
Program
Dasar-Dasar Kecerdasan Buatan
10 Hr
Large language models (LLM) menjadi semakin penting dalam kecerdasan buatan, dengan aplikasi di berbagai industri.
Seiring meningkatnya permintaan terhadap profesional yang memiliki keahlian LLM, artikel ini menyediakan kumpulan pertanyaan dan jawaban wawancara yang komprehensif, mencakup konsep dasar, teknik lanjutan, dan penerapan praktis.
Jika Anda sedang mempersiapkan wawancara kerja atau sekadar ingin memperluas pengetahuan, artikel ini akan bermanfaat.
Untuk memahami LLM, penting untuk memulai dari konsep fundamental. Pertanyaan-pertanyaan dasar ini mencakup aspek penting seperti arsitektur, mekanisme kunci, dan tantangan umum, sehingga memberikan landasan kuat untuk mempelajari topik yang lebih lanjut.
Arsitektur Transformer adalah model deep learning yang diperkenalkan oleh Vaswani dkk. pada 2017, dirancang untuk menangani data sekuensial dengan efisiensi dan kinerja yang lebih baik dibandingkan model sebelumnya seperti recurrent neural networks (RNN) dan long short-term memory (LSTM).
Model ini mengandalkan mekanisme self-attention untuk memproses data masukan secara paralel, sehingga sangat skalabel dan mampu menangkap ketergantungan jarak jauh.
Dalam LLM, arsitektur Transformer menjadi tulang punggung, memungkinkan model memproses data teks dalam jumlah besar secara efisien dan menghasilkan keluaran teks yang relevan secara kontekstual dan koheren.
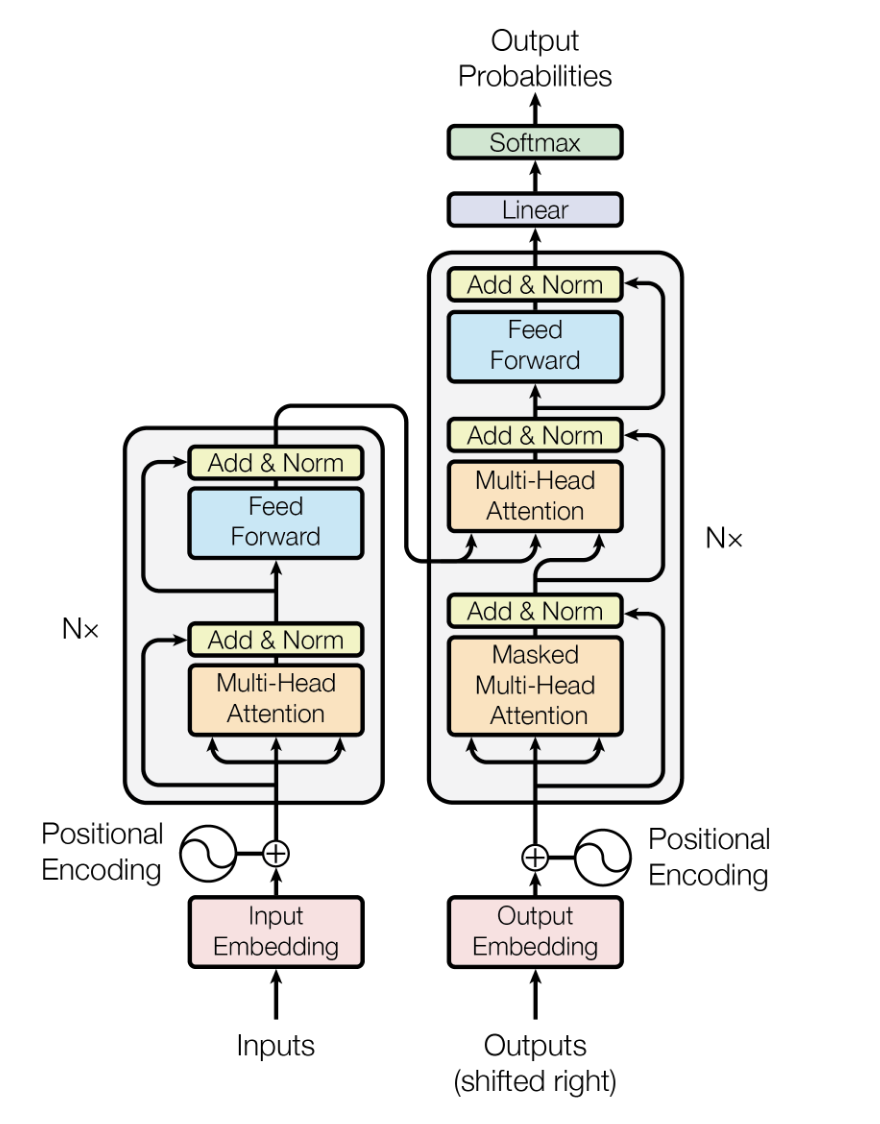
Arsitektur model Transformer. Sumber
Context window dalam LLM mengacu pada rentang teks (dalam token atau kata) yang dapat dipertimbangkan model sekaligus saat menghasilkan atau memahami bahasa. Signifikansi context window terletak pada dampaknya terhadap kemampuan model untuk menghasilkan respons yang logis dan relevan.
Secara umum, context window yang lebih besar memungkinkan model mempertimbangkan lebih banyak konteks, sehingga menghasilkan pemahaman dan generasi teks yang lebih baik, terutama dalam percakapan yang kompleks atau panjang. Namun, ini juga meningkatkan kebutuhan komputasi, sehingga perlu keseimbangan antara kinerja dan efisiensi.
