
Curso
Practicando preguntas de entrevistas de estadística en Python
4 h
16.5K
Dominar las herramientas de la analítica de datos sin comprender los conceptos que hay detrás es como tener una caja de herramientas con destornilladores, pero no saber cuándo y cómo utilizar cada destornillador. Es importante aprender estadística porque el auge de las herramientas de análisis generadas y asistidas por IA hará que las habilidades técnicas dejen de ser una ventaja competitiva en favor de la comprensión de conocimientos y la comprensión crítica.
Te invito a que no te dejes intimidar por la complejidad de las estadísticas. Este artículo pretende presentar una guía completa de los conceptos estadísticos más relevantes para los analistas y científicos de datos a través de 35 preguntas y respuestas de entrevistas sobre estadística. Tanto si te estás preparando para una entrevista como si no, estoy seguro de que estas preguntas te resultarán informativas.
Por último, antes de empezar, considera la posibilidad de realizar nuestro curso Introducción a la Estadística en R para aprender los fundamentos, incluido cómo realizar análisis estadísticos e interpretar los resultados. Además, si te estás preparando activamente para una entrevista que requiere conocimientos estadísticos, los dos cursos DataCamp siguientes cubren todos los temas estadísticos más frecuentes: Preguntas prácticas para entrevistas de estadística en Python y Preguntas prácticas para entrevistas de estadística en R.
La mayoría de los trabajos de análisis de datos, si no todos, requieren conocimientos básicos de estadística, incluida la estadística descriptiva, la estadística inferencial y la probabilidad. Si quieres repasar tus conocimientos de estadística descriptiva antes de una entrevista, descárgate nuestra Ficha de Estadística Descriptiva para consultarla fácilmente. Además, si quieres trabajar con algunos cálculos y métodos, consulta los siguientes tutoriales de DataCamp para profundizar en los conceptos relevantes:
Tanto la varianza como la desviación típica miden la dispersión o dispersión de un conjunto de datos. La varianza es la media de las diferencias al cuadrado respecto a la media. Da una idea de cuánto difieren de la media los valores de un conjunto de datos. Sin embargo, como utiliza diferencias al cuadrado, las unidades también son al cuadrado, lo que puede resultar menos intuitivo que la desviación típica. La desviación típica es la raíz cuadrada de la varianza, con lo que las unidades vuelven a ser las mismas que los datos originales. Proporciona una medida más interpretable de la dispersión. Por ejemplo, si la varianza de un conjunto de datos es 25, la desviación típica es √25 = 5.
La asimetría mide la asimetría de un conjunto de datos en torno a su media, que puede ser positiva, negativa o cero. Los datos con asimetría positiva, o datos sesgados a la derecha, tienen una cola derecha más larga, lo que significa que la media es mayor que la mediana. Los datos con asimetría negativa, o datos sesgados a la izquierda, tienen una cola izquierda más larga, lo que significa que la media es menor que la mediana. La asimetría cero indica una distribución simétrica, como una distribución normal, en la que la media, la mediana y la moda son iguales.
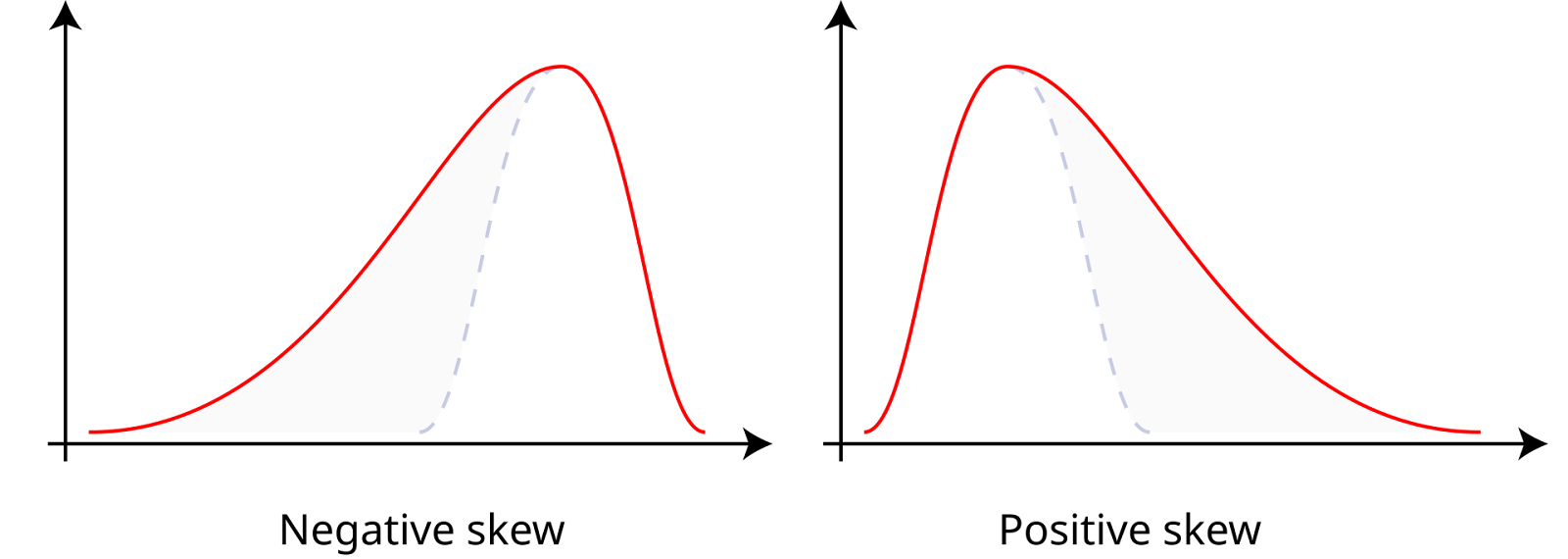
Asimetría positiva y negativa. Fuente: Wikiversidad.
