
Cours
S’entraîner aux questions d’entretien en statistiques avec Python
4 h
16.5K
Maîtriser les outils de l'analyse des données sans comprendre les concepts qui les sous-tendent, c'est comme avoir une boîte à outils remplie de tournevis sans savoir quand et comment utiliser chacun d'entre eux. Il est important d'apprendre les statistiques, car l'essor des outils d'analyse générés et assistés par l'IA réduira l'avantage concurrentiel des compétences techniques au profit de la compréhension des connaissances et de l'esprit critique.
Je vous invite à ne pas vous laisser intimider par la complexité des statistiques. Cet article vise à présenter un guide complet des concepts statistiques les plus pertinents pour les analystes de données et les scientifiques de données à travers 35 questions et réponses d'entretien sur les statistiques. Que vous vous prépariez ou non à un entretien, je suis sûr que vous trouverez ces questions instructives.
Enfin, avant de commencer, pensez à suivre notre cours Introduction aux statistiques en R pour apprendre les bases, notamment comment effectuer des analyses statistiques et interpréter les résultats. De plus, si vous vous préparez activement à un entretien nécessitant des connaissances statistiques, les deux cours DataCamp suivants couvrent tous les sujets statistiques les plus fréquemment abordés : Praticing Statistics Interview Questions in Python et Practicing Statistics Interview Questions in R.
La plupart des emplois dans le domaine de l'analyse des données, si ce n'est tous, requièrent des connaissances de base en statistiques, notamment en statistiques descriptives, en statistiques inférentielles et en probabilités. Si vous souhaitez réviser vos statistiques descriptives avant un entretien, téléchargez notre aide-mémoire sur les statistiques descriptives pour vous y référer facilement. De plus, si vous souhaitez travailler sur certains calculs et méthodes, consultez les tutoriels DataCamp suivants pour approfondir les concepts pertinents :
La variance et l'écart-type mesurent tous deux la dispersion ou l'étendue d'un ensemble de données. La variance est la moyenne des différences au carré par rapport à la moyenne. Il donne une idée de l'écart entre les valeurs d'un ensemble de données et la moyenne. Cependant, comme il utilise des différences au carré, les unités sont également au carré, ce qui peut être moins intuitif que l'écart-type. L'écart-type est la racine carrée de la variance, ce qui ramène les unités à la même valeur que les données d'origine. Il fournit une mesure plus facile à interpréter de la dispersion. Par exemple, si la variance d'un ensemble de données est de 25, l'écart-type est de √25 = 5.
L'asymétrie mesure l'asymétrie d'un ensemble de données autour de sa moyenne, qui peut être positive, négative ou nulle. Les données dont l'asymétrie est positive, ou données asymétriques, ont une queue droite plus longue, ce qui signifie que la moyenne est supérieure à la médiane. Les données présentant une asymétrie négative, ou données asymétriques à gauche, ont une queue gauche plus longue, ce qui signifie que la moyenne est inférieure à la médiane. Une asymétrie nulle indique une distribution symétrique, comme une distribution normale, où la moyenne, la médiane et le mode sont égaux.
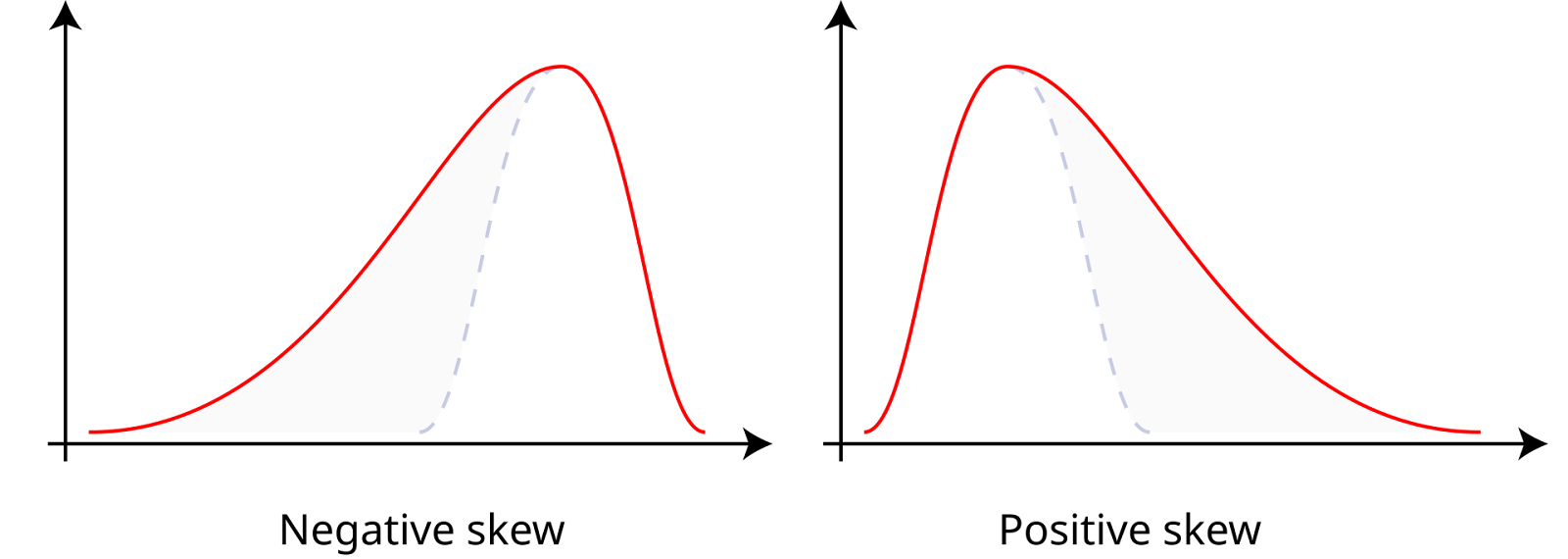
Asymétrie positive et négative. Source : Wikiversité.
