
Programa
Cientista de machine learning em Python
85 h
Pense em um modelo de IA como um time de especialistas, cada um com uma competência específica. Um modelo mixture of experts (MoE) opera nesse princípio ao dividir uma tarefa complexa em redes menores e especializadas, conhecidas como “experts”.
Cada expert foca em um aspecto específico do problema, permitindo que o modelo resolva a tarefa com mais eficiência e precisão. É como ter um médico para questões de saúde, um mecânico para o carro e um chef para a cozinha — cada expert cuida do que faz melhor.
Ao colaborar, esses especialistas resolvem uma gama mais ampla de problemas com mais eficácia do que um generalista sozinho.
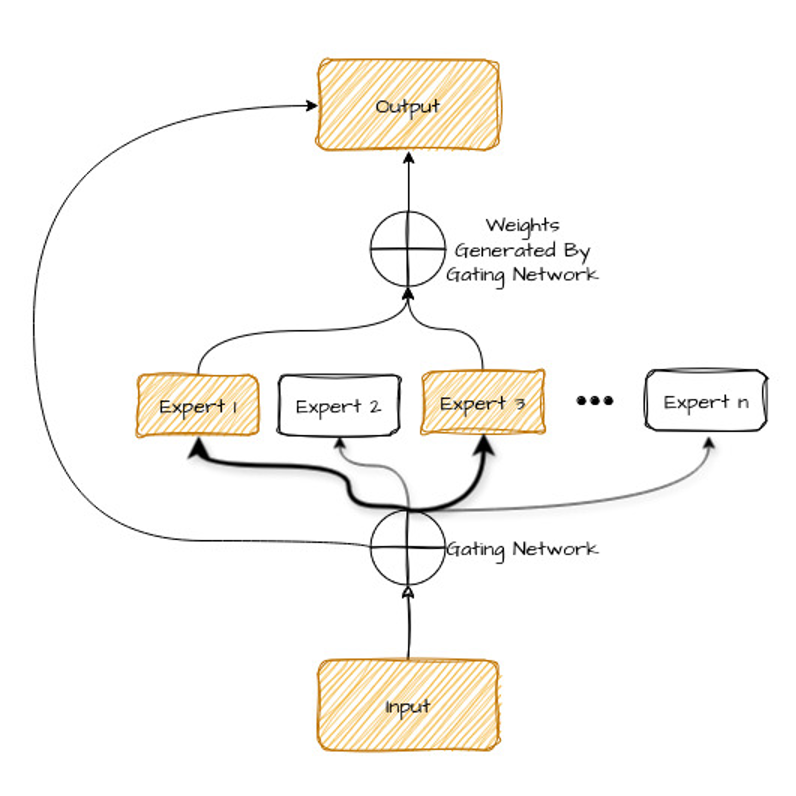
Confira o diagrama abaixo — vamos explicá-lo em seguida.
Vamos destrinchar os componentes deste diagrama:
As vantagens de usar MoE são:
Agora, vamos detalhar um pouco mais as redes de experts e as gating networks.
Pense nas “redes de experts” em um modelo MoE como um time de especialistas. Em vez de um único modelo de IA fazer tudo, cada expert foca em um tipo de tarefa ou dado.
Em um modelo MoE, esses experts são como redes neurais individuais, cada uma treinada em diferentes conjuntos de dados ou tarefas.
Elas são esparsas, ou seja, apenas algumas ficam ativas a cada momento, dependendo da natureza da entrada. Isso evita sobrecarga e garante que os experts mais relevantes atuem no problema.
Mas como o modelo sabe quais experts escolher? É aí que entra a gating network.
A gating network (o roteador) é outro tipo de rede neural que aprende a analisar os dados de entrada (como uma frase a ser traduzida) e determinar quais experts estão mais aptos a tratá-los.
Ela faz isso atribuindo um “peso” ou pontuação de importância a cada expert com base nas características da entrada. Os experts com maiores pesos são selecionados para processar os dados.
Existem várias maneiras (chamadas de “algoritmos de roteamento”) de a gating network selecionar os experts certos. Algumas comuns:
Durante a predição, o modelo combina as saídas dos experts seguindo o mesmo processo usado para atribuir as tarefas. Em uma única tarefa, pode ser necessário mais de um expert, dependendo da complexidade e variedade do problema.
Agora, vamos entender como um MoE funciona.
O MoE opera em duas etapas:
Assim como em outros modelos de machine learning, o MoE começa treinando em um conjunto de dados. Porém, o treinamento não é aplicado ao modelo inteiro de uma vez — cada componente é treinado individualmente.
Cada componente do framework MoE é treinado em um subconjunto específico de dados ou tarefas. O objetivo é permitir que cada componente foque em um aspecto particular do problema maior.
Essa especialização é alcançada fornecendo a cada componente dados relevantes para sua tarefa. Em processamento de linguagem, por exemplo, um componente pode focar em sintaxe e outro em semântica.
O treinamento de cada componente segue o processo padrão de redes neurais, em que o modelo aprende a minimizar a função de perda no seu subconjunto de dados.
A gating network tem a tarefa de aprender a selecionar o expert mais adequado para uma dada entrada.
Durante o treinamento, ela é treinada em conjunto com as redes de experts. Recebe a mesma entrada que os experts e aprende a prever uma distribuição de probabilidade sobre os experts, indicando qual deles está mais apto a lidar com a entrada atual.
Geralmente, a gating network é otimizada considerando tanto sua própria acurácia quanto o desempenho dos experts escolhidos.
Na fase de treinamento conjunto, todo o sistema MoE, incluindo os modelos experts e a gating network, é treinado em harmonia.
