
Program
Ilmuwan Pembelajaran Mesin dalam Python
85 Hr
Bayangkan sebuah model AI sebagai tim spesialis, masing-masing dengan keahliannya sendiri. Model mixture of experts (MoE) beroperasi dengan prinsip ini dengan membagi tugas kompleks ke jaringan yang lebih kecil dan terspesialisasi yang disebut “expert.”
Setiap expert berfokus pada aspek tertentu dari masalah, sehingga model dapat menangani tugas lebih efisien dan akurat. Ibaratnya Anda memiliki dokter untuk masalah medis, montir untuk masalah mobil, dan koki untuk urusan memasak—masing-masing expert menangani hal yang paling dikuasainya.
Dengan berkolaborasi, para spesialis ini dapat menyelesaikan rentang masalah yang lebih luas secara lebih efektif daripada seorang generalis tunggal.
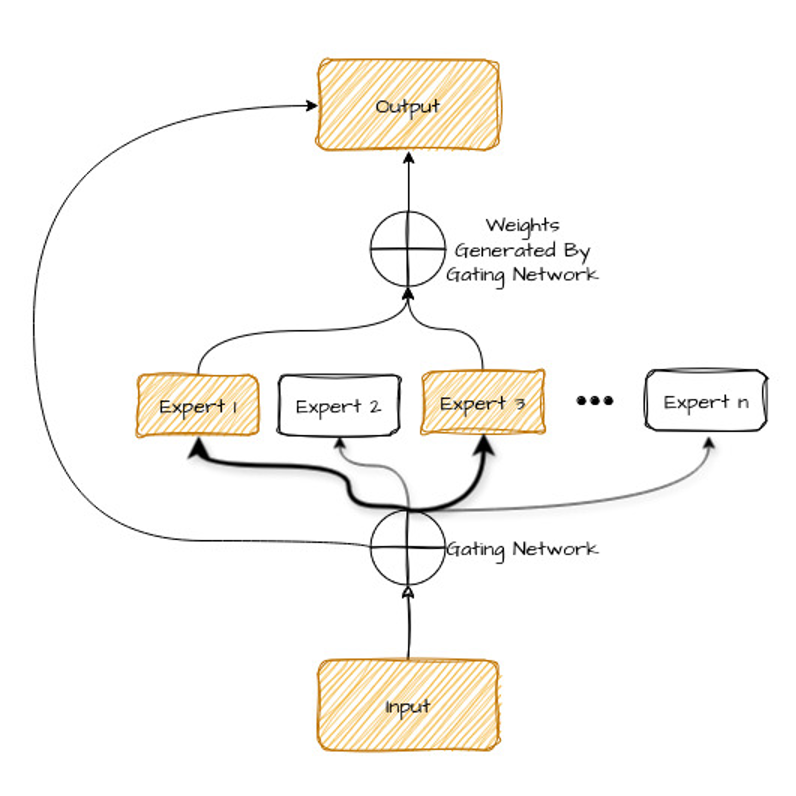
Mari lihat diagram di bawah—penjelasannya akan kita bahas sesaat lagi.
Mari kita uraikan komponen pada diagram ini:
Keuntungan menggunakan MoE antara lain:
Sekarang mari bahas lebih rinci tentang expert network dan gating network.
Anggap "expert network" dalam model MoE sebagai tim spesialis. Alih-alih satu model AI melakukan segalanya, tiap expert fokus pada jenis tugas atau data tertentu.
Dalam model MoE, para expert ini seperti jaringan saraf individual, masing-masing dilatih pada dataset atau tugas yang berbeda.
Mereka dirancang bersifat sparse, artinya hanya beberapa yang aktif pada suatu waktu, bergantung pada sifat input. Ini mencegah sistem kewalahan dan memastikan expert yang paling relevan yang mengerjakan masalah.
Namun bagaimana model mengetahui expert mana yang dipilih? Di sinilah gating network berperan.
Gating network (router) adalah jenis jaringan saraf lain yang belajar menganalisis data input (seperti kalimat yang akan diterjemahkan) dan menentukan expert mana yang paling tepat menanganinya.
Ia melakukannya dengan menetapkan "bobot" atau skor kepentingan untuk tiap expert berdasarkan karakteristik input. Expert dengan bobot tertinggi kemudian dipilih untuk memproses data.
