
Programa
Fundamentos da IA
10 h
Modelos de linguagem grandes (LLMs) têm se tornado cada vez mais importantes na inteligência artificial, com aplicações em vários setores.
Com a crescente demanda por profissionais com experiência em LLM, este artigo traz um conjunto completo de perguntas e respostas para entrevistas, cobrindo conceitos básicos, técnicas avançadas e aplicações práticas.
Se você está se preparando para uma entrevista de emprego ou simplesmente quer expandir seus conhecimentos, este artigo vai ser útil.
Pra entender os LLMs, é importante começar com os conceitos básicos. Essas questões básicas cobrem aspectos essenciais, como arquitetura, mecanismos principais e desafios típicos, oferecendo uma base sólida para aprender tópicos mais avançados.
A arquitetura Transformer é um modelo de aprendizado profundo apresentado por Vaswani et alem 2017, feito pra lidar com dados sequenciais com mais eficiência e desempenho do que os modelos anteriores, como redes neurais recorrentes (RNNs) e memórias de curto prazo longas (LSTMs).
Depende de mecanismos de autoatenção para processar dados de entrada em paralelo, tornando-o altamente escalável e capaz de capturar dependências de longo alcance.
Nos LLMs, a arquitetura Transformer é tipo a espinha dorsal, permitindo que os modelos processem grandes quantidades de dados de texto de forma eficiente e gerem resultados de texto contextualmente relevantes e coerentes.
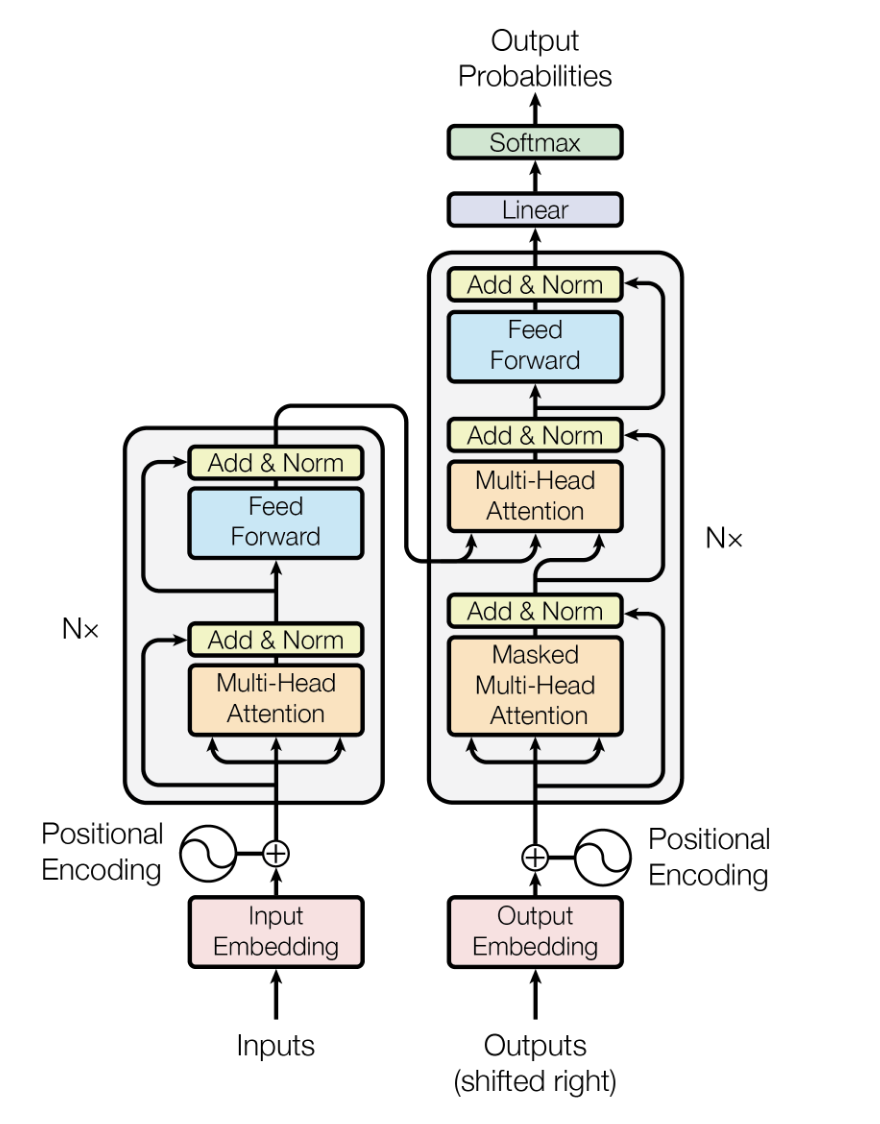
A arquitetura do modelo Transformer. Fonte
A janela de contexto nos LLMs é o trecho de texto (em termos de tokens ou palavras) que o modelo pode considerar de uma vez só ao gerar ou entender a linguagem. A importância da janela de contexto está no impacto que ela tem na capacidade do modelo de gerar respostas lógicas e relevantes.