Un histogramme est une représentation graphique de la distribution d'un ensemble de données. Il divise les données en cases (intervalles) et indique la fréquence (ou le nombre) de points de données dans chaque case. Les histogrammes sont utilisés pour comprendre la distribution de fréquence sous-jacente (forme) d'un ensemble de données continues. Ils permettent d'identifier des tendances telles que l'asymétrie, la modalité (nombre de pics) et la présence de valeurs aberrantes.
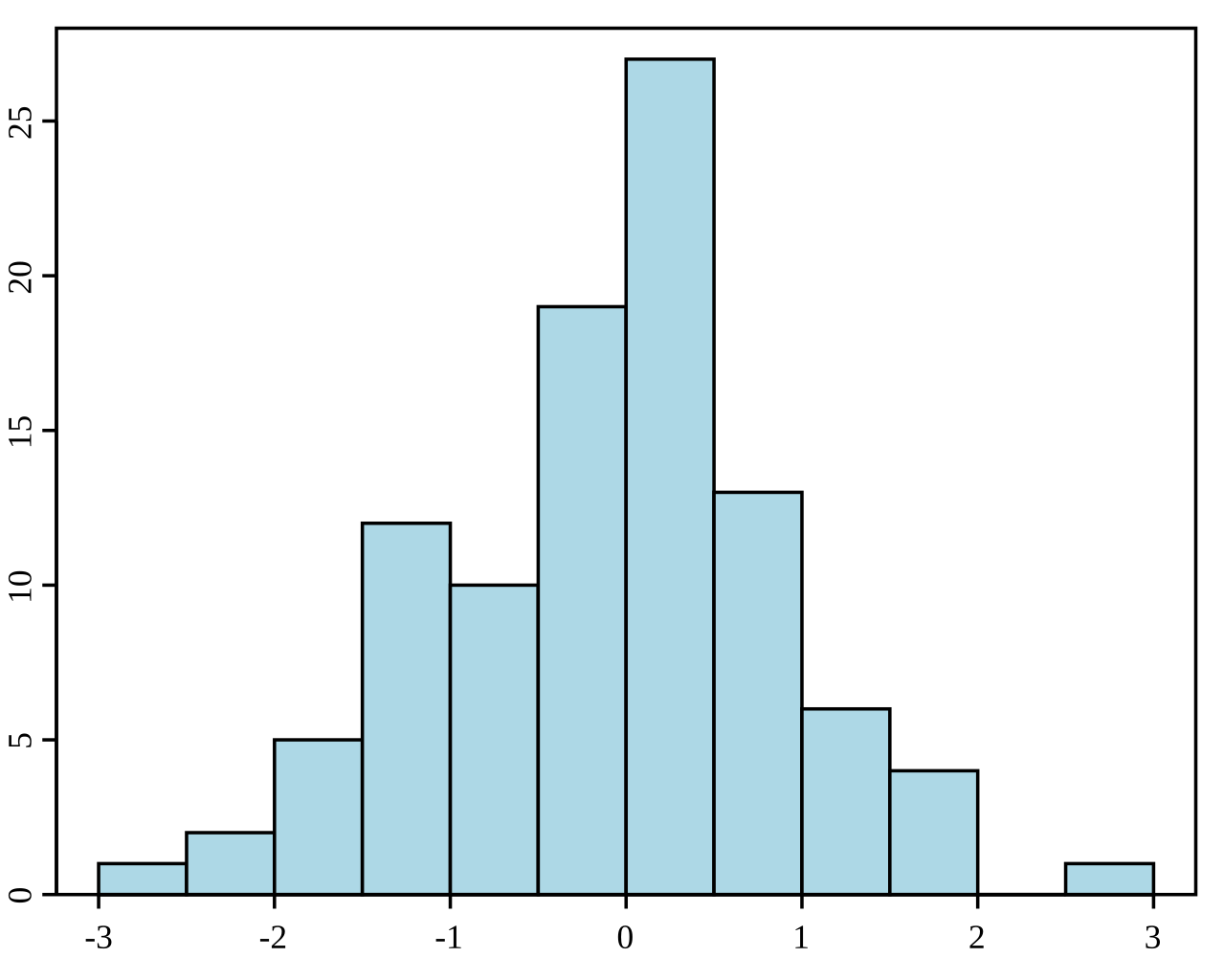
Exemple d'histogramme. Source : Wikipedia.
