
Kurs
Statistik-Interviewfragen in Python üben
4 Std.
16.5K
Die Werkzeuge der Datenanalyse zu beherrschen, ohne die Konzepte dahinter zu verstehen, ist so, als hätte man einen Werkzeugkasten mit Schraubenziehern, ohne zu wissen, wann und wie man jeden Schraubenzieher benutzt. Es ist wichtig, Statistik zu lernen, denn mit dem Aufkommen von KI-generierten und KI-unterstützten Analysetools werden technische Fähigkeiten zugunsten von Wissensverständnis und kritischem Verstehen an Bedeutung verlieren.
Ich lade dich ein, dich von der Komplexität der Statistik nicht einschüchtern zu lassen. Dieser Artikel soll einen umfassenden Leitfaden für die wichtigsten statistischen Konzepte für Datenanalysten und Datenwissenschaftler mit 35 Fragen und Antworten zu Statistik-Interviews bieten. Egal, ob du dich auf ein Vorstellungsgespräch vorbereitest oder nicht, ich bin sicher, du wirst diese Fragen informativ finden.
Bevor wir anfangen, solltest du unseren Kurs "Einführung in die Statistik in R" besuchen, um die Grundlagen zu erlernen, z. B. wie man statistische Analysen durchführt und Ergebnisse interpretiert. Wenn du dich aktiv auf ein Vorstellungsgespräch vorbereitest, das statistisches Verständnis erfordert, decken die beiden folgenden DataCamp-Kurse die am häufigsten behandelten statistischen Themen ab: Praktische Statistik-Interviewfragen in Python und Praktische Statistik-Interviewfragen in R.
Die meisten, wenn nicht sogar alle Jobs in der Datenanalyse erfordern ein grundlegendes Verständnis der Statistik, einschließlich der deskriptiven Statistik, der Folgerungsstatistik und der Wahrscheinlichkeitsrechnung. Wenn du vor einem Vorstellungsgespräch deine Kenntnisse in deskriptiver Statistik auffrischen willst, kannst du dir unseren Spickzettel für deskriptive Statistik herunterladen. Wenn du einige Berechnungen und Methoden durcharbeiten möchtest, kannst du dir auch die folgenden DataCamp-Tutorials ansehen, um die relevanten Konzepte genauer zu verstehen:
Varianz und Standardabweichung messen beide die Streuung eines Datensatzes. Die Varianz ist der Durchschnitt der quadrierten Abweichungen vom Mittelwert. Sie gibt ein Gefühl dafür, wie sehr die Werte in einem Datensatz vom Mittelwert abweichen. Da sie jedoch quadrierte Differenzen verwendet, sind auch die Einheiten quadriert, was weniger intuitiv sein kann als die Standardabweichung. Die Standardabweichung ist die Quadratwurzel aus der Varianz, wodurch die Einheiten wieder mit den ursprünglichen Daten übereinstimmen. Sie bietet ein besser interpretierbares Maß für die Streuung. Wenn die Varianz eines Datensatzes zum Beispiel 25 beträgt, ist die Standardabweichung √25 = 5.
Die Schiefe misst die Asymmetrie eines Datensatzes um seinen Mittelwert, der positiv, negativ oder null sein kann. Daten mit positiver Schiefe oder rechtsschiefe Daten haben einen längeren rechten Schwanz, was bedeutet, dass der Mittelwert größer ist als der Median. Daten mit negativer Schiefe oder linksschiefe Daten haben einen längeren linken Schwanz, was bedeutet, dass der Mittelwert kleiner ist als der Median. Eine Schiefe von Null weist auf eine symmetrische Verteilung hin, wie eine Normalverteilung, bei der der Mittelwert, der Median und der Modus gleich sind.
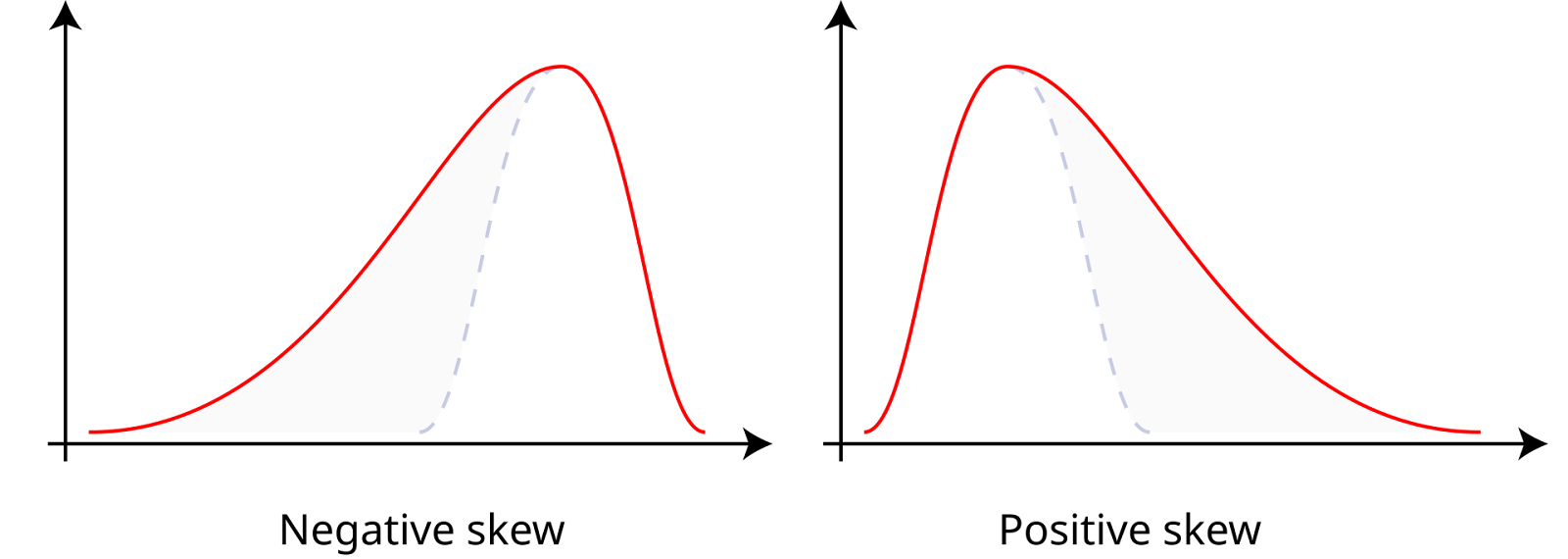
Positive und negative Schiefe. Quelle: Wikiversity.
