
Kurs
Python ile İstatistik Mülakat Soruları Pratiği
4 sa
16.6K
Arkasındaki kavramları anlamadan veri analitiği araçlarına hâkim olmak, farklı tornavidalarla dolu bir alet çantasına sahip olup her birini ne zaman ve nasıl kullanacağınızı bilmemek gibidir. İstatistik öğrenmek önemlidir; çünkü yapay zekâ tarafından üretilen ve yapay zekâ destekli analiz araçlarının yükselişi, teknik becerileri rekabet üstünlüğü olmaktan çıkarıp bilgi kavrayışı ve eleştirel anlayışı öne çıkaracaktır.
İstatistiğin karmaşıklığından gözünüzün korkmamasını rica ediyorum. Bu makale, veri analistleri ve veri bilimcileri için en ilgili istatistiksel kavramları 35 istatistik mülakat sorusu ve cevabı üzerinden kapsamlı bir rehber olarak sunmayı amaçlıyor. Bir mülakata hazırlanıyor olun ya da olmayın, bu soruları bilgilendirici bulacağınıza eminim.
Son olarak, başlamadan önce temel konuları öğrenmek, istatistiksel analizler yapmayı ve sonuçları yorumlamayı öğrenmek için R ile İstatistiğe Giriş kursumuzu almayı düşünün. Ayrıca, istatistiksel bilgi gerektiren bir mülakata aktif olarak hazırlanıyorsanız, aşağıdaki iki DataCamp kursu en sık ele alınan istatistik konularının tümünü kapsar: Python ile İstatistik Mülakat Soruları Pratiği ve R ile İstatistik Mülakat Soruları Pratiği.
Veri analitiği işlerinin çoğu, hatta tamamı, betimsel istatistik, çıkarımsal istatistik ve olasılık dahil olmak üzere istatistiğin temel düzeyde anlaşılmasını gerektirir. Bir mülakat öncesinde betimsel istatistik bilginizi tazeliyorsanız, kolay başvuru için Betimsel İstatistik El Kartımızı indirin. Ayrıca bazı hesaplamalar ve yöntemler üzerinde çalışmak istiyorsanız, ilgili kavramları daha ayrıntılı ele almak için aşağıdaki DataCamp eğitimlerine göz atın:
Varyans ve standart sapma, bir veri setinin yayılımını veya saçılmasını ölçer. Varyans, her bir değerin ortalamadan farkının karesinin ortalamasıdır. Veri setindeki değerlerin ortalamadan ne kadar saptığına dair bir fikir verir. Ancak kare farklar kullanıldığı için birimi de karelenir; bu da standart sapmaya göre daha az sezgiseldir. Standart sapma, varyansın kareköküdür ve birimi verinin özgün birimine geri getirir. Yayılımın daha yorumlanabilir bir ölçüsünü sunar. Örneğin bir veri setinin varyansı 25 ise, standart sapma √25 = 5’tir.
Çarpıklık, bir veri setinin ortalaması etrafındaki asimetrisini ölçer; pozitif, negatif veya sıfır olabilir. Pozitif çarpıklığa sahip, yani sağa çarpık veride sağ kuyruk daha uzundur; bu da ortalamanın medyandan büyük olduğu anlamına gelir. Negatif çarpıklığa sahip, yani sola çarpık veride sol kuyruk daha uzundur; bu da ortalamanın medyandan küçük olduğu anlamına gelir. Sıfır çarpıklık, ortalama, medyan ve modun eşit olduğu normal dağılım gibi simetrik bir dağılıma işaret eder.