Selain itu, riset terbaru mengungkapkan bahwa kebanyakan model menunjukkan penurunan kinerja jauh sebelum batas yang diiklankan. Model dapat menunjukkan fenomena "lost in the middle" di mana informasi di bagian tengah konteks diabaikan atau tidak diprioritaskan. Oleh karena itu, konteks yang terkurasi dan relevan dalam jendela yang lebih kecil sering kali mengungguli pengisian jendela besar dengan noise.
Tujuan pra-pelatihan umum untuk LLM mencakup masked language modeling (MLM) dan autoregressive language modeling. Pada MLM, kata-kata acak dalam sebuah kalimat ditutupi (masked), dan model dilatih untuk memprediksi kata yang ditutupi berdasarkan konteks sekitarnya. Ini membantu model memahami konteks dua arah.
Autoregressive language modeling melibatkan prediksi kata berikutnya dalam sebuah urutan dan melatih model untuk menghasilkan teks satu token demi satu. Kedua tujuan ini memungkinkan model mempelajari pola bahasa dan semantik dari korpus besar, menyediakan fondasi kuat untuk fine-tuning pada tugas spesifik.
Fine-tuning dalam konteks LLM melibatkan pengambilan model pra-terlatih dan melatihnya lebih lanjut pada dataset yang lebih kecil dan spesifik untuk tugas tertentu. Proses ini membantu model menyesuaikan pemahaman bahasa umum dengan nuansa aplikasi spesifik, sehingga meningkatkan kinerja.
Ini adalah teknik penting karena memanfaatkan pengetahuan bahasa yang luas yang diperoleh selama pra-pelatihan sambil memodifikasi model agar berkinerja baik pada aplikasi tertentu, seperti analisis sentimen, peringkasan teks, atau tanya jawab.
Menggunakan LLM memiliki beberapa tantangan, termasuk:
LLM menangani kata atau token di luar kosakata (OOV) menggunakan teknik seperti tokenisasi sub-kata (misalnya Byte Pair Encoding atau BPE, dan WordPiece). Teknik-teknik ini memecah kata yang tidak dikenal menjadi unit sub-kata yang lebih kecil dan dikenal oleh model.
Pendekatan ini memastikan bahwa meskipun sebuah kata tidak terlihat saat pelatihan, model tetap dapat memahami dan menghasilkan teks berdasarkan bagian-bagiannya, sehingga meningkatkan fleksibilitas dan ketangguhan.
