
Leerpad
Wetenschapper op het gebied van machine learning in Python
85 Hr
Stel je een AI-model voor als een team van specialisten, elk met een eigen expertise. Een mixture of experts (MoE)-model werkt volgens dit principe door een complexe taak op te delen in kleinere, gespecialiseerde netwerken die “experts” worden genoemd.
Elke expert richt zich op een specifiek aspect van het probleem, waardoor het model de taak efficiënter en nauwkeuriger kan aanpakken. Het is vergelijkbaar met een arts voor medische kwesties, een monteur voor autoproblemen en een chef voor koken—elke expert doet waar hij of zij het beste in is.
Door samen te werken kunnen deze specialisten een breder scala aan problemen effectiever oplossen dan één generalist.
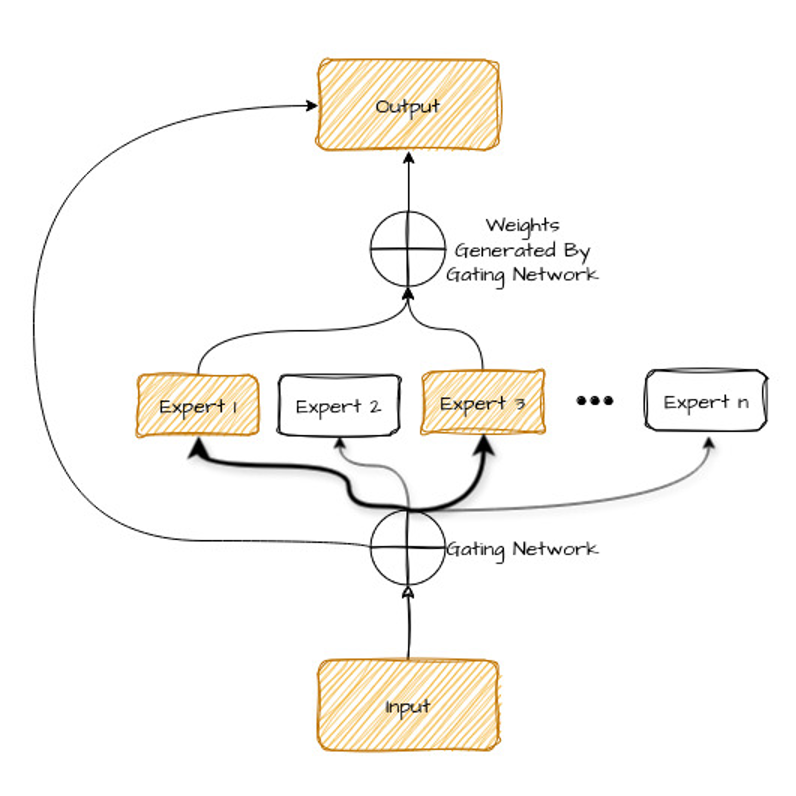
Kijk eens naar het diagram hieronder—we leggen het zo uit.
Laten we de componenten van dit diagram uiteenzetten:
De voordelen van MoE zijn:
Laten we iets dieper ingaan op expertnetwerken en gating-netwerken.
Zie de "expertnetwerken" in een MoE-model als een team van specialisten. In plaats van één AI-model dat alles doet, focust elke expert op een bepaald type taak of data.
In een MoE-model zijn deze experts als afzonderlijke neurale netwerken, elk getraind op verschillende datasets of taken.
Ze zijn ontworpen om schaars te zijn: slechts enkele zijn op een willekeurig moment actief, afhankelijk van de aard van de input. Dit voorkomt dat het systeem overbelast raakt en zorgt dat de meest relevante experts aan het probleem werken.
Maar hoe weet het model welke experts het moet kiezen? Daar komt het gating-netwerk om de hoek kijken.
Het gating-netwerk (de router) is een ander type neuraal netwerk dat leert de inputdata te analyseren (zoals een zin om te vertalen) en te bepalen welke experts daar het best bij passen.
Het doet dit door een "gewicht" of belangrijkheidsscore aan elke expert toe te kennen op basis van de kenmerken van de input. De experts met de hoogste gewichten worden vervolgens geselecteerd om de data te verwerken.
