato numerose metriche di valutazione per misurare le prestazioni di un LLM. Le metriche classiche includono:
Oltre alle metriche tradizionali, oggi si usano benchmark standardizzati per scopi diversi, come MMLU (test di conoscenza su 57 compiti), MMMU-Pro (ragionamento multimodale) e HumanEval (generazione di codice). Inoltre, classifiche come LMArena ordinano gli LLM in base alle preferenze umane. Per i sistemi in produzione, è diventato essenziale misurare tassi di allucinazione nel mondo reale, latenza ed efficienza dei token.
Si possono usare diverse tecniche per controllare l’output di un LLM, tra cui:
Per ridurre il costo computazionale degli LLM, si possono adottare:
L’interpretabilità del modello è essenziale per capire come un LLM prende decisioni, fondamentale per costruire fiducia, garantire responsabilità e individuare e mitigare i bias. Per ottenere interpretabilità si possono adottare diversi approcci, tra cui:
Gli LLM gestiscono le dipendenze a lungo termine nel testo tramite la loro architettura, in particolare il meccanismo di self-attention, che permette di considerare simultaneamente tutti i token della sequenza di input. Questa capacità di prestare attenzione a token distanti aiuta gli LLM a catturare relazioni e dipendenze su contesti estesi.
Inoltre, modelli avanzati come Transformer-XL e Longformer sono specificamente progettati per estendere la finestra di contesto e gestire sequenze più lunghe in modo più efficace, garantendo una migliore gestione delle dipendenze a lungo termine.
I modelli moderni in produzione usano strategie più avanzate per gestire le dipendenze a lungo termine e contrastare il degrado delle prestazioni con l’espansione della finestra di contesto, come:
La RAG combina meccanismi di recupero con modelli generativi per reperire informazioni rilevanti da fonti esterne durante la generazione del testo. Questo approccio affronta direttamente due limiti critici degli LLM: le allucinazioni e l’attualità della conoscenza. La RAG tradizionale usa pipeline di recupero e generazione relativamente semplici, ma con l’evoluzione verso la "RAG 2.0" è diventata significativamente più sofisticata.
Le caratteristiche chiave della RAG 2.0 includono:
La RAG 2.0, combinata con gli LLM, riduce efficacemente i tassi di allucinazione del 40–60% nei sistemi in produzione rispetto ai modelli base.
Comprendere i concetti avanzati negli LLM è utile per i professionisti che mirano a spingere i limiti di ciò che questi modelli possono ottenere. Questa sezione esplora argomenti complessi e sfide comuni del settore.
Il few-shot learning negli LLM indica la capacità del modello di apprendere ed eseguire nuovi compiti usando solo pochi esempi. Questa capacità sfrutta l’ampia conoscenza pre-addestrata dell’LLM, permettendogli di generalizzare a partire da un numero ridotto di istanze.
I principali vantaggi del few-shot learning includono minori requisiti di dati, poiché si riduce la necessità di grandi dataset specifici per il compito, maggiore flessibilità, consentendo al modello di adattarsi a vari compiti con un fine-tuning minimo, ed efficienza dei costi, poiché requisiti di dati inferiori e tempi di addestramento ridotti si traducono in risparmi significativi nella raccolta dei dati e nelle risorse computazionali.
I modelli autoregressivi e i masked language model differiscono principalmente nell’approccio predittivo e nell’idoneità ai compiti. I modelli autoregressivi, come GPT-5.2, Claude 4.5 Opus e Gemini 3, prevedono la parola successiva in una sequenza sulla base delle parole precedenti, generando testo un token alla volta.
Questi modelli sono particolarmente adatti ai compiti di generazione di testo. Al contrario, i masked language model, come BERT, mascherano casualmente parole in una frase e addestrano il modello a prevederle in base al contesto circostante. Questo approccio bidirezionale aiuta il modello a comprendere il contesto in entrambe le direzioni, rendendolo ideale per compiti di classificazione del testo e question answering.