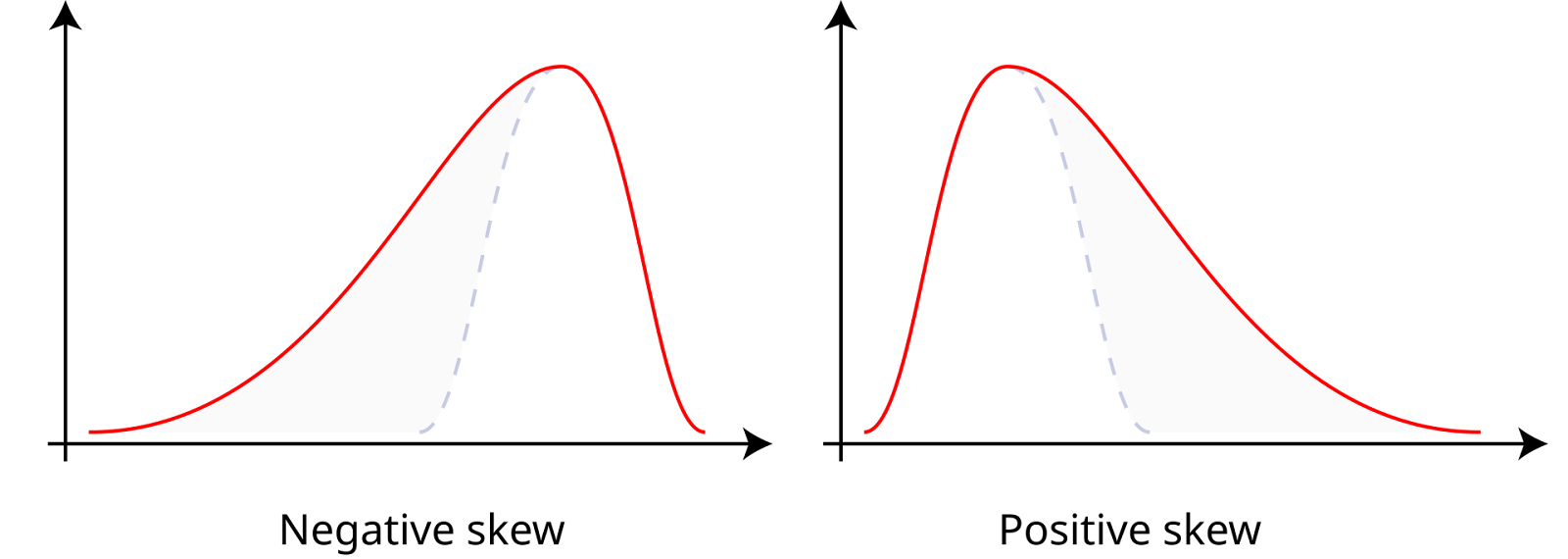
Pozitif ve negatif çarpıklık. Kaynak: Wikiversity.
Histogram, bir veri setinin dağılımının görsel bir temsilidir. Veriyi sınıflara (aralıklara) böler ve her sınıftaki veri noktalarının sıklığını (veya sayısını) gösterir. Sürekli verilerin altta yatan frekans dağılımını (şeklini) anlamak için kullanılır. Çarpıklık, çok tepelilik (tepe sayısı) ve aykırı değerlerin varlığı gibi desenleri belirlemeye yardımcı olur.
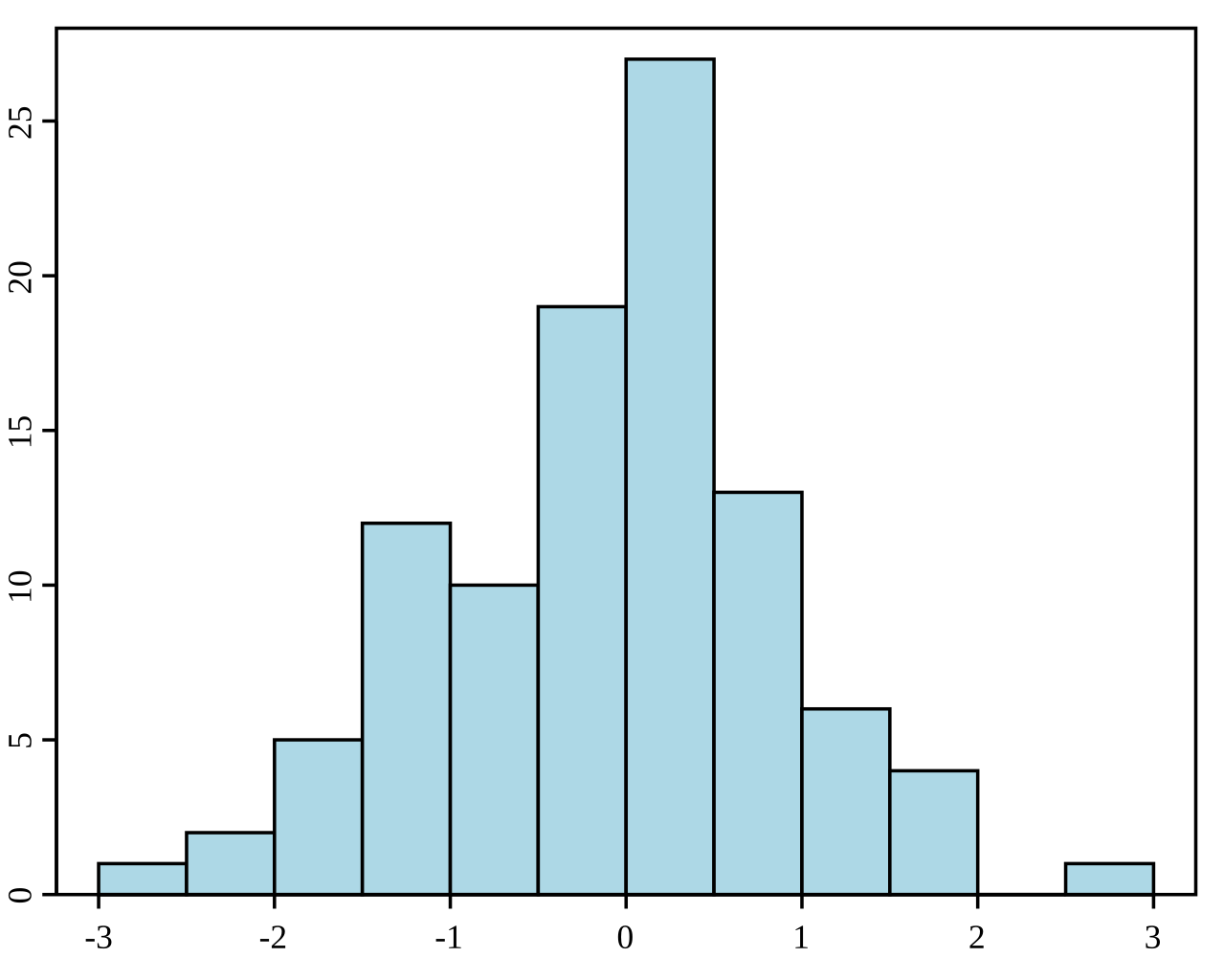
Bir histogram örneği. Kaynak: Vikipedi.
