
Leerpad
AI-basisprincipes
10 Hr
Large language models (LLM’s) zijn steeds belangrijker geworden binnen kunstmatige intelligentie, met toepassingen in uiteenlopende sectoren.
Nu de vraag naar professionals met LLM-expertise groeit, biedt dit artikel een uitgebreide set interviewvragen en -antwoorden, van basisbegrippen tot geavanceerde technieken en praktische toepassingen.
Of je je nu voorbereidt op een sollicitatiegesprek of je kennis wilt uitbreiden, dit artikel komt van pas.
Om LLM’s te begrijpen, is het belangrijk te beginnen bij de basisconcepten. Deze fundamenten bestrijken essentiële aspecten zoals architectuur, kernmechanismen en typische uitdagingen, en vormen een solide basis om verder te leren over meer geavanceerde onderwerpen.
De Transformer-architectuur is een deep-learningmodel, geïntroduceerd door Vaswani et al. in 2017, ontworpen om sequentiële data efficiënter en met betere prestaties te verwerken dan eerdere modellen zoals recurrent neural networks (RNN’s) en long short-term memory (LSTM’s).
Het steunt op self-attention-mechanismen om inputdata parallel te verwerken, waardoor het zeer schaalbaar is en lange-afstandsafhankelijkheden kan vastleggen.
In LLM’s vormt de Transformer-architectuur de ruggengraat, waardoor modellen grote hoeveelheden tekst efficiënt kunnen verwerken en contextueel relevante, coherente tekst kunnen genereren.
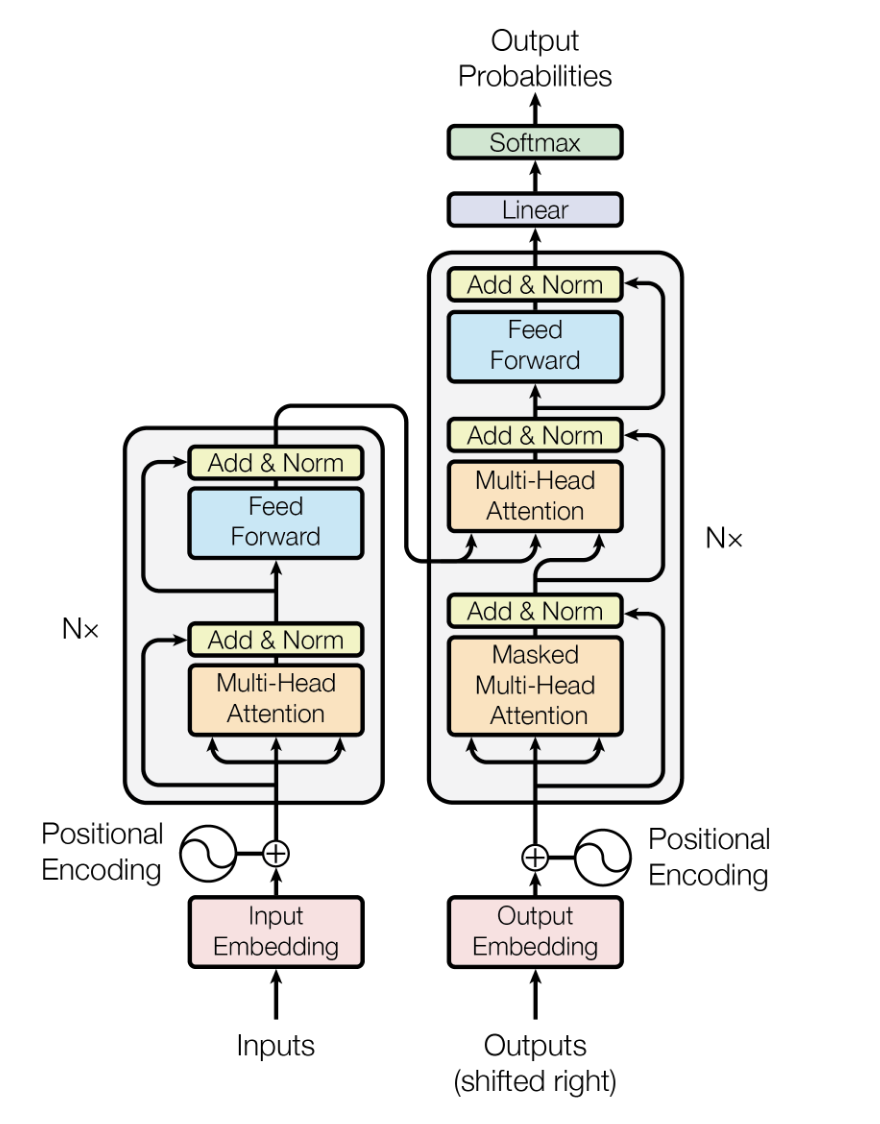
De Transformer-modelarchitectuur. Bron
De context window in LLM’s verwijst naar de hoeveelheid tekst (in termen van tokens of woorden) die het model in één keer kan meenemen bij het genereren of begrijpen van taal. De betekenis van de context window ligt in de invloed op het vermogen van het model om logische en relevante antwoorden te geven.
