
Programma
Scienziato specializzato in apprendimento automatico in Python
85 h
Immagina un modello di AI come una squadra di specialisti, ognuno con una competenza unica. Un modello mixture of experts (MoE) si basa su questo principio dividendo un compito complesso tra reti più piccole e specializzate chiamate "esperti".
Ogni esperto si concentra su un aspetto specifico del problema, consentendo al modello di affrontare il compito in modo più efficiente e accurato. È come avere un medico per i problemi di salute, un meccanico per l'auto e uno chef per la cucina: ogni esperto gestisce ciò che sa fare meglio.
Collaborando, questi specialisti riescono a risolvere un ventaglio più ampio di problemi in modo più efficace rispetto a un unico generalista.
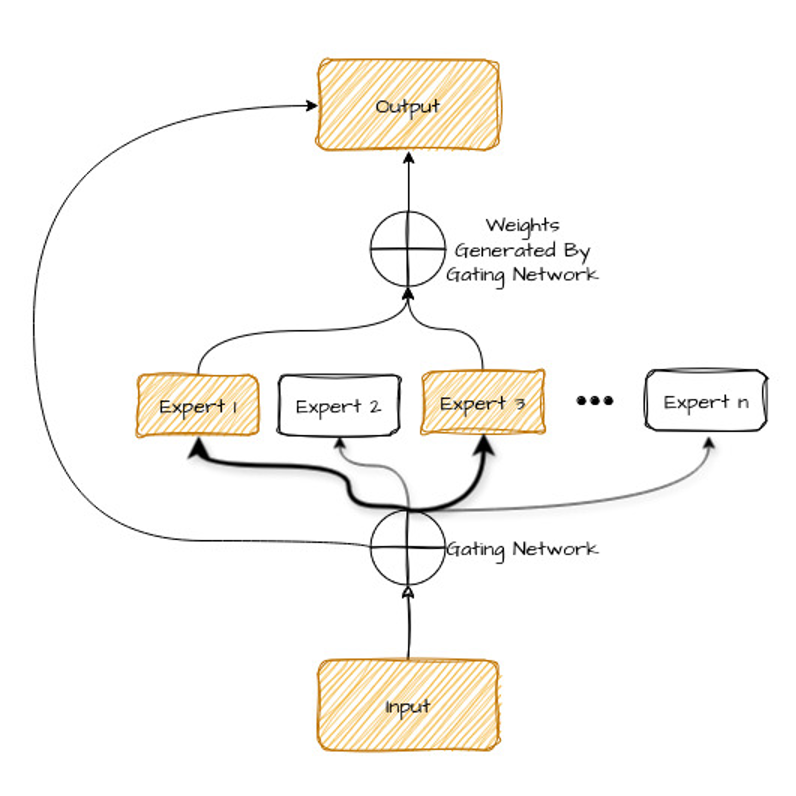
Diamo uno sguardo al diagramma qui sotto: lo spiegheremo tra poco.
Analizziamo i componenti di questo diagramma:
I vantaggi dell'uso delle MoE sono:
Entriamo un po' più nel dettaglio con le reti di esperti e le reti di gating.
Pensa alle "reti di esperti" in un modello MoE come a una squadra di specialisti. Invece di avere un unico modello di AI che fa tutto, ogni esperto si concentra su un particolare tipo di compito o di dato.
In un modello MoE, questi esperti sono come singole reti neurali, ciascuna addestrata su dataset o compiti diversi.
Sono progettati per essere sparsi, cioè solo pochi sono attivi in un dato momento, a seconda della natura dell'input. Questo evita di sovraccaricare il sistema e garantisce che lavorino gli esperti più pertinenti.
Ma come fa il modello a sapere quali esperti scegliere? Qui entra in gioco la rete di gating.
La rete di gating (il router) è un altro tipo di rete neurale che impara ad analizzare i dati in input (come una frase da tradurre) e a determinare quali esperti sono più adatti a gestirli.
Lo fa assegnando un "peso" o punteggio di importanza a ciascun esperto in base alle caratteristiche dell'input. Gli esperti con i pesi più alti vengono poi selezionati per elaborare i dati.