Çıkarımsal istatistik, bir popülasyondan rastgele alınan bir örneğe dayanarak popülasyon hakkında tahminler veya çıkarımlar yapmayı içerir. Popülasyon parametrelerini tahmin etmek, hipotezleri test etmek ve tahminlerde bulunmak için çeşitli yöntemler kullanır. Betimsel istatistik bir veri setinin özelliklerini özetler ve açıklar; çıkarımsal istatistik ise bu verileri kullanarak daha geniş bir popülasyon hakkında genelleme yapar ve sonuç çıkarır.
Örneklerin temsili ve rastgele olmasını sağlamak için farklı örnekleme yöntemleri kullanılır. Basit rastgele örnekleme, popülasyondaki her birime seçilme açısından eşit şans verir. Sistematik örnekleme, rastgele seçilen bir başlangıç noktasından başlayarak her k’inci birimin seçilmesini içerir. Katmanlı örnekleme, popülasyonu katmanlara veya alt gruplara ayırır ve her katmandan rastgele örnekler alır. Küme örneklemesi, popülasyonu kümelere ayırır; bazı kümeler rastgele seçilir ve bu kümelerin tüm üyeleri örneklenir.
Merkezi limit teoremi, örneklem ortalamasının örnekleme dağılımının, örneklem büyüklüğü arttıkça, popülasyonun dağılımından bağımsız olarak normal dağılıma yaklaşacağını söyler; yeter ki örnekler birbirinden bağımsız ve özdeş dağılımlı olsun.
Marjinal olasılık, diğer olaylardan bağımsız olarak tek bir olayın gerçekleşme olasılığıdır ve A olayı için P(A) ile gösterilir. Birleşik olasılık, iki olayın birlikte gerçekleşme olasılığıdır ve A ve B olayları için P(A∩B) ile gösterilir. Koşullu olasılık, bir olayın, başka bir olayın gerçekleştiği bilindiğinde gerçekleşme olasılığıdır ve P(A|B) şeklinde ifade edilir.
Olasılık dağılımı, bir rassal değişkenin değerlerinin nasıl dağıldığını açıklar. Rassal değişkenin sonuçlarını karşılık gelen olasılıklarına eşleyen bir fonksiyon sunar. İki ana tür olasılık dağılımı vardır. Biri, ikili ya da Poisson dağılımı gibi ayrık rassal değişkenler için ayrık olasılık dağılımıdır. Diğeri, normal ya da üstel dağılım gibi sürekli rassal değişkenler için sürekli olasılık dağılımıdır.
Normal dağılım, Gauss dağılımı olarak da bilinir; ortalama etrafında simetrik, çan şeklinde bir eğriyle karakterize edilen sürekli bir olasılık dağılımıdır. Normal dağılımlarda ortalama medyana eşittir. Ayrıca verilerin yaklaşık %68’inin ortalamanın bir standart sapması içinde, %95’inin iki standart sapması içinde ve %99,7’sinin üç standart sapması içinde yer aldığı bilinir. Buna 68-95-99,7 Kuralı denir.
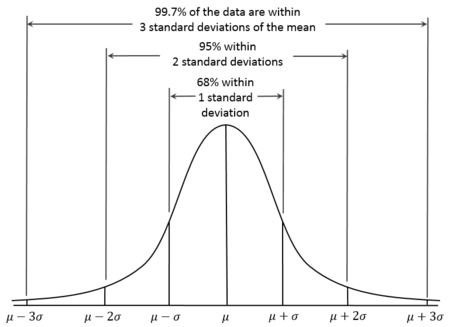
Normal dağılım eğrisi. Kaynak: Wikiversity.
Binom dağılımı, her bir denemenin başarı olasılığı aynı olan sabit sayıda bağımsız Bernoulli denemesinde elde edilen başarı sayısını modelleyen ayrık bir olasılık dağılımıdır. Her deneme için tam olarak iki olası sonuç (başarı ve başarısızlık) olduğunda kullanılır. Örneğin, bir dizi yazı-tura atışında gelen tura sayısını modellemek için kullanılabilir.