La statistique inférentielle consiste à faire des prédictions ou des déductions sur une population à partir d'un échantillon aléatoire de données prélevées dans cette population. Elle utilise diverses méthodes pour estimer les paramètres de la population, tester des hypothèses et faire des prédictions. Alors que les statistiques descriptives résument et décrivent les caractéristiques d'un ensemble de données, les statistiques inférentielles utilisent les données pour faire des généralisations et tirer des conclusions sur une population plus large.
Différentes méthodes d'échantillonnage sont utilisées pour garantir que les échantillons sont représentatifs et aléatoires. L'échantillonnage aléatoire simple donne à chaque membre de la population une chance égale d'être sélectionné. L'échantillonnage systématique consiste à sélectionner chaque k-ième membre de la population, à partir d'un point choisi au hasard. L'échantillonnage stratifié divise la population en strates ou sous-groupes, et des échantillons aléatoires sont prélevés dans chaque strate. L'échantillonnage en grappes divise la population en grappes, sélectionne au hasard certaines grappes et échantillonne tous les membres qui s'y trouvent.
Le théorème de la limite centrale stipule que la distribution d'échantillonnage de la moyenne de l'échantillon se rapproche d'une distribution normale à mesure que la taille de l'échantillon augmente, quelle que soit la distribution de la population, à condition que les échantillons soient indépendants et identiquement distribués.
La probabilité marginale est la probabilité qu'un seul événement se produise, indépendamment des autres événements, représentée par P(A) pour l'événement A. La probabilité conjointe est la probabilité que deux événements se produisent ensemble, représentée par P(A∩B) pour les événements A et B. La probabilité conditionnelle est la probabilité qu'un événement se produise étant donné qu'un autre événement s'est produit, exprimée par P(A|B) pour les événements A et B.
Une distribution de probabilités décrit la façon dont les valeurs d'une variable aléatoire sont distribuées. Il s'agit d'une fonction qui associe les résultats d'une variable aléatoire aux probabilités correspondantes. Il existe deux types principaux de distributions de probabilités. La première est la distribution de probabilité discrète pour les variables aléatoires discrètes, comme la distribution binomiale ou la distribution de Poisson. L'autre est la distribution de probabilité continue pour les variables aléatoires continues, comme la distribution normale ou la distribution exponentielle.
La distribution normale, également connue sous le nom de distribution gaussienne, est une distribution de probabilité continue caractérisée par une courbe en forme de cloche, symétrique par rapport à la moyenne. Dans les distributions normales, la moyenne est donc égale à la médiane. On sait également qu'environ 68 % des données se situent à l'intérieur d'un écart-type de la moyenne, 95 % à l'intérieur de deux écarts-types et 99,7 % à l'intérieur de trois écarts-types. C'est ce qu'on appelle la règle 68-95-99.7.
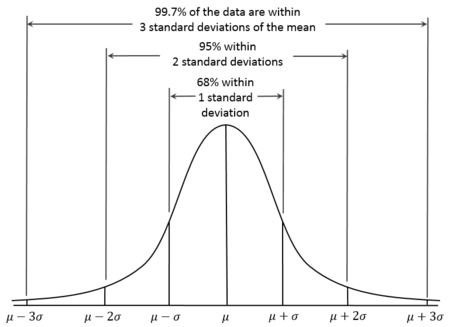
Courbe de distribution normale. Source : Wikiversité.
La distribution binomiale est une distribution de probabilité discrète qui modélise le nombre de succès dans un nombre fixe d'essais de Bernoulli indépendants, chacun ayant la même probabilité de succès. Elle est utilisée lorsqu'il y a exactement deux résultats possibles (succès et échec) pour chaque essai. Par exemple, il peut être utilisé pour modéliser le nombre de têtes dans une série de tirages à pile ou face.