Geralmente, uma janela de contexto maior permite que o modelo considere mais contexto, levando a uma melhor compreensão e geração de texto, especialmente em conversas complexas ou longas. Mas isso também aumenta os requisitos computacionais, o que faz com que seja preciso encontrar um equilíbrio entre desempenho e eficiência.
Além disso, pesquisas recentes mostram que os modelos de most apresentam desempenho ruim bem antes dos limites anunciados. Os modelos podem apresentar um fenômeno de “perda no meio”, em que as informações no centro do contexto são ignoradas ou deixadas de lado. Então,contexto relevante e selecionado em janelas menores costuma ter um desempenho melhor do que preencher janelas maiores com ruído.
Os objetivos comuns de pré-treinamento para LLMs incluem modelagem de linguagem mascarada (MLM) e modelagem de linguagem autorregressiva. No MLM, palavras aleatórias em uma frase são mascaradas, e o modelo é treinado para prever as palavras mascaradas com base no contexto ao redor. Isso ajuda o modelo a entender o contexto bidirecional.
A modelagem autorregressiva de linguagem envolve prever a próxima palavra em uma sequência e treinar o modelo para gerar texto um token de cada vez. Os dois objetivos permitem que o modelo aprenda padrões linguísticos e semânticos a partir de grandes corpora, dando uma base sólida para ajustar tarefas específicas.
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

O ajuste fino no contexto dos LLMs envolve pegar um modelo pré-treinado e treiná-lo ainda mais em um conjunto de dados menor e específico para a tarefa. Esse processo ajuda o modelo a adaptar sua compreensão geral da linguagem às nuances da aplicação específica, melhorando assim o desempenho.
Essa é uma técnica importante porque aproveita o amplo conhecimento linguístico adquirido durante o pré-treinamento, ao mesmo tempo em que modifica o modelo para ter um bom desempenho em aplicações específicas, como análise de sentimentos, resumo de textos ou perguntas e respostas.
Usar LLMs traz vários desafios, incluindo:
Os LLMs lidam com palavras ou tokens fora do vocabulário (OOV) usando técnicas como tokenização de subpalavras (por exemplo, Byte Pair Encoding ou BPE e WordPiece). Essas técnicas dividem palavras desconhecidas em unidades menores e conhecidas, que o modelo consegue processar.
Essa abordagem garante que, mesmo que uma palavra não seja vista durante o treinamento, o modelo ainda consiga entender e gerar texto com base em suas partes constituintes, melhorando a flexibilidade e a robustez.
As camadas de incorporação são um componente importante nos LLMs, que são usados para transformar dados categóricos, como palavras, em representações vetoriais densas. Essas incorporações capturam as relações semânticas entre as palavras, representando-as em um espaço vetorial contínuo, onde palavras parecidas ficam mais próximas. A importância de incorporar camadas em LLMs inclui:
As codificações posicionais dizem aos transformadores onde cada token está localizado na sequência.
Codificações posicionais sinusoidais tradicionais (de Vaswani et al. 2017) usaram funções matemáticas fixas para codificar posições de forma estática. Os Rotary Position Embeddings (RoPE), que surgiram mais recentemente, viraram o padrão nos LLMs modernos porque têm propriedades bem melhores.
O RoPE funciona representando posições como ângulos de rotação em um espaço vetorial complexo, girando as incorporações de tokens por um ângulo proporcional à sua posição. Essa abordagem geométrica é mais eficiente e naturalmente suporta a interpolação para sequências mais longas do que as vistas durante o treinamento, o que é uma capacidade crítica para estender as janelas de contexto. Modelos como GPT-5.2 e Gemini 3 usam RoPE como sua codificação posicional.