Un histograma es una representación gráfica de la distribución de un conjunto de datos. Divide los datos en bins (intervalos) y muestra la frecuencia (o recuento) de puntos de datos dentro de cada bin. Los histogramas se utilizan para comprender la distribución de frecuencias subyacente (forma) de un conjunto de datos continuos. Ayudan a identificar patrones como la asimetría, la modalidad (número de picos) y la presencia de valores atípicos.
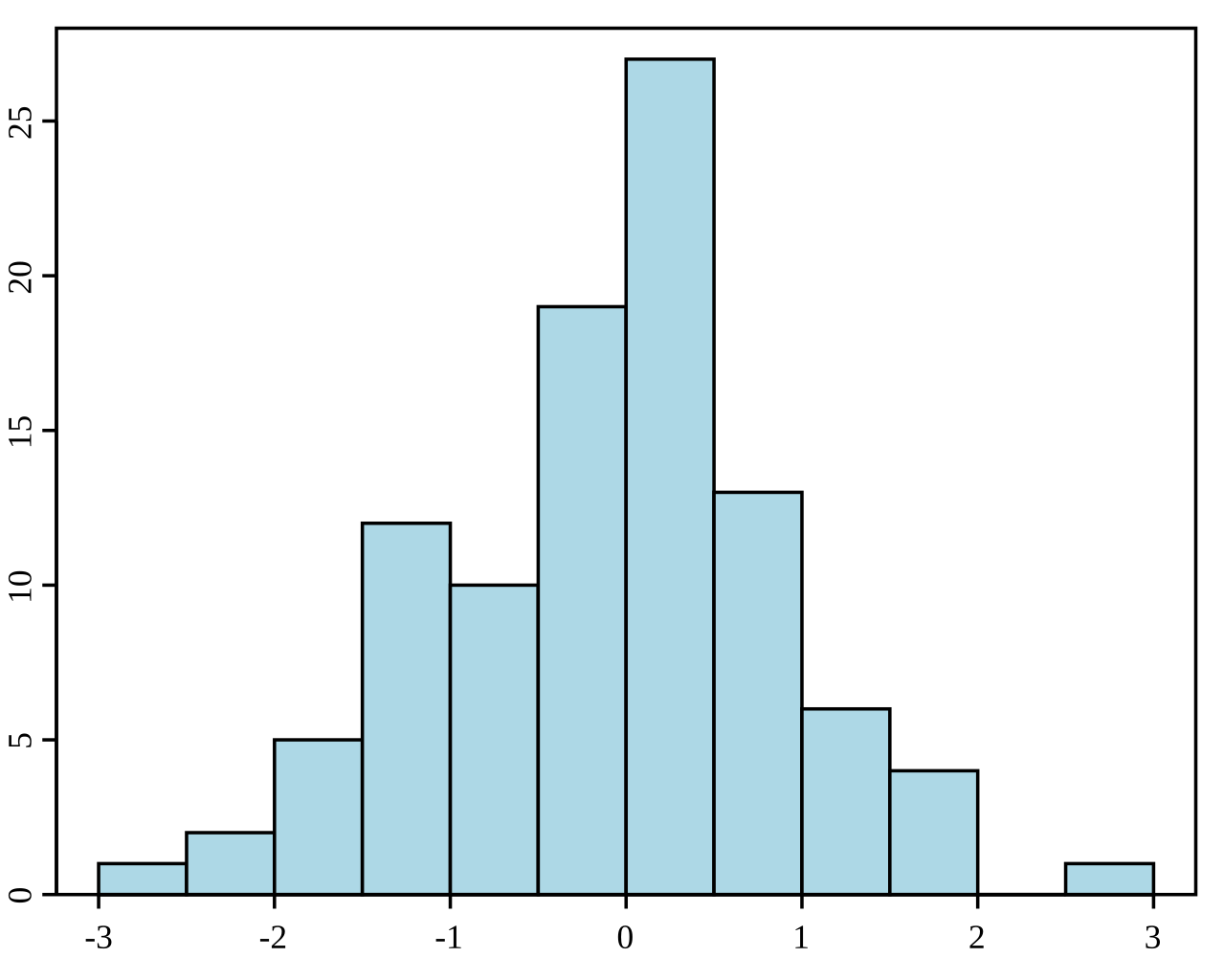
Ejemplo de histograma. Fuente: Wikipedia.
