
Lernpfad
Grundlagen der KI
10 Std.
Große Sprachmodelle (LLMs) werden in der künstlichen Intelligenz immer wichtiger und finden in vielen Branchen Anwendung.
Da immer mehr Leute mit LLM-Kenntnissen gesucht werden, gibt's in diesem Artikel eine ganze Reihe von Interviewfragen und Antworten, die grundlegende Konzepte, fortgeschrittene Techniken und praktische Anwendungen abdecken.
Wenn du dich auf ein Vorstellungsgespräch vorbereitest oder einfach nur dein Wissen erweitern möchtest, ist dieser Artikel genau das Richtige für dich.
Um LLMs zu verstehen, sollte man mit den grundlegenden Konzepten anfangen. Diese grundlegenden Fragen decken wichtige Sachen wie Architektur, Schlüsselmechanismen und typische Herausforderungen ab und bieten eine solide Basis, um fortgeschrittenere Themen zu lernen.
Die Transformer-Architektur ist ein Deep-Learning-Modell, das von 20172017 vorgestellt wurde. Es ist dafür gedacht, sequenzielle Daten effizienter und besser zu verarbeiten als frühere Modelle wie rekurrenten neuronalen Netzen (RNNs) und Long Short-Term Memory (LSTMs).
Es setzt auf Selbstaufmerksamkeitsmechanismen , um Eingabedaten parallel zu verarbeiten, was es super skalierbar macht und es ihm ermöglicht, weitreichende Abhängigkeiten zu erfassen.
Bei LLMs ist die Transformer-Architektur das Herzstück. Sie sorgt dafür, dass die Modelle große Mengen an Textdaten effizient verarbeiten und kontextbezogene, zusammenhängende Text-Outputs erstellen können.
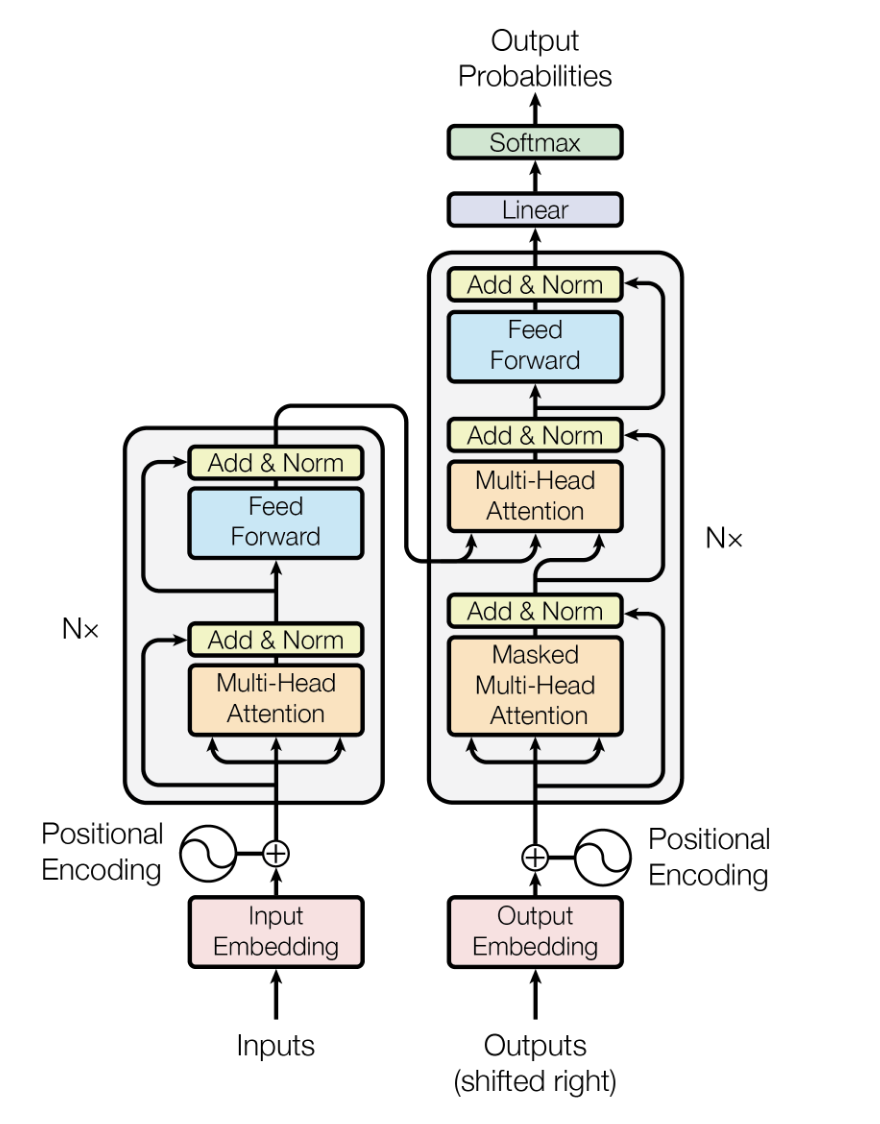
Die Architektur des Transformer-Modells. Quelle
Das Kontextfenster in LLMs ist der Textbereich (in Form von Tokens oder Wörtern), den das Modell auf einmal berücksichtigen kann, wenn es Sprache generiert oder versteht. Das Kontextfenster ist wichtig, weil es beeinflusst, wie gut das Modell logische und passende Antworten machen kann.