Over het algemeen stelt een grotere context window het model in staat meer context mee te nemen, wat leidt tot beter begrip en betere tekstgeneratie, vooral in complexe of lange gesprekken. Daartegenover staat dat de rekenvereisten toenemen, waardoor het een afweging is tussen prestaties en efficiëntie.
Daarnaast laat recent onderzoek zien dat veel modellen al vóór hun opgegeven limieten slechter presteren. Modellen kunnen een “lost in the middle”-fenomeen vertonen, waarbij informatie in het midden van de context wordt genegeerd of minder prioriteit krijgt. Daarom presteert zorgvuldig geselecteerde, relevante context in kleinere vensters vaak beter dan het vullen van grotere vensters met ruis.
Veelgebruikte pre-trainingsdoelen voor LLM’s zijn masked language modeling (MLM) en autoregressieve taalmodellering. Bij MLM worden willekeurige woorden in een zin gemaskeerd en wordt het model getraind om de gemaskeerde woorden te voorspellen op basis van de omringende context. Dit helpt het model om bidirectionele context te begrijpen.
Autoregressieve taalmodellering houdt in dat het volgende woord in een reeks wordt voorspeld, en dat het model wordt getraind om tekst token voor token te genereren. Beide doelen laten het model taalpatronen en semantiek leren uit grote corpora en vormen zo een stevige basis voor fine-tuning op specifieke taken.
Fine-tuning in de context van LLM’s houdt in dat je een voorgetraind model neemt en het verder traint op een kleinere, taakspecifieke dataset. Dit helpt het model zijn algemene taalbegrip aan te passen aan de nuances van de specifieke toepassing en verbetert zo de prestaties.
Dit is belangrijk omdat het de brede taalkennis uit de pre-training benut, terwijl het model wordt bijgestuurd om goed te presteren op specifieke toepassingen, zoals sentimentanalyse, samenvatten of vraag-en-antwoord.
Het gebruik van LLM’s kent verschillende uitdagingen, waaronder:
LLM’s gaan met out-of-vocabulary (OOV)-woorden of -tokens om via technieken als subword-tokenisatie (bijv. Byte Pair Encoding of BPE, en WordPiece). Deze technieken splitsen onbekende woorden op in kleinere, bekende subword-eenheden die het model kan verwerken.
Zo kan het model, zelfs als een woord niet tijdens training is gezien, de tekst nog begrijpen en genereren op basis van de samenstellende delen. Dat vergroot flexibiliteit en robuustheid.
Embedding-lagen zijn een belangrijk onderdeel in LLM’s om categorische data, zoals woorden, om te zetten naar dichte vectorrepresentaties. Deze embeddings vangen semantische relaties tussen woorden door ze te representeren in een continue vectorruimte, waarin vergelijkbare woorden dichter bij elkaar liggen. De importantie van embedding-lagen in LLM’s omvat:
Positionele coderingen geven transformers aan waar elk token zich in de sequentie bevindt.
Traditionele sinusvormige positionele coderingen (van Vaswani et al. 2017) gebruikten vaste wiskundige functies om posities statisch te coderen. Rotary Position Embeddings (RoPE), recenter geïntroduceerd, zijn de standaard geworden in moderne LLM’s omdat ze fundamenteel superieure eigenschappen bieden.
RoPE werkt door posities te representeren als rotatiehoeken in een complexe vectorruimte, waarbij token-embeddings worden geroteerd met een hoek evenredig aan hun positie. Deze geometrische benadering is efficiënter en ondersteunt van nature interpolatie naar langere sequenties dan tijdens training gezien, wat cruciaal is om contextvensters te vergroten. Modellen zoals GPT-5.2 en Gemini 3 gebruiken RoPE als hun positionele codering.
