
Program
Makine Öğrenimi Bilimcisi Python'da
85 sa
Bir yapay zekâ modelini, her biri kendi alanında uzman bir ekip gibi düşünün. Uzmanlar karışımı (MoE) modeli, karmaşık bir görevi “uzman” olarak adlandırılan daha küçük, uzmanlaşmış ağlara bölerek bu prensiple çalışır.
Her uzman, problemin belirli bir yönüne odaklanır; bu da modelin görevi daha verimli ve doğru biçimde ele almasını sağlar. Tıpkı tıbbi sorunlar için bir doktor, araba sorunları için bir tamirci ve yemek için bir şef olması gibi—her uzman en iyi yaptığı işi üstlenir.
Birlikte çalışarak bu uzmanlar, tek bir genelistten daha geniş bir problem yelpazesini daha etkili biçimde çözebilir.
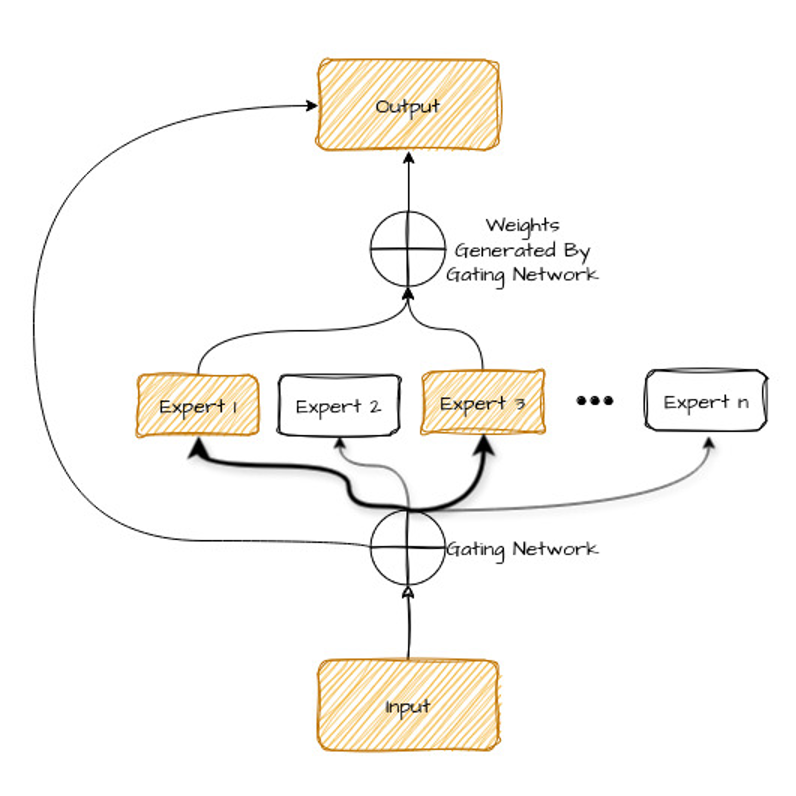
Aşağıdaki diyagrama bir göz atalım—az sonra açıklayacağız.
Bu diyagramın bileşenlerini parçalara ayıralım:
MoE kullanmanın avantajları şunlardır:
Şimdi uzman ağları ve geçit ağlarını biraz daha detaylandıralım.
MoE modelindeki "uzman ağları"nı bir uzman ekibi gibi düşünün. Tek bir yapay zekâ modelinin her şeyi yapması yerine, her uzman belirli bir görev ya da veri türüne odaklanır.
Bir MoE modelinde bu uzmanlar, tek tek sinir ağları gibidir ve her biri farklı veri kümeleri ya da görevler üzerinde eğitilmiştir.
Seyrek olacak şekilde tasarlanırlar; yani girdinin niteliğine bağlı olarak herhangi bir anda yalnızca birkaç tanesi etkin olur. Bu durum, sistemin bunalmamasını sağlar ve en ilgili uzmanların problem üzerinde çalışmasını temin eder.
Peki model hangi uzmanları seçeceğini nasıl bilir? İşte burada geçit ağı devreye girer.
Geçit ağı (yönlendirici), girdiyi (örneğin çevrilecek bir cümleyi) analiz etmeyi ve onu en iyi şekilde ele alabilecek uzmanları belirlemeyi öğrenen başka bir sinir ağı türüdür.
Bunu, girdinin özelliklerine göre her uzmana bir "ağırlık" ya da önem puanı atayarak yapar. En yüksek ağırlığa sahip uzmanlar veriyi işlemek üzere seçilir.
Geçit ağının doğru uzmanları seçmek için kullanabileceği çeşitli yöntemler ("yönlendirme algoritmaları" olarak adlandırılır) vardır. İşte yaygın olanlardan bazıları:
Tahmin üretme sürecinde model, uzmanlara görev atarken kullandığı sürecin aynısını izleyerek uzman çıktılarının birleştirilmesini sağlar. Tek bir görev için, problemin karmaşıklığına ve çeşitliliğine bağlı olarak birden fazla uzmana ihtiyaç duyulabilir.