La distribution de Poisson est une distribution de probabilité discrète qui modélise le nombre d'événements se produisant dans un intervalle de temps ou d'espace fixe, où les événements se produisent indépendamment et à un taux moyen constant. Il convient de l'utiliser lorsque vous souhaitez modéliser le décompte d'événements rares, tels que le nombre de courriers électroniques reçus en une heure ou le nombre de tremblements de terre en une année.
Pour les rôles intermédiaires en statistiques, concentrez-vous sur les tests d'hypothèse, l'estimation des intervalles et la modélisation de la régression. Si, en lisant ces questions, vous ne vous sentez pas à l'aise avec certains concepts, vous pouvez vous tourner vers les ressources de DataCamp. Vous pouvez apprendre les tests d'hypothèses grâce aux cours Tests d'hypothèses en Python et Tests d'hypothèses en R. Vous pouvez également maîtriser les techniques de régression grâce aux cours et tutoriels suivants :
Une valeur p est la probabilité d'obtenir une statistique de test au moins aussi extrême que celle observée, en supposant que l'hypothèse nulle est vraie. Il est utilisé dans les tests d'hypothèse pour déterminer la signification du résultat du test. Si la valeur p est inférieure ou égale au seuil de signification choisi (α), nous rejetons l'hypothèse nulle. Si la valeur p est supérieure à α, nous ne rejetons pas l'hypothèse nulle.
Les erreurs de type I dans les tests d'hypothèse se produisent lorsque l'hypothèse nulle est vraie, mais que nous la rejetons à tort, ce qui donne lieu à un faux positif. La probabilité de commettre une erreur de type I est la même que le niveau de signification. Les erreurs de type II se produisent lorsque l'hypothèse nulle est fausse, mais que nous ne parvenons pas à la rejeter, ce qui entraîne un faux négatif.
Les tests paramétriques supposent que les données suivent une distribution spécifique, comme la normale, et nécessitent certains paramètres de population, ce qui les rend idéaux lorsque ces hypothèses sont respectées. Quelques exemples de tests paramétriques que j'utilise couramment sont le test t, le test Z et l'ANOVA. Les tests non paramétriques ne supposent pas de distribution spécifique et sont utilisés lorsque les données ne répondent pas aux hypothèses paramétriques, en particulier avec de petits échantillons. De nombreuses personnes connaissent ces tests, mais ne les identifient pas nécessairement comme étant non paramétriques. J'ai utilisé le test du chi carré, le test U de Mann-Whitney, le test de Wilcoxon et le test de Kruskal-Wallis, pour n'en citer que quelques-uns.
L'analyse de régression est une méthode statistique utilisée pour examiner la relation entre une variable dépendante et une ou plusieurs variables indépendantes. Elle permet de comprendre comment la variable dépendante évolue lorsque l'une des variables indépendantes est modifiée, alors que les autres variables indépendantes sont maintenues constantes.
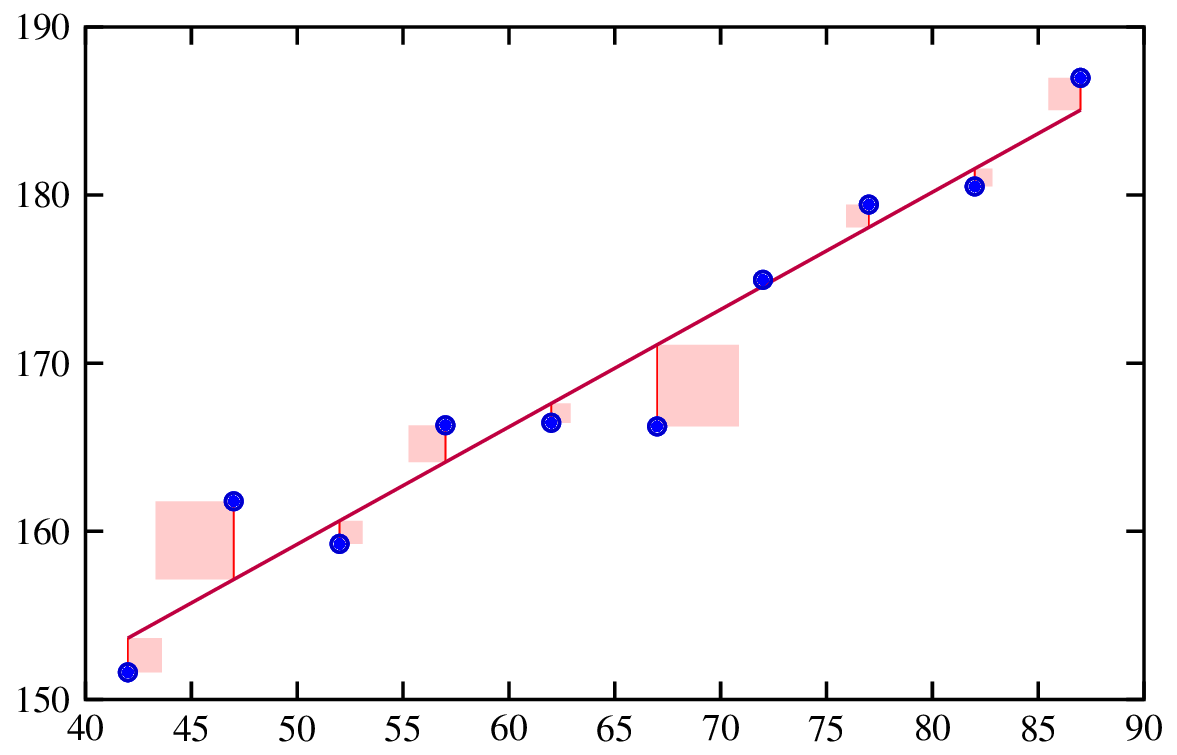
Ajustement d'une droite de régression. Source : Ingénierie des risques.
