
Curso
Praticando perguntas de entrevista de Estatística em Python
4 h
16.5K
Dominar as ferramentas de análise de dados sem entender os conceitos por trás delas é como ter uma caixa de ferramentas com chaves de fenda, mas sem saber quando e como usar cada uma delas. É importante aprender estatística porque o aumento das ferramentas de análise geradas e assistidas por IA tornará as habilidades técnicas menos competitivas em favor da compreensão do conhecimento e do entendimento crítico.
Convido você a não se intimidar com a complexidade das estatísticas. Este artigo tem como objetivo apresentar um guia abrangente dos conceitos estatísticos mais relevantes para analistas e cientistas de dados por meio de 35 perguntas e respostas de entrevistas sobre estatística. Esteja você se preparando para uma entrevista ou não, tenho certeza de que achará essas perguntas informativas.
Por fim, antes de começarmos, considere fazer nosso curso Introdução à estatística em R para aprender os fundamentos, inclusive como realizar análises estatísticas e interpretar resultados. Além disso, se você estiver se preparando ativamente para uma entrevista que exija conhecimento estatístico, os dois cursos DataCamp a seguir abordam todos os tópicos estatísticos mais frequentes: Praticando perguntas de entrevista de estatística em Python e Praticando perguntas de entrevista de estatística em R.
A maioria dos trabalhos de análise de dados, se não todos, exige um conhecimento básico de estatística, incluindo estatística descritiva, estatística inferencial e probabilidade. Se você estiver aprimorando suas estatísticas descritivas antes de uma entrevista, faça o download da nossa Folha de consulta de estatísticas descritivas para facilitar a consulta. Além disso, se você quiser trabalhar com alguns cálculos e métodos, confira os tutoriais do DataCamp a seguir para analisar os conceitos relevantes com mais detalhes:
A variância e o desvio padrão medem a dispersão ou o spread de um conjunto de dados. A variância é a média das diferenças quadráticas em relação à média. Ela dá uma ideia de quanto os valores em um conjunto de dados diferem da média. Entretanto, como ele usa diferenças quadradas, as unidades também são quadradas, o que pode ser menos intuitivo do que o desvio padrão. O desvio padrão é a raiz quadrada da variação, o que faz com que as unidades voltem a ser as mesmas dos dados originais. Ele fornece uma medida mais interpretável de propagação. Por exemplo, se a variação de um conjunto de dados for 25, o desvio padrão será √25 = 5.
A assimetria mede a assimetria de um conjunto de dados em torno de sua média, que pode ser positiva, negativa ou zero. Os dados com assimetria positiva, ou dados com assimetria à direita, têm uma cauda direita mais longa, o que significa que a média é maior que a mediana. Os dados com assimetria negativa, ou dados com assimetria à esquerda, têm uma cauda esquerda mais longa, o que significa que a média é menor que a mediana. A assimetria zero indica uma distribuição simétrica, como uma distribuição normal, em que a média, a mediana e a moda são iguais.
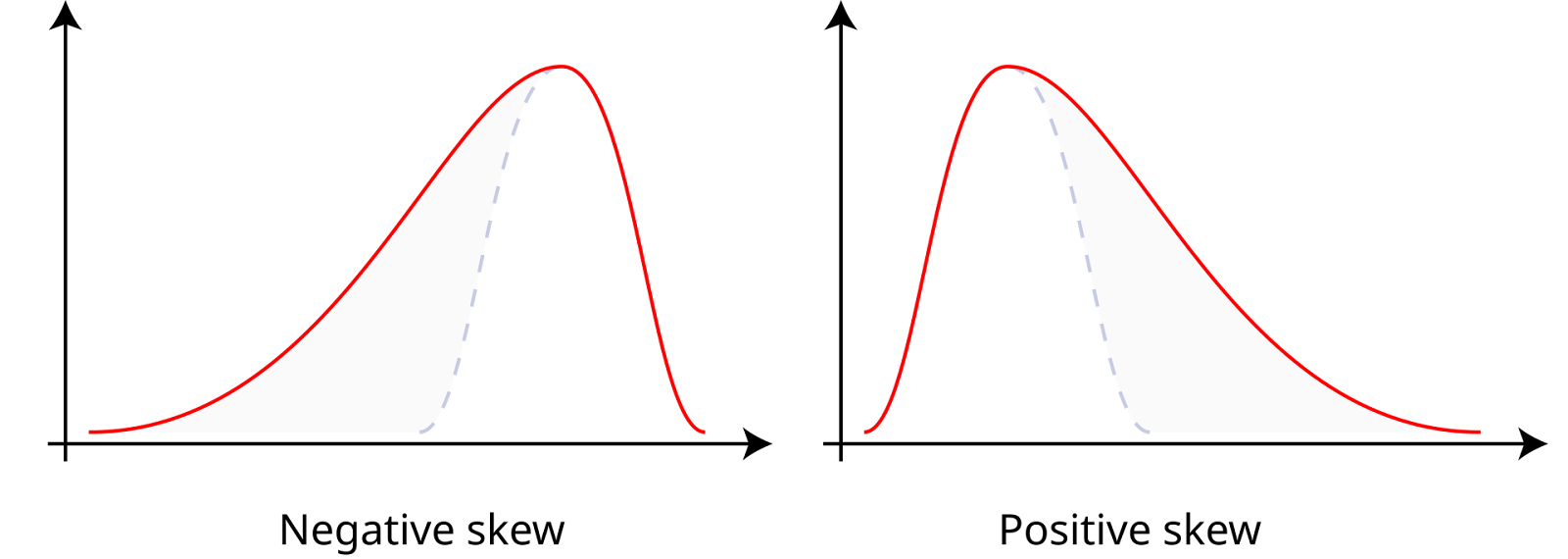
Skewness positivo e negativo. Fonte: Wikiversidade.