Ein Histogramm ist eine grafische Darstellung der Verteilung eines Datensatzes. Sie unterteilt die Daten in Bins (Intervalle) und zeigt die Häufigkeit (oder Anzahl) der Datenpunkte in jedem Bin. Histogramme werden verwendet, um die zugrunde liegende Häufigkeitsverteilung (Form) eines Satzes kontinuierlicher Daten zu verstehen. Sie helfen dabei, Muster wie Schiefe, Modalität (Anzahl der Peaks) und das Vorhandensein von Ausreißern zu erkennen.
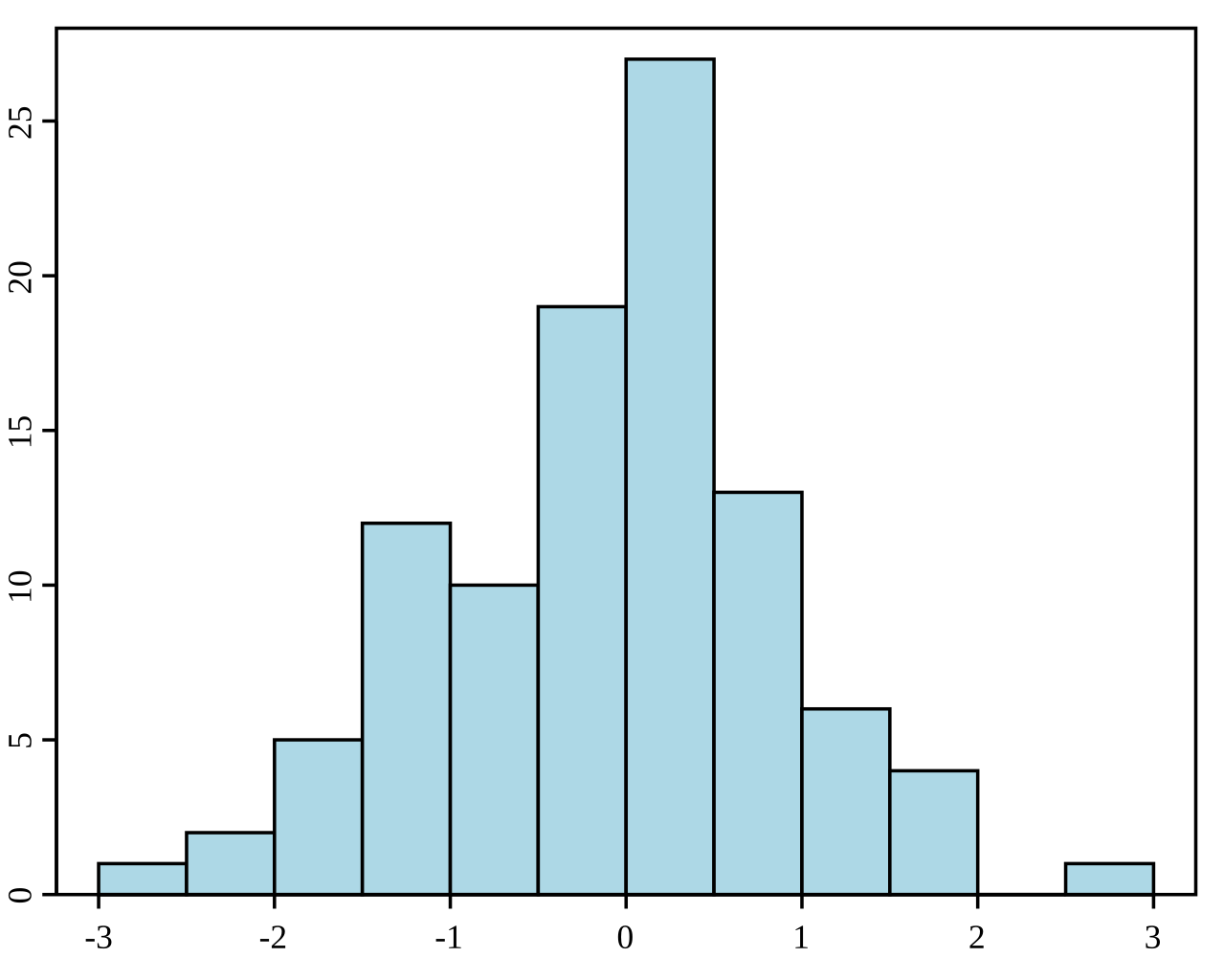
Beispiel für ein Histogramm. Quelle: Wikipedia.