Im Allgemeinen kann das Modell mit einem größeren Kontextfenster mehr Kontext berücksichtigen, was zu einem besseren Verständnis und einer besseren Textgenerierung führt, vor allem bei komplizierten oder langen Gesprächen. Allerdings braucht man dafür auch mehr Rechenleistung, sodass man einen Mittelweg zwischen Leistung und Effizienz finden muss.
Außerdem zeigen aktuelle Studien, dass die meisten Modelle von m-Ost schon weit vor ihren angegebenen Grenzen an Leistung verlieren. Modelle können ein „Lost in the Middle“-Phänomen zeigen, bei dem Infos im Kontextzentrum einfach ignoriert oder als weniger wichtig angesehen werden. Deshalb ist einkuratierter, relevanter Inhalt in kleineren Fenstern oft besser als große Fenster, die mit Lärm vollgestopft sind.
Zu den üblichen Vorbereitungszielen für LLMs gehören masked language modeling (MLM) und autoregressive language modeling. Bei MLM werden zufällige Wörter in einem Satz verdeckt, und das Modell lernt, die verdeckten Wörter anhand des umgebenden Kontexts vorherzusagen. Das hilft dem Modell, den bidirektionalen Kontext zu verstehen.
Beim autoregressiven Sprachmodell geht's darum, das nächste Wort in einer Sequenz vorherzusagen und das Modell so zu trainieren, dass es Text Zeichen für Zeichen generiert. Beide Ziele helfen dem Modell, Sprachmuster und Semantik aus großen Textkorpora zu lernen, und bieten so eine solide Basis für die Feinabstimmung bestimmter Aufgaben.
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Feinabstimmung im Zusammenhang mit LLMs bedeutet, dass man ein vortrainiertes Modell nimmt und es mit einem kleineren, auf bestimmte Aufgaben zugeschnittenen Datensatz weiter trainiert. Dieser Prozess hilft dem Modell, sein allgemeines Sprachverständnis an die Feinheiten der jeweiligen Anwendung anzupassen und so die Leistung zu verbessern.
Das ist echt wichtig, weil es die Sprachkenntnisse nutzt, die man schon vorher gelernt hat, und gleichzeitig das Modell so anpasst, dass es bei bestimmten Sachen wie Stimmungsanalyse, Textzusammenfassung oder Fragen beantworten gut funktioniert.
Der Einsatz von LLMs bringt ein paar Herausforderungen mit sich, darunter:
LLMs gehen mit Wörtern oder Tokens, die nicht im Vokabular sind (OOV), um, indem sie Techniken wie die Subword-Tokenisierung nutzen (z. B. Byte Pair Encoding oder BPE und WordPiece). Diese Techniken zerlegen unbekannte Wörter in kleinere, bekannte Unterwörtereinheiten, die das Modell verarbeiten kann.
Dieser Ansatz sorgt dafür, dass das Modell auch dann, wenn ein Wort während des Trainings nicht vorkommt, den Text anhand seiner Bestandteile verstehen und generieren kann, was die Flexibilität und Robustheit verbessert.
Einbettungsschichten sind ein wichtiger Teil von LLMs, die dazu dienen, kategoriale Daten wie Wörter in dichte Vektordarstellungen umzuwandeln. Diese Einbettungen fangen die semantischen Beziehungen zwischen Wörtern ein, indem sie sie in einem kontinuierlichen Vektorraum darstellen, in dem ähnliche Wörter näher beieinander liegen. Die Bedeutung der Einbettung von Schichten in LLMs umfasst:
Positionskodierungen sagen Transformatoren, wo sich jedes Token in der Sequenz befindet.