La estadística inferencial consiste en hacer predicciones o inferencias sobre una población a partir de una muestra aleatoria de datos tomados de esa población. Utiliza diversos métodos para estimar los parámetros de la población, probar hipótesis y hacer predicciones. Mientras que la estadística descriptiva resume y describe las características de un conjunto de datos, la estadística inferencial utiliza los datos para hacer generalizaciones y sacar conclusiones sobre una población más amplia.
Se utilizan distintos métodos de muestreo para garantizar que las muestras sean representativas y aleatorias. El muestreo aleatorio simple da a cada miembro de la población las mismas posibilidades de ser seleccionado. El muestreo sistemático consiste en seleccionar cada k-ésimo miembro de la población, partiendo de un punto elegido al azar. El muestreo estratificado divide la población en estratos o subgrupos, y se toman muestras aleatorias de cada estrato. El muestreo por conglomerados divide la población en conglomerados, selecciona aleatoriamente algunos conglomerados y muestrea a todos sus miembros.
El teorema del límite central afirma que la distribución muestral de la media muestral se aproximará a una distribución normal a medida que aumente el tamaño de la muestra, independientemente de la distribución de la población, siempre que las muestras sean independientes e idénticamente distribuidas.
La probabilidad marginal se refiere a la probabilidad de que ocurra un único suceso, independientemente de otros sucesos, representada como P(A) para el suceso A. La probabilidad conjunta es la probabilidad de que ocurran dos sucesos juntos, representada como P(A∩B) para los sucesos A y B. La probabilidad condicional es la probabilidad de que ocurra un suceso dado que ha ocurrido otro suceso, expresada como P(A|B) para los sucesos A y B.
Una distribución de probabilidad describe cómo se distribuyen los valores de una variable aleatoria. Proporciona una función que asigna los resultados de una variable aleatoria a sus probabilidades correspondientes. Hay dos tipos principales de distribuciones de probabilidad. Una es la distribución de probabilidad discreta para variables aleatorias discretas, como la distribución binomial o la distribución de Poisson. La otra es la distribución de probabilidad continua para variables aleatorias continuas, como la distribución normal o la distribución exponencial.
La distribución normal, también conocida como distribución de Gauss, es una distribución de probabilidad continua caracterizada por su curva en forma de campana, que es simétrica respecto a la media. En las distribuciones normales, la media es, por tanto, igual a la mediana. Además, se sabe que aproximadamente el 68% de los datos caen dentro de una desviación típica de la media, el 95% dentro de dos desviaciones típicas y el 99,7% dentro de tres desviaciones típicas. Esto se conoce como la Regla 68-95-99,7.
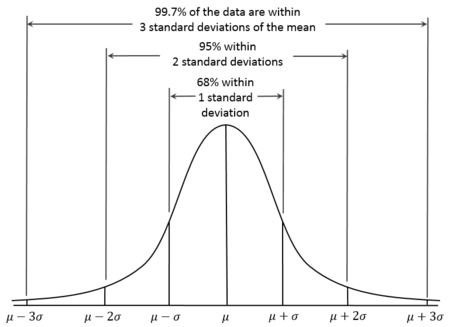
Curva de distribución normal. Fuente: Wikiversidad.
La distribución binomial es una distribución de probabilidad discreta que modela el número de aciertos en un número fijo de ensayos Bernoulli independientes, cada uno con la misma probabilidad de acierto. Se utiliza cuando hay exactamente dos resultados posibles (éxito y fracaso) para cada ensayo. Por ejemplo, puede utilizarse para modelar el número de caras en una serie de lanzamientos de monedas.