Voortbouwend op de basis duiken vragen op middelniveau in de praktische technieken om LLM-prestaties te optimaliseren en uitdagingen aan te pakken rond rekenefficiëntie en modeluitlegbaarheid.
Attention is een methode waarmee het model zich kan richten op verschillende delen van de inputsequentie bij het doen van voorspellingen. Het kent dynamisch gewichten toe aan andere tokens in de input en markeert zo de meest relevante voor de huidige taak.
Dit wordt geïmplementeerd via self-attention, waarbij het model attentiescores berekent voor elk token ten opzichte van alle andere tokens in de sequentie, zodat het afhankelijkheden kan vastleggen ongeacht hun afstand.
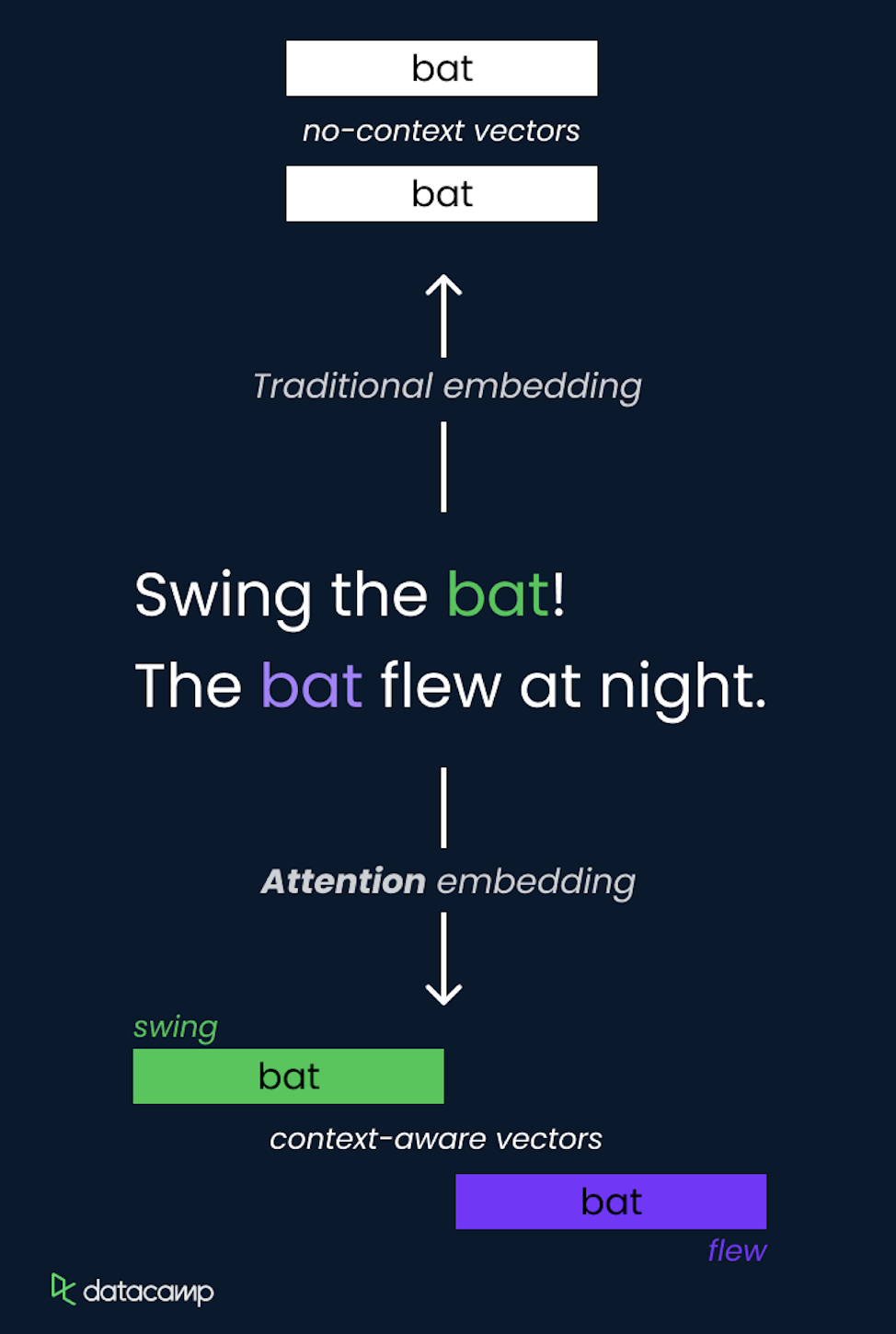
Het self-attention-mechanisme is een kernonderdeel van de Transformer-architectuur en maakt efficiënte verwerking en het vastleggen van langetermijnrelaties mogelijk.