Traditionelle sinusförmige Positionskodierungen (von Vaswani et al. 2017) haben feste mathematische Funktionen benutzt, um Positionen statisch zu kodieren. Rotary Position Embeddings (RoPE), die erst kürzlich eingeführt wurden, sind mittlerweile der Standard in modernen LLMs, weil sie einfach bessere Eigenschaften haben.
RoPE funktioniert so, dass es Positionen als Drehwinkel in einem komplexen Vektorraum darstellt und Token-Einbettungen um einen Winkel dreht, der proportional zu ihrer Position ist. Dieser geometrische Ansatz ist effizienter und unterstützt ganz natürlich die Interpolation zu längeren Sequenzen als denen, die während des Trainings gesehen wurden. Das ist eine wichtige Funktion für die Erweiterung von Kontextfenstern. Modelle wie GPT-5.2 und Gemini 3 nutzen RoPE als ihre Positionskodierung.
Auf der Basis von Grundkonzepten beschäftigen sich die Fragen für Fortgeschrittene mit den praktischen Techniken, die man benutzt, um die Leistung von LLM zu verbessern und Probleme im Zusammenhang mit der Recheneffizienz und der Interpretierbarkeit von Modellen anzugehen.
Das Konzept der Aufmerksamkeit in LLMs ist eine Methode, mit der sich das Modell bei der Erstellung von Vorhersagen auf verschiedene Teile der Eingabesequenz konzentrieren kann. Es gibt anderen Tokens in der Eingabe dynamisch Gewichte und hebt die relevantesten für die aktuelle Aufgabe hervor.
Das wird mit Selbstaufmerksamkeit gemacht, wo das Modell für jedes Token Aufmerksamswerte im Verhältnis zu allen anderen Tokens in der Sequenz berechnet, sodass es Abhängigkeiten unabhängig von ihrer Entfernung erfassen kann.
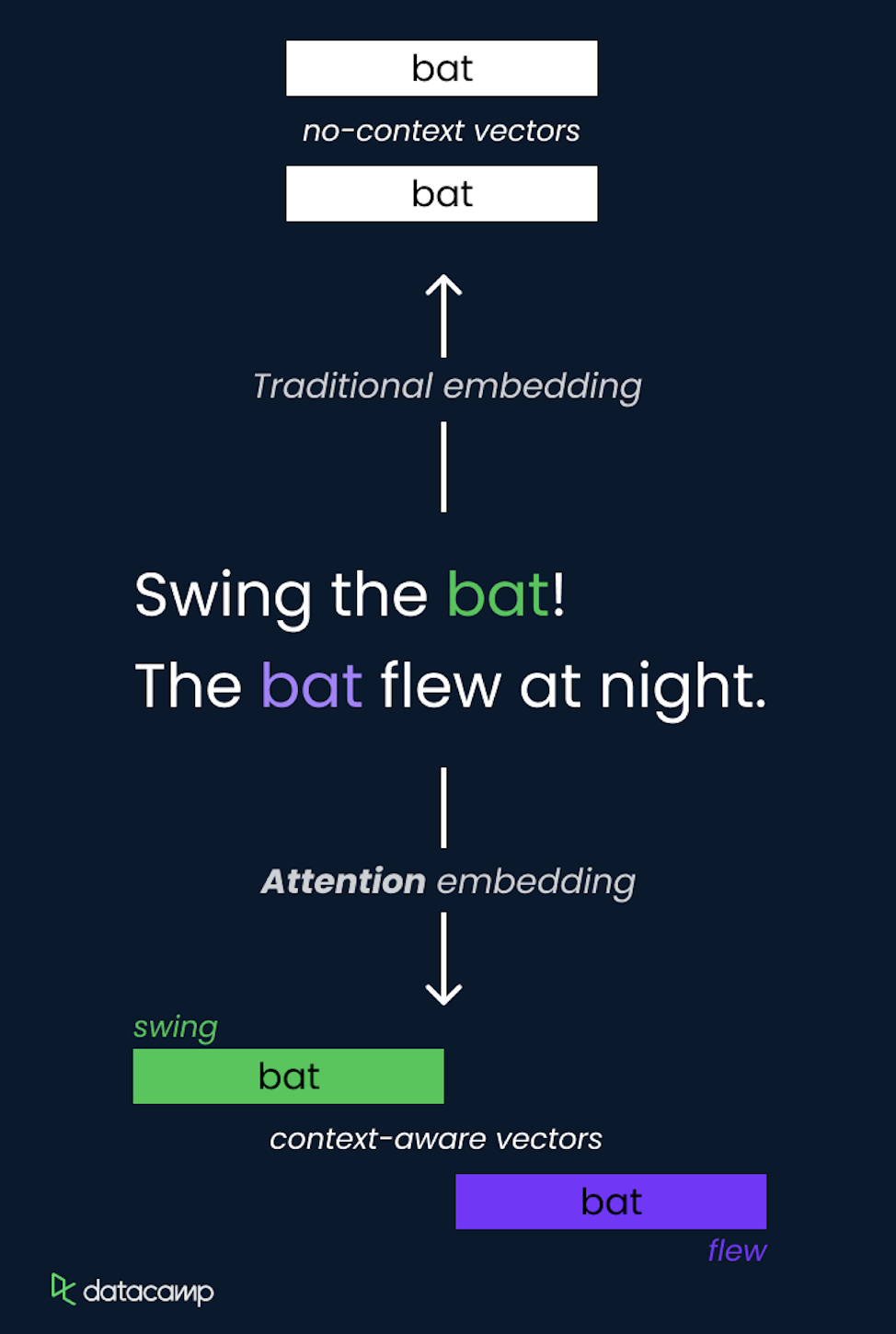
Der Selbstaufmerksamkeitsmechanismus ist ein wichtiger Teil der Transformer-Architektur, der es ihr ermöglicht, Infos effizient zu verarbeiten und weitreichende Beziehungen zu erfassen.
Tokenisierung Das heißt, man zerlegt einen Text in kleinere Teile, die man „Token” nennt. Das können Wörter, Teile von Wörtern oder einfach Zeichen sein.