Les résidus sont les différences entre les valeurs observées et les valeurs prédites par un modèle de régression. Ils sont importants car l'analyse des résidus permet de vérifier les hypothèses de notre modèle, ainsi que l'adéquation globale du modèle.
Dans un modèle de régression linéaire, chaque coefficient représente la variation attendue de la variable dépendante pour une variation d'une unité de la variable indépendante correspondante, toutes les autres variables restant constantes. Par exemple, si le coefficient d'une variable indépendante 𝑥𝑖 est de 2, cela signifie que pour chaque augmentation d'une unité de 𝑥𝑖, la variable dépendante y devrait augmenter de 2 unités, en supposant que les autres variables restent inchangées.
Un intervalle de confiance de 95 % signifie que si l'on prélève de nombreux échantillons et que l'on calcule un intervalle de confiance pour chaque échantillon, environ 95 % de ces intervalles contiendront le véritable paramètre de la population. Nous pourrions également dire que nous sommes sûrs à 95 % que la valeur du paramètre se situe dans l'intervalle estimé.
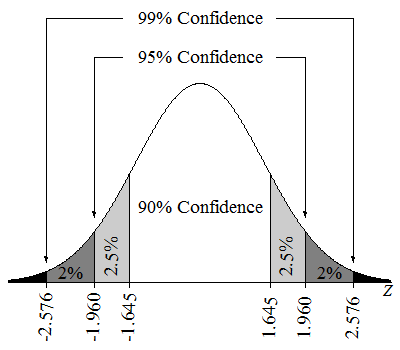
Intervalles de confiance sur une distribution Z. Source : Lumen Learning.
On parle de multicolinéarité lorsque deux ou plusieurs variables indépendantes d'un modèle de régression multiple sont fortement corrélées. C'est un problème car il peut rendre les estimations des coefficients instables et difficiles à interpréter. Une forte multicolinéarité peut également gonfler les erreurs standard des coefficients, ce qui rend les tests statistiques moins fiables.
Les techniques de régularisation sont une technique puissante pour traiter la multicolinéarité dans les modèles de régression. Ils sont également utilisés pour éviter l'ajustement excessif en ajoutant une pénalité au modèle en cas de coefficients élevés. Cela permet de créer un modèle plus généralisable. Les techniques de régularisation les plus courantes sont le Lasso et la régression Ridge.
Si je devais me préparer à un entretien nécessitant une connaissance approfondie des statistiques, je veillerais à étudier les statistiques bayésiennes et l'apprentissage automatique.
Pour les statistiques bayésiennes, consultez nos cours : Analyse de données bayésiennes en Python et Principes fondamentaux de l'analyse de données bayésiennes en R. Pour l'apprentissage automatique, consultez les cursus de carrière ou les cours de DataCamp sur l'apprentissage automatique, notamment notre cursus de carrière Scientifique en apprentissage automatique avec Python et notre cours Comprendre l'apprentissage automatique.
Les statistiques bayésiennes impliquent l'utilisation du théorème de Bayes pour mettre à jour la probabilité d'une hypothèse au fur et à mesure que de nouvelles preuves ou informations sont disponibles. Il combine les croyances antérieures avec les nouvelles données pour former une probabilité postérieure.
La chaîne de Markov Monte Carlo est une classe d'algorithmes utilisés pour échantillonner à partir d'une distribution de probabilité lorsque l'échantillonnage direct est difficile. Elle est importante dans les statistiques bayésiennes car elle permet d'estimer les distributions postérieures, en particulier dans les modèles complexes où les solutions analytiques ne sont pas réalisables.