Um histograma é uma representação gráfica da distribuição de um conjunto de dados. Ele divide os dados em compartimentos (intervalos) e mostra a frequência (ou contagem) dos pontos de dados em cada compartimento. Os histogramas são usados para entender a distribuição de frequência subjacente (forma) de um conjunto de dados contínuos. Eles ajudam a identificar padrões como distorção, modalidade (número de picos) e a presença de discrepâncias.
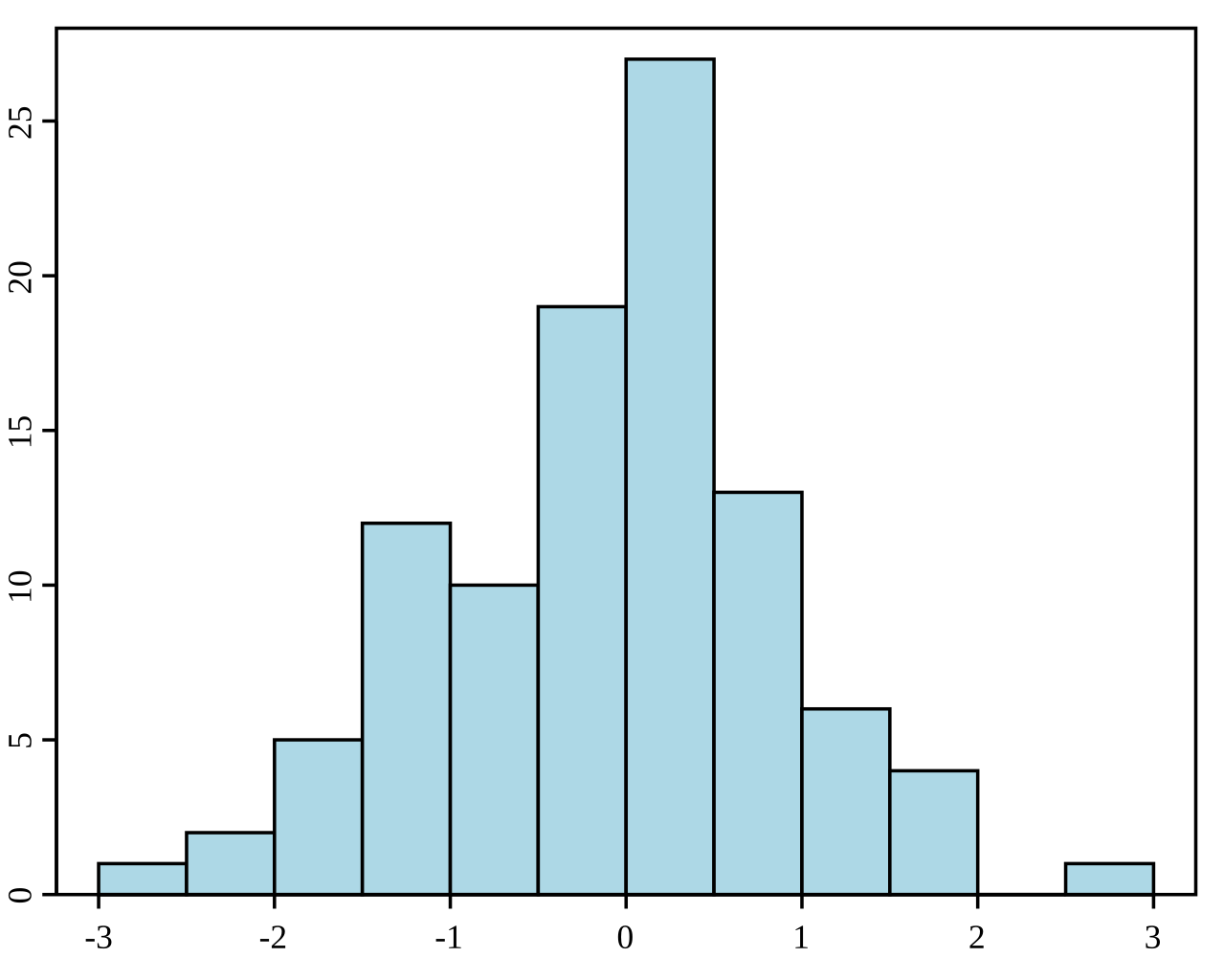
Exemplo de um histograma. Fonte: Wikipedia.