L’integrazione di conoscenza esterna in un LLM può essere ottenuta con diversi metodi:
Il deployment degli LLM in produzione comporta diverse sfide:
Il degrado del modello si verifica quando le prestazioni di un LLM diminuiscono nel tempo a causa di cambiamenti nella distribuzione dei dati sottostante. Per gestirlo, è necessario il riaddestramento regolare con dati aggiornati per mantenere le prestazioni. Un monitoraggio continuo è necessario per tracciare le prestazioni del modello e rilevare segnali di degrado.
Tecniche di apprendimento incrementale consentono al modello di apprendere da nuovi dati senza dimenticare quanto già appreso. Inoltre, l’A/B testing confronta le prestazioni del modello attuale con nuove versioni e aiuta a individuare possibili miglioramenti prima del deployment completo.
Per garantire l’uso etico degli LLM, si possono implementare diverse tecniche:
La sicurezza dei dati usati con gli LLM richiede l’implementazione di varie misure. Tra queste, l’uso di tecniche di cifratura per i dati a riposo e in transito per proteggerli da accessi non autorizzati. Controlli di accesso rigorosi sono necessari per garantire che solo il personale autorizzato possa accedere ai dati sensibili.
È inoltre fondamentale anonimizzare i dati per rimuovere le informazioni personali identificabili (PII) prima di usarli per addestramento o inferenza. Inoltre, la conformità a normative sulla protezione dei dati come GDPR o CCPA è essenziale per evitare problemi legali.
Queste misure aiutano a proteggere integrità, riservatezza e disponibilità dei dati. Tale protezione è cruciale per mantenere la fiducia degli utenti e rispettare gli standard normativi.
RLHF è una tecnica che consiste nell’addestrare un LLM ad allineare i propri output alle preferenze umane incorporando il feedback dei valutatori. Questo processo iterativo aiuta il modello a generare risposte non solo accurate ma anche sicure, non di parte e utili.
Tuttavia, l’RLHF presenta sfide. Una riguarda il potenziale bias nel feedback umano, poiché valutatori diversi possono avere preferenze e interpretazioni differenti.
Un’altra sfida è la scalabilità del processo di feedback, poiché raccogliere e incorporare grandi quantità di feedback umano può essere dispendioso in termini di tempo e costi. Inoltre, garantire che il modello di ricompensa usato nell’RLHF catturi accuratamente i comportamenti e i valori desiderati può essere complesso. Lo step di ottimizzazione PPO (Proximal Policy Optimization) aggiunge complessità e può introdurre instabilità durante l’addestramento.
Sono emerse alternative moderne che affrontano molte delle limitazioni dell’RLHF:
La maggior parte dei modelli in produzione usa DPO, RLAIF o combinazioni ibride piuttosto che un RLHF puro basato su PPO.
Le allucinazioni basate sulla conoscenza si verificano quando il modello non dispone dei fatti corretti (o ha fatti obsoleti) e quindi inventa informazioni plausibili. Le correzioni in genere prevedono:
Le allucinazioni basate sulla logica si verificano quando il modello dispone di informazioni pertinenti ma ragiona in modo errato o produce incongruenze. Le correzioni comuni sono:
Sebbene oggi i Transformer dominino gli LLM, i modelli state-space (SSM) come Mamba sono emersi come un paradigma architetturale competitivo con proprietà computazionali e prestazionali fondamentalmente diverse. Conoscere entrambi è sempre più importante per i professionisti moderni degli LLM.
Transformer:
State-Space Models (Mamba, Mamba-2):
Ricerche recenti dimostrano che Transformer e SSM sono complementari più che direttamente in competizione, con casi d’uso e vincoli diversi che favoriscono architetture differenti. I Transformer restano la scelta pratica per LLM generalisti e probabilmente continueranno a dominare per ora. È probabile un futuro ibrido, con modelli specializzati per diversi requisiti computazionali e di compito.
