
Cursus
Chercheur en apprentissage automatique en Python
85 h
Imagine an AI model as a team of specialists, each with their own unique expertise. A mixture of experts (MoE) model operates on this principle by dividing a complex task among smaller, specialized networks known as “experts.”
Each expert focuses on a specific aspect of the problem, enabling the model to address the task more efficiently and accurately. It’s similar to having a doctor for medical issues, a mechanic for car problems, and a chef for cooking—each expert handles what they do best.
By collaborating, these specialists can solve a broader range of problems more effectively than a single generalist.
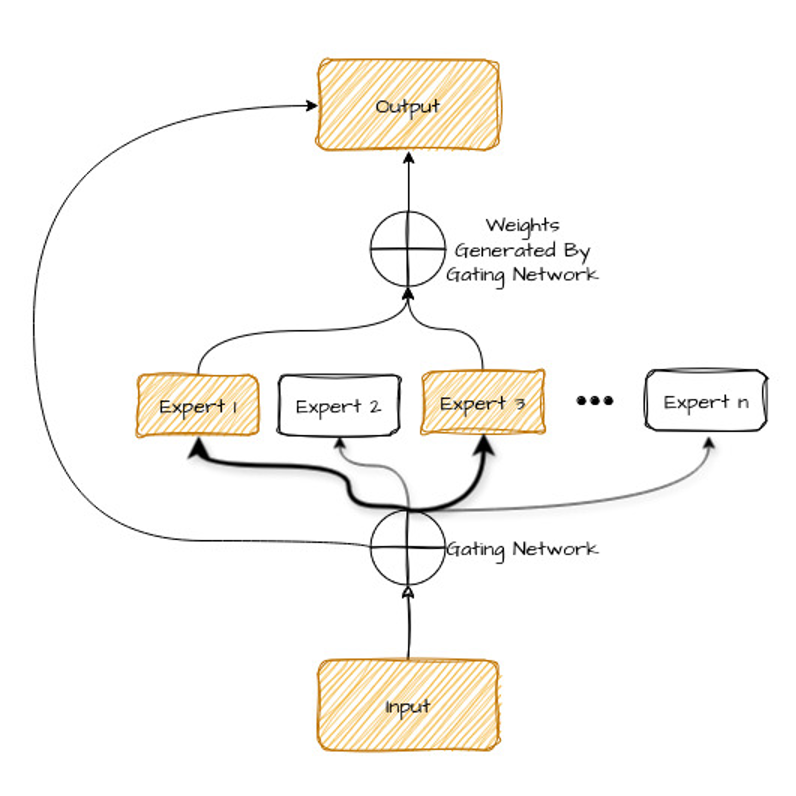
Let’s take a look at the diagram below—we’ll explain it shortly after.
Let’s break down the components of this diagram:
The advantages of using MoE are:
Let’s get into a little more detail with expert networks and gating networks.
Think of the "expert networks" in a MoE model as a team of specialists. Instead of having one AI model do everything, each expert focuses on a particular type of task or data.
In an MoE model, these experts are like individual neural networks, each trained on different datasets or tasks.
They are designed to be sparse meaning only a few are active at any given time, depending on the nature of the input. This prevents the system from being overwhelmed and ensures that the most relevant experts are working on the problem.
But how does the model know which experts to choose? That's where the gating network comes in.
The gating network (the router) is another type of neural network that learns to analyze the input data (like a sentence to be translated) and determine which experts are best suited to handle it.
It does this by assigning a "weight" or importance score to each expert based on the characteristics of the input. The experts with the highest weights are then selected to process the data.
There are various ways (called "routing algorithms") that the gating network can select the right experts. Here are a few common ones:
During the process of making predictions, the model combines the outputs from the experts, following the same process it used to assign tasks to the experts. For a single task, more than one expert might be needed, depending on how complex and varied the problem is.
Now, let's understand how an MoE works.
MoE operates in two stages:
Similar to other machine learning models, MoE begins by training on a dataset. However, the training process is not applied to the entire model but is instead conducted on its components individually.
Each component of an MoE framework undergoes training on a specific subset of data or tasks. The aim is to enable each component to focus on a particular aspect of the broader problem.
This focus is achieved by providing each component with data relevant to its assigned task. For instance, in a language processing task, one component might concentrate on syntax while another on semantics.
The training for each component follows a standard neural network training process, where the model learns to minimize the loss function for its specific data subset.
The gating network is tasked with learning to select the most suitable expert for a given input.
During the training of the gating network, is trained alongside the expert networks. It receives the same input as the experts and learns to predict a probability distribution over the experts. This distribution indicates which expert is best suited to handle the current input.
The gating network is typically trained using optimization methods that include both the accuracy of the gating network and the performance of the selected experts.
In the joint training phase, the entire MoE system, which includes both the expert models and the gating network, is trained together.
This strategy ensures that both the gating network and the experts are optimized to work in harmony. The loss function in joint training combines the losses from the individual experts and the gating network, encouraging a collaborative optimization approach.
The combined loss gradients are then propagated through both the gating network and the expert models, facilitating updates that improve the overall performance of the MoE system.
Inference involves generating outputs by combining context from gating networks with outputs from experts. In MoE, this process is designed to keep inference costs minimal.
In the context of MoE, the role of the gating network is pivotal in deciding which models should process a specific input.
Upon receiving an input, the gating network assesses it and creates a probability distribution across all the models. This distribution then directs the input to the most suitable models, leveraging the patterns learned during the training phase. This ensures that the right expertise is applied to each task, optimizing the decision-making process.
Only a select few models, usually one or a few, are chosen to process each input. This selection is determined by the probabilities assigned by the gating network.
Choosing a limited number of models for each input helps in the efficient use of computational resources while still benefiting from the specialized knowledge within the MoE framework.
The output from the gating network ensures that the chosen models are the most appropriate for handling the input, thereby improving the system's overall efficiency and performance.
The last step in the inference process involves merging the outputs from the selected models.
This merging is often achieved through weighted averaging, where the weights reflect the probabilities assigned by the gating network. In certain scenarios, alternative methods like voting or learned combination techniques might be employed to merge the expert outputs. The aim is to integrate the varied insights from the selected models into a unified and accurate final prediction, thereby leveraging the strengths of the MoE architecture.
With the rapid advancement of technology, there is an increasing need for fast, efficient, and optimized techniques to handle large models. MoE is emerging as a promising solution in this regard. What other benefits does MoE offer?
Mixture of Experts (MoE) architecture offers several advantages:
The fact that MoEs have been around for the last 30 years makes it a widely used technique in different areas of machine learning.
MoE offers a unique approach to training large models with improved efficiency, faster pre-training, and competitive inference speeds.
In traditional dense models, all parameters are used for all inputs. Sparsity, however, allows the model to run only specific parts of the system based on the input, significantly reducing computation.
One example is Microsoft’s translation API, Z-code. The MoE architecture in Z-code supports a massive scale of model parameters while keeping the amount of compute constant.
Google's V-MoEs, a sparse architecture based on Vision Transformers (ViT), showcase the effectiveness of MoE in computer vision tasks.
By partitioning images into smaller patches and feeding them to a gating/routing layer, V-MoEs can dynamically select the most appropriate experts for each patch, optimizing both accuracy and efficiency.
A notable advantage of this approach is its flexibility. You can decrease the number of selected experts per token to save time and compute, without any further training on the model weights.
MoE has also been successfully applied to recommendation systems. For example, Google researchers have proposed an MMoE (Multi-Gate Mixture of Experts) based ranking system for YouTube video recommendations.
They first group their task objective into two categories: engagement and satisfaction. Given the list of candidate videos from the retrieval step, their ranking system uses candidate, user, and context features to learn to predict the probabilities corresponding to the two categories of user behavior.
One thing to note in this approach is that they did not apply the MoE layer directly to the input because the high dimensionality of input would lead to significant model training and serving costs.
MoEs have seen a wide-scale adoption in the industry for several applications. Their learning procedure divides the task into appropriate subtasks, each of which can be solved by a very simple expert network. This capability translates to parallelizable training and fast inference, making MoEs lucrative for large-scale systems.
Experts are particularly beneficial for high-throughput scenarios involving many machines. Given a fixed compute budget for pretraining, a sparse model can be more efficient.
However, sparse models require substantial memory during execution, as all experts need to be stored in memory. This can be a significant limitation in systems with low VRAM, where such models may struggle.
Let’s explore other limitations of MoEs.
Training MoE models is more complex than training a single model. Here’s why:
Inference in MoE models can be less efficient due to a few factors:
MoE models tend to be larger than single models due to the multiple experts:
In this article, we explored the Mixture of Experts (MoE) technique, a sophisticated approach for scaling neural networks to handle complex tasks and diverse data. MoE uses multiple specialized experts and a gating network to route inputs effectively.
We covered the core components of MoE, including expert networks and the gating network, and discussed its training and inference processes.
Benefits such as improved performance, scalability, and adaptability were highlighted, along with applications in natural language processing, computer vision, and recommendation systems.
Despite challenges in training complexity and model size, MoE offers a promising method for advancing AI capabilities.
Learn AI with these courses!
Cursus
Cursus
Cours
blog
Bhavishya Pandit
7 min
blog
Richie Cotton
8 min
blog
Javier Canales Luna
10 min
blog
Natassha Selvaraj
15 min
Tutoriel
Zoumana Keita
Tutoriel
Bhavishya Pandit