La distribución de Poisson es una distribución de probabilidad discreta que modela el número de sucesos que ocurren en un intervalo fijo de tiempo o espacio, en el que los sucesos ocurren independientemente y a una tasa media constante. Es adecuado utilizarlo cuando quieras modelizar el recuento de sucesos poco frecuentes, como el número de correos electrónicos recibidos en una hora o el número de terremotos en un año.
Para las funciones intermedias de estadística, céntrate en las pruebas de hipótesis, la estimación de intervalos y los modelos de regresión. Si, al leer estas preguntas, no te sientes seguro con algunos de los conceptos, puedes recurrir a los recursos de DataCamp. Puedes aprender a realizar pruebas de hipótesis a través de los cursos Pruebas de Hipótesis en Python y Pruebas de Hipótesis en R. También puedes dominar las técnicas de regresión con los siguientes cursos y tutoriales:
Un valor p es la probabilidad de obtener una estadística de prueba al menos tan extrema como la observada, suponiendo que la hipótesis nula sea cierta. Se utiliza en la comprobación de hipótesis para determinar la significación del resultado de la prueba. Si el valor p es menor o igual que el nivel de significación elegido (α), rechazamos la hipótesis nula. Si el valor p es mayor que α, no rechazamos la hipótesis nula.
Los errores de tipo I en las pruebas de hipótesis se producen cuando la hipótesis nula es verdadera, pero la rechazamos incorrectamente, lo que da lugar a un falso positivo. La probabilidad de cometer un error de tipo I es la misma que el nivel de significación. Los errores de tipo II se producen cuando la hipótesis nula es falsa, pero no logramos rechazarla, lo que da lugar a un falso negativo.
Las pruebas paramétricas suponen que los datos siguen una distribución específica, como la normal, y requieren ciertos parámetros poblacionales, por lo que son ideales cuando se cumplen estos supuestos. Algunos ejemplos de pruebas paramétricas que suelo utilizar son la prueba t, la prueba Z y el ANOVA. Las pruebas no paramétricas no asumen una distribución específica y se utilizan cuando los datos no cumplen los supuestos paramétricos, especialmente con muestras pequeñas. Muchas personas están familiarizadas con estas pruebas, pero no las identifican necesariamente como no paramétricas. He utilizado la prueba Chi-cuadrado, la prueba U de Mann-Whitney, la prueba de rango con signo de Wilcoxon y la prueba de Kruskal-Wallis, por nombrar algunas.
El análisis de regresión es un método estadístico utilizado para examinar la relación entre una variable dependiente y una o más variables independientes. Ayuda a comprender cómo cambia la variable dependiente cuando varía alguna de las variables independientes, mientras que las demás variables independientes se mantienen constantes.
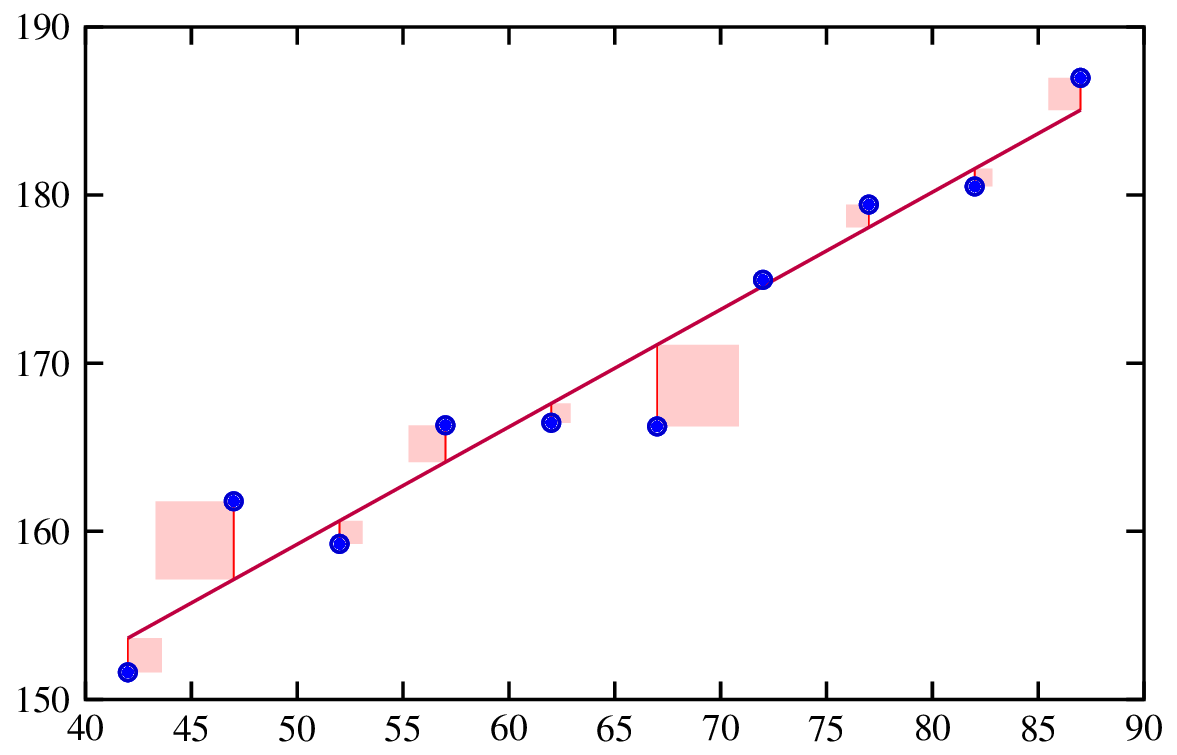
Ajustar una recta de regresión. Fuente: Ingeniería de riesgos.
