
Cursus
Principes fondamentaux de l'IA
10 h
Les grands modèles linguistiques (LLM) ont pris une importance croissante dans le domaine de l'intelligence artificielle, avec des applications dans divers secteurs.
Alors que la demande en professionnels possédant une expertise en LLM augmente, cet article fournit un ensemble complet de questions et réponses d'entretien, couvrant les concepts fondamentaux, les techniques avancées et les applications pratiques.
Si vous vous préparez à un entretien d'embauche ou si vous souhaitez simplement élargir vos connaissances, cet article vous sera utile.
Pour appréhender les LLM, il est essentiel de commencer par les concepts fondamentaux. Ces questions fondamentales couvrent des aspects essentiels tels que l'architecture, les mécanismes clés et les défis typiques, fournissant ainsi une base solide pour l'apprentissage de sujets plus avancés.
L' architecture Transformer est un modèle d'apprentissage profond présenté par Vaswani et alen 2017. Elle est conçue pour traiter des données séquentielles avec une efficacité et des performances améliorées par rapport aux modèles précédents, tels que les réseaux neuronaux récurrents (RNN) et les réseaux neuronaux à mémoire à court terme (LSTM).
Il repose sur des mécanismes d'auto-attention pour traiter les données d'entrée en parallèle, ce qui le rend hautement évolutif et capable de capturer des dépendances à longue portée.
Dans les LLM, l'architecture Transformer constitue la colonne vertébrale, permettant aux modèles de traiter efficacement de grandes quantités de données textuelles et de générer des sorties textuelles cohérentes et pertinentes sur le plan contextuel.
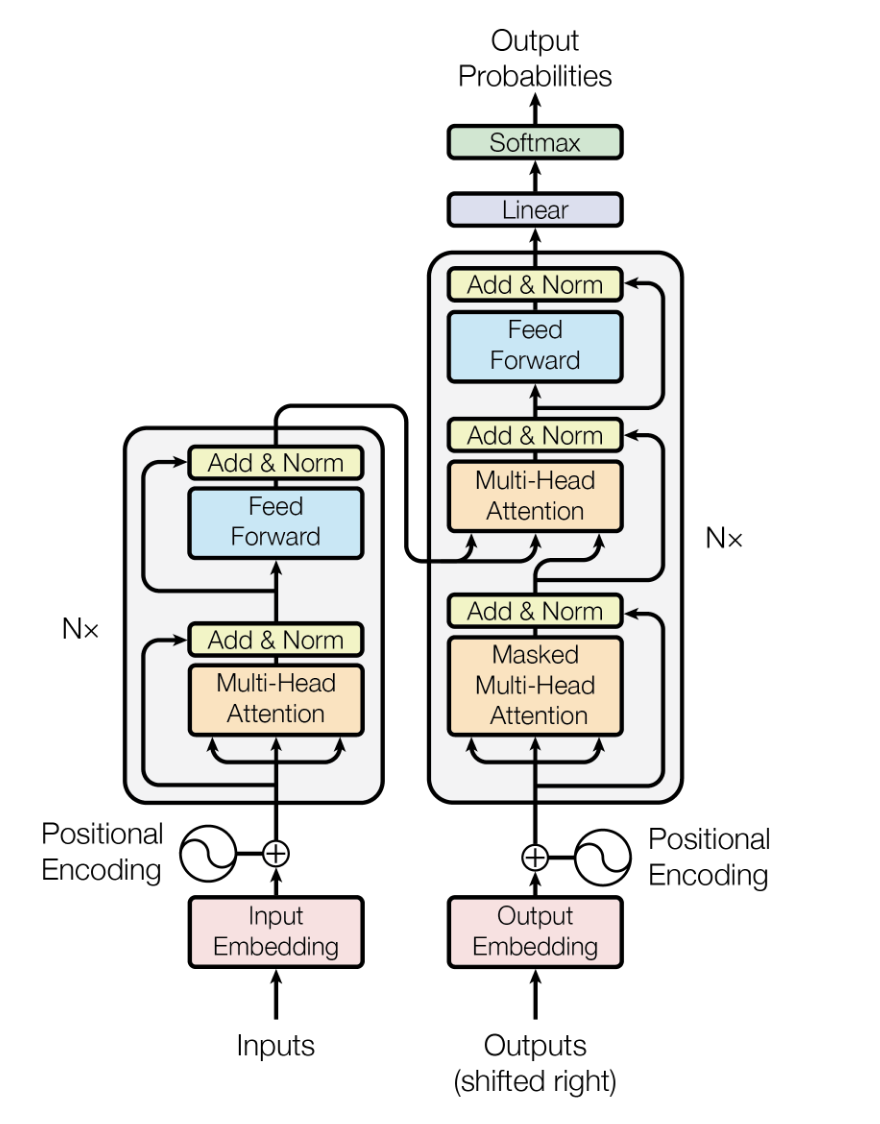
L'architecture du modèle Transformer. Source
La fenêtre contextuelle dans les LLM fait référence à la plage de texte (en termes de tokens ou de mots) que le modèle peut prendre en compte simultanément lors de la génération ou de la compréhension du langage. L'importance de la fenêtre contextuelle réside dans son impact sur la capacité du modèle à générer des réponses logiques et pertinentes.
En règle générale, une fenêtre contextuelle plus large permet au modèle de prendre en compte davantage de contexte, ce qui améliore la compréhension et la génération de texte, en particulier dans les conversations complexes ou longues. Cependant, cela augmente également les exigences en matière de calcul, ce qui nécessite de trouver un équilibre entre performance et efficacité.