A estatística inferencial envolve fazer previsões ou inferências sobre uma população com base em uma amostra aleatória de dados extraídos dessa população. Ele usa vários métodos para estimar parâmetros populacionais, testar hipóteses e fazer previsões. Enquanto as estatísticas descritivas resumem e descrevem os recursos de um conjunto de dados, as estatísticas inferenciais usam os dados para fazer generalizações e tirar conclusões sobre uma população maior.
Diferentes métodos de amostragem são usados para garantir que as amostras sejam representativas e aleatórias. A amostragem aleatória simples dá a cada membro da população a mesma chance de ser selecionado. A amostragem sistemática envolve a seleção de cada k-ésimo membro da população, a partir de um ponto escolhido aleatoriamente. A amostragem estratificada divide a população em estratos ou subgrupos, com amostras aleatórias retiradas de cada estrato. A amostragem por cluster divide a população em clusters, selecionando aleatoriamente alguns clusters e amostrando todos os membros dentro deles.
O teorema do limite central afirma que a distribuição de amostragem da média da amostra se aproximará de uma distribuição normal à medida que o tamanho da amostra aumenta, independentemente da distribuição da população, desde que as amostras sejam independentes e distribuídas de forma idêntica.
A probabilidade marginal se refere à probabilidade de ocorrência de um único evento, independentemente de outros eventos, denotada como P(A) para o evento A. A probabilidade conjunta é a probabilidade de dois eventos ocorrerem juntos, representada como P(A∩B) para os eventos A e B. A probabilidade condicional é a probabilidade de ocorrência de um evento, considerando que outro evento tenha ocorrido, expressa como P(A|B) para os eventos A e B.
Uma distribuição de probabilidade descreve como os valores de uma variável aleatória são distribuídos. Ele fornece uma função que mapeia os resultados de uma variável aleatória para suas probabilidades correspondentes. Há dois tipos principais de distribuições de probabilidade. Uma é a distribuição de probabilidade discreta para variáveis aleatórias discretas, como a distribuição binomial ou a distribuição de Poisson. A outra é a distribuição de probabilidade contínua para variáveis aleatórias contínuas, como a distribuição normal ou a distribuição exponencial.
A distribuição normal, também conhecida como distribuição gaussiana, é uma distribuição de probabilidade contínua caracterizada por sua curva em forma de sino, que é simétrica em relação à média. Com distribuições normais, a média é, portanto, igual à mediana. Além disso, sabe-se que cerca de 68% dos dados estão dentro de um desvio padrão da média, 95% dentro de dois desvios padrão e 99,7% dentro de três desvios padrão. Isso é conhecido como a regra 68-95-99.7.
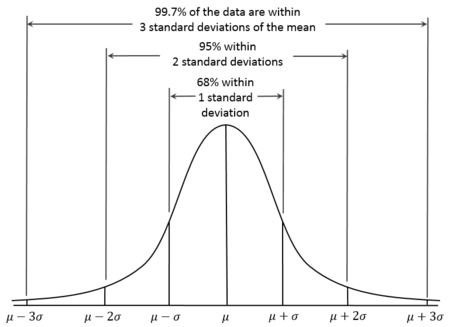
Curva de distribuição normal. Fonte: Wikiversidade.
A distribuição binomial é uma distribuição de probabilidade discreta que modela o número de sucessos em um número fixo de tentativas independentes de Bernoulli, cada uma com a mesma probabilidade de sucesso. Ele é usado quando há exatamente dois resultados possíveis (sucesso e fracasso) para cada tentativa. Por exemplo, ele pode ser usado para modelar o número de caras em uma série de lançamentos de moedas.