Los residuos son las diferencias entre los valores observados y los valores predichos de un modelo de regresión. Son importantes porque analizar los residuos ayuda a comprobar los supuestos de nuestro modelo, así como a comprobar el ajuste general del modelo.
En un modelo de regresión lineal, cada coeficiente representa el cambio esperado en la variable dependiente para un cambio de una unidad en la variable independiente correspondiente, manteniendo constantes todas las demás variables. Por ejemplo, si el coeficiente de una variable independiente 𝑥𝑖 es 2, significa que por cada aumento de una unidad en 𝑥𝑖 se espera que la variable dependiente y aumente 2 unidades, suponiendo que las demás variables permanezcan invariables.
Un intervalo de confianza del 95% significa que si tomáramos muchas muestras y calculáramos un intervalo de confianza para cada muestra, aproximadamente el 95% de estos intervalos contendrían el verdadero parámetro poblacional. También podríamos decir que tenemos un 95% de confianza en que el valor del parámetro se encuentra en el intervalo estimado.
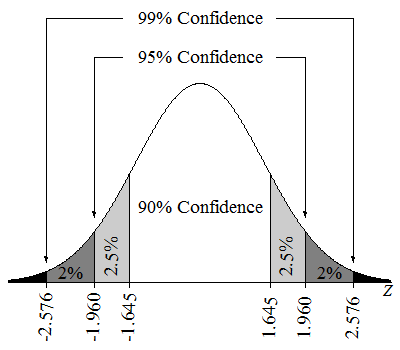
Intervalos de confianza en una distribución Z. Fuente: Aprendizaje Lumen.
La multicolinealidad se produce cuando dos o más variables independientes de un modelo de regresión múltiple están muy correlacionadas. Es un problema porque puede hacer que las estimaciones de los coeficientes sean inestables y difíciles de interpretar. Una multicolinealidad elevada también puede inflar los errores estándar de los coeficientes, lo que da lugar a pruebas estadísticas menos fiables.
Las técnicas de regularización son una potente técnica para tratar la multicolinealidad en los modelos de regresión. También se utilizan para evitar el sobreajuste, añadiendo una penalización al modelo por tener coeficientes grandes. Esto ayuda a crear un modelo más generalizable. Entre las técnicas habituales de regularización están el Lasso y la Regresión Ridge.
Si me estuviera preparando para una entrevista que requiriera conocimientos avanzados de estadística, me aseguraría de estudiar estadística bayesiana y aprendizaje automático.
Para la estadística bayesiana, explora nuestros cursos: Análisis Bayesiano de Datos en Python y Fundamentos del Análisis Bayesiano de Datos en R. Para el aprendizaje automático, consulta los itinerarios profesionales o cursos DataCamp sobre aprendizaje automático, incluido nuestro itinerario profesional Científico de Aprendizaje Automático con Python y nuestro curso Comprender el Aprendizaje Automático.
La estadística bayesiana implica el uso del teorema de Bayes para actualizar la probabilidad de una hipótesis a medida que se dispone de más pruebas o información. Combina las creencias previas con los nuevos datos para formar una probabilidad posterior.
Markov Chain Monte Carlo es una clase de algoritmos utilizados para muestrear a partir de una distribución de probabilidad cuando el muestreo directo es difícil. Es importante en la estadística bayesiana porque permite estimar las distribuciones posteriores, especialmente en modelos complejos en los que las soluciones analíticas no son factibles.