Embedding layer adalah komponen penting dalam LLM yang digunakan untuk mengubah data kategorikal, seperti kata, menjadi representasi vektor dens. Embedding ini menangkap hubungan semantik antar-kata dengan merepresentasikannya dalam ruang vektor kontinu di mana kata-kata yang mirip memiliki kedekatan lebih kuat. Pentingnya embedding layer dalam LLM mencakup:
Positional encoding memberi tahu transformer posisi setiap token dalam urutan.
Positional encoding sinusoidal tradisional (dari Vaswani dkk. 2017) menggunakan fungsi matematis tetap untuk menyandikan posisi secara statis. Rotary Position Embeddings (RoPE), yang diperkenalkan belakangan, menjadi standar pada LLM modern karena menawarkan sifat yang secara fundamental lebih unggul.
RoPE bekerja dengan merepresentasikan posisi sebagai sudut rotasi dalam ruang vektor kompleks, memutar embedding token dengan sudut yang proporsional terhadap posisinya. Pendekatan geometris ini lebih efisien dan secara alami mendukung interpolasi ke sekuens yang lebih panjang daripada yang terlihat saat pelatihan, yang merupakan kemampuan krusial untuk memperluas context window. Model seperti GPT-5.2 dan Gemini 3 menggunakan RoPE sebagai positional encoding mereka.
Membangun di atas konsep dasar, pertanyaan tingkat menengah membahas teknik praktis untuk mengoptimalkan kinerja LLM serta mengatasi tantangan terkait efisiensi komputasi dan interpretabilitas model.
Konsep attention dalam LLM adalah metode yang memungkinkan model memfokuskan diri pada bagian-bagian berbeda dari urutan masukan saat membuat prediksi. Metode ini secara dinamis memberikan bobot pada token lain dalam masukan, menyoroti yang paling relevan untuk tugas saat ini.
Hal ini diimplementasikan menggunakan self-attention, di mana model menghitung skor attention untuk setiap token relatif terhadap semua token lain dalam urutan, memungkinkannya menangkap ketergantungan tanpa memandang jarak.
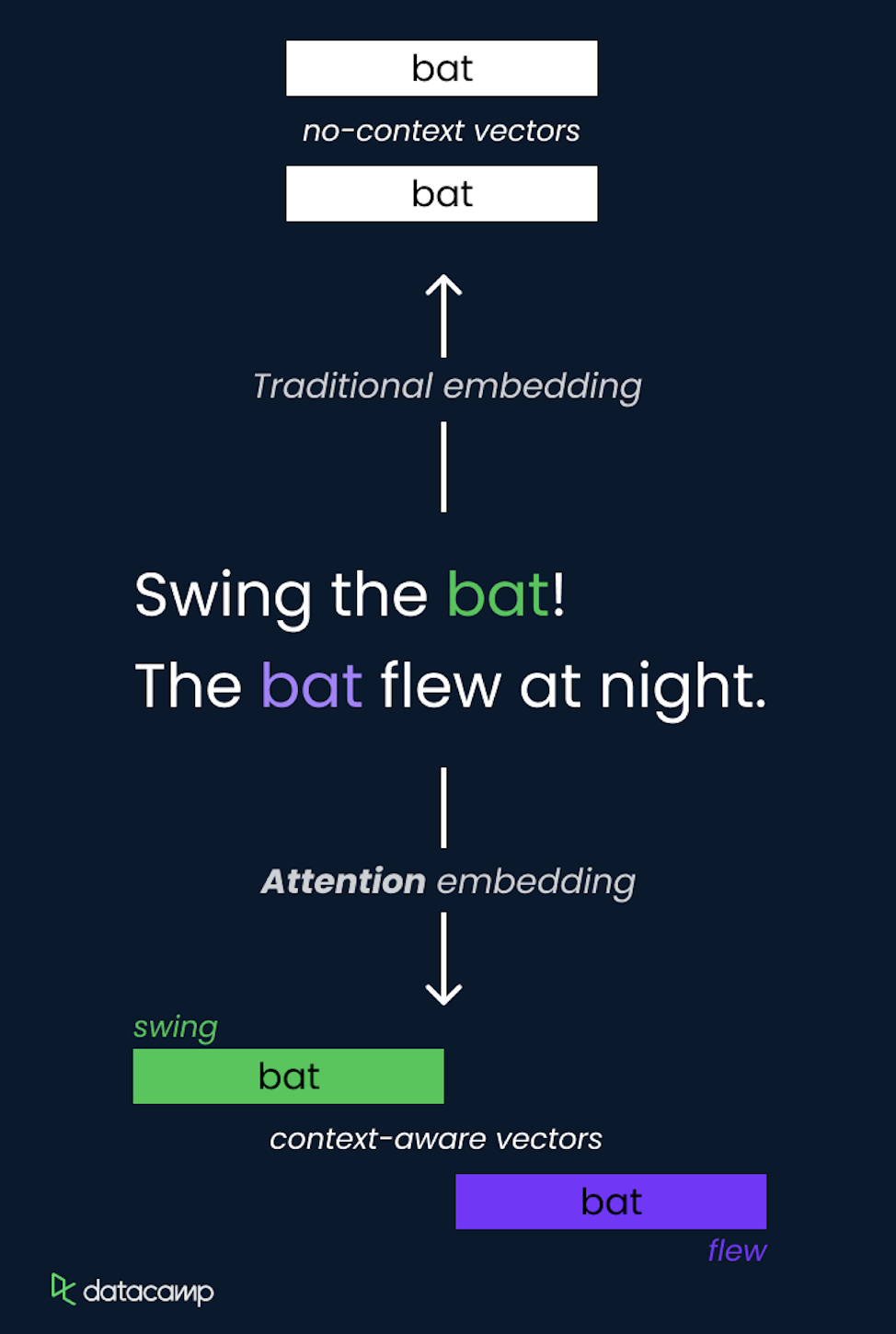