A distribuição de Poisson é uma distribuição de probabilidade discreta que modela o número de eventos que ocorrem em um intervalo fixo de tempo ou espaço, em que os eventos ocorrem independentemente e a uma taxa média constante. Ele é apropriado para ser usado quando você deseja modelar a contagem de eventos raros, como o número de e-mails recebidos em uma hora ou o número de terremotos em um ano.
Para funções estatísticas intermediárias, concentre-se em testes de hipóteses, estimativa de intervalos e modelagem de regressão. Se, ao ler essas perguntas, você não se sentir confiante com alguns dos conceitos, poderá recorrer aos recursos do DataCamp. Você pode aprender sobre testes de hipóteses por meio dos cursos Hypothesis Testing in Python e Hypothesis Testing in R. Você também pode dominar as técnicas de regressão com os seguintes cursos e tutoriais:
Um valor p é a probabilidade de você obter uma estatística de teste pelo menos tão extrema quanto a observada, supondo que a hipótese nula seja verdadeira. É usado em testes de hipóteses para determinar a importância do resultado do teste. Se o valor p for menor ou igual ao nível de significância escolhido (α), rejeitamos a hipótese nula. Se o valor de p for maior que α, não rejeitaremos a hipótese nula.
Os erros do tipo I no teste de hipóteses ocorrem quando a hipótese nula é verdadeira, mas nós a rejeitamos incorretamente, resultando em um falso positivo. A probabilidade de você cometer um erro do Tipo I é a mesma do nível de significância. Os erros do tipo II ocorrem quando a hipótese nula é falsa, mas não conseguimos rejeitá-la, levando a um falso negativo.
Os testes paramétricos presumem que os dados seguem uma distribuição específica, como a normal, e exigem determinados parâmetros populacionais, o que os torna ideais quando essas suposições são atendidas. Alguns exemplos de testes paramétricos que costumo usar são o teste t, o teste Z e a ANOVA. Os testes não paramétricos não pressupõem uma distribuição específica e são usados quando os dados não atendem às pressuposições paramétricas, especialmente com amostras pequenas. Muitas pessoas estão familiarizadas com esses testes, mas não os identificam necessariamente como não paramétricos. Usei o teste Qui-Quadrado, o teste U de Mann-Whitney, o teste Wilcoxon Signed-Rank e o teste Kruskal-Wallis, para citar alguns.
A análise de regressão é um método estatístico usado para examinar a relação entre uma variável dependente e uma ou mais variáveis independentes. Ela ajuda a entender como a variável dependente muda quando uma das variáveis independentes varia, enquanto as outras variáveis independentes são mantidas constantes.
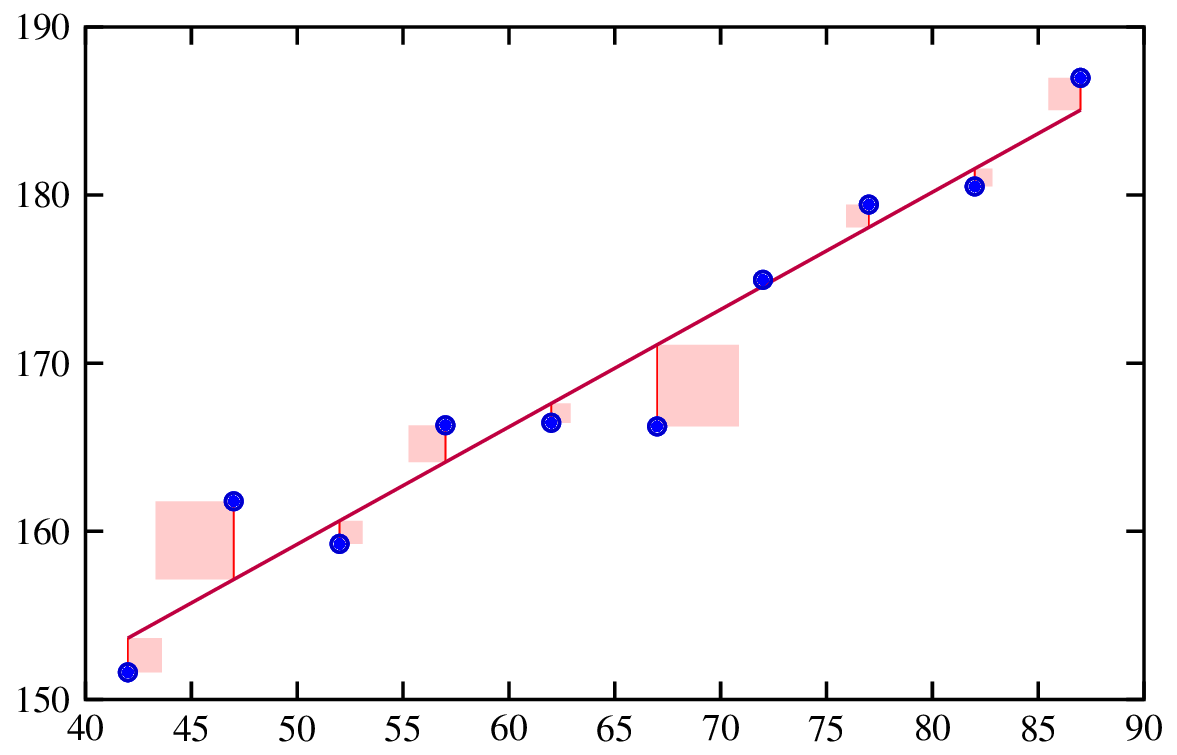
Ajuste de uma linha de regressão. Fonte: Engenharia de risco.