Die Tokenisierung ist super wichtig bei der Verarbeitung von LLM, weil sie Text in ein Format umwandelt, das das Modell verstehen und verarbeiten kann.
Effektive Tokenisierung sorgt dafür, dass das Modell mit einer Vielzahl von Eingaben klarkommt, auch mit seltenen Wörtern und verschiedenen Sprachen, indem es sie in überschaubare Teile zerlegt. Dieser Schritt ist wichtig für ein optimales Training und eine optimale Inferenz, weil er die Eingaben standardisiert und dem Modell hilft, sinnvolle Muster in den Daten zu lernen.
Forscher und Praktiker haben viele Bewertungsmetriken entwickelt, um die Leistung eines LLM zu messen. Zu den klassischen Kennzahlen gehören:
Über die üblichen Messgrößen hinaus nutzen Fachleute jetzt standardisierte Benchmarks für verschiedene Zwecke, wie zum Beispiel MMLU (57-Aufgaben-Wissenstest), MMMU-Pro (multimodales Denken) und HumanEval (Code-Generierung). Außerdem bewerten Ranglisten wie LMArena LLMs nach menschlicher Präferenz. Bei eingesetzten Systemen ist es jetzt echt wichtig, die tatsächlichen Halluzinationsraten, Latenzzeiten und die Token-Effizienz zu messen.
Es gibt ein paar Techniken, mit denen man die Ausgabe eines LLM steuern kann, zum Beispiel:
Um die Rechenkosten von LLMs zu senken, können wir Folgendes nutzen:
Die Interpretierbarkeit von Modellen ist wichtig, um zu verstehen, wie ein LLM Entscheidungen trifft. Das ist wichtig, um Vertrauen aufzubauen, Verantwortlichkeit sicherzustellen und Verzerrungen zu erkennen und zu verringern. Um Interpretierbarkeit zu erreichen, kann man verschiedene Wege gehen, zum Beispiel:
LLMs können mit langfristigen Abhängigkeiten im Text umgehen, weil sie so aufgebaut sind, vor allem wegen dem Selbstaufmerksamkeitsmechanismus, der es ihnen ermöglicht, alle Token in der Eingabesequenz gleichzeitig zu berücksichtigen. Diese Fähigkeit, auf entfernte Token zu achten, hilft LLMs dabei, Beziehungen und Abhängigkeiten über lange Kontexte hinweg zu erfassen.