Poisson dağılımı, olayların bağımsız ve sabit ortalama hızla gerçekleştiği, sabit bir zaman veya mekân aralığında meydana gelen olay sayısını modelleyen ayrık bir olasılık dağılımıdır. Saatte alınan e-posta sayısı veya bir yıldaki deprem sayısı gibi nadir olay sayılarını modellemek istediğinizde uygundur.
Orta düzey istatistik rollerinde hipotez testi, aralık tahmini ve regresyon modellemesine odaklanın. Bu soruları okurken bazı kavramlarda kendinizi güvensiz hissederseniz, DataCamp kaynaklarına başvurabilirsiniz. Hipotez testini Python ile Hipotez Testi ve R ile Hipotez Testi kurslarıyla öğrenebilirsiniz. Ayrıca aşağıdaki kurs ve eğitimlerle regresyon tekniklerinde ustalaşabilirsiniz:
p-değeri, sıfır hipotezinin doğru olduğu varsayımı altında, gözlemlenen kadar veya ondan daha uç bir test istatistiği elde etme olasılığıdır. Hipotez testinde test sonucunun anlamlılığını belirlemek için kullanılır. p-değeri seçilen anlamlılık düzeyinden (α) küçük veya ona eşitse sıfır hipotezini reddederiz. p-değeri α’dan büyükse sıfır hipotezini reddedemeyiz.
Hipotez testinde Tip I hata, sıfır hipotezi doğruyken onu yanlışlıkla reddettiğimizde meydana gelir; bu, yanlış pozitif sonuçtur. Tip I hata olasılığı, anlamlılık düzeyi ile aynıdır. Tip II hata ise sıfır hipotezi yanlışken onu reddedemediğimizde ortaya çıkar; bu da yanlış negatif sonuçtur.
Parametrik testler, verinin normal gibi belirli bir dağılımı izlediğini varsayar ve bazı popülasyon parametrelerini gerektirir; bu varsayımlar sağlandığında idealdir. Sıklıkla kullandığım parametrik testlere örnek olarak t-testi, Z-testi ve ANOVA verilebilir. Parametrik olmayan testler belirli bir dağılım varsaymaz ve özellikle küçük örneklemlerde veriler parametrik varsayımları karşılamadığında kullanılır. Birçok kişi bu testlere aşinadır ama onları mutlaka parametrik olmayan olarak adlandırmaz. Örnek olarak Ki-kare testi, Mann-Whitney U testi, Wilcoxon İşaretli Sıra Testi ve Kruskal-Wallis testini kullandım.
Regresyon analizi, bir bağımlı değişken ile bir veya daha fazla bağımsız değişken arasındaki ilişkiyi incelemek için kullanılan istatistiksel bir yöntemdir. Diğer bağımsız değişkenler sabit tutulurken, bağımsız değişkenlerden herhangi birindeki bir birimlik değişimle bağımlı değişkenin nasıl değiştiğini anlamaya yardımcı olur.
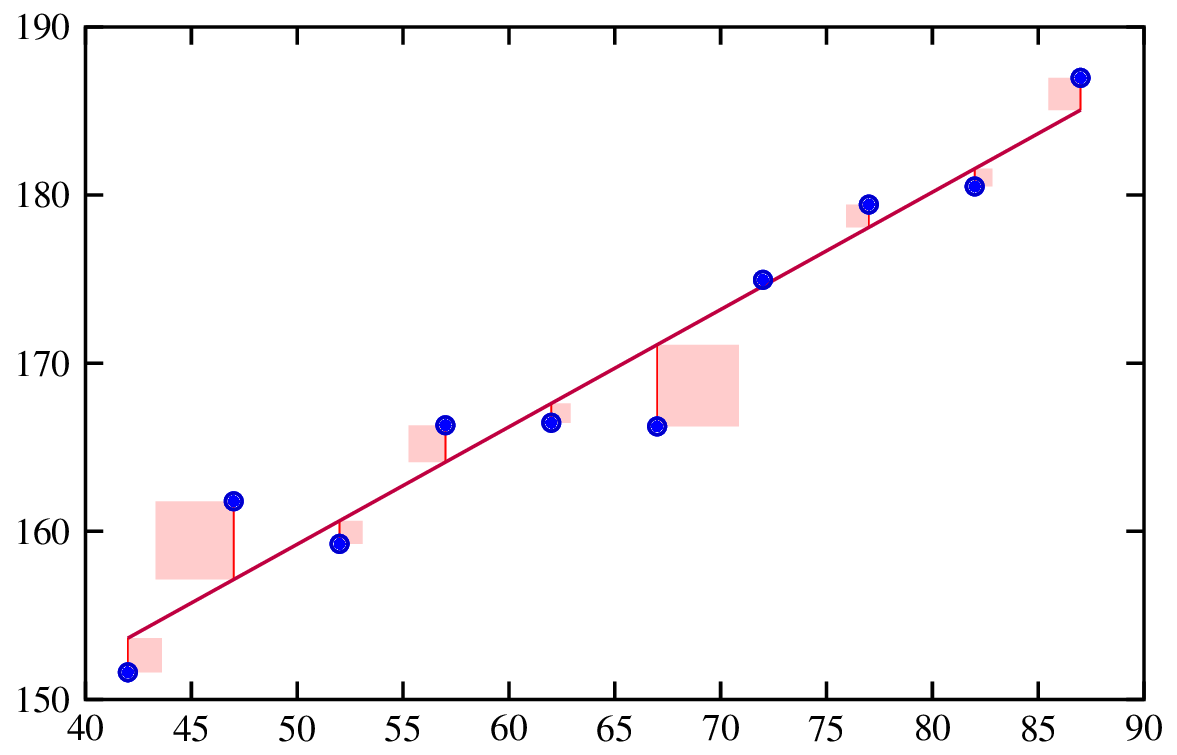
Bir regresyon doğrusunun uydurulması. Kaynak: Risk Engineering.