Mekanisme self-attention adalah komponen inti arsitektur Transformer, yang memungkinkannya memproses informasi secara efisien dan menangkap hubungan jarak jauh.
Tokenisasi mengubah teks mentah menjadi unit-unit yang lebih kecil yang disebut token, yang bisa berupa kata, sub-kata, atau karakter.
Peran tokenisasi dalam pemrosesan LLM sangat penting karena mengubah teks menjadi format yang dapat dipahami dan diproses oleh model.
Tokenisasi yang efektif memastikan model dapat menangani beragam masukan, termasuk kata langka dan berbagai bahasa, dengan memecahnya menjadi bagian yang mudah dikelola. Langkah ini diperlukan untuk pelatihan dan inferensi yang optimal, karena menstandarkan masukan dan membantu model mempelajari pola yang bermakna dalam data.
Peneliti dan praktisi telah mengembangkan banyak metrik evaluasi untuk menilai kinerja LLM. Metrik klasik meliputi:
Di luar metrik tradisional, praktisi kini menggunakan benchmark standar untuk berbagai tujuan, seperti MMLU (uji pengetahuan 57 tugas), MMMU-Pro (penalaran multimodal), dan HumanEval (generasi kode). Selain itu, leaderboard seperti LMArena memberi peringkat LLM berdasarkan preferensi manusia. Untuk sistem yang sudah diterapkan, mengukur tingkat halusinasi di dunia nyata, latensi, dan efisiensi token menjadi esensial.
Beberapa teknik dapat digunakan untuk mengendalikan keluaran LLM, termasuk:
Untuk mengurangi biaya komputasi LLM, kita dapat menerapkan:
Interpretabilitas model penting untuk memahami bagaimana LLM mengambil keputusan, yang krusial untuk membangun kepercayaan, memastikan akuntabilitas, serta mengidentifikasi dan mengurangi bias. Mencapai interpretabilitas dapat melibatkan berbagai pendekatan, seperti:
LLM menangani ketergantungan jangka panjang dalam teks melalui arsitekturnya, khususnya mekanisme self-attention, yang memungkinkan model mempertimbangkan semua token dalam urutan masukan secara bersamaan. Kemampuan untuk memberi perhatian pada token yang jauh membantu LLM menangkap hubungan dan ketergantungan dalam konteks panjang.