El equilibrio entre sesgo y varianza en el aprendizaje automático implica equilibrar dos fuentes de error. El sesgo es el error derivado de unas suposiciones del modelo demasiado simplistas, que provocan un ajuste insuficiente y la falta de patrones de datos. La varianza es el error derivado de una sensibilidad excesiva a las fluctuaciones de los datos de entrenamiento, que provoca un ajuste excesivo y capta ruido en lugar de patrones verdaderos.
La inferencia causal es una idea importante que ha estado recibiendo mucha atención. La inferencia causal es el proceso de determinar si una variable (la causa) afecta directamente a otra variable (el efecto) y cómo lo hace, lo que constituye una característica distintiva entre la inferencia causal y la mera correlación. La inferencia causal es, en realidad, un grupo de métodos cuyo objetivo es establecer una relación causa-efecto para comprender si algo funciona, como una intervención o un tratamiento de algún tipo. Si un investigador necesita saber si un fármaco funciona, por ejemplo, la inferencia causal puede ayudar a responder a la pregunta.
El Modelado de Ecuaciones Estructurales es una técnica para analizar las relaciones entre lo que se denominan variables observadas y latentes. Es una especie de mezcla entre regresión múltiple y análisis factorial. El modelado de ecuaciones estructurales requiere múltiples pasos, como la especificación del modelo, la estimación y, después, la evaluación. El SEM es conocido por su flexibilidad, pero requiere muestras de gran tamaño y, para utilizarlo, necesitarás una sólida base teórica.
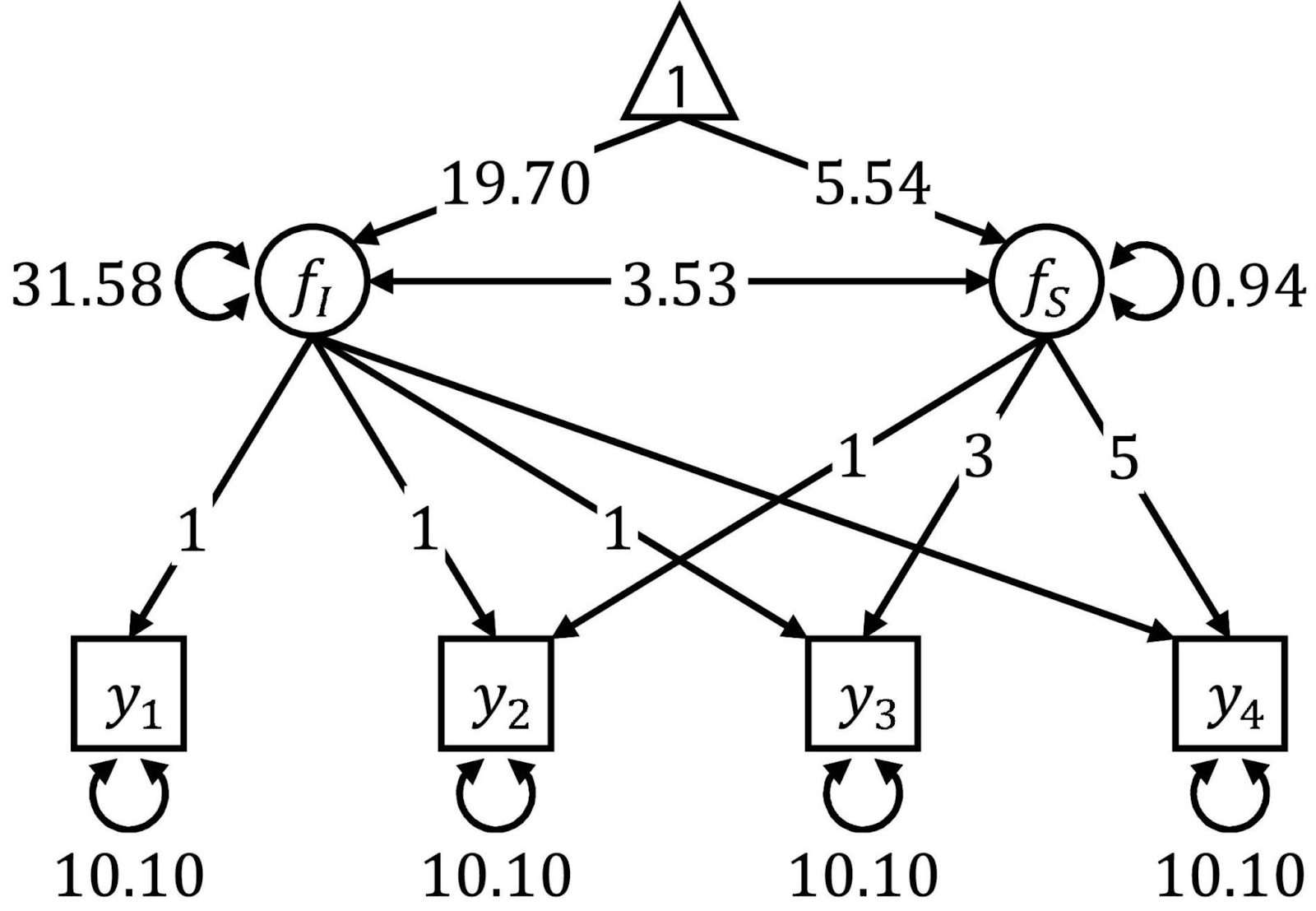
Los diagramas de trayectorias se utilizan a menudo para visualizar SEM. Fuente: Frontiers.