Bei der Inferenzstatistik geht es darum, Vorhersagen oder Schlussfolgerungen über eine Grundgesamtheit auf der Grundlage einer Zufallsstichprobe von Daten aus dieser Grundgesamtheit zu treffen. Sie nutzt verschiedene Methoden, um Bevölkerungsparameter zu schätzen, Hypothesen zu testen und Vorhersagen zu treffen. Während die deskriptive Statistik die Merkmale eines Datensatzes zusammenfasst und beschreibt, nutzt die inferentielle Statistik die Daten, um Verallgemeinerungen und Schlussfolgerungen über eine größere Population zu ziehen.
Um sicherzustellen, dass die Stichproben repräsentativ sind und nach dem Zufallsprinzip gezogen werden, werden verschiedene Stichprobenverfahren eingesetzt. Bei einer einfachen Zufallsstichprobe hat jedes Mitglied der Grundgesamtheit die gleiche Chance, ausgewählt zu werden. Bei einer systematischen Stichprobe wird jedes k-te Mitglied der Grundgesamtheit ausgewählt, ausgehend von einem zufällig gewählten Punkt. Bei der geschichteten Stichprobe wird die Grundgesamtheit in Schichten oder Untergruppen unterteilt und aus jeder Schicht werden Zufallsstichproben gezogen. Bei der Cluster-Stichprobe wird die Grundgesamtheit in Cluster unterteilt, wobei einige Cluster zufällig ausgewählt werden und alle Mitglieder innerhalb dieser Cluster befragt werden.
Das zentrale Grenzwertsatztheorem besagt, dass sich die Stichprobenverteilung des Stichprobenmittelwerts mit zunehmendem Stichprobenumfang einer Normalverteilung annähert, unabhängig von der Verteilung der Grundgesamtheit, vorausgesetzt, die Stichproben sind unabhängig und identisch verteilt.
Die marginale Wahrscheinlichkeit bezeichnet die Wahrscheinlichkeit, dass ein einzelnes Ereignis unabhängig von anderen Ereignissen eintritt, ausgedrückt als P(A) für das Ereignis A. Die gemeinsame Wahrscheinlichkeit ist die Wahrscheinlichkeit, dass zwei Ereignisse zusammen auftreten, dargestellt als P(A∩B) für die Ereignisse A und B. Die bedingte Wahrscheinlichkeit ist die Wahrscheinlichkeit, dass ein Ereignis eintritt, wenn ein anderes Ereignis eingetreten ist, ausgedrückt als P(A|B) für die Ereignisse A und B.
Eine Wahrscheinlichkeitsverteilung beschreibt, wie die Werte einer Zufallsvariablen verteilt sind. Sie bietet eine Funktion, die die Ergebnisse einer Zufallsvariablen auf die entsprechenden Wahrscheinlichkeiten abbildet. Es gibt zwei Haupttypen von Wahrscheinlichkeitsverteilungen. Eine davon ist die diskrete Wahrscheinlichkeitsverteilung für diskrete Zufallsvariablen, wie die Binomialverteilung oder die Poisson-Verteilung. Die andere ist die kontinuierliche Wahrscheinlichkeitsverteilung für kontinuierliche Zufallsvariablen, wie die Normalverteilung oder die Exponentialverteilung.
Die Normalverteilung, auch bekannt als Gauß-Verteilung, ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die sich durch ihre glockenförmige Kurve auszeichnet, die symmetrisch zum Mittelwert ist. Bei Normalverteilungen ist der Mittelwert also gleich dem Median. Außerdem ist bekannt, dass etwa 68% der Daten innerhalb einer Standardabweichung vom Mittelwert liegen, 95% innerhalb von zwei Standardabweichungen und 99,7% innerhalb von drei Standardabweichungen. Dies wird als 68-95-99,7-Regel bezeichnet.
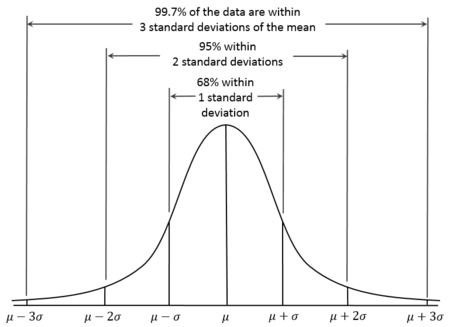
Normalverteilungskurve. Quelle: Wikiversity.
Die Binomialverteilung ist eine diskrete Wahrscheinlichkeitsverteilung, die die Anzahl der Erfolge bei einer festen Anzahl unabhängiger Bernoulli-Versuche modelliert, die jeweils die gleiche Erfolgswahrscheinlichkeit haben. Sie wird verwendet, wenn es genau zwei mögliche Ergebnisse (Erfolg und Misserfolg) für jeden Versuch gibt. Sie kann zum Beispiel verwendet werden, um die Anzahl der Köpfe bei einer Reihe von Münzwürfen zu modellieren.