Tokenisatie zet ruwe tekst om in kleinere eenheden, tokens genoemd, die woorden, subwords of karakters kunnen zijn.
De rol van tokenisatie in LLM-verwerking is cruciaal omdat het tekst omzet in een formaat dat het model kan begrijpen en verwerken.
Effectieve tokenisatie zorgt ervoor dat het model een breed scala aan input aankan, inclusief zeldzame woorden en verschillende talen, door ze op te splitsen in hanteerbare stukjes. Deze stap is noodzakelijk voor optimale training en inferentie, omdat ze de input standaardiseert en het model helpt betekenisvolle patronen in de data te leren.
Onderzoekers en practitioners hebben tal van evaluatiemetrics ontwikkeld om de prestaties van een LLM te meten. Klassieke metrics zijn onder meer:
Naast traditionele metrics gebruiken practitioners nu gestandaardiseerde benchmarks voor verschillende doelen, zoals MMLU (57-taken kennistest), MMMU-Pro (multimodale redenering) en HumanEval (codegeneratie). Daarnaast rangschikken leaderboards zoals LMArena LLM’s op basis van menselijke voorkeur. Voor uitgerolde systemen zijn het meten van hallucinatiepercentages in de praktijk, latency en tokenefficiëntie essentieel geworden.
Er zijn verschillende technieken om de output van een LLM te sturen, waaronder:
Om de rekenkosten van LLM’s te verlagen, kun je inzetten op:
Modeluitlegbaarheid is cruciaal om te begrijpen hoe een LLM beslissingen neemt, wat belangrijk is voor vertrouwen, verantwoording en het identificeren en mitigeren van biases. Uitlegbaarheid bereiken kan via verschillende benaderingen, zoals:
LLM’s verwerken langetermijnafhankelijkheden in tekst via hun architectuur, met name het self-attention-mechanisme, waarmee ze alle tokens in de inputsequentie tegelijk kunnen meenemen. Dit vermogen om naar verre tokens te kijken helpt LLM’s relaties en afhankelijkheden over lange contexten vast te leggen.
Daarnaast zijn geavanceerde modellen zoals Transformer-XL en Longformer specifiek ontworpen om de context window te vergroten en langere sequenties effectiever te verwerken, wat zorgt voor betere omgang met langetermijnafhankelijkheden.
Moderne productiemodellen gebruiken geavanceerdere strategieën om langetermijnafhankelijkheden te verwerken en prestatiedegradatie bij grotere contextvensters tegen te gaan, zoals:
RAG combineert retrievalmechanismen met generatieve modellen om tijdens tekstgeneratie relevante informatie uit externe bronnen op te halen. Deze aanpak pakt direct twee belangrijke LLM-beperkingen aan: hallucinaties en actualiteit van kennis. Traditionele RAG gebruikt relatief eenvoudige pipelines voor ophalen en genereren, maar in zijn evolutie naar “RAG 2.0” is het aanzienlijk geavanceerder geworden.
Belangrijke kenmerken van RAG 2.0 zijn:
RAG 2.0, gecombineerd met LLM’s, reduceert hallucinatiepercentages in productiesystemen effectief met 40–60% vergeleken met basismodellen.
Geavanceerde concepten in LLM’s begrijpen is nuttig voor professionals die de grenzen willen verleggen van wat deze modellen kunnen. Dit deel verkent complexe onderwerpen en veelvoorkomende uitdagingen in het veld.
Few-shot learning in LLM’s verwijst naar het vermogen van het model om nieuwe taken te leren en uit te voeren met slechts enkele voorbeelden. Deze capaciteit benut de uitgebreide, voorgetrainde kennis van het LLM, waardoor het kan generaliseren op basis van een klein aantal voorbeelden.
De belangrijkste voordelen van few-shot learning zijn minder data-eisen, doordat grote taakspecifieke datasets minder nodig zijn; meer flexibiliteit, doordat het model zich met minimale fine-tuning kan aanpassen aan uiteenlopende taken; en kostenefficiëntie, omdat minder data en kortere trainingstijden leiden tot aanzienlijke besparingen in dataverzameling en rekenmiddelen.
Autoregressieve en gemaskeerde taalmodellen verschillen vooral in hun voorspellingsaanpak en taakgeschiktheid. Autoregressieve modellen, zoals GPT-5.2, Claude 4.5 Opus en Gemini 3, voorspellen het volgende woord in een reeks op basis van de voorgaande woorden en genereren tekst token voor token.