Ada berbagai cara (disebut "algoritme routing") yang dapat digunakan gating network untuk memilih expert yang tepat. Berikut beberapa yang umum:
Selama proses membuat prediksi, model menggabungkan output dari para expert, mengikuti proses yang sama seperti saat menetapkan tugas kepada expert. Untuk satu tugas, lebih dari satu expert mungkin diperlukan, tergantung pada kompleksitas dan variasi masalah.
Sekarang, mari pahami bagaimana MoE bekerja.
MoE beroperasi dalam dua tahap:
Serupa dengan model machine learning lainnya, MoE dimulai dengan pelatihan pada suatu dataset. Namun, proses pelatihannya tidak diterapkan pada seluruh model, melainkan dilakukan pada komponennya secara individual.
Setiap komponen dalam kerangka MoE menjalani pelatihan pada subset data atau tugas tertentu. Tujuannya adalah agar tiap komponen fokus pada aspek spesifik dari masalah yang lebih luas.
Fokus ini dicapai dengan memberikan tiap komponen data yang relevan dengan tugasnya. Misalnya, dalam tugas pemrosesan bahasa, satu komponen mungkin berfokus pada sintaks, sementara yang lain pada semantik.
Pelatihan tiap komponen mengikuti proses pelatihan jaringan saraf standar, di mana model belajar meminimalkan fungsi loss untuk subset datanya masing-masing.
Gating network bertugas mempelajari cara memilih expert yang paling sesuai untuk suatu input.
Selama pelatihan gating network, ia dilatih bersamaan dengan expert network. Gating menerima input yang sama seperti para expert dan belajar memprediksi distribusi probabilitas atas para expert. Distribusi ini menunjukkan expert mana yang paling cocok menangani input saat ini.
Gating network umumnya dilatih menggunakan metode optimasi yang mempertimbangkan akurasi gating network dan kinerja expert yang dipilih.
Dalam fase pelatihan gabungan, seluruh sistem MoE, yang mencakup model-model expert dan gating network, dilatih bersama.
Strategi ini memastikan gating network dan para expert dioptimalkan agar selaras. Fungsi loss pada pelatihan gabungan mengombinasikan loss dari tiap expert dan gating network, mendorong pendekatan optimasi kolaboratif.
Gradien loss gabungan kemudian dipropagasikan melalui gating network dan model expert, memfasilitasi pembaruan yang meningkatkan kinerja keseluruhan sistem MoE.
Inferensi melibatkan pembuatan output dengan menggabungkan konteks dari gating network dengan output dari expert. Dalam MoE, proses ini dirancang untuk menjaga biaya inferensi seminimal mungkin.
Dalam konteks MoE, peran gating network sangat penting dalam memutuskan model mana yang harus memproses suatu input.
Saat menerima input, gating network menilainya dan membuat distribusi probabilitas di seluruh model. Distribusi ini kemudian mengarahkan input ke model yang paling sesuai, memanfaatkan pola yang dipelajari selama fase pelatihan. Ini memastikan keahlian yang tepat diterapkan pada setiap tugas, mengoptimalkan proses pengambilan keputusan.
Hanya beberapa model terpilih, biasanya satu atau beberapa, yang dipilih untuk memproses setiap input. Pemilihan ini ditentukan oleh probabilitas yang ditetapkan oleh gating network.
Memilih sejumlah terbatas model untuk setiap input membantu pemanfaatan sumber daya komputasi secara efisien sekaligus tetap memetik manfaat dari pengetahuan terspesialisasi dalam kerangka MoE.
Output dari gating network memastikan model yang dipilih paling tepat untuk menangani input, sehingga meningkatkan efisiensi dan kinerja sistem secara keseluruhan.
Langkah terakhir dalam proses inferensi adalah menggabungkan output dari model terpilih.
Penggabungan ini sering dilakukan melalui perata-rataan berbobot, di mana bobot mencerminkan probabilitas yang ditetapkan oleh gating network. Dalam skenario tertentu, metode alternatif seperti voting atau teknik penggabungan yang dipelajari bisa digunakan untuk menggabungkan output expert. Tujuannya adalah mengintegrasikan beragam wawasan dari model terpilih menjadi prediksi akhir yang terpadu dan akurat, dengan demikian memanfaatkan kekuatan arsitektur MoE.
Dengan kemajuan teknologi yang pesat, kebutuhan akan teknik yang cepat, efisien, dan teroptimasi untuk menangani model besar semakin meningkat. MoE muncul sebagai solusi yang menjanjikan. Apa saja manfaat lain yang ditawarkan MoE?