Außerdem sind fortgeschrittene Modelle wie Transformer-XL und Longformer extra dafür gemacht, das Kontextfenster zu erweitern und längere Sequenzen besser zu verwalten, damit langfristige Abhängigkeiten besser geklärt werden können.
Moderne Produktionsmodelle nutzen ausgeklügeltere Strategien, um mit langfristigen Abhängigkeiten umzugehen und Leistungseinbußen durch erweiterte Kontextfenster auszugleichen, wie zum Beispiel:
RAG mischt Suchmechanismen mit generativen Modellen, um während der Textgenerierung relevante Infos aus externen Quellen zu holen. Dieser Ansatz geht direkt auf zwei wichtige Einschränkungen von LLM ein: Halluzinationen und Aktualität des Wissens. Das klassische RAG nutzt ziemlich einfache Abruf- und Generierungspipelines, aber mit der Weiterentwicklung zu „RAG 2.0” ist es deutlich komplexer geworden.
Die wichtigsten Features von RAG 2.0 sind:
RAG 2.0 zusammen mit LLMs senkt die Halluzinationsrate in Produktionssystemen im Vergleich zu Basismodellen um 40 bis 60 %.
Das Verständnis fortgeschrittener Konzepte in LLMs ist nützlich für Fachleute, die die Grenzen dessen, was diese Modelle leisten können, erweitern wollen. Hier geht's um schwierige Themen und typische Probleme, die in diesem Bereich auftauchen.
Few-Shot-Lernen in LLMs bedeutet, dass das Modell neue Aufgaben mit nur wenigen Beispielen lernen und ausführen kann. Diese Funktion nutzt das umfangreiche, vorab trainierte Wissen des LLM und lässt es aus wenigen Beispielen Schlussfolgerungen ziehen.
Die Hauptvorteile des Few-Shot-Lernens sind weniger Daten, weil man keine riesigen aufgabenbezogenen Datensätze braucht, mehr Flexibilität, weil sich das Modell mit wenig Feintuning an verschiedene Aufgaben anpassen kann, und Kosteneffizienz, weil man mit weniger Daten und kürzeren Trainingszeiten bei der Datenerfassung und den Rechenressourcen viel Geld sparen kann.
Autoregressive und maskierte Sprachmodelle unterscheiden sich hauptsächlich in ihrem Vorhersageansatz und ihrer Eignung für bestimmte Aufgaben. Autoregressive Modelle wie GPT-5.2, Claude 4.5 Opus und Gemini 3 sagen das nächste Wort in einer Sequenz voraus, basierend auf den vorherigen Wörtern, und machen so einen Text Token für Token.
Diese Modelle sind besonders gut für Aufgaben zur Textgenerierung geeignet. Im Gegensatz dazu gibt's maskierte Sprachmodelle wie BERT, maskieren Wörter in einem Satz nach dem Zufallsprinzip und trainieren das Modell, diese maskierten Wörter anhand des umgebenden Kontexts vorherzusagen. Dieser bidirektionale Ansatz hilft dem Modell, den Kontext aus beiden Richtungen zu verstehen, was es super für Textklassifizierungs- und Frage-Antwort-Aufgaben macht.
Externes Wissen in einen LLM einbauen kann man auf verschiedene Arten:
Der Einsatz von LLMs in der Produktion bringt verschiedene Herausforderungen mit sich:
Modellverschlechterung passiert, wenn die Leistung eines LLM mit der Zeit nachlässt, weil sich die zugrunde liegende Datenverteilung ändert. Um die Verschlechterung des Modells zu vermeiden, muss man es regelmäßig mit neuen Daten trainieren, damit es gut läuft. Man muss das Modell ständig im Auge behalten, um zu sehen, wie es läuft und ob es Anzeichen für Probleme gibt.
Mit inkrementellen Lerntechniken kann das Modell aus neuen Daten lernen, ohne vorher gelernte Infos zu vergessen. Außerdem vergleicht das A/B-Testing die Leistung des aktuellen Modells mit neuen Versionen und hilft dabei, mögliche Verbesserungen vor der vollständigen Einführung zu erkennen.