Os resíduos são as diferenças entre os valores observados e os valores previstos em um modelo de regressão. Eles são importantes porque a análise dos resíduos ajuda a verificar as suposições do nosso modelo, bem como a verificar o ajuste geral do modelo.
Em um modelo de regressão linear, cada coeficiente representa a mudança esperada na variável dependente para uma mudança de uma unidade na variável independente correspondente, mantendo todas as outras variáveis constantes. Por exemplo, se o coeficiente de uma variável independente 𝑥𝑖 for 2, isso significa que, para cada aumento de uma unidade em 𝑥𝑖, espera-se que a variável dependente y aumente em 2 unidades, supondo que as outras variáveis permaneçam inalteradas.
Um intervalo de confiança de 95% significa que, se coletássemos muitas amostras e calculássemos um intervalo de confiança para cada amostra, cerca de 95% desses intervalos conteriam o verdadeiro parâmetro da população. Também poderíamos dizer que estamos 95% confiantes de que o valor do parâmetro está no intervalo estimado.
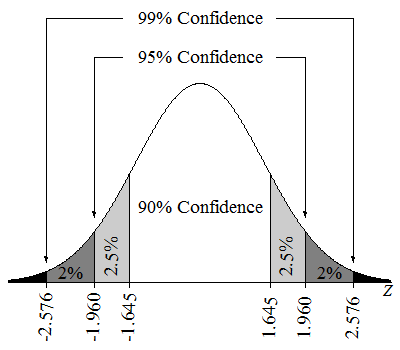
Intervalos de confiança em uma distribuição Z. Fonte: Lumen Learning.
A multicolinearidade ocorre quando duas ou mais variáveis independentes em um modelo de regressão múltipla estão altamente correlacionadas. Isso é um problema porque pode tornar as estimativas do coeficiente instáveis e difíceis de interpretar. A alta multicolinearidade também pode inflar os erros padrão dos coeficientes, levando a testes estatísticos menos confiáveis.
As técnicas de regularização são uma técnica poderosa para tratar a multicolinearidade em modelos de regressão. Eles também são usados para evitar o ajuste excessivo, adicionando uma penalidade ao modelo por ter coeficientes grandes. Isso ajuda a criar um modelo mais generalizável. As técnicas comuns de regularização incluem Lasso e Ridge Regression.
Se eu estivesse me preparando para uma entrevista que exigisse um conhecimento avançado de estatística, eu me certificaria de estudar estatística bayesiana e aprendizado de máquina.
Para estatísticas bayesianas, explore nossos cursos: Análise de dados bayesianos em Python e Fundamentos da análise de dados bayesianos em R. Para o aprendizado de máquina, confira os cursos ou trilhas de carreira do DataCamp sobre aprendizado de máquina, incluindo nossa trilha de carreira Cientista de Aprendizado de Máquina com Python e nosso curso Entendendo o Aprendizado de Máquina.
A estatística bayesiana envolve o uso do teorema de Bayes para atualizar a probabilidade de uma hipótese à medida que mais evidências ou informações se tornam disponíveis. Ele combina crenças anteriores com novos dados para formar uma probabilidade posterior.
O Markov Chain Monte Carlo é uma classe de algoritmos usados para obter amostras de uma distribuição de probabilidade quando a amostragem direta é difícil. É importante na estatística bayesiana porque permite a estimativa de distribuições posteriores, especialmente em modelos complexos em que soluções analíticas não são viáveis.