Şimdi bir MoE nasıl çalışır, bunu anlayalım.
MoE iki aşamada işler:
Diğer makine öğrenimi modellerine benzer şekilde, MoE bir veri kümesi üzerinde eğitimle başlar. Ancak eğitim süreci tüm modele uygulanmaz; bunun yerine bileşenlerin her birinde ayrı ayrı yürütülür.
MoE çerçevesinin her bir bileşeni, belirli bir veri alt kümesi ya da görev üzerinde eğitilir. Amaç, her bileşenin daha geniş problemin belirli bir yönüne odaklanmasını sağlamaktır.
Bu odak, her bileşene, atanan görevle ilgili veriler sağlanarak elde edilir. Örneğin bir dil işleme görevinde bir bileşen sözdizimine, bir diğeri anlambilime odaklanabilir.
Her bileşenin eğitimi, modelin kendi veri alt kümesi için kayıp fonksiyonunu en aza indirmeyi öğrendiği standart bir sinir ağı eğitim sürecini izler.
Geçit ağı, verilen bir girdi için en uygun uzmanı seçmeyi öğrenmekle görevlidir.
Geçit ağının eğitimi sırasında, uzman ağlarla birlikte eğitilir. Uzmanlarla aynı girdiyi alır ve uzmanlar üzerinde bir olasılık dağılımı tahmin etmeyi öğrenir. Bu dağılım, mevcut girdiyi en iyi hangisinin ele alabileceğini gösterir.
Geçit ağı genellikle hem kendi doğruluğunu hem de seçilen uzmanların performansını içeren optimizasyon yöntemleriyle eğitilir.
Birlikte eğitim aşamasında, uzman modeller ve geçit ağından oluşan tüm MoE sistemi bir arada eğitilir.
Bu strateji, geçit ağı ile uzmanların uyum içinde çalışacak şekilde optimize edilmesini sağlar. Birlikte eğitimdeki kayıp fonksiyonu, tek tek uzmanlardan ve geçit ağından gelen kayıpları birleştirerek işbirlikçi bir optimizasyon yaklaşımını teşvik eder.
Birleştirilen kayıp gradyanları daha sonra hem geçit ağına hem de uzman modellere geri yayılır; böylece MoE sisteminin genel performansını iyileştiren güncellemeler yapılır.
Çıkarım, geçit ağlarından gelen bağlamla uzmanların çıktılarının birleştirilmesiyle çıktı üretilmesini içerir. MoE’de bu süreç, çıkarım maliyetlerini düşük tutacak şekilde tasarlanmıştır.
MoE bağlamında geçit ağının rolü, belirli bir girdiyi hangi modellerin işlemesi gerektiğine karar vermede kritiktir.
Bir girdi alındığında, geçit ağı onu değerlendirir ve tüm modeller arasında bir olasılık dağılımı oluşturur. Bu dağılım, eğitim aşamasında öğrenilen örüntülerden yararlanarak girdiyi en uygun modellere yönlendirir. Bu sayede her göreve doğru uzmanlık uygulanır ve karar verme süreci optimize edilir.
Yalnızca birkaçı, genellikle bir ya da birkaç model, her girdiyi işlemek üzere seçilir. Bu seçim, geçit ağının atadığı olasılıklar tarafından belirlenir.
Her girdi için sınırlı sayıda model seçmek, hesaplama kaynaklarının verimli kullanılmasına yardımcı olurken MoE çerçevesindeki uzman bilgiden de yararlanmayı sürdürür.
Geçit ağından gelen çıktı, seçilen modellerin girdiyi ele almak için en uygun olanlar olmasını sağlar ve böylece sistemin genel verimliliği ile performansını artırır.
Çıkarım sürecinin son adımı, seçilen modellerin çıktılarının birleştirilmesidir.
Bu birleştirme genellikle, ağırlıkların geçit ağı tarafından atanan olasılıkları yansıttığı ağırlıklı ortalama yoluyla gerçekleştirilir. Bazı durumlarda oylama ya da öğrenilmiş birleştirme teknikleri gibi alternatif yöntemler de uzman çıktılarının birleştirilmesinde kullanılabilir. Amaç, seçilen modellerden gelen farklı içgörüleri tek ve doğru bir nihai tahminde bütünleştirerek MoE mimarisinin güçlü yönlerinden yararlanmaktır.
Teknolojinin hızla gelişmesiyle birlikte, büyük modelleri ele almak için hızlı, verimli ve optimize tekniklere duyulan ihtiyaç artıyor. MoE bu açıdan umut vadeden bir çözüm olarak öne çıkıyor. MoE başka ne gibi faydalar sunuyor?