Com base nos conceitos básicos, as perguntas de nível intermediário exploram as técnicas práticas usadas para otimizar o desempenho do LLM e lidar com os desafios relacionados à eficiência computacional e à interpretabilidade do modelo.
O conceito de atenção em LLMs é um jeito que permite que o modelo se concentre em diferentes partes da sequência de entrada ao fazer previsões. Ele atribui pesos dinamicamente a outros tokens na entrada, destacando os mais relevantes para a tarefa atual.
Isso é feito usando autoatenção, onde o modelo calcula pontuações de atenção para cada token em relação a todos os outros tokens na sequência, permitindo capturar dependências independentemente da distância entre elas.
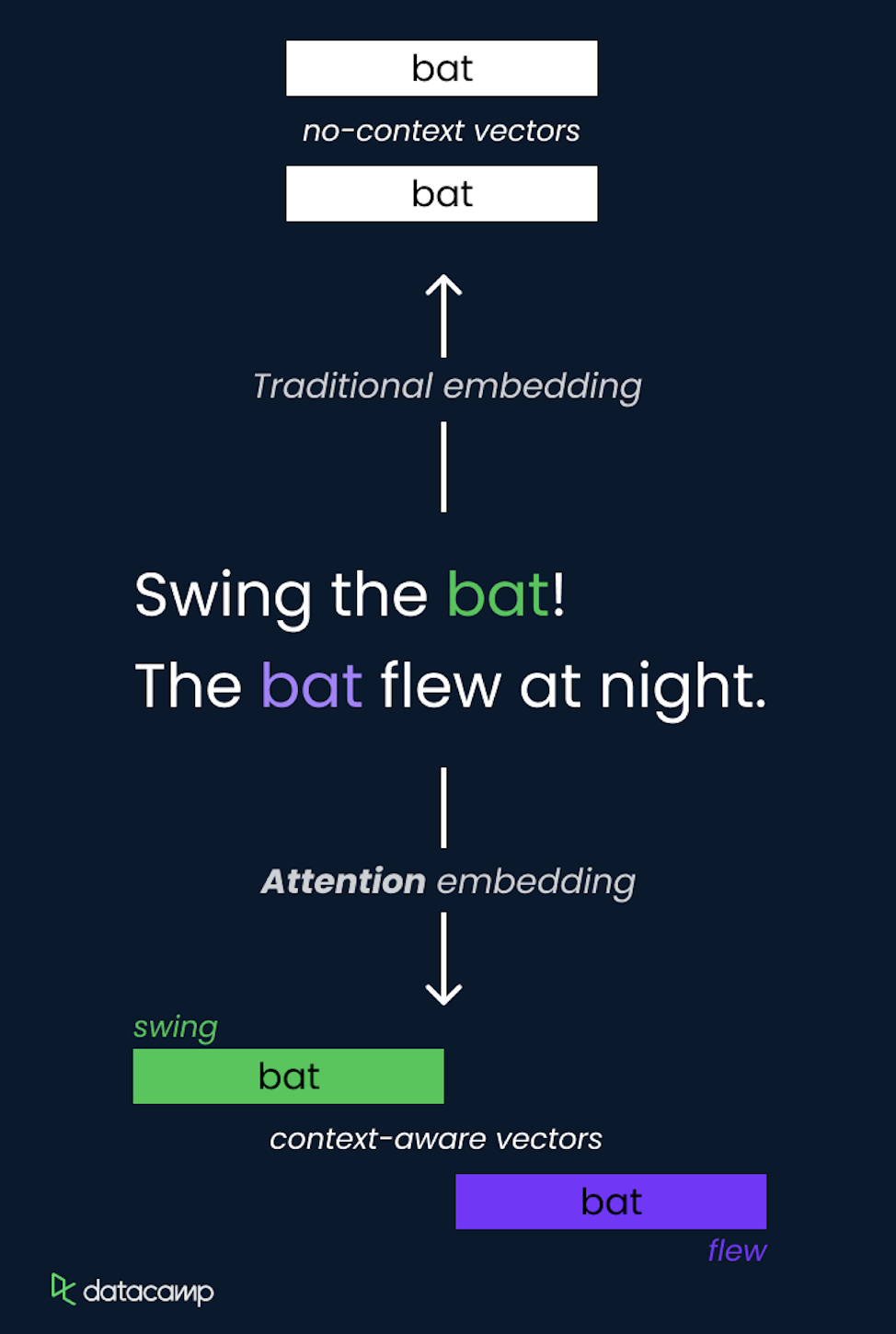
O mecanismo de autoatenção é um componente essencial da arquitetura Transformer, que permite processar informações de forma eficiente e capturar relações de longo alcance.