Las siguientes preguntas te resultarán útiles si aspiras a un puesto más centrado en la intersección de la ciencia de datos y la estadística. Los temas incluyen el preprocesamiento y la limpieza de datos, las pruebas A/B y el diseño experimental, la previsión de series temporales y las técnicas estadísticas avanzadas.
Si te encuentras tembloroso en estos conceptos y te tomas en serio la mejora de tu proceso de entrevistas, toma estos recursos de DataCamp sobre las pruebas A/B: Curso de Pruebas A/B en Python o Curso de Pruebas A/B en R. Después, para dominar el análisis de series temporales, elige entre las vías de habilidad Series Tempor ales con R o Series Temporales con Python para adquirir experiencia.
Dividir los datos en conjuntos de entrenamiento y de prueba nos ayuda a evaluar el rendimiento del modelo en datos no vistos. El conjunto de entrenamiento se utiliza para entrenar el modelo, mientras que el conjunto de prueba se utiliza para evaluar lo bien que el modelo generaliza a los nuevos datos. Esta práctica ayuda a detectar el sobreajuste y garantiza que el modelo pueda funcionar bien con datos del mundo real.
La sobreadaptación se produce cuando un modelo aprende tanto los patrones subyacentes como el ruido de los datos de entrenamiento, lo que conduce a un rendimiento excelente en los datos de entrenamiento, pero a un rendimiento deficiente en los nuevos datos no vistos. La inadaptación se produce cuando un modelo es demasiado simple para captar los patrones subyacentes en los datos, lo que da lugar a un rendimiento deficiente tanto en los datos de entrenamiento como en los nuevos datos.
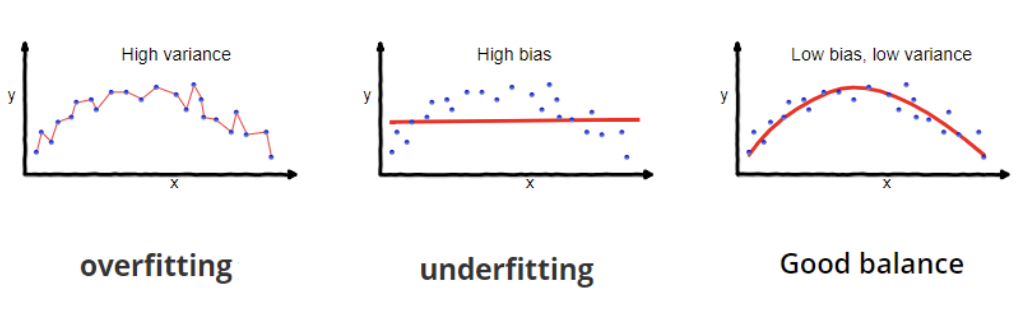
Sobreajuste e infraajuste. Fuente: Wikipedia.
Comprender el mecanismo de la omisión (MCAR, MAR, MNAR) es crucial porque orienta la elección de los métodos adecuados para tratar los datos omitidos. Utilizar técnicas inadecuadas puede introducir sesgos, reducir la validez de los resultados y llevar a conclusiones incorrectas. Por ejemplo, los métodos de imputación simples pueden ser adecuados para los datos MCAR, mientras que técnicas más sofisticadas como la imputación múltiple o los métodos basados en modelos pueden ser necesarios para que los datos MAR o MNAR produzcan estimaciones insesgadas.
Eliminar los valores omitidos puede ser adecuado cuando la proporción de datos omitidos es muy pequeña, normalmente inferior al 5%. Además, es una buena idea cuando los datos omitidos son MCAR (Missing Completely at Random), lo que significa que la omisión no introduce sesgo. Por último, yo consideraría la posibilidad de eliminar los valores perdidos si el conjunto de datos es lo suficientemente grande como para que la eliminación de un pequeño número de filas no afecte significativamente al análisis.