Uzmanlar Karışımı (MoE) mimarisi birçok avantaj sunar:
MoE’lerin son 30 yıldır var olması, bunu farklı makine öğrenimi alanlarında yaygın kullanılan bir teknik hâline getirmiştir.
MoE, büyük modelleri eğitmek için gelişmiş verimlilik, daha hızlı ön eğitim ve rekabetçi çıkarım hızları sunan benzersiz bir yaklaşım sağlar.
Geleneksel yoğun modellerde tüm parametreler tüm girdiler için kullanılır. Seyreklik ise girdiye bağlı olarak sistemin yalnızca belirli kısımlarının çalıştırılmasına olanak tanır ve hesaplamayı önemli ölçüde azaltır.
Buna bir örnek Microsoft’un çeviri API’sı Z-code’dur. Z-code’daki MoE mimarisi, hesaplama miktarını sabit tutarken muazzam ölçekli model parametrelerine olanak tanır.
Google’ın V-MoE’leri, Vision Transformer (ViT) tabanlı seyrek bir mimari olarak, bilgisayarla görme görevlerinde MoE’nin etkinliğini ortaya koyar.
Görüntüleri daha küçük yamalara bölüp bir geçit/yönlendirme katmanına besleyerek, V-MoE’ler her yama için en uygun uzmanları dinamik olarak seçebilir; böylece hem doğruluk hem verimlilik optimize edilir.
Bu yaklaşımın kayda değer bir avantajı esnekliğidir. Model ağırlıklarında ek bir eğitim yapmadan, zamandan ve hesaplamadan tasarruf etmek için token başına seçilen uzman sayısını azaltabilirsiniz.
MoE öneri sistemlerinde de başarıyla uygulanmıştır. Örneğin Google araştırmacıları YouTube video önerileri için MMoE (Multi-Gate Mixture of Experts) tabanlı bir sıralama sistemi önermiştir.
Önce görev hedeflerini iki kategoriye ayırırlar: etkileşim ve memnuniyet. Getirme adımından gelen aday video listesi verildiğinde, sıralama sistemleri aday, kullanıcı ve bağlam özelliklerini kullanarak kullanıcı davranışının bu iki kategorisine karşılık gelen olasılıkları tahmin etmeyi öğrenir.
Bu yaklaşımda dikkat edilmesi gereken bir nokta, girdinin yüksek boyutluluğunun önemli model eğitim ve servis maliyetlerine yol açacağından, MoE katmanını doğrudan girdiye uygulamadıklarıdır.
MoE’ler, çeşitli uygulamalar için sektörde geniş çapta benimsenmiştir. Öğrenme prosedürleri görevi uygun alt görevlere ayırır; bunların her biri çok basit bir uzman ağ tarafından çözülebilir. Bu yetenek, paralelleştirilebilir eğitime ve hızlı çıkarıma dönüşür; bu da MoE’leri büyük ölçekli sistemler için cazip kılar.
Uzmanlar, çok sayıda makine içeren yüksek verim senaryolarında özellikle faydalıdır. Sabit bir ön eğitim hesaplama bütçesi verildiğinde, seyrek bir model daha verimli olabilir.
Bununla birlikte, seyrek modeller çalıştırma sırasında önemli bellek gerektirir; çünkü tüm uzmanların bellekte tutulması gerekir. Bu durum, VRAM’i düşük sistemlerde önemli bir sınırlama olabilir ve bu tür modellerin zorlanmasına neden olabilir.
MoE’lerin diğer sınırlamalarını keşfedelim.
MoE modellerini eğitmek, tek bir modeli eğitmekten daha karmaşıktır. İşte nedeni:
MoE modellerinde çıkarım birkaç nedenle daha az verimli olabilir:
Birden fazla uzmana sahip olmaları nedeniyle MoE modelleri tekil modellere göre daha büyük olma eğilimindedir:
Bu yazıda, karmaşık görevleri ve çeşitli verileri ele almak üzere sinir ağlarını ölçeklendirmek için kullanılan gelişmiş bir yaklaşım olan Uzmanlar Karışımı (MoE) tekniğini inceledik. MoE, girdileri etkin şekilde yönlendirmek için birden fazla uzman ve bir geçit ağı kullanır.
MoE’nin uzman ağlar ve geçit ağı dâhil temel bileşenlerini ele aldık ve eğitim ile çıkarım süreçlerini tartıştık.
Geliştirilmiş performans, ölçeklenebilirlik ve uyarlanabilirlik gibi faydaların yanı sıra doğal dil işleme, bilgisayarla görme ve öneri sistemlerindeki uygulamalarına değindik.
Eğitim karmaşıklığı ve model boyutu gibi zorluklara rağmen, MoE yapay zekâ yeteneklerini ilerletmek için umut vadeden bir yöntem sunar.
Bu kurslarla yapay zekâyı öğrenin!
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