Um den ethische Nutzung von LLMskönnen verschiedene Techniken eingesetzt werden:
Um die mit LLMs verwendeten Daten zu schützen, muss man verschiedene Maßnahmen umsetzen. Dazu gehört, dass man Verschlüsselungstechniken für gespeicherte und übertragene Daten nutzt, um sie vor unbefugtem Zugriff zu schützen. Es braucht strenge Zugriffskontrollen, damit nur Leute, die das dürfen, an sensible Daten rankommen.
Es ist auch super wichtig, Daten zu anonymisieren, um persönliche Infos (PII) zu entfernen, bevor man sie für Training oder Schlussfolgerungen nutzt. Außerdem ist es wichtig, Datenschutzbestimmungen wie die DSGVO oder den CCPA einzuhalten, um rechtliche Probleme zu vermeiden.
Diese Maßnahmen helfen dabei, die Datenintegrität, Vertraulichkeit und Verfügbarkeit zu schützen. Dieser Schutz ist super wichtig, um das Vertrauen der Nutzer zu behalten und die gesetzlichen Standards einzuhalten.
RLHF ( ) ist eine Technik, bei der ein LLM trainiert wird, seine Ergebnisse an menschlichen Präferenzen auszurichten, indem Feedback von menschlichen Bewertern einfließt. Dieser wiederholte Prozess hilft dem Modell dabei, Antworten zu lernen, die nicht nur genau, sondern auch sicher, unvoreingenommen und hilfreich sind.
Allerdings bringt RLHF auch Herausforderungen mit sich. Eine Herausforderung ist, dass menschliches Feedback voreingenommen sein kann, weil verschiedene Bewerter unterschiedliche Vorlieben und Interpretationen haben können.
Eine weitere Herausforderung ist die Skalierbarkeit des Feedback-Prozesses, da das Sammeln und Einarbeiten großer Mengen an menschlichem Feedback zeitaufwändig und teuer sein kann. Außerdem kann es schwierig sein, sicherzustellen, dass das in RLHF verwendete Belohnungsmodell die gewünschten Verhaltensweisen und Werte genau erfasst. Der Optimierungsschritt PPO (Proximal Policy Optimization) macht die Sache komplizierter und kann während des Trainings zu Instabilität führen.
Es gibt jetzt moderne Alternativen, die viele der Einschränkungen von RLHF lösen:
Die meisten Serienmodelle nutzen DPO, RLAIF oder hybride Kombinationen statt reinem PPO-basiertem RLHF.
Wissensbasierte Halluzinationen treten auf, wenn das Modell nicht die richtigen Fakten hat (oder veraltete Fakten hat), sodass es sich plausible Informationen ausdenkt. Korrekturen umfassen normalerweise:
Logikbasierte Halluzinationen treten auf, wenn das Modell zwar über relevante Infos verfügt, aber falsch argumentiert oder Unstimmigkeiten erzeugt. Häufige Lösungen sind:
Während Transformers heute die LLMs dominieren, haben sich Zustandsraummodelle (SSMs) wie Mamba als konkurrenzfähiges Architekturparadigma mit ganz anderen Rechen- und Leistungseigenschaften durchgesetzt. Für moderne LLM-Profis wird es immer wichtiger, beides zu verstehen.
Transformatoren:
Zustandsraummodelle (Mamba, Mamba-2):
Neueste Studien zeigen, dass Transformers und SSMs sich eher ergänzen als direkt miteinander konkurrieren, da unterschiedliche Anwendungsfälle und Einschränkungen verschiedene Architekturen begünstigen. Transformatoren sind immer noch die beste Wahl für allgemeine LLMs und werden wahrscheinlich vorerst weiter dominieren. Eine hybride Zukunft ist wahrscheinlich, mit speziellen Modellen für unterschiedliche Rechen- und Aufgabenanforderungen.
Prompt Engineering ist ein wichtiger Teil bei der Nutzung von LLMs. Es geht darum, genaue und effektive Eingabeaufforderungen zu erstellen, um die gewünschten Antworten vom Modell zu bekommen. Hier geht's um wichtige Fragen, die Ingenieure vielleicht haben.
Prompt Engineering bedeutet, Prompts zu entwerfen und zu verfeinern, um LLMs dabei zu helfen, genaue und relevante Ergebnisse zu liefern. Das ist super wichtig für die Arbeit mit LLMs, weil die Qualität der Eingabe direkt die Leistung des Modells beeinflusst.
Effektive Eingabeaufforderungen können das Modell dabei unterstützen, die Aufgabe besser zu verstehen, genaue und relevante Antworten zu generieren und die Fehlerwahrscheinlichkeit zu verringern.