Selain itu, model lanjutan seperti Transformer-XL dan Longformer secara khusus dirancang untuk memperluas context window dan mengelola urutan yang lebih panjang secara lebih efektif, sehingga memastikan penanganan ketergantungan jangka panjang yang lebih baik.
Model produksi modern menggunakan strategi yang lebih maju untuk menangani ketergantungan jangka panjang dan melawan penurunan kinerja saat context window diperluas, seperti:
RAG menggabungkan mekanisme retrieval dengan model generatif untuk mengambil informasi relevan dari sumber eksternal selama proses generasi teks. Pendekatan ini secara langsung mengatasi dua keterbatasan kritis LLM: halusinasi dan kebaruan pengetahuan. RAG tradisional menggunakan pipeline retrieval dan generasi yang relatif sederhana, tetapi dalam evolusinya ke "RAG 2.0", pendekatan ini menjadi jauh lebih canggih.
Fitur utama RAG 2.0 meliputi:
RAG 2.0, jika dikombinasikan dengan LLM, secara efektif mengurangi tingkat halusinasi sebesar 40–60% dalam sistem produksi dibandingkan model dasar.
Memahami konsep lanjutan dalam LLM bermanfaat bagi profesional yang ingin mendorong batas kemampuan model ini. Bagian ini membahas topik kompleks dan tantangan umum di bidang ini.
Few-shot learning dalam LLM mengacu pada kemampuan model untuk mempelajari dan melakukan tugas baru hanya dengan beberapa contoh. Kemampuan ini memanfaatkan pengetahuan pra-pelatihan LLM yang luas, memungkinkannya melakukan generalisasi dari sejumlah kecil contoh.
Keunggulan utama few-shot learning mencakup kebutuhan data yang lebih sedikit karena kebutuhan akan dataset besar khusus tugas diminimalkan, fleksibilitas yang meningkat karena model dapat beradaptasi dengan berbagai tugas dengan fine-tuning minimal, serta efisiensi biaya, karena kebutuhan data lebih rendah dan waktu pelatihan berkurang yang berarti penghematan signifikan dalam pengumpulan data dan sumber daya komputasi.
Model bahasa autoregresif dan masked berbeda terutama pada pendekatan prediksi dan kesesuaian tugas. Model autoregresif, seperti GPT-5.2, Claude 4.5 Opus, dan Gemini 3, memprediksi kata berikutnya dalam urutan berdasarkan kata-kata sebelumnya, menghasilkan teks satu token demi satu.
Model ini sangat cocok untuk tugas generasi teks. Sebaliknya, masked language model, seperti BERT, secara acak menutupi kata-kata dalam kalimat dan melatih model untuk memprediksi kata yang ditutupi berdasarkan konteks sekitarnya. Pendekatan dua arah ini membantu model memahami konteks dari kedua arah, menjadikannya ideal untuk tugas klasifikasi teks dan tanya jawab.
Mengintegrasikan pengetahuan eksternal ke dalam LLM dapat dicapai melalui beberapa metode:
Menerapkan LLM di produksi melibatkan berbagai tantangan:
Degradasi model terjadi ketika kinerja LLM menurun seiring waktu akibat perubahan distribusi data yang mendasari. Menangani degradasi model melibatkan pelatihan ulang secara berkala dengan data terbaru untuk mempertahankan kinerja. Pemantauan berkelanjutan diperlukan untuk melacak kinerja model dan mendeteksi tanda-tanda degradasi.
Teknik pembelajaran inkremental memungkinkan model belajar dari data baru tanpa melupakan informasi yang telah dipelajari sebelumnya. Selain itu, pengujian A/B membandingkan kinerja model saat ini dengan versi baru dan membantu mengidentifikasi potensi perbaikan sebelum penerapan penuh.