Die Poisson-Verteilung ist eine diskrete Wahrscheinlichkeitsverteilung, die die Anzahl der Ereignisse modelliert, die innerhalb eines festen Zeit- oder Raumintervalls auftreten, wobei die Ereignisse unabhängig voneinander und mit einer konstanten durchschnittlichen Rate auftreten. Sie ist geeignet, wenn du die Anzahl seltener Ereignisse modellieren willst, z. B. die Anzahl der E-Mails, die in einer Stunde eingehen, oder die Anzahl der Erdbeben in einem Jahr.
In der Statistik für Fortgeschrittene konzentrierst du dich auf Hypothesentests, Intervallschätzungen und Regressionsmodellierung. Wenn du dich beim Durchlesen dieser Fragen mit einigen Konzepten unsicher fühlst, kannst du auf die DataCamp-Ressourcen zurückgreifen. Du kannst Hypothesentests in den Kursen Hypothesentests in Python und Hypothesentests in R lernen. Du kannst die Regressionstechniken auch mit den folgenden Kursen und Tutorials meistern:
Ein p-Wert ist die Wahrscheinlichkeit, eine Teststatistik zu erhalten, die mindestens so extrem ist wie die beobachtete, vorausgesetzt, die Nullhypothese ist wahr. Sie wird bei Hypothesentests verwendet, um die Signifikanz des Testergebnisses zu bestimmen. Wenn der p-Wert kleiner oder gleich dem gewählten Signifikanzniveau (α) ist, lehnen wir die Nullhypothese ab. Wenn der p-Wert größer als α ist, können wir die Nullhypothese nicht zurückweisen.
Fehler vom Typ I bei Hypothesentests treten auf, wenn die Nullhypothese wahr ist, wir sie aber fälschlicherweise ablehnen, was zu einem falsch positiven Ergebnis führt. Die Wahrscheinlichkeit, einen Fehler vom Typ I zu machen, ist gleich dem Signifikanzniveau. Fehler vom Typ II treten auf, wenn die Nullhypothese falsch ist, wir sie aber nicht zurückweisen können, was zu einem falsch negativen Ergebnis führt.
Parametrische Tests gehen davon aus, dass die Daten einer bestimmten Verteilung folgen, z. B. der Normalverteilung, und erfordern bestimmte Populationsparameter. Einige Beispiele für parametrische Tests, die ich häufig verwende, sind der t-Test, der Z-Test und die ANOVA. Nichtparametrische Tests gehen nicht von einer bestimmten Verteilung aus und werden verwendet, wenn die Daten nicht den parametrischen Annahmen entsprechen, insbesondere bei kleinen Stichproben. Viele Menschen sind mit diesen Tests vertraut, aber sie erkennen sie nicht unbedingt als nicht-parametrische Tests. Ich habe den Chi-Quadrat-Test, den Mann-Whitney-U-Test, den Wilcoxon Signed-Rank-Test und den Kruskal-Wallis-Test verwendet, um nur einige zu nennen.
Die Regressionsanalyse ist eine statistische Methode, mit der die Beziehung zwischen einer abhängigen Variable und einer oder mehreren unabhängigen Variablen untersucht wird. Sie hilft zu verstehen, wie sich die abhängige Variable verändert, wenn eine der unabhängigen Variablen variiert wird, während die anderen unabhängigen Variablen konstant gehalten werden.
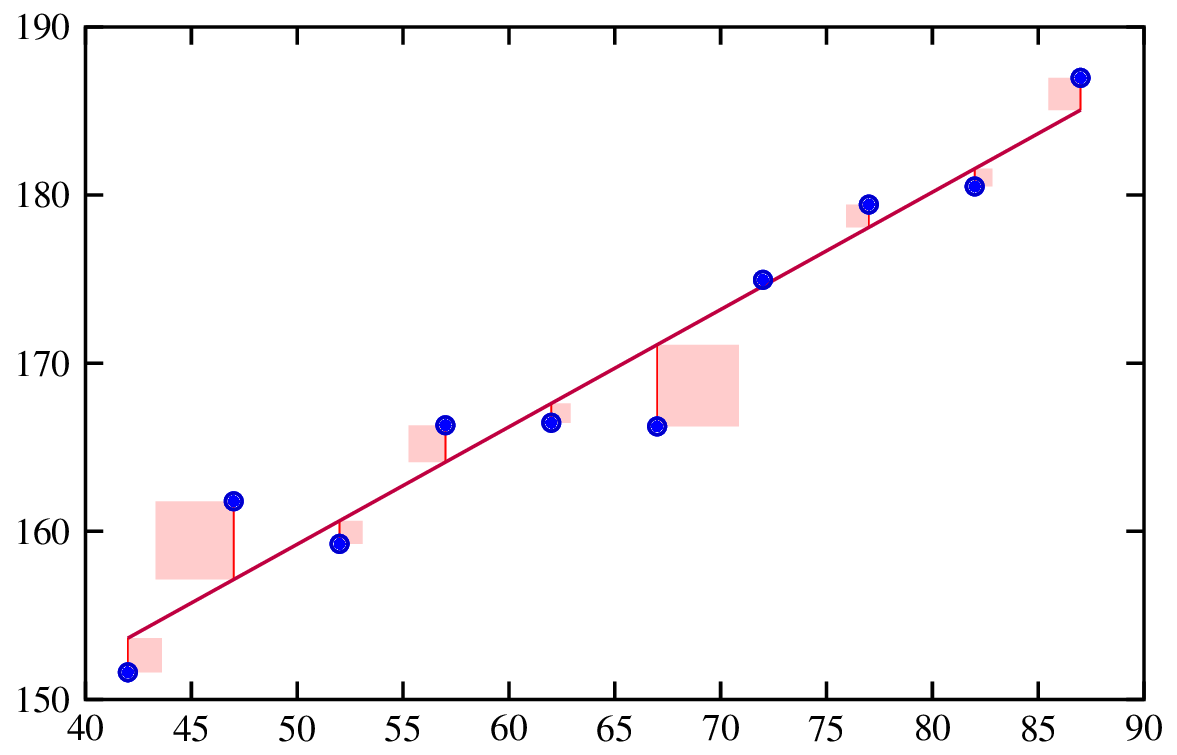
Anpassen einer Regressionslinie. Quelle: Risk Engineering.