Cada método de imputación tiene sus pros y sus contras. Por ejemplo, la imputación media/mediana/modo es fácil de aplicar, pero puede introducir sesgos y distorsionar las relaciones entre las variables. La imputación K-vecinos más cercanos (KNN) tiene en cuenta las relaciones entre variables y puede dar lugar a resultados más precisos, pero puede ser costosa desde el punto de vista informático.
Las pruebas A/B son un método utilizado en el diseño experimental para comparar dos versiones de una variable, como una página web, una función de una aplicación o una campaña de marketing, para determinar cuál funciona mejor. Es un tema muy relevante y aparece en la sección "obligatorio" de muchas descripciones de puestos de trabajo.
La estacionalidad es uno de los componentes de las series temporales, además de la tendencia y los residuos (ruido). Para detectar la estacionalidad, primero podemos inspeccionar visualmente la serie temporal mediante un gráfico de líneas. Si se sospecha la presencia de estacionalidad, podemos proceder a aplicar una descomposición de la serie temporal para hallar la magnitud del efecto estacional.
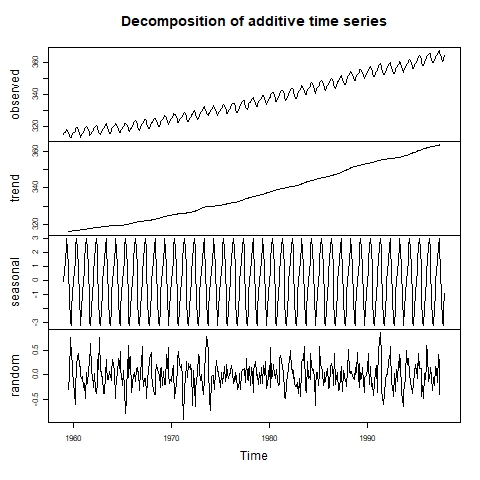
Series temporales descompuestas visualmente. Fuente: Laboratorio de Informática Ambiental.
Los modelos de Alisamiento Exponencial utilizan medias ponderadas de observaciones pasadas para realizar previsiones simples a corto plazo. Los modelos ARIMA combinan componentes de autoregresión, diferenciación y media móvil, lo que los hace más complejos pero adecuados para la previsión tanto a corto como a largo plazo, especialmente con patrones complejos y autocorrelaciones significativas.
La validación cruzada es una técnica para evaluar cómo generalizará un modelo de aprendizaje automático a un conjunto de datos independiente. Implica dividir los datos en varios pliegues y realizar varias rondas de entrenamiento y validación.
Puesto que el perfeccionamiento de las estadísticas y los resultados de los análisis no está completo sin la comunicación de los resultados a las partes interesadas de la empresa, la asistencia a las habilidades interpersonales es vital para los empleadores que contratan para puestos relacionados con los datos, sobre todo porque comunicar las percepciones de las estadísticas nunca es fácil.
Para comunicarme eficazmente con las distintas partes interesadas, ajusto mi estilo en función de sus antecedentes e intereses. Por ejemplo, para los ejecutivos, priorizo el impacto empresarial, utilizando lenguaje empresarial y visuales para facilitar la toma rápida de decisiones. Por otro lado, para los desarrolladores, proporciono detalles técnicos. En ambos casos, me aseguro de que los conceptos implicados sean pertinentes, claros y accesibles, y animo a que se formulen preguntas y comentarios. Este enfoque garantiza que cada grupo de interesados reciba la información que necesita en un formato que les resulte familiar.
Aprender estadística para funciones de análisis de datos puede ser un reto. Muchas personas se incorporan a este campo desde diversos ámbitos que no implican necesariamente muchos o ningún conocimiento estadístico. La mayoría de los recursos disponibles en Internet animan a los alumnos a centrarse sólo en las herramientas, pasando por alto la importancia vital de las estadísticas.
Para mejorar aún más tus conocimientos y oportunidades profesionales, considera la posibilidad de explorar recursos y cursos adicionales. Para obtener una guía detallada sobre cómo convertirse en estadístico, consulta nuestra entrada del blog, Cómo convertirse en estadístico, que ofrece valiosas ideas. Puedes complementarlo con nuestro itinerario profesional de Estadístico con R. Tómate tu tiempo para poner a prueba tu intuición con el curso Puzzles de Probabilidad en R. Si prefieres Python, nuestro itinerario de conocimientos Fundamentos de Estadística con Python es una gran opción.
¡Mucha suerte en tus próximas entrevistas!
Aprende Estadística con DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Matt Crabtree
12 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
9 min
blog
Austin Chia
15 min