De plus, des recherches récentes indiquent que les modèles de most présentent une dégradation de leurs performances bien avant d'atteindre les limites annoncées. Les modèles peuvent présenter un phénomène de « perte au milieu » où les informations situées au centre du contexte sont ignorées ou reléguées au second plan. Par conséquent, uncontexte pertinent et soigneusement sélectionné dans des fenêtres plus petites est souvent plus efficace que de remplir de bruit des fenêtres plus grandes.
Les objectifs courants avant formation pour les LLM comprennent la modélisation linguistique masquée (MLM) et la modélisation linguistique autorégressive. Dans le MLM, des mots aléatoires dans une phrase sont masqués, et le modèle est entraîné à prédire les mots masqués en fonction du contexte environnant. Cela permet au modèle de mieux appréhender le contexte bidirectionnel.
La modélisation autorégressive du langage consiste à prédire le mot suivant dans une séquence et à entraîner le modèle à générer du texte un token à la fois. Ces deux objectifs permettent au modèle d'apprendre les schémas linguistiques et la sémantique à partir de vastes corpus, fournissant ainsi une base solide pour affiner des tâches spécifiques.
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Le réglage fin dans le contexte des LLM consiste à prendre un modèle pré-entraîné et à le perfectionner à l'aide d'un ensemble de données plus restreint et spécifique à une tâche. Ce processus aide le modèle à adapter sa compréhension générale du langage aux nuances de l'application spécifique, améliorant ainsi ses performances.
Il s'agit d'une technique importante, car elle exploite les connaissances linguistiques générales acquises lors de la pré-formation tout en modifiant le modèle afin qu'il fonctionne efficacement dans des applications spécifiques, telles que l'analyse des sentiments, la synthèse de texte ou les questions-réponses.
L'utilisation des LLM présente plusieurs défis, notamment :
Les LLM traitent les mots ou les tokens hors vocabulaire (OOV) à l'aide de techniques telles que la tokenisation des sous-mots (par exemple, le codage par paires d'octets ou BPE, et WordPiece). Ces techniques décomposent les mots inconnus en unités plus petites et connues, que le modèle peut traiter.
Cette approche garantit que même si un mot n'apparaît pas pendant l'entraînement, le modèle peut tout de même comprendre et générer du texte à partir de ses éléments constitutifs, ce qui améliore sa flexibilité et sa robustesse.