Arsitektur Mixture of Experts (MoE) menawarkan beberapa keunggulan:
Fakta bahwa MoE telah ada selama 30 tahun terakhir membuatnya menjadi teknik yang banyak digunakan di berbagai bidang machine learning.
MoE menawarkan pendekatan unik untuk melatih model besar dengan efisiensi lebih baik, pre-training lebih cepat, dan kecepatan inferensi yang kompetitif.
Dalam model dense tradisional, semua parameter digunakan untuk semua input. Sparsity memungkinkan model hanya menjalankan bagian tertentu dari sistem berdasarkan input, sehingga secara signifikan mengurangi komputasi.
Salah satu contohnya adalah API terjemahan Microsoft, Z-code. Arsitektur MoE di Z-code mendukung skala parameter model yang masif sembari menjaga jumlah komputasi tetap konstan.
V-MoE Google, arsitektur sparse berbasis Vision Transformer (ViT), menunjukkan efektivitas MoE dalam tugas visi komputer.
Dengan membagi gambar menjadi patch kecil dan memberikannya ke lapisan gating/routing, V-MoE dapat secara dinamis memilih expert yang paling tepat untuk tiap patch, mengoptimalkan akurasi dan efisiensi.
Keunggulan menonjol dari pendekatan ini adalah fleksibilitasnya. Anda dapat mengurangi jumlah expert yang dipilih per token untuk menghemat waktu dan komputasi, tanpa perlu pelatihan ulang bobot model.
MoE juga berhasil diterapkan pada sistem rekomendasi. Sebagai contoh, peneliti Google mengusulkan sistem pemeringkatan berbasis MMoE (Multi-Gate Mixture of Experts) untuk rekomendasi video YouTube.
Mereka terlebih dahulu mengelompokkan tujuan tugas menjadi dua kategori: keterlibatan dan kepuasan. Berdasarkan daftar kandidat video dari langkah retrieval, sistem pemeringkatan mereka menggunakan fitur kandidat, pengguna, dan konteks untuk belajar memprediksi probabilitas yang sesuai dengan dua kategori perilaku pengguna.
Satu hal yang perlu dicatat dalam pendekatan ini adalah mereka tidak menerapkan lapisan MoE langsung pada input karena dimensi input yang tinggi akan menyebabkan biaya pelatihan dan penyajian model yang signifikan.
MoE telah diadopsi secara luas di industri untuk berbagai aplikasi. Prosedur pembelajarannya membagi tugas menjadi sub-tugas yang tepat, yang masing-masing dapat diselesaikan oleh jaringan expert yang sangat sederhana. Kemampuan ini menghasilkan pelatihan yang dapat diparalelkan dan inferensi yang cepat, menjadikan MoE menarik untuk sistem skala besar.
Expert sangat bermanfaat untuk skenario throughput tinggi yang melibatkan banyak mesin. Dengan anggaran komputasi tetap untuk pretraining, model sparse bisa lebih efisien.
Namun, model sparse memerlukan memori yang besar saat dijalankan, karena semua expert harus disimpan di memori. Ini bisa menjadi keterbatasan signifikan pada sistem dengan VRAM rendah, di mana model seperti ini mungkin kesulitan.
Mari jelajahi keterbatasan MoE lainnya.
Melatih model MoE lebih kompleks daripada melatih satu model. Berikut alasannya:
Inferensi pada model MoE bisa kurang efisien karena beberapa faktor:
Model MoE cenderung lebih besar daripada model tunggal karena adanya banyak expert:
Dalam artikel ini, kita menelusuri teknik Mixture of Experts (MoE), pendekatan canggih untuk melakukan penskalaan jaringan saraf agar mampu menangani tugas yang kompleks dan data yang beragam. MoE menggunakan banyak expert terspesialisasi dan sebuah gating network untuk merutekan input secara efektif.
Kita membahas komponen inti MoE, termasuk expert network dan gating network, serta proses pelatihan dan inferensinya.
Manfaat seperti peningkatan kinerja, skalabilitas, dan adaptabilitas turut disorot, beserta penerapannya pada pemrosesan bahasa alami, visi komputer, dan sistem rekomendasi.
Meski ada tantangan dalam kompleksitas pelatihan dan ukuran model, MoE menawarkan metode yang menjanjikan untuk memajukan kapabilitas AI.
Pelajari AI dengan kursus-kursus ini!
Program
Program
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