Untuk memastikan penggunaan LLM yang etis, beberapa teknik dapat diterapkan:
Mengamankan data yang digunakan dengan LLM memerlukan penerapan berbagai langkah. Ini termasuk penggunaan teknik enkripsi untuk data saat disimpan dan saat ditransmisikan guna melindungi dari akses tidak sah. Kontrol akses yang ketat diperlukan agar hanya personel berwenang yang dapat mengakses data sensitif.
Meng-anonimkan data untuk menghapus informasi identitas pribadi (PII) sebelum digunakan untuk pelatihan atau inferensi juga penting. Selain itu, kepatuhan terhadap regulasi perlindungan data seperti GDPR atau CCPA sangat penting untuk menghindari masalah hukum.
Langkah-langkah ini membantu melindungi integritas, kerahasiaan, dan ketersediaan data. Perlindungan ini krusial untuk menjaga kepercayaan pengguna dan mematuhi standar regulasi.
RLHF adalah teknik yang melibatkan pelatihan LLM untuk menyelaraskan keluarannya dengan preferensi manusia dengan memasukkan umpan balik dari evaluator manusia. Proses iteratif ini membantu model belajar menghasilkan respons yang tidak hanya akurat tetapi juga aman, tidak bias, dan membantu.
Namun, RLHF memiliki tantangan. Salah satunya adalah potensi bias dalam umpan balik manusia, karena evaluator berbeda mungkin memiliki preferensi dan interpretasi yang bervariasi.
Tantangan lain adalah skalabilitas proses umpan balik, karena mengumpulkan dan memasukkan umpan balik manusia dalam jumlah besar dapat memakan waktu dan mahal. Selain itu, memastikan bahwa model reward yang digunakan dalam RLHF secara akurat menangkap perilaku dan nilai yang diinginkan bisa jadi rumit. Langkah optimisasi PPO (Proximal Policy Optimization) menambah kompleksitas dan dapat memperkenalkan ketidakstabilan selama pelatihan.
Alternatif modern telah muncul yang mengatasi banyak keterbatasan RLHF:
Sebagian besar model produksi menggunakan DPO, RLAIF, atau kombinasi hibrida alih-alih RLHF berbasis PPO murni.
Halusinasi berbasis pengetahuan terjadi saat model tidak memiliki fakta yang tepat (atau faktanya usang), sehingga ia menciptakan informasi yang terdengar masuk akal. Perbaikannya biasanya meliputi:
Halusinasi berbasis logika terjadi saat model memiliki informasi relevan namun bernalar secara keliru atau menghasilkan inkonsistensi. Perbaikan umum adalah:
Meskipun Transformer mendominasi LLM saat ini, state-space model (SSM) seperti Mamba muncul sebagai paradigma arsitektural kompetitif dengan sifat komputasi dan kinerja yang secara fundamental berbeda. Memahami keduanya semakin penting bagi profesional LLM modern.
Transformer:
State-Space Model (Mamba, Mamba-2):
Riset terbaru menunjukkan bahwa Transformer dan SSM saling melengkapi alih-alih bersaing langsung, dengan use case dan kendala berbeda yang memfavoritkan arsitektur yang berbeda. Transformer tetap menjadi pilihan praktis untuk LLM serbaguna dan kemungkinan akan tetap mendominasi untuk saat ini. Masa depan hibrida mungkin terjadi, dengan model khusus untuk kebutuhan komputasi dan tugas yang berbeda.
Prompt engineering adalah aspek penting dalam memanfaatkan LLM. Ini melibatkan perancangan prompt yang tepat dan efektif untuk menghasilkan respons yang diinginkan dari model. Bagian ini menelaah pertanyaan kunci yang mungkin ditemui prompt engineer.
Prompt engineering melibatkan perancangan dan penyempurnaan prompt untuk mengarahkan LLM menghasilkan keluaran yang akurat dan relevan. Hal ini penting saat bekerja dengan LLM karena kualitas prompt berdampak langsung pada kinerja model.