Artıklar, gözlemlenen değerlerle regresyon modelinin tahmin ettiği değerler arasındaki farklardır. Artıkları analiz etmek, model varsayımlarını ve modelin genel uyumunu kontrol etmeye yardımcı olduğu için önemlidir.
Doğrusal regresyon modelinde her bir katsayı, diğer tüm değişkenler sabitken, ilgili bağımsız değişkendeki bir birimlik artış için bağımlı değişkende beklenen değişimi temsil eder. Örneğin, bağımsız bir değişken 𝑥𝑖’nin katsayısı 2 ise, 𝑥𝑖’deki her bir birimlik artış için bağımlı değişken y’nin 2 birim artması beklenir; diğer değişkenlerin değişmediği varsayılır.
%95 güven aralığı, çok sayıda örnek alıp her örnek için bir güven aralığı hesaplasaydık, bu aralıkların yaklaşık %95’inin gerçek popülasyon parametresini içereceği anlamına gelir. Ayrıca, parametre değerinin tahmin edilen aralıkta yer aldığı konusunda %95 güvende olduğumuzu da söyleyebiliriz.
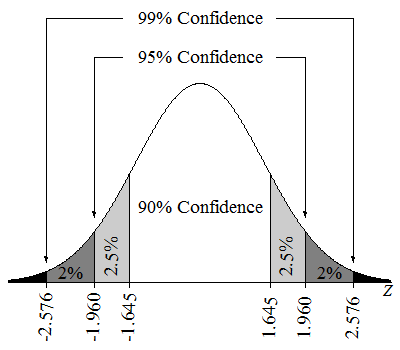
Z-dağılımı üzerinde güven aralıkları. Kaynak: Lumen Learning.
Çoklu doğrusal bağlantı, çoklu regresyon modelindeki iki veya daha fazla bağımsız değişken yüksek derecede ilişkili olduğunda ortaya çıkar. Bu durum, katsayı tahminlerini dengesiz ve yorumlanması güç hâle getirebileceği için sorunludur. Yüksek çoklu doğrusal bağlantı, katsayıların standart hatalarını da şişirerek istatistiksel testlerin güvenilirliğini azaltabilir.
Düzenlileştirme teknikleri, regresyon modellerinde çoklu doğrusal bağlantıyı ele almak için güçlü yöntemlerdir. Ayrıca, büyük katsayılara ceza ekleyerek aşırı uyumu (overfitting) önlemek için kullanılırlar. Bu, daha genellenebilir bir model oluşturulmasına yardımcı olur. Yaygın düzenlileştirme tekniklerine Lasso ve Ridge Regresyonu örnek verilebilir.
İstatistikte ileri düzey bir anlayış gerektiren bir mülakata hazırlanıyor olsam, Bayesçi istatistik ve makine öğrenmesini mutlaka çalışırdım.
Bayesçi istatistik için şu kurslarımızı keşfedin: Python ile Bayesçi Veri Analizi ve R ile Bayesçi Veri Analizinin Temelleri. Makine öğrenmesi için DataCamp kariyer yollarına veya kurslarına göz atın; örneğin Python ile Makine Öğrenmesi Bilimcisi kariyer yolu ve Makine Öğrenmesini Anlamak kursu.
Bayesçi istatistik, bir hipotezin olasılığını, yeni kanıt veya bilgi geldikçe güncellemek için Bayes teoreminden yararlanır. Önsel inançları yeni verilerle birleştirerek sonsal olasılığı oluşturur.
Markov Zinciri Monte Carlo, doğrudan örneklemenin zor olduğu durumlarda bir olasılık dağılımından örnekleme yapmak için kullanılan algoritmalar sınıfıdır. Bayesçi istatistikte önemlidir; çünkü özellikle analitik çözümlerin mümkün olmadığı karmaşık modellerde sonsal dağılımların tahmin edilmesine imkân tanır.