Le compromis biais-variance dans l'apprentissage automatique consiste à équilibrer deux sources d'erreur. Le biais est l'erreur due à des hypothèses de modèle trop simplistes, entraînant un sous-ajustement et des modèles de données manquantes. La variance est l'erreur due à une sensibilité excessive aux fluctuations des données d'apprentissage, ce qui entraîne un surajustement et la capture de bruit au lieu de véritables modèles.
L'inférence causale est une idée importante qui a fait l'objet de beaucoup d'attention. L'inférence causale consiste à déterminer si et comment une variable (la cause) affecte directement une autre variable (l'effet), ce qui constitue une caractéristique distinctive entre l'inférence causale et la simple corrélation. L'inférence causale est en fait un groupe de méthodes visant à établir une relation de cause à effet afin de comprendre si quelque chose fonctionne, comme une intervention ou un traitement quelconque. Si un chercheur a besoin de comprendre si un médicament est efficace, par exemple, l'inférence causale peut l'aider à répondre à la question.
La modélisation par équations structurelles est une technique d'analyse des relations entre ce que l'on appelle les variables observées et latentes. Il s'agit en quelque sorte d'un mélange entre la régression multiple et l'analyse factorielle. La modélisation par équations structurelles nécessite plusieurs étapes, telles que la spécification du modèle, l'estimation et l'évaluation. Le SEM est connu pour sa flexibilité, mais il nécessite des échantillons de grande taille et, pour l'utiliser, vous aurez besoin d'une base théorique solide.
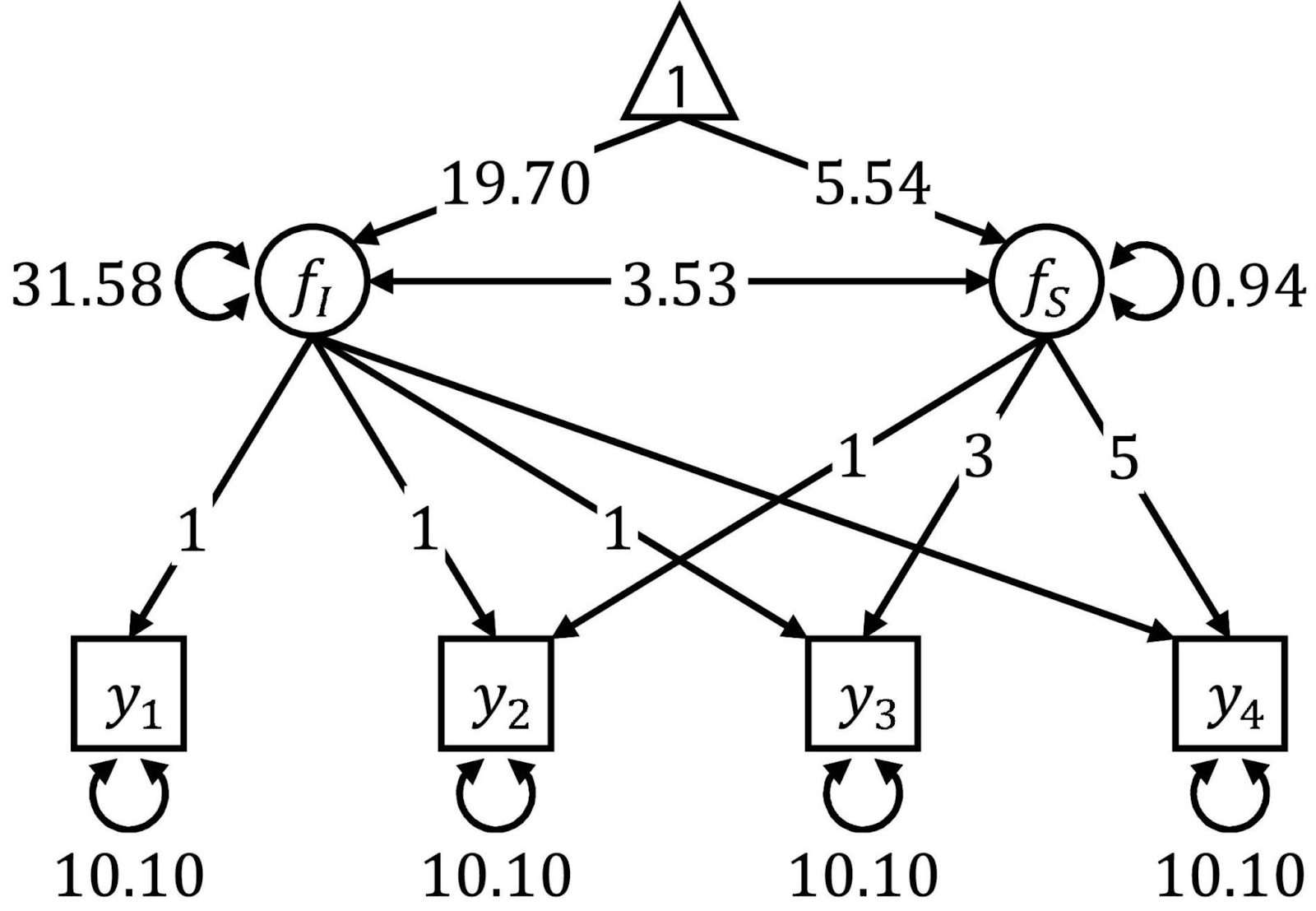
Les diagrammes de cheminement sont souvent utilisés pour visualiser les SEM. Source : Frontières.