Les couches d'intégration constituent un élément important des modèles d'apprentissage profond (LLM) utilisés pour convertir des données catégorielles, telles que des mots, en représentations vectorielles denses. Ces intégrations capturent les relations sémantiques entre les mots en les représentant dans un espace vectoriel continu où les mots similaires présentent une plus grande proximité. L'importance de l'intégration des couches dans les LLM comprend :
Les encodages positionnels indiquent aux transformateurs où chaque token se trouve dans la séquence.
Codages de position sinusoïdaux traditionnels (d'après Vaswani et al. 2017) ont utilisé des fonctions mathématiques fixes pour coder les positions de manière statique. Les intégrations de position rotative (RoPE), introduites plus récemment, sont devenues la norme dans les LLM modernes car elles offrent des propriétés fondamentalement supérieures.
RoPE fonctionne en représentant les positions sous forme d'angles de rotation dans un espace vectoriel complexe, en faisant pivoter les intégrations de jetons selon un angle proportionnel à leur position. Cette approche géométrique est plus efficace et prend naturellement en charge l'interpolation vers des séquences plus longues que celles observées pendant l'entraînement, ce qui est une capacité essentielle pour étendre les fenêtres contextuelles. Des modèles tels que GPT-5.2 et Gemini 3 utilisent RoPE comme codage positionnel.
S'appuyant sur des concepts fondamentaux, les questions de niveau intermédiaire explorent les techniques pratiques utilisées pour optimiser les performances des modèles LLM et relever les défis liés à l'efficacité computationnelle et à l'interprétabilité des modèles.
Le concept d'attention dans les LLM est une méthode qui permet au modèle de se concentrer sur différentes parties de la séquence d'entrée lorsqu'il effectue des prédictions. Il attribue de manière dynamique des pondérations aux autres tokens de l'entrée, en mettant en évidence ceux qui sont les plus pertinents pour la tâche en cours.
Ceci est réalisé à l'aide de l'auto-attention, où le modèle calcule des scores d'attention pour chaque token par rapport à tous les autres tokens de la séquence, ce qui lui permet de capturer les dépendances indépendamment de leur distance.
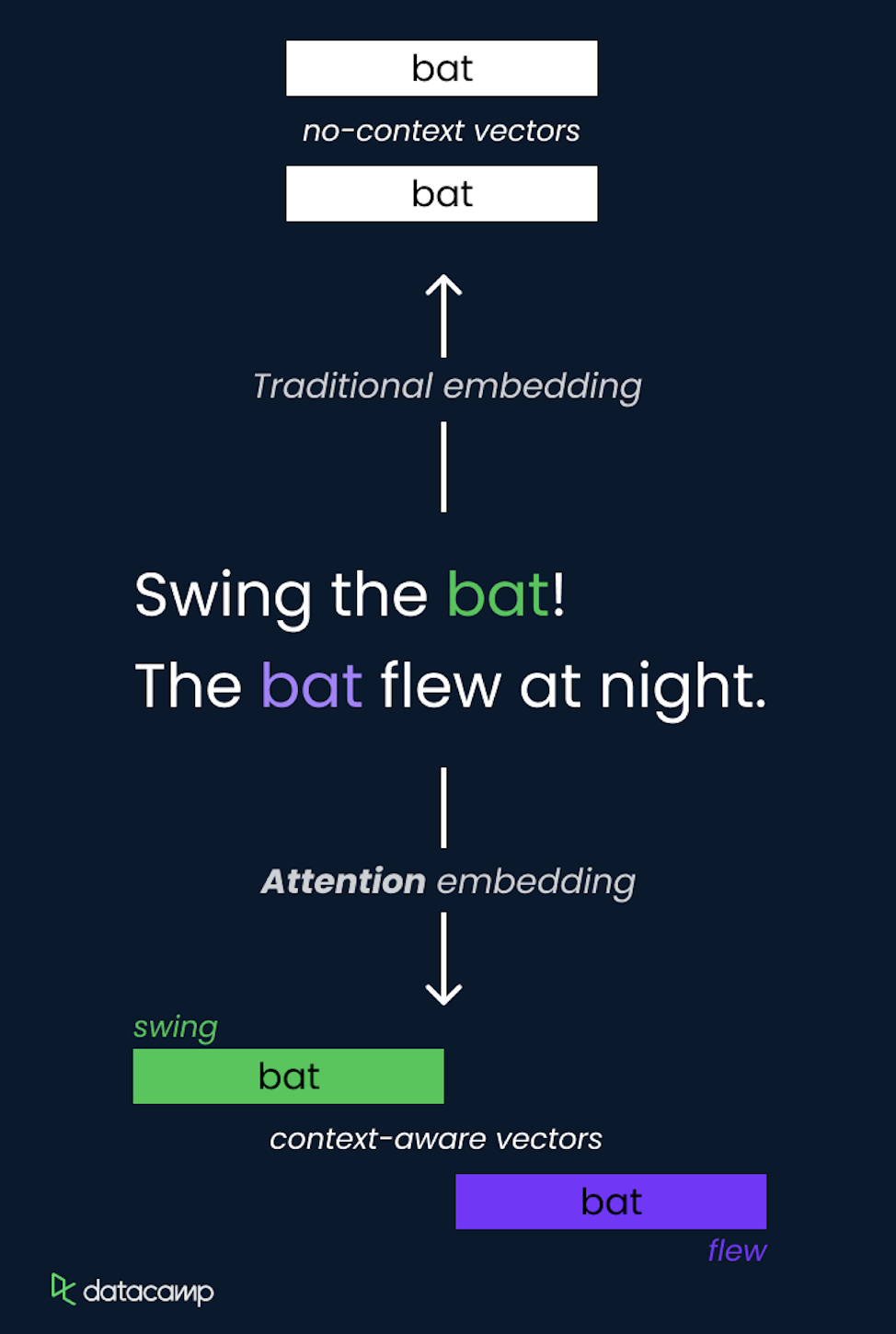