Esistono vari modi (detti "algoritmi di instradamento") con cui la rete di gating può selezionare gli esperti giusti. Eccone alcuni comuni:
Durante il processo di previsione, il modello combina gli output degli esperti seguendo lo stesso processo usato per assegnare loro i compiti. Per un singolo compito possono servire più esperti, a seconda della complessità e varietà del problema.
Ora vediamo come funziona una MoE.
La MoE opera in due fasi:
Analogamente ad altri modelli di machine learning, la MoE inizia addestrandosi su un dataset. Tuttavia, il processo non si applica all'intero modello, ma ai suoi componenti singolarmente.
Ogni componente di un framework MoE viene addestrato su un sottoinsieme specifico di dati o compiti. L'obiettivo è permettere a ciascun componente di concentrarsi su un aspetto particolare del problema più ampio.
Questo focus si ottiene fornendo a ogni componente dati pertinenti al compito assegnato. Per esempio, in un compito di elaborazione del linguaggio, un componente potrebbe concentrarsi sulla sintassi e un altro sulla semantica.
L'addestramento di ciascun componente segue un normale processo di training di una rete neurale, in cui il modello impara a minimizzare la funzione di perdita per il proprio sottoinsieme di dati.
La rete di gating ha il compito di imparare a selezionare l'esperto più adatto per un dato input.
Durante l'addestramento della rete di gating, questa viene addestrata insieme alle reti di esperti. Riceve lo stesso input degli esperti e impara a predire una distribuzione di probabilità sugli esperti. Questa distribuzione indica quale esperto è più adatto a gestire l'input corrente.
La rete di gating è in genere addestrata usando metodi di ottimizzazione che tengono conto sia dell'accuratezza della rete di gating sia delle prestazioni degli esperti selezionati.
Nella fase di addestramento congiunto, l'intero sistema MoE, che include sia i modelli esperti sia la rete di gating, viene addestrato insieme.
Questa strategia assicura che sia la rete di gating sia gli esperti siano ottimizzati per lavorare in armonia. La funzione di perdita nell'addestramento congiunto combina le perdite dei singoli esperti e della rete di gating, promuovendo un'ottimizzazione collaborativa.
I gradienti della perdita combinata vengono quindi propagati sia attraverso la rete di gating sia attraverso i modelli esperti, facilitando aggiornamenti che migliorano le prestazioni complessive del sistema MoE.
L'inferenza consiste nel generare output combinando il contesto dalle reti di gating con gli output degli esperti. Nelle MoE, questo processo è progettato per mantenere minimi i costi di inferenza.
Nel contesto delle MoE, il ruolo della rete di gating è fondamentale nel decidere quali modelli devono elaborare uno specifico input.
Alla ricezione di un input, la rete di gating lo valuta e crea una distribuzione di probabilità su tutti i modelli. Questa distribuzione indirizza quindi l'input verso i modelli più adatti, sfruttando i pattern appresi durante la fase di addestramento. Ciò garantisce che a ogni compito venga applicata l'esperienza giusta, ottimizzando il processo decisionale.
Solo un numero ristretto di modelli, di solito uno o pochi, viene scelto per elaborare ciascun input. Questa selezione è determinata dalle probabilità assegnate dalla rete di gating.
Scegliere un numero limitato di modelli per ogni input aiuta a usare in modo efficiente le risorse computazionali, beneficiando al contempo delle conoscenze specialistiche all'interno del framework MoE.
L'output della rete di gating assicura che i modelli scelti siano i più appropriati per gestire l'input, migliorando così l'efficienza e le prestazioni complessive del sistema.
L' ultimo passaggio del processo di inferenza consiste nel fondere gli output dei modelli selezionati.
Questa fusione si ottiene spesso tramite una media pesata, in cui i pesi riflettono le probabilità assegnate dalla rete di gating. In alcuni scenari si possono usare metodi alternativi, come il voto o tecniche di combinazione apprese, per unire gli output degli esperti. L'obiettivo è integrare i diversi contributi dei modelli selezionati in una previsione finale unificata e accurata, sfruttando i punti di forza dell'architettura MoE.
Con il rapido avanzamento della tecnologia, cresce la necessità di tecniche veloci, efficienti e ottimizzate per gestire modelli di grandi dimensioni. Le MoE stanno emergendo come una soluzione promettente in questo senso. Quali altri vantaggi offrono le MoE?