Er zijn verschillende manieren ("routing-algoritmen") waarop het gating-netwerk de juiste experts kan selecteren. Enkele gangbare zijn:
Tijdens de voorspellingsfase combineert het model de outputs van de experts, volgens hetzelfde proces waarmee het taken aan de experts toekende. Voor één taak kunnen meerdere experts nodig zijn, afhankelijk van hoe complex en gevarieerd het probleem is.
Laten we nu begrijpen hoe een MoE werkt.
MoE werkt in twee fasen:
Net als bij andere machinelearningmodellen begint MoE met trainen op een dataset. De training wordt echter niet op het hele model toegepast, maar afzonderlijk op de componenten uitgevoerd.
Elke component van een MoE-raamwerk wordt getraind op een specifieke subset van data of taken. Het doel is dat elke component zich richt op een bepaald aspect van het bredere probleem.
Die focus wordt bereikt door elke component data te geven die relevant is voor zijn toegewezen taak. Bij een taalverwerkingstaak kan één component zich bijvoorbeeld op syntaxis richten en een andere op semantiek.
De training van elke component volgt een standaard trainingsproces voor neurale netwerken, waarbij het model leert de verliesfunctie voor zijn specifieke datasubset te minimaliseren.
Het gating-netwerk heeft als taak te leren de meest geschikte expert voor een gegeven input te selecteren.
Tijdens de training van het gating-netwerk wordt het samen met de expertnetwerken getraind. Het ontvangt dezelfde input als de experts en leert een kansverdeling over de experts te voorspellen. Deze verdeling geeft aan welke expert het best geschikt is voor de huidige input.
Het gating-netwerk wordt doorgaans getraind met optimalisatiemethoden die zowel de nauwkeurigheid van het gating-netwerk als de prestaties van de geselecteerde experts meenemen.
In de fase van gezamenlijke training wordt het hele MoE-systeem, dus zowel de expertmodellen als het gating-netwerk, samen getraind.
Deze strategie zorgt ervoor dat het gating-netwerk en de experts optimaal in harmonie werken. De verliesfunctie in gezamenlijke training combineert de verliezen van de individuele experts en het gating-netwerk, wat een collaboratieve optimalisatieaanpak stimuleert.
De gecombineerde verliesgradiënten worden vervolgens door zowel het gating-netwerk als de expertmodellen teruggepropageerd, zodat updates de algehele prestaties van het MoE-systeem verbeteren.
Inferentie houdt in dat outputs worden gegenereerd door context uit gating-netwerken te combineren met outputs van experts. In MoE is dit proces zo ontworpen dat de kosten van inferentie minimaal blijven.
Binnen de context van MoE is de rol van het gating-netwerk cruciaal bij het bepalen welke modellen een specifieke input moeten verwerken.
Na het ontvangen van een input beoordeelt het gating-netwerk deze en maakt het een kansverdeling over alle modellen. Deze verdeling stuurt de input vervolgens naar de meest geschikte modellen, op basis van de patronen die tijdens de training zijn geleerd. Dit zorgt ervoor dat voor elke taak de juiste expertise wordt ingezet, wat de besluitvorming optimaliseert.
Slechts een select aantal modellen, meestal één of enkele, wordt gekozen om elke input te verwerken. Deze selectie wordt bepaald door de door het gating-netwerk toegekende waarschijnlijkheden.
Het kiezen van een beperkt aantal modellen per input helpt om rekenbronnen efficiënt te gebruiken en toch te profiteren van de gespecialiseerde kennis binnen het MoE-raamwerk.
De output van het gating-netwerk zorgt ervoor dat de gekozen modellen het meest geschikt zijn voor de input, waardoor de algehele efficiëntie en prestaties verbeteren.
De laatste stap in het inferentieproces is het samenvoegen van de outputs van de geselecteerde modellen.
Dit samenvoegen gebeurt vaak via gewogen middelen, waarbij de gewichten de waarschijnlijkheden van het gating-netwerk weerspiegelen. In sommige situaties kunnen alternatieve methoden zoals stemmen of geleerde combinatietechnieken worden gebruikt om de expertoutputs te combineren. Het doel is om de uiteenlopende inzichten van de geselecteerde modellen te integreren tot één eenduidige en nauwkeurige eindvoorspelling, en zo de sterke punten van de MoE-architectuur te benutten.
Met de snelle technologische vooruitgang groeit de behoefte aan snelle, efficiënte en geoptimaliseerde technieken om grote modellen te verwerken. MoE komt hierbij naar voren als een veelbelovende oplossing. Welke andere voordelen biedt MoE?