Deze modellen zijn bij uitstek geschikt voor tekstgeneratie. Daarentegen maskeren gemaskeerde taalmodellen, zoals BERT, willekeurig woorden in een zin en trainen ze het model om deze gemaskeerde woorden te voorspellen op basis van de omringende context. Deze bidirectionele aanpak helpt het model context vanuit beide richtingen te begrijpen, wat het ideaal maakt voor tekstclassificatie en vraag-en-antwoord.
Externe kennis in een LLM integreren kan op verschillende manieren:
Het uitrollen van LLM’s in productie brengt diverse uitdagingen met zich mee:
Modeldegradatie treedt op wanneer de prestaties van een LLM in de loop van de tijd afnemen door veranderingen in de onderliggende dataverdeling. Om dit te adresseren, is regelmatige hertraining met geüpdatete data nodig om prestaties te behouden. Continue monitoring is noodzakelijk om de prestaties van het model te volgen en tekenen van degradatie te detecteren.
Incrementele leertechnieken stellen het model in staat te leren van nieuwe data zonder eerder geleerde informatie te vergeten. Daarnaast vergelijkt A/B-testen de prestaties van het huidige model met nieuwe versies en helpt zo verbeteringen te identificeren vóór volledige uitrol.
Om het ethische gebruik van LLM’s te borgen, kun je verschillende technieken implementeren:
Dataveiligheid bij LLM’s vereist diverse maatregelen. Denk aan encryptie voor data in rust en tijdens transport om ongeautoriseerde toegang te voorkomen. Strikte toegangscontrole is nodig om te waarborgen dat alleen geautoriseerd personeel toegang heeft tot gevoelige data.
Data anonimiseren om persoonsgegevens (PII) te verwijderen voordat die voor training of inferentie wordt gebruikt, is ook cruciaal. Daarnaast is naleving van regelgeving voor gegevensbescherming, zoals de AVG of CCPA, essentieel om juridische problemen te vermijden.
Deze maatregelen beschermen de integriteit, vertrouwelijkheid en beschikbaarheid van data. Die bescherming is cruciaal om gebruikersvertrouwen te behouden en aan regelgeving te voldoen.
RLHF is een techniek waarbij een LLM wordt getraind om zijn output af te stemmen op menselijke voorkeuren door feedback van menselijke beoordelaars te incorporeren. Dit iteratieve proces helpt het model om reacties te geven die niet alleen accuraat zijn, maar ook veilig, onbevooroordeeld en behulpzaam.
RLHF kent echter uitdagingen. Eén daarvan is mogelijke bias in de menselijke feedback, omdat verschillende beoordelaars uiteenlopende voorkeuren en interpretaties kunnen hebben.
Een andere uitdaging is de schaalbaarheid van het feedbackproces, aangezien het verzamelen en verwerken van veel menselijke feedback tijdrovend en kostbaar kan zijn. Daarnaast is het lastig om te waarborgen dat het beloningsmodel in RLHF de gewenste gedragingen en waarden nauwkeurig vastlegt. De PPO (Proximal Policy Optimization)-stap voegt complexiteit toe en kan instabiliteit tijdens training introduceren.
Er zijn moderne alternatieven ontstaan die veel RLHF-beperkingen adresseren:
De meeste productiemodellen gebruiken DPO, RLAIF of hybride combinaties in plaats van pure, op PPO gebaseerde RLHF.
Kennisgebaseerde hallucinaties ontstaan wanneer het model niet over de juiste feiten beschikt (of verouderde feiten heeft) en daarom aannemelijk klinkende informatie verzint. Oplossingen omvatten doorgaans:
Logische hallucinaties ontstaan wanneer het model wel over relevante informatie beschikt, maar onjuist redeneert of inconsistenties produceert. Veelvoorkomende oplossingen zijn:
Hoewel Transformers vandaag de dag dominant zijn bij LLM’s, zijn state-space-modellen (SSM’s) zoals Mamba opgekomen als een concurrerend architecturaal paradigma met fundamenteel andere rekenkundige en prestatie-eigenschappen. Beide begrijpen wordt steeds belangrijker voor moderne LLM-professionals.