Makine öğrenmesinde sapma-varyans dengesi, iki hata kaynağı arasında denge kurmayı içerir. Sapma, aşırı basitleştirici model varsayımlarından kaynaklanan hatadır; yetersiz uyuma ve veri desenlerinin kaçırılmasına yol açar. Varyans ise eğitime aşırı duyarlılıktan kaynaklanan hatadır; aşırı uyuma ve gerçek desenler yerine gürültünün yakalanmasına neden olur.
Nedensel çıkarım, çokça ilgi gören önemli bir fikirdir. Bir değişkenin (neden) diğer bir değişkeni (sonuç) doğrudan etkileyip etkilemediğini ve nasıl etkilediğini belirleme sürecidir; bu yönüyle sadece korelasyondan ayrılır. Nedensel çıkarım, bir müdahale veya tedavi gibi bir şeyin işe yarayıp yaramadığını anlamak için nedensellik ilişkisi kurmayı amaçlayan yöntemler bütünüdür. Örneğin bir araştırmacı bir ilacın işe yarayıp yaramadığını anlamak istiyorsa, nedensel çıkarım bu soruyu yanıtlamaya yardımcı olabilir.
Yapısal Eşitlik Modellemesi, gözlenen ve örtük (gizil) değişkenler arasındaki ilişkileri analiz etmeye yönelik bir tekniktir. Çoklu regresyon ile faktör analizinin bir karışımı gibidir. Yapısal eşitlik modellemesi; model tanımlama, tahmin ve değerlendirme gibi çoklu adımlar gerektirir. SEM esnekliğiyle bilinir; ancak büyük örneklemler ister ve kullanılabilmesi için güçlü bir kuramsal temel gereklidir.
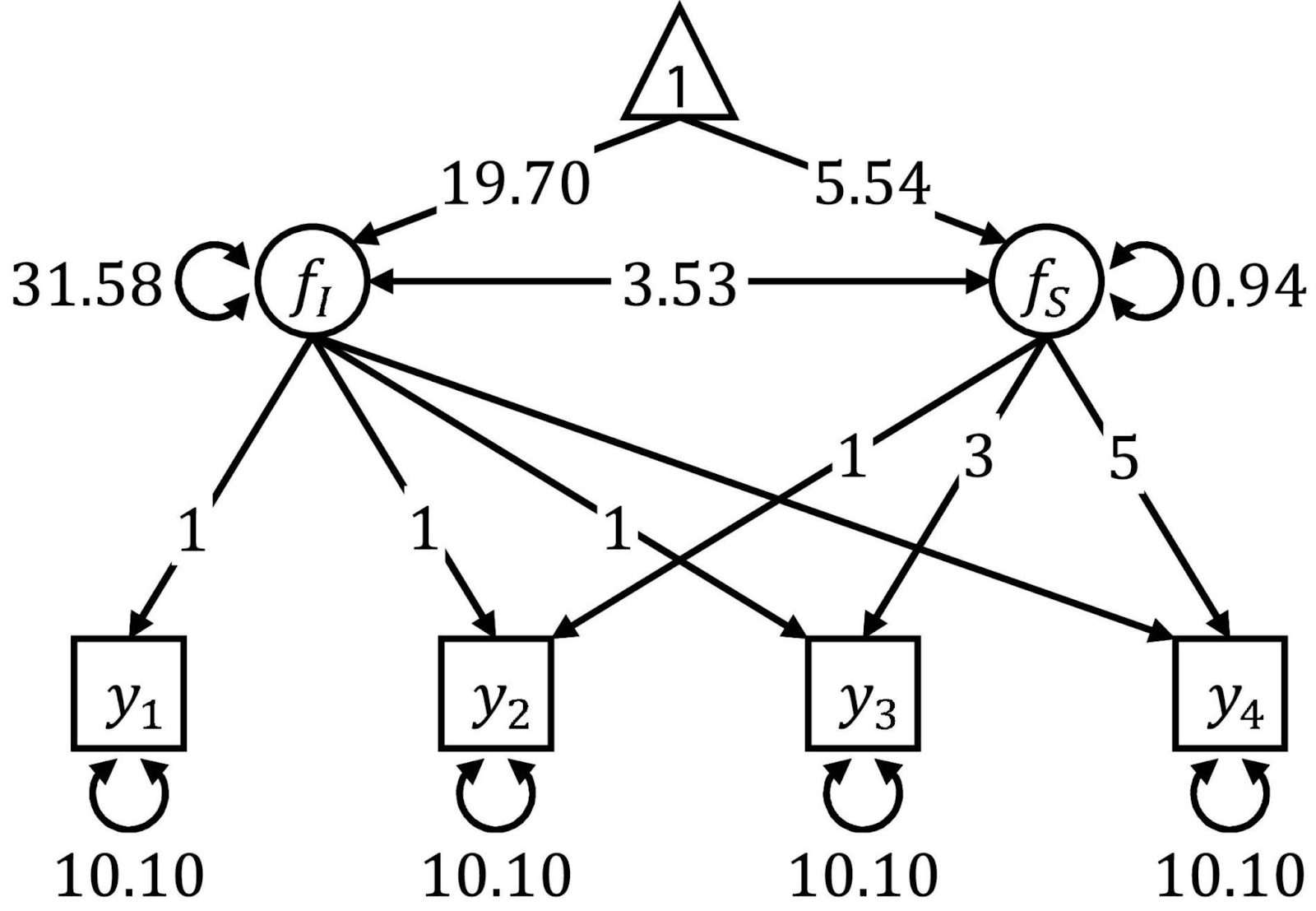
SEM’i görselleştirmek için sıklıkla yol diyagramları kullanılır. Kaynak: Frontiers.