Les questions suivantes vous seront utiles si vous êtes à la recherche d'un poste plus axé sur l'intersection de la science des données et des statistiques. Les sujets abordés comprennent le prétraitement et le nettoyage des données, les tests A/B et la conception expérimentale, les prévisions de séries chronologiques et les techniques statistiques avancées.
Si ces concepts vous laissent perplexe et que vous souhaitez vraiment améliorer votre processus d'entretien, consultez ces ressources DataCamp sur les tests A/B : Cours A/B Testing in Python ou A/B Testing in R. Ensuite, pour maîtriser l'analyse des séries temporelles, choisissez entre les parcours de compétences Série temporelle avec R ou Série temporelle avec Python pour acquérir de l'expérience.
La division des données en ensembles de formation et de test nous permet d'évaluer les performances du modèle sur des données inédites. L'ensemble d'apprentissage est utilisé pour former le modèle, tandis que l'ensemble de test est utilisé pour évaluer le degré de généralisation du modèle à de nouvelles données. Cette pratique permet de détecter les ajustements excessifs et de s'assurer que le modèle peut fonctionner correctement sur des données réelles.
Il y a surajustement lorsqu'un modèle apprend à la fois les modèles sous-jacents et le bruit des données d'apprentissage, ce qui se traduit par d'excellentes performances sur les données d'apprentissage, mais de piètres performances sur de nouvelles données inédites. Il y a sous-ajustement lorsqu'un modèle est trop simple pour capturer les modèles sous-jacents dans les données, ce qui se traduit par de mauvaises performances à la fois sur les données d'apprentissage et sur les nouvelles données.
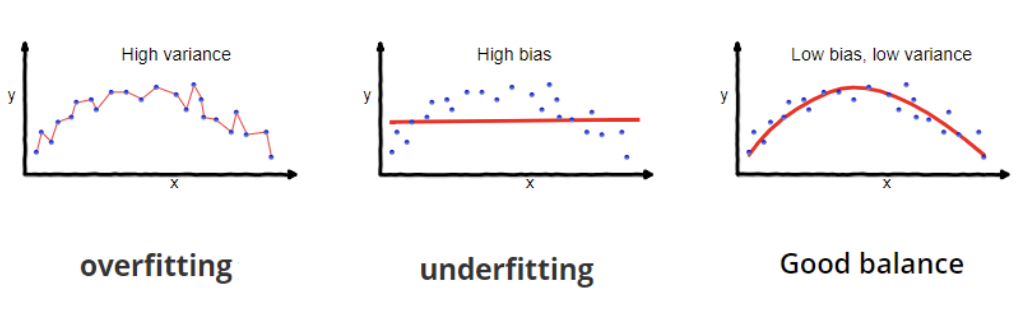
L'ajustement excessif et l'ajustement insuffisant. Source : Wikipedia.
Il est essentiel de comprendre le mécanisme des données manquantes (MCAR, MAR, MNAR), car cela oriente le choix des méthodes appropriées pour traiter les données manquantes. L'utilisation de techniques inappropriées peut introduire des biais, réduire la validité des résultats et conduire à des conclusions erronées. Par exemple, les méthodes d'imputation simples peuvent convenir aux données MCAR, tandis que des techniques plus sophistiquées telles que l'imputation multiple ou les méthodes basées sur un modèle peuvent être nécessaires pour les données MAR ou MNAR afin de produire des estimations non biaisées.
La suppression des valeurs manquantes peut être appropriée lorsque la proportion de données manquantes est très faible, généralement inférieure à 5 %. C'est également une bonne idée lorsque les données manquantes sont MCAR (Missing Completely at Random), ce qui signifie que l'absence de données n'introduit pas de biais. Enfin, j'envisagerais de supprimer les valeurs manquantes si l'ensemble de données est suffisamment important pour que la suppression d'un petit nombre de lignes n'ait pas d'impact significatif sur l'analyse.