Essa estratégia garante que ambos — gating e experts — sejam otimizados para trabalhar de forma coordenada. A função de perda combina as perdas dos experts e da gating network, incentivando uma otimização colaborativa.
Os gradientes da perda combinada são propagados pela gating network e pelos modelos experts, promovendo atualizações que melhoram o desempenho geral do sistema MoE.
A inferência envolve gerar saídas combinando o contexto da gating network com as saídas dos experts. No MoE, esse processo é projetado para manter o custo de inferência baixo.
No MoE, o papel da gating network é decisivo para definir quais modelos devem processar uma entrada específica.
Ao receber uma entrada, a gating network a avalia e cria uma distribuição de probabilidade sobre todos os modelos. Essa distribuição direciona a entrada para os modelos mais adequados, aproveitando os padrões aprendidos na fase de treinamento. Assim, a expertise certa é aplicada a cada tarefa, otimizando a tomada de decisão.
Apenas um ou poucos modelos são escolhidos para processar cada entrada, conforme as probabilidades atribuídas pela gating network.
Limitar o número de modelos por entrada ajuda a usar os recursos computacionais com eficiência, sem abrir mão do conhecimento especializado do framework MoE.
A saída da gating network garante que os modelos escolhidos sejam os mais apropriados para a entrada, elevando a eficiência e o desempenho do sistema.
A última etapa da inferência envolve mesclar as saídas dos modelos selecionados.
Geralmente isso é feito por média ponderada, em que os pesos refletem as probabilidades atribuídas pela gating network. Em certos cenários, podem ser usadas alternativas como votação ou combinações aprendidas. A ideia é integrar os diferentes insights dos modelos selecionados em uma previsão final única e precisa, aproveitando ao máximo a arquitetura MoE.
Com o avanço acelerado da tecnologia, cresce a necessidade de técnicas rápidas, eficientes e otimizadas para lidar com modelos grandes. O MoE desponta como uma solução promissora nesse cenário. Que outros benefícios ele oferece?
A arquitetura Mixture of Experts (MoE) oferece diversas vantagens:
O fato de os MoEs existirem há mais de 30 anos faz deles uma técnica amplamente usada em diferentes áreas de machine learning.
O MoE traz uma abordagem única para treinar modelos grandes com mais eficiência, pré-treinamento mais rápido e velocidade de inferência competitiva.
Em modelos densos tradicionais, todos os parâmetros são usados para todas as entradas. A esparsidade permite acionar apenas partes específicas do sistema conforme a entrada, reduzindo significativamente a computação.
Um exemplo é a API de tradução da Microsoft, Z-code. A arquitetura MoE no Z-code suporta uma escala massiva de parâmetros mantendo constante a quantidade de computação.
V-MoEs do Google, uma arquitetura esparsa baseada em Vision Transformers (ViT), mostram a eficácia do MoE em tarefas de visão computacional.
Ao particionar imagens em patches menores e passá-los por uma camada de roteamento, os V-MoEs conseguem selecionar dinamicamente os experts mais adequados para cada patch, otimizando precisão e eficiência.
Uma vantagem notável dessa abordagem é a flexibilidade. Você pode reduzir o número de experts selecionados por token para economizar tempo e computação, sem necessidade de retreinar os pesos do modelo.
O MoE também tem sido aplicado com sucesso a sistemas de recomendação. Por exemplo, pesquisadores do Google propuseram um sistema de ranqueamento baseado em MMoE (Multi-Gate Mixture of Experts) para recomendações de vídeos no YouTube.
Eles agrupam os objetivos de tarefa em duas categorias: engajamento e satisfação. Dada a lista de candidatos vinda da etapa de recuperação, o sistema de ranqueamento usa recursos do candidato, do usuário e do contexto para aprender a prever as probabilidades correspondentes aos dois tipos de comportamento do usuário.
Um ponto importante dessa abordagem é que eles não aplicaram a camada MoE diretamente à entrada, pois a alta dimensionalidade resultaria em custos significativos de treinamento e de serving do modelo.
MoEs têm sido amplamente adotados na indústria em várias aplicações. Seu procedimento de aprendizado divide a tarefa em subtarefas apropriadas, cada uma resolvida por uma rede de expert muito simples. Isso permite treinamento paralelizável e inferência rápida, tornando MoEs muito atraentes para sistemas em larga escala.
Experts são especialmente úteis em cenários de alto throughput envolvendo muitas máquinas. Com um orçamento de computação fixo para pré-treinamento, um modelo esparso pode ser mais eficiente.
Por outro lado, modelos esparsos exigem muita memória na execução, já que todos os experts precisam estar carregados. Isso pode ser uma limitação significativa em sistemas com pouca VRAM.
Vamos ver outras limitações dos MoEs.
Treinar modelos MoE é mais complexo do que treinar um único modelo. Eis o porquê:
A inferência em modelos MoE pode ser menos eficiente por alguns fatores:
Modelos MoE tendem a ser maiores que modelos únicos por conta dos vários experts:
Neste artigo, exploramos a técnica Mixture of Experts (MoE), uma abordagem sofisticada para escalar redes neurais e lidar com tarefas complexas e dados diversos. O MoE usa múltiplos experts especializados e uma gating network para rotear entradas com eficácia.
Cobrimos os componentes centrais — redes de experts e gating network — e discutimos seus processos de treinamento e inferência.
Destacamos benefícios como desempenho, escalabilidade e adaptabilidade, além de aplicações em processamento de linguagem natural, visão computacional e sistemas de recomendação.
Apesar dos desafios de complexidade de treinamento e tamanho do modelo, o MoE é uma aposta promissora para avançar as capacidades da IA.
Aprenda IA com estes cursos!
Programa
Programa
Curso