A troca de viés e variância no aprendizado de máquina envolve o equilíbrio de duas fontes de erro. O viés é o erro decorrente de suposições de modelos excessivamente simplistas, causando padrões de dados ausentes e de subajuste. A variância é o erro decorrente da sensibilidade excessiva às flutuações dos dados de treinamento, causando ajuste excessivo e capturando ruído em vez de padrões verdadeiros.
A inferência causal é uma ideia importante que vem recebendo muita atenção. A inferência causal é o processo de determinar se e como uma variável (a causa) afeta diretamente outra variável (o efeito), o que é uma característica distintiva entre a inferência causal e a mera correlação. A inferência causal é, na verdade, um grupo de métodos que visa a estabelecer uma relação de causa e efeito para entender se algo está funcionando, como uma intervenção ou algum tipo de tratamento. Se um pesquisador precisa entender se um medicamento está funcionando, por exemplo, a inferência causal pode ajudar a responder a essa pergunta.
A modelagem de equações estruturais é uma técnica para analisar as relações entre as chamadas variáveis observadas e latentes. É uma espécie de mistura entre regressão múltipla e análise fatorial. A modelagem de equações estruturais requer várias etapas, como a especificação do modelo, a estimativa e a avaliação. O SEM é conhecido por ser flexível, mas requer grandes tamanhos de amostra e, para usá-lo, você precisará de uma base teórica sólida.
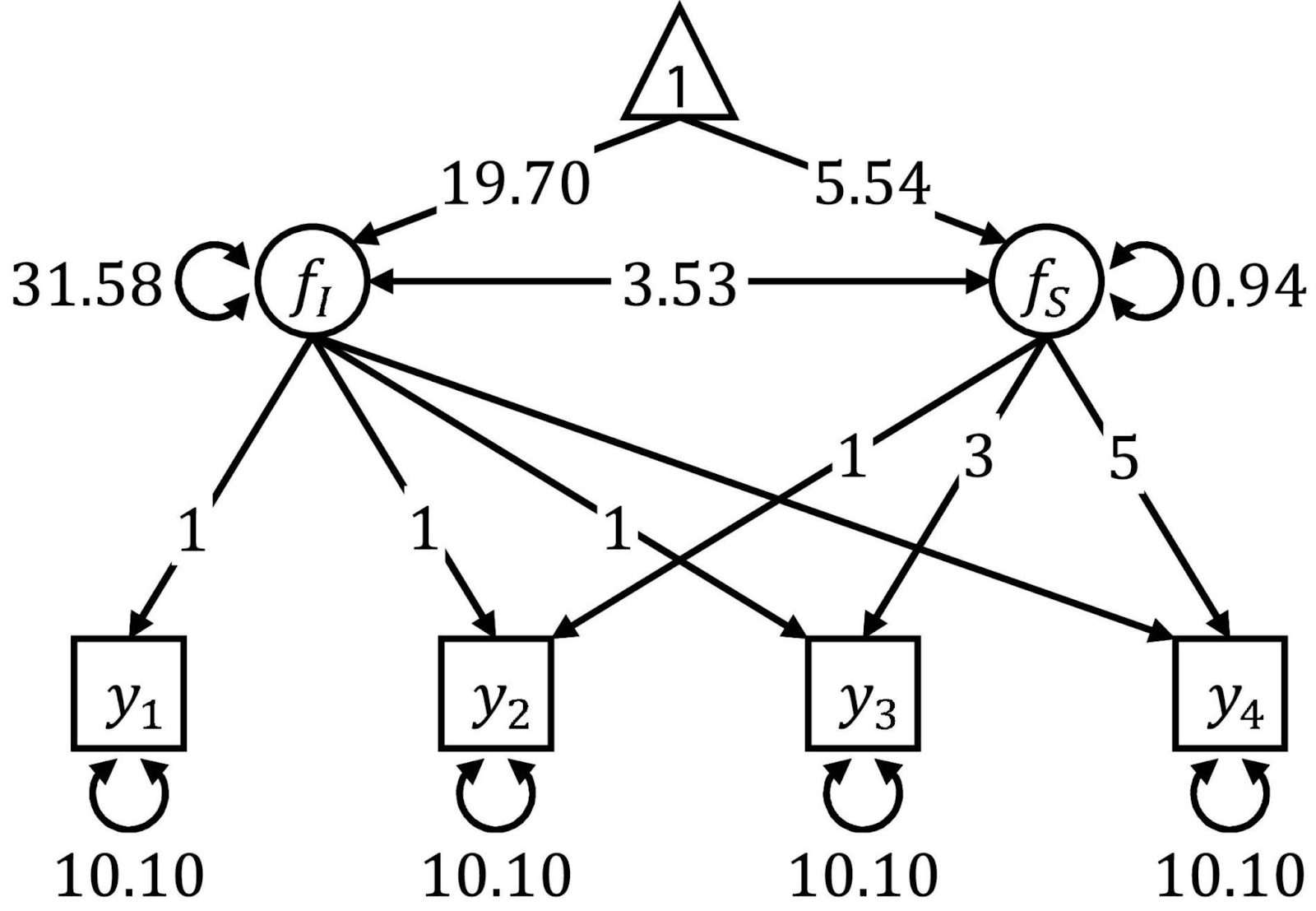
Os diagramas de caminho são frequentemente usados para visualizar o SEM. Fonte: Fronteiras.