L'architettura Mixture of Experts (MoE) offre diversi vantaggi:
Il fatto che le MoE esistano da 30 anni le rende una tecnica ampiamente usata in diverse aree del machine learning.
Le MoE offrono un approccio unico all'addestramento di modelli di grandi dimensioni con maggiore efficienza, pre-training più rapido e velocità di inferenza competitive.
Nei modelli densi tradizionali, tutti i parametri sono utilizzati per tutti gli input. La sparsità consente invece al modello di eseguire solo parti specifiche del sistema in base all'input, riducendo significativamente i calcoli.
Un esempio è l'API di traduzione di Microsoft, Z-code. L'architettura MoE in Z-code supporta una scala enorme di parametri del modello mantenendo costante la quantità di calcolo.
I V-MoE di Google, un'architettura sparsa basata sui Vision Transformer (ViT), mostrano l'efficacia delle MoE nei task di computer vision.
Suddividendo le immagini in patch più piccole e inviandole a un livello di gating/instradamento, i V-MoE possono selezionare dinamicamente gli esperti più adatti per ogni patch, ottimizzando sia l'accuratezza sia l'efficienza.
Un vantaggio notevole di questo approccio è la flessibilità. Puoi diminuire il numero di esperti selezionati per token per risparmiare tempo e calcolo, senza ulteriore addestramento sui pesi del modello.
Le MoE sono state applicate con successo anche ai sistemi di raccomandazione. Per esempio, i ricercatori di Google hanno proposto un sistema di ranking basato su MMoE (Multi-Gate Mixture of Experts) per le raccomandazioni di video su YouTube.
Hanno innanzitutto raggruppato gli obiettivi del task in due categorie: engagement e soddisfazione. Dato l'elenco di video candidati dalla fase di retrieval, il loro sistema di ranking utilizza caratteristiche del candidato, dell'utente e del contesto per imparare a prevedere le probabilità corrispondenti alle due categorie di comportamento utente.
Da notare che in questo approccio non hanno applicato direttamente il livello MoE all'input, perché l'alta dimensionalità dell'input comporterebbe costi significativi di addestramento e serving del modello.
Le MoE hanno visto un'adozione su larga scala nell'industria per diverse applicazioni. La loro procedura di apprendimento divide il compito in sottocompiti appropriati, ognuno dei quali può essere risolto da una rete di esperti molto semplice. Questa capacità si traduce in addestramento parallelizzabile e inferenza rapida, rendendo le MoE attraenti per sistemi su larga scala.
Gli esperti sono particolarmente vantaggiosi in scenari ad alto throughput che coinvolgono molte macchine. A parità di budget computazionale per il pretraining, un modello sparso può essere più efficiente.
Tuttavia, i modelli sparsi richiedono molta memoria in esecuzione, poiché tutti gli esperti devono essere conservati in memoria. Questo può essere un limite significativo in sistemi con poca VRAM, dove tali modelli possono avere difficoltà.
Esploriamo altre limitazioni delle MoE.
Addestrare modelli MoE è più complesso che addestrare un singolo modello. Ecco perché:
L'inferenza nei modelli MoE può essere meno efficiente per alcuni fattori:
I modelli MoE tendono a essere più grandi dei modelli singoli a causa dei molteplici esperti:
In questo articolo abbiamo esplorato la tecnica Mixture of Experts (MoE), un approccio sofisticato per scalare le reti neurali in modo da gestire compiti complessi e dati eterogenei. Le MoE utilizzano molteplici esperti specializzati e una rete di gating per instradare efficacemente gli input.
Abbiamo trattato i componenti fondamentali delle MoE, incluse le reti di esperti e la rete di gating, e discusso i processi di addestramento e inferenza.
Abbiamo evidenziato vantaggi come prestazioni, scalabilità e adattabilità migliorate, insieme ad applicazioni in elaborazione del linguaggio naturale, computer vision e sistemi di raccomandazione.
Nonostante le sfide in termini di complessità di addestramento e dimensioni del modello, le MoE offrono un metodo promettente per far progredire le capacità dell'AI.
Impara l'AI con questi corsi!
Programma
Programma
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