Il prompt engineering è un aspetto importante nell’utilizzo degli LLM. Consiste nel creare prompt precisi ed efficaci per generare dal modello le risposte desiderate. Questa sezione esamina le principali domande che i prompt engineer possono incontrare.
Il prompt engineering consiste nel progettare e perfezionare i prompt per guidare gli LLM nella generazione di output accurati e pertinenti. È fondamentale per lavorare con gli LLM perché la qualità del prompt impatta direttamente sulle prestazioni del modello.
Prompt efficaci possono migliorare la capacità del modello di comprendere il compito, generare risposte accurate e rilevanti e ridurre la probabilità di errori.
Il prompt engineering è essenziale per massimizzare l’utilità degli LLM in varie applicazioni, dalla generazione di testo alla risoluzione di problemi complessi.
Valutare l’efficacia di un prompt comporta:
Il perfezionamento iterativo dei prompt prevede:
Diversi strumenti e framework possono semplificare il processo di prompt engineering:
Questa domanda affronta le questioni etiche e pratiche dei contenuti generati dagli LLM. Una buona risposta dovrebbe mostrare consapevolezza di questi problemi e discutere tecniche come le seguenti.
Tecniche di mitigazione delle allucinazioni:
Tecniche di mitigazione dei bias:
I template di prompt forniscono un formato strutturato per i prompt, spesso con segnaposto per informazioni o istruzioni specifiche. Possono essere riutilizzati in compiti e scenari diversi, migliorando coerenza ed efficienza nella progettazione dei prompt.
Una buona risposta spiegherebbe come i template possano racchiudere best practice, incorporare conoscenze specifiche di dominio e semplificare il processo di generazione di prompt efficaci per varie applicazioni.
Il tokenizer ha un ruolo cruciale nel modo in cui l’LLM interpreta ed elabora il prompt di input. Tokenizer diversi hanno dimensioni di vocabolario differenti e gestiscono in modo diverso le parole fuori vocabolario (OOV). Un tokenizer a sotto-parole come il Byte Pair Encoding (BPE) può gestire le parole OOV suddividendole in sotto-unità più piccole, mentre un tokenizer basato su parole potrebbe trattarle come token sconosciuti.
La scelta del tokenizer può influire sulle prestazioni del modello in diversi modi. Ad esempio, un tokenizer a sotto-parole può essere più efficace nel catturare il significato di termini rari o tecnici, mentre un tokenizer basato su parole può essere più semplice e veloce per compiti linguistici generici.
Nel prompt engineering, la scelta del tokenizer può influenzare la struttura dei prompt. Ad esempio, usando un tokenizer a sotto-parole potresti dover prestare più attenzione a come le parole vengono suddivise per garantire che il modello colga il significato desiderato.
L’agentic prompting è un approccio di progettazione dei prompt in cui si istruisce il modello ad agire come un “agente” che può pianificare, compiere azioni (ad esempio chiamare tool/API o recuperare documenti), osservare i risultati e iterare finché non completa un obiettivo.
A differenza del prompt engineering tradizionale, che mira soprattutto a ottenere la miglior risposta possibile in un solo colpo attraverso istruzioni chiare, esempi e vincoli di formattazione, l’agentic prompting enfatizza un ciclo di controllo multi-step (pianifica → agisci → osserva → perfeziona).
È particolarmente utile per compiti in cui la correttezza dipende dall’interazione con sistemi esterni (database, ricerca, esecuzione di codice) o dalla verifica di risultati intermedi, piuttosto che dal solo sapere interno del modello.
I buoni prompt agentici definiscono in genere l’obiettivo, gli strumenti/azioni disponibili, come decidere quale azione intraprendere e quando fermarsi. È anche comune aggiungere passaggi espliciti di verifica (ad es. “controlla le fonti recuperate” o “ricalcola prima della risposta finale”) per ridurre le allucinazioni e migliorare l’affidabilità.
Scopri di più sugli LLM!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