Daha çok veri bilimi ile istatistiğin kesişimine odaklanan bir rol hedefliyorsanız aşağıdaki sorular faydalı olacaktır. Konular arasında veri önişleme ve temizleme, A/B testi ve deney tasarımı, zaman serisi tahmini ve ileri istatistik teknikleri yer alır.
Bu kavramlarda kendinizi zayıf hissediyor ve mülakat performansınızı ciddi şekilde geliştirmek istiyorsanız, A/B testi için şu DataCamp kaynaklarını alın: Python ile A/B Testi kursu veya R ile A/B Testi kursu. Ardından zaman serisi analizinde ustalaşmak için deneyim kazanmak adına R ile Zaman Serileri veya Python ile Zaman Serileri beceri yollarından birini seçin.
Veriyi eğitim ve test kümelerine ayırmak, modelin görülmemiş veriler üzerindeki performansını değerlendirmemize yardımcı olur. Eğitim kümesi modeli eğitmek için, test kümesi ise modelin yeni verilere ne kadar iyi genellenebildiğini değerlendirmek için kullanılır. Bu uygulama, aşırı uyumu tespit etmeye ve modelin gerçek dünyadaki verilerde iyi performans göstermesini sağlamaya yardımcı olur.
Aşırı uyum, bir modelin eğitim verilerindeki temel desenlerin yanı sıra gürültüyü de öğrenmesiyle oluşur; bu durumda eğitim verisinde mükemmele yakın, yeni veride ise zayıf performans görülür. Yetersiz uyum ise modelin verideki temel desenleri yakalayamayacak kadar basit olmasıyla oluşur; hem eğitim verisinde hem de yeni veride zayıf performansa yol açar.
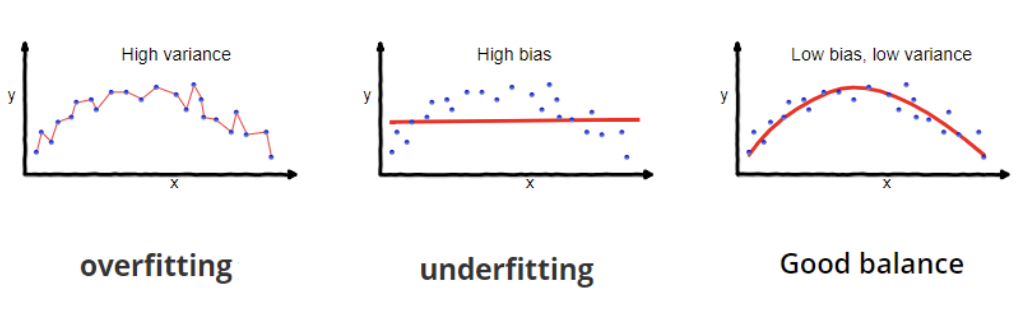
Aşırı uyum ve yetersiz uyum. Kaynak: Vikipedi.
Eksiklik mekanizmasını (MCAR, MAR, MNAR) anlamak kritik önemdedir; çünkü kayıp veriyi ele almak için uygun yöntemlerin seçimini yönlendirir. Uygun olmayan teknikler önyargı katabilir, sonuçların geçerliliğini düşürebilir ve yanlış çıkarımlara yol açabilir. Örneğin, basit atama yöntemleri MCAR veri için uygun olabilirken, MAR veya MNAR veri için önyargısız tahminler üretebilmek adına çoklu atama veya modele dayalı yöntemler gibi daha sofistike tekniklere ihtiyaç duyulabilir.
Eksik verinin oranı çok küçük olduğunda, tipik olarak %5’in altında olduğunda, kaldırmak uygun olabilir. Ayrıca, eksik veriler MCAR (Tamamen Rastgele Eksik) ise, yani eksiklik önyargı yaratmıyorsa iyi bir fikirdir. Son olarak, veri kümesi yeterince büyükse ve az sayıda satırı silmek analizi anlamlı derecede etkilemeyecekse eksik değerleri kaldırmayı düşünebilirim.