As perguntas a seguir serão úteis se você estiver se candidatando a uma função mais focada na interseção entre ciência de dados e estatística. Os tópicos aqui incluem pré-processamento e limpeza de dados, teste A/B e projeto experimental, previsão de séries temporais e técnicas estatísticas avançadas.
Se você não estiver familiarizado com esses conceitos e quiser mesmo melhorar seu processo de entrevista, consulte estes recursos do DataCamp sobre testes A/B: Curso A/B Testing in Python ou Curso A/B Testing in R. Em seguida, para dominar a análise de séries temporais, escolha entre as faixas de habilidades Time Series with R ou Time Series with Python para obter experiência.
A divisão dos dados em conjuntos de treinamento e teste nos ajuda a avaliar o desempenho do modelo em dados não vistos. O conjunto de treinamento é usado para treinar o modelo, enquanto o conjunto de teste é usado para avaliar a capacidade de generalização do modelo para novos dados. Essa prática ajuda a detectar o ajuste excessivo e garante que o modelo possa ter um bom desempenho em dados do mundo real.
O overfitting ocorre quando um modelo aprende tanto os padrões subjacentes quanto o ruído nos dados de treinamento, levando a um excelente desempenho nos dados de treinamento, mas a um desempenho ruim em dados novos e não vistos. A subadaptação ocorre quando um modelo é simples demais para capturar os padrões subjacentes nos dados, resultando em um desempenho ruim nos dados de treinamento e nos novos dados.
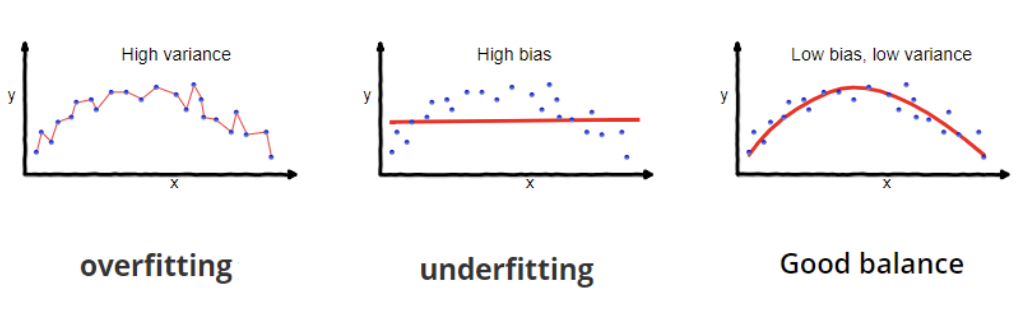
Excesso de ajuste e falta de ajuste. Fonte: Wikipedia.
Compreender o mecanismo de ausência de dados (MCAR, MAR, MNAR) é fundamental, pois orienta a escolha dos métodos apropriados para o tratamento de dados ausentes. O uso de técnicas inadequadas pode introduzir preconceitos, reduzir a validade dos resultados e levar a conclusões incorretas. Por exemplo, métodos simples de imputação podem ser adequados para dados MCAR, enquanto técnicas mais sofisticadas, como imputação múltipla ou métodos baseados em modelos, podem ser necessárias para que os dados MAR ou MNAR produzam estimativas imparciais.
A remoção de valores ausentes pode ser adequada quando a proporção de dados ausentes é muito pequena, normalmente inferior a 5%. Além disso, é uma boa ideia quando os dados ausentes são MCAR (Missing Completely at Random), o que significa que a ausência de dados não introduz viés. Por fim, eu consideraria a remoção de valores ausentes se o conjunto de dados for grande o suficiente para que a exclusão de um pequeno número de linhas não afete significativamente a análise.