Transformers:
State-Space-modellen (Mamba, Mamba-2):
Recent onderzoek laat zien dat Transformers en SSM’s complementair zijn in plaats van direct concurrerend, met uiteenlopende use-cases en randvoorwaarden die verschillende architecturen begunstigen. Transformers blijven de praktische keuze voor general-purpose LLM’s en zullen naar verwachting voorlopig domineren. Een hybride toekomst ligt voor de hand, met gespecialiseerde modellen voor verschillende reken- en taakvereisten.
Prompt engineering is een belangrijk aspect van het benutten van LLM’s. Het omvat het zorgvuldig formuleren van precieze en effectieve prompts om gewenste reacties van het model te genereren. Dit deel behandelt kernvragen die prompt engineers kunnen tegenkomen.
Prompt engineering draait om het ontwerpen en verfijnen van prompts om LLM’s te sturen naar accurate en relevante output. Het is cruciaal omdat de kwaliteit van de prompt direct de prestaties van het model beïnvloedt.
Effectieve prompts kunnen het vermogen van het model om de taak te begrijpen vergroten, leiden tot accurate en relevante antwoorden en de kans op fouten verkleinen.
Prompt engineering is essentieel om de waarde van LLM’s te maximaliseren in uiteenlopende toepassingen, van tekstgeneratie tot complexe probleemoplossing.
De effectiviteit van een prompt evalueren omvat:
Iteratieve promptverfijning omvat:
Diverse tools en frameworks kunnen het promptengineeringproces stroomlijnen:
Deze vraag raakt aan de ethische en praktische kwesties rond door LLM’s gegenereerde content. Een sterk antwoord toont bewustzijn van deze problemen en bespreekt technieken zoals de volgende.
Technieken om hallucinaties te mitigeren:
Technieken om bias te mitigeren:
Prompttemplates bieden een gestructureerd format voor prompts, vaak met placeholders voor specifieke informatie of instructies. Ze kunnen worden hergebruikt in verschillende taken en scenario’s en verbeteren de consistentie en efficiëntie van promptontwerp.
Een goed antwoord laat zien hoe prompttemplates best practices kunnen vastleggen, domeinspecifieke kennis kunnen opnemen en het genereren van effectieve prompts voor diverse toepassingen kunnen stroomlijnen.
De tokenizer speelt een cruciale rol in hoe het LLM de inputprompt interpreteert en verwerkt. Verschillende tokenizers hebben uiteenlopende vocabulairgroottes en gaan anders om met out-of-vocabulary (OOV)-woorden. Een subword-tokenizer zoals Byte Pair Encoding (BPE) kan OOV-woorden aan door ze op te splitsen in kleinere subword-eenheden, terwijl een woordgebaseerde tokenizer ze als onbekende tokens kan behandelen.
De keuze van tokenizer kan de prestaties van het model op meerdere manieren beïnvloeden. Zo kan een subword-tokenizer effectiever zijn in het vastleggen van de betekenis van zeldzame of technische termen, terwijl een woordgebaseerde tokenizer eenvoudiger en sneller kan zijn voor algemene taaltoepassingen.
Bij prompt engineering kan de keuze van tokenizer bepalen hoe je je prompts structureert. Gebruik je bijvoorbeeld een subword-tokenizer, dan moet je mogelijk beter letten op hoe woorden in subwords worden opgesplitst om te borgen dat het model de beoogde betekenis oppikt.
Agentische prompting is een promptontwerpaanpak waarbij het model wordt geïnstrueerd om te handelen als een “agent” die kan plannen, acties kan uitvoeren (bijvoorbeeld tools/API’s aanroepen of documenten ophalen), de resultaten kan observeren en kan itereren totdat een doel is bereikt.
In tegenstelling tot traditionele prompt engineering, die vooral probeert om in één keer het beste mogelijke antwoord te krijgen via duidelijke instructies, voorbeelden en opmaakconstraints, legt agentische prompting de nadruk op een meerstaps controllus (plannen → handelen → observeren → verfijnen).
Het is vooral nuttig voor taken waarbij correctheid afhangt van interactie met externe systemen (databases, zoeken, code-uitvoering) of het verifiëren van tussentijdse resultaten, in plaats van te vertrouwen op alleen de interne kennis van het model.
Goede agentische prompts definiëren doorgaans het doel, de beschikbare tools/acties, hoe te beslissen welke actie te nemen en wanneer te stoppen. Het is ook gebruikelijk om expliciete verificatiestappen toe te voegen (bijv. “controleer opgehaalde bronnen” of “reken opnieuw vóór het eindantwoord”) om hallucinaties te verminderen en de betrouwbaarheid te verhogen.
Leer meer over LLM’s!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