Prompt yang efektif dapat meningkatkan kemampuan model memahami tugas, menghasilkan respons yang akurat dan relevan, serta mengurangi kemungkinan kesalahan.
Prompt engineering sangat penting untuk memaksimalkan kegunaan LLM dalam berbagai aplikasi, mulai dari generasi teks hingga pemecahan masalah yang kompleks.
Mengevaluasi efektivitas prompt melibatkan:
Penyempurnaan prompt secara iteratif melibatkan:
Beberapa alat dan kerangka kerja dapat menyederhanakan proses prompt engineering:
Pertanyaan ini menyoroti isu etis dan praktis dari konten yang dihasilkan LLM. Jawaban yang kuat akan menunjukkan kesadaran atas masalah ini dan membahas teknik seperti berikut.
Teknik mitigasi halusinasi:
Teknik mitigasi bias:
Template prompt menyediakan format terstruktur untuk prompt, sering kali mencakup placeholder untuk informasi atau instruksi tertentu. Template dapat digunakan kembali di berbagai tugas dan skenario, meningkatkan konsistensi dan efisiensi dalam desain prompt.
Jawaban yang baik akan menjelaskan bagaimana template prompt dapat digunakan untuk mengenkapsulasi praktik terbaik, memasukkan pengetahuan spesifik domain, dan menyederhanakan proses pembuatan prompt yang efektif untuk berbagai aplikasi.
Tokenizer memainkan peran krusial dalam bagaimana LLM menafsirkan dan memproses prompt masukan. Tokenizer berbeda memiliki ukuran kosakata yang bervariasi dan menangani kata di luar kosakata (OOV) secara berbeda. Tokenizer sub-kata seperti Byte Pair Encoding (BPE) dapat menangani kata OOV dengan memecahnya menjadi unit sub-kata yang lebih kecil, sementara tokenizer berbasis kata mungkin memperlakukannya sebagai token tidak dikenal.
Pilihan tokenizer dapat memengaruhi kinerja model dalam beberapa cara. Misalnya, tokenizer sub-kata mungkin lebih efektif menangkap makna istilah langka atau teknis, sementara tokenizer berbasis kata mungkin lebih sederhana dan cepat untuk tugas bahasa umum.
Dalam prompt engineering, pilihan tokenizer dapat memengaruhi bagaimana Anda menyusun prompt. Misalnya, jika menggunakan tokenizer sub-kata, Anda mungkin perlu lebih memperhatikan cara kata dipecah menjadi sub-kata untuk memastikan model menangkap makna yang dimaksud.
Agentic prompting adalah pendekatan desain prompt di mana model diinstruksikan untuk bertindak seperti “agen” yang dapat merencanakan, mengambil tindakan (misalnya memanggil alat/API atau mengambil dokumen), mengamati hasilnya, dan mengulang hingga menyelesaikan tujuan.
Tidak seperti prompt engineering tradisional, yang terutama berupaya mendapatkan respons terbaik dalam satu kali percobaan melalui instruksi jelas, contoh, dan batasan format, agentic prompting menekankan loop kontrol multi-langkah (rencana → bertindak → observasi → perbaikan).
Pendekatan ini sangat berguna untuk tugas yang ketepatannya bergantung pada interaksi dengan sistem eksternal (basis data, pencarian, eksekusi kode) atau verifikasi hasil antara, alih-alih hanya mengandalkan pengetahuan internal model.
Prompt agen yang baik biasanya mendefinisikan tujuan, alat/tindakan yang tersedia, cara memutuskan tindakan yang diambil, dan kapan harus berhenti. Umumnya juga ditambahkan langkah verifikasi eksplisit (misalnya “periksa sumber yang diambil” atau “hitung ulang sebelum jawaban akhir”) untuk mengurangi halusinasi dan meningkatkan keandalan.
Pelajari lebih lanjut tentang LLM!
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