Residuen sind die Unterschiede zwischen den beobachteten Werten und den vorhergesagten Werten eines Regressionsmodells. Sie sind wichtig, weil die Analyse der Residuen dabei hilft, die Annahmen unseres Modells zu überprüfen und die allgemeine Anpassung des Modells zu kontrollieren.
In einem linearen Regressionsmodell stellt jeder Koeffizient die erwartete Veränderung der abhängigen Variable bei einer Veränderung der entsprechenden unabhängigen Variable um eine Einheit dar, wobei alle anderen Variablen konstant bleiben. Wenn der Koeffizient einer unabhängigen Variable 𝑥𝑖 beispielsweise 2 ist, bedeutet das, dass für jede Erhöhung von 𝑥𝑖 um eine Einheit die abhängige Variable y voraussichtlich um 2 Einheiten steigen wird, vorausgesetzt, die anderen Variablen bleiben unverändert.
Ein Konfidenzintervall von 95 % bedeutet, dass, wenn wir viele Stichproben nehmen und für jede Stichprobe ein Konfidenzintervall berechnen würden, etwa 95 % dieser Intervalle den wahren Populationsparameter enthalten würden. Wir könnten auch sagen, dass wir zu 95% sicher sind, dass der Parameterwert im geschätzten Intervall liegt.
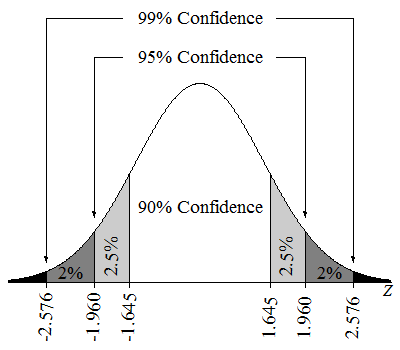
Konfidenzintervalle bei einer Z-Verteilung. Quelle: Lumen Learning.
Multikollinearität liegt vor, wenn zwei oder mehr unabhängige Variablen in einem multiplen Regressionsmodell hoch korreliert sind. Das ist ein Problem, weil es die Koeffizientenschätzungen instabil und schwer zu interpretieren machen kann. Eine hohe Multikollinearität kann auch die Standardfehler der Koeffizienten aufblähen, was zu weniger zuverlässigen statistischen Tests führt.
Regularisierungstechniken sind eine leistungsstarke Technik zur Behandlung von Multikollinearität in Regressionsmodellen. Sie werden auch verwendet, um eine Überanpassung zu verhindern, indem dem Modell ein Malus für große Koeffizienten hinzugefügt wird. Das hilft dabei, ein verallgemeinerbares Modell zu erstellen. Zu den gängigen Regularisierungstechniken gehören Lasso und Ridge Regression.
Wenn ich mich auf ein Vorstellungsgespräch vorbereiten würde, das ein fortgeschrittenes Verständnis von Statistik erfordert, würde ich sicherstellen, dass ich Bayes'sche Statistik und maschinelles Lernen studiere.
Für Bayes'sche Statistik, schau dir unsere Kurse an: Bayesianische Datenanalyse in Python und Grundlagen der Bayesianischen Datenanalyse in R. Wenn du dich für maschinelles Lernen interessierst, schau dir die DataCamp Lernpfade oder Kurse zum Thema maschinelles Lernen an, z.B. unseren Lernpfad "Machine Learning Scientist with Python " und unseren Kurs "Maschinelles Lernen verstehen".
Bei der Bayes'schen Statistik wird das Bayes-Theorem verwendet, um die Wahrscheinlichkeit einer Hypothese zu aktualisieren, wenn mehr Beweise oder Informationen verfügbar werden. Sie kombiniert vorherige Überzeugungen mit neuen Daten, um eine Nachfolgewahrscheinlichkeit zu bilden.