Le mécanisme d'auto-attention est un élément central de l'architecture Transformer, lui permettant de traiter efficacement les informations et de saisir les relations à long terme.
La tokenisation convertit le texte brut en unités plus petites appelées jetons, qui peuvent être des mots, des sous-mots ou des caractères.
Le rôle de la tokenisation dans le traitement LLM est essentiel, car elle transforme le texte en un format que le modèle peut comprendre et traiter.
Une tokenisation efficace garantit que le modèle peut traiter une grande diversité d'entrées, y compris des mots rares et différentes langues, en les décomposant en éléments gérables. Cette étape est essentielle pour optimiser l'entraînement et l'inférence, car elle permet de normaliser les données d'entrée et aide le modèle à identifier des modèles significatifs dans les données.
Les chercheurs et les praticiens ont développé de nombreux indicateurs d'évaluation pour mesurer les performances d'un LLM. Les indicateurs classiques comprennent :
Au-delà des mesures traditionnelles, les praticiens utilisent désormais des benchmarks standardisés à des fins diverses, tels que MMLU (test de connaissances en 57 tâches), MMMU-Pro (raisonnement multimodal) et HumanEval (génération de code). De plus, des classements tels que LMArena évaluent les LLM en fonction des préférences humaines. Pour les systèmes déployés, il est devenu essentiel de mesurer les taux d'hallucination, la latence et l'efficacité des jetons dans le monde réel.
Plusieurs techniques peuvent être utilisées pour contrôler la sortie d'un LLM, notamment :
Afin de réduire le coût de calcul des LLM, nous pouvons utiliser :
L'interprétabilité des modèles est essentielle pour comprendre comment un LLM prend ses décisions, ce qui est important pour instaurer la confiance, garantir la responsabilité et identifier et atténuer les biais. L'interprétabilité peut être obtenue par différentes approches, telles que :
Les LLM gèrent les dépendances à long terme dans le texte grâce à leur architecture, en particulier le mécanisme d'auto-attention, qui leur permet de prendre en compte simultanément tous les tokens de la séquence d'entrée. Cette capacité à prendre en compte des éléments distants aide les LLM à saisir les relations et les dépendances dans des contextes étendus.