Tokenização é quando a gente transforma um texto bruto em partes menores chamadas tokens, que podem ser palavras, partes de palavras ou caracteres.
O papel da tokenização no processamento de LLM é super importante, porque transforma o texto num formato que o modelo consegue entender e processar.
A tokenização eficaz garante que o modelo possa lidar com uma gama diversificada de entradas, incluindo palavras raras e diferentes idiomas, dividindo-as em partes gerenciáveis. Essa etapa é importante para um treinamento e uma inferência legais, porque padroniza a entrada e ajuda o modelo a aprender padrões significativos nos dados.
Pesquisadores e profissionais desenvolveram várias métricas de avaliação para medir o desempenho de um LLM. As métricas clássicas incluem:
Além das métricas tradicionais, os profissionais agora usam referências padronizadas para diferentes fins, como MMLU (teste de conhecimento de 57 tarefas), MMMU-Pro (raciocínio multimodal) e HumanEval (geração de código). Além disso, tabelas de classificação como a LMArena classificam os LLMs de acordo com a preferência humana. Para sistemas implantados, medir as taxas reais de alucinação, latência e eficiência de tokens tornou-se essencial.
Várias técnicas podem ser usadas para controlar a saída de um LLM, incluindo:
Para reduzir o custo computacional dos LLMs, podemos usar:
A interpretabilidade do modelo é essencial para entender como um LLM toma decisões, o que é importante para construir confiança, garantir a responsabilidade e identificar e mitigar preconceitos. Alcançar a interpretabilidade pode envolver diferentes abordagens, tais como:
Os LLMs lidam com dependências de longo prazo no texto por meio de sua arquitetura, principalmente o mecanismo de autoatenção, que permite que eles considerem todos os tokens na sequência de entrada ao mesmo tempo. Essa capacidade de prestar atenção a tokens distantes ajuda os LLMs a capturar relações e dependências em contextos longos.
Além disso, modelos avançados como o Transformer-XL e o Longformer foram criados especialmente para ampliar a janela de contexto e lidar com sequências mais longas de forma mais eficiente, garantindo um melhor tratamento das dependências de longo prazo.
Os modelos de produção modernos usam estratégias mais avançadas para lidar com dependências de longo prazo e combater a degradação do desempenho com janelas de contexto em expansão, tais como:
O RAG junta mecanismos de recuperação com modelos generativos para pegar informações relevantes de fontes externas durante a geração de texto. Essa abordagem resolve diretamente duas limitações importantes do LLM: alucinação e atualização do conhecimento. O RAG tradicional usa pipelines de recuperação e geração relativamente simples, mas, na sua evolução para o “RAG 2.0”, ficou bem mais sofisticado.
As principais características do RAG 2.0 incluem:
O RAG 2.0, junto com os LLMs, reduz bem as taxas de alucinação em 40-60% nos sistemas de produção, comparado com os modelos básicos.
Entender conceitos avançados em LLMs é útil para profissionais que querem ir além do que esses modelos podem fazer. Essa seção fala sobre assuntos complexos e desafios comuns que a gente enfrenta na área.
Aprendizado com poucos exemplos em LLMs é quando o modelo consegue aprender e fazer novas tarefas usando só alguns exemplos. Essa capacidade aproveita o amplo conhecimento pré-treinado do LLM, permitindo que ele generalize a partir de um pequeno número de instâncias.
As principais vantagens do aprendizado com poucos exemplos incluem requisitos de dados reduzidos, já que a necessidade de grandes conjuntos de dados específicos para tarefas é minimizada, maior flexibilidade, permitindo que o modelo se adapte a várias tarefas com um mínimo de ajustes, e eficiência de custos, já que requisitos de dados mais baixos e tempos de treinamento reduzidos se traduzem em economias significativas na coleta de dados e recursos computacionais.