Markov Chain Monte Carlo ist eine Klasse von Algorithmen, die verwendet werden, um eine Stichprobe aus einer Wahrscheinlichkeitsverteilung zu ziehen, wenn eine direkte Stichprobe schwierig ist. Sie ist in der Bayes'schen Statistik wichtig, weil sie die Schätzung von Posteriorverteilungen ermöglicht, insbesondere bei komplexen Modellen, bei denen analytische Lösungen nicht möglich sind.
Beim maschinellen Lernen geht es um den Ausgleich von zwei Fehlerquellen. Bias ist der Fehler, der durch zu einfache Modellannahmen entsteht und zu einer Unteranpassung und fehlenden Datenmustern führt. Die Varianz ist der Fehler, der durch eine übermäßige Empfindlichkeit gegenüber Schwankungen in den Trainingsdaten entsteht, was zu einer Überanpassung führt und Rauschen anstelle von echten Mustern erfasst.
Kausalschlüsse sind eine wichtige Idee, der viel Aufmerksamkeit geschenkt wird. Der Kausalschluss ist der Prozess, bei dem festgestellt wird, ob und wie eine Variable (die Ursache) eine andere Variable (die Wirkung) direkt beeinflusst, was ein Unterscheidungsmerkmal zwischen Kausalschluss und bloßer Korrelation ist. Kausalschlüsse sind eine Gruppe von Methoden, die darauf abzielen, eine Ursache-Wirkungs-Beziehung herzustellen, um zu verstehen, ob etwas funktioniert, z. B. eine Intervention oder eine Behandlung irgendeiner Art. Wenn ein Forscher zum Beispiel herausfinden will, ob ein Medikament wirkt, kann der Kausalschluss helfen, die Frage zu beantworten.
Die Strukturgleichungsmodellierung ist ein Verfahren zur Analyse von Beziehungen zwischen sogenannten beobachteten und latenten Variablen. Sie ist eine Art Mischung aus multipler Regression und Faktorenanalyse. Die Strukturgleichungsmodellierung erfordert mehrere Schritte, wie die Modellspezifikation, die Schätzung und die Auswertung. Die SEM ist als flexibel bekannt, aber sie erfordert große Stichproben und du brauchst eine solide theoretische Grundlage, um sie anwenden zu können.
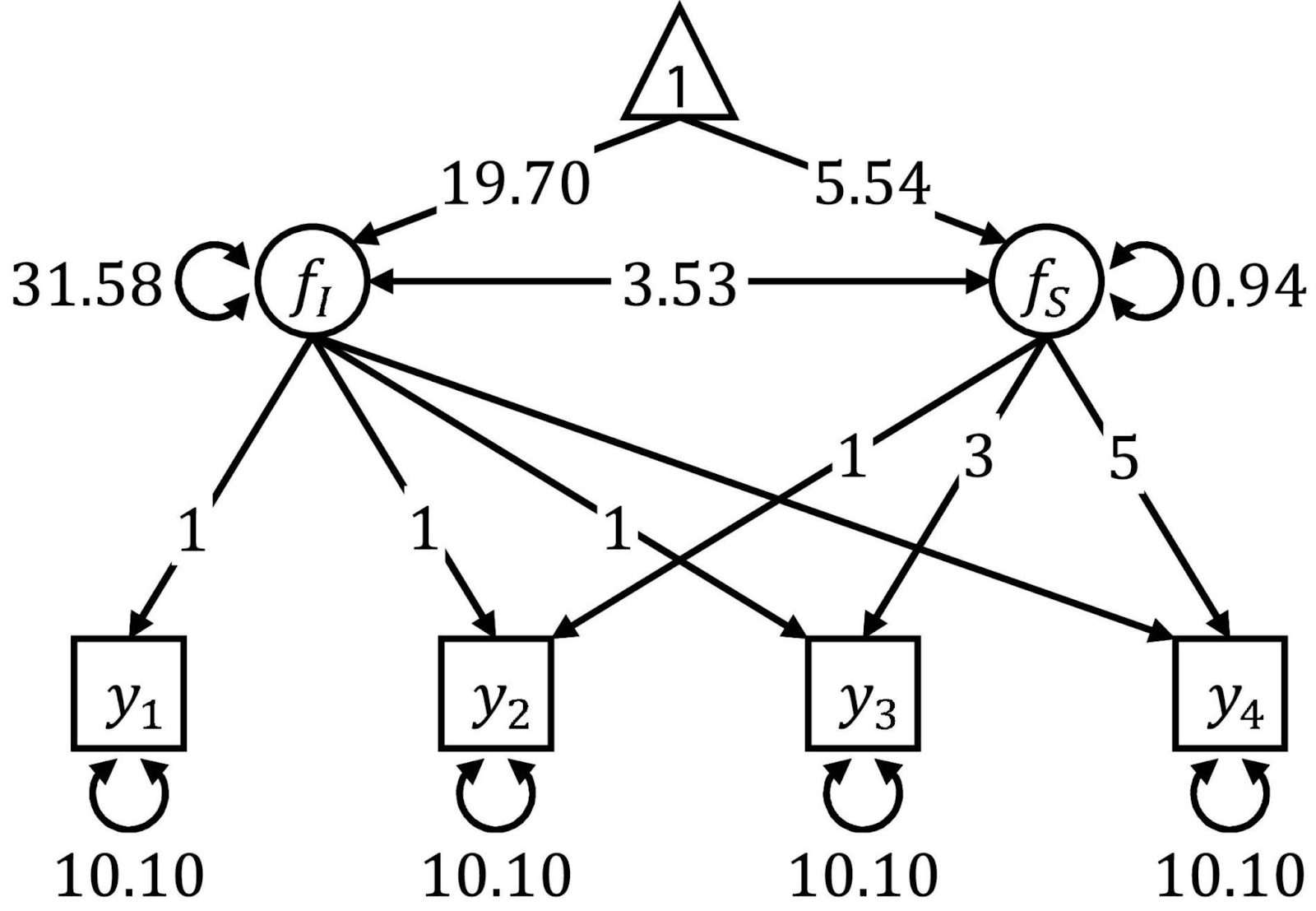
Pfaddiagramme werden oft verwendet, um SEM zu visualisieren. Quelle: Grenzen.