De Mixture of Experts (MoE)-architectuur biedt verschillende voordelen:
Het feit dat MoE's al 30 jaar bestaan, maakt het tot een veelgebruikte techniek in verschillende domeinen van de machine learning.
MoE biedt een unieke aanpak om grote modellen te trainen met verbeterde efficiëntie, snellere pretraining en concurrerende inferentiesnelheden.
In traditionele dichte modellen worden alle parameters voor alle inputs gebruikt. Schaarsheid maakt het daarentegen mogelijk om alleen specifieke delen van het systeem te draaien op basis van de input, wat de benodigde berekeningen aanzienlijk vermindert.
Een voorbeeld is Microsofts vertaal-API, Z-code. De MoE-architectuur in Z-code ondersteunt een enorme schaal aan modelparameters terwijl de benodigde rekenkracht constant blijft.
Google's V-MoE's, een schaarse architectuur gebaseerd op Vision Transformers (ViT), tonen de effectiviteit van MoE bij computervisie-taken aan.
Door afbeeldingen op te delen in kleinere patches en die aan een gating-/routeringslaag aan te bieden, kunnen V-MoE's dynamisch de meest geschikte experts per patch selecteren, wat zowel nauwkeurigheid als efficiëntie optimaliseert.
Een belangrijk voordeel van deze aanpak is de flexibiliteit. Je kunt het aantal geselecteerde experts per token verlagen om tijd en rekenkracht te besparen, zonder de modelgewichten verder te hoeven trainen.
MoE is ook met succes toegepast op aanbevelingssystemen. Zo hebben Google-onderzoekers een MMoE (Multi-Gate Mixture of Experts)-gebaseerd rankingsysteem voorgesteld voor YouTube-videorecommendaties.
Ze delen hun taakdoel eerst op in twee categorieën: engagement en tevredenheid. Gegeven de lijst met kandidaatvideo's uit de retrievalstap, gebruikt hun rankingsysteem kandidaat-, gebruikers- en contextkenmerken om de kansen te leren voorspellen die overeenkomen met de twee categorieën gebruikersgedrag.
Belangrijk om te noemen is dat zij de MoE-laag niet direct op de input toepasten, omdat de hoge dimensionaliteit van de input zou leiden tot aanzienlijke kosten voor modeltraining en -serving.
MoE's zijn op grote schaal geïmplementeerd in de industrie voor verschillende toepassingen. Hun leerprocedure verdeelt de taak in passende deeltaken, die elk door een heel eenvoudig expertnetwerk kunnen worden opgelost. Deze mogelijkheid leidt tot paralleliseerbare training en snelle inferentie, wat MoE's aantrekkelijk maakt voor grootschalige systemen.
Experts zijn vooral voordelig voor high-throughput-scenario's waarbij veel machines betrokken zijn. Gegeven een vaste rekencap voor pretraining kan een schaars model efficiënter zijn.
Schattingen vereisen echter veel geheugen tijdens de uitvoering, omdat alle experts in het geheugen moeten worden opgeslagen. Dit kan een aanzienlijke beperking zijn in systemen met weinig VRAM, waar dergelijke modellen kunnen worstelen.
Laten we andere beperkingen van MoE's verkennen.
Het trainen van MoE-modellen is complexer dan het trainen van één enkel model. Dit is waarom:
Inferentie in MoE-modellen kan minder efficiënt zijn door een paar factoren:
MoE-modellen zijn doorgaans groter dan enkele modellen vanwege de meerdere experts:
In dit artikel verkenden we de Mixture of Experts (MoE)-techniek, een geavanceerde aanpak om neurale netwerken op te schalen voor complexe taken en diverse data. MoE gebruikt meerdere gespecialiseerde experts en een gating-netwerk om inputs effectief te routeren.
We behandelden de kernelementen van MoE, waaronder expertnetwerken en het gating-netwerk, en bespraken de trainings- en inferentieprocessen.
Voordelen zoals betere prestaties, schaalbaarheid en aanpasbaarheid kwamen aan bod, evenals toepassingen in natural language processing, computervisie en aanbevelingssystemen.
Ondanks uitdagingen rond trainingscomplexiteit en modelomvang biedt MoE een veelbelovende manier om AI-capaciteiten verder te brengen.
Leer AI met deze cursussen!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