Os modelos autorregressivos e os modelos de linguagem mascarados diferem principalmente na sua abordagem de previsão e adequação à tarefa. Modelos autoregressivos, como GPT-5.2, Claude 4.5 Opus e Gemini 3, preveem a próxima palavra em uma sequência com base nas palavras anteriores, gerando texto um token de cada vez.
Esses modelos são especialmente bons para tarefas de geração de texto. Por outro lado, modelos de linguagem mascarados, como o BERT, mascaram aleatoriamente palavras em uma frase e treinam o modelo para prever essas palavras mascaradas com base no contexto ao redor. Essa abordagem bidirecional ajuda o modelo a entender o contexto das duas maneiras, o que é ótimo para classificar textos e responder perguntas.
Incorporar conhecimento externo em um LLM pode ser feito de várias maneiras:
Implantar LLMs na produção tem vários desafios:
A degradação do modelo acontece quando o desempenho de um LLM cai com o tempo por causa de mudanças na distribuição dos dados de base. Lidar com a degradação do modelo envolve retreinamento regular com dados atualizados para manter o desempenho. É preciso ficar de olho no desempenho do modelo e ver se tem algum sinal de problema.
As técnicas de aprendizagem incremental permitem que o modelo aprenda com novos dados sem esquecer as informações aprendidas anteriormente. Além disso, o teste A/B compara o desempenho do modelo atual com as novas versões e ajuda a identificar possíveis melhorias antes da implantação completa.
Para garantir o uso ético dos LLMs, várias técnicas podem ser implementadas:
Proteger os dados usados com LLMs exige várias medidas. Isso inclui usar técnicas de criptografia para dados em repouso e em trânsito, pra proteger contra acesso não autorizado. É preciso ter controles de acesso bem rígidos pra garantir que só quem tem autorização possa acessar dados confidenciais.
Tornar os dados anônimos pra tirar informações pessoais identificáveis (PII) antes de usá-los pra treinamento ou inferência também é super importante. Além disso, seguir as regras de proteção de dados, como o GDPR ou o CCPA, é essencial pra evitar problemas legais.
Essas medidas ajudam a proteger a integridade, a confidencialidade e a disponibilidade dos dados. Essa proteção é essencial para manter a confiança dos usuários e seguir as normas regulatórias.
RLHF ( ) é uma técnica que envolve treinar um LLM para alinhar seus resultados com as preferências humanas, usando o feedback de avaliadores humanos. Esse processo iterativo ajuda o modelo a aprender a gerar respostas que não são só precisas, mas também seguras, imparciais e úteis.
Mas, o RLHF também tem seus desafios. Um desafio é a possibilidade de parcialidade no feedback humano, já que diferentes avaliadores podem ter preferências e interpretações diferentes.
Outro desafio é a escalabilidade do processo de feedback, já que coletar e incorporar grandes quantidades de feedback humano pode ser demorado e caro. Além disso, garantir que o modelo de recompensa usado na RLHF capte com precisão os comportamentos e valores desejados pode ser complicado. A etapa de otimização PPO (Proximal Policy Optimization) adiciona complexidade e pode causar instabilidade durante o treinamento.
Surgiram alternativas modernas que resolvem muitas das limitações do RLHF:
A maioria dos modelos de produção usa DPO, RLAIF ou combinações híbridas em vez de RLHF baseado exclusivamente em PPO.
As alucinações baseadas no conhecimento acontecem quando o modelo não tem os fatos certos (ou tem fatos desatualizados), então inventa informações que parecem plausíveis. As correções geralmente envolvem:
As alucinações baseadas na lógica acontecem quando o modelo tem informações relevantes, mas raciocina de forma errada ou cria inconsistências. As correções mais comuns são:
Embora os Transformers dominem os LLMs hoje em dia, modelos de espaço de estado (SSMs), como o Mamba, surgiram como um paradigma arquitetônico competitivo com propriedades computacionais e de desempenho fundamentalmente diferentes. Entender os dois é cada vez mais importante para os profissionais modernos de LLM.