Chaque méthode d'imputation a ses avantages et ses inconvénients. Par exemple, l'imputation moyenne/médiane/mode est facile à mettre en œuvre mais peut introduire des biais et fausser les relations entre les variables. L'imputation par K-voisins les plus proches (KNN) prend en compte les relations entre les variables et peut conduire à des résultats plus précis, mais elle peut être coûteuse en termes de calcul.
Le test A/B est une méthode utilisée dans la conception expérimentale pour comparer deux versions d'une variable, telle qu'une page web, une fonctionnalité d'application ou une campagne de marketing, afin de déterminer laquelle est la plus performante. Il s'agit d'un sujet très pertinent qui figure dans la section "requis" de nombreuses descriptions d'emploi.
La saisonnalité est l'une des composantes des séries temporelles, à côté de la tendance et des résidus (bruit). Pour détecter la saisonnalité, nous pouvons tout d'abord inspecter visuellement la série temporelle à l'aide d'un graphique linéaire. Si la présence d'une saisonnalité est suspectée, nous pouvons procéder à une décomposition de la série temporelle afin de déterminer l'ampleur de l'effet saisonnier.
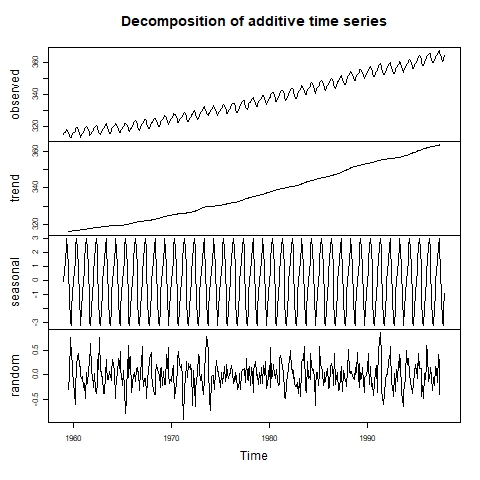
Séries temporelles visuellement décomposées. Source : Laboratoire d'informatique environnementale.
Les modèles de lissage exponentiel utilisent des moyennes pondérées des observations passées pour des prévisions simples et à court terme. Les modèles ARIMA combinent les composantes autorégression, différenciation et moyenne mobile, ce qui les rend plus complexes mais les rend adaptés aux prévisions à court et à long terme, en particulier avec des modèles complexes et des autocorrélations significatives.
La validation croisée est une technique permettant d'évaluer la généralisation d'un modèle d'apprentissage automatique à un ensemble de données indépendant. Il s'agit de diviser les données en plusieurs plis et d'effectuer plusieurs cycles de formation et de validation.
Étant donné que le perfectionnement des statistiques et des résultats d'analyse n'est pas complet sans la communication des résultats aux parties prenantes de l'entreprise, il est essentiel pour les employeurs qui recrutent pour des postes liés aux données de disposer de compétences non techniques, d'autant plus qu'il n'est jamais facile de communiquer des informations à partir de statistiques.
Pour communiquer efficacement avec les différentes parties prenantes, j'adapte mon style en fonction de leurs antécédents et de leurs intérêts. Par exemple, pour les cadres, je donne la priorité à l'impact sur l'entreprise, en utilisant un langage professionnel et des images pour faciliter une prise de décision rapide. En revanche, pour les développeurs, je fournis des détails techniques. Dans les deux cas, je m'assure que les concepts impliqués sont clairs et accessibles, et j'encourage les questions et les commentaires. Cette approche garantit que chaque groupe de parties prenantes reçoit les informations dont il a besoin dans un format qui lui convient.
L'apprentissage des statistiques pour les fonctions d'analyse de données peut s'avérer difficile. De nombreuses personnes arrivent dans ce domaine après avoir suivi des formations diverses qui n'impliquent pas nécessairement de connaissances statistiques. La plupart des ressources disponibles en ligne encouragent les apprenants à se concentrer uniquement sur les outils, en négligeant l'importance vitale des statistiques.
Pour améliorer vos connaissances et vos perspectives de carrière, envisagez d'explorer des ressources et des cours supplémentaires. Pour un guide détaillé sur la façon de devenir statisticien, consultez notre article de blog, Comment devenir statisticien, qui offre des informations précieuses. Vous pouvez compléter cela avec notre cursus de carrière Statisticien avec R. Prenez le temps de tester votre intuition avec le cours Probability Puzzles in R. Si vous préférez Python, notre cursus de compétences Fondamentaux de la statistique avec Python est une excellente option.
Bonne chance pour vos prochains entretiens !
Apprenez les statistiques avec DataCamp
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Matt Crabtree
14 min
Tutoriel
Samuel Shaibu