De plus, des modèles avancés tels que Transformer-XL et Longformer sont spécialement conçus pour élargir la fenêtre contextuelle et gérer plus efficacement les séquences plus longues, garantissant ainsi une meilleure prise en charge des dépendances à long terme.
Les modèles de production modernes utilisent des stratégies plus avancées pour gérer les dépendances à long terme et contrer la dégradation des performances avec des fenêtres contextuelles en expansion, telles que :
RAG combine des mécanismes de récupération avec des modèles génératifs afin d'extraire des informations pertinentes à partir de sources externes pendant la génération de texte. Cette approche répond directement à deux limitations critiques des LLM : l'hallucination et l'actualité des connaissances. Le RAG traditionnel utilise des pipelines de récupération et de génération relativement simples, mais dans son évolution vers le « RAG 2.0 », il est devenu nettement plus sophistiqué.
Les principales fonctionnalités de RAG 2.0 comprennent :
RAG 2.0, associé aux LLM, réduit efficacement les taux d'hallucination de 40 à 60 % dans les systèmes de production par rapport aux modèles de base.
La compréhension des concepts avancés des LLM est utile pour les professionnels qui souhaitent repousser les limites de ce que ces modèles peuvent accomplir. Cette section explore des sujets complexes et les défis courants rencontrés dans ce domaine.
L'apprentissage en quelques essais dans les LLM fait référence à la capacité du modèle à apprendre et à effectuer de nouvelles tâches en utilisant seulement quelques exemples. Cette fonctionnalité exploite les connaissances approfondies pré-entraînées du LLM, lui permettant de généraliser à partir d'un petit nombre d'exemples.
Les principaux avantages de l'apprentissage en quelques essais comprennent une réduction des besoins en données, car le besoin de grands ensembles de données spécifiques à une tâche est minimisé, une flexibilité accrue, permettant au modèle de s'adapter à diverses tâches avec un réglage minimal, et une rentabilité, car la réduction des besoins en données et des temps de formation se traduit par des économies significatives en matière de collecte de données et de ressources informatiques.
Les modèles autorégressifs et les modèles linguistiques masqués se distinguent principalement par leur approche de prédiction et leur adéquation à la tâche. Les modèles autorégressifs, tels que GPT-5.2, Claude 4.5 Opus et Gemini 3, prédisent le mot suivant dans une séquence en se basant sur les mots précédents, générant ainsi du texte un token à la fois. prédisent le mot suivant dans une séquence en se basant sur les mots précédents, générant ainsi le texte un token à la fois.
Ces modèles sont particulièrement adaptés aux tâches de génération de texte. En revanche, les modèles linguistiques masqués, tels que BERT, masquent de manière aléatoire des mots dans une phrase et entraînent le modèle à prédire ces mots masqués en fonction du contexte environnant. Cette approche bidirectionnelle permet au modèle de comprendre le contexte dans les deux sens, ce qui le rend idéal pour les tâches de classification de texte et de réponse à des questions.
L'intégration de connaissances externes dans un LLM peut être réalisée de plusieurs manières :
Le déploiement des LLM en production implique divers défis :
La dégradation du modèle se produit lorsque les performances d'un LLM diminuent au fil du temps en raison de changements dans la distribution des données sous-jacentes. La gestion de la dégradation du modèle implique un réentraînement régulier avec des données mises à jour afin de maintenir les performances. Une surveillance continue est nécessaire pour suivre les performances du modèle et détecter les signes de dégradation.
Les techniques d'apprentissage incrémental permettent au modèle d'apprendre à partir de nouvelles données sans oublier les informations apprises précédemment. De plus, les tests A/B permettent de comparer les performances du modèle actuel avec celles des nouvelles versions et contribuent à identifier les améliorations potentielles avant le déploiement complet.
Afin de garantir une utilisation éthique des modèles d'apprentissage automatique (LLM), il est essentiel de mettre en place des mesures de utilisation éthique des LLM, plusieurs techniques peuvent être mises en œuvre :
La sécurisation des données utilisées avec les LLM nécessite la mise en œuvre de diverses mesures. Il s'agit notamment d'utiliser des techniques de chiffrement pour les données au repos et en transit afin de les protéger contre tout accès non autorisé. Des contrôles d'accès rigoureux sont nécessaires pour garantir que seul le personnel autorisé puisse accéder aux données sensibles.
Il est également essentiel d'anonymiser les données afin de supprimer les informations personnelles identifiables (PII) avant de les utiliser à des fins de formation ou d'inférence. De plus, il est essentiel de respecter les réglementations en matière de protection des données, telles que le RGPD ou le CCPA, afin d'éviter tout problème juridique.
Ces mesures contribuent à protéger l'intégrité, la confidentialité et la disponibilité des données. Cette protection est essentielle pour maintenir la confiance des utilisateurs et respecter les normes réglementaires.
L'apprentissage par rétroaction (, RLHF) est une technique qui consiste à former un modèle LLM afin d'aligner ses résultats sur les préférences humaines en intégrant les commentaires d'évaluateurs humains. Ce processus itératif aide le modèle à apprendre à générer des réponses qui sont non seulement précises, mais également sûres, impartiales et utiles.
Cependant, le RLHF présente des défis. L'un des défis réside dans le risque de partialité des commentaires humains, car différents évaluateurs peuvent avoir des préférences et des interprétations variées.
Un autre défi réside dans l'évolutivité du processus de rétroaction, car la collecte et l'intégration d'un grand nombre de commentaires humains peuvent s'avérer longues et coûteuses. De plus, il peut être difficile de s'assurer que le modèle de récompense utilisé dans le RLHF reflète fidèlement les comportements et les valeurs souhaités. L'étape d'optimisation PPO (Proximal Policy Optimization) ajoute de la complexité et peut entraîner une certaine instabilité pendant l'entraînement.
Des alternatives modernes ont vu le jour pour pallier bon nombre des limites du RLHF :
La plupart des modèles de production utilisent le DPO, le RLAIF ou des combinaisons hybrides plutôt que le RLHF basé uniquement sur le PPO.
Les hallucinations basées sur les connaissances surviennent lorsque le modèle ne dispose pas des faits corrects (ou dispose de faits obsolètes), et invente donc des informations qui semblent plausibles. Les corrections impliquent généralement :
Les hallucinations logiques surviennent lorsque le modèle dispose d'informations pertinentes, mais raisonne de manière incorrecte ou produit des incohérences. Les solutions courantes sont les suivantes :
Alors que les Transformers dominent actuellement le domaine des LLM, les modèles d'espace d'état (SSM) tels que Mamba se sont imposés comme un paradigme architectural compétitif, avec des propriétés de calcul et de performance fondamentalement différentes. Il est de plus en plus important pour les professionnels modernes du droit de comprendre ces deux aspects.
Transformateurs :
Modèles d'espace d'état (Mamba, Mamba-2) :
Des recherches récentes démontrent que les transformateurs et les SSM sont complémentaires plutôt que directement concurrents, avec des cas d'utilisation et des contraintes différents favorisant des architectures différentes. Les transformateurs restent le choix le plus pratique pour les LLM à usage général et devraient continuer à dominer le marché pour le moment. Un avenir hybride est probable, avec des modèles spécialisés pour différentes exigences en matière de calcul et de tâches.
L'ingénierie des invites est un aspect important de l'utilisation des LLM. Il s'agit de créer des invites précises et efficaces afin de générer les réponses souhaitées du modèle. Cette section examine les questions clés auxquelles les ingénieurs peuvent être confrontés.
L'ingénierie des invites consiste à concevoir et à perfectionner des invites afin de guider les modèles d'apprentissage automatique (LLM) dans la génération de résultats précis et pertinents. Il est essentiel de travailler avec des LLM, car la qualité de l'invite a un impact direct sur les performances du modèle.