Transformers:
Modelos de espaço de estado (Mamba, Mamba-2):
Pesquisas recentes mostram que Transformers e SSMs são mais complementares do que concorrentes diretos, com diferentes casos de uso e restrições que favorecem diferentes arquiteturas. Os transformadores continuam sendo a escolha prática para LLMs de uso geral e provavelmente continuarão dominando por enquanto. É provável que tenhamos um futuro híbrido, com modelos especializados para diferentes requisitos computacionais e tarefas.
A engenharia de prompts é um aspecto importante da utilização de LLMs. Isso envolve criar prompts precisos e eficazes para gerar as respostas desejadas do modelo. Essa seção fala sobre as principais questões que os engenheiros podem encontrar.
A engenharia de prompts envolve projetar e refinar prompts para orientar os LLMs na geração de resultados precisos e relevantes. Isso é super importante pra trabalhar com LLMs, porque a qualidade do prompt afeta diretamente o desempenho do modelo.
Sugestões eficazes podem melhorar a capacidade do modelo de entender a tarefa, gerar respostas precisas e relevantes e reduzir a probabilidade de erros.
A engenharia de prompts é essencial para maximizar a utilidade dos LLMs em várias aplicações, desde a geração de texto até tarefas complexas de resolução de problemas.
Avaliar a eficácia de um aviso envolve:
O refinamento iterativo do prompt envolve:
Várias ferramentas e estruturas podem simplificar o processo de engenharia de prompts:
Essa questão aborda os problemas éticos e práticos do conteúdo gerado pelo LLM. Uma resposta forte mostraria que você tá ligado nesses problemas e falaria sobre técnicas como as que vêm a seguir.
Técnicas para diminuir as alucinações:
Técnicas de redução de viés:
Os modelos de prompt oferecem um formato estruturado para prompts, geralmente com espaços reservados para informações ou instruções específicas. Eles podem ser reutilizados em diferentes tarefas e cenários, melhorando a consistência e a eficiência no design de prompts.
Uma boa resposta explicaria como os modelos de prompts podem ser usados para resumir as melhores práticas, incorporar conhecimento específico do domínio e simplificar o processo de geração de prompts eficazes para várias aplicações.
O tokenizador é super importante na forma como o LLM entende e processa o prompt de entrada. Diferentes tokenizadores têm tamanhos de vocabulário diferentes e lidam com palavras fora do vocabulário (OOV) de maneiras diferentes. Um tokenizador de subpalavras como o Byte Pair Encoding (BPE) consegue lidar com palavras OOV (Out Of Vocabulary, fora do vocabulário) dividindo-as em unidades menores de subpalavras, enquanto um tokenizador baseado em palavras pode tratá-las como tokens desconhecidos.
A escolha do tokenizador pode afetar o desempenho do modelo de várias maneiras. Por exemplo, um tokenizador de subpalavras pode ser mais eficaz para capturar o significado de termos raros ou técnicos, enquanto um tokenizador baseado em palavras pode ser mais simples e rápido para tarefas linguísticas de uso geral.
Na engenharia de prompts, a escolha do tokenizador pode influenciar a forma como você estrutura seus prompts. Por exemplo, se você estiver usando um tokenizador de subpalavras, talvez precise prestar mais atenção em como as palavras são divididas em subpalavras para garantir que o modelo capte o significado pretendido.
O prompt agênico é uma abordagem de design de prompt em que o modelo é instruído a agir como um “agente” que pode planejar, tomar medidas (por exemplo, chamar ferramentas/APIs ou recuperar documentos), observar os resultados e iterar até completar um objetivo.
Diferente da engenharia de prompts tradicional, que tenta principalmente obter a melhor resposta possível de uma só vez por meio de instruções claras, exemplos e restrições de formatação, o prompting agênico enfatiza um ciclo de controle em várias etapas (planejar → agir → observar → refinar).
É especialmente útil para tarefas em que a correção depende da interação com sistemas externos (bancos de dados, pesquisa, execução de código) ou da verificação de resultados intermediários, em vez de depender apenas do conhecimento interno do modelo.
Boas instruções de agente geralmente definem o objetivo, as ferramentas/ações disponíveis, como decidir qual ação tomar e quando parar. Também é comum adicionar etapas de verificação explícitas (por exemplo, “verificar fontes recuperadas” ou “recalcular antes da resposta final”) para reduzir alucinações e melhorar a confiabilidade.
Saiba mais sobre LLMs!
Programa
Curso
Curso
blog
Hesam Sheikh Hassani
15 min
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer

