
programa
Científico especializado en machine learning en Python
85 h
Imagina un modelo de IA como un equipo de especialistas, cada uno con su propia pericia. Un modelo mixture of experts (MoE) opera con este principio dividiendo una tarea compleja entre redes más pequeñas y especializadas conocidas como «expertos».
Cada experto se centra en un aspecto concreto del problema, lo que permite abordar la tarea con más eficiencia y precisión. Es como tener a un médico para los temas de salud, a un mecánico para el coche y a un chef para la cocina: cada experto se ocupa de lo que mejor sabe hacer.
Al colaborar, estos especialistas pueden resolver un abanico más amplio de problemas con mayor eficacia que un único generalista.
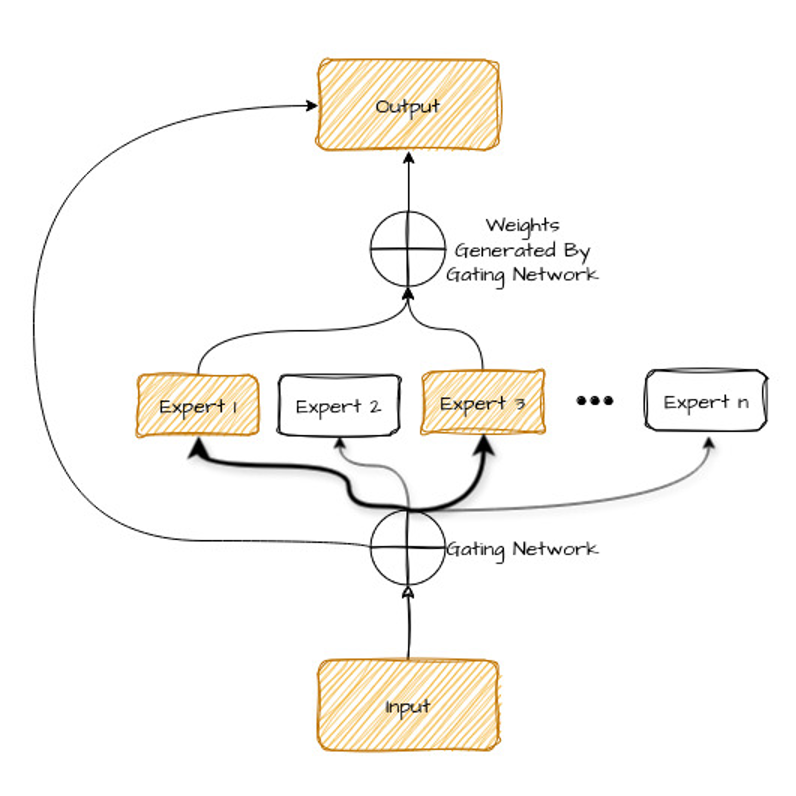
Echa un vistazo al diagrama de abajo: lo explicamos a continuación.
Desglosemos los componentes de este diagrama:
Las ventajas de usar MoE son:
Veamos con más detalle las redes de expertos y las redes de enrutamiento.
Piensa en las «redes de expertos» de un modelo MoE como en un equipo de especialistas. En lugar de que un único modelo de IA lo haga todo, cada experto se enfoca en un tipo de tarea o dato concreto.
En un modelo MoE, estos expertos son como redes neuronales individuales, entrenadas cada una con distintos conjuntos de datos o tareas.
Son dispersas, es decir, solo unas pocas están activas en cada momento, según la naturaleza de la entrada. Esto evita que el sistema se sature y garantiza que los expertos más relevantes trabajen en el problema.
Pero ¿cómo sabe el modelo qué expertos elegir? Ahí entra en juego la red de enrutamiento (gating).
La red de enrutamiento (el router) es otro tipo de red neuronal que aprende a analizar los datos de entrada (por ejemplo, una frase a traducir) y determinar qué expertos están mejor preparados para tratarlos.
Lo hace asignando un «peso» o puntuación de importancia a cada experto en función de las características de la entrada. Los expertos con mayor peso son los que se seleccionan para procesar los datos.
Existen varias formas (llamadas «algoritmos de enrutamiento») de seleccionar a los expertos adecuados. Algunas habituales son:
Durante la predicción, el modelo combina las salidas de los expertos siguiendo el mismo proceso usado para asignarles las tareas. Para una sola tarea pueden intervenir varios expertos, según lo compleja y diversa que sea.
Ahora, veamos cómo funciona un MoE.
MoE opera en dos fases:
Al igual que en otros modelos de aprendizaje automático, MoE comienza entrenándose con un conjunto de datos. Sin embargo, el entrenamiento no se aplica al modelo completo, sino a sus componentes por separado.
Cada componente del marco MoE se entrena con un subconjunto específico de datos o tareas. El objetivo es que cada componente se especialice en un aspecto concreto del problema global.
Esto se logra proporcionando a cada componente datos relevantes para su tarea asignada. Por ejemplo, en una tarea de procesamiento del lenguaje, un componente puede centrarse en la sintaxis y otro en la semántica.
El entrenamiento de cada componente sigue el proceso estándar de las redes neuronales, donde el modelo aprende a minimizar la función de pérdida para su subconjunto de datos.
La red de enrutamiento aprende a seleccionar el experto más adecuado para una entrada dada.
Durante su entrenamiento, se entrena junto con las redes de expertos. Recibe la misma entrada que los expertos y aprende a predecir una distribución de probabilidad sobre ellos. Esta distribución indica qué experto está mejor preparado para gestionar la entrada actual.
Suele entrenarse con métodos de optimización que tienen en cuenta tanto la precisión de la propia red de enrutamiento como el rendimiento de los expertos seleccionados.
En la fase conjunta, todo el sistema MoE, que incluye tanto los modelos expertos como la red de enrutamiento, se entrena a la vez.
Esta estrategia garantiza que la red de enrutamiento y los expertos se optimicen para trabajar en armonía. La función de pérdida conjunta combina las pérdidas de los expertos y de la red de enrutamiento, fomentando una optimización colaborativa.
Los gradientes de la pérdida combinada se propagan por la red de enrutamiento y por los modelos expertos, facilitando actualizaciones que mejoran el rendimiento global del sistema MoE.
La inferencia consiste en generar salidas combinando el contexto de las redes de enrutamiento con las salidas de los expertos. En MoE, este proceso está diseñado para mantener los costes de inferencia al mínimo.
En MoE, el papel de la red de enrutamiento es clave para decidir qué modelos deben procesar una entrada concreta.
Al recibir una entrada, la red de enrutamiento la evalúa y crea una distribución de probabilidad sobre todos los modelos. Esta distribución dirige la entrada a los modelos más adecuados, aprovechando los patrones aprendidos durante el entrenamiento. Así se aplica la pericia correcta a cada tarea, optimizando la toma de decisiones.
Solo se elige a unos pocos modelos, normalmente uno o varios, para procesar cada entrada. Esta elección la determinan las probabilidades asignadas por la red de enrutamiento.
Seleccionar un número limitado de modelos por entrada ayuda a usar los recursos de forma eficiente, sin perder las ventajas del conocimiento especializado del marco MoE.
La salida de la red de enrutamiento garantiza que los modelos elegidos sean los más adecuados para la entrada, mejorando así la eficiencia y el rendimiento del sistema.
El último paso de la inferencia consiste en fusionar las salidas de los modelos seleccionados.
Suele hacerse mediante un promedio ponderado, donde los pesos reflejan las probabilidades asignadas por la red de enrutamiento. En ciertos casos, pueden emplearse métodos alternativos como el voto o combinaciones aprendidas para unir las salidas de los expertos. El objetivo es integrar las aportaciones de los modelos seleccionados en una predicción final unificada y precisa, aprovechando así las fortalezas de la arquitectura MoE.
Con el avance acelerado de la tecnología, crece la necesidad de técnicas rápidas, eficientes y optimizadas para manejar modelos grandes. MoE se perfila como una solución prometedora. ¿Qué otros beneficios ofrece?
La arquitectura Mixture of Experts (MoE) ofrece varias ventajas:
Que los MoE lleven 30 años entre nosotros los convierte en una técnica muy extendida en distintas áreas del aprendizaje automático.
MoE ofrece una forma singular de entrenar modelos grandes con mayor eficiencia, preentrenamiento más rápido y velocidades de inferencia competitivas.
En los modelos densos tradicionales, todos los parámetros se usan para todas las entradas. La dispersión permite, en cambio, ejecutar solo partes específicas del sistema según la entrada, reduciendo drásticamente el cómputo.
Un ejemplo es la API de traducción de Microsoft, Z-code. La arquitectura MoE de Z-code admite una escala masiva de parámetros manteniendo constante el cómputo necesario.
Los V-MoE de Google, una arquitectura dispersa basada en Vision Transformers (ViT), demuestran la eficacia de MoE en tareas de visión.
Al dividir las imágenes en patches y pasarlos a una capa de enrutamiento, los V-MoE pueden seleccionar dinámicamente los expertos más adecuados para cada patch, optimizando precisión y eficiencia.
Una ventaja notable de este enfoque es su flexibilidad. Puedes reducir el número de expertos seleccionados por token para ahorrar tiempo y cómputo, sin reentrenar los pesos del modelo.
MoE también se ha aplicado con éxito a sistemas de recomendación. Por ejemplo, investigadores de Google propusieron un sistema de ranking basado en MMoE (Multi-Gate Mixture of Experts) para las recomendaciones de YouTube.
Primero agrupan su objetivo en dos categorías: interacción y satisfacción. Dada la lista de vídeos candidatos del paso de recuperación, su sistema de ranking usa características del candidato, del usuario y del contexto para aprender a predecir las probabilidades asociadas a ambos tipos de comportamiento.
Algo a tener en cuenta es que no aplicaron la capa MoE directamente a la entrada porque la alta dimensionalidad habría disparado los costes de entrenamiento y servicio del modelo.
Los MoE se han adoptado a gran escala en la industria para múltiples aplicaciones. Su procedimiento de aprendizaje divide la tarea en subtareas adecuadas, cada una de las cuales puede resolverse con una red experta muy simple. Esto permite entrenamiento en paralelo e inferencia rápida, lo que hace a los MoE muy atractivos para sistemas a gran escala.
Los expertos son especialmente útiles en escenarios de alto rendimiento con muchas máquinas. Dado un presupuesto de cómputo fijo para el preentrenamiento, un modelo disperso puede ser más eficiente.
Sin embargo, los modelos dispersos requieren mucha memoria en ejecución, ya que todos los expertos deben estar cargados. Esto puede ser una limitación importante en sistemas con poca VRAM, donde estos modelos pueden tener dificultades.
Veamos otras limitaciones de los MoE.
Entrenar modelos MoE es más complejo que entrenar un único modelo. He aquí por qué:
La inferencia en modelos MoE puede ser menos eficiente por varios motivos:
Los modelos MoE tienden a ser más grandes que los modelos únicos debido a los múltiples expertos:
En este artículo hemos explorado la técnica Mixture of Experts (MoE), un enfoque avanzado para escalar redes neuronales y abordar tareas complejas y datos diversos. MoE utiliza varios expertos especializados y una red de enrutamiento para dirigir eficazmente las entradas.
Hemos cubierto los componentes clave de MoE, incluidas las redes de expertos y la red de enrutamiento, y hemos comentado sus procesos de entrenamiento e inferencia.
También hemos destacado ventajas como el rendimiento, la escalabilidad y la adaptabilidad, junto con aplicaciones en procesamiento del lenguaje natural, visión por computador y sistemas de recomendación.
Pese a los desafíos en complejidad de entrenamiento y tamaño del modelo, MoE es un método prometedor para seguir ampliando las capacidades de la IA.
¡Aprende IA con estos cursos!
programa
programa
Curso
blog
Bhavishya Pandit
7 min
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
11 min
blog
Matt Crabtree
14 min
blog
Abid Ali Awan
15 min
blog
Zoumana Keita
14 min