Die folgenden Fragen werden dir helfen, wenn du dich für eine Stelle bewirbst, die sich mehr auf die Schnittstelle von Datenwissenschaft und Statistik konzentriert. Zu den Themen gehören Datenvorverarbeitung und -bereinigung, A/B-Tests und Versuchsplanung, Zeitreihenprognosen und fortgeschrittene statistische Verfahren.
Wenn du dich bei diesen Konzepten unsicher fühlst und es dir ernst damit ist, deinen Interviewprozess zu verbessern, solltest du diese DataCamp-Ressourcen zu A/B-Tests nutzen: Kurs "A/B-Tests in Python " oder "A/B-Tests in R ". Um die Zeitreihenanalyse zu beherrschen, wähle einen der Lernpfade Zeitreihen mit R oder Zeitreihen mit Python, um Erfahrungen zu sammeln.
Die Aufteilung der Daten in Trainings- und Testdatensätze hilft uns, die Leistung des Modells bei ungesehenen Daten zu bewerten. Die Trainingsmenge wird verwendet, um das Modell zu trainieren, während die Testmenge dazu dient, zu beurteilen, wie gut das Modell auf neue Daten verallgemeinert. Diese Vorgehensweise hilft dabei, eine Überanpassung zu erkennen, und stellt sicher, dass das Modell auch bei realen Daten gut funktioniert.
Überanpassung tritt auf, wenn ein Modell sowohl die zugrundeliegenden Muster als auch das Rauschen in den Trainingsdaten lernt, was zu einer hervorragenden Leistung bei den Trainingsdaten, aber zu einer schlechten Leistung bei neuen, ungesehenen Daten führt. Underfitting liegt vor, wenn ein Modell zu einfach ist, um die zugrundeliegenden Muster in den Daten zu erfassen, was zu einer schlechten Leistung sowohl bei den Trainingsdaten als auch bei den neuen Daten führt.
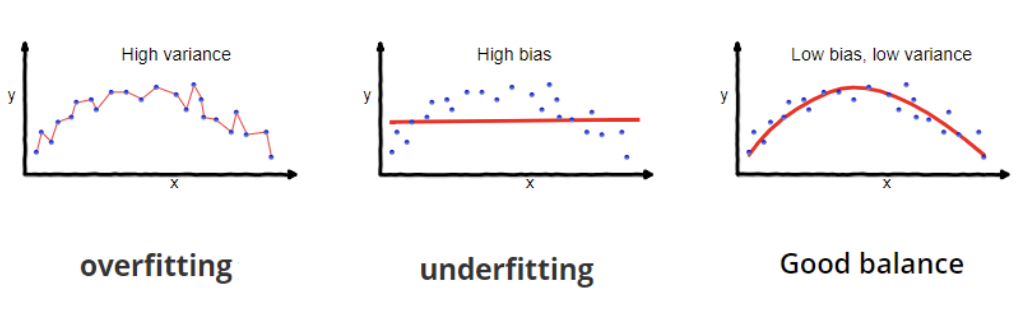
Überanpassung und Unteranpassung. Quelle: Wikipedia.
Das Verständnis des Mechanismus der Missingness (MCAR, MAR, MNAR) ist von entscheidender Bedeutung, da es die Wahl der geeigneten Methoden für den Umgang mit fehlenden Daten bestimmt. Die Verwendung ungeeigneter Techniken kann zu Verzerrungen führen, die Aussagekraft der Ergebnisse verringern und zu falschen Schlussfolgerungen führen. So können beispielsweise einfache Imputationsmethoden für MCAR-Daten geeignet sein, während für MAR- oder MNAR-Daten ausgefeiltere Techniken wie die multiple Imputation oder modellbasierte Methoden notwendig sein können, um unverzerrte Schätzungen zu erhalten.
Das Entfernen fehlender Werte kann sinnvoll sein, wenn der Anteil der fehlenden Daten sehr gering ist, in der Regel weniger als 5 %. Außerdem ist es eine gute Idee, wenn die fehlenden Daten MCAR (Missing Completely at Random) sind, was bedeutet, dass die fehlenden Daten keine Verzerrungen verursachen. Schließlich würde ich in Erwägung ziehen, fehlende Werte zu entfernen, wenn der Datensatz groß genug ist, dass das Löschen einer kleinen Anzahl von Zeilen keinen großen Einfluss auf die Analyse hat.