Prompt Engineering ist super wichtig, um den Nutzen von LLMs in verschiedenen Anwendungen zu maximieren, von der Textgenerierung bis hin zu komplexen Problemlösungsaufgaben.
Die Wirksamkeit einer Aufforderung zu checken, bedeutet:
Die iterative Verfeinerung von Eingabeaufforderungen umfasst:
Es gibt ein paar Tools und Frameworks, die den Prozess des Prompt Engineerings vereinfachen können:
Diese Frage geht um die ethischen und praktischen Probleme von Inhalten, die von LLM erzeugt werden. Eine gute Antwort würde zeigen, dass du dir dieser Probleme bewusst bist, und Techniken wie die folgenden ansprechen.
Techniken zur Linderung von Halluzinationen:
Techniken zur Verringerung von Verzerrungen:
Prompt-Vorlagen bieten ein strukturiertes Format für Eingabeaufforderungen und haben oft Platzhalter für bestimmte Infos oder Anweisungen. Sie können für verschiedene Aufgaben und Situationen wiederverwendet werden, was die Konsistenz und Effizienz beim Entwerfen von Eingabeaufforderungen verbessert.
Eine gute Antwort würde erklären, wie man mit Prompt-Vorlagen bewährte Verfahren zusammenfassen, fachspezifisches Wissen einbauen und den Prozess der Erstellung effektiver Prompts für verschiedene Anwendungen optimieren kann.
Der Tokenizer ist echt wichtig dafür, wie das LLM die Eingabe interpretiert und verarbeitet. Verschiedene Tokenizer haben unterschiedliche Vokabulargrößen und gehen anders mit Wörtern um, die nicht im Vokabular sind (OOV-Wörter). Ein Subword-Tokenizer wie Byte Pair Encoding (BPE) kann OOV-Wörter verarbeiten, indem er sie in kleinere Subword-Einheiten aufteilt, während ein wortbasierter Tokenizer sie vielleicht als unbekannte Tokens behandelt.
Die Wahl des Tokenizers kann die Leistung des Modells auf verschiedene Arten beeinflussen. Zum Beispiel kann ein Subword-Tokenizer besser sein, um die Bedeutung von seltenen oder technischen Begriffen zu erfassen, während ein wortbasierter Tokenizer für allgemeine Sprachaufgaben einfacher und schneller sein kann.
Bei der Prompt-Entwicklung kann die Wahl des Tokenizers beeinflussen, wie du deine Prompts aufbaust. Wenn du zum Beispiel einen Subword-Tokenizer benutzt, solltest du vielleicht genauer drauf achten, wie Wörter in Subwords aufgeteilt werden, damit das Modell die beabsichtigte Bedeutung richtig erfasst.
Agentisches Prompting ist ein Ansatz zum Entwerfen von Prompts, bei dem das Modell so programmiert wird, dass es wie ein „Agent” agiert, der planen, Maßnahmen ergreifen (z. B. Tools/APIs aufrufen oder Dokumente abrufen), die Ergebnisse beobachten und so lange wiederholen kann, bis ein Ziel erreicht ist.
Im Gegensatz zum traditionellen Prompt Engineering, bei dem man vor allem versucht, mit klaren Anweisungen, Beispielen und Formatierungsvorgaben auf Anhieb die bestmögliche Antwort zu kriegen, setzt das agentenbasierte Prompting auf einen mehrstufigen Regelkreis (Planen → Ausführen → Beobachten → Verfeinern).
Das ist besonders nützlich für Aufgaben, bei denen es darauf ankommt, mit externen Systemen (Datenbanken, Suche, Codeausführung) zu interagieren oder Zwischenergebnisse zu überprüfen, anstatt sich nur auf das interne Wissen des Modells zu verlassen.
Gute Handlungsaufforderungen sagen normalerweise, was das Ziel ist, welche Tools/Aktionen man nutzen kann, wie man entscheidet, was man macht, und wann man aufhören sollte. Es ist auch üblich, explizite Verifizierungsschritte hinzuzufügen (z. B. „abgerufene Quellen überprüfen“ oder „vor der endgültigen Antwort neu berechnen“), um Halluzinationen zu reduzieren und die Zuverlässigkeit zu verbessern.
Erfahre mehr über LLMs!
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Blog
Matt Crabtree
14 Min.
Tutorial
Mark Pedigo