Her atama yönteminin artıları ve eksileri vardır. Örneğin, ortalama/medyan/mod ataması uygulaması kolaydır; ancak önyargı katabilir ve değişkenler arası ilişkileri bozabilir. K-en yakın komşu (KNN) ataması, değişkenler arası ilişkileri dikkate alır ve daha doğru sonuçlar verebilir; fakat hesaplama açısından maliyetli olabilir.
A/B testi, bir değişkenin iki sürümünü (ör. bir web sayfası, uygulama özelliği veya pazarlama kampanyası) karşılaştırarak hangisinin daha iyi performans gösterdiğini belirlemek için deney tasarımında kullanılan bir yöntemdir. Son derece ilgili bir konudur ve pek çok iş ilanında “gerekli” bölümünde yer alır.
Mevsimsellik, eğilim ve artıklar (gürültü) ile birlikte zaman serisinin bileşenlerinden biridir. Mevsimselliği tespit etmek için önce zaman serisini bir çizgi grafikle görsel olarak inceleyebiliriz. Mevsimselliğin varlığından şüpheleniliyorsa, mevsimsel etkinin büyüklüğünü bulmak için serinin ayrıştırılması uygulanabilir.
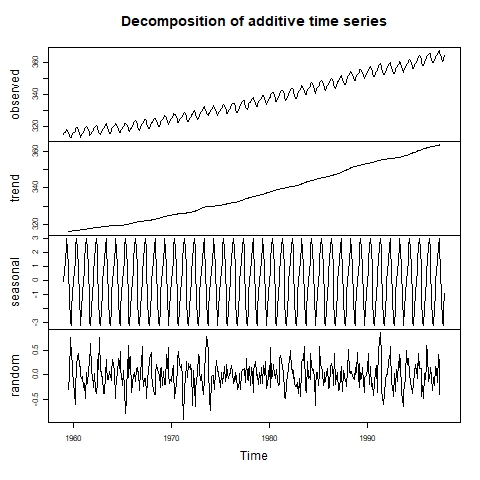
Zaman serisinin görsel olarak ayrıştırılması. Kaynak: Çevresel Enformatik Laboratuvarı.
Üstel Düzeltme modelleri, basit ve kısa vadeli tahminler için geçmiş gözlemlerin ağırlıklı ortalamalarını kullanır. ARIMA modelleri ise otoregresyon, fark alma ve hareketli ortalama bileşenlerini birleştirir; daha karmaşıktır ancak karmaşık desenler ve belirgin otokorelasyonlar içeren durumlarda hem kısa hem uzun vadeli tahminler için uygundur.
Çapraz doğrulama, bir makine öğrenmesi modelinin bağımsız bir veri kümesine nasıl genelleneceğini değerlendirmek için kullanılan bir tekniktir. Veriyi birkaç katmana (fold) bölmeyi ve birden çok eğitim-doğrulama turu gerçekleştirmeyi içerir.
İstatistik ve analiz sonuçlarını mükemmelleştirmek, çıktıyı iş paydaşlarına aktarmadan tamamlanmış sayılmaz; bu nedenle veri rolleri için işe alımda sosyal beceriler kritik önemdedir; özellikle de istatistikten çıkarılan içgörüleri anlatmak hiçbir zaman kolay olmadığından.
Farklı paydaşlarla etkili iletişim kurmak için üslubumu onların geçmişleri ve ilgi alanlarına göre uyarlarım. Örneğin, yöneticiler için iş etkisini önceliklendirir, hızlı karar almayı kolaylaştırmak üzere iş dili ve görseller kullanırım. Geliştiriciler için ise teknik ayrıntılar sunarım. Her iki durumda da ilgili kavramların yeterince açık ve erişilebilir olmasını sağlar, soru ve geri bildirimi teşvik ederim. Bu yaklaşım, her paydaş grubunun ihtiyaç duyduğu bilgiyi onlarla uyumlu bir formatta almasını sağlar.
Veri analitiği rolleri için istatistik öğrenmek zorlayıcı olabilir. Pek çok kişi, istatistik bilgisi çok az olan ya da hiç olmayan farklı geçmişlerden bu alana gelir. Çevrimiçi mevcut kaynakların çoğu, öğrenenleri yalnızca araçlara odaklanmaya teşvik eder ve istatistiğin hayati önemini göz ardı eder.
Bilginizi ve kariyer fırsatlarınızı daha da geliştirmek için ek kaynak ve kursları keşfetmeyi düşünün. İstatistikçi olma yoluna dair ayrıntılı bir rehber için değerli içgörüler sunan blog yazımız How to Become a Statistician’a göz atın. Bunu R ile İstatistikçi kariyer yoluyla tamamlayabilirsiniz. Sezginizi sınamak için R ile Olasılık Bulmacaları kursunu deneyin. Python’u tercih ediyorsanız, Python ile İstatistik Temelleri beceri yolu harika bir seçenektir.
Yaklaşan mülakatlarınızda bol şans!
DataCamp ile İstatistik Öğrenin
Kurs
Kurs
Kurs