Cada método de imputação tem seus prós e contras. Por exemplo, a imputação de média/mediana/modo é fácil de implementar, mas pode introduzir viés e distorcer as relações entre as variáveis. A imputação K-nearest neighbors (KNN) considera as relações entre as variáveis e pode levar a resultados mais precisos, mas pode ser computacionalmente cara.
O teste A/B é um método usado no design experimental para comparar duas versões de uma variável, como uma página da Web, um recurso de aplicativo ou uma campanha de marketing, para determinar qual delas tem melhor desempenho. É um tópico altamente relevante e aparece na seção "obrigatório" de muitas descrições de cargos.
A sazonalidade é um dos componentes da série temporal, além da tendência e dos resíduos (ruído). Para detectar a sazonalidade, primeiro podemos inspecionar visualmente a série temporal por meio de um gráfico de linhas. Se você suspeitar da presença de sazonalidade, poderá implementar uma decomposição da série temporal para descobrir o tamanho do efeito sazonal.
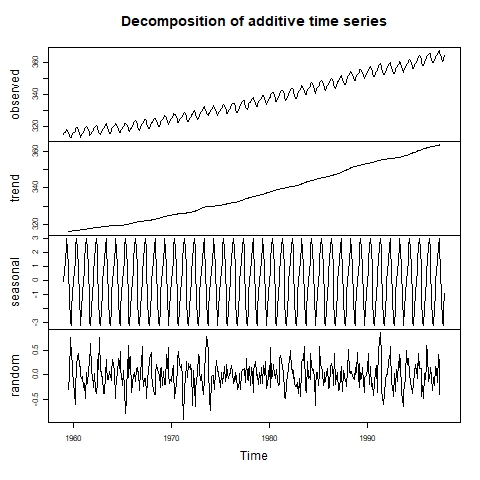
Série temporal decomposta visualmente. Fonte: Laboratório de Informática Ambiental.
Os modelos de suavização exponencial usam médias ponderadas de observações passadas para previsões simples e de curto prazo. Os modelos ARIMA combinam componentes de autorregressão, diferenciação e média móvel, o que os torna mais complexos, mas adequados para previsões de curto e longo prazo, especialmente com padrões complexos e autocorrelações significativas.
A validação cruzada é uma técnica para avaliar como um modelo de aprendizado de máquina será generalizado para um conjunto de dados independente. Isso envolve a divisão dos dados em várias dobras e a realização de várias rodadas de treinamento e validação.
Como o aperfeiçoamento das estatísticas e dos resultados da análise não está completo sem a comunicação do resultado às partes interessadas da empresa, a assistência às habilidades interpessoais é vital para os empregadores que estão contratando para funções de dados, especialmente porque nunca é fácil comunicar as percepções das estatísticas.
Para me comunicar efetivamente com diferentes partes interessadas, ajusto meu estilo com base em seus históricos e interesses. Por exemplo, para os executivos, priorizo o impacto nos negócios, usando linguagem comercial e recursos visuais para facilitar a tomada rápida de decisões. Por outro lado, para os desenvolvedores, forneço detalhes técnicos. Em ambos os casos, certifico-me de que os conceitos envolvidos sejam relevantes, claros e acessíveis, e incentivo perguntas e comentários. Essa abordagem garante que cada grupo de partes interessadas receba as informações de que precisa em um formato que lhe agrade.
Aprender estatística para funções de análise de dados pode ser um desafio. Muitas pessoas entram no campo com várias formações que não necessariamente envolvem muito ou nenhum conhecimento estatístico. A maioria dos recursos disponíveis on-line incentiva os alunos a se concentrarem apenas nas ferramentas, ignorando a importância vital das estatísticas.
Para aprimorar ainda mais seu conhecimento e suas oportunidades de carreira, considere a possibilidade de explorar recursos e cursos adicionais. Para obter um guia detalhado sobre como se tornar um estatístico, confira nossa postagem no blog, How to Become a Statistician (Como se tornar um estatístico), que oferece informações valiosas. Você pode complementar isso com nosso curso de carreira de Estatístico com R. Reserve um tempo para testar sua intuição com o curso Probability Puzzles in R (Enigmas de probabilidade em R ). Se você preferir Python, nosso curso de habilidades Fundamentos de Estatística com Python é uma ótima opção.
Boa sorte em suas próximas entrevistas!
Aprenda estatística com o DataCamp
Curso
Curso
Curso
blog
Austin Chia
15 min
blog
Tim Lu
9 min
blog
Artur Sannikov
12 min
blog
Abid Ali Awan
15 min