Jede Imputationsmethode hat ihre Vor- und Nachteile. Die Imputation von Mittelwert/Mittelwert/Modus ist zum Beispiel einfach zu implementieren, kann aber zu Verzerrungen führen und die Beziehungen zwischen den Variablen verzerren. Die K-Nächste-Nachbarn-Imputation (KNN) berücksichtigt die Beziehungen zwischen den Variablen und kann zu genaueren Ergebnissen führen, ist aber sehr rechenintensiv.
A/B-Tests sind eine Methode, die in der Versuchsplanung verwendet wird, um zwei Versionen einer Variable zu vergleichen, z. B. eine Webseite, eine App-Funktion oder eine Marketingkampagne, um festzustellen, welche Version besser abschneidet. Es ist ein sehr relevantes Thema und steht in vielen Stellenbeschreibungen unter "Anforderungen".
Die Saisonalität ist neben dem Trend und den Residuen (Rauschen) eine der Komponenten der Zeitreihe. Um die Saisonalität zu erkennen, können wir die Zeitreihe zunächst visuell mit einem Liniendiagramm untersuchen. Wird das Vorhandensein von Saisonalität vermutet, können wir eine Zerlegung der Zeitreihe vornehmen, um die Größe des saisonalen Effekts zu ermitteln.
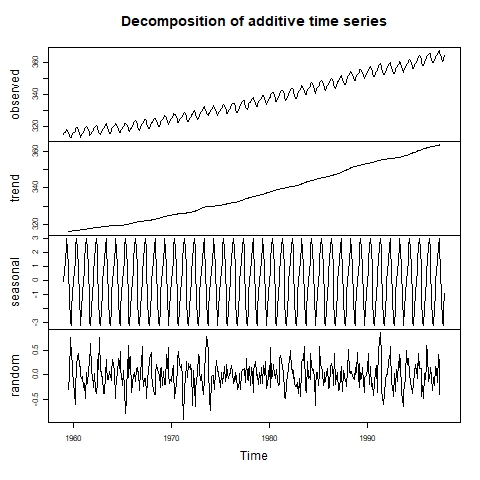
Zeitreihen werden visuell zerlegt. Quelle: Labor für Umweltinformatik.
Exponential Smoothing-Modelle verwenden gewichtete Durchschnitte vergangener Beobachtungen für einfache, kurzfristige Prognosen. ARIMA-Modelle kombinieren die Komponenten Autoregression, Differenzbildung und gleitender Durchschnitt, was sie zwar komplexer macht, aber sowohl für kurz- als auch für langfristige Prognosen geeignet ist, insbesondere bei komplexen Mustern und erheblichen Autokorrelationen.
Die Kreuzvalidierung ist eine Technik, mit der man beurteilen kann, wie ein maschinelles Lernmodell auf einen unabhängigen Datensatz verallgemeinert werden kann. Dabei werden die Daten in mehrere Foldings aufgeteilt und mehrere Trainings- und Validierungsrunden durchgeführt.
Da die Perfektionierung der Statistiken und der Analyseergebnisse nicht vollständig ist, wenn man die Ergebnisse nicht an die Stakeholder des Unternehmens kommuniziert, ist die Unterstützung von Soft Skills für Arbeitgeber, die Stellen im Datenbereich besetzen, von entscheidender Bedeutung, zumal es nie einfach ist, Erkenntnisse aus Statistiken zu vermitteln.
Um mit verschiedenen Interessengruppen effektiv zu kommunizieren, passe ich meinen Stil an ihre Hintergründe und Interessen an. Für Führungskräfte setze ich zum Beispiel Prioritäten bei den Auswirkungen auf das Geschäft und verwende Geschäftssprache und visuelle Darstellungen, um schnelle Entscheidungen zu erleichtern. Auf der anderen Seite liefere ich den Entwicklern technische Details. In beiden Fällen stelle ich sicher, dass die Konzepte klar und verständlich sind, und ich ermutige zu Fragen und Feedback. Dieser Ansatz stellt sicher, dass jede Interessengruppe die Informationen erhält, die sie braucht, und zwar in einem Format, das sie anspricht.
Das Erlernen von Statistiken für die Datenanalyse kann eine Herausforderung sein. Viele Menschen kommen aus verschiedenen Bereichen, die nicht unbedingt viel oder gar kein statistisches Wissen voraussetzen. Die meisten der online verfügbaren Ressourcen ermutigen die Lernenden, sich nur auf die Werkzeuge zu konzentrieren und übersehen dabei die entscheidende Bedeutung der Statistik.
Um dein Wissen und deine Karrierechancen weiter zu verbessern, solltest du dir zusätzliche Ressourcen und Kurse ansehen. Einen detaillierten Leitfaden, wie du Statistiker/in werden kannst, findest du in unserem Blogbeitrag Wie werde ich Statistiker/in, der wertvolle Einblicke bietet. Du kannst dies mit unserem Lernpfad Statistiker/in mit R ergänzen. Nimm dir Zeit, um deine Intuition mit dem Kurs " Wahrscheinlichkeitsrätsel in R " zu testen. Wenn du Python bevorzugst, ist unser Lernpfad Grundlagen der Statistik mit Python eine gute Option.
Viel Glück bei deinen kommenden Vorstellungsgesprächen!
Statistik lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
Blog