Des invites efficaces peuvent améliorer la capacité du modèle à comprendre la tâche, générer des réponses précises et pertinentes, et réduire le risque d'erreurs.
L'ingénierie des invites est essentielle pour maximiser l'utilité des LLM dans diverses applications, de la génération de texte aux tâches complexes de résolution de problèmes.
L'évaluation de l'efficacité d'une invite implique :
Le raffinement itératif des invites implique :
Plusieurs outils et cadres peuvent rationaliser le processus d'ingénierie rapide :
Cette question aborde les aspects éthiques et pratiques du contenu généré par les LLM. Une réponse convaincante démontrerait une prise de conscience de ces problèmes et aborderait des techniques telles que celles décrites ci-dessous.
Techniques d'atténuation des hallucinations :
Techniques d'atténuation des biais :
Les modèles d'invites fournissent un format structuré pour les invites, comprenant souvent des espaces réservés pour des informations ou des instructions spécifiques. Ils peuvent être réutilisés dans différentes tâches et différents scénarios, améliorant ainsi la cohérence et l'efficacité de la conception des invites.
Une réponse appropriée expliquerait comment les modèles de prompts peuvent être utilisés pour intégrer les meilleures pratiques, incorporer des connaissances spécifiques à un domaine et rationaliser le processus de génération de prompts efficaces pour diverses applications.
Le tokeniseur joue un rôle crucial dans la manière dont le LLM interprète et traite la commande d'entrée. Les différents tokeniseurs ont des tailles de vocabulaire variables et traitent différemment les mots hors vocabulaire (OOV). Un tokeniseur de sous-mots tel que le Byte Pair Encoding (BPE) peut traiter les mots OOV en les divisant en unités de sous-mots plus petites, tandis qu'un tokeniseur basé sur les mots peut les traiter comme des tokens inconnus.
Le choix du tokeniseur peut influencer les performances du modèle de plusieurs manières. Par exemple, un tokeniseur de sous-mots peut être plus efficace pour saisir le sens de termes rares ou techniques, tandis qu'un tokeniseur basé sur les mots peut être plus simple et plus rapide pour les tâches linguistiques générales.
Dans l'ingénierie des invites, le choix du tokeniseur peut influencer la manière dont vous structurez vos invites. Par exemple, si vous utilisez un tokeniseur de sous-mots, il pourrait être nécessaire de prêter davantage attention à la manière dont les mots sont divisés en sous-mots afin de garantir que le modèle capture le sens souhaité.
L'incitation agentique est une approche de conception d'incitation dans laquelle le modèle est programmé pour agir comme un « agent » capable de planifier, d'agir (par exemple, appeler des outils/API ou récupérer des documents), d'observer les résultats et d'itérer jusqu'à ce qu'il atteigne un objectif.
Contrairement à l'ingénierie traditionnelle des invites, qui vise principalement à obtenir la meilleure réponse possible en une seule fois grâce à des instructions claires, des exemples et des contraintes de formatage, les invites agencées mettent l'accent sur une boucle de contrôle en plusieurs étapes (planifier → agir → observer → affiner).
Il est particulièrement utile pour les tâches dont l'exactitude dépend de l'interaction avec des systèmes externes (bases de données, recherche, exécution de code) ou de la vérification des résultats intermédiaires plutôt que de se fier uniquement aux connaissances internes du modèle.
Les bonnes invites agentiques définissent généralement l'objectif, les outils/actions disponibles, la manière de décider quelle action entreprendre et quand s'arrêter. Il est également courant d'ajouter des étapes de vérification explicites (par exemple, « vérifier les sources récupérées » ou « recalculer avant la réponse finale ») afin de réduire les erreurs et d'améliorer la fiabilité.
Veuillez vous renseigner davantage sur les LLM.
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
9 min
blog
blog
Lynn Heidmann
blog
Kurtis Pykes